Mat-基本图像容器
目标
我们有多种方式从现实世界中获取数字图像:数码相机,扫描仪,计算机断层扫描和磁共振成像等等。在任何情况下,我们(人类)看到的都是图像。然而,当将其转换为数字设备时,我们记录的是图像中每个点的数值。

例如在上述图像中,您可以看到汽车的镜像只不过是一个包含像素点所有强度值的矩阵。我们如何获取和存储像素值可能会根据我们的需要而有所不同,但最终,计算机世界内的所有图像可能会被减少到描述矩阵本身的数字矩阵和其他信息。OpenCV是一个计算机视觉库,其主要重点是处理和操纵这些信息。因此,您需要熟悉的第一件事是OpenCV如何存储和处理图像。
Mat
OpenCV自2001年以来一直存在。在那些日子里,库是围绕C接口构建的,并将图像存储在内存中,它们使用了一个称为IplImage的C结构。这是大部分老版本的教程和教材。这样做的问题是它带来了C语言的所有缺点。最大的问题是手动内存管理。它建立在用户负责处理内存分配和释放的假设的基础上。虽然这不是一个较小的程序的问题,但一旦你的代码基础的增长,处理这些代码就更难,而不是专注于解决你的发展目标。
幸运的是C ++来了,并介绍了类的概念,使用户更容易通过自动内存管理(或多或少)。好消息是,C ++与C完全兼容,所以在进行更改时不会出现任何兼容性问题。因此,OpenCV 2.0引入了一个新的C ++界面,它提供了一种新的处理方式,这意味着您不需要调节内存管理,使您的代码简洁(少写,实现更多)。C ++界面的主要缺点是,目前许多嵌入式开发系统只支持C.因此,除非您定位嵌入式平台,否则无需使用旧方法(除非您是一个受虐狂程序员,而且您在问为了麻烦)。
您需要了解Mat的第一件事是,您不再需要手动分配其内存,并在不需要它时立即发布它。在执行此操作仍然是可能的情况下,大多数OpenCV功能将自动分配其输出数据。如果您传递已经存在的Mat对象(已经为矩阵分配了所需的空间),那么这是一个很好的奖励,这将被重用。换句话说,我们在任何时候都使用与我们需要执行任务一样多的内存。
Mat基本上是一个具有两个数据部分的类:矩阵头(包含矩阵的大小,用于存储的方法,存储在哪个地址的信息等等)和指向包含像素值(取决于所选存储方法的任何维度)。矩阵头大小是恒定的,然而矩阵本身的大小可以随着图像的不同而变化,通常会大一个数量级。
OpenCV是一个图像处理库。它包含大量的图像处理功能。为了解决计算挑战,大多数时候你最终会使用库的多个功能。因此,将图像传递给功能是常见的做法。我们不应该忘记,我们正在谈论的图像处理算法,这往往是相当计算重。我们想要做的最后一件事是通过制作不必要的可能的大图像副本进一步降低程序的速度。
为解决这个问题,OpenCV使用引用计数系统。这个想法是每个Mat对象都有自己的头,但是通过使它们的矩阵指针指向相同的地址,矩阵可以在它们的两个实例之间共享。此外,复制操作符只会将头和指针复制到大矩阵,而不是数据本身。
Mat A, C; // creates just the header parts
A = imread(argv[1], IMREAD_COLOR); // here we'll know the method used (allocate matrix)
Mat B(A); // Use the copy constructor
C = A; // Assignment operator
所有上述对象,最后指向相同的单个数据矩阵。然而,它们的头部是不同的,并且使用它们中的任何一个进行修改也会影响所有其他的。在实践中,不同的对象只是向相同的底层数据提供不同的访问方法。然而,他们的头部不一样。真正有趣的部分是您可以创建仅引用完整数据的小节的标题。例如,要在图像中创建感兴趣区域(ROI),您只需创建一个新边界的新标题:
Mat D (A, Rect(10, 10, 100, 100) ); // using a rectangle
Mat E = A(Range::all(), Range(1,3)); // using row and column boundaries
现在您可以询问矩阵本身是否属于多个Mat对象,它们在不再需要时负责清理它。简短的答案是:使用它的最后一个对象。这是通过使用引用计数机制来处理的。每当有人复制Mat对象的标题时,矩阵的计数器就会增加。每当头部被清洁时,这个计数器就会减少。当计数器达到零时,矩阵也被释放。有时你也想复制矩阵本身,所以OpenCV提供了cv :: Mat :: clone()和cv :: Mat :: copyTo()函数。
Mat F = A.clone();
Mat G;
A.copyTo(G);
现在修改F或G不会影响Mat头指向的矩阵。所有这一切你需要记住的是:
- OpenCV功能的输出图像分配是自动的(除非另有说明)。
- 您不需要考虑OpenCVs C ++界面的内存管理。
- 赋值运算符和复制构造函数只复制标题。
- 可以使用cv :: Mat :: clone()和cv :: Mat :: copyTo()函数复制图像的基础矩阵。
存储方法
这是关于如何存储像素值。您可以选择使用的颜色空间和数据类型。颜色空间是指我们如何组合颜色分量以编码给定的颜色。最简单的一个是灰色,我们可以使用的颜色是黑色和白色。这些组合使我们能够创建许多灰色阴影。
对于丰富多彩的方式,我们有更多的选择方法。他们每个人都将它们分解成三到四个基本组件,我们可以使用这些组合来创建其他组件。最流行的是RGB,主要是因为这也是我们的眼睛如何建立颜色。其基色为红,绿,蓝。为了编码颜色的透明度有时是第四个元素:添加了α(A)。
然而,还有许多其他颜色系统都有自己的优势:
- RGB是最常见的,因为我们的眼睛使用类似的东西,但请记住,OpenCV标准显示系统使用BGR颜色空间(红色和蓝色通道的开关)组成颜色。
- HSV和HLS将颜色分解为色调,饱和度和值/亮度分量,这是我们描述颜色的更自然的方式。例如,您可能会忽略最后一个组件,使您的算法对输入图像的光线条件不太敏感。
- YCrCb被流行的JPEG图像格式使用。
- CIE L * a * b *是感知统一的颜色空间,如果您需要测量给定颜色与其他颜色的距离,则可方便使用。
每个建筑组件都有自己的有效域。这导致使用的数据类型。我们如何存储组件定义了我们在其域中的控件。可能的最小数据类型是char,这意味着一个字节或8位。这可能是无符号的(因此可以存储从0到255的值)或带符号(从-127到+127的值)。尽管在三个组件的情况下,这已经提供了1600万个可能的颜色来表示(像在RGB情况下),我们可以通过使用浮点数(4字节= 32位)或双(8字节= 64位)数据来获得更精细的控制每个组件的类型。然而,请记住,增加组件的大小也会增加内存中整个画面的大小。
明确创建一个Mat对象
在加载,修改和保存图像教程中,您已经学习了如何使用cv :: imwrite()函数将矩阵写入图像文件。但是,为了调试目的,查看实际值更为方便。您可以使用Mat的“操作符”来执行此操作。请注意,这仅适用于二维矩阵。
虽然Mat作为一个图像容器非常好,但它也是一个通用的矩阵类。因此,可以创建和操纵多维矩阵。您可以通过多种方式创建Mat对象:
- cv :: Mat :: Mat构造函数
Mat M(2,2,CV_8UC3,Scalar(0,0,255));
cout << “M =” << endl << “” <<“M << endl << endl;
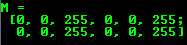
对于二维和多通道图像,我们首先定义它们的大小:行和列数明智。
然后,我们需要指定用于存储元素的数据类型和每个矩阵点的通道数。为此,我们根据以下约定构造了多个定义:
CV_[The number of bits per item][Signed or Unsigned][Type Prefix]C[The channel number]
例如,CV_8UC3意味着我们使用8位长的无符号字符类型,每个像素有三个形成三个通道。这是最多四个通道号预定义的。该CV ::标量是四个元件短矢量。指定这一点,您可以使用自定义值初始化所有矩阵点。如果您需要更多功能,您可以使用上部宏来创建类型,在括号中设置通道号,如下所示。
- 使用C / C ++数组并通过构造函数进行初始化
int sz[3] = {2,2,2};
Mat L(3,sz, CV_8UC(1), Scalar::all(0));
上面的例子显示了如何创建一个具有两维以上的矩阵。指定其维度,然后传递一个包含每个维的大小的指针,其余的保持不变。
- cv :: Mat :: create function:
M.create(4,4,CV_8UC(2));
cout << “M =” << endl << “” <<“M << endl << endl;
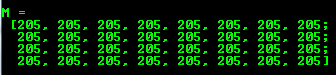
您无法使用此结构初始化矩阵值。如果新的大小不适合旧的,它将仅重新分配其矩阵数据存储器。
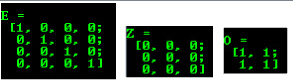
- MATLAB样式初始化器:cv :: Mat :: zeros,cv :: Mat :: ones,cv :: Mat :: eye。指定要使用的大小和数据类型:
Mat E = Mat :: eye(4,4,CV_64F);
cout << “E =” << endl << “” << E << endl << endl;
Mat O = Mat :: ones(2,2,CV_32F);
cout << “O =” << endl << “” <<“O << endl << endl;
Mat Z = Mat :: zeros(3,3,CV_8UC1);
cout << “Z =” << endl << “” << Z << endl << endl;
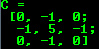
- 对于小矩阵,您可以使用逗号分隔的初始化器或初始化器列表(在最后一种情况下需要C ++ 11支持):
Mat C =(Mat_ <double>(3,3)<< 0,-1,0,-1,5,-1,0,-1,0);
cout << “C =” << endl << “”“ << C << endl << endl;
C =(Mat_ <double>({0,-1,0,-1,5,-1,0,-1,0}))。reshape(3);
cout << “C =” << endl << “”“ << C << endl << endl;
为现有的Mat对象和cv :: Mat :: clone或cv :: Mat :: copyTo创建一个新标题。
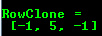
Mat RowClone = C.row(1).clone();
cout << “RowClone =” << endl << “” << RowClone << endl << endl;
注意
您可以使用cv :: randu()函数填入随机值的矩阵。您需要给出随机值的较低和较高值:
Mat R = Mat(3,2,CV_8UC3);
randu(R,Scalar :: all(0),Scalar :: all(255));
输出格式
在上述示例中,您可以看到默认的格式化选项。然而,OpenCV允许您格式化矩阵输出:
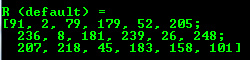
- Default
cout << “R(default)=” << endl << R << endl << endl;
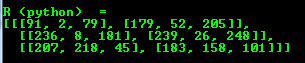
- Python
cout << "R (python) = " << endl << format(R, Formatter::FMT_PYTHON) << endl << endl;
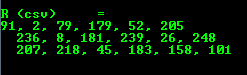
- Comma separated values (CSV)
cout << “R(csv)=” << endl << format(R,Formatter :: FMT_CSV)<< endl << endl;
- NumPy
cout << "R (numpy) = " << endl << format(R, Formatter::FMT_NUMPY ) << endl << endl;

- C
cout << “R(c)=” << endl << format(R,Formatter :: FMT_C)<< endl << endl;
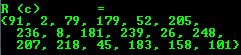
其他常用项目的输出
OpenCV还通过<<运算符来支持其他常见OpenCV数据结构的输出:
- 2D Point
Point2f P(5,1);
cout << “Point(2D)=” << P << endl << endl;

- 3D Point
Point3f P3f(2, 6, 7);
cout << "Point (3D) = " << P3f << endl << endl;

- std :: vector via cv :: Mat
vector<float> v;
v.push_back( (float)CV_PI); v.push_back(2); v.push_back(3.01f);
cout << "Vector of floats via Mat = " << Mat(v) << endl << endl;

- std::vector of points
vector<Point2f> vPoints(20);
for (size_t i = 0; i < vPoints.size(); ++i)
vPoints[i] = Point2f((float)(i * 5), (float)(i % 7));
cout << "A vector of 2D Points = " << vPoints << endl << endl;

这里的大多数样品已被包含在一个小的控制台应用程序中。您可以从这里或cpp示例的核心部分下载。
如何使用OpenCV扫描图像,查找表格和时间测量
目标
我们会为以下问题寻求答案:
- 如何通过图像的每个像素?
- OpenCV矩阵值如何存储?
- 如何衡量我们的算法的性能?
- 什么是查找表,为什么使用它们?
我们的测试用例
让我们考虑一种简单的减色方法。通过对矩阵项存储使用unsigned char C和C ++类型,像素通道最多可以有256个不同的值。对于三通道图像,这可以允许形成太多的颜色(1600万精确)。使用如此多的色调可能会对我们的算法性能造成沉重打击。然而,有时候,只要少一点工作能够得到相同的最终结果就足够了。
在这种情况下,我们通常会减少色彩空间。这意味着我们将颜色空间当前值与新的输入值分开,以减少颜色。例如,零和九之间的每个值都将新的值为零,每个值在十到十十之间的值十等等。
当您使用int值将uchar(unsigned char-aka值在0和255之间)值分隔时,结果也将是char。这些值只能是char值。因此,任何分数将被向下舍入。利用这一事实,uchar域中的上层操作可以表示为:
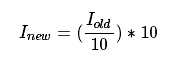
简单的颜色空间缩小算法将包括仅通过图像矩阵的每个像素并应用该公式。值得注意的是,我们做一个除法和乘法运算。这些操作对于系统来说是昂贵的。如果可能,通过使用更便宜的操作(如少量减法,添加或在最佳情况下是简单的分配)来避免这种情况。此外,请注意,我们只有上限操作的输入值有限。在uchar系统的情况下,这是256。
因此,对于较大的图像,预先计算所有可能的值,并且在分配期间通过使用查找表来进行分配是明智的。查找表是简单的数组(具有一个或多个维),对于给定的输入值变量保存最终的输出值。其实力在于我们不需要进行计算,只需要读取结果。
我们的测试用例程序(以及此处提供的示例)将执行以下操作:读取控制台线路参数图像(可以是颜色或灰度级 - 控制台线路参数),并使用给定的控制台行参数整数值。在OpenCV中,目前有三种主要通过像素逐个通过图像的方法。为了使事情更有趣,将使用所有这些方法对每个图像进行扫描,并打印出花费多长时间。
您可以在这里下载完整的源代码,或者在OpenCV的sample目录中查看核心部分的cpp教程代码。其基本用途是:
how_to_scan_images imageName.jpg intValueToReduce [G]
最后一个参数是可选的。如果给定图像将以灰度格式加载,否则使用BGR颜色空间。首先是计算查找表。
int divideWith = 0; // convert our input string to number - C++ style
stringstream s;
s << argv[2];
s >> divideWith;
if (!s || !divideWith)
{
cout << "Invalid number entered for dividing. " << endl;
return -1;
}
uchar table[256];
for (int i = 0; i < 256; ++i)
table[i] = (uchar)(divideWith * (i/divideWith));
这里我们首先使用C ++ stringstream类将第三个命令行参数从文本转换为整数格式。然后我们使用一个简单的外观和上面的公式来计算查找表。没有OpenCV具体的东西在这里。
另一个问题是我们如何衡量时间?那么OpenCV提供了两个简单的函数来实现这个cv :: getTickCount()和cv :: getTickFrequency()。第一个从某个事件返回系统CPU的刻度数(就像您启动系统一样)。第二次返回您的CPU在一秒钟内发出多少次刻录。所以为了测量秒数,两次操作之间的时间容易如下:
double t = (double)getTickCount();
// do something ...
t = ((double)getTickCount() - t)/getTickFrequency();
cout << "Times passed in seconds: " << t << endl;
图像矩阵如何存储在内存中?
正如您已经阅读我的Mat - 基本图像容器教程中的矩阵大小取决于使用的颜色系统。更准确地说,它取决于所使用的通道数量。在灰度图像的情况下,我们有一些像:
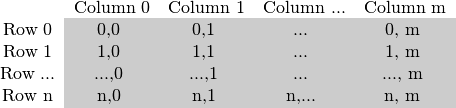
对于多通道图像,列包含与通道数一样多的子列。例如在BGR颜色系统的情况下:

