首先说说,为什么要写这篇文章:
- Quartz 的
v2.3.2版本改动比较大,目前网上的资料都是旧版本,很缺乏相关资料 - 很多资料讲解非常不全面,例如 Quartz Listener 的介绍和使用基本缺失
- Springboot 整合 Quartz 是目前普遍的使用场景,但是 Quartz 官方没有相关资料
- 网上很少关于基于 Springboot 整合的 Quartz 搭建集群环境,而且大多无法运行
为了避免让大家重复踩坑,综上所述就是我要写本篇文章的目的了
本文档编写时间 23.1.17,基于目前最新的稳定版 quartz 2.3.2 实现
概述
简单介绍:
Quartz 是目前 Java 领域应用最为广泛的任务调度框架之一,目前很多流行的分布式调度框架,例如 xxl-job 都是基于它衍生出来的,所以了解和掌握 Quartz 的使用,对于平时完成一些需要定时调度的工作会更有帮助
快速开始
我们通过一个最简单的示例,先快速上手 Quartz 最基本的用法,然后再逐步讲解 Quartz 每个模块的功能点
第一步:添加依赖
在 pom.xml 文件添加 Quart 依赖:
<!-- 引入 quartz 基础依赖:可取当前最新版本 -->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.2</version>
</dependency>
<!-- 引入 quartz 所需的日志依赖:可取当前最新版本 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.26</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.26</version>
<scope>compile</scope>
</dependency>
第二步:配置文件
在项目的 classpath 路径下创建 Quartz 默认的 quartz.properties 配置文件,它看起来像这样:
# 调度程序的名称
org.quartz.scheduler.instanceName = MyScheduler
# 线程数量
org.quartz.threadPool.threadCount = 3
# 内存数据库(推荐刚上手时使用)
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
第三步:定义任务类
实现 Job 接口,然后在覆盖的 execute 函数内定义任务逻辑,如下:
package org.example.quartz.tutorial;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext context) {
System.out.println("hello quartz!");
}
}
第四步:任务调度
我们简单的使用 main() 方法即可运行 Quartz 任务调度示例:
package org.example.quartz.tutorial;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SimpleScheduleBuilder;
import org.quartz.SimpleTrigger;
import org.quartz.TriggerBuilder;
import org.quartz.impl.StdSchedulerFactory;
public class QuartzTest {
public static void main(String[] args) {
try {
// 获取默认的调度器实例
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 打开调度器
scheduler.start();
// 定义一个简单的任务
JobDetail job = JobBuilder.newJob(HelloJob.class)
.withIdentity("job11", "group1")
.build();
// 定义一个简单的触发器: 每隔 1 秒执行 1 次,任务永不停止
SimpleTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "group1")
.startNow()
.withSchedule(SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(1)
.repeatForever()
).build();
// 开始调度任务
scheduler.scheduleJob(job, trigger);
// 等待任务执行一些时间
Thread.sleep(3000);
// 关闭调度器
scheduler.shutdown();
} catch (Exception se) {
se.printStackTrace();
}
}
}
最后控制台会输出任务运行的全过程,然后关闭进程,如下:
[main] INFO org.quartz.impl.StdSchedulerFactory - Using default implementation for ThreadExecutor
[main] INFO org.quartz.core.SchedulerSignalerImpl - Initialized Scheduler Signaller of type: class org.quartz.core.SchedulerSignalerImpl
[main] INFO org.quartz.core.QuartzScheduler - Quartz Scheduler v.2.3.2 created.
[main] INFO org.quartz.simpl.RAMJobStore - RAMJobStore initialized.
[main] INFO org.quartz.core.QuartzScheduler - Scheduler meta-data: Quartz Scheduler (v2.3.2) 'MyScheduler' with instanceId 'NON_CLUSTERED'
Scheduler class: 'org.quartz.core.QuartzScheduler' - running locally.
NOT STARTED.
Currently in standby mode.
Number of jobs executed: 0
Using thread pool 'org.quartz.simpl.SimpleThreadPool' - with 3 threads.
Using job-store 'org.quartz.simpl.RAMJobStore' - which does not support persistence. and is not clustered.
[main] INFO org.quartz.impl.StdSchedulerFactory - Quartz scheduler 'MyScheduler' initialized from default resource file in Quartz package: 'quartz.properties'
[main] INFO org.quartz.impl.StdSchedulerFactory - Quartz scheduler version: 2.3.2
[main] INFO org.quartz.core.QuartzScheduler - Scheduler MyScheduler_$_NON_CLUSTERED started.
hello quartz!
hello quartz!
hello quartz!
hello quartz!
