| 本文所有教程及源码、软件仅为技术研究。不涉及计算机信息系统功能的删除、修改、增加、干扰,更不会影响计算机信息系统的正常运行。不得将代码用于非法用途,如侵立删! |
某星充电APP 充电桩信息
环境
- win10
- 某星充电 APP 7.9.0版本
- Android8.1
X-Ca-Signature参数分析
APP有防抓包检测,使用算法助手启动可正常抓包,分析数据包后发现关键的就是X-Ca-Timestamp和X-Ca-Signature, Timestamp很明显看出来是时间戳,重点分析一下Signature参数
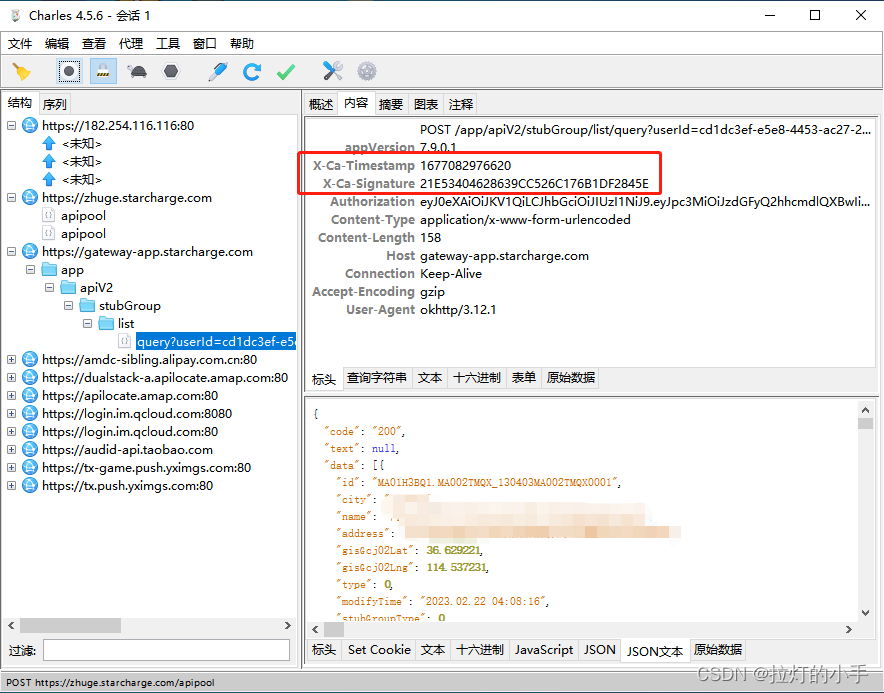
脱壳后搜索关键词:X-Ca-Signature
只有一处跟进去分析一下具体的参数构造
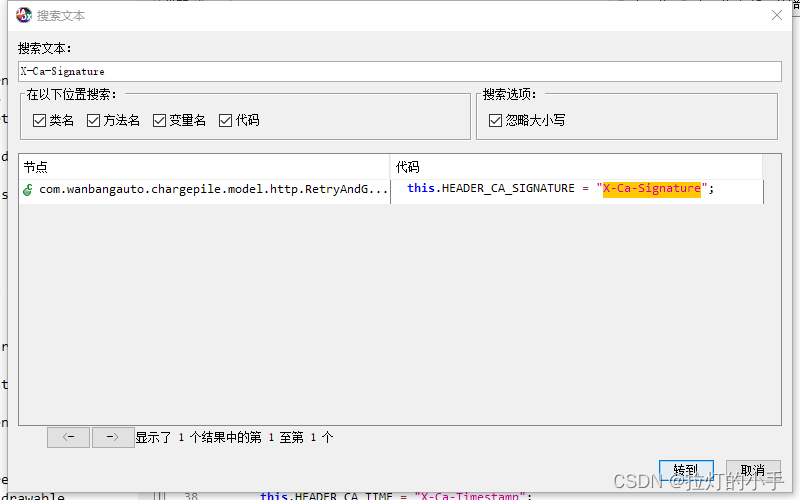
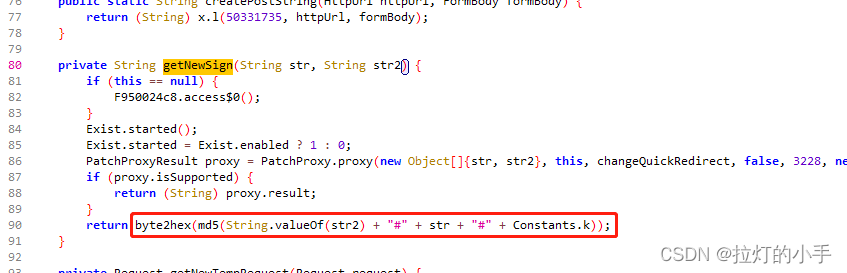
可以很明显看到是参数加上固定的key拼接后做了md5处理
Signature参数分析
站点详情有一个Signature参数是H5加载js生成的,定位到具体赋值的位置,然后往上跟可以看到是经过一个随机uid+时间戳生成的
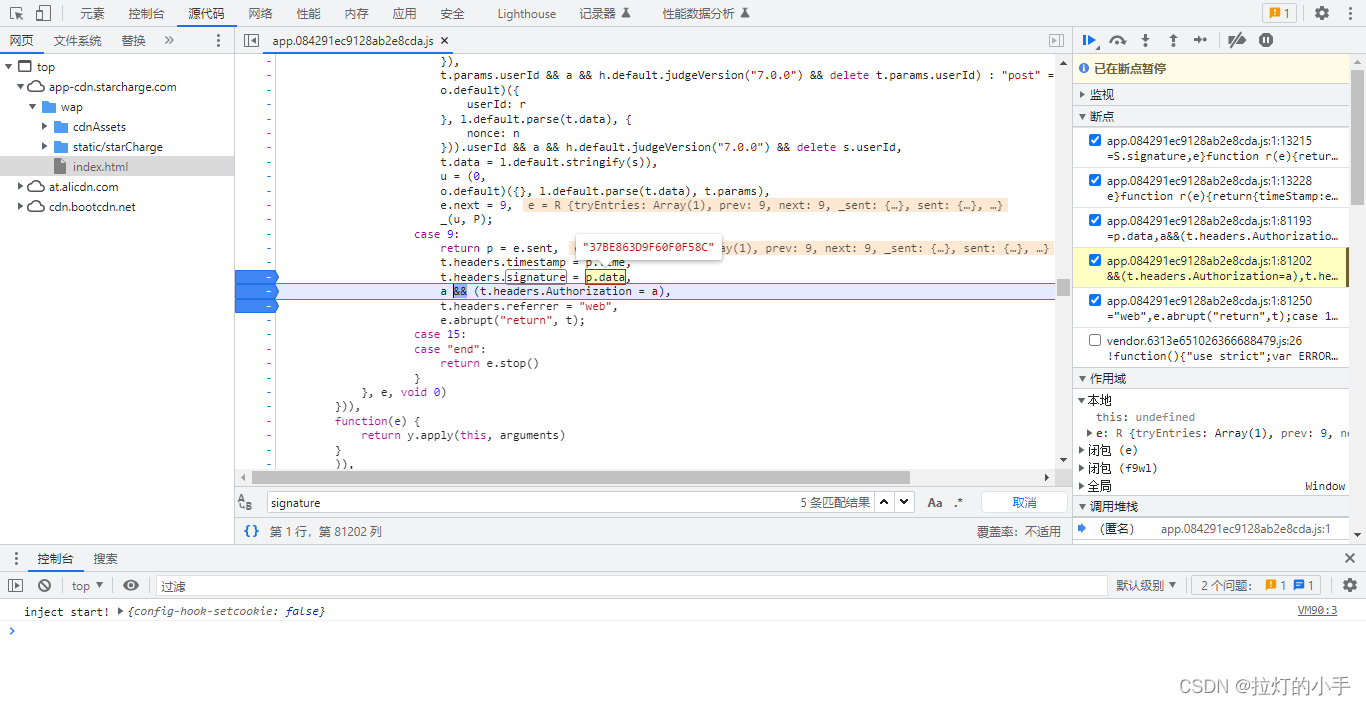
def get_signtrue(self, dic: dict):
"""
生成signature参数:7.9.0版本
"""
if (not "userId" in dic):
dic["userId"] = ""
new_list = []
for i in self.run_sort(dic.keys()):
new_list.append(f"{i}={dic[i]}")
return self.get_md5("&".join(new_list))
获取指定城市所有站点数据
def get_SearchStation(self, k, v):
"""
获取指定城市所有站点数据
"""
# 提取城市经纬度
center = v['districts'][0]['center']
lng = center.split(',')[0] # 经度
lat = center.split(',')[1] # 维度