注意,通道的顺序是反向的:BGR而不是RGB。因为在许多情况下,内存足够大以便以连续的方式存储行,所以这些行可以一个接一个地跟随,创建一个长行。因为一切都在一个地方,这可能有助于加快扫描过程。我们可以使用cv :: Mat :: isContinuous()函数来询问矩阵是否是这种情况。继续下一节找一个例子。
有效的方式
当涉及到性能时,你无法击败经典的C风格操作符[](指针)访问。因此,我们可以推荐使用最有效的方法进行分配:
Mat& ScanImageAndReduceC(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
int channels = I.channels();
int nRows = I.rows;
int nCols = I.cols * channels;
if (I.isContinuous())
{
nCols *= nRows;
nRows = 1;
}
int i,j;
uchar* p;
for( i = 0; i < nRows; ++i)
{
p = I.ptr<uchar>(i);
for ( j = 0; j < nCols; ++j)
{
p[j] = table[p[j]];
}
}
return I;
}
在这里,我们基本上只是获取一个指向每行开头的指针,直到它结束。在特殊情况下,矩阵以连续的方式存储,我们只需要单次请求指针,直到最后。我们需要寻找彩色图像:我们有三个通道,所以我们需要通过每行三次以上的项目。
还有另一种方法。Mat对象的数据数据成员返回指向第一行第一列的指针。如果此指针为空,则该对象中没有有效的输入。检查这是检查您的图像加载是否成功的最简单的方法。如果存储是连续的,我们可以使用它来遍历整个数据指针。在灰度图像的情况下,它将如下所示:
uchar * p = I.data;
for(unsigned int i = 0; i <ncol * nrows; ++ i)
* p ++ = table [* p];
你会得到相同的结果。但是,这段代码稍后阅读很难阅读。如果你有更先进的技术,那就更难了。此外,在实践中,我观察到您将获得相同的性能结果(因为大多数现代编译器可能会为您自动实现这种小型优化技巧)。
迭代程序(安全)方法
如果有效的方式确保您通过适量的uchar字段,并跳过行之间可能发生的差距是您的责任。迭代程序方法被认为是更安全的方式,因为它从用户接管这些任务。所有你需要做的是要求图像矩阵的开始和结束,然后只是增加开始迭代程序,直到你到达结束。要获取迭代程序指向的值,使用*运算符(在它之前添加)。
Mat& ScanImageAndReduceIterator(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
const int channels = I.channels();
switch(channels)
{
case 1:
{
MatIterator_<uchar> it, end;
for( it = I.begin<uchar>(), end = I.end<uchar>(); it != end; ++it)
*it = table[*it];
break;
}
case 3:
{
MatIterator_<Vec3b> it, end;
for( it = I.begin<Vec3b>(), end = I.end<Vec3b>(); it != end; ++it)
{
(*it)[0] = table[(*it)[0]];
(*it)[1] = table[(*it)[1]];
(*it)[2] = table[(*it)[2]];
}
}
}
return I;
}
在彩色图像的情况下,我们每列有三个uchar项目。这可能被认为是一个简短的uchar项目向量,已经在OpenCV中使用Vec3b名称进行了浸礼。要访问第n个子列,我们使用简单的operator []访问。重要的是要记住,OpenCV迭代程序遍历列,并自动跳到下一行。因此,如果使用简单的uchar迭代程序,您将只能访问蓝色通道值。
参考返回的即时地址计算
最后的方法不推荐用于扫描。它是为了获取或修改图像中的某种方式的随机元素。它的基本用法是指定要访问的项目的行号和列号。在我们早期的扫描方法中,您可以通过我们正在查看的图像来观察这一点很重要。这在这里没有什么不同,因为您需要手动指定在自动查找时要使用的类型。如果下列源代码的灰度图像(+ cv :: at()函数的用法),您可以观察这一点:
Mat& ScanImageAndReduceRandomAccess(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
const int channels = I.channels();
switch(channels)
{
case 1:
{
for( int i = 0; i < I.rows; ++i)
for( int j = 0; j < I.cols; ++j )
I.at<uchar>(i,j) = table[I.at<uchar>(i,j)];
break;
}
case 3:
{
Mat_<Vec3b> _I = I;
for( int i = 0; i < I.rows; ++i)
for( int j = 0; j < I.cols; ++j )
{
_I(i,j)[0] = table[_I(i,j)[0]];
_I(i,j)[1] = table[_I(i,j)[1]];
_I(i,j)[2] = table[_I(i,j)[2]];
}
I = _I;
break;
}
}
return I;
}
这些功能需要您的输入类型和坐标,并即时计算查询项目的地址。然后返回一个引用。当您设置值时,获取值和非常数时,这可能是常数。作为调试模式的安全步骤*,执行一个检查,您的输入坐标是有效的并且确实存在。如果不是这样,您将在标准错误输出流上获得一个很好的输出消息。与释放模式中的有效方式相比,使用此方法的唯一区别是,对于图像的每个元素,您将获得一个新的行指针,以便我们使用C运算符[]获取列元素。
如果您需要使用此方法对图像执行多次查找,则可能会麻烦和耗时地为每个访问输入类型和at关键字。为了解决这个问题OpenCV有一个cv :: Mat_数据类型。与Mat相同,在定义中需要通过查看数据矩阵来指定数据类型,但是您可以使用operator()快速访问项目。为了使事情变得更好,这可以很容易地从和通常的cv :: Mat数据类型转换。您可以在上方功能的彩色图像的情况下看到此示例的用法。然而,重要的是要注意,cv :: at()可以完成相同的操作(具有相同的运行时速度)功能。对于懒惰的程序员的伎俩来说,这是一个更少的事情。
核心功能
这是在图像中实现查找表修改的一种奖励方法。在图像处理中,很常见的是要将所有给定的图像值修改为其他值。OpenCV提供了修改图像值的功能,无需编写图像的扫描逻辑。我们使用核心模块的cv :: LUT()函数。首先我们构建一个Mat类型的查找表:
Mat lookUpTable(1, 256, CV_8U);
uchar* p = lookUpTable.ptr();
for( int i = 0; i < 256; ++i)
p[i] = table[i];
最后调用函数(我是我们的输入图像,J是输出的一个):
LUT(I,lookUpTable,J);
性能差异
为了最好的结果,编译程序并以自己的速度运行它。为了使差异更加清晰,我使用了相当大的(2560 X 1600)图像。这里呈现的性能是彩色图像。为了获得更准确的值,我将从函数调用得到的值平均为100次。
| 方法 | 时间 |
|---|---|
| 高效的方式 | 79.4717毫秒 |
| 迭代程序 | 83.7201毫秒 |
| 在飞行RA | 93.7878毫秒 |
| LUT功能 | 32.5759毫秒 |
我们可以总结一些事情。如果可能,请使用OpenCV已经创建的功能(而不是重新创建它们)。最快的方法是LUT功能。这是因为OpenCV库通过Intel Threaded Building Blocks启用多线程。但是,如果你需要编写一个简单的图像扫描,喜欢指针方法。迭代程序程序
是一个更安全的赌注,但是相当慢。使用即时参考访问方法进行全图像扫描是调试模式中最昂贵的。在释放模式下,它可能会击败迭代程序方法,但是它肯定会牺牲迭代程序的安全性能。
OpenCV矩阵上的掩码操作
矩阵上的掩码操作非常简单。这个想法是,我们根据掩码矩阵(也称为内核)重新计算图像中的每个像素值。该掩码保存将调整相邻像素(和当前像素)对新像素值有多大影响的值。从数学的角度来看,我们用加权平均值与我们指定的值进行比较。
我们的测试案例
C++
让我们考虑图像对比度增强方法的问题。基本上我们要为图像的每个像素应用以下公式:

第一个符号是使用公式,而第二个是通过使用掩码的第一个压缩版本。通过将掩模矩阵的中心(在零值索引的大写表示)放在要计算的像素上,并使用叠加的矩阵值乘以像素值,并使用掩码。这是同样的事情,但是在大型矩阵的情况下,后一种符号更容易查看。
现在让我们看看如何通过使用基本的像素访问方法或使用cv :: filter2D函数来实现这一点。
基本方法
这里有一个功能:
void Sharpen(const Mat& myImage,Mat& Result)
{
CV_Assert(myImage.depth() == CV_8U); // accept only uchar images
const int nChannels = myImage.channels();
Result.create(myImage.size(),myImage.type());
for(int j = 1 ; j < myImage.rows-1; ++j)
{
const uchar* previous = myImage.ptr<uchar>(j - 1);
const uchar* current = myImage.ptr<uchar>(j );
const uchar* next = myImage.ptr<uchar>(j + 1);
uchar* output = Result.ptr<uchar>(j);
for(int i= nChannels;i < nChannels*(myImage.cols-1); ++i)
{
*output++ = saturate_cast<uchar>(5*current[i]
-current[i-nChannels] - current[i+nChannels] - previous[i] - next[i]);
}
}
Result.row(0).setTo(Scalar(0));
Result.row(Result.rows-1).setTo(Scalar(0));
Result.col(0).setTo(Scalar(0));
Result.col(Result.cols-1).setTo(Scalar(0));
}
首先我们确保输入图像数据是unsigned char格式。为此,我们使用cv :: CV_Assert函数,当其中的表达式为false时,该函数会引发错误。
CV_Assert(myImage.depth() == CV_8U); // accept only uchar images
我们创建一个与我们的输入相同大小和相同类型的输出图像。您可以在存储部分看到,根据通道数量,我们可能有一个或多个子列。
我们将通过指针迭代它们,因此元素的总数取决于这个数字。
const int nChannels = myImage.channels();
Result.create(myImage.size(),myImage.type());
我们将使用普通C []运算符来访问像素。因为我们需要在同一时间访问多行,我们将获取每个行的指针(前一个,当前和下一行)。我们需要另一个指向我们要保存计算的指针。然后只需使用[]运算符访问正确的项目。为了在前面移动输出指针,我们在每个操作之后简单地增加一个(一个字节):
for(int j = 1; j <myImage.rows-1; ++ j)
{
const uchar * previous = myImage.ptr < uchar >(j - 1);
const uchar * current = myImage.ptr < uchar >(j);
const uchar * next = myImage.ptr < uchar >(j + 1);
uchar * output = Result.ptr < uchar >(j);
for(int i = nChannels; i <nChannels *(myImage.cols-1); ++ i)
{
* output ++ = saturate_cast < uchar >(5 * current [i]
-current [i-nChannels] - current [i + nChannels] - 上一个[i] - next [i]);
}
}
在图像的边框上,上面的符号会导致像素位置不一致(如减去一个减去一个)。在这些点上,我们的公式是未定义的。一个简单的解决方案是在这些点上不应用内核,例如,将边框上的像素设置为零:
Result.row(0).setTo(Scalar(0));
Result.row(Result.rows-1).setTo(Scalar(0));
Result.col(0).setTo(Scalar(0));
Result.col(Result.cols-1).setTo(Scalar(0));
filter2D function
应用这样的过滤器在图像处理中是常见的,在OpenCV中存在着将应用掩码(在某些地方也称为内核)的功能。为此,您首先需要定义一个保存掩码的对象:
Mat kernel = (Mat_<char>(3,3) << 0, -1, 0,
-1, 5, -1,
0, -1, 0);
然后调用cv :: filter2D函数,指定输入,输出图像和内核使用:
filter2D(src,dst1,src.depth(),kernel);
该函数甚至有第五个可选参数来指定内核的中心,第六个可选参数,用于在将其存储在K中之前添加可选值,然后将其存储在K中,第七个用于确定在操作未定义的区域中要执行的操作(国界)。
此功能较短,较少冗长,因为有一些优化,通常比手工编码方法更快。例如在我的测试中,第二个只花了13毫秒,第一次花费了大约31毫秒。有一些区别。
例如:
您可以从这里下载此源代码,或查看OpenCV源代码库示例目录samples/cpp/tutorial_code/core/mat_mask_operations/mat_mask_operations.cpp。
Java
让我们考虑图像对比度增强方法的问题。基本上我们要为图像的每个像素应用以下公式:

第一个符号是使用公式,而第二个是通过使用掩码的第一个压缩版本。通过将掩模矩阵的中心(在零值索引的大写表示)放在要计算的像素上,并使用叠加的矩阵值乘以像素值,并使用掩码。这是同样的事情,但是在大型矩阵的情况下,后一种符号更容易查看。
现在让我们看看如何通过使用基本的像素访问方法或者使用Imgproc.filter2D()函数来实现这一点。
基本方法
这里有一个功能:
public static double saturate(double x) {
return x > 255.0 ? 255.0 : (x < 0.0 ? 0.0 : x);
}
public Mat sharpen(Mat myImage, Mat Result) {
myImage.convertTo(myImage, CvType.CV_8U);
int nChannels = myImage.channels();
Result.create(myImage.size(), myImage.type());
for (int j = 1; j < myImage.rows() - 1; ++j) {
for (int i = 1; i < myImage.cols() - 1; ++i) {
double sum[] = new double[nChannels];
for (int k = 0; k < nChannels; ++k) {
double top = -myImage.get(j - 1, i)[k];
double bottom = -myImage.get(j + 1, i)[k];
double center = (5 * myImage.get(j, i)[k]);
double left = -myImage.get(j, i - 1)[k];
double right = -myImage.get(j, i + 1)[k];
sum[k] = saturate(top + bottom + center + left + right);
}
Result.put(j, i, sum);
}
}
Result.row(0).setTo(new Scalar(0));
Result.row(Result.rows() - 1).setTo(new Scalar(0));
Result.col(0).setTo(new Scalar(0));
Result.col(Result.cols() - 1).setTo(new Scalar(0));
return Result;
}
首先我们确保输入图像数据以无符号8位格式。
myImage.convertTo(myImage,CvType .CV_8U);
我们创建一个与我们的输入相同大小和相同类型的输出图像。您可以在存储部分看到,根据通道数量,我们可能有一个或多个子列。
int nChannels = myImage.channels();
Result.create(myImage.size(),myImage.type());
我们需要访问多个行和列,可以通过向当前中心(i,j)添加或减去1来完成。然后我们应用总和并将新值放在结果矩阵中。
for(int j = 1; j <myImage.rows() - 1; ++ j){
for(int i = 1; i <myImage.cols() - 1; ++ i){
double sum [] = new double [nChannels];
for(int k = 0; k <nChannels; ++ k){
double top = -myImage.get(j - 1,i)[k];
double bottom = -myImage.get(j + 1,i)[k];
double center =(5 * myImage.get(j,i)[k]);
double left = -myImage.get(j,i-1)[k];
double right = -myImage.get(j,i + 1)[k];
sum [k] =饱和(顶+底+中+左+右);
}
Result.put(j,i,sum);
}
}
在图像的边框上,上面的符号会导致像素位置不存在(如(-1,-1))。在这些点上,我们的公式是未定义的。一个简单的解决方案是在这些点上不应用内核,例如,将边框上的像素设置为零:
Result.row(0).setTo(new Scalar(0));
Result.row(Result.rows() - 1).setTo(new Scalar(0));
Result.col(0).setTo(new Scalar(0));
Result.col(Result.cols() - 1).setTo(new Scalar(0));
filter2D function
应用这样的过滤器在图像处理中是常见的,在OpenCV中存在着将应用掩码(在某些地方也称为内核)的功能。为此,您首先需要定义一个保存掩码的对象:
Mat kern = new Mat(3,3,CvType .CV_8S);
int row = 0,col = 0;
kern.put(row,col,0,-1,0,-1,5,-1,0,-1,0);
然后调用Imgproc.filter2D()函数,指定要使用的输入,输出图像和内核:
Imgproc.filter2D(src,dst1,src.depth(),kern);
该函数甚至有第五个可选参数来指定内核的中心,第六个可选参数,用于在将其存储在K中之前添加可选值,然后将其存储在K中,第七个用于确定在操作未定义的区域中要执行的操作(国界)。
此功能较短,较少冗长,因为有一些优化,通常比手工编码方法更快。例如在我的测试中,第二个只花了13毫秒,第一次花费了大约31毫秒。有一些区别。
例如:
您可以在OpenCV源代码库示例目录中查看samples/java/tutorial_code/core/mat_mask_operations/MatMaskOperations.java。
Python
我们考虑图像对比度增强方法的问题。基本上我们要为图像的每个像素应用以下公式:

第一个符号是使用公式,而第二个是通过使用掩码的第一个压缩版本。通过将掩模矩阵的中心(在零值索引的大写表示)放在要计算的像素上,并使用叠加的矩阵值乘以像素值,并使用掩码。这是同样的事情,但是在大型矩阵的情况下,后一种符号更容易查看。
现在让我们看看如何通过使用基本的像素访问方法或使用cv2.filter2D()函数来实现这一点。
基本方法
这里有一个功能:
def is_grayscale(my_image):
return len(my_image.shape) < 3
def saturated(sum_value):
if sum_value > 255:
sum_value = 255
if sum_value < 0:
sum_value = 0
return sum_value
def sharpen(my_image):
if is_grayscale(my_image):
height, width = my_image.shape
else:
my_image = cv2.cvtColor(my_image, cv2.CV_8U)
height, width, n_channels = my_image.shape
result = np.zeros(my_image.shape, my_image.dtype)
for j in range(1, height - 1):
for i in range(1, width - 1):
if is_grayscale(my_image):
sum_value = 5 * my_image[j, i] - my_image[j + 1, i] - my_image[j - 1, i] \
- my_image[j, i + 1] - my_image[j, i - 1]
result[j, i] = saturated(sum_value)
else:
for k in range(0, n_channels):
sum_value = 5 * my_image[j, i, k] - my_image[j + 1, i, k] - my_image[j - 1, i, k] \
- my_image[j, i + 1, k] - my_image[j, i - 1, k]
result[j, i, k] = saturated(sum_value)
return result
首先我们确保输入图像数据以无符号8位格式。
my_image = cv2.cvtColor(my_image,cv2.CV_8U)
我们创建一个与我们的输入相同大小和相同类型的输出图像。您可以在存储部分看到,根据通道数量,我们可能有一个或多个子列。
height,width,n_channels = my_image.shape
result = np.zeros(my_image.shape,my_image.dtype)
我们需要访问多个行和列,可以通过向当前中心(i,j)添加或减去1来完成。然后我们应用总和并将新值放在结果矩阵中。
for j in range(1, height - 1):
for i in range(1, width - 1):
if is_grayscale(my_image):
sum_value = 5 * my_image[j, i] - my_image[j + 1, i] - my_image[j - 1, i] \
- my_image[j, i + 1] - my_image[j, i - 1]
result[j, i] = saturated(sum_value)
else:
for k in range(0, n_channels):
sum_value = 5 * my_image[j, i, k] - my_image[j + 1, i, k] - my_image[j - 1, i, k] \
- my_image[j, i + 1, k] - my_image[j, i - 1, k]
result[j, i, k] = saturated(sum_value)
The filter2D function
应用这样的过滤器在图像处理中是常见的,在OpenCV中存在着将应用掩码(在某些地方也称为内核)的功能。为此,您首先需要定义一个保存掩码的对象:
kernel = np.array([[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]], np.float32) # kernel should be floating point type
然后调用cv2.filter2D()函数,指定要使用的输入,输出图像和kernell:
dst1 = cv2.filter2D(src, -1, kernel) # ddepth = -1, means destination image has depth same as input image
此功能较短,较少冗长,因为有一些优化,通常比手工编码方法更快。例如在我的测试中,第二个只花了13毫秒,第一次花费了大约31毫秒。有一些区别。
例如:
您可以在OpenCV源代码库示例目录中查看samples/python/tutorial_code/core/mat_mask_operations/mat_mask_operations.py。
OpenCV图像操作
输入/输出
图片
从文件加载图像:
Mat img = imread(filename)
如果您读取jpg文件,则默认情况下会创建3通道映像。如果需要灰度图像,请使用:
Mat img = imread(filename,IMREAD_GRAYSCALE);
注意
文件的格式由其内容决定(前几个字节)将图像保存到文件中:
imwrite(filename,img);
-
注意
文件的格式由其扩展名决定。
使用imdecode和imencode从/到内存而不是文件读写图像。
具有图像的基本操作
访问像素强度值
为了获得像素强度值,您必须知道图像的类型和通道数。以下是单通道灰度图像(类型8UC1)和像素坐标x和y的示例:
Scalar intensity = img.at<uchar>(y, x);
intensity.val [0]包含0到255之间的值。请注意x和y的顺序。由于OpenCV中的图像由与矩阵相同的结构表示,所以对于两种情况,我们使用相同的约定 - 基于0的行索引(或y坐标)首先出现,并且基于0的列索引(或x坐标)跟随它。或者,您可以使用以下符号:
Scalar intensity = img.at<uchar>(Point(x, y));
现在让我们考虑使用BGR颜色排序的3通道图像(由imread返回的默认格式):
Vec3b intensity = img.at < Vec3b >(y,x);
uchar blue = intensity.val [0];
uchar green = intensity.val [1];
uchar red = intensity.val [2];
您可以使用相同的浮点图像方法(例如,您可以通过在3通道图像上运行Sobel来获取此类图像):
(y,x); Vec3f intensity = img.at < Vec3f >(y,x);
float blue = intensity.val [0];
float green = intensity.val [1];
float red = intensity.val [2];
可以使用相同的方法来改变像素强度:
img.at < UCHAR >(Y,X)= 128;
OpenCV中有功能,特别是calib3d模块,如projectPoints,它们以Mat的形式存在2D或3D数组。矩阵应该只包含一列,每行对应一个点,矩阵类型应相应为32FC2或32FC3。这样一个矩阵可以很容易地构造成std::vector:
vector<Point2f> points;
//... fill the array
Mat pointsMat = Mat(points);
可以使用与Mat :: at相同的方法访问此矩阵中的一个点:
Point2f point = pointsMat.at < Point2f >(i,0);
内存管理和引用计数
Mat是一种保持矩阵/图像特征(行和列数,数据类型等)和指向数据的指针的结构。所以没有什么可以阻止我们有几个Mat对应于相同数据的实例。当Mat的特定实例被破坏时,Mat保留一个引用计数,指示数据是否必须被释放。以下是创建两个矩阵而不复制数据的示例:
std::vector<Point3f> points;
// .. fill the array
Mat pointsMat = Mat(points).reshape(1);
因此,我们得到一个32FC1矩阵与3列而不是32FC3矩阵与1列。pointsMat使用点数据,销毁时不会释放内存。然而,在这种特殊情况下,开发人员必须确保点的生命周期比pointMat长。如果我们需要复制数据,可以使用例如cv :: Mat :: copyTo或cv :: Mat :: clone:
Mat img = imread(“image.jpg”);
Mat img1 = img.clone();
相反,使用C API,必须由开发人员创建输出图像,可以向每个功能提供空输出Mat。每个实现都为目标矩阵调用Mat :: create。如果矩阵为空,则此方法分配数据。如果它不是空且具有正确的大小和类型,该方法什么都不做。然而,如果大小或类型与输入参数不同,则数据被释放(并丢失)并分配新的数据。例如:
Mat img = imread(“image.jpg”);
Mat sobelx;
Sobel(img,sobelx,CV_32F,1,0);
原始操作
在矩阵上定义了一些方便的操作符。例如,这里是我们如何从现有的灰度图像“img”制作黑色图像:
img = Scalar(0);
选择感兴趣的区域:
Rect r(10, 10, 100, 100);
Mat smallImg = img(r);
从Mat到C API数据结构的转换:
Mat img = imread(“image.jpg”);
IplImage img1 = img;
CvMat m = img;
请注意,这里没有数据复制。
从颜色到灰度的转换:
Mat img = imread("image.jpg"); // loading a 8UC3 image
Mat grey;
cvtColor(img, grey, COLOR_BGR2GRAY);
将图像类型从8UC1更改为32FC1:
src.convertTo(dst,CV_32F);
可视化图像
在开发过程中看到算法的中间结果是非常有用的。OpenCV提供了可视化图像的便捷方式。可以使用以下方式显示8U图像:
Mat img = imread(“image.jpg”);
namedWindow(“image”,WINDOW_AUTOSIZE);
imshow(“image”,img);
waitKey();
对waitKey()的调用会启动一个消息传递循环,等待“图像”窗口中的关键笔划。32F图像需要转换为8U型。例如:
Mat img = imread("image.jpg");
Mat grey;
cvtColor(img, grey, COLOR_BGR2GRAY);
Mat sobelx;
Sobel(grey, sobelx, CV_32F, 1, 0);
double minVal, maxVal;
minMaxLoc(sobelx, &minVal, &maxVal); //find minimum and maximum intensities
Mat draw;
sobelx.convertTo(draw, CV_8U, 255.0/(maxVal - minVal), -minVal * 255.0/(maxVal - minVal));
namedWindow("image", WINDOW_AUTOSIZE);
imshow("image", draw);
waitKey();
使用OpenCV添加(混合)两个图像
目标
在本教程中,您将学习:
- 什么是线性混合,为什么它是有用的?
- 如何使用cv :: addWeighted添加两个图像
理论
-
注意
下面的解释属于Richard Szeliski 的“ 计算机视觉:算法与应用 ”一书
从我们以前的教程中,我们已经知道了一些像素运算符。一个有趣的二元(双输入)运算符是线性混合运算符:
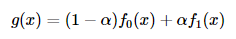
通过从0 \ rightarrow 1改变,此运算符可用于执行两个图像或视频之间的时间交叉解,如幻灯片放映和电影制作(cool,eh?)所示。α0→1
源代码
从这里下载源代码。
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main( void )
{
double alpha = 0.5; double beta; double input;
Mat src1, src2, dst;
cout << " Simple Linear Blender " << endl;
cout << "-----------------------" << endl;
cout << "* Enter alpha [0-1]: ";
cin >> input;
// We use the alpha provided by the user if it is between 0 and 1
if( input >= 0 && input <= 1 )
{ alpha = input; }
src1 = imread( "../data/LinuxLogo.jpg" );
src2 = imread( "../data/WindowsLogo.jpg" );
if( src1.empty() ) { cout << "Error loading src1" << endl; return -1; }
if( src2.empty() ) { cout << "Error loading src2" << endl; return -1; }
beta = ( 1.0 - alpha );
addWeighted( src1, alpha, src2, beta, 0.0, dst);
imshow( "Linear Blend", dst );
waitKey(0);
return 0;
}
说明
- 由于我们要执行:
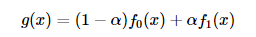
我们需要两个源图像(和)。所以,我们以通常的方式加载它们:f0(x)f1(x)
src1 = imread(“../data/LinuxLogo.jpg”);
src2 = imread(“../data/WindowsLogo.jpg”);
警告
由于我们添加 src1和src2,它们必须具有相同的大小(宽和高)和类型。
- 现在我们需要生成
g(x)图像。为此,函数cv :: addWeighted非常方便:
β=(1.0-α);
addWeighted(src1,alpha,src2,beta,0.0,dst);
因为cv :: addWeighted产生:
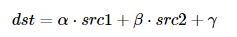
在这种情况下,gamma是上面代码中的参数。0.0
- 创建窗口,显示图像并等待用户结束程序。
imshow( "Linear Blend", dst );
waitKey(0);
结果

