前言 本文回顾了深度多模态学习方法的演变,并讨论了使主干对各种下游任务具有鲁棒性所需的预训练的类型和目标。本文转载自专知
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
计算机视觉入门1v3辅导班
多模态表示学习是一种学习从不同模态及其相关性中嵌入信息的技术,已经在视觉问答(Visual Question Answering, VQA)、视觉推理自然语言(Natural Language for Visual Reasoning, NLVR)和视觉语言检索(Vision Language Retrieval, VLR)等领域取得了显著的成功。在这些应用中,来自不同模态的跨模态交互和互补信息对于高级模型执行任何多模态任务至关重要,如理解、识别、检索或优化生成。研究人员提出了不同的方法来解决这些任务。

https://www.zhuanzhi.ai/paper/e354713123ff3c4d72713e37300d0784基于transformer的架构的不同变体在多种模态上表现出色。本综述介绍了关于深度学习多模态架构的进化和增强,以处理各种跨模态和现代多模态任务的文本、视觉和音频特征的全面文献。本文总结了(i)最近任务特定的深度学习方法,(ii)预训练类型和多模态预训练目标,(iii)从最先进的预训练多模态方法到统一架构,以及(iv)多模态任务类别和未来可能的改进,可以设计出更好的多模态学习。为新研究人员准备了一个数据集部分,涵盖了预训练和微调的大多数基准。最后,探讨了面临的主要挑战、差距和潜在的研究方向。与我们的综述相关的不断更新的论文列表保存在https://github.com/marslanm/multimodality-representation-learning上。
1. 引言