[main] INFO org.quartz.core.QuartzScheduler - Scheduler MyScheduler_$_NON_CLUSTERED shutting down.
[main] INFO org.quartz.core.QuartzScheduler - Scheduler MyScheduler_$_NON_CLUSTERED paused.
[main] INFO org.quartz.core.QuartzScheduler - Scheduler MyScheduler_$_NON_CLUSTERED shutdown complete.
Process finished with exit code 0
可以看到,到这里一个最基本简单的 Quartz 使用示例基本就 OK 了,接下来介绍更多核心概念和深入使用的场景
核心概念
触发器和作业
基本概念
掌握 Quartz 之前,先来了解它框架的 3 个核心组件和概念,如下:
- Schduler:调度器,主要用于管理作业(JobDetail),触发器(Trigger)
- JobDetail:作业实例,内部包含作业运行的具体逻辑
- Trigger:触发器实例,内部包含作业执行的实践计划
工作流程
如上所示,使用 Quartz 的工作流程也很简单,大致如下:
- 首页基于
Job接口定义你的作业JobDetail实例和触发器Trigger实例对象 - 将定义的作业和触发器实例对象通过调度器
scheduleJob,开始调度执行 - 调度器启动工作线程开始执行
JobDetail实例的execute方法内容 - 任务运行时所需信息通过,
JobExecutionContext对象传递到工作线程,也可以在多个工作线程中跨线程传递
示意图:
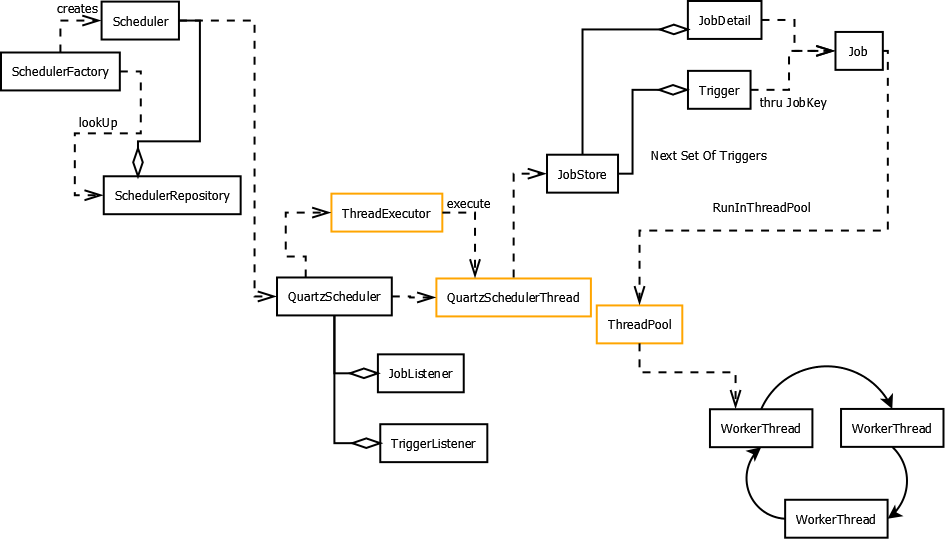
唯一标识
关于创建 JobDetail 作业实例和 Trigger 触发器的几个注意事项:
- 创建作业和触发器都需要通过(JobKey 和 TriggerKey + Group)组合创建唯一标识
- 你可以通过唯一标识在 Schduler 中获取作业对象,并且管理和维护他们
- 引入 Group 标识的目的也是了更好的让你管理作业环境:例如:通过不同的 Group 来区分:【测试作业,生产作业】等
JobDetail 的更多细节
通过示例可以看到,定义和使用 Job 都非常简单,但是如果要深入使用,你可能需要了解关于 Job 的更多细节
先看看 Quartz 对于 JobDetail 的处理策略:
- 每次执行任务都会创建一个新的 JobDetail 实例对象,意味每次执行的 JobDetail 都是新对象,JobDetail 对象也是无状态的
- JobDetail 实例对象任务完成后 (execute 方法),调度器 Schduler 会将作业实例对象删除,然后进行垃圾回收
- JobDetail 实例之间的状态数据,只能通过
JobExecutionContext(实际上是 JobDataMap) 进行跨作业传递
JobDataMap
jobDataMap 的使用主要分 2 步:
1:在 execute() 函数内,使用 jobDataMap 获取数据
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext context) {
// 通过 JobDataMap 对象,可以在作业的执行逻辑中,获取参数
JobDataMap jobDataMap = context.getJobDetail().getJobDataMap();
String name = jobDataMap.getString("name");
System.out.println("hello " + name);
}
}
2:jobDataMao 添加参数
// 定义作业时,通过 usingJobData 将参数放入 JobDataMap
JobDetail job = JobBuilder.newJob(HelloJob.class)
.withIdentity("job11", "group1")
.usingJobData("name", "phoenix")
.build();
最后运行效果如下:
[main] INFO org.quartz.core.QuartzScheduler - Scheduler MyScheduler_$_NON_CLUSTERED started.
