前言 本文旨在计算和内存限制的情况下,解决在大规模图像上训练现有CNN 架构的问题。提出PatchGD,它基于这样的假设:与其一次对整个图像执行基于梯度的更新,不如一次只对图像的一小部分执行模型更新,确保其中的大部分是在迭代过程中覆盖。
当在大规模图像上训练模型时,PatchGD 广泛享有更好的内存和计算效率。尤其是在计算内存有限的情况下,该方法在处理大图像时比标准梯度下降法更稳定和高效。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文:https://arxiv.org/pdf/2301.13817.pdf
论文:https://arxiv.org/pdf/2301.13817.pdf
论文出发点
现有的使用 CNN 的深度学习模型主要在相对较低的分辨率范围(小于 300 × 300 像素)上进行训练和测试。这部分是因为广泛使用的图像基准数据集。在高分辨率图像上使用这些模型会导致相关激活大小的二次增长,而这反过来又会导致训练计算量和内存占用量的大幅增加。此外,当可用的 GPU 内存有限时,CNN 无法处理如此大的图像。 解决使用 CNN 处理超大图像问题的工作非常有限。其中最常见的方法是通过降尺度来降低图像的分辨率。然而,这会导致与小尺度特征相关的信息大量丢失,并且会对与图像相关的语义上下文产生不利影响。另一种策略是将图像划分为重叠或不重叠的图块,然后按顺序处理这些图块。然而,这种方法并不能保证块之间的语义链接将被保留,并且它会阻碍学习过程。存在几种类似的策略来尝试学习大图像中包含的信息,但是,它们无法捕获全局上下文限制了它们的使用。这篇论文提出一种可扩展的训练策略,旨在构建具有非常大的图像、非常低的内存计算或两者结合的神经网络。
创新思路 本文认为“大图像”不应该根据它们所包含的像素数量来简单解释,而是如果相应的计算内存预算很小,则图像应该被认为太大而无法使用 CNN 进行训练。 因此提出PatchGD ,一次只使用图像的一部分执行模型更新,同时还确保它在多个步骤的过程中看到几乎完整的上下文。 方法 General description PatchGD 的核心是构建或填充 Z 块。无论输入的哪些部分用于执行模型更新,Z 都会根据从前几个更新步骤中为图像的不同部分获取的信息构建完整图像的编码。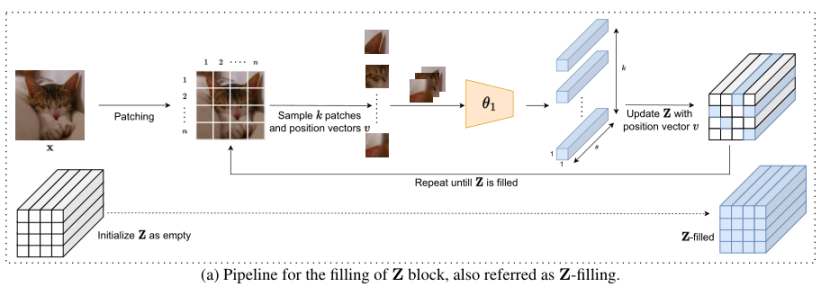
Z 块的使用如图a 所示 。首先将输入图像分成 m×n 块,每个块使用 θ1 作为独立图像处理。模型的输出与各patch对应的位置相结合,并将它们作为批次传递给模型进行处理,用于填充 Z 的各个部分。
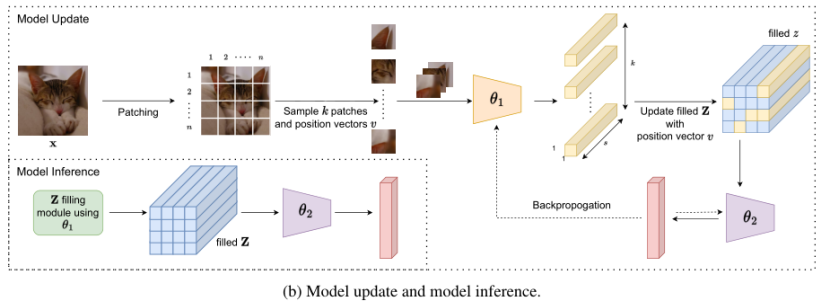
为了构建端到端 CNN 模型,添加了一个包含卷积层和全连接层的小型子网络,该子网络处理 Z 中包含的信息,并将其转换为分类任务所需的概率向量。模型训练和推理的pipeline如下图 b 所示。在训练期间,更新模型组件 θ1 和 θ2。基于从输入图像中采样的一小部分patch,使用 θ1 的最新状态计算相应的编码,输出用于更新已填充 Z 中的相应条目。然后使用部分更新的 Z 进一步计算损失函数值,并通过反向传播更新模型参数。
Z 块的使用如图a 所示 。首先将输入图像分成 m×n 块,每个块使用 θ1 作为独立图像处理。模型的输出与各patch对应的位置相结合,并将它们作为批次传递给模型进行处理,用于填充 Z 的各个部分。
为了构建端到端 CNN 模型,添加了一个包含卷积层和全连接层的小型子网络,该子网络处理 Z 中包含的信息,并将其转换为分类任务所需的概率向量。模型训练和推理的pipeline如下图 b 所示。在训练期间,更新模型组件 θ1 和 θ2。基于从输入图像中采样的一小部分patch,使用 θ1 的最新状态计算相应的编码,输出用于更新已填充 Z 中的相应条目。然后使用部分更新的 Z 进一步计算损失函数值,并通过反向传播更新模型参数。
 Mathematical formulation
Mathematical formulation
PatchGD 避免一次性对整个图像样本进行模型更新,而是仅使用部分图像计算梯度并更新模型参数。由此,其模型更新步骤可以表示为:
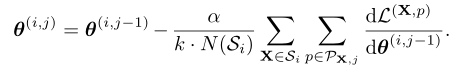
