点亮 ⭐️ Star · 照亮开源之路
GitHub:https://github.com/apache/dolphinscheduler

精彩回顾
近期,BIGO 的大数据研发工程师许名勇在社区线上 Meetup 上给大家分享了主题为《DS 及 SPARK 在 BIGO 的应用和改进》的演讲。
主要介绍了 BIGO 如何使用 DophinScheduler 来调度以 SPARK 为主的多种类型的离线任务,以及为了满足业务需求、提升用户使用体验,在 DS 和 Spark 上所做的各种改进。
讲师介绍
精彩回顾
近期,BIGO 的大数据研发工程师许名勇在社区线上 Meetup 上给大家分享了主题为《DS 及 SPARK 在 BIGO 的应用和改进》的演讲。
主要介绍了 BIGO 如何使用 DophinScheduler 来调度以 SPARK 为主的多种类型的离线任务,以及为了满足业务需求、提升用户使用体验,在 DS 和 Spark 上所做的各种改进。
讲师介绍

许名勇
Bigo 大数据研发工程师
文章整理:白鲸开源-曾辉
今天的演讲会围绕下面三点展开:
许名勇
Bigo 大数据研发工程师
文章整理:白鲸开源-曾辉
今天的演讲会围绕下面三点展开:
- Apache DolphinScheduler 应用概况
- Apache DolphinScheduler 改进
- Apache Spark 改进
DS 应用概况
01 为什么选择DS?
我们原来的调度平台用过很多个,无一例外都碰到一些难以满足自身需求的痛点问题:- Oozie :查看日志不便,缺少任务状态统计、工作流数量多了后存在调度压力等;
- Airflow : 需要用 python 代码来绘制 DAG,存在一定使用门槛;
- Crontab:就更原始了,而且是单点,使用不便。
- 能对工作流 DAG 可视化进行编辑,简单易用,日志查看也比较方便。
- 去中心化的多 master 多 worker 架构,可以线性扩展,从而保证了高可用。
- 支持的任务类型很丰富,契合大数据生态,方便定制和改造。
- 还支持补数,这个功能很实用。
02 DS 集群概况
DS 在我们生产环境运行有1年时间了,目前部署的情况是:1台 alert 服务,3台 api 服务,10 台 master 9台 worker,这些服务混合部署在10台物理机上。
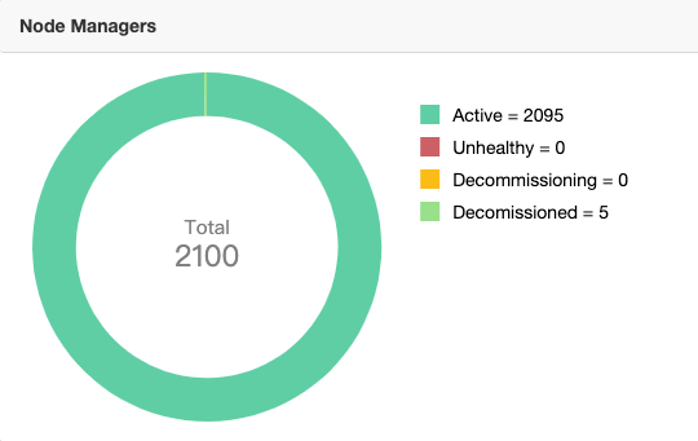
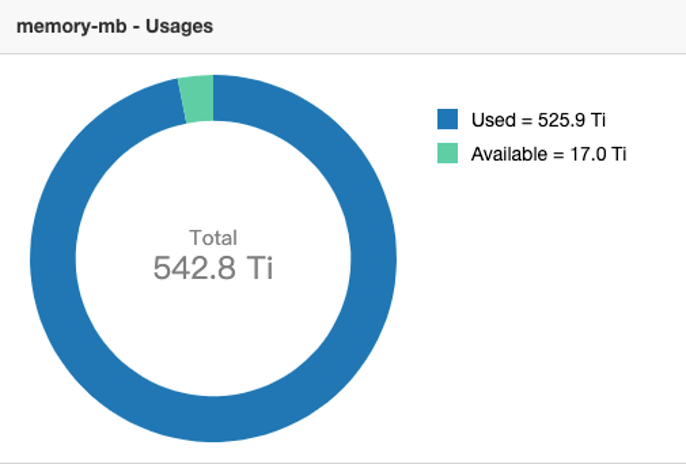
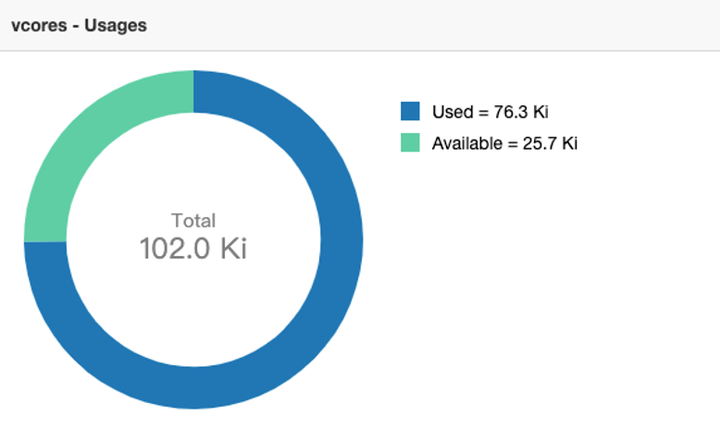
改造后的 DS 任务基本都是提交到 Yarn 上运行, Yarn 集群规模目前是有 2000 多台 node manager 节点,集群总共有 500 多 T内存、10多万 core。
改造后的 DS 任务基本都是提交到 Yarn 上运行, Yarn 集群规模目前是有 2000 多台 node manager 节点,集群总共有 500 多 T内存、10多万 core。
03 DS 作业概况
关于作业情况,目前已经完成了最主要的 Oozie 工作流迁移,现在日均调度 1.8W 多个工作流实例,5W 多个任务实例。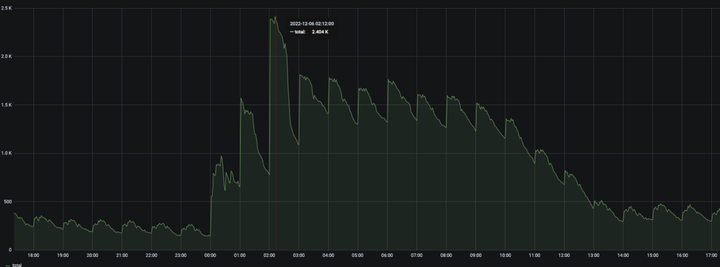