hello phoenix
[main] INFO org.quartz.core.QuartzScheduler - Scheduler MyScheduler_$_NON_CLUSTERED shutting down.
# ....
关于 JobDataMap 的使用,需要关注以下的注意事项:
- 虽然 JobDataMap 可以传递任意类型的数据,对象的反序列化在版本迭代中容易遇到类版本控制的问题
- 如果从长远的安全性考虑,尽可能的将 jobDataMap 设置为只允许存放基本类型和字符串(通过
jobStore.useProperties设置) - Quartz 会自动通过 Job 类的 setter 方法和 JobDataMap 主键匹配,帮助你自动注入属性到 Job 类中
并发性和持久化
Quartz 对于 Job 提供几个注释,合理的使用可以更好的控制 Quartz 的调度行为,具体如下:
-
@DisallowConcurrentExecution:添加到 Job 类中,告诉 Job 防止相同定义的任务并发执行,例如:任务 A 实例未完成任务,则任务 B 实例不会开始执行(Quartz 默认策略是不会等待,启用新线程并发调度)
-
@PersistJobDataAfterExecution:添加到 Job 类中,默认情况下 Job 作业运行逻辑不会影响到 JobDataMap (既每个 JobDetail 拿到的都是初始化的 JobDataMap 内容),开启该注解后,Job 的
execute()方法完成后,对于 JobDataMap 的更新,将会被持久化到 JobDataMap 中,从而供其他的 JobDetail 使用,这对于任务 B 依赖任务 A 的运行结果的场景下,非常有用,所以强烈建议和@DisallowConcurrentExecution注解一起使用,会让任务运行结果更加符合预期
使用示例如下:
@DisallowConcurrentExecution
@PersistJobDataAfterExecution
public class QuartzTest {
public static void main(String[] args) {
//.....
}
}
Trigger 的更多细节
和 Job 类似,触发器的定义和使用也非常简单,但是如果想充分的利用它来工作,你还需要了解关于触发器的更多细节
在 Quartz 中 Trigger 触发器有很多种类型,但是他们都有几个共同的属性,如下:
- startTime:触发器首次生效的时间
- endTime:触发器失效时间
以上共同属性的值都是 java.util.Date 对象
关于 Trigger 的其他几个概念:
- Priority 优先权:当调度器遇到多个同时执行的 Trigger 时候,会根据优先权大小排序,然后先后调度
- Misfire 错过触发:Trigger 达到触发时间,但因为外部原因无法执行,Trigger 开始计算 Misfire 时间
- 常见的外部原因有哪些?例如:调度程序被关闭,线程池无可用工作线程等
- Calendar 日历(不是 java.util.calendar 对象):用于排除执行日期非常有用
- 例如:定义一个每天 9 点执行 Trigger ,但是排除所有法定节假日
SimpleTrigger
SimpleTrigger 是适用于大多数场景的触发器,它可以指定特定时间,重复间隔,重复次数等简单场景,它主要设定参数如下:
- 开始时间
- 结束时间
- 重复次数
- 间隔时间
具体的 API 可以参考 Quartz 的 Java Doc 文档,这里就不赘述了
misfire 处理策略:
我们上面说过 Quartz Misfire 的概念,从源码 SimpleScheduleBuilder 类中可以看到 MISFIRE_INSTRUCTION_SMART_POLICY 是默认的触发策略,但是也我们也可以在创建 Trigger 时候设置我们期望的错过触发策略,如下:
SimpleTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "group1")
.withSchedule(SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(1)
.repeatForever()
// misfireInstruction = SimpleTrigger.MISFIRE_INSTRUCTION_FIRE_NOW;
.withMisfireHandlingInstructionFireNow()
).build();
在 SimpleTrigger 类中的常量可以看到所有错过触发(misfire)处理逻辑:
MISFIRE_INSTRUCTION_FIRE_NOW
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT
关于 misfire 的具体的行为,可以查阅 Quartz 的 Java Doc 文档
CronTrigger
相比 SimpleTrigger 可以指定更为复杂的执行计划,CRON 是来自 UNIX 基于时间的任务管理系统,相关内容就不再展开,可以参阅 Cron - (wikipedia.org) 文档进一步了解,
Cron 也有类似 SimpleTrigger 的相同属性,设置效果如下:
- startTime:触发器首次生效的时间
- endTime:触发器失效时间
看看 CronTrigger 的使用示例:
CronTrigger cronTrigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "group1")
.withSchedule(CronScheduleBuilder
.cronSchedule("0 0/2 8-17 * * ?")
