Mybatis Plus 新增数据并返回主键 ID(图文讲解)
更新时间 2023-01-10 15:37:37大家好,我是小哈。
本小节中,我们将学习如何通过 Mybatis Plus 框架给数据库表新增数据,主要内容思维导图如下:

表结构
为了演示新增数据,在前面小节中,我们已经定义好了一个用于测试的用户表, 执行脚本如下:
DROP TABLE IF EXISTS t_user;
CREATE TABLE `t_user` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(30) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NULL DEFAULT NULL COMMENT '年龄',
`gender` tinyint(2) NOT NULL DEFAULT 0 COMMENT '性别,0:女 1:男',
PRIMARY KEY (`id`)
) COMMENT = '用户表';
定义实体类
定义一个名为 User 实体类:
@Data
@TableName("t_user")
public class User {
/**
* 主键 ID, @TableId 注解定义字段为表的主键,type 表示主键类型,IdType.AUTO 表示随着数据库 ID 自增
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private Integer gender;
}
讲解一下实体类中用到的注解:
@TableName 表名注解
作用:标识实体类对应的表。
TIP :
- 当实体类名称和实际表名一致时,如实体名为
User, 表名为user,可不用添加该注解,Mybatis Plus 会自动识别并映射到该表。- 当实体类名称和实际表名不一致时,如实体名为
User, 表名为t_user,需手动添加该注解,并填写实际表名称。
@TableId 主键注解
作用:声明实体类中的主键对应的字段。
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 主键字段名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
IdType 主键类型
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(默认) |
| INPUT | 插入数据前,需自行设置主键的值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID (默认 default 方法) |
分布式全局唯一 ID 长整型类型 (推荐使用 ASSIGN_ID) |
|
32 位 UUID 字符串 (推荐使用 ASSIGN_UUID) |
|
分布式全局唯一 ID 字符串类型 (推荐使用 ASSIGN_ID) |
开始新增数据
测试表准备好后,我们准备开始演示新增数据。实际上,Mybatis Plus 对 Mapper 层和 Service 层都将常见的增删改查操作都封装好了,只需简单的继承,即可轻松搞定对数据的增删改查,本文重点讲解新增数据这块。
Mapper 层
定义一个 UserMapper , 让其继承 BaseMapper :
public interface UserMapper extends BaseMapper<User> {
}
然后,注入 Mapper :
@Autowired
private UserMapper userMapper;
BaseMapper 提供的新增方法仅一个 insert() 方法:
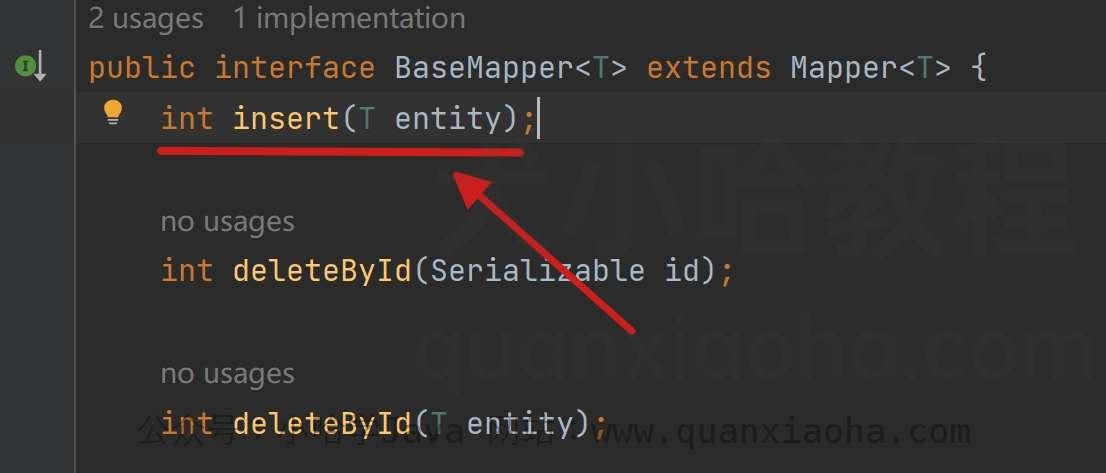
我们通过它测试一下添加数据,并获取主键 ID :
User user = new User();
user.setName("犬小哈");
user.setAge(30);
user.setGender(1);
userMapper.insert(user);
// 获取插入数据的主键 ID
Long id = user.getId();
System.out.println("id:" + id);
怎么样,是不是非常简单呢!
Service 层
Mybatis Plus 同样也封装了通用的 Service 层 CRUD 操作,并且提供了更丰富的方法。接下来,我们上手看 Service 层的代码结构,如下图:

先定义 UserService 接口 ,让其继承自 IService:
public interface UserService extends IService<User> {
}
再定义实现类 UserServiceImpl,让其继承自 ServiceImpl, 同时实现 UserService 接口,这样就可以让 UserService 拥有了基础通用的 CRUD 功能,当然,实际开发中,业务会更加复杂,就需要向 IService 接口自定义方法并实现:
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}
注入 UserService :
@Autowired
private UserService userService;
与 Mapper 层不同的是,Service 层的新增方法均以 save 开头,并且功能更丰富,来看看都提供了哪些方法:

简单解释下每个方法的作用,以作了解:
// 新增数据
sava(T) : boolean
// 伪批量插入,实际上是通过 for 循环一条一条的插入
savaBatch(Collection<T>) : boolean
// 伪批量插入,int 表示批量提交数,默认为 1000
savaBatch(Collection<T>, int) : boolean
// 新增或更新(单条数据)
saveOrUpdate(T) : boolean
// 批量新增或更新
saveOrUpdateBatch(Collection<T>) : boolean
// 批量新增或更新(可指定批量提交数)
saveOrUpdateBatch(Collection<T>, int) : boolean
大致看完后,上手测试一下。
sava(T)
简单的新增数据,示例代码如下:
// 新增数据
// 实际执行 SQL : INSERT INTO user ( name, age, gender ) VALUES ( '小哈 111', 30, 1 )
User user = new User();
user.setName("小哈 111");
user.setAge(30);
user.setGender(1);
boolean isSuccess = userService.save(user);
// 返回主键ID
Long id = user.getId();
System.out.println("isSuccess:" + isSuccess);
System.out.println("主键 ID: " + id);
savaBatch(Collection)
伪批量插入,注意,命名虽然包含了批量的意思,但这不是真的批量插入,不信的话,我们来实际测试一下:
// 批量插入
List<User> users = new ArrayList<>();
for (int i = 0; i < 5; i++) {
User user = new User();
user.setName("犬小哈" + i);
user.setAge(i);
user.setGender(1);
users.add(user);
}
boolean isSuccess = userService.saveBatch(users);
System.out.println("isSuccess:" + isSuccess);
执行代码,实际执行的 SQL 如下:
TIP : 如何打印实际执行的 SQL, 可参考之前小节的 《Mybatis Plus 打印 SQL 语句(包含执行耗时)》 。

可以看到,并不是 insert into user (xxx) values (xxx),(xxx),(xxx) 这种批量形式,还是一条一条插入的。
批量新增源码分析
我们来看下源码, 内部的saveBatch() 方法默认的批量提交阀值参数,数值为 1000, 即达到 1000 条批量提交一次,继续点进去看::


public boolean saveBatch(Collection<T> entityList, int batchSize) {
// 获取预编译的插入 SQL
String sqlStatement = this.getSqlStatement(SqlMethod.INSERT_ONE);
// for 循环执行 insert
return this.executeBatch(entityList, batchSize, (sqlSession, entity) -> {
sqlSession.insert(sqlStatement, entity);
});
}
再看下 SqlMethod.INSERT_ONE 这个枚举,描述信息为插入一条数据:

继续往 executeBatch() 方法里看,瞅瞅它这个批量到底是怎么处理的,具体每行代码的意思,小哈都加了注释:
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
// 断言需要批处理数据集大小不等于1
Assert.isFalse(batchSize < 1, "batchSize must not be less than one", new Object[0]);
// 判空数据集,若不为空,则开始执行批量处理
return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, (sqlSession) -> {
int size = list.size();
// 将批处理大小与传入的操作集合大小进行比较,取最小的那个
int idxLimit = Math.min(batchSize, size);
int i = 1;
// 迭代器循环
for(Iterator var7 = list.iterator(); var7.hasNext(); ++i) {
// 获取当前需要执行的数据库操作
E element = var7.next();
// 回调 sqlSession.insert() 方法
consumer.accept(sqlSession, element);
// 判断是否达到需要批处理的阀值
if (i == idxLimit) {
// 开始批处理,此方法执行并清除缓存在 JDBC 驱动类中的执行语句
sqlSession.flushStatements();
idxLimit = Math.min(idxLimit + batchSize, size);
}
}
});
}
看完就明白了,相比较自己手动 for 循环执行插入,Mybatis Plus 这个伪批量插入性能会更好些,内部会将每次的插入语句缓存起来,等到达到 1000 条的时候,才会统一推给数据库,虽然最终在数据库那边还是一条一条的执行 INSERT,但还是在和数据库交互的 IO 上做了优化。
savaBatch(Collection, int)
多了个 batchSize 参数,可以手动指定批处理的大小,即多少 SQL 操作执行一次,默认为 1000。
saveOrUpdate(T)
保存或者更新。即当你需要执行的数据,数据库中不存在时,就执行插入操作:
// 实际执行 SQL : INSERT INTO user ( name, age, gender ) VALUES ( '小小哈', 60, 1 )
User user = new User();
user.setName("小小哈");
user.setAge(60);
user.setGender(1);
userService.saveOrUpdate(user);
当你需要执行的数据,数据库中已存在时,就执行更新操作。框架是如何判断该记录是否存在呢? 如设置了主键 ID,因为主键 ID 必须是唯一的,Mybatis Plus 会先执行查询操作,判断数据是否存在,存在即执行更新,否则,执行插入操作:
User user = new User();
// 设置了主键字段
user.setId(21L);
user.setName("小小哈");
user.setAge(60);
user.setGender(1);
userService.saveOrUpdate(user);
具体执行 SQL 如下:

saveOrUpdateBatch(Collection)
批量保存或者更新,示例代码如下:
List<User> users = new ArrayList<>();
for (int i = 0; i < 5; i++) {
User user = new User();
user.setId(Long.valueOf(i));
user.setName("犬小哈" + i);
user.setAge(i+1);
user.setGender(1);
users.add(user);
}
userService.saveOrUpdateBatch(users);
saveOrUpdateBatch(Collection, int)
批量保存或者更新(可手动指定批量大小),示例代码如下:
List<User> users = new ArrayList<>();
for (int i = 0; i < 5; i++) {
User user = new User();
user.setId(Long.valueOf(i));
user.setName("犬小哈" + i);
user.setAge(i+1);
user.setGender(1);
users.add(user);
}
userService.saveOrUpdateBatch(users, 100);