注意力机制
注意力机制在NLP领域十分火热,克服了以往seq2seq翻译定位不准的问题,加强了词的前后联系,能够根据当前的语境,合理分配候选词的权重,提升翻译的准确率。
注意力机制的原理便是寻找当前语境(当前状态)与各个候选词之间的匹配度,计算各个候选词的得分,最终选取合成最佳的词汇。
为什么要引入注意力机制
在Attention诞生之前,已经有CNN和RNN及其变体模型了,那为什么还要引入attention机制?主要有两个方面的原因,如下:
(1)计算能力的限制:当要记住很多“信息“,模型就要变得更复杂,然而目前计算能力依然是限制神经网络发展的瓶颈。
(2)优化算法的限制:LSTM只能在一定程度上缓解RNN中的长距离依赖问题,且信息“记忆”能力并不高。
什么是注意力机制
在介绍什么是注意力机制之前,先让大家看一张图片。当大家看到下面图片,会首先看到什么内容?当过载信息映入眼帘时,我们的大脑会把注意力放在主要的信息上,这就是大脑的注意力机制。

同样,当我们读一句话时,大脑也会首先记住重要的词汇,这样就可以把注意力机制应用到自然语言处理任务中,于是人们就通过借助人脑处理信息过载的方式,提出了Attention机制。
3.注意力机制模型
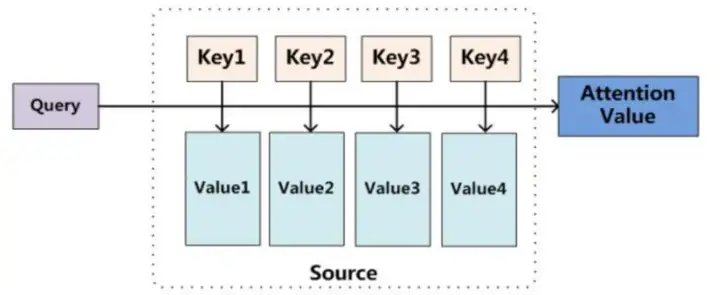
从本质上理解,Attention是从大量信息中筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如图展示的三个阶段。
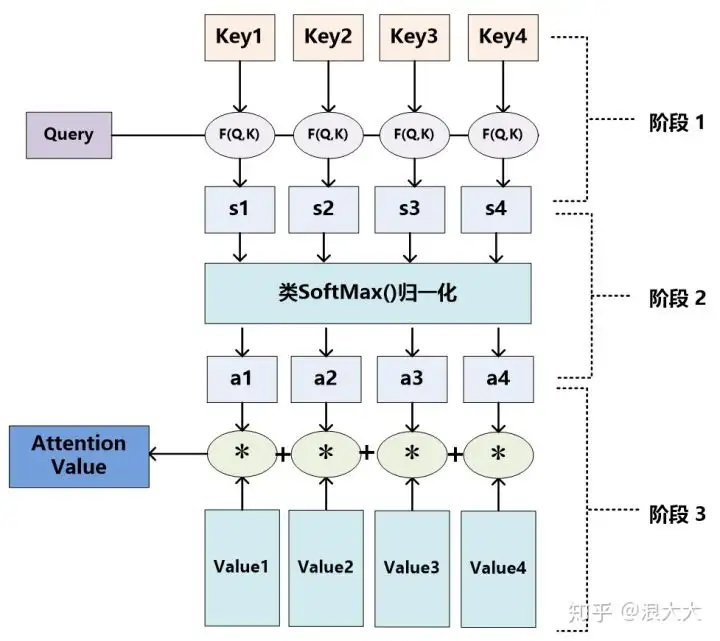
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个 Keyi ,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
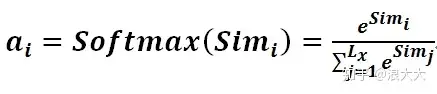
第二阶段的计算结果 ai 即为 Valuei 对应的权重系数,然后进行加权求和即可得到Attention数值:
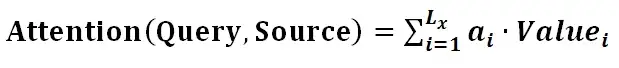
通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
========================================================================================
【python】注意力机制代码
https://blog.csdn.net/weixin_39190382/article/details/117711239
常见的注意力机制模块:
CBAM、SE、BAM、SK等模块均为常见注意力机制模块(或是称为一种operation。),是一种可插组件,便于移植;(另外,我想尝试分享一下我的观点,尽管我不知道这种理解是否正确(也请大家在阅读的时候带着一种批判性的思维阅读):所谓的注意力——attention,在我现在的认知中,本质上,它仅仅只是一组权重。例如,在CBAM中,我们通过一种方法来学习Input Signals(在计算机视觉中,Input通常是我们的feature maps)不同“域”(空域及通道域)上不同元素在该“域”上的重要性,最后通过这种“重要性”来对最初输入的特征进行相乘的操作,达到一种“修正”的效果(refined最初的特征)。)
https://aistudio.baidu.com/aistudio/projectdetail/2401371
========================================================================================
注意力机制可以解决什么问题?