.withMisfireHandlingInstructionFireAndProceed()
)
.build();
scheduler.scheduleJob(job, cronTrigger);
上述代码完成以下几件事情:
- 创建 Cron 表达式:每天上午 8 点到下午 5 点之间每隔一分钟触发一次
- 指定 MISFIRE_INSTRUCTION_FIRE_NOW 为 CronTrigger 的处理策略
- 通过 Schduler 对任务开始进行调度
CronTrigger Misfire 策略定义在 CronTrigger 常量中,可以在 Java Doc 文档中查看其具体的行为
Linstener 监听器
监听器用于监听 Quartz 任务事件执行对应的操作,大致分类如下:
- JobListener:用于监听 JobDetail 相关事件
- TriggerListener:用于监听 Trigger 相关事件
- SchdulerListener:用于监听 Schduler 相关事件
在常见的 JobListener 接口中,提供以下事件监听:
public interface JobListener {
public String getName();
// 作业即将开始执行时触发
public void jobToBeExecuted(JobExecutionContext context);
// 作业即将取消时通知
public void jobExecutionVetoed(JobExecutionContext context);
// 作业执行完成后通知
public void jobWasExecuted(JobExecutionContext context, JobExecutionException jobException);
}
想要实现监听,需要以下几步:
- 自定义监听类,实现 *Listener 监听接口
- 在你感兴趣的事件,加入你的逻辑代码
- 将自定义监听类,在任务调度前,注册到 Schduler 中即可
在 Schduler 中注册一个对所有任务生效的 Listener 的示例:
scheduler.getListenerManager().addJobListener(myJobListener, allJobs());
关于使用 Listener 的建议:
- 在最新的
2.3.2Listener 不会存储在 JobStore 中,所以在持久化模式下,每次启动都需要重新注册监听 - 大多数场景下 Quartz 用户不会使用 Listener,除非非常必要的情况才使用
JobStore 作业存储
JobStore 属性在 Quartz 配置文件中声明,用于定义 Quartz 所有运行时任务的存储方式,目前主要有两种方式
RAMJobStore
RAMJobStore 是基于内存的存储模式,其特点如下:
- 优点:使用,配置简单,性能最高
- 缺点:程序关闭后,任务信息会丢失
配置方式如下:
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
JDBCJobStore
JDBCJobStore 是基于数据的存储模式,其特点如下:
- 优点:支持常见的数据库,可以持久化保存任务信息
- 缺点:配置繁琐,性能不高(取决于数据库)
使用示例
使用 JDBCJobStore 需要以下 3 步完成:
第一步:在项目中添加相关数据库依赖:
<!-- 添加数据库依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