在夜里高峰时段同时有 2400 多个工作流实例运行,这些实例主要以 Spark、Sparksql、Shell、Python、Sqoop 节点为主。
在夜里高峰时段同时有 2400 多个工作流实例运行,这些实例主要以 Spark、Sparksql、Shell、Python、Sqoop 节点为主。
2 DophinScheduler 改进
01 用户体验提升
为了提升用户体验,我们围绕降低开发成本,简化任务配置做了很多改进。 打通 OA ,免去注册。方便用户登录。对于这种公司内部系统来说,还需要注册显然是不太方便的。 然后在 DAG 编辑页面完成开发、上线、树形图查看、运行、定时管理等一站式操作,尽量让用户在一个页面就能完成工作流的各个操作。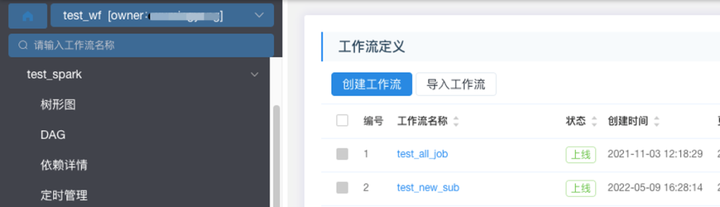
在树形图页面聚合了单个工作流定义的所有实例列表,这样可以更加清晰的看到属于当前工作流的实例。
首页提供定时调度概况。展示调度的实例成功与否的状态,这样用户对自己的定时调度最近运行的情况就可以一目了然,
增加页面分层级树形导航条,提供在项目、工作流、树形图页面快速切换等等。
因为用户是以项目为粒度组织工作流,一个用户可能会有多个项目,这个快速切换可以方便用户从一个项目下的工作流快速切到另一个项目下的工作流,提高用户的开发效率。关于工作流的体验改进我们还做了很多,因为篇幅有限,我就不展开来讲。如果您对此有兴趣,欢迎来社区跟我探讨。
在依赖选择方面,简化了依赖节点的配置。
原先配置一个依赖节点,是要先选择项目,再选择工作流,用户反馈使用起来不太方便,因此我们做了相关改进,在配置依赖节点的时候可以直接按工作流ID、工作流名称或工作流 owner 来搜索依赖工作流进行配置。
在树形图页面聚合了单个工作流定义的所有实例列表,这样可以更加清晰的看到属于当前工作流的实例。
首页提供定时调度概况。展示调度的实例成功与否的状态,这样用户对自己的定时调度最近运行的情况就可以一目了然,
增加页面分层级树形导航条,提供在项目、工作流、树形图页面快速切换等等。
因为用户是以项目为粒度组织工作流,一个用户可能会有多个项目,这个快速切换可以方便用户从一个项目下的工作流快速切到另一个项目下的工作流,提高用户的开发效率。关于工作流的体验改进我们还做了很多,因为篇幅有限,我就不展开来讲。如果您对此有兴趣,欢迎来社区跟我探讨。
在依赖选择方面,简化了依赖节点的配置。
原先配置一个依赖节点,是要先选择项目,再选择工作流,用户反馈使用起来不太方便,因此我们做了相关改进,在配置依赖节点的时候可以直接按工作流ID、工作流名称或工作流 owner 来搜索依赖工作流进行配置。
 搜索配图
我们还在首页的详情页面,提供了便捷查看上游依赖实例详情的入口,让用户一眼就能看到当前工作流实例的上游是哪个实例没有完成。
搜索配图
我们还在首页的详情页面,提供了便捷查看上游依赖实例详情的入口,让用户一眼就能看到当前工作流实例的上游是哪个实例没有完成。
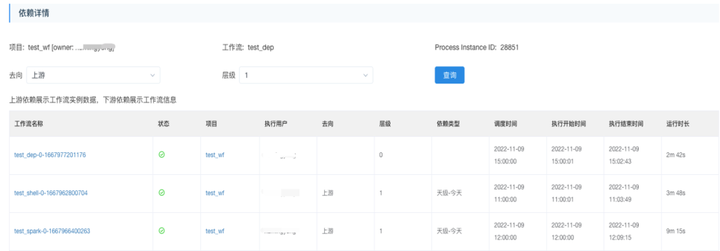
这样可以在出现任务延迟的时候方便排查是不是上游还没完成导致的。
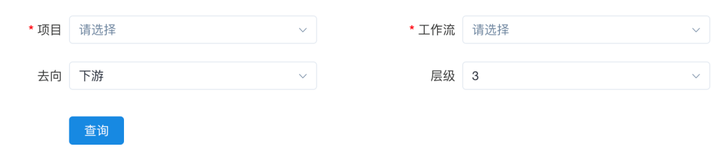
