作者:vivo 互联网容器团队- Pan Liangbiao
本文根据潘良彪老师在“2022 vivo开发者大会"现场演讲内容整理而成。公众号回复【2022 VDC】获取互联网技术分会场议题相关资料。
2018年起,vivo以容器作为基础底座,打造了一站式云原生机器学习平台。向上支撑了算法中台,为算法工程师提供数据管理、模型训练、模型管理、模型部署等能力,为广告、推荐和搜索等业务赋能,成功为算法实现了降本、提效,让云原生和容器价值初露锋芒。基于机器学习平台的试点成果,经过算法场景的试点实践和价值分析,对内部战略做了升级。确定基于云原生理念去构建行业一流的容器生态,实现规模化的降本提效目标。
本文会详细介绍vivo在容器集群高可用建设中的具体实践,包括在容器集群高可用建设、容器集群自动化运维、容器平台架构升级、容器平台能力增强、容器生态打通等层面的打磨和建设。目前,vivo容器产品能力矩阵逐渐趋于完善,并将围绕全面容器化、拥抱云原生和在离线混部三个方向继续发力。
云原生和容器,是当下比较火热的话题,其中 Kubernetes更是成为容器编排领域的事实标准。
国内外各企业在内部落地云原生和容器的过程中,基于自己的业务场景和发展阶段,会遇到各种问题和挑战,本文是vivo在云原生容器领域的探索和落地实践,希望能对读者有一些借鉴和帮助。
一、容器技术和云原生理念
首先是容器技术和云原生理念的介绍。
1.1 容器技术简介
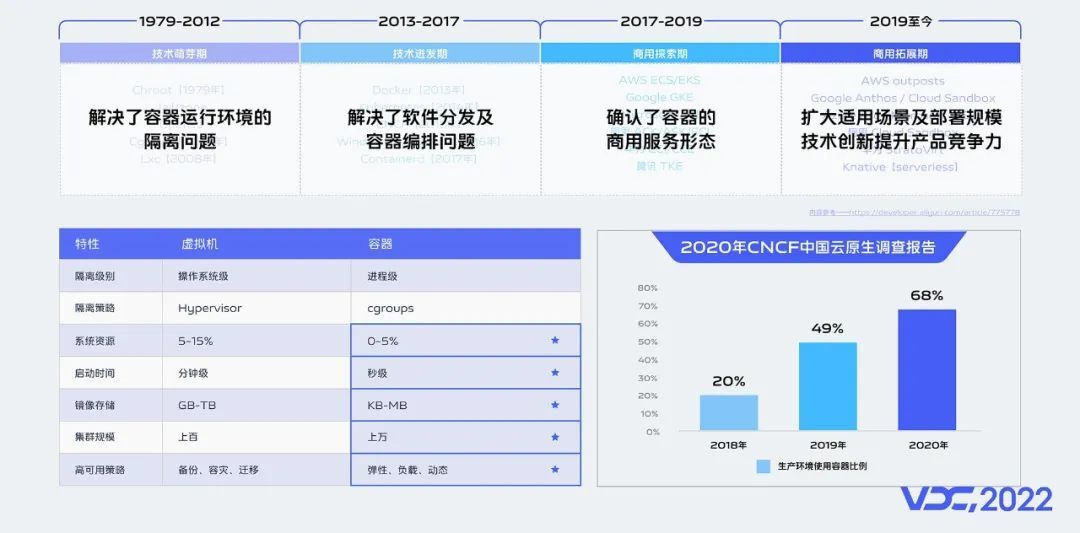