第二步:在数据库执行 [Quartz 官方的 SQL DDL 脚本](quartz/tables_mysql_innodb.sql at master · quartz-scheduler/quartz (github.com)),创建数据库表结构,Quartz 核心的表结构如下:
| Table Name | Description |
|---|---|
| QRTZ_CALENDARS | 存储Quartz的Calendar信息 |
| QRTZ_CRON_TRIGGERS | 存储CronTrigger,包括Cron表达式和时区信息 |
| QRTZ_FIRED_TRIGGERS | 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存储已暂停的Trigger组的信息 |
| QRTZ_SCHEDULER_STATE | 存储少量的有关Scheduler的状态信息,和别的Scheduler实例 |
| QRTZ_LOCKS | 存储程序的悲观锁的信息 |
| QRTZ_JOB_DETAILS | 存储每一个已配置的Job的详细信息 |
| QRTZ_JOB_LISTENERS | 存储有关已配置的JobListener的信息 |
| QRTZ_SIMPLE_TRIGGERS | 存储简单的Trigger,包括重复次数、间隔、以及已触的次数 |
| QRTZ_BLOG_TRIGGERS | Trigger作为Blob类型存储 |
| QRTZ_TRIGGERS | 存储已配置的Trigger的信息 |
第三步:配置文件修改为 JDBCJobStore 模式,配置数据源,并且将 jobStore 指定为该数据源,如下
# quartz scheduler config
org.quartz.scheduler.instanceName = MyScheduler
org.quartz.threadPool.threadCount = 3
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.tablePrefix = QRTZ_
org.quartz.jobStore.dataSource = myDS
# dataSource
org.quartz.dataSource.myDS.driver = com.mysql.cj.jdbc.Driver
org.quartz.dataSource.myDS.URL = jdbc:mysql://127.0.0.1:3306/quartz_demo
org.quartz.dataSource.myDS.user = root
org.quartz.dataSource.myDS.password = test123456
org.quartz.dataSource.myDS.maxConnections = 30
最后运行 QuartzTest 后可以看到数据库 QRTZ_JOB_DETAILS 表已经添加数据,如下:

注意事项
在使用 JDBCJobStore 时,需要注意以下事项:
- Quartz 的 JobStoreTX 默认是独立示例,如果需要和其他事务一起工作(例如 J2EE 服务器),可以选择
JobStoreCMT - 默认表前缀是
QRTZ_,可进行配置,使用多个不同的前缀有助于实现同一数据库的任务调度多组表结构 - JDBC 委托驱动