除此之外,还新增了一张表来记录工作流的上下游关系,在保存和更新工作流定义的时候去更新这个依赖表,然后提供了工作流依赖关系查看功能,以树形图的形式展示一个工作流的所有上游或是下游。
这样可以在出现任务延迟的时候方便排查是不是上游还没完成导致的。
除此之外,还新增了一张表来记录工作流的上下游关系,在保存和更新工作流定义的时候去更新这个依赖表,然后提供了工作流依赖关系查看功能,以树形图的形式展示一个工作流的所有上游或是下游。
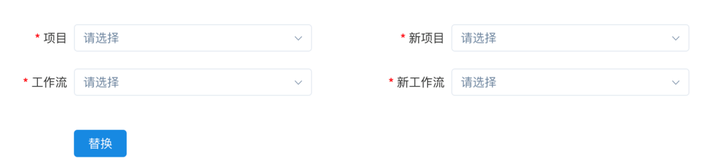
我们还支持了下游依赖的批量替换。比如,一个工作流可能有很多下游,这时因为业务需求可能希望用新的工作流替换原先这个工作流,就可以用这个功能同时把下游依赖也替换掉。
我们还支持了下游依赖的批量替换。比如,一个工作流可能有很多下游,这时因为业务需求可能希望用新的工作流替换原先这个工作流,就可以用这个功能同时把下游依赖也替换掉。
在补数方面,我们做了比较大的改进,其中最常见的业务场景,就是可以支持触发下游,用户在补数的时候可能会希望当前工作流补完了,带动下游工作流也一起补。
在补数方面,我们做了比较大的改进,其中最常见的业务场景,就是可以支持触发下游,用户在补数的时候可能会希望当前工作流补完了,带动下游工作流也一起补。

那这种情况下补数去触发下游,其实也是一个工作流实例的 DAG 了,因此我们不仅支持查看补数的进度,还可以知道当前补数是补到哪个工作流的哪个调度时间。
那这种情况下补数去触发下游,其实也是一个工作流实例的 DAG 了,因此我们不仅支持查看补数的进度,还可以知道当前补数是补到哪个工作流的哪个调度时间。

限制同一个调度时间的实例同时运行。这是因为如果一个下游有多个上游开始触发下游补数时,这个下游可能会补数补重,也就是同时有两个相同调度时间的补数实例在跑,当然用户如果误补数的话也有这种情况发生,所以我们做了限制来避免同时跑。
告警管理,我们把超时告警和失败告警整合到了定时调度配置页面来一起设置,并支持告警到值班组。因为我们实际需求是只需要对定时调度的实例去告警,其他手动运行或是补数的实例不需要告警,因此这两个超时和失败告警整合到定时调度配置页面,在配置调度的时候去配置告警。
限制同一个调度时间的实例同时运行。这是因为如果一个下游有多个上游开始触发下游补数时,这个下游可能会补数补重,也就是同时有两个相同调度时间的补数实例在跑,当然用户如果误补数的话也有这种情况发生,所以我们做了限制来避免同时跑。
告警管理,我们把超时告警和失败告警整合到了定时调度配置页面来一起设置,并支持告警到值班组。因为我们实际需求是只需要对定时调度的实例去告警,其他手动运行或是补数的实例不需要告警,因此这两个超时和失败告警整合到定时调度配置页面,在配置调度的时候去配置告警。
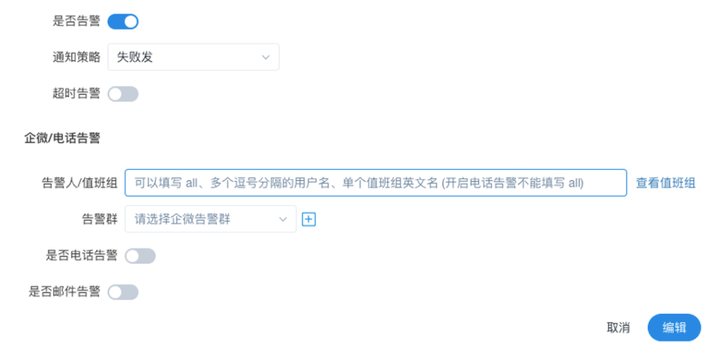
告警人可以填值班组,而不仅仅是用户,值班组里的成员每天都会排班。
超时和失败告警我们改成了用户如果没处理会每小时发一次告警,原先是发送一次就没了,这有可能会让用户遗漏,导致工作流没有得到及时处理。
如果用户不需要处理这个实例或者单纯想取消告警,我们也在实例上提供了取消告警的选择。用户也可以在工作流上屏蔽告警,并且可以同时屏蔽下游。在屏蔽时间范围内将不会发送告警。