容器技术不是一个新技术,从1979年unix系统的chroot诞生到现在,历经40多年的发展,共经过了四个阶段,分别是:技术萌芽期、技术迸发期、商用探索期和商用拓展期。
每个阶段,解决了不同的技术问题,分别是:环境隔离、软件分发和编排、商用服务形态、规模化和场景拓展。
相比于虚拟机,容器技术少了一层虚拟操作系统的损耗,因此它比虚拟机具有更好的性能表现。另外容器在系统资源、启动时间、集群规模、高可用策略等方面,也有非常明显的优势。
2020年CNCF中国云原生调查报告显示,接受调查的中国企业,有68%已经在生产环境使用容器技术。
从行业发展看,不管是云厂商还是各大科技公司,都在基于容器技术构建自己的新一代基础架构,推动企业数字创新。容器技术已经得到广泛的认可和普及。
1.2 云原生理念介绍
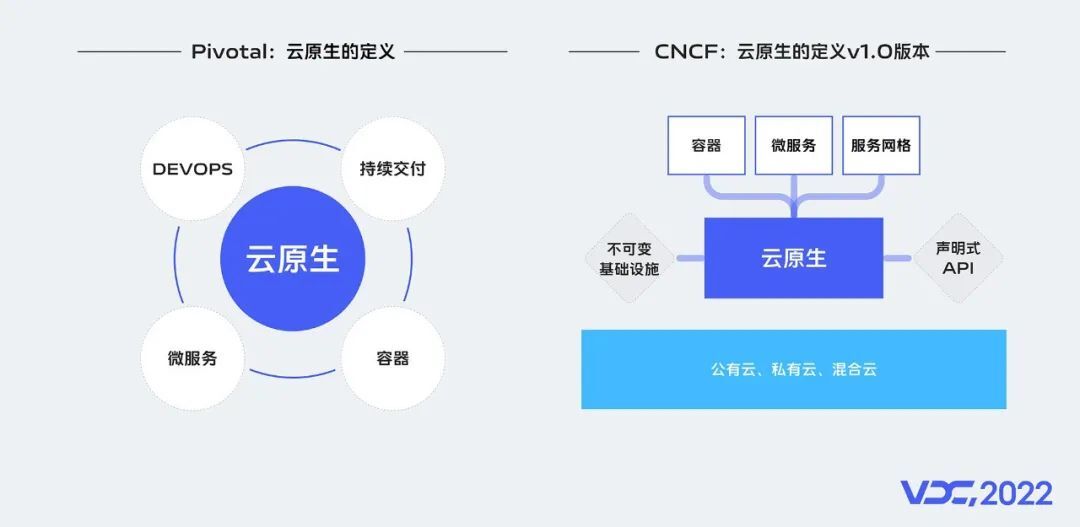
容器技术催生了云原生思潮,云原生生态推动了容器技术的发展。那么云原生的准确定义和含义是什么呢?
云原生其实没有标准定义,如果非要给他一个定义,行业有两种观点:
-
一个定义来自Pivotal 这家公司,它是云原生应用的提出者,是云原生的先驱者、探路者。Pivotal最新的官网对云原生的介绍有四个要点,分别是:DevOps、持续交付、微服务和容器。
-
另外一个定义来自CNCF,CNCF建立于2015年,它是一个开源组织,其存在的目的,是支持开源社区开发关键的云原生组件,包括 Kubernetes、Prometheus监控等。