其中, i 表示某个 epoch 内的 mini-batch 迭代的索引, j 表示内部迭代。在每次内部迭代中,从输入图像 X中采样 k 个补丁,执行梯度的更新。
其中, i 表示某个 epoch 内的 mini-batch 迭代的索引, j 表示内部迭代。在每次内部迭代中,从输入图像 X中采样 k 个补丁,执行梯度的更新。
算法 1 描述了对一批 B 图像的模型训练。作为模型训练过程的第一步,初始化每个输入图像对应的Z:
 算法 2 描述了 Z 的填充过程:
算法 2 描述了 Z 的填充过程:

结果
结果
本文在UltraMNIST和PANDA前列腺癌分级评估两个数据集上进行实验验证。其中,UltraMNIST 是一个分类数据集,每个样本包含 3-5 个不同比例的 MNIST 数字,这些数字位于图像中的随机位置,数字之和介于 0-9 之间。PANDA 数据集包含高分辨率组织病理学图像。
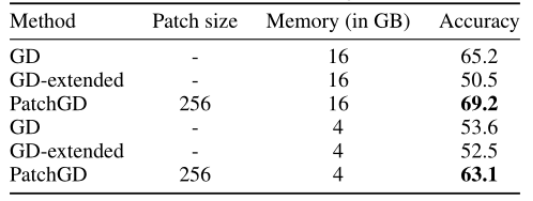
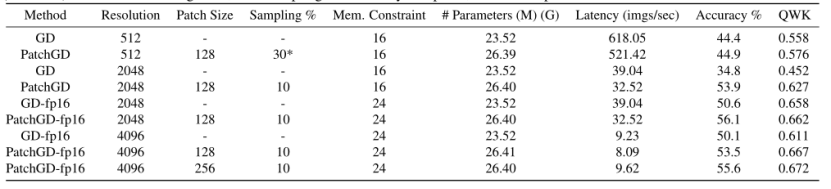
使用 ResNet50 架构在 UltraMNIST 分类任务中,对于512 × 512图像,PatchGD 的性能优于 GD 以及 GD-extended 的大幅提升:
同理,使用MobileNetV2 架构的对比情况:
同理,使用MobileNetV2 架构的对比情况:
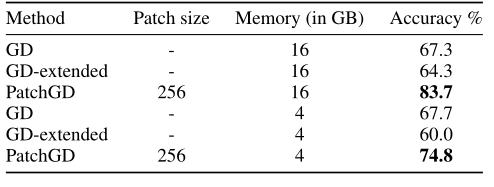
PANDA 数据集上使用 Resnet50的验证情况:
PANDA 数据集上使用 Resnet50的验证情况:
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
其它文章 姿态估计端到端新方案 | DirectMHP:用于全范围角度2D多人头部姿势估计 深度理解变分自编码器(VAE) | 从入门到精通 计算机视觉入门1v3辅导班 计算机视觉交流群 用于超大图像的训练策略:Patch Gradient Descent CV小知识讨论与分析(5)到底什么是Latent Space? 【免费送书活动】关于语义分割的亿点思考 新方案:从错误中学习,点云分割中的自我规范化层次语义表示 经典文章:Transformer是如何进军点云学习领域的? CVPR 2023 Workshop | 首个大规模视频全景分割比赛 如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策 Transformer交流群 经典文章:Transformer是如何进军点云学习领域的? CVPR 2023 Workshop | 首个大规模视频全景分割比赛 如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策 U-Net在2022年相关研究的论文推荐 用少于256KB内存实现边缘训练,开销不到PyTorch千分之一 PyTorch 2.0 重磅发布:一行代码提速 30% Hinton 最新研究:神经网络的未来是前向-前向算法 聊聊计算机视觉入门 FRNet:上下文感知的特征强化模块 DAMO-YOLO | 超越所有YOLO,兼顾模型速度与精度 《医学图像分割》综述,详述六大类100多个算法 如何高效实现矩阵乘?万文长字带你从CUDA初学者的角度入门 近似乘法对卷积神经网络的影响 BT-Unet:医学图像分割的自监督学习框架 语义分割该如何走下去? 轻量级模型设计与部署总结 从CVPR22出发,聊聊CAM是如何激活我们文章的热度! 入门必读系列(十六)经典CNN设计演变的关键总结:从VGGNet到EfficientNet 入门必读系列(十五)神经网络不work的原因总结 入门必读系列(十四)CV论文常见英语单词总结 入门必读系列(十三)高效阅读论文的方法 入门必读系列(十二)池化各要点与各方法总结 TensorRT教程(三)TensorRT的安装教程 TensorRT教程(一)初次介绍TensorRT TensorRT教程(二)TensorRT进阶介绍
标签:Descent,训练,Gradient,模型,更新,Patch,图像,CNN,入门 From: https://www.cnblogs.com/wxkang/p/17127457.html