CityCode = v['districts'][0]['adcode'] # 城市代码
_time = self.get_time() # 时间戳
page = 1
while True:
data = {
"stubGroupTypes": "0",
"currentLat": lat, # 当前坐标经度
"orderType": "1",
"orCityCode": CityCode, # 城市代码
"lng": lng, # 城市坐标维度
"pagecount": "50",
"currentLng": lng, # 当前坐标维度
"page": page,
"radius": "10000",
"lat": lat, # 城市坐标经度
"showPromoteLabel": "1"
}
X_Ca_Signature = self.get_X_Ca_Signature(data, _time)
headers = {
'appVersion': '7.9.1.1',
'X-Ca-Timestamp': _time,
'X-Ca-Signature': X_Ca_Signature,
'Connection': 'Keep-Alive',
'User-Agent': 'okhttp/3.12.1',
}
# res = requests.post(url=url, data=data, headers=headers, proxies=self.proxies, verify=True, allow_redirects=True, timeout=60)
res = self._parse_url(url=url, data=data, headers=headers)
# print(res.text)
if not res.text or res.status_code != 200:
logger.info(f'{k} 第{page}页数据获取失败')
return
if not res.json().get('data'):
logger.info(f'{k} 数据获取完成')
return
new_path = '数据' + os.sep + k
if not os.path.exists(new_path):