它把云原生分为3种核心技术和2个核心理念:
-
3种核心技术:分别是容器、微服务、服务网格。
-
2个核心理念:分别指不可变基础设施和声明式API。
但是,不管是那一种定义,容器都是其基础,是云原生落地的核心技术手段。
1.3 云原生价值分析
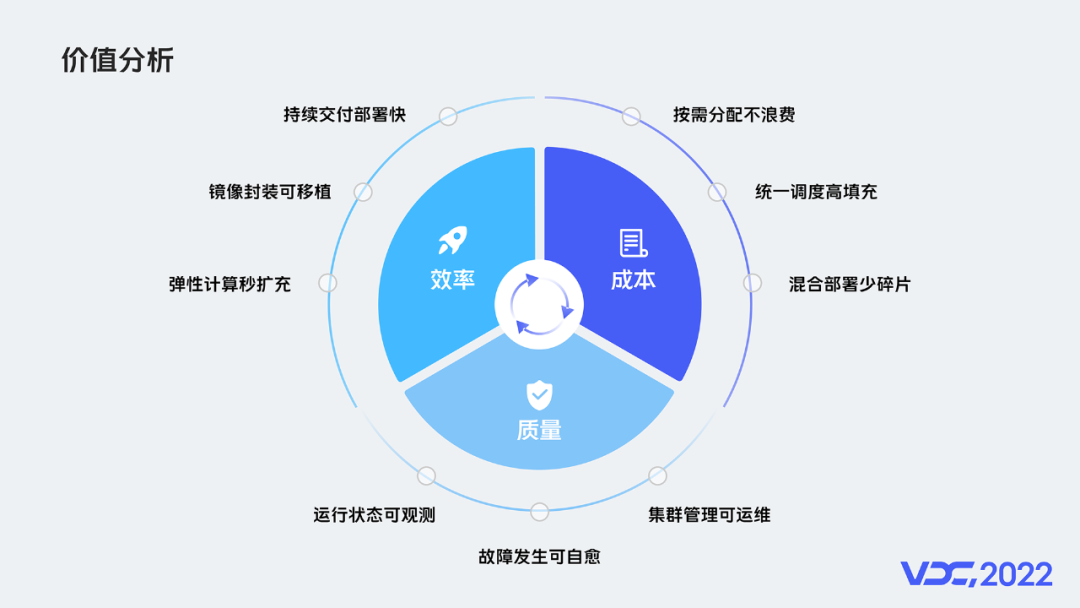
任何技术和理念,都必须有实际的业务价值。从效率、成本、质量三个维度,来分析云原生和容器的技术价值,可总结如下:
-
效率:可实现持续交付部署快、镜像封装可移植、弹性计算秒扩容。
-
成本:可实现按需分配不浪费、统一调度高填充、混合部署少碎片。
-
质量:可实现运行状态可观测、故障发生可自愈、集群管理可运维。
二、vivo 容器技术探索与实践
新技术的引入带来新的价值,也必然会引入新的问题,接下来介绍vivo在容器技术上的探索和实践。
2.1 试点探索
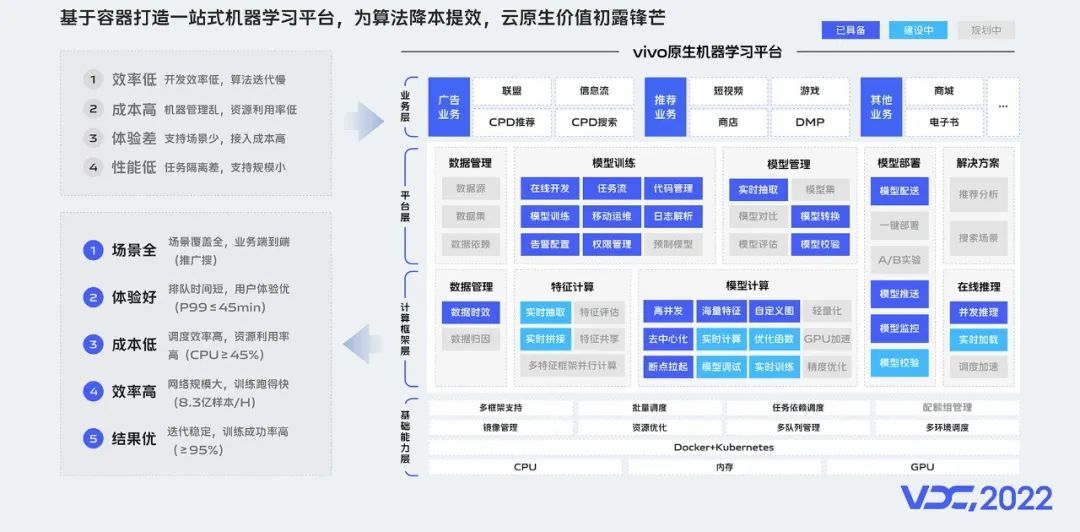
在vivo的算法场景中,机器学习平台负责算法模型迭代,是互联网算法业务中核心的一环,早期的平台基于传统的架构,在效率、成本、性能和体验上均有一定的不足,无法满足算法业务快速增长的诉求。基于此,我们首先在算法场景进行容器的试点探索。从2018年开始,我们以容器作为基础底座,打造了vivo的一站式云原生机器学习平台,向上支撑了公司的算法中台,为算法工程师提供数据管理、模型训练、模型管理、模型部署等能力,为广告、推荐和搜索等业务赋能。