OpenCV改变图像的对比度和亮度
目标
在本教程中,您将学习如何:
- 访问像素值
- 用零初始化矩阵
- 了解cv :: saturate_cast是什么,为什么它是有用的
- 获取有关像素变换的一些很酷的信息
- 在一个实际的例子中提高图像的亮度
理论
-
注意
下面的解释属于Richard Szeliski 的“ 计算机视觉:算法与应用 ”一书
图像处理
- 一般的图像处理算子是采用一个或多个输入图像并产生输出图像的函数。
- 图像变换可以看作:点运算符(像素变换)邻里(区域)运营商
像素变换
- 在这种图像处理变换中,每个输出像素的值仅取决于相应的输入像素值(可能是一些全局采集的信息或参数)。
- 这些操作者的示例包括亮度和对比度调整以及颜色校正和变换。
亮度和对比度调整
- 两个常用的点处理是乘法和加法:
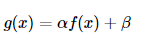
- 参数和\ beta通常称为增益和偏置参数; 有时这些参数被分别控制对比度和亮度。α>0β
- 您可以将视为源图像像素,g(x)作为输出图像像素。然后,我们可以更方便地将表达式写成:f(x)g(x)
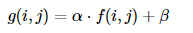
其中和j表示像素位于第i行和第j列。ij
Code
以下代码执行:g(i,j)=α⋅f(i,j)+β
#include "opencv2/imgcodecs.hpp"
#include "opencv2/highgui.hpp"
#include <iostream>
using namespace std;
using namespace cv;
int main( int argc, char** argv )
{
double alpha = 1.0; /*< Simple contrast control */
int beta = 0; /*< Simple brightness control */
String imageName("../data/lena.jpg"); // by default
if (argc > 1)
{
imageName = argv[1];
}
Mat image = imread( imageName );
Mat new_image = Mat::zeros( image.size(), image.type() );
cout << " Basic Linear Transforms " << endl;
cout << "-------------------------" << endl;
cout << "* Enter the alpha value [1.0-3.0]: "; cin >> alpha;
cout << "* Enter the beta value [0-100]: "; cin >> beta;
for( int y = 0; y < image.rows; y++ ) {
for( int x = 0; x < image.cols; x++ ) {
for( int c = 0; c < 3; c++ ) {
new_image.at<Vec3b>(y,x)[c] =
saturate_cast<uchar>( alpha*( image.at<Vec3b>(y,x)[c] ) + beta );
}
}
}
namedWindow("Original Image", WINDOW_AUTOSIZE);
namedWindow("New Image", WINDOW_AUTOSIZE);
imshow("Original Image", image);
imshow("New Image", new_image);
waitKey();
return 0;
}
说明
- 我们首先创建参数来保存用户要输入的和\ beta:αβ
double alpha = 1.0; /*< Simple contrast control */
int beta = 0; /*< Simple brightness control */
- 我们使用cv :: imread加载图像并将其保存在Mat对象中:
String imageName("../data/lena.jpg"); // by default
if (argc > 1)
{
imageName = argv[1];
}
Mat image = imread( imageName );
- 现在,由于我们会对这个图像进行一些转换,所以我们需要一个新的Mat对象来存储它。此外,我们希望这具有以下功能:
- 初始像素值等于零
- 与原始图像相同的大小和类型
Mat new_image = Mat :: zeros(image.size(),image.type());
我们观察到cv :: Mat :: zeros返回基于image.size()和image.type()的Matlab风格的零初始化器,
-
现在,要执行我们将访问图像中的每个像素。由于我们使用BGR图像,我们将每像素(B,G和R)有三个值,因此我们也将分别访问它们。这是代码片段:g(i,j)=α⋅f(i,j)+β
for( int y = 0; y < image.rows; y++ ) { for( int x = 0; x < image.cols; x++ ) { for( int c = 0; c < 3; c++ ) { new_image.at<Vec3b>(y,x)[c] = saturate_cast<uchar>( alpha*( image.at<Vec3b>(y,x)[c] ) + beta ); } } }
请注意以下事项:
- 初始像素值等于零
- 与原始图像相同的大小和类型
-
最后,我们创建窗口并显示图像,通常的方式。
-
namedWindow("Original Image", WINDOW_AUTOSIZE); namedWindow("New Image", WINDOW_AUTOSIZE); imshow("Original Image", image); imshow("New Image", new_image); waitKey();
注意
而不是使用for循环访问每个像素,我们可以简单地使用这个命令:
image.convertTo(new_image,-1,alpha,beta);
其中cv :: Mat :: convertTo将有效地执行* new_image = a * image + beta *。但是,我们想告诉你如何访问每个像素。在任何情况下,两种方法都给出相同的结果,但是convertTo是更优化的,并且工作得更快。
结果
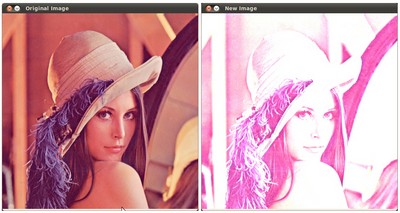
运行我们的代码并使用和\ beta = 50α=2.2β=50
$ ./BasicLinearTransforms lena.jpg
Basic Linear Transforms
-------------------------
* Enter the alpha value [1.0-3.0]: 2.2
* Enter the beta value [0-100]: 50
我们得到这个:
实际例子
在本段中,我们将通过调整图像的亮度和对比度来实践我们学到的来校正曝光不足的图像。我们还将看到另一种技术来校正称为伽马校正的图像的亮度。
亮度和对比度调整
增加(/减少)值将为每个像素添加(/减)一个常量值。像素值超出[0; 255]范围将饱和(即像素值高于(/小于255)(/ 0)将被钳位到255(/ 0))。β
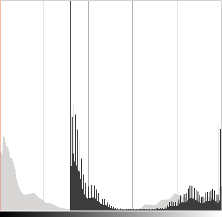
在浅灰色,原始图像的直方图,在深灰色当亮度= 80在Gimp
直方图表示每个颜色级别具有该颜色级别的像素数。黑暗的图像将具有许多具有低颜色值的像素,因此直方图将在其左部分呈现峰值。当添加恒定偏差时,直方图向右移动,因为我们向所有像素添加了一个恒定的偏置。
该参数将修改水平如何传播。如果\ alpha <1,颜色级别将被压缩,结果将是对比度较小的图像。αα<1
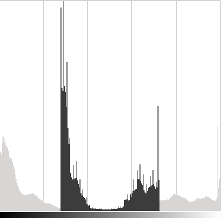
在浅灰色,原始图像的直方图,在Gimp中对比度<0时,呈深灰色
请注意,这些直方图是使用Gimp软件中的“亮度 - 对比度”工具获得的。亮度工具应该与偏置参数相同,但是对比度工具似乎与\ alpha增益不同,其中输出范围似乎以Gimp为中心(您可以注意到先前的直方图)。βα
可以发现,使用偏置可以提高亮度,但是同时,由于对比度会降低,图像会出现轻微的面纱。该\阿尔法收益可以用来diminue这种效果,但由于饱和,我们将失去原有的明亮区域的一些细节。βα
伽玛矫正
伽马校正可以用于通过使用输入值和映射的输出值之间的非线性变换来校正图像的亮度:
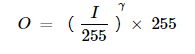
由于该关系是非线性的,因此对于所有像素的效果将不同,并且将取决于它们的原始值。
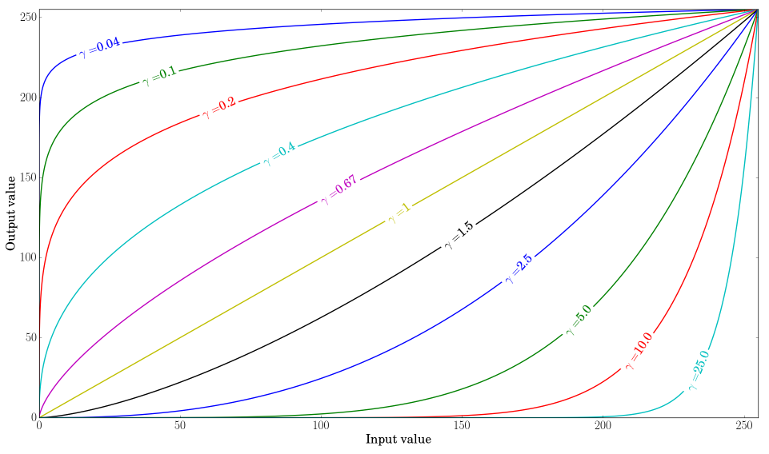
绘制不同的伽玛值
当,原始的暗区域会更亮,直方图将向右移动,而\ gamma> 1则会相反。γ<1γ>1
更正曝光不足的图像
以下图像已更正:和\ beta = 40。α=1.3β=40

维基百科,自由的百科全书[CC BY-SA 3.0]
整体亮度得到改善,但您可以注意到,由于实施的数字饱和度,云彩现在已经饱和了(突出显示拍摄中的剪辑)。
以下图像已更正:。γ=0.4

维基百科,自由的百科全书[CC BY-SA 3.0]
伽马校正应倾向于增加较少的饱和效应,因为映射是非线性的,并且没有像以前的方法那样的数值饱和。

左:直方图alpha,β校正; 中心:原始图像的直方图; 右:伽马校正后的直方图
上图比较了三个图像的直方图(三个直方图之间的y范围是不一样的)。您可以注意到,大多数像素值位于原始图像的直方图的较低部分。在,更正后,由于饱和度以及右侧的偏移,我们可以在255观察到一个高峰。在伽马校正之后,直方图向右移动,但是暗区域中的像素比明亮区域中的像素更大偏移(参见伽马曲线图)。αβ
在本教程中,您已经看到了两种简单的方法来调整图像的对比度和亮度。它们是基本技术,不用于替代光栅图形编辑器!
Code
本教程的代码在这里。伽马校正代码:
Mat LookUpTable(1,256,CV_8U);
uchar * p = lookUpTable.ptr();
for(int i = 0; i <256; ++ i)
p [i] = saturate_cast <uchar>(pow(i / 255.0,gamma_)* 255.0);
Mat res = img.clone();
LUT(img,lookUpTable,res);
查询表用于提高计算性能,因为只需要计算256个值。
额外的资源
OpenCV基本绘图
目标
在本教程中,您将学习如何:
- 使用cv :: Point定义图像中的2D点。
- 使用cv :: Scalar,为什么它是有用的
- 画一条线使用OpenCV的函数CV ::线
- 画一个椭圆利用OpenCV的功能CV ::椭圆形
- 绘制一个矩形,使用OpenCV的功能CV ::矩形
- 画一个圆圈使用OpenCV的功能CV ::圈
- 使用OpenCV函数cv :: fillPoly绘制一个填充的多边形
OpenCV理论
对于本教程,我们将大量使用两个结构:cv :: Point和cv :: Scalar:
Point
它表示由其图像坐标和指定的2D点。我们可以将其定义为:xy
Point pt;
pt.x = 10;
pt.y = 8;
or
Point pt = Point(10,8);
Scalar
- 代表一个4元素的向量。Scalar类型广泛用于OpenCV中,用于传递像素值。
- 在本教程中,我们将广泛使用它来表示BGR颜色值(3个参数)。如果不使用最后一个参数,则无需定义最后一个参数。
- 让我们看一个例子,如果我们被要求一个颜色参数,我们给出:
Scalar( a, b, c )
我们将定义一个BGR颜色,如:Blue = a,Green = b和Red = c
Code
#include <opencv2/core.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
#define w 400
using namespace cv;
void MyEllipse( Mat img, double angle );
void MyFilledCircle( Mat img, Point center );
void MyPolygon( Mat img );
void MyLine( Mat img, Point start, Point end );
int main( void ){
char atom_window[] = "Drawing 1: Atom";
char rook_window[] = "Drawing 2: Rook";
Mat atom_image = Mat::zeros( w, w, CV_8UC3 );
Mat rook_image = Mat::zeros( w, w, CV_8UC3 );
MyEllipse( atom_image, 90 );
MyEllipse( atom_image, 0 );
MyEllipse( atom_image, 45 );
MyEllipse( atom_image, -45 );
MyFilledCircle( atom_image, Point( w/2, w/2) );
MyPolygon( rook_image );
rectangle( rook_image,
Point( 0, 7*w/8 ),
Point( w, w),
Scalar( 0, 255, 255 ),
FILLED,
LINE_8 );
MyLine( rook_image, Point( 0, 15*w/16 ), Point( w, 15*w/16 ) );
MyLine( rook_image, Point( w/4, 7*w/8 ), Point( w/4, w ) );
MyLine( rook_image, Point( w/2, 7*w/8 ), Point( w/2, w ) );
MyLine( rook_image, Point( 3*w/4, 7*w/8 ), Point( 3*w/4, w ) );
imshow( atom_window, atom_image );
moveWindow( atom_window, 0, 200 );
imshow( rook_window, rook_image );
moveWindow( rook_window, w, 200 );
waitKey( 0 );
return(0);
}
void MyEllipse( Mat img, double angle )
{
int thickness = 2;
int lineType = 8;
ellipse( img,
Point( w/2, w/2 ),
Size( w/4, w/16 ),
angle,
0,
360,
Scalar( 255, 0, 0 ),
thickness,
lineType );
}
void MyFilledCircle( Mat img, Point center )
{
circle( img,
center,
w/32,
Scalar( 0, 0, 255 ),
FILLED,
LINE_8 );
}
void MyPolygon( Mat img )
{
int lineType = LINE_8;
Point rook_points[1][20];
rook_points[0][0] = Point( w/4, 7*w/8 );
rook_points[0][1] = Point( 3*w/4, 7*w/8 );
rook_points[0][2] = Point( 3*w/4, 13*w/16 );
rook_points[0][3] = Point( 11*w/16, 13*w/16 );
rook_points[0][4] = Point( 19*w/32, 3*w/8 );
rook_points[0][5] = Point( 3*w/4, 3*w/8 );
rook_points[0][6] = Point( 3*w/4, w/8 );
rook_points[0][7] = Point( 26*w/40, w/8 );
rook_points[0][8] = Point( 26*w/40, w/4 );
rook_points[0][9] = Point( 22*w/40, w/4 );
rook_points[0][10] = Point( 22*w/40, w/8 );
rook_points[0][11] = Point( 18*w/40, w/8 );
rook_points[0][12] = Point( 18*w/40, w/4 );
rook_points[0][13] = Point( 14*w/40, w/4 );
rook_points[0][14] = Point( 14*w/40, w/8 );
rook_points[0][15] = Point( w/4, w/8 );
rook_points[0][16] = Point( w/4, 3*w/8 );
rook_points[0][17] = Point( 13*w/32, 3*w/8 );
rook_points[0][18] = Point( 5*w/16, 13*w/16 );
rook_points[0][19] = Point( w/4, 13*w/16 );
const Point* ppt[1] = { rook_points[0] };
int npt[] = { 20 };
