关于创建高性能的索引
索引是什么?索引相当于一本书的目录,我们要查找某一知识点,首先会到目录章节中进行比对,根据目录的指引快速定位到我们需要查找的某一指定章节的内容。
这一动作相比于我们拿起一本书从第一页开始翻阅查找我们想要的章节点,显然效率高出了很多。
对于数据库而言我们对数据库中的某一数据进行查找,其实就相当于我们在翻阅一本书进行查阅定位我们想要的内容,那那么对于这种方法的查找无一例外,如果我们要查阅的这本书比较单薄(数据量较小),对于查询所花费的时间来说是比较少的,对于如果这本书非常的厚(数据库庞大),那么如果去查找,这个过程就非常的占用计算机的性能,非常的消耗时间了。
所以说到这里,“索引” 这一概念在数据库中的体现也就变得清晰了许多,给数据库的字段添加索引其实就是为了解决,当数据库过于庞大,查询所带来的性能占用过高这样的问题的。
在《高性能MySQL》书中的 5.1.1 章节中提到,关于索引几个基本的原理图,如下图所示:
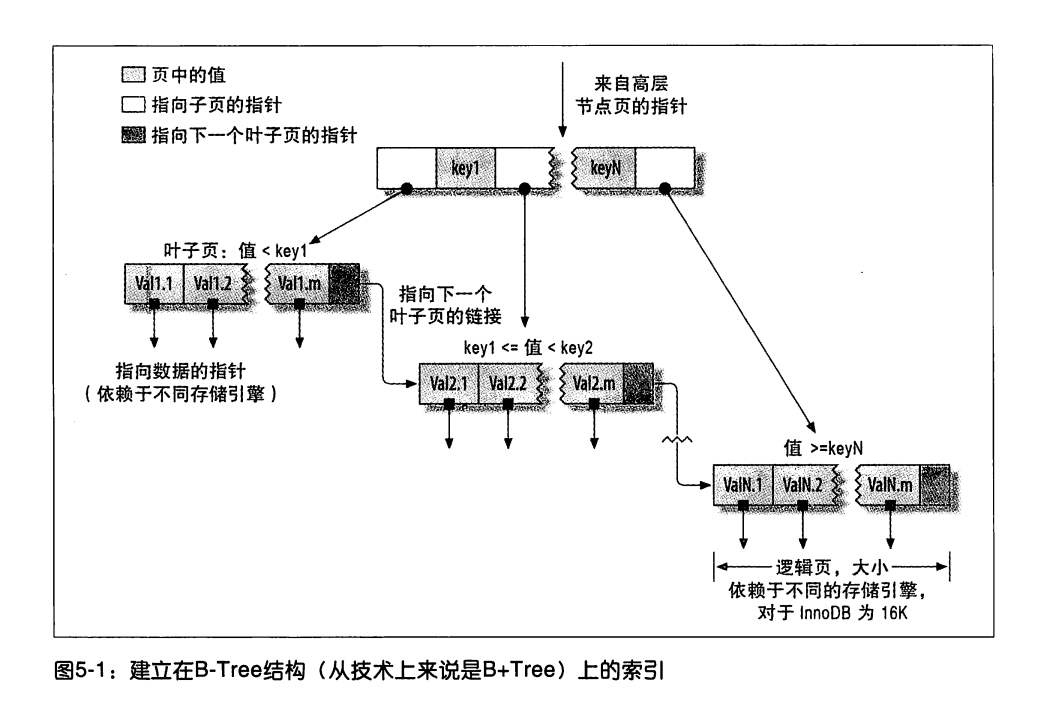
图中描述的是 B-Tree 的基本存储结构
150页 案例
假设有如下的数据表:
CREATE TABLE People(
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m','f') not null,
key(last_name,first_name,dob)
)
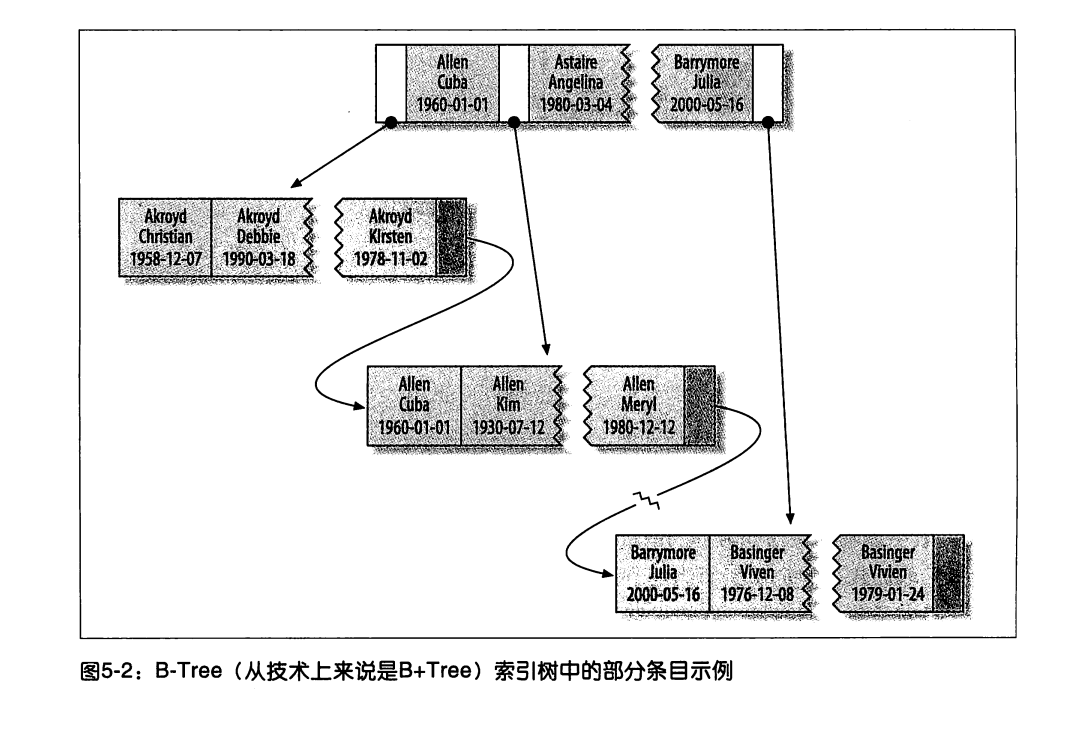
根据上图 5-1 可以看到图 5-2 中所描述的 People 表的基本结构为:
首先是根据 last_name 字段按照字母的 A~Z 顺序进行建立索引,如果字段 last_name 相同则根据 first_name 字段建立索引。前两个字段的数据都相同的时候,会根据 date 建立索引。
标签:last,name,高性能,数据库,索引,查找,创建,null From: https://www.cnblogs.com/peggys/p/17014631.html