最后还提供了工作流定时调度到期提醒功能。如果工作流即将到期,将会发送通知给用户,前端页面也会增加醒目的提示提醒用户工作流快过期了,要及时延期,避免影响工作流的正常调度。
告警人可以填值班组,而不仅仅是用户,值班组里的成员每天都会排班。
超时和失败告警我们改成了用户如果没处理会每小时发一次告警,原先是发送一次就没了,这有可能会让用户遗漏,导致工作流没有得到及时处理。
如果用户不需要处理这个实例或者单纯想取消告警,我们也在实例上提供了取消告警的选择。用户也可以在工作流上屏蔽告警,并且可以同时屏蔽下游。在屏蔽时间范围内将不会发送告警。
最后还提供了工作流定时调度到期提醒功能。如果工作流即将到期,将会发送通知给用户,前端页面也会增加醒目的提示提醒用户工作流快过期了,要及时延期,避免影响工作流的正常调度。
02 系统层面改进
Worker 支持任务无需重跑的 failover。以前 Worker 重启,Worker 上正在运行的任务需要 Kill 重新提交。 这就有几个问题:- 任务运行时间比较长,直接 kill 重跑代价大;
- 重跑比较浪费集群资源;
- 限制 worker 同时运行任务数量的上限;
- 在实例表增加一个字段,master/worker 容错时根据字段来来判断实例是否需要容错。
- 是在 master 端重试分发 task 时,优先分发到上一次分发的 worker。
- 提交到 yarn 的 task 设置 yarn tags,failover 后的 task 重新分发到 worker 后如果没有 app id 信息,则通过 yarn tags 检查 yarn 上该 task 是否已经提交或者在运行了。
- 增大工作流实例和任务实例状态轮询的间隔;
- 实例表增加索引,加快 sql 查询速度;
- 依赖节点查询上游实例状态时通过随机化分散查询,降低同时查询的并发数;
- 增加缓存,减少不必要的重复查询;
- 单个任务灰度可以添加 spark.yarn.archive 参数来指定 Spark 版本,但如果要批量灰度就不方便了;
- 我们也可以在 Worker 级别灰度,这样无法指定具体的工作流,也不好控制灰度规模。
3 Spark 改进
01 小文件合并
关于小文件合并,众所周知,小文件与 hdfs 是不友好的,太多的小文件会给 hdfs 带来严重的性能瓶颈。 而Spark作业并行度高的话又容易产生小文件,因此小文件合并对于 Spark 来说是十分有必要的。 小文件合并的实现方案有很多,比如可以在最后增加一个 shuffle 来控制文件数量。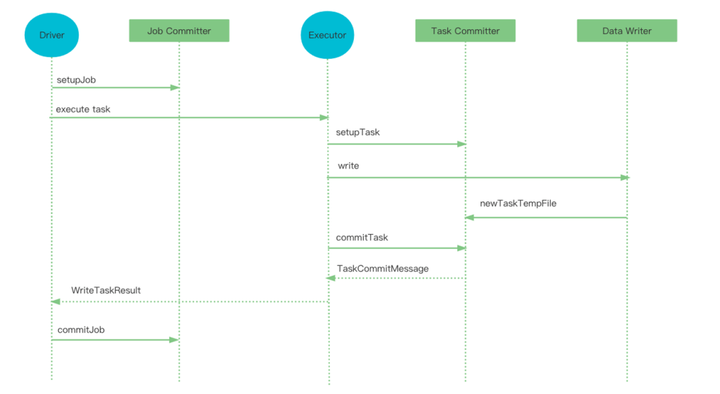
我们的方案是:在文件 commit 过程中去实现的。首先看 Spark 任务的文件提交机制,在 driver 端会先 setupJob,然后在 executor 端执行 task 的时候 setupTask,创建 task 临时目录,在 commitTask 的时候将数据文件从 task 临时目录转移到 job 临时目录。
最后 driver 端执行 commitJob 方法,将各个 task 任务提交的数据文件,从 Job 临时目录转移到 Job 的最终目标目录。
小文件合并方案是:在 driver 端 setup job 时,在 Job 最终目标目录下创建临时的 merge 目录,然后按照正常的流程将数据写到这个临时目录,在 driver commit job 之后,所有的数据文件都已经转移到了这个临时目录中。