StdJDBCDelegate适用于大多数数据库,目前只针对测试StdJDBCDelegate时出现问题的类型进行特定的委托- DB2v6Delegate:适用于 DB2 版本 6 及更早版本
- HSQLDBDelegate:适用于 HSQLDB 数据库
- MSSQLDelegate:适用于 Microsoft SQLServer 数据库
- PostgreSQLDelegate:适用于 PostgreSQL 数据库
- WeblogicDelegate:由 Weblogic 制作的驱动程序
- OracleDelegate:适用于 Oracle 数据库
- …………
- 将
org.quartz.jobStore.useProperties设置为 True,避免将非基础类型数据存储到数据库的 BLOB 字段
springboot 集成
Quartz 整合 Springboot 非常普遍的场景,整合 Spring 可以带来好处:
- 更加简洁的配置,开箱即用
- 和 Spring 的 IOC 容器融合,使用更便捷
添加依赖
可以在现有项目上添加 springboot 官方提供的 starter-quartz 依赖,如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
如果是新项目,可以直接在 Spring Initializr 添加 Quartz Schduler 如下:
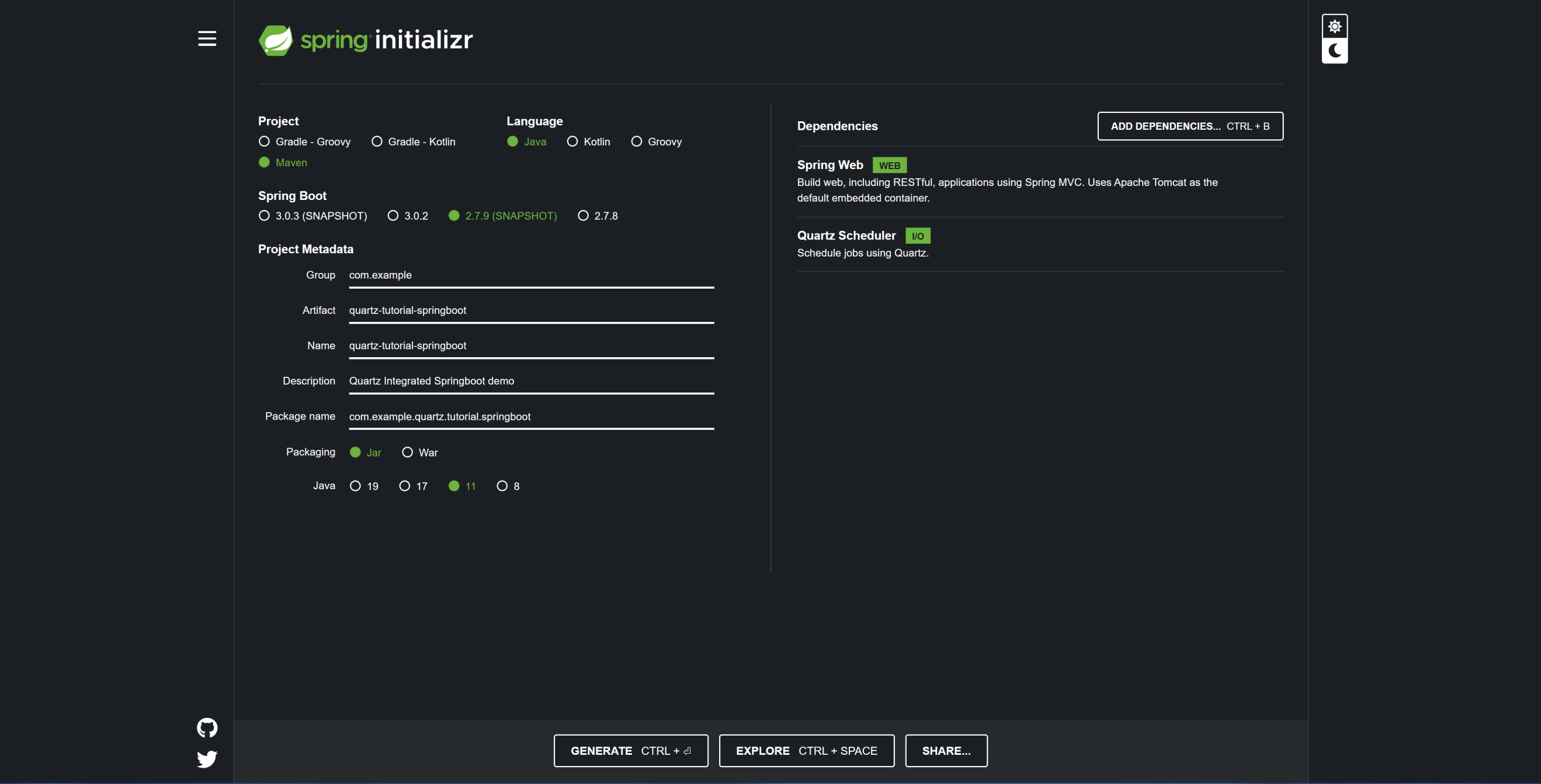
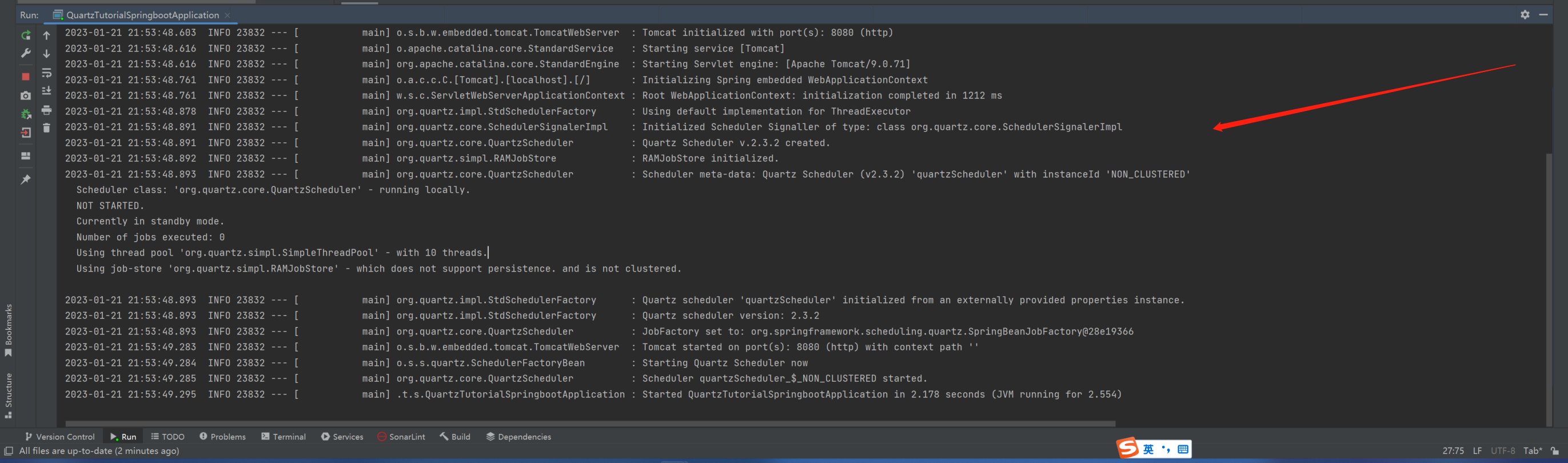
启动 Springboot 会发现,无需任何配置就已经整合 Quartz 模块了:
使用示例
现在基于整合模式实现刚才的 Demo 示例,首先定义任务,这里不再是实现 Job 类:
public class HelloJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
JobDataMap jobDataMap = context.getJobDetail().getJobDataMap();
String name = jobDataMap.getString("name");
System.out.println("Hello :" + name);
}
}
这里实现由 Springboot 提供的 QuartzJobBean,实现 executerInternal() 方法,这是一个经过 Spring 容器包装后的任务类,可以在任务类使用 Spring 容器的实例
在 Demo 示例里面,我们调度启动都是在 Main 方法启动,在本地测试没有问题,但在生产环境就不建议了,和 springboot 整合后关于任务执行,现在可以有 2 中选项:
- 在控制层 Controller 提供接口,手动接收任务指定
- 监听 Spring 容器,在容器启动后,自动加载任务,并且注册为 Bean
手动执行
我们先看看第一种实现方式,我们创建控制器,然后接收参数,创建任务,如下:
@RestController
public class HelloController {
@Autowired
private Scheduler scheduler;
@GetMapping("/hello")
public void helloJob(String name) throws SchedulerException {
// 定义一个的任务
JobDetail job = JobBuilder.newJob(HelloJob.class)