多模态系统利用两个或多个输入模态,如音频、文本、图像或视频,来产生与输入不同的输出模态。跨模态系统是多模态系统的一个分支,它利用一种模态的信息来增强另一种模态的性能。例如,多模态系统将使用图像和文本模态来评估情况并执行任务,而跨模态系统将使用图像模态来输出文本模态[1,2]。视听语音识别(AVSR)[3]、检测模因[4]中的宣传和视觉问答(VQA)[5]都是多模态系统的例子。多模态表示学习技术通过分层处理原始异构数据来缩小不同模态之间的异构鸿沟。来自不同模态的异构特征以上下文信息[6]的形式提供额外的语义。因此,互补信息可以通过多种模态学习到。例如,视觉模态可以通过在AVSR中提供[7]唇动来帮助语音识别。最近的深度学习方法的高级变体通过在表示空间中映射不同的模态,解决了经典的多模态挑战(相关性、翻译、对齐、融合)。
近年来,大量针对特定任务的深度学习方法提升了不同多模态任务的性能[8]。最近,由于语义丰富的表示和大规模公开可用模型[9],自然语言处理(NLP)和计算机视觉(CV)的预训练和微调的实现得到了最大的关注。本文回顾了深度多模态学习方法的演变,并讨论了使主干对各种下游任务具有鲁棒性所需的预训练的类型和目标。大多数预训练方法都基于Transformer,这提出了统一架构的想法,以处理所有下游任务的所有模态[10]。本综述全面介绍了最近几种预训练和统一架构的方法,以及它们在基准、应用和下游任务评估上的性能。
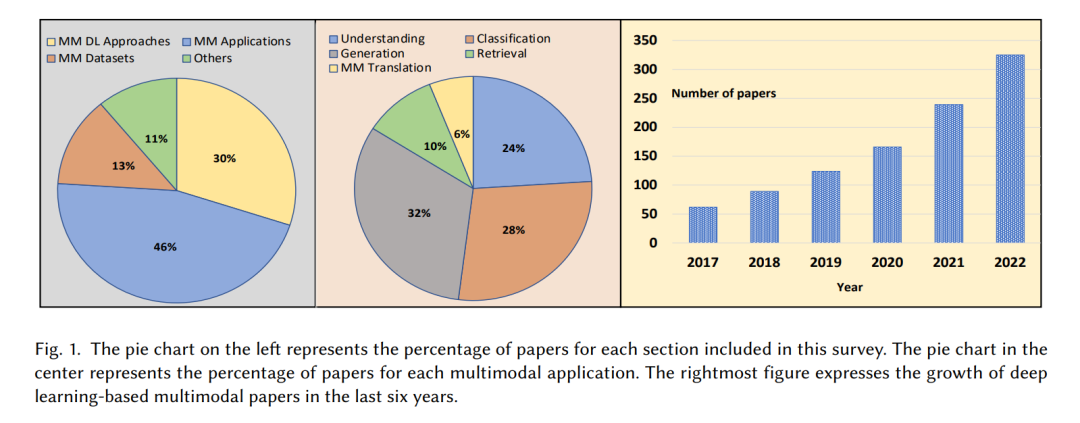 去年,已经发表了一些关于视觉语言预训练的研究[11,12]。相比之下,我们涵盖了在最近的工作[13]中展示的视觉、语言和音频预训练模型的架构细节。除了讨论预训练类型外,我们还回顾了预训练目标的通用和多模态版本。此外,我们总结了最近的统一架构(通用模型),这些架构消除了对不同下游任务的微调,最终减少了时间和计算复杂性。与最近的调研相反,我们更关注由视觉和音频模式增强的NLP应用,例如情感分析、文档理解、假新闻检测、检索、翻译和其他推理应用。图1展示了本次调研中包含的深度学习多模态论文的分类百分比。该柱状图显示了每年互联网上深度学习多模态方法的发展和可用性。本次调研的贡献如下:
我们对多模态表示学习技术进行了全面的调研,以有效的方式弥合语言、视觉和音频输入之间的差距。
去年,已经发表了一些关于视觉语言预训练的研究[11,12]。相比之下,我们涵盖了在最近的工作[13]中展示的视觉、语言和音频预训练模型的架构细节。除了讨论预训练类型外,我们还回顾了预训练目标的通用和多模态版本。此外,我们总结了最近的统一架构(通用模型),这些架构消除了对不同下游任务的微调,最终减少了时间和计算复杂性。与最近的调研相反,我们更关注由视觉和音频模式增强的NLP应用,例如情感分析、文档理解、假新闻检测、检索、翻译和其他推理应用。图1展示了本次调研中包含的深度学习多模态论文的分类百分比。该柱状图显示了每年互联网上深度学习多模态方法的发展和可用性。本次调研的贡献如下:
我们对多模态表示学习技术进行了全面的调研,以有效的方式弥合语言、视觉和音频输入之间的差距。
- 解决多模态的特定任务和基于transformer的预训练架构的发展。
- 详细阐述了预训练类型、多模态学习的高级预训练目标、详细的架构讨论和比较。
- 统一架构的开发,以解决所有下游任务的多种模式进行调研。
- 我们开发了深度多模态架构和复杂多模态应用的分类。
- 数据集部分描述了用于预训练、微调和评估多模态方法的所有基准的综合信息,为初学者提供了现成的详细信息。
- 最后,阐述了该领域的主要挑战、开放缺口和可能的未来预测。
2. 多模态深度学习方法
2. 多模态深度学习方法
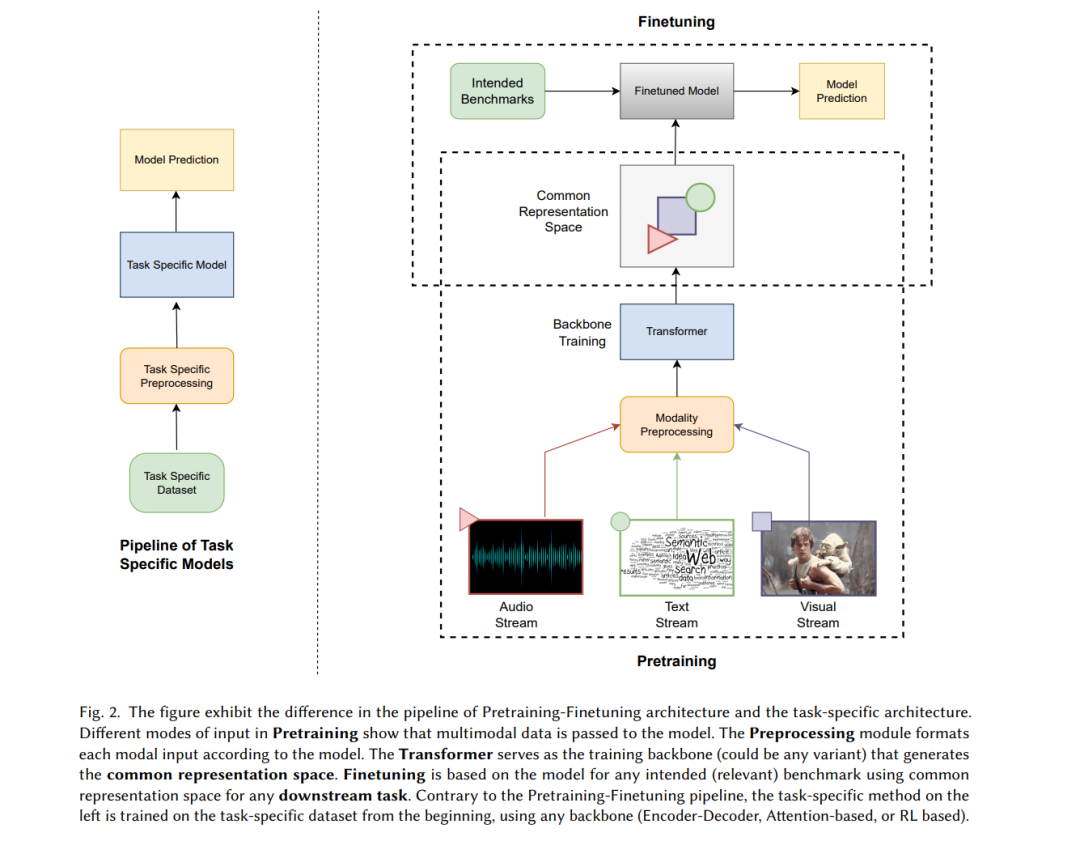
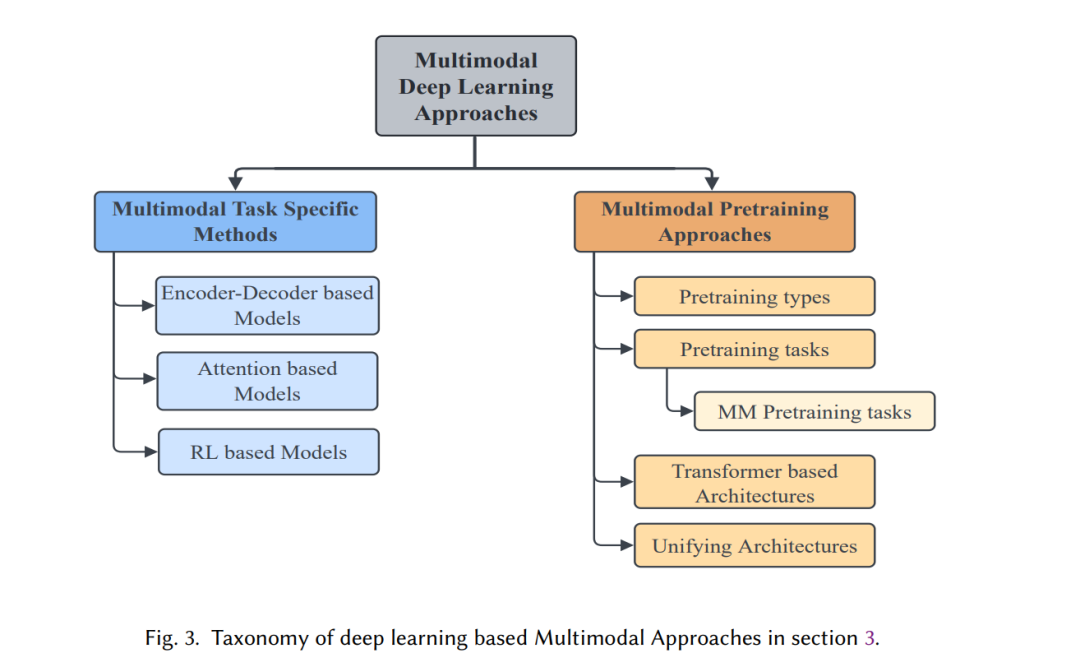