此时去计算这个临时目录下每个分区路径下的数据文件的平均大小,如果只有一个文件或大于指定的阈值,就不需要合并,可以直接移动到最终目标目录。
如果小于指定阈值,则按照分区路径下文件大小之和除以阈值来计算合并后的文件数量,然后将分区路径下的文件读成 HadoopRDD 或 FileScanRDD,再按照计算的合并后文件数量进行 coalesce 操作,然后启动一个 Spark Job 将 RDD 数据写到最终目标目录中。
这个小文件合并方案在我们线上也应用了很长时间,虽然需要启动一个额外的 job,但仍然带来了较大的收益。比如,它大大减少了文件数量,减轻 NameNode 的负载压力。也降低了 Spark 作业 driver OOM 出现的概率,提高了数据读取效率,加快了执行速度。
我们的方案是:在文件 commit 过程中去实现的。首先看 Spark 任务的文件提交机制,在 driver 端会先 setupJob,然后在 executor 端执行 task 的时候 setupTask,创建 task 临时目录,在 commitTask 的时候将数据文件从 task 临时目录转移到 job 临时目录。
最后 driver 端执行 commitJob 方法,将各个 task 任务提交的数据文件,从 Job 临时目录转移到 Job 的最终目标目录。
小文件合并方案是:在 driver 端 setup job 时,在 Job 最终目标目录下创建临时的 merge 目录,然后按照正常的流程将数据写到这个临时目录,在 driver commit job 之后,所有的数据文件都已经转移到了这个临时目录中。
此时去计算这个临时目录下每个分区路径下的数据文件的平均大小,如果只有一个文件或大于指定的阈值,就不需要合并,可以直接移动到最终目标目录。
如果小于指定阈值,则按照分区路径下文件大小之和除以阈值来计算合并后的文件数量,然后将分区路径下的文件读成 HadoopRDD 或 FileScanRDD,再按照计算的合并后文件数量进行 coalesce 操作,然后启动一个 Spark Job 将 RDD 数据写到最终目标目录中。
这个小文件合并方案在我们线上也应用了很长时间,虽然需要启动一个额外的 job,但仍然带来了较大的收益。比如,它大大减少了文件数量,减轻 NameNode 的负载压力。也降低了 Spark 作业 driver OOM 出现的概率,提高了数据读取效率,加快了执行速度。
02 AQE优化
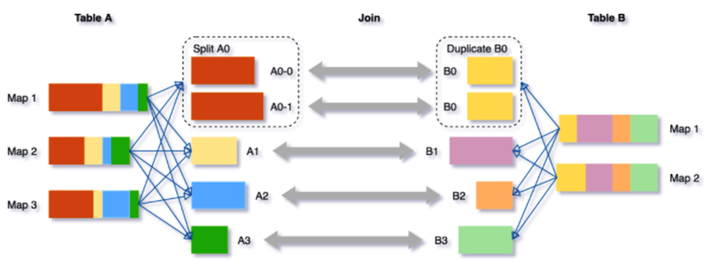
关于 AQE 的优化。AQE 是 Spark3 的重要功能,通过收集运行时的统计信息,来动态调整后续的执行计划。AQE 主要有三个优化场景:动态分区合并、动态调整 Join 策略以及动态优化倾斜 Join ,实现原理就不在这里赘述了。
AQE 的进一步优化。
第一点,分区合并可以让 reducer 处理的数据量适中,但如果物理计划中存在 expand 算子,会导致数据膨胀,即使 reducer 读取的数据量适中但经过数据膨胀之后,也会造成极大性能倒退,这种情况不适合进行分区合并或是需要调整分区合并的大小,针对这种情况,我们选择了针对这个 stage 不进行分区合并的操作。
