pre
ref: https://zhuanlan.zhihu.com/p/463907942
paper: https://openaccess.thecvf.com/content/CVPR2021/html/Xie_DG-Font_Deformable_Generative_Networks_for_Unsupervised_Font_Generation_CVPR_2021_paper.html
code: https://github.com/ecnuycxie/DG-Font/issues
intro
与字体生成最相关的图像生成领域 (Image-To-Image Translation),在通常的image-to-image的转换模型中通常将style定义为纹理和颜色,而字体的style往往是指字体的格式几何形状、笔画粗细、笔尖和连笔书写的模式等内容。(geometric transformation, stroke thickness, tips, and joined-up writing pattern),故而没法直接应用到字体的生成上。同时在图像中往往采用的AdaIN-based方法(这种方法是在统计学上对齐特征来迁移图像的纹理和颜色特征)对于字体这种变换局部的特征模式的任务是不合适的。
同时,对于image-to-image的生成任务而言,一系列的无监督的方法,都是使用对抗训练结合Consistent Contrains来进行的。如果使用image-to-image的方法直接应用到字体生成任务中的话,即使Consistent Constraints会帮助我们保留一个字符图片内容的结构,但是他们仍然会导致诸如模糊、丢失笔画等问题。
Deformable convolution v1
Task 上的难点
视觉任务中一个难点就是如何 model 物体的几何变换,比如由于物体大小,pose, viewpoint 引起的。一般两类做法:
- 让 training dataset 就包含所有可能的集合变换。通过 affine transformation 去做 augmentation
- 另一种设计 transformation-invariant (对那些几何变换不变)的 feature 和算法。比如 SIFT 和 sliding window 的方式。
而上述两种方式有问题,几何变换我们是事先知道的,这种不能 generalize 到其它场景和任务中。
CNN 的缺陷
前的 CNN 主要是通过 data augmentation 和一些手工设计,比如 max-pooling 解决的(max-pooling 只能解决一些很小程度的变化,比如字母 A 稍微倾斜了一下),因为它的采样操作是 fixed 的。每个点的 receptive field 是一样大的,对 high-level 的语义不太好。
Controbution & Details
主要提出了两个模块,Deformable Conv 和 Deformable Pooling。他们的优点是很方便的嵌入的已有的模型中,不需要额外的监督信号。
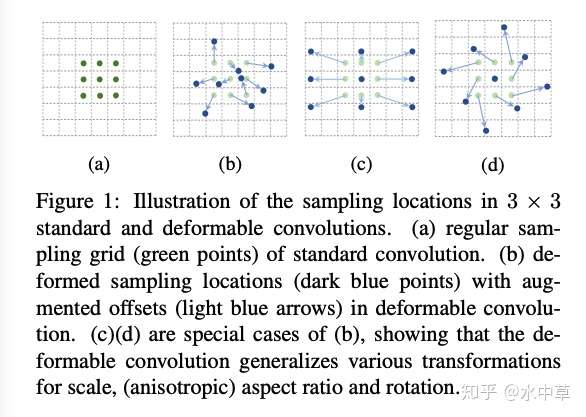
对原本3x3卷积的位置做出了改变,从 kernel 的角度看,输入的 feature 相当于发生了形变(局部的)
Deformable convolution v2
v1 版本使用了 deformable conv 后,还是会覆盖到 irrelevant context, 影响performance,v2 的 contribution 基本上围绕如何消除 irrelevant context 的影响
modulated deformable conv: 为了减少 irrelevant 区域的影响,在学习 offset 的同时,又学习一个权重,它对每个 location 不同的,我们可以让这些区域的 weight 变得比较小。
可变形卷积Deformable Convolution,其加强了CNN的变换建模能力,它通过额外的偏移量增加了模块中的空间采样位置。在DG-Font 中,可变形卷积的偏移量是通过 learned latent style code来进行估计的
主要设计思想
作者提出了可变形生成网络(Deformable Generative Networks)来做非监督的字体生成。其利用提供的目标字体图像(style image input)来将一种字体的字符变形和转换为另一种字体。
其核心模块为一个叫做FDSC(feature deformation skip connection)的东西,可以用来预测一个位移映射map然后使用位移映射map去对low-level的特征图做变形卷积。然后FDSC的输出被送入一个混合器,然后生成最终的结果。
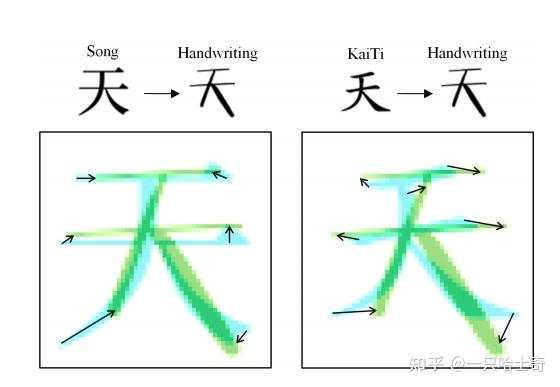
FDSC模块将会对内容图像的低层级特征进行变换,其能够保留文字本身的模式,比如笔画和偏旁部首信息。因为对于内容相同的两种不同风格的字体,它们的每一笔画通常都是对应的(如下图所示)。利用字体的空间关系,利用FDSC进行空间变形,有效地保证了生成的字符具有完整的结构。
具体方法与网络架构
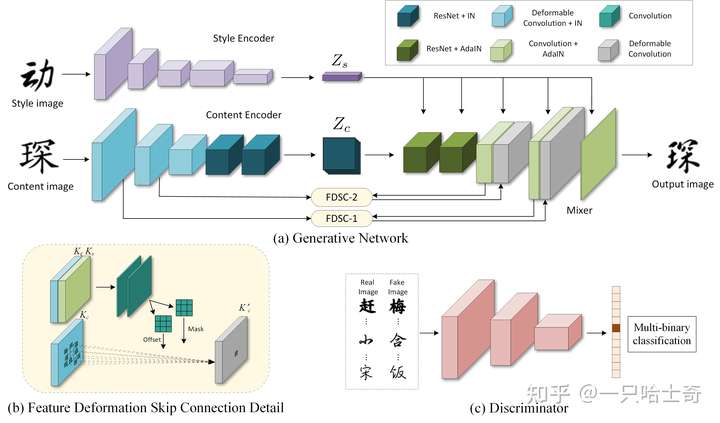
- Style Encoder 从输入图像中学习Style Representation。具体而言,其将一个Style Image作为输入,将其映射至一个Style Latent Vector \(Z_S\)。
- Content Encoder 提取Content Images的结构特征,将其 映射到一个空间特征图 \(Z_C\)
- Deformable Convolution能够使得Content Encoder去识别到相同内容的字中Style-Invariant的特征
- Mixer 通过混合\(Z_C\)和\(Z_S\)来生成输出字符。其使用AdaIN方法将style特征注入Mixer中。
- FDSC 模块能够将变形的Low-Level特征从Content Encoder中传输到Mixer中
- Multi-Task Discriminator :当字符图像从生成网络生成后,该判别器用来对每个单独的 Style 同时执行判断任务。对于每一个style来说, Discriminator的输出是一个二元分类器, 判断其是真实图片还是生成图片。同时,因为在训练集中,有多种不同的字体风格,所以判别器的输出是一个数组,它的长度是所有风格的数量