.withIdentity("job11", "group1")
.usingJobData("name", name)
.build();
// 定义一个简单的触发器: 每隔 1 秒执行 1 次,任务永不停止
SimpleTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "group1")
.withSchedule(SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(1)
.repeatForever()
).build();
// 开始调度
scheduler.scheduleJob(job, trigger);
}
}
然后启动服务器,访问接口传入参数:
$curl --location --request GET 'http://localhost:8080/hello?name=phoenix'
然后控制台会输出:
2023-01-21 22:03:03.213 INFO 23832 --- [nio-8080-exec-2] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'
2023-01-21 22:03:03.213 INFO 23832 --- [nio-8080-exec-2] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2023-01-21 22:03:03.214 INFO 23832 --- [nio-8080-exec-2] o.s.web.servlet.DispatcherServlet : Completed initialization in 1 ms
Hello :phoenix
Hello :phoenix
#....
自动执行
将 JobDetail 注册 Bean,任务就会随 Spring 启动自动触发执行,这对于需要随程序启动执行的作业非常有效,配置如下:
先创建一个配置类:
@Configuration
public class QuartzConfig {
@Bean
public JobDetail jobDetail() {
JobDetail job = JobBuilder.newJob(HelloJob.class)
.withIdentity("job11", "group1")
.usingJobData("name", "springboot")
.storeDurably()
.build();
return job;
}
@Bean
public Trigger trigger() {
SimpleTrigger trigger = TriggerBuilder.newTrigger()
.forJob(jobDetail())
.withIdentity("trigger1", "group1")
.withSchedule(SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(1)
.repeatForever()
).build();
return trigger;
}
}
然后在 springboot 启动后,任务就自动执行:
2023-01-21 22:29:51.962 INFO 46376 --- [ main] org.quartz.core.QuartzScheduler : Scheduler quartzScheduler_$_NON_CLUSTERED started.