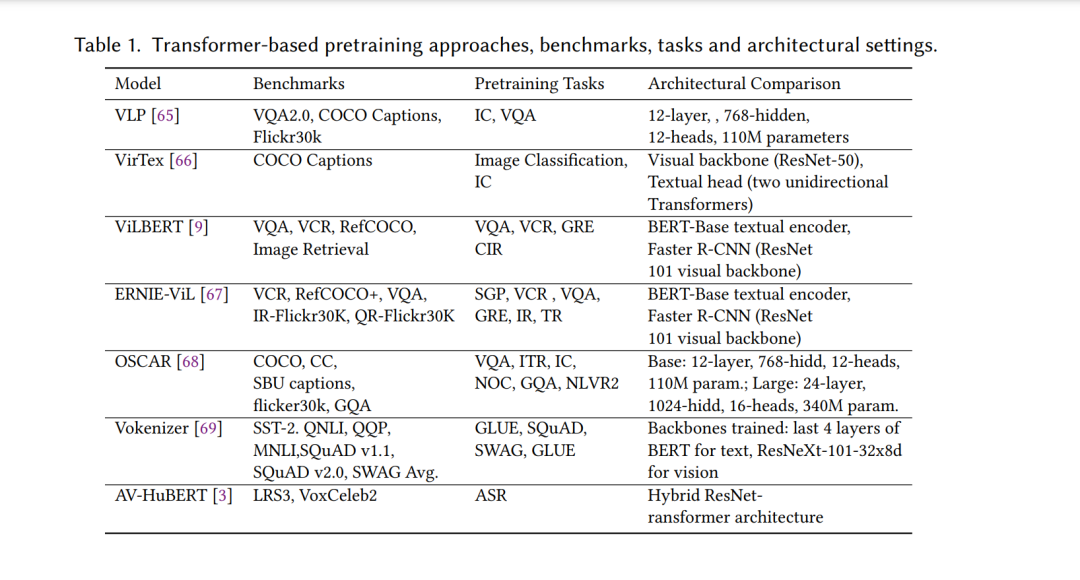
本节介绍了多模态架构的众多变体,主要分为特定任务架构和预训练-微调架构(管道如图2所示)。图3展示了第3节的分类。第3.1节是本研究中提到的任务的首字母缩略词。第3.2节全面总结了特定任务的方法,这些方法是近年来转变为大规模预训练方法的先进多模态方法的基础。第3.3节演示了在多模态数据集上训练的预训练过程、类型、目标和SOTA框架,以执行增强的NLP和跨模态任务。此外,本文最后还详细介绍了最近获得关注的统一体系结构。第3.4小节对SOTA方法在各种多模态任务上产生的结果进行了比较讨论。
 3. 多模态应用
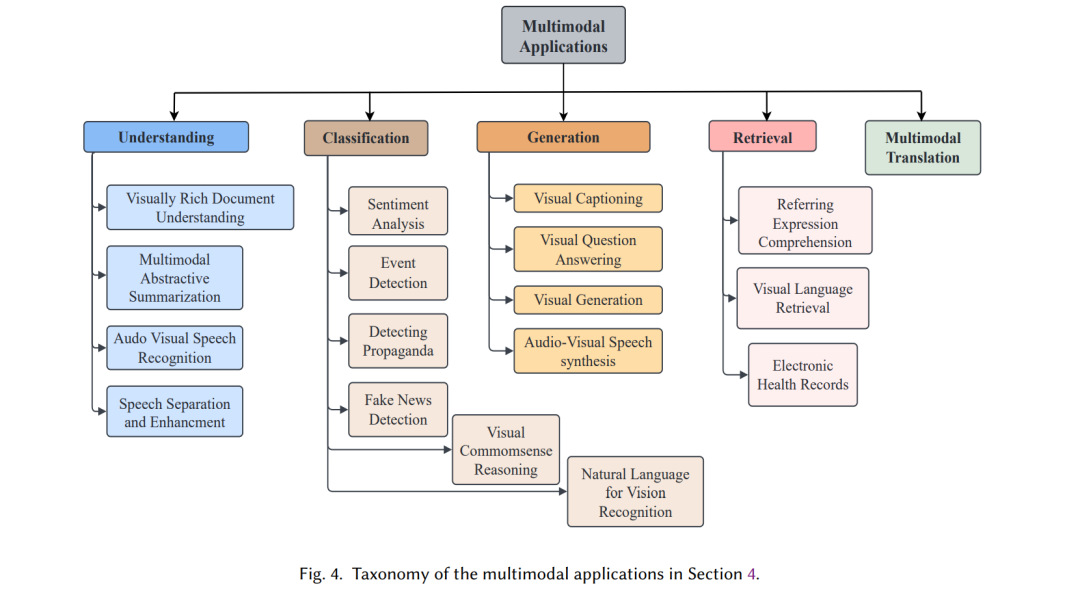
本节展示了由深度学习架构增强的多模态应用程序的分类细节,如图4所示。多模态任务分为主要类别:理解、分类、检索和生成。针对每个多模态应用,讨论了最佳性能架构的基准、评估指标、描述和比较。
3. 多模态应用
本节展示了由深度学习架构增强的多模态应用程序的分类细节,如图4所示。多模态任务分为主要类别:理解、分类、检索和生成。针对每个多模态应用,讨论了最佳性能架构的基准、评估指标、描述和比较。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
其它文章 深度理解变分自编码器(VAE) | 从入门到精通 计算机视觉入门1v3辅导班 计算机视觉交流群 用于超大图像的训练策略:Patch Gradient Descent CV小知识讨论与分析(5)到底什么是Latent Space? 