关于 AQE 的优化。AQE 是 Spark3 的重要功能,通过收集运行时的统计信息,来动态调整后续的执行计划。AQE 主要有三个优化场景:动态分区合并、动态调整 Join 策略以及动态优化倾斜 Join ,实现原理就不在这里赘述了。
AQE 的进一步优化。
第一点,分区合并可以让 reducer 处理的数据量适中,但如果物理计划中存在 expand 算子,会导致数据膨胀,即使 reducer 读取的数据量适中但经过数据膨胀之后,也会造成极大性能倒退,这种情况不适合进行分区合并或是需要调整分区合并的大小,针对这种情况,我们选择了针对这个 stage 不进行分区合并的操作。



第二点,目前倾斜 Join 优化是根据分区数据量的大小来判断是否存在倾斜的,扩展倾斜 Join,可以支持收集分区的行数信息,这样既可以根据分区数据量大小,也可以根据分区的行数来判断一个分区是否倾斜。
第三点,我们利用收集到的行数信息,在合并分区时还会根据数据量大小和行数的比值来决定是否进行分区的合并。
AQE 的优化我们也上线了很长时间,可以说对大部分作业都缩短了运行时间,提高了执行效率。经过统计,开启 AQE 优化后,我们集群整体作业的平均运行时间缩短了 10%。
今天的分享就到这里,如果大家对我文章内容有任何问题,可以在社区里面来找我交流,感谢大家聆听和关注。
第二点,目前倾斜 Join 优化是根据分区数据量的大小来判断是否存在倾斜的,扩展倾斜 Join,可以支持收集分区的行数信息,这样既可以根据分区数据量大小,也可以根据分区的行数来判断一个分区是否倾斜。
第三点,我们利用收集到的行数信息,在合并分区时还会根据数据量大小和行数的比值来决定是否进行分区的合并。
AQE 的优化我们也上线了很长时间,可以说对大部分作业都缩短了运行时间,提高了执行效率。经过统计,开启 AQE 优化后,我们集群整体作业的平均运行时间缩短了 10%。
今天的分享就到这里,如果大家对我文章内容有任何问题,可以在社区里面来找我交流,感谢大家聆听和关注。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。 参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手 Leonard-ds ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手时请说明想参与贡献,来吧,开源社区非常期待您的参与。
标签:调度,工作,任务,实例,灰度,BIGO,Spark,2.4
From: https://www.cnblogs.com/DolphinScheduler/p/17102731.html
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手 Leonard-ds ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手时请说明想参与贡献,来吧,开源社区非常期待您的参与。
标签:调度,工作,任务,实例,灰度,BIGO,Spark,2.4
From: https://www.cnblogs.com/DolphinScheduler/p/17102731.html