fillPoly( img,
ppt,
npt,
1,
Scalar( 255, 255, 255 ),
lineType );
}
void MyLine( Mat img, Point start, Point end )
{
int thickness = 2;
int lineType = LINE_8;
line( img,
start,
end,
Scalar( 0, 0, 0 ),
thickness,
lineType );
}
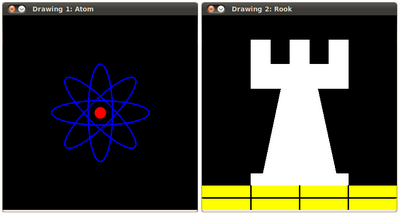
说明
- 由于我们计划绘制两个例子(an atom and a rook),我们必须创建两个图像和两个窗口来显示它们。
char atom_window[] = "Drawing 1: Atom";
char rook_window[] = "Drawing 2: Rook";
Mat atom_image = Mat::zeros( w, w, CV_8UC3 );
Mat rook_image = Mat::zeros( w, w, CV_8UC3 );
- 我们创建了绘制不同几何形状的功能。例如,为了绘制原子,我们使用MyEllipse和MyFilledCircle:
MyEllipse( atom_image, 90 );
MyEllipse( atom_image, 0 );
MyEllipse( atom_image, 45 );
MyEllipse( atom_image, -45 );
MyFilledCircle( atom_image, Point( w/2, w/2) );
- 并提请我们所使用的车MYLINE,矩形和MyPolygon:
MyPolygon( rook_image );
rectangle( rook_image,
Point( 0, 7*w/8 ),
Point( w, w),
Scalar( 0, 255, 255 ),
FILLED,
LINE_8 );
MyLine( rook_image, Point( 0, 15*w/16 ), Point( w, 15*w/16 ) );
MyLine( rook_image, Point( w/4, 7*w/8 ), Point( w/4, w ) );
MyLine( rook_image, Point( w/2, 7*w/8 ), Point( w/2, w ) );
MyLine( rook_image, Point( 3*w/4, 7*w/8 ), Point( 3*w/4, w ) );
- 我们来检查一下这些功能的内容:
MYLINE
void MyLine( Mat img, Point start, Point end )
{
int thickness = 2;
int lineType = LINE_8;
line( img,
start,
end,
Scalar( 0, 0, 0 ),
thickness,
lineType );
}
我们可以看到,MyLine只是调用函数cv :: line,它执行以下操作:
- 从点开始到点结束绘制一条线
- 该行显示在图像img中
- 线颜色由Scalar(0,0,0)定义,它是与Black相对应的RGB值
- 线厚度设定为厚度(在这种情况下为2)
- 线是8连接线(lineType = 8)
MyEllipse
void MyEllipse( Mat img, double angle )
{
int thickness = 2;
int lineType = 8;
ellipse( img,
Point( w/2, w/2 ),
Size( w/4, w/16 ),
angle,
0,
360,
Scalar( 255, 0, 0 ),
thickness,
lineType );
}
从上面的代码,我们可以看到函数cv :: ellipse绘制一个椭圆,使得:
- 椭圆显示在图像img中
- 椭圆中心位于(w / 2,w / 2)的点,并且被包围在大小为(w / 4,w / 16)
- 椭圆旋转角度
- 椭圆延伸0到360度之间的圆弧
- 图中的颜色将为标量(255,0,0),表示BGR值为蓝色。
- 椭圆的厚度为2。
MyFilledCircle
void MyFilledCircle( Mat img, Point center )
{
circle( img,
center,
w/32,
Scalar( 0, 0, 255 ),
FILLED,
LINE_8 );
}
类似于椭圆函数,我们可以观察到圆接 作为参数:
- 将显示圆圈的图像(img)
- 圆的中心表示为点中心
- 圆的半径:w / 32
- 圆的颜色:标量(0,0,255),表示BGR中的红色
- 由于厚度 = -1,圆将被绘制填充。
MyPolygon
void MyPolygon( Mat img )
{
int lineType = LINE_8;
Point rook_points[1][20];
rook_points[0][0] = Point( w/4, 7*w/8 );
rook_points[0][1] = Point( 3*w/4, 7*w/8 );
rook_points[0][2] = Point( 3*w/4, 13*w/16 );
rook_points[0][3] = Point( 11*w/16, 13*w/16 );
rook_points[0][4] = Point( 19*w/32, 3*w/8 );
rook_points[0][5] = Point( 3*w/4, 3*w/8 );
rook_points[0][6] = Point( 3*w/4, w/8 );
rook_points[0][7] = Point( 26*w/40, w/8 );
rook_points[0][8] = Point( 26*w/40, w/4 );
rook_points[0][9] = Point( 22*w/40, w/4 );
rook_points[0][10] = Point( 22*w/40, w/8 );
rook_points[0][11] = Point( 18*w/40, w/8 );
rook_points[0][12] = Point( 18*w/40, w/4 );
rook_points[0][13] = Point( 14*w/40, w/4 );
rook_points[0][14] = Point( 14*w/40, w/8 );
rook_points[0][15] = Point( w/4, w/8 );
rook_points[0][16] = Point( w/4, 3*w/8 );
rook_points[0][17] = Point( 13*w/32, 3*w/8 );
rook_points[0][18] = Point( 5*w/16, 13*w/16 );
rook_points[0][19] = Point( w/4, 13*w/16 );
const Point* ppt[1] = { rook_points[0] };
int npt[] = { 20 };
fillPoly( img,
ppt,
npt,
1,
Scalar( 255, 255, 255 ),
lineType );
}
要绘制一个填充的多边形,我们使用函数cv :: fillPoly。我们注意到:
- 多边形将在img上绘制
- 多边形的顶点是ppt中的一组点
- 要绘制的顶点总数为npt
- 要绘制的多边形的数量只有1
- 多边形的颜色由Scalar(255,255,255)定义,它是白色的BGR值
rectangle
rectangle( rook_image,
Point( 0, 7*w/8 ),
Point( w, w),
Scalar( 0, 255, 255 ),
FILLED,
LINE_8 );
最后我们有cv :: rectangle函数(我们没有为这个人创建一个特殊的函数)。我们注意到:
- 矩形将在rook_image上绘制
- 矩形的两个相对顶点由点(0,7 * w / 8)和点(w,w)**定义
- 矩形的颜色由Scalar(0,255,255)给出,它是黄色的BGR值
- 由于厚度值由FILLED(-1)给出,矩形将被填充。
结果
编译和运行你的程序应该给你一个这样的结果:
随机生成器和OpenCV文本
目标
在本教程中,您将学习如何:
- 使用随机数生成器类(cv :: RNG)以及如何从均匀分布中获取随机数。
- 使用函数cv :: putText在OpenCV窗口中显示文本
Code
- 在前面的教程(基本绘图)中,我们绘制了不同的几何图形,作为输入参数,如坐标(以cv :: Point的形式),颜色,厚度等。您可能已经注意到,我们给出了这些参数的特定值。
- 在本教程中,我们打算为绘图参数使用随机值。此外,我们打算用大量的几何图形填充我们的形象。由于我们将以随机的方式对它们进行初始化,所以这个过程将是自动的,并且使用循环。
- 此代码位于您的OpenCV示例文件夹中。否则你可以从这里抓住它
说明
- 我们首先检查主要功能。我们观察到,我们首先做的是创建一个随机数生成器对象(RNG):
RNG rng( 0xFFFFFFFF );
RNG实现一个随机数生成器。在本例中,rng是以0xFFFFFFFF值初始化的RNG元素
- 然后我们创建一个初始化为零的矩阵(这意味着它将显示为黑色),指定其高度,宽度和类型:
Mat image = Mat :: zeros(window_height,window_width,CV_8UC3);
imshow(window_name,image);
- 然后我们继续画疯狂的东西。看看代码后,可以看到它主要分为8个部分,定义为函数:
c = Drawing_Random_Lines(image,window_name,rng);
if(c!= 0)return 0;
c = Drawing_Random_Rectangles(image,window_name,rng);
if(c!= 0)return 0;
c = Drawing_Random_Ellipses(image,window_name,rng);
if(c!= 0)return 0;
c = Drawing_Random_Polylines(image,window_name,rng);
if(c!= 0)return 0;
c = Drawing_Random_Filled_Polygons(image,window_name,rng);
if(c!= 0)return 0;
c = Drawing_Random_Circles(image,window_name,rng);
if(c!= 0)return 0;
c = Displaying_Random_Text(image,window_name,rng);
if(c!= 0)return 0;
c = Displaying_Big_End(image,window_name,rng);
所有这些功能都遵循相同的模式,因此我们将仅分析其中的一些功能,因为同样的解释适用于所有的功能。
- 检出函数Drawing_Random_Lines:
int Drawing_Random_Lines( Mat image, char* window_name, RNG rng )
{
int lineType = 8;
Point pt1, pt2;
for( int i = 0; i < NUMBER; i++ )
{
pt1.x = rng.uniform( x_1, x_2 );
pt1.y = rng.uniform( y_1, y_2 );
pt2.x = rng.uniform( x_1, x_2 );
pt2.y = rng.uniform( y_1, y_2 );
line( image, pt1, pt2, randomColor(rng), rng.uniform(1, 10), 8 );
imshow( window_name, image );
if( waitKey( DELAY ) >= 0 )
{ return -1; }
}
return 0;
}
- 我们可以看到以下内容:
- 该用于循环将重复NUMBER次。由于函数cv :: line在该循环内,这意味着将生成NUMBER行。
- 线极值由pt1和pt2给出。对于pt1,我们可以看到:
pt1.x = rng.uniform(x_1,x_2);
pt1.y = rng.uniform(y_1,y_2);
-
我们知道rng是一个随机数生成器对象。在上面的代码中,我们调用rng.uniform(a,b)。这产生了值a和b之间的随机均匀分布(包括在a中,排除在b中)。
-
从上面的解释,我们推导出极值pt1和pt2将是随机值,所以线位置将是非常不可预测的,给出一个很好的视觉效果(查看下面的结果部分)。
-
另外观察一下,我们注意到在
cv :: line
参数中,输入颜色:
randomColor(RNG)
我们来看看功能的实现:
static Scalar randomColor( RNG& rng )
{
int icolor = (unsigned) rng;
return Scalar( icolor&255, (icolor>>8)&255, (icolor>>16)&255 );
}
我们可以看到,返回值是具有3个随机初始化值的标量,它被用作线颜色的R,G和B参数。因此,线条的颜色也是随机的!
- 上面的说明适用于生成圆,椭圆,多边形等的其他函数。中心和顶点等参数也随机生成。
- 在完成之前,我们还应该看看Display_Random_Text和Displaying_Big_End的功能,因为它们都有一些有趣的功能:
- Display_Random_Text:
int Displaying_Random_Text( Mat image, char* window_name, RNG rng )
{
int lineType = 8;
for ( int i = 1; i < NUMBER; i++ )
{
Point org;
org.x = rng.uniform(x_1, x_2);
org.y = rng.uniform(y_1, y_2);
putText( image, "Testing text rendering", org, rng.uniform(0,8),
rng.uniform(0,100)*0.05+0.1, randomColor(rng), rng.uniform(1, 10), lineType);
imshow( window_name, image );
if( waitKey(DELAY) >= 0 )
{ return -1; }
}
return 0;
}
一切看起来很熟悉,但表达式:
putText(image,“testing text rendering”,org,rng.uniform(0,8),
rng.uniform(0,100)* 0.05 + 0.1,randomColor(rng),rng.uniform(1,10),lineType);
那么函数cv :: putText是做什么的呢?在我们的例子中:
- 绘制文本“测试文本渲染”在图像中
- 文本的左下角将位于Point org中
- 字体类型是一个随机整数值,范围为:。[0,8>
- 字体的大小由表达式rng.uniform(0,100)x0.05 + 0.1表示(表示其范围为 0.1,5.1 ][0.1,5.1>
- 文本颜色是随机的(由randomColor(rng)表示))
- 文本厚度范围介于1到10之间,由rng.uniform(1,10)
因此,我们将在随机位置获得(分析其他绘图功能)NUMBER个文本在我们的图像上。
- Displaying_Big_End
int Displaying_Big_End( Mat image, char* window_name, RNG rng )
{
Size textsize = getTextSize("OpenCV forever!", FONT_HERSHEY_COMPLEX, 3, 5, 0);
Point org((window_width - textsize.width)/2, (window_height - textsize.height)/2);
int lineType = 8;
Mat image2;
for( int i = 0; i < 255; i += 2 )
{
image2 = image - Scalar::all(i);
putText( image2, "OpenCV forever!", org, FONT_HERSHEY_COMPLEX, 3,
Scalar(i, i, 255), 5, lineType );
imshow( window_name, image2 );
if( waitKey(DELAY) >= 0 )
{ return -1; }
}
return 0;
}
除了函数getTextSize(获取参数文本的大小)之外,我们可以观察到的新操作在foor循环中:
image2 = image - Scalar :: all(i)
所以,image2是图像和Scalar :: all(i)的减法。事实上,这里发生的一切是,image2的每个像素都将减去图像的每个像素减去i的值(记住,对于每个像素,我们考虑三个值,如R,G和B,因此每个像素会受到影响)
还要记住,减法运算总是在内部执行饱和运算,这意味着获得的结果将始终在允许的范围内(对于我们的示例,不会为负值,在0到255之间)。
结果
正如您刚才在“代码”部分所看到的,程序将依次执行不同的绘图功能,这将产生:
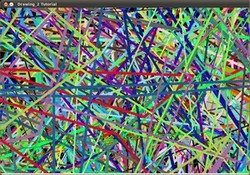
- 首先,一个随机的NUMBER行将出现在屏幕上,如可以在这个屏幕截图中看到的:

- 然后,一组新的数字,这些时间矩形将跟随。
- 现在将出现一些椭圆,其中每个都有随机位置,大小,厚度和弧长:

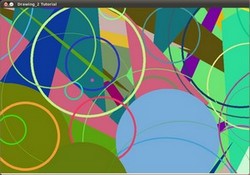
- 现在,具有03段的折线将出现在屏幕上,再次以随机配置。
- 填充的多边形(在此示例中为三角形)将跟随。
- 最后几何图形出现:圈子!
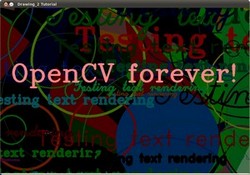
- 接近尾声,文字“测试文字呈现”将以各种字体,大小,颜色和位置出现。
- 而大端(也是这样表达了一个大道理):
OpenCV离散傅里叶变换
目标
我们会为以下问题寻求答案:
- 什么是傅里叶变换,为什么要使用?
- 在OpenCV中怎么做?
- 函数的使用如:cv :: copyMakeBorder(),cv :: merge(),cv :: dft(),cv :: getOptimalDFTSize(),cv :: log()和cv :: normalize()。
源代码
您可以从这里下载,也可以在samples/cpp/tutorial_code/core/discrete_fourier_transform/discrete_fourier_transform.cppOpenCV源代码库中找到它。
以下是cv :: dft()的示例用法:
#include "opencv2/core.hpp"
2 #include "opencv2/imgproc.hpp"
3 #include "opencv2/imgcodecs.hpp"
4 #include "opencv2/highgui.hpp"
5
6 #include <iostream>
7
8 using namespace cv;
9 using namespace std;
10
11 static void help(char* progName)
12 {
13 cout << endl
14 << "This program demonstrated the use of the discrete Fourier transform (DFT). " << endl
15 << "The dft of an image is taken and it's power spectrum is displayed." << endl
16 << "Usage:" << endl
17 << progName << " [image_name -- default ../data/lena.jpg] " << endl << endl;
18 }
19
20 int main(int argc, char ** argv)
21 {
22 help(argv[0]);
23
24 const char* filename = argc >=2 ? argv[1] : "../data/lena.jpg";
25
26 Mat I = imread(filename, IMREAD_GRAYSCALE);
27 if( I.empty())
28 return -1;
29
30 Mat padded; //expand input image to optimal size
31 int m = getOptimalDFTSize( I.rows );
32 int n = getOptimalDFTSize( I.cols ); // on the border add zero values
33 copyMakeBorder(I, padded, 0, m - I.rows, 0, n - I.cols, BORDER_CONSTANT, Scalar::all(0));
34
35 Mat planes[] = {Mat_<float>(padded), Mat::zeros(padded.size(), CV_32F)};
36 Mat complexI;
37 merge(planes, 2, complexI); // Add to the expanded another plane with zeros
38
39 dft(complexI, complexI); // this way the result may fit in the source matrix
40
41 // compute the magnitude and switch to logarithmic scale
42 // => log(1 + sqrt(Re(DFT(I))^2 + Im(DFT(I))^2))
43 split(complexI, planes); // planes[0] = Re(DFT(I), planes[1] = Im(DFT(I))
44 magnitude(planes[0], planes[1], planes[0]);// planes[0] = magnitude
45 Mat magI = planes[0];
46
47 magI += Scalar::all(1); // switch to logarithmic scale
48 log(magI, magI);
49
50 // crop the spectrum, if it has an odd number of rows or columns
51 magI = magI(Rect(0, 0, magI.cols & -2, magI.rows & -2));
52
53 // rearrange the quadrants of Fourier image so that the origin is at the image center
54 int cx = magI.cols/2;
55 int cy = magI.rows/2;
56
57 Mat q0(magI, Rect(0, 0, cx, cy)); // Top-Left - Create a ROI per quadrant
58 Mat q1(magI, Rect(cx, 0, cx, cy)); // Top-Right
59 Mat q2(magI, Rect(0, cy, cx, cy)); // Bottom-Left
60 Mat q3(magI, Rect(cx, cy, cx, cy)); // Bottom-Right
61
62 Mat tmp; // swap quadrants (Top-Left with Bottom-Right)
63 q0.copyTo(tmp);
64 q3.copyTo(q0);
65 tmp.copyTo(q3);
66
67 q1.copyTo(tmp); // swap quadrant (Top-Right with Bottom-Left)
68 q2.copyTo(q1);
69 tmp.copyTo(q2);
70
71 normalize(magI, magI, 0, 1, NORM_MINMAX); // Transform the matrix with float values into a
72 // viewable image form (float between values 0 and 1).
73
74 imshow("Input Image" , I ); // Show the result
75 imshow("spectrum magnitude", magI);
76 waitKey();
77
78 return 0;
79 }
说明
傅立叶变换将图像分解为其窦道和余弦分量。换句话说,它会将图像从其空间域转换到其频域。这个想法是任何函数可以用无限窦和余弦函数的和来精确地近似。傅立叶变换是一种如何做到这一点的方法。数学上二维图像傅立叶变换是:
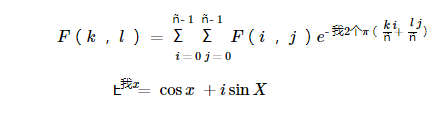
这里f是其空间域中的图像值,在其频域中是F。转换的结果是复数。可以通过实际图像和复杂图像或通过幅度和相位图像来显示这一点。然而,在整个图像处理算法中,只有幅面图像很有趣,因为它包含了我们所需要的关于图像几何结构的所有信息。然而,如果您打算以这些形式对图像进行一些修改,那么您需要重新转换它,您将需要保留这两种形式。
在本例中,我将展示如何计算和显示傅立叶变换的幅度图像。在数字图像是离散的情况下。这意味着它们可以占用给定域值的值。例如,在基本的灰度图像中,值通常在0和255之间。因此,傅里叶变换也需要是离散傅里叶变换,导致离散傅里叶变换(DFT)。当您需要从几何角度确定图像的结构时,您将需要使用它。以下是要遵循的步骤(在灰度输入图像I的情况下):
**
**
- 将图像展开至最佳尺寸。DFT的性能取决于图像大小。对于数字二,三和五的倍数,图像尺寸趋向于最快。因此,为了获得最大的性能,通常最好将边框值填充到图像以获得具有这种特征的大小。该品种:: getOptimalDFTSize()返回这个最佳规模,我们可以使用CV :: copyMakeBorder()函数来扩大图像的边界:
Mat padded; //expand input image to optimal size
int m = getOptimalDFTSize( I.rows );
int n = getOptimalDFTSize( I.cols ); // on the border add zero pixels
copyMakeBorder(I, padded, 0, m - I.rows, 0, n - I.cols, BORDER_CONSTANT, Scalar::all(0));
附加的像素被初始化为零。
- 为复杂和真实的价值取得成就。傅里叶变换的结果是复杂的。这意味着对于每个图像值,结果是两个图像值(每个分量一个)。此外,频域范围远远大于其空间对应物。因此,我们通常至少以浮动格式存储它们。因此,我们将把我们的输入图像转换为这种类型,并用另一个通道来展开,以保持复杂的值:
Mat planes[] = {Mat_<float>(padded), Mat::zeros(padded.size(), CV_32F)};
Mat complexI;
merge(planes, 2, complexI); // Add to the expanded another plane with zeros
- 进行离散傅里叶变换。可能的就地计算(与输出相同的输入):
dft(complexI, complexI); // this way the result may fit in the source matrix
- 将真实和复杂的值转化为大小。复数具有真实(Re)和复数(虚数Im)部分。DFT的结果是复数。DFT的大小是:
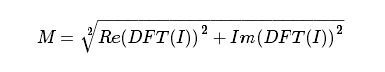
翻译为OpenCV代码:
split(complexI, planes); // planes[0] = Re(DFT(I), planes[1] = Im(DFT(I))
magnitude(planes[0], planes[1], planes[0]);// planes[0] = magnitude
Mat magI = planes[0];
- 切换到对数刻度。原来,傅里叶系数的动态范围太大,无法显示在屏幕上。我们有一些小而高的变化值,我们不能这样观察。因此,高价值将全部作为白点,而小的则为黑色。为了将灰度值用于可视化,我们可以将我们的线性比例变换为对数:
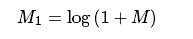
翻译为OpenCV代码:
magI += Scalar::all(1); // switch to logarithmic scale
log(magI, magI);
- 作物和重新排列。记住,在第一步,我们扩大了形象?那么现在是摒弃新推出的价值观的时候了。为了可视化的目的,我们还可以重新排列结果的象限,使原点(零,零)对应于图像中心。
magI = magI(Rect(0, 0, magI.cols & -2, magI.rows & -2));
int cx = magI.cols/2;
int cy = magI.rows/2;
Mat q0(magI, Rect(0, 0, cx, cy)); // Top-Left - Create a ROI per quadrant
Mat q1(magI, Rect(cx, 0, cx, cy)); // Top-Right
Mat q2(magI, Rect(0, cy, cx, cy)); // Bottom-Left
Mat q3(magI, Rect(cx, cy, cx, cy)); // Bottom-Right
Mat tmp; // swap quadrants (Top-Left with Bottom-Right)
q0.copyTo(tmp);
q3.copyTo(q0);
tmp.copyTo(q3);
q1.copyTo(tmp); // swap quadrant (Top-Right with Bottom-Left)
q2.copyTo(q1);
tmp.copyTo(q2);
- 规范化。这再次为可视化目的而完成。我们现在有这样的大小,但是这仍然是我们的图像显示范围从零到一。我们使用cv :: normalize()函数将值归一化到此范围。
normalize(magI, magI, 0, 1, NORM_MINMAX); // Transform the matrix with float values into a
// viewable image form (float between values 0 and 1).
结果
应用程序的想法将是确定图像中存在的几何取向。例如,让我们来看一下文本是否是横向的?看一些文字你会注意到,文本行的形式也是水平线,字母形成垂直线。在傅里叶变换的情况下,也可以看到文本片段的这两个主要组成部分。让我们使用这个水平和这个旋转的图像关于一个文本。
在水平文本的情况下:

在旋转文本的情况下:

您可以看到频域中最有影响力的组件(幅度图像上最亮点)遵循图像上对象的几何旋转。由此,我们可以计算偏移量并执行图像旋转以纠正最终的错误对准。
OpenCV文件输入和输出使用XML和YAML文件
目标
您会找到以下问题的答案:
- 如何使用YAML或XML文件打印和读取文本和OpenCV文本条目?
- OpenCV数据结构如何做同样的操作?
- 如何为您的数据结构做这个?
- OpenCV数据结构的使用,如cv :: FileStorage,cv :: FileNode或cv :: FileNodeIterator。
源代码
您可以从这里下载,也可以在samples/cpp/tutorial_code/core/file_input_output/file_input_output.cppOpenCV源代码库中找到它。
以下是如何实现目标列表中枚举的所有内容的示例代码。
#include <opencv2/core.hpp>
#include <iostream>
#include <string>
using namespace cv;
using namespace std;
static void help(char** av)
{
cout << endl
<< av[0] << " shows the usage of the OpenCV serialization functionality." << endl
<< "usage: " << endl
<< av[0] << " outputfile.yml.gz" << endl
<< "The output file may be either XML (xml) or YAML (yml/yaml). You can even compress it by "
<< "specifying this in its extension like xml.gz yaml.gz etc... " << endl
<< "With FileStorage you can serialize objects in OpenCV by using the << and >> operators" << endl
<< "For example: - create a class and have it serialized" << endl
<< " - use it to read and write matrices." << endl;
}
class MyData
{
public:
MyData() : A(0), X(0), id()
{}
explicit MyData(int) : A(97), X(CV_PI), id("mydata1234") // explicit to avoid implicit conversion
{}
void write(FileStorage& fs) const //Write serialization for this class
{
fs << "{" << "A" << A << "X" << X << "id" << id << "}";
}
void read(const FileNode& node) //Read serialization for this class
{
A = (int)node["A"];
X = (double)node["X"];
id = (string)node["id"];
}
public: // Data Members
int A;
double X;
string id;
};
//These write and read functions must be defined for the serialization in FileStorage to work
static void write(FileStorage& fs, const std::string&, const MyData& x)
{
x.write(fs);
}
static void read(const FileNode& node, MyData& x, const MyData& default_value = MyData()){
if(node.empty())
x = default_value;
else
x.read(node);
}
// This function will print our custom class to the console
static ostream& operator<<(ostream& out, const MyData& m)
{
out << "{ id = " << m.id << ", ";
out << "X = " << m.X << ", ";
out << "A = " << m.A << "}";
return out;
}
int main(int ac, char** av)
{
if (ac != 2)
{
help(av);
return 1;
}
string filename = av[1];
{ //write
Mat R = Mat_<uchar>::eye(3, 3),
T = Mat_<double>::zeros(3, 1);
MyData m(1);
FileStorage fs(filename, FileStorage::WRITE);
fs << "iterationNr" << 100;
fs << "strings" << "["; // text - string sequence
fs << "image1.jpg" << "Awesomeness" << "../data/baboon.jpg";
fs << "]"; // close sequence
fs << "Mapping"; // text - mapping
fs << "{" << "One" << 1;
fs << "Two" << 2 << "}";
fs << "R" << R; // cv::Mat
fs << "T" << T;
fs << "MyData" << m; // your own data structures
fs.release(); // explicit close
cout << "Write Done." << endl;
}
{//read
cout << endl << "Reading: " << endl;
FileStorage fs;
fs.open(filename, FileStorage::READ);
int itNr;
//fs["iterationNr"] >> itNr;
itNr = (int) fs["iterationNr"];
cout << itNr;
if (!fs.isOpened())
{
cerr << "Failed to open " << filename << endl;
help(av);
return 1;
}
FileNode n = fs["strings"]; // Read string sequence - Get node
if (n.type() != FileNode::SEQ)
{
cerr << "strings is not a sequence! FAIL" << endl;
return 1;
}
FileNodeIterator it = n.begin(), it_end = n.end(); // Go through the node
for (; it != it_end; ++it)
cout << (string)*it << endl;
n = fs["Mapping"]; // Read mappings from a sequence
cout << "Two " << (int)(n["Two"]) << "; ";
cout << "One " << (int)(n["One"]) << endl << endl;
MyData m;
Mat R, T;
fs["R"] >> R; // Read cv::Mat
fs["T"] >> T;
fs["MyData"] >> m; // Read your own structure_
cout << endl
<< "R = " << R << endl;
cout << "T = " << T << endl << endl;
cout << "MyData = " << endl << m << endl << endl;
//Show default behavior for non existing nodes
cout << "Attempt to read NonExisting (should initialize the data structure with its default).";
fs["NonExisting"] >> m;
cout << endl << "NonExisting = " << endl << m << endl;
}
cout << endl
<< "Tip: Open up " << filename << " with a text editor to see the serialized data." << endl;
return 0;
}
说明
这里我们仅谈论XML和YAML文件输入。您的输出(及其相应的输入)文件可能只有这些扩展中的一个和结构来自此。它们是可以序列化的两种数据结构:映射(如STL映射)和元素序列(如STL向量)。这些之间的区别是,在地图中,每个元素都有一个唯一的名称,通过您可以访问它。对于序列,您需要通过它们查询特定项目。
- XML / YAML文件打开和关闭。在将任何内容写入此类文件之前,您需要将其打开并结束关闭。OpenCV中的XML / YAML数据结构是cv :: FileStorage。要指定文件在硬盘驱动器上绑定的结构,您可以使用其构造函数或open()函数:
string filename = "I.xml";
FileStorage fs(filename, FileStorage::WRITE);
//...
fs.open(filename, FileStorage::READ);
您使用第二个参数中的任何一个是一个常数,指定您可以在其上执行的操作类型:WRITE,READ或APPEND。文件名中指定的扩展名也可以确定要使用的输出格式。如果指定扩展名,例如* .xml.gz *,输出可能会被压缩。
当cv :: FileStorage对象被销毁时,文件会自动关闭。但是,您可以使用发布功能显式地调用此功能:
fs.release(); // explicit close
- 文本和数字的输入和输出。数据结构使用与STL库相同的<<输出运算符。为了输出任何类型的数据结构,我们首先需要指定其名称。我们只需打印出这个名称即可。对于基本类型,您可以使用值的打印符号:
fs << “iterationNr” << 100;
读入是一个简单的寻址(通过[]操作符)和转换操作或通过>>操作符读取:
int itNr;
fs["iterationNr"] >> itNr;
itNr = (int) fs["iterationNr"];
- OpenCV数据结构的输入/输出。那么这些行为就像基本的C ++类型一样:
Mat R = Mat_<uchar >::eye (3, 3),
T = Mat_<double>::zeros(3, 1);
fs << "R" << R; // Write cv::Mat
fs << "T" << T;
fs["R"] >> R; // Read cv::Mat
fs["T"] >> T;
- 向量(数组)和关联图的输入/输出。如前所述,我们可以输出地图和序列(数组,向量)。再次,我们首先打印变量的名称,然后我们必须指定我们的输出是序列还是地图。
对于第一个元素之前的序列打印“[”字符,最后一个“]”字符后:
fs << "strings" << "["; // text - string sequence
fs << "image1.jpg" << "Awesomeness" << "baboon.jpg";
fs << "]"; // close sequence
对于地图,钻头是一样的,现在我们使用“{”和“}”分隔符:
fs << "Mapping"; // text - mapping
fs << "{" << "One" << 1;
fs << "Two" << 2 << "}";
要读取这些,我们使用cv :: FileNode和cv :: FileNodeIterator数据结构。cv :: FileStorage类的[]运算符返回一个cv :: FileNode数据类型。如果节点是顺序的,我们可以使用cv :: FileNodeIterator遍历项目:
FileNode n = fs["strings"]; // Read string sequence - Get node
if (n.type() != FileNode::SEQ)
{
cerr << "strings is not a sequence! FAIL" << endl;
return 1;
}
FileNodeIterator it = n.begin(), it_end = n.end(); // Go through the node
for (; it != it_end; ++it)
cout << (string)*it << endl;
对于地图,您可以再次使用[]运算符来访问给定项目(或>>运算符):
n = fs["Mapping"]; // Read mappings from a sequence
cout << "Two " << (int)(n["Two"]) << "; ";
cout << "One " << (int)(n["One"]) << endl << endl;
- 读写自己的数据结构。假设你有一个数据结构,如:
class MyData
{
public:
MyData() : A(0), X(0), id() {}
public: // Data Members
int A;
double X;
string id;
};
通过OpenCV I / O XML / YAML接口(就像OpenCV数据结构一样),可以通过在类中添加一个读取和写入函数来对其进行序列化。对于内部:
void write(FileStorage& fs) const //Write serialization for this class
{
fs << "{" << "A" << A << "X" << X << "id" << id << "}";
}
void read(const FileNode& node) //Read serialization for this class
{
A = (int)node["A"];
X = (double)node["X"];
id = (string)node["id"];
}
那么你需要在类之外添加以下函数定义:
void write(FileStorage& fs, const std::string&, const MyData& x)
{
x.write(fs);
}
void read(const FileNode& node, MyData& x, const MyData& default_value = MyData())
{
if(node.empty())
x = default_value;
else
x.read(node);
}
在这里您可以看到,在阅读部分中,我们定义了如果用户尝试读取不存在的节点会发生什么。在这种情况下,我们只返回默认的初始化值,但是更详细的解决方案是返回一个对象ID的减号值。
一旦添加了这四个函数,就可以使用>>操作符进行写操作,而<<操作符用于读取:
MyData m(1);
fs << "MyData" << m; // your own data structures
fs["MyData"] >> m; // Read your own structure_
或尝试阅读一个不存在的阅读:
fs["NonExisting"] >> m; // Do not add a fs << "NonExisting" << m command for this to work
cout << endl << "NonExisting = " << endl << m << endl;
结果
主要是我们打印出定义的数字。您可以在控制台的屏幕上看到:
Write Done.
Reading:
100image1.jpg
Awesomeness
baboon.jpg
Two 2; One 1
R = [1, 0, 0;
0, 1, 0;
0, 0, 1]
T = [0; 0; 0]
MyData =
{ id = mydata1234, X = 3.14159, A = 97}
Attempt to read NonExisting (should initialize the data structure with its default).
NonExisting =
{ id = , X = 0, A = 0}
Tip: Open up output.xml with a text editor to see the serialized data.
不过,输出xml文件中可能会看到的更有趣:
<?xml version="1.0"?>
<opencv_storage>
<iterationNr>100</iterationNr>
<strings>
image1.jpg Awesomeness baboon.jpg</strings>
<Mapping>
<One>1</One>
<Two>2</Two></Mapping>
<R type_id="opencv-matrix">
<rows>3</rows>
<cols>3</cols>
<dt>u</dt>
<data>
1 0 0 0 1 0 0 0 1</data></R>
<T type_id="opencv-matrix">
<rows>3</rows>
<cols>1</cols>
<dt>d</dt>
<data>
0. 0. 0.</data></T>
<MyData>
<A>97</A>
<X>3.1415926535897931e+000</X>
<id>mydata1234</id></MyData>
</opencv_storage>
或YAML文件:
%YAML:1.0
iterationNr: 100
strings:
- "image1.jpg"
- Awesomeness
- "baboon.jpg"
Mapping:
One: 1
Two: 2
R: !!opencv-matrix
rows: 3
cols: 3
dt: u
data: [ 1, 0, 0, 0, 1, 0, 0, 0, 1 ]
T: !!opencv-matrix
rows: 3
cols: 1
dt: d
data: [ 0., 0., 0. ]
MyData:
A: 97
X: 3.1415926535897931e+000
id: mydata1234
与OpenCV 1的互操作性
目标
对于OpenCV开发团队来说,不断改进库是很重要的。我们一直在思考可以缓解工作流程的方法,同时保持库的灵活性。新的C ++接口是我们的一个发展,服务于这个目标。然而,向后兼容仍然很重要。我们不想打破为早期版本的OpenCV库编写的代码。因此,我们确保添加了一些处理此功能的功能。在下面你会学到:
- 与其第一个版本相比,使用该库的方式与OpenCV的版本2发生了什么变化
- 如何向图像添加一些高斯噪声
- 什么是查找表,为什么使用它们?
General
在进行切换时,首先需要了解有关图像的新数据结构:Mat - Basic Image Container,这取代了旧的CvMat和IplImage。切换到新功能更容易。你只需要记住几件新事物。
OpenCV 2收到重组。所有的功能不再被压缩到一个库中。我们有很多模块,每个模块都包含与某些任务相关的数据结构和功能。这样,如果您仅使用OpenCV的一个子集,则不需要运送大型库。这意味着你也应该只包括你将使用的标题。例如
#include < opencv2 / core.hpp >
#include < opencv2 / imgproc.hpp >
#include < opencv2 / highgui.hpp >
所有与OpenCV相关的内容都放在cv命名空间中,以避免与其他库数据结构和函数的名称冲突。因此,您需要在来自OpenCV的所有内容之前或之后添加cv ::关键字,只需添加一个使用此指令的指令即可:
using namespace cv; // The new C++ interface API is inside this namespace. Import it.
因为这些函数已经在命名空间中,所以不需要在它们的名称中包含cv前缀。因此,所有新的C ++兼容功能都没有这个,它们遵循骆驼案例命名规则。这意味着第一个字母很小(除非是像Canny这样的名字),后续的单词将以大写字母(如copyMakeBorder)开头。
现在,请记住,您需要链接到应用程序所有使用的模块,如果您在Windows上使用DLL系统,您将需要再次添加所有二进制文件的路径。有关更多深入的信息,如果您在Windows上阅读如何使用OpenCV在“Microsoft Visual Studio”和Linux中构建应用程序,使用OpenCV与Eclipse(插件CDT)一起解释了一个示例用法。
现在转换Mat对象可以使用IplImage或CvMat操作符。在C界面中,您曾经在这里使用指针,不再是这样。在C ++界面中,我们主要使用Mat对象。这些对象可以通过简单的赋值自由转换为IplImage和CvMat。例如:
Mat I;
IplImage pI = I;
CvMat mI = I;
现在,如果你想要指针,转换就会变得更复杂一些。编译器不能再自动确定您想要什么,并且您需要明确指定您的目标。这是调用IplImage和CvMat操作符,然后获取它们的指针。为了得到指针,我们使用&sign:
Mat I;
IplImage* pI = &I.operator IplImage();
CvMat* mI = &I.operator CvMat();
现在,你的基础知识做了这里的一个例子,将C接口与C++的用法。您需要弄清楚什么时候可以安全释放未使用的对象,并确保在程序完成之前这样做,否则您可能会遇到麻烦的记忆韭菜。要解决OpenCV中的这个问题,引入了一种智能指针。当它不再使用时,它将自动释放对象。要使用它,将该指针声明为Ptr的专业化:
Ptr<IplImage> piI = &I.operator IplImage();
从C数据结构到Mat的转换是通过将这些内容传递给它的构造函数来实现的。例如:
Mat K(piL),L;
L = Mat(pI);
案例研究
现在,您在这里完成的基础是将C接口的使用与C ++的使用相结合的示例。您还将在OpenCV源代码库的示例目录中找到它samples/cpp/tutorial_code/core/interoperability_with_OpenCV_1/interoperability_with_OpenCV_1.cpp。为了进一步帮助看到差异,程序支持两种模式:一种混合C和C ++和一种纯C ++。如果您定义了DEMO_MIXED_API_USE,则最终将使用第一个。程序分离色平面,对它们进行一些修改,最终将它们合并在一起。
#include <iostream>
#include <opencv2/imgproc.hpp>
#include "opencv2/imgcodecs.hpp"
#include <opencv2/highgui.hpp>
using namespace cv; // The new C++ interface API is inside this namespace. Import it.
using namespace std;
// comment out the define to use only the latest C++ API
#define DEMO_MIXED_API_USE
#ifdef DEMO_MIXED_API_USE
# include <opencv2/highgui/highgui_c.h>
# include <opencv2/imgcodecs/imgcodecs_c.h>
#endif
int main( int argc, char** argv )
{
help(argv[0]);
const char* imagename = argc > 1 ? argv[1] : "../data/lena.jpg";
#ifdef DEMO_MIXED_API_USE
Ptr<IplImage> IplI(cvLoadImage(imagename)); // Ptr<T> is a safe ref-counting pointer class
if(!IplI)
{
cerr << "Can not load image " << imagename << endl;
return -1;
}
Mat I = cv::cvarrToMat(IplI); // Convert to the new style container. Only header created. Image not copied.
#else
Mat I = imread(imagename); // the newer cvLoadImage alternative, MATLAB-style function
if( I.empty() ) // same as if( !I.data )
{
cerr << "Can not load image " << imagename << endl;
return -1;
}
#endif
在这里,您可以观察到,使用新的结构,我们没有指针问题,尽管可以使用旧的函数,最终只是将结果转换为Mat对象。
// convert image to YUV color space. The output image will be created automatically.
Mat I_YUV;
cvtColor(I, I_YUV, COLOR_BGR2YCrCb);
vector<Mat> planes; // Use the STL's vector structure to store multiple Mat objects
split(I_YUV, planes); // split the image into separate color planes (Y U V)
因为,我们想要混淆我们首先从默认BGR转换为YUV颜色空间的图像亮度分量,然后将结果分割成单独的平面。这里的程序分裂:在第一个例子中,它使用OpenCV(C []运算符,迭代器,单个元素访问中的三种主要图像扫描算法之一来处理每个平面)。在第二个变体中,我们向图像添加一些高斯噪声,然后根据一些公式将信道混合在一起。
扫描版本如下所示:
// Mat scanning
// Method 1. process Y plane using an iterator
MatIterator_<uchar> it = planes[0].begin<uchar>(), it_end = planes[0].end<uchar>();
for(; it != it_end; ++it)
{
double v = *it * 1.7 + rand()%21 - 10;
*it = saturate_cast<uchar>(v*v/255);
}
for( int y = 0; y < I_YUV.rows; y++ )
{
// Method 2. process the first chroma plane using pre-stored row pointer.
uchar* Uptr = planes[1].ptr<uchar>(y);
for( int x = 0; x < I_YUV.cols; x++ )
{
Uptr[x] = saturate_cast<uchar>((Uptr[x]-128)/2 + 128);
// Method 3. process the second chroma plane using individual element access
uchar& Vxy = planes[2].at<uchar>(y, x);
Vxy = saturate_cast<uchar>((Vxy-128)/2 + 128);
}
}
在这里,您可以观察到,我们可以以三种方式浏览图像的所有像素:迭代器,C指针和单个元素访问样式。您可以在“ 如何使用OpenCV教程扫描图像,查找表格和时间测量”中阅读更深入的描述。从旧的函数名转换很容易。只需删除cv前缀并使用新的Mat数据结构。以下是使用加权加法函数的例子:
Mat noisyI(I.size(), CV_8U); // Create a matrix of the specified size and type
// Fills the matrix with normally distributed random values (around number with deviation off).
// There is also randu() for uniformly distributed random number generation
randn(noisyI, Scalar::all(128), Scalar::all(20));
// blur the noisyI a bit, kernel size is 3x3 and both sigma's are set to 0.5
GaussianBlur(noisyI, noisyI, Size(3, 3), 0.5, 0.5);
const double brightness_gain = 0;
const double contrast_gain = 1.7;
#ifdef DEMO_MIXED_API_USE
// To pass the new matrices to the functions that only work with IplImage or CvMat do:
// step 1) Convert the headers (tip: data will not be copied).
// step 2) call the function (tip: to pass a pointer do not forget unary "&" to form pointers)
IplImage cv_planes_0 = planes[0], cv_noise = noisyI;
cvAddWeighted(&cv_planes_0, contrast_gain, &cv_noise, 1, -128 + brightness_gain, &cv_planes_0);
#else
addWeighted(planes[0], contrast_gain, noisyI, 1, -128 + brightness_gain, planes[0]);
#endif
const double color_scale = 0.5;
// Mat::convertTo() replaces cvConvertScale.
// One must explicitly specify the output matrix type (we keep it intact - planes[1].type())
planes[1].convertTo(planes[1], planes[1].type(), color_scale, 128*(1-color_scale));
// alternative form of cv::convertScale if we know the datatype at compile time ("uchar" here).
// This expression will not create any temporary arrays ( so should be almost as fast as above)
planes[2] = Mat_<uchar>(planes[2]*color_scale + 128*(1-color_scale));
// Mat::mul replaces cvMul(). Again, no temporary arrays are created in case of simple expressions.
planes[0] = planes[0].mul(planes[0], 1./255);
您可能会看到,平面变量是Mat类型。然而,从Mat转换为IplImage是容易的,并使用简单的赋值运算符自动进行。
merge(planes, I_YUV); // now merge the results back
cvtColor(I_YUV, I, COLOR_YCrCb2BGR); // and produce the output RGB image
namedWindow("image with grain", WINDOW_AUTOSIZE); // use this to create images
#ifdef DEMO_MIXED_API_USE
// this is to demonstrate that I and IplI really share the data - the result of the above
// processing is stored in I and thus in IplI too.
cvShowImage("image with grain", IplI);
#else
imshow("image with grain", I); // the new MATLAB style function show
#endif
新的imshow highgui函数接受Mat和IplImage数据结构。编译并运行程序,如果下面的第一个图像是您的输入,您可以获得第一个或第二个输出:

您可以从这里下载源代码,或者samples/cpp/tutorial_code/core/interoperability_with_OpenCV_1/interoperability_with_OpenCV_1.cpp在OpenCV源代码库中找到它.
OpenCV中的英特尔®IPP异步C / C ++库
目标
本教程演示了使用OpenCV 的英特尔®IPP异步C / C ++库使用。下面的代码示例说明了使用英特尔®IPP异步C / C ++功能加速的Sobel操作的实现。在这个代码示例中,cv :: hpp :: getMat和cv :: hpp :: getHpp函数用于hppiMatrix和Mat矩阵之间的数据转换。
Code
您还可以在samples/cpp/tutorial_code/core/ippasync/ippasync_sample.cppOpenCV源文件的文件中找到源代码,或从这里下载。
#include <stdio.h>
#include "opencv2/core/utility.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
#include "cvconfig.h"
using namespace std;
using namespace cv;
#ifdef HAVE_IPP_A
#include "opencv2/core/ippasync.hpp"
#define CHECK_STATUS(STATUS, NAME)\
if(STATUS!=HPP_STATUS_NO_ERROR){ printf("%s error %d\n", NAME, STATUS);\
if (virtMatrix) {hppStatus delSts = hppiDeleteVirtualMatrices(accel, virtMatrix); CHECK_DEL_STATUS(delSts,"hppiDeleteVirtualMatrices");}\
if (accel) {hppStatus delSts = hppDeleteInstance(accel); CHECK_DEL_STATUS(delSts, "hppDeleteInstance");}\
return -1;}
#define CHECK_DEL_STATUS(STATUS, NAME)\
if(STATUS!=HPP_STATUS_NO_ERROR){ printf("%s error %d\n", NAME, STATUS); return -1;}
#endif
static void help()
{
printf("\nThis program shows how to use the conversion for IPP Async.\n"
"This example uses the Sobel filter.\n"
"You can use cv::Sobel or hppiSobel.\n"
"Usage: \n"
"./ipp_async_sobel [--camera]=<use camera,if this key is present>, \n"
" [--file_name]=<path to movie or image file>\n"
" [--accel]=<accelerator type: auto (default), cpu, gpu>\n\n");
}
const char* keys =
{
"{c camera | | use camera or not}"
"{fn file_name|../data/baboon.jpg | image file }"
"{a accel |auto | accelerator type: auto (default), cpu, gpu}"
};
//this is a sample for hppiSobel functions
int main(int argc, const char** argv)
{
help();
VideoCapture cap;
CommandLineParser parser(argc, argv, keys);
Mat image, gray, result;
#ifdef HAVE_IPP_A
hppiMatrix* src,* dst;
hppAccel accel = 0;
hppAccelType accelType;
hppStatus sts;
hppiVirtualMatrix * virtMatrix;
bool useCamera = parser.has("camera");
string file = parser.get<string>("file_name");
string sAccel = parser.get<string>("accel");
parser.printMessage();
if( useCamera )
{
printf("used camera\n");
cap.open(0);
}
else
{
printf("used image %s\n", file.c_str());
cap.open(file.c_str());
}
if( !cap.isOpened() )
{
printf("can not open camera or video file\n");
return -1;
}
accelType = sAccel == "cpu" ? HPP_ACCEL_TYPE_CPU:
sAccel == "gpu" ? HPP_ACCEL_TYPE_GPU:
HPP_ACCEL_TYPE_ANY;
//Create accelerator instance
sts = hppCreateInstance(accelType, 0, &accel);
CHECK_STATUS(sts, "hppCreateInstance");
accelType = hppQueryAccelType(accel);
sAccel = accelType == HPP_ACCEL_TYPE_CPU ? "cpu":
accelType == HPP_ACCEL_TYPE_GPU ? "gpu":
accelType == HPP_ACCEL_TYPE_GPU_VIA_DX9 ? "gpu dx9": "?";
printf("accelType %s\n", sAccel.c_str());
virtMatrix = hppiCreateVirtualMatrices(accel, 1);
for(;;)
{
cap >> image;
if(image.empty())
break;
cvtColor( image, gray, COLOR_BGR2GRAY );
result.create( image.rows, image.cols, CV_8U);
double execTime = (double)getTickCount();
//convert Mat to hppiMatrix
src = hpp::getHpp(gray,accel);
dst = hpp::getHpp(result,accel);
sts = hppiSobel(accel,src, HPP_MASK_SIZE_3X3,HPP_NORM_L1,virtMatrix[0]);
CHECK_STATUS(sts,"hppiSobel");
sts = hppiConvert(accel, virtMatrix[0], 0, HPP_RND_MODE_NEAR, dst, HPP_DATA_TYPE_8U);
CHECK_STATUS(sts,"hppiConvert");
// Wait for tasks to complete
sts = hppWait(accel, HPP_TIME_OUT_INFINITE);
CHECK_STATUS(sts, "hppWait");
execTime = ((double)getTickCount() - execTime)*1000./getTickFrequency();
printf("Time : %0.3fms\n", execTime);
imshow("image", image);
imshow("rez", result);
waitKey(15);
sts = hppiFreeMatrix(src);
CHECK_DEL_STATUS(sts,"hppiFreeMatrix");
sts = hppiFreeMatrix(dst);
CHECK_DEL_STATUS(sts,"hppiFreeMatrix");
}
if (!useCamera)
waitKey(0);
if (virtMatrix)
{
sts = hppiDeleteVirtualMatrices(accel, virtMatrix);
CHECK_DEL_STATUS(sts,"hppiDeleteVirtualMatrices");
}
if (accel)
{
sts = hppDeleteInstance(accel);
CHECK_DEL_STATUS(sts, "hppDeleteInstance");
}
printf("SUCCESS\n");
#else
printf("IPP Async not supported\n");
#endif
return 0;
}
说明
- 为OpenCV创建参数:
VideoCapture cap;
Mat image, gray, result;
和IPP异步:
hppiMatrix* src,* dst;
hppAccel accel = 0;
hppAccelType accelType;
hppStatus sts;
hppiVirtualMatrix * virtMatrix;
- 加载输入图像或视频。如何打开和读取视频流,您可以在视频输入中使用OpenCV和相似度测量教程。
if( useCamera )
{
printf("used camera\n");
cap.open(0);
}
else
{
printf("used image %s\n", file.c_str());
cap.open(file.c_str());
}
if( !cap.isOpened() )
{
printf("can not open camera or video file\n");
return -1;
}
- 使用hppCreateInstance创建加速器实例:
accelType = sAccel == "cpu" ? HPP_ACCEL_TYPE_CPU:
sAccel == "gpu" ? HPP_ACCEL_TYPE_GPU:
HPP_ACCEL_TYPE_ANY;
//Create accelerator instance
sts = hppCreateInstance(accelType, 0, &accel);
CHECK_STATUS(sts, "hppCreateInstance");
- 使用hppiCreateVirtualMatrices函数创建一个虚拟矩阵数组。
virtMatrix = hppiCreateVirtualMatrices(accel,1);
- 为输入和输出数据准备一个矩阵:
cap >> image;
if(image.empty())
break;
cvtColor( image, gray, COLOR_BGR2GRAY );
result.create( image.rows, image.cols, CV_8U);
- 使用cv :: hpp :: getHpp将Mat转换为hppiMatrix并调用hppiSobel函数。
//convert Mat to hppiMatrix
src = getHpp(gray, accel);
dst = getHpp(result, accel);
sts = hppiSobel(accel,src, HPP_MASK_SIZE_3X3,HPP_NORM_L1,virtMatrix[0]);
CHECK_STATUS(sts,"hppiSobel");
sts = hppiConvert(accel, virtMatrix[0], 0, HPP_RND_MODE_NEAR, dst, HPP_DATA_TYPE_8U);
CHECK_STATUS(sts,"hppiConvert");
// Wait for tasks to complete
sts = hppWait(accel, HPP_TIME_OUT_INFINITE);
CHECK_STATUS(sts, "hppWait");
我们使用hppiConvert,因为hppiSobel返回具有HPP_DATA_TYPE_8U类型的源矩阵的HPP_DATA_TYPE_16S数据类型的目标矩阵。每次调用IPP异步函数后,应该检查hppStatus。
- 创建窗口并显示图像,通常的方式。
imshow("image", image);
imshow("rez", result);
waitKey(15);
- 删除hpp矩阵。
sts = hppiFreeMatrix(src);
CHECK_DEL_STATUS(sts,“hppiFreeMatrix”);
sts = hppiFreeMatrix(dst);
CHECK_DEL_STATUS(sts,“hppiFreeMatrix”);
- 删除虚拟矩阵和加速器实例。
if (virtMatrix)
{
sts = hppiDeleteVirtualMatrices(accel, virtMatrix);
CHECK_DEL_STATUS(sts,"hppiDeleteVirtualMatrices");
}
if (accel)
{
sts = hppDeleteInstance(accel);
CHECK_DEL_STATUS(sts, "hppDeleteInstance");
}
结果
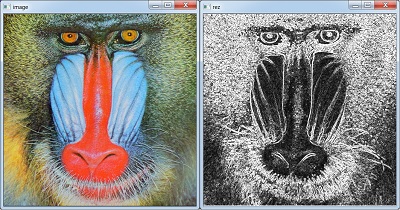
在编译上面的代码之后,我们可以执行它,给出图像或视频路径和加速器类型作为参数。对于本教程,我们使用baboon.png图像作为输入。结果如下。
如何使用OpenCV parallel_for_来并行化代码
目标
本教程的目的是向您展示如何使用OpenCV parallel_for_框架轻松并行化代码。为了说明这个概念,我们将编写一个程序来绘制一个利用几乎所有可用CPU负载的Mandelbrot集合。完整的教程代码在这里。如果您想要有关多线程的更多信息,则必须参考参考书或课程,因为本教程的目的是保持简单。
前提
第一个先决条件是使用OpenCV构建并行框架。在OpenCV 3.2中,以下并行框架按照以下顺序提供:
- 英特尔线程构建块(第三方库,应显式启用)
- C =并行C / C ++编程语言扩展(第三方库,应明确启用)
- OpenMP(集成到编译器,应该被显式启用)
- APPLE GCD(系统范围广,自动使用(仅限APPLE))
- Windows RT并发(系统范围,自动使用(仅Windows RT))
- Windows并发(运行时的一部分,自动使用(仅限Windows) - MSVC ++> = 10))
- Pthreads(如果有的话)
您可以看到,OpenCV库中可以使用多个并行框架。一些并行库是第三方库,必须在CMake(例如TBB,C =)中进行显式构建和启用,其他可以自动与平台(例如APPLE GCD)一起使用,但是您应该可以使用这些库来访问并行框架直接或通过启用CMake中的选项并重建库。
第二个(弱)前提条件与要实现的任务更相关,因为并不是所有的计算都是合适的/可以被平行地运行。为了保持简单,可以分解成多个基本操作而没有内存依赖性(无可能的竞争条件)的任务很容易并行化。计算机视觉处理通常易于并行化,因为大多数时间一个像素的处理不依赖于其他像素的状态。
简单的例子:绘制一个Mandelbrot集
我们将使用绘制Mandelbrot集的示例来显示如何从常规的顺序代码中轻松调整代码来平滑计算。
理论
Mandelbrot定义被数学家Adrien Douady命名为数学家Benoit Mandelbrot。它在数学领域以外是着名的,因为图像表示是一类分形的一个例子,一个表现出每个尺度显示的重复图案的数学集(甚至更多的是,Mandelbrot集是整体形状可以是自相似的反复看不同规模)。对于更深入的介绍,您可以查看相应的维基百科文章。在这里,我们将介绍公式来绘制Mandelbrot集(从维基百科的文章)。
Mandelbrot集是在二次映射迭代中的0的轨道的复平面中的的值的集合c
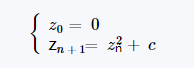
依然有限。也就是说,复数是Mandelbrot集的一部分,如果以z_0 = 0开始并重复应用迭代,则z_n的绝对值保持有界,然而大n得到。这也可以表示为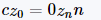
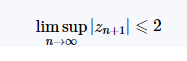
Pseudocode
用于生成Mandelbrot集合的表示的简单算法称为“逃逸时间算法”。对于渲染图像中的每个像素,如果复数在最大迭代次数下是有界的,则使用递归关系进行测试。不属于Mandelbrot集的像素将迅速逃脱,而我们假设像素在固定的最大迭代次数后位于集合中。迭代次数很高会产生更为详细的图像,但计算时间会相应增加。我们使用“转义”所需的迭代次数来描绘图像中的像素值。
For each pixel (Px, Py) on the screen, do:
{
x0 = scaled x coordinate of pixel (scaled to lie in the Mandelbrot X scale (-2, 1))
y0 = scaled y coordinate of pixel (scaled to lie in the Mandelbrot Y scale (-1, 1))
x = 0.0
y = 0.0
iteration = 0
max_iteration = 1000
while (x*x + y*y < 2*2 AND iteration < max_iteration) {
xtemp = x*x - y*y + x0
y = 2*x*y + y0
x = xtemp
iteration = iteration + 1
}
color = palette[iteration]
plot(Px, Py, color)
}
关于伪代码和理论之间的关系,我们有:
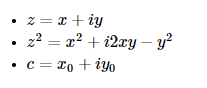
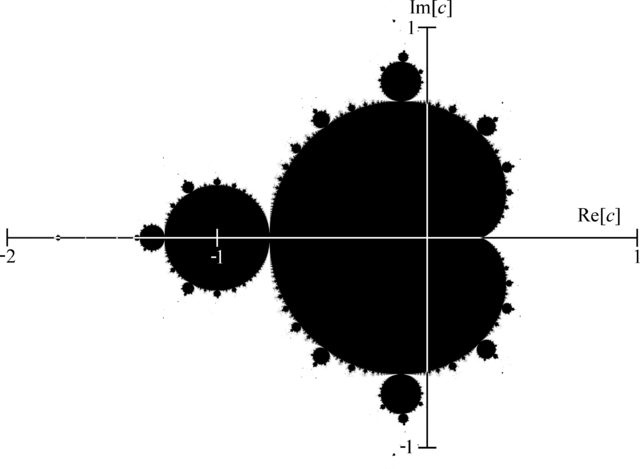
在这个数字上,我们记得一个复数的实部是在x轴和y轴上的虚部。如果我们放大特定位置,您可以看到整个形状可以反复显示。
履行
逃脱时间算法实现
int mandelbrot(const complex<float> &z0, const int max)
{
complex<float> z = z0;
for (int t = 0; t < max; t++)
{
if (z.real()*z.real() + z.imag()*z.imag() > 4.0f) return t;
z = z*z + z0;
}
return max;
}
在这里,我们使用std::complex模板类来表示一个复数。此函数执行测试以检查像素是否处于置位,并返回“转义”迭代。
顺序Mandelbrot实现
void sequentialMandelbrot(Mat &img, const float x1, const float y1, const float scaleX, const float scaleY)
{
for (int i = 0; i < img.rows; i++)
{
for (int j = 0; j < img.cols; j++)
{
float x0 = j / scaleX + x1;
float y0 = i / scaleY + y1;
complex<float> z0(x0, y0);
uchar value = (uchar) mandelbrotFormula(z0);
img.ptr<uchar>(i)[j] = value;
}
}
}
在这个实现中,我们依次迭代渲染图像中的像素,以执行测试以检查像素是否可能属于Mandelbrot集。
另一个要做的就是将像素坐标转换为Mandelbrot集空间:
Mat mandelbrotImg(4800, 5400, CV_8U);
float x1 = -2.1f, x2 = 0.6f;
float y1 = -1.2f, y2 = 1.2f;
float scaleX = mandelbrotImg.cols / (x2 - x1);
float scaleY = mandelbrotImg.rows / (y2 - y1);
最后,要将灰度值分配给像素,我们使用以下规则:
- 如果达到最大迭代次数(像素假定为Mandelbrot集合),则像素为黑色,
- 否则我们根据转义的迭代分配灰度值,并按比例缩放以适应灰度范围。
int mandelbrotFormula(const complex<float> &z0, const int maxIter=500) {
int value = mandelbrot(z0, maxIter);
if(maxIter - value == 0)
{
return 0;
}
return cvRound(sqrt(value / (float) maxIter) * 255);
}
使用线性尺度变换不足以感知灰度变化。为了克服这个问题,我们将通过使用平方根尺度转换(从他的博客文章中借鉴于Jeremy D. Frens )来提高感知:
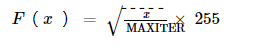
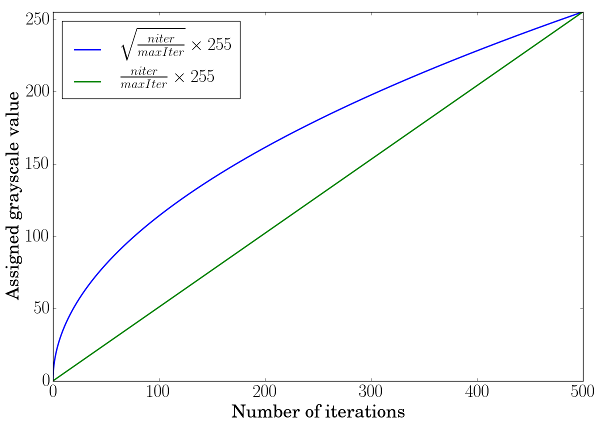
绿色曲线对应于简单的线性尺度变换,蓝色一到平方根尺度变换,您可以观察到在这些位置观察斜率时最低值将如何提升。
并行Mandelbrot实现
当看到顺序实现时,我们可以注意到每个像素是独立计算的。为了优化计算,我们可以通过利用现代处理器的多核架构并行执行多个像素计算。为了轻松实现,我们将使用OpenCV cv :: parallel_for_框架。
class ParallelMandelbrot : public ParallelLoopBody
{
public:
ParallelMandelbrot (Mat &img, const float x1, const float y1, const float scaleX, const float scaleY)
: m_img(img), m_x1(x1), m_y1(y1), m_scaleX(scaleX), m_scaleY(scaleY)
{
}
virtual void operator ()(const Range& range) const
{
for (int r = range.start; r < range.end; r++)
{
int i = r / m_img.cols;
int j = r % m_img.cols;
float x0 = j / m_scaleX + m_x1;
float y0 = i / m_scaleY + m_y1;
complex<float> z0(x0, y0);
uchar value = (uchar) mandelbrotFormula(z0);
m_img.ptr<uchar>(i)[j] = value;
}
}
ParallelMandelbrot& operator=(const ParallelMandelbrot &) {
return *this;
};
private:
Mat &m_img;
float m_x1;
float m_y1;
float m_scaleX;
float m_scaleY;
};
首先是声明一个继承自cv :: ParallelLoopBody并覆盖的自定义类virtual void operator ()(const cv::Range& range) const。
该范围operator ()表示将由单独线程处理的像素子集。这种分割是自动完成的,以平均分配计算负荷。我们必须将像素索引坐标转换为2D [row, col]坐标。另请注意,我们必须保留对mat图像的参考,以便能够原地修改图像。
并行执行调用:
ParallelMandelbrot parallelMandelbrot(mandelbrotImg,x1,y1,scaleX,scaleY);
parallel_for_(Range(0,mandelbrotImg.rows * mandelbrotImg.cols),parallelMandelbrot);
这里,范围表示要执行的操作的总数,因此图像中的像素总数。要设置线程数,可以使用:cv :: setNumThreads。您还可以使用cv :: parallel_for_中的nstripes参数指定拆分次数。例如,如果您的处理器有4个线程,则设置cv::setNumThreads(2)或设置nstripes=2应与默认值相同,它将使用所有可用的处理器线程,但将仅在两个线程上分割工作负载。
-
注意
C ++ 11标准允许通过摆脱
ParallelMandelbrot类并用lambda表达式来替换它来简化并行实现:
parallel_for_(Range(0, mandelbrotImg.rows*mandelbrotImg.cols), [&](const Range& range){
for (int r = range.start; r < range.end; r++)
{
int i = r / mandelbrotImg.cols;
int j = r % mandelbrotImg.cols;
float x0 = j / scaleX + x1;
float y0 = i / scaleY + y1;
complex<float> z0(x0, y0);
uchar value = (uchar) mandelbrotFormula(z0);
mandelbrotImg.ptr<uchar>(i)[j] = value;
}
});
结果
您可以在这里找到完整的教程代码。并行实现的性能取决于您拥有的CPU类型。例如,在4个内核/ 8个线程CPU上,您可以预期加速大约为6.9X。有很多因素可以解释为什么我们不能达到将近8倍的加速。主要原因主要是由于:
- 创建和管理线程的开销,
- 后台进程并行运行,
- 4个硬核之间的差异,每个核心有2个逻辑线程,8个硬件核心。
由教程代码生成的图像(您可以修改代码以使用更多迭代,并根据转义的迭代分配像素颜色,并使用调色板获得更多美学图像):

Mandelbrot设置为xMin = -2.1,xMax = 0.6,yMin = -1.2,yMax = 1.2,maxIterations = 500
标签:Mat,int,核心,image,OpenCV,模块,图像,cv From: https://www.cnblogs.com/L707/p/16998376.html