神经网络中的注意力机制(Attention Mechanism)是在计算能力有限的情况下,将计算资源分配给更重要的任务,同时解决信息超载问题的一种资源分配方案。在神经网络学习中,一般而言模型的参数越多则模型的表达能力越强,模型所存储的信息量也越大,但这会带来信息过载的问题。那么通过引入注意力机制,在众多的输入信息中聚焦于对当前任务更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。
这就类似于人类的视觉注意力机制,通过扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多的注意力资源,获取更多与目标有关的细节信息,而忽视其他无关信息。通过这种机制可以利用有限的注意力资源从大量信息中快速筛选出高价值的信息。
1. Attention机制由来
意力机制借鉴了人类注意力的说法,比如我们在阅读过程中,会把注意集中在重要的信息上。在训练过程中,输入的权重也都是不同的,注意力机制就是学习到这些权重。最开始attention机制在CV领域被提出来,但后面广泛应用在NLP领域。
2. Encoder-Decoder 框架
需要注意的是,注意力机制是一种通用的思想和技术,不依赖于任何模型,换句话说,注意力机制可以用于任何模型。只是我们介绍注意力机制的时候更多会用encoder-decoder框架做介绍。
Encoder-Decoder 框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。下图是文本处理领域里 Encoder-Decoder 框架最抽象的一种表示。

图1:Encoder-Decoder框架
在NLP领域,可以把Encoder-Decoder框架看作是:将一个句子(篇章)转换成另一个句子(篇章)。最直观的例子就是机器翻译,将一种语言的表达翻译成另一种语言。对于句子对<source,target>,将给定输入句子
source,通过Encoder-Decoder框架生成目标句子target。其中,source和target都是一组单词序列:
Encoder是对source进行编码,转换成中间语义:
对于解码器Decoder,其任务是根据中间语义C和当前已经生成的历史信息来生成下一时刻要生成的单词:
3. 最常见的attention模型——Soft Attention
我们从最常见的Soft Attention模型开始介绍attention的基本思路。
在上一节介绍的Encoder-Decoder框架是没有体现出“注意力模型”的,为什么这么说呢?我们可以看下target的生成过程:
其中,是Decoder的非线性变换函数。从上面式子中可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子source的语义编码
都是一样的,没有任何区别。而语义编码
又是通过对source经过Encoder编码产生的,因此对于target中的任何一个单词,source中任意单词对某个目标单词
来说影响力都是相同的,这就是为什么说图1中的模型没有体现注意力的原因。
没有引入注意力的模型在输入句子比较短的时候问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,因此很多细节信息会被丢失。这也是为何要引入注意力模型的重要原因。
下面从一个例子入手,具体说明下注意力机制是怎么做的。
比如机器翻译任务,输入source是英文句子:Tom chase Jerry;输出target想得到中文:汤姆 追逐 杰瑞。在翻译“Jerry”这个单词的时候,在普通Encoder-Decoder模型中,source里的每个单词对“杰瑞”的贡献是相同的,很明显这样不太合理,因为“Jerry”对于翻译成“杰瑞”更重要。如果引入Attention模型,在生成“杰瑞”的时候,应该体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
每个英文单词的概率代表了翻译当前单词“杰瑞”时注意力分配模型分配给不同英文单词的注意力大小。同理,对于target中任意一个单词都应该有对应的source中的单词的注意力分配概率,可以把所有的注意力概率看作,其中
表示source长度,
表示target长度。而且,由于注意力模型的加入,原来在生成target单词时候的中间语义
就不再是固定的,而是会根据注意力概率变化的
,加入了注意力模型的Encoder-Decoder框架就变成了如图2所示。
 图2: 加入Attention模型的Encoder-Decoder框架
图2: 加入Attention模型的Encoder-Decoder框架
根据图2,生成target的过程就变成了下面形式:
因为每个可能对应着不同的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
其中,表示Encoder对输入英文单词的某种变换函数,比如如果Encoder是用RNN模型的话,这个
函数的结果往往是某个时刻输入
后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即:
其中,代表输入句子Source的长度,
代表在Target输出第
个单词时Source输入句子第
个单词的注意力分配系数,而
则是Source输入句子中第
个单词的语义编码。假设下标
就是上面例子所说的“汤姆”生成如下图:
 图3: C(汤姆)的计算过程
图3: C(汤姆)的计算过程
那另一个问题来了:注意力概率分布是怎么得到的呢?为了便于说明,我们假设图1的Encoder-Decoder框架中,Encoder和Decoder都采用RNN模型,那么图1变成下图4:
图4: RNN作为具体模型的Encoder-Decoder框架 那么注意力分配概率分布值的通用计算过程如图5: 图5: 注意力分配概率计算 上图中Attention机制的本质思想
从我的角度看,其实Attention机制可以看作,Target中每个单词是对Source每个单词的加权求和,而权重是Source中每个单词对Target中每个单词的重要程度。因此,Attention的本质思想会表示成下图6:
图6: Attention机制的本质思想
将Source中的构成元素看作是一系列的<Key, Value>数据对,给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,即权重系数;然后对Value进行加权求和,并得到最终的Attention数值。将本质思想表示成公式如下:
其中,表示Source的长度。
深度学习中的注意力机制中提到:
因为在计算 Attention 的过程中,Source 中的 Key 和 Value 合二为一,指向的 是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种 能够体现本质思想的结构。
另一种解释是将Attention机制看作一种软寻址。
因此,Attention机制的具体计算过程实际上分成了3个阶段,如图7:
图7: Attention机制的具体计算过程第一阶段可以引入不同的函数和计算机制,根据Query和某个
第二阶段引入类似SoftMax的计算方式,对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用的公式如下:
第三阶段的计算结果即为
对应的权重系数,然后进行加权求和即可得到Attention数值:
通过如上三个阶段的计算,就可以求出针对Query的Attention数值。
4. 其他attention模型
soft vs. hard
上面介绍的是soft Attention,hard Attention的区别在于soft Attention中是概率分布,而hard Attention取值为0/1。Hard Attention在图像上有使用,具体可见 引入attention机制。
global vs. local
这里的global attention其实就是soft Attention,global attention需要考虑encoder中所有的;而local Attention直观上理解是只考虑局部的
。
self-attention
Self-attention是Google在transformer模型中提出的,上面介绍的都是一般情况下Attention发生在Target元素Query和Source中所有元素之间。而Self Attention,指的是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力机制。当然,具体的计算过程仍然是一样的,只是计算对象发生了变化而已。
上面内容也有说到,一般情况下Attention本质上是Target和Source之间的一种单词对齐机制。那么如果是Self Attention机制,到底学的是哪些规律或者抽取了哪些特征呢?或者说引入Self Attention有什么增益或者好处呢?仍然以机器翻译为例来说明,如图8和图9:
图8: self-attention 实例1 图9: self-attention实例2
从图8和图9可以看出,self-attention可以捕获同一个句子之间的一些句法特征(如图8有一定距离的短语结构)或者语义特征(如图9展示的its的指代对象Law)。
很明显,引入 Self Attention 后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。但是Self-Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此之外,Self-Attention对于增加计算的并行性也有直接帮助作用。这是为何Self-Attention逐渐被广泛使用的主要原因。
Scaled Dot-Product Attention
具体做法是点乘和
,然后除以
,并经过Softmax,以此得到
的权重。也就是说Attention计算过程如下式,其中
是scaled factor:
注意力的计算一般有两种:加性注意力(additive attention)、乘法(点积)注意力(multiplicative attention)。(这里可以和第3部分计算相似度对应)
加性注意力是最经典的注意力机制,它使用了有一个隐藏层的前馈网络(全连接)来计算注意力; 乘法注意力就是Transformer用的方式。这两种注意力在复杂度上是相似的,但是乘法注意力在实践中要更快速、具有高效的存储,因为它可以使用矩阵操作更高效地实现。
Transformer原文:
While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
Multi-Attention
Multi-Head Attention是用不同的得到不同的Attention,最后将这些Attention拼接起来作为输出。公式如下:
其中, ;在Transformer模型中,
。
Scaled Dot-Product Attention和Multi-Attention如下图所示:
图:(left) Scaled Dot-Product Attention. (right)Multi-Head Attention作者:张虾米试错
链接:https://www.jianshu.com/p/3968af85d3cb
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://www.jianshu.com/p/3968af85d3cb
https://blog.csdn.net/qq_37492509/article/details/114991482
https://imzhanghao.com/2021/09/01/attention-mechanism/
https://www.jianshu.com/p/3968af85d3cb
标签:attention,Attention,Encoder,单词,机制,注意力 From: https://www.cnblogs.com/emanlee/p/17128676.html