Hello :springboot
Hello :springboot
Hello :springboot
# ....
集群模式
对于生产环境来说,高可用,负载均衡,故障恢复,这些分布式的能力是必不可少的,Quartz 天生支持基于数据库的分布式:
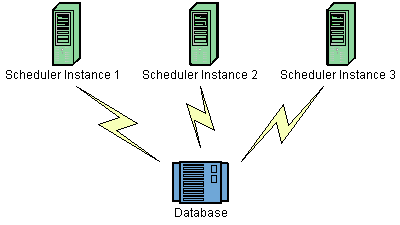
要启用集群模式,需要注意以下事项:
- 需要启用 JDBCStore 或者 TerracottaJobStore 运行模式
- 需要将
jobStore.isClustered属性设置为 True - 每个单独实例需要设置唯一的
instanceId(Quartz 提供参数让这点很容易实现)
配置集群
下面看看 springboot 集成的模式下如何配置 quartz 集群模式:
在 application.yml 添加 quartz 集群配置信息:
spring:
datasource:
driverClassName: com.mysql.cj.jdbc.Driver
password: 123456
url: jdbc:mysql://127.0.0.1:3306/quartz_demo
username: root
quartz:
job-store-type: jdbc
properties:
org:
quartz:
scheduler:
instanceName: ClusteredScheduler # 集群名,若使用集群功能,则每一个实例都要使用相同的名字
instanceId: AUTO # 若是集群下,每个 instanceId 必须唯一,设置 AUTO 自动生成唯一 Id
threadPool:
class: org.quartz.simpl.SimpleThreadPool
threadCount: 25
threadPriority: 5
jobStore:
class: org.springframework.scheduling.quartz.LocalDataSourceJobStore
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: QRTZ_
useProperties: true # 使用字符串参数,避免了将非 String 类序列化为 BLOB 的类版本问题
isClustered: true # 打开集群模式
clusterCheckinInterval: 5000 # 集群存活检测间隔
misfireThreshold: 60000 # 最大错过触发事件时间
使用集群模式需要添加数据库依赖,如下:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
然后创建 SchedulerConfig 配置类,将相关的配置信息加载到 SchedulerFactoryBean 中才能生效:
@Configuration
public class SchedulerConfig {
@Autowired
private DataSource dataSource;
@Autowired
private QuartzProperties quartzProperties;
@Bean
public SchedulerFactoryBean schedulerFactoryBean() {
Properties properties = new Properties();
properties.putAll(quartzProperties.getProperties());
SchedulerFactoryBean factory = new SchedulerFactoryBean();
factory.setOverwriteExistingJobs(true);
factory.setDataSource(dataSource);
factory.setQuartzProperties(properties);
return factory;
}
}
最后在启动日志内,可以看到 Quartz 启动集群模式运行:
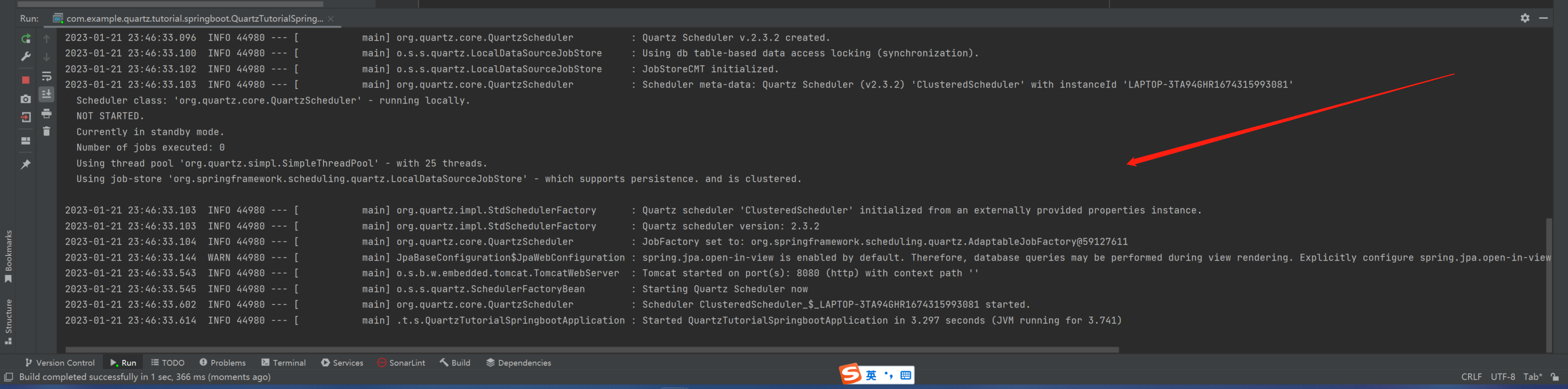
注意事项
使用集群模式,需要注意以下事项:
- 不要在单机模式下使用集群模式,不然会出现时钟同步问题,具体参考 NIST Internet Time Service (ITS) | NIST
- 不要在集群示例中,运行单机示例,不然会出现数据混乱和不稳定的情况
- 关于任务的运行节点是随机的(哪个节点抢到锁就可以执行),尤其对大量情人的情况
- 如果不想依赖 JDBC 数据库实现集群,可以看看 TerracottaJobStore 模式
以上对于 Quartz 的总结就到这里了,有什么不当之处,欢迎交流指正。
标签:教程,Quartz,Trigger,quartz,使用,org,public,JobDetail From: https://www.cnblogs.com/xiao2shiqi/p/17064305.html