os.makedirs(new_path)
filename = new_path + os.sep + '站点列表.json'
# 多页的情况直接把新数据添加至已有文件
if os.path.exists(filename):
with open(filename, 'r+', encoding='utf-8') as f:
row_data = json.load(f)
row_data['data'] += res.json().get('data')
with open(filename, 'w', encoding='utf-8') as f1:
json.dump(row_data, f1, ensure_ascii=False)
else:
with open(filename, 'w', encoding='utf-8') as f:
# ensure_ascii 不适用ascii编码 解决不能显示中文问题
json.dump(res.json(), f, ensure_ascii=False)
logger.info(f'{k} 第{page}页数据获取成功')
page += 1
获取站点详情信息
def get_detail(self, stationId, name, lat, lng):
"""
获取站点详情
"""
_time = self.get_time() # 时间戳
nonce = self.get_nonce() # nonce参数
test_ = {
"id": stationId,
"gisType": "1",
"lat": lat,
"lng": lng,
"stubType": "0",
"versionFlag": "1",
"nonce": nonce,
"timestamp": _time
}
get_signtrue = self.get_signtrue(test_)
headers = {
"referrer": "web",
"Accept": "application/json, text/plain, */*",
"timestamp": _time,
"signature": get_signtrue,
"User-Agent": "Mozilla/5.0 (Linux; Android 8.1.0; Nexus 5X Build/OPM7.181205.001; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/61.0.3163.98 Mobile Safari/537.36",
"appVersion": "7.9.0",
"Accept-Language": "zh-CN,en-CA;q=0.8,en-US;q=0.6",
}
params = {
"id": stationId,
"gisType": "1",
"lat": lat,
"lng": lng,
"stubType": "0",
"versionFlag": "1",
"nonce": nonce,
}
response = requests.get(url, headers=headers, params=params)
print(response.text)
if not response.text or response.status_code != 200:
logger.info(f'{name} 数据获取失败')
return
if not response.json().get('data'):
logger.info(f'{name} 数据获取完成')
return
return response.json()
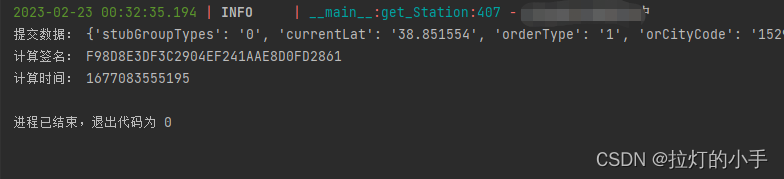
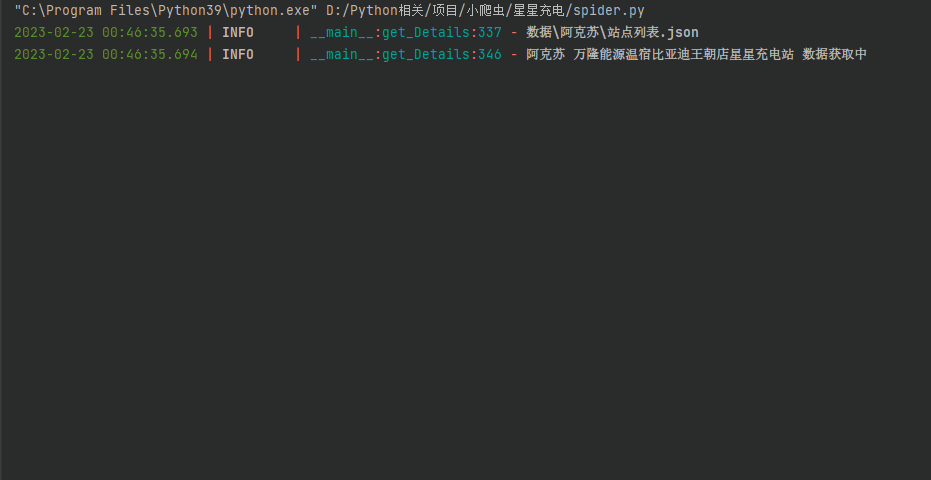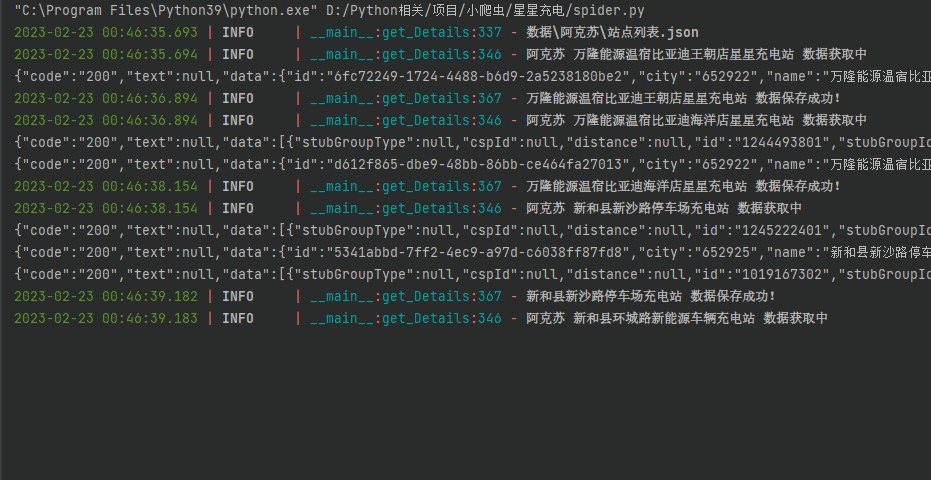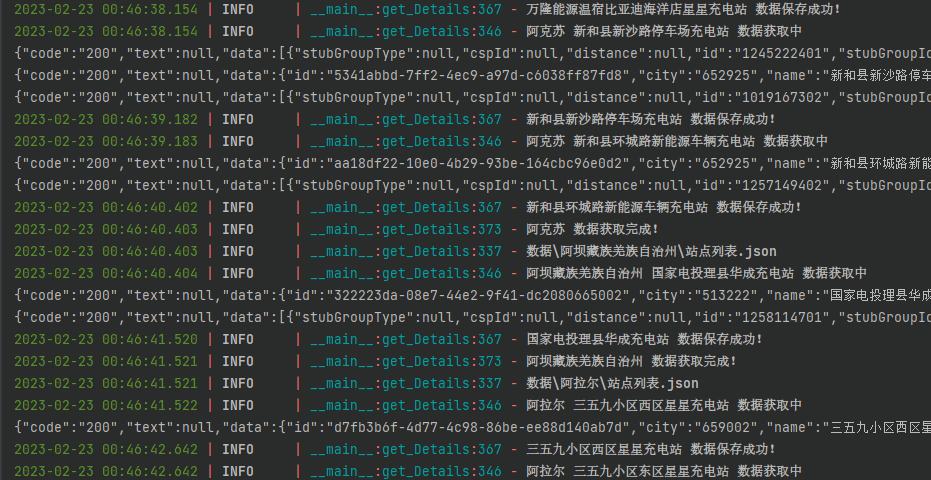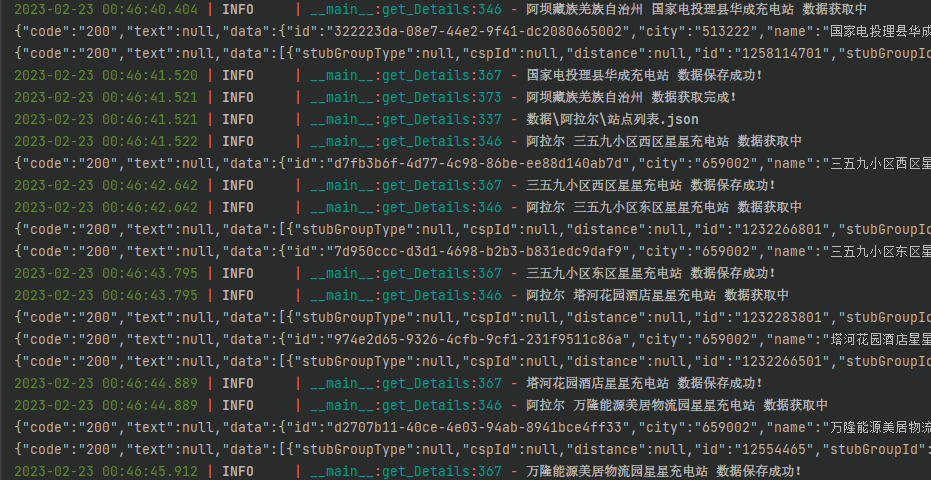
效果
资源下载
https://download.csdn.net/download/qq_38154948/87484473
| 本文仅供学习交流使用,如侵立删! |
标签:星星,get,self,爬虫,json,Signature,充电,lng,data From: https://www.cnblogs.com/c1033383881/p/17146531.html