【免费送书活动】关于语义分割的亿点思考 新方案:从错误中学习,点云分割中的自我规范化层次语义表示 经典文章:Transformer是如何进军点云学习领域的? CVPR 2023 Workshop | 首个大规模视频全景分割比赛 如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策 Transformer交流群 经典文章:Transformer是如何进军点云学习领域的? CVPR 2023 Workshop | 首个大规模视频全景分割比赛 如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策 U-Net在2022年相关研究的论文推荐 用少于256KB内存实现边缘训练,开销不到PyTorch千分之一 PyTorch 2.0 重磅发布:一行代码提速 30% Hinton 最新研究:神经网络的未来是前向-前向算法 聊聊计算机视觉入门 FRNet:上下文感知的特征强化模块 DAMO-YOLO | 超越所有YOLO,兼顾模型速度与精度 《医学图像分割》综述,详述六大类100多个算法 如何高效实现矩阵乘?万文长字带你从CUDA初学者的角度入门 近似乘法对卷积神经网络的影响 BT-Unet:医学图像分割的自监督学习框架 语义分割该如何走下去? 轻量级模型设计与部署总结 从CVPR22出发,聊聊CAM是如何激活我们文章的热度! 入门必读系列(十六)经典CNN设计演变的关键总结:从VGGNet到EfficientNet 入门必读系列(十五)神经网络不work的原因总结 入门必读系列(十四)CV论文常见英语单词总结 入门必读系列(十三)高效阅读论文的方法 入门必读系列(十二)池化各要点与各方法总结 TensorRT教程(三)TensorRT的安装教程 TensorRT教程(一)初次介绍TensorRT TensorRT教程(二)TensorRT进阶介绍
标签:模态,架构,综述,训练,学习,任务,视觉 From: https://www.cnblogs.com/wxkang/p/17128458.html