vivo的云原生机器学习平台具备如下5大优势:
-
场景全:业务端到端,覆盖推荐、广告、搜索多场景。
-
体验好:排队时间短,用户体验优,任务P99排队时长小于45分钟。
-
成本低:调度能力好,资源利用率高,CPU利用率均值大于45%。
-
效率高:网络规模大,训练跑得快,训练速度8.3亿样本每小时。
-
结果优:算法迭代稳定,训练成功率高,训练成功率大于95%。
vivo云原生机器学习平台,成功为算法实现了降本、提效,让云原生和容器价值初露锋芒。
2.2 价值挖掘
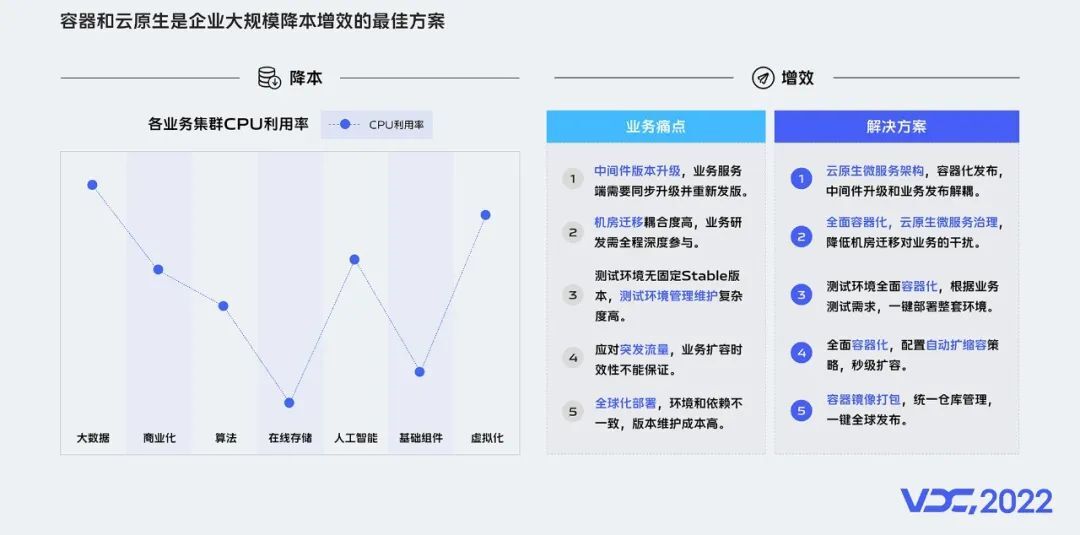
基于前面机器学习平台的试点成果,我们深入分析和挖掘容器和云原生的价值,结合vivo的情况,我们发现容器和云原生是企业大规模降本和提效的最佳方案。
1)在降本方面
当前我们内部服务器资源的利用率较低,以CPU利用率为例,当前vivo服务器整体利用率均值在25%左右,相比行业一流水平的40%~50%,还有不少的提升空间。
容器在资源隔离、统一调度和在离线混部等方面的优势,均是提升资源ROI的有效技术手段。
2)在提效方面
当前我们在中间件版本升级、机器迁移、测试环境管理、突发流量应对和全球化部署的环境一致性等方面均有业务痛点。
容器的快速交付、弹性自运维、微服务、服务网格等云原生技术和架构,则是提效的有力措施。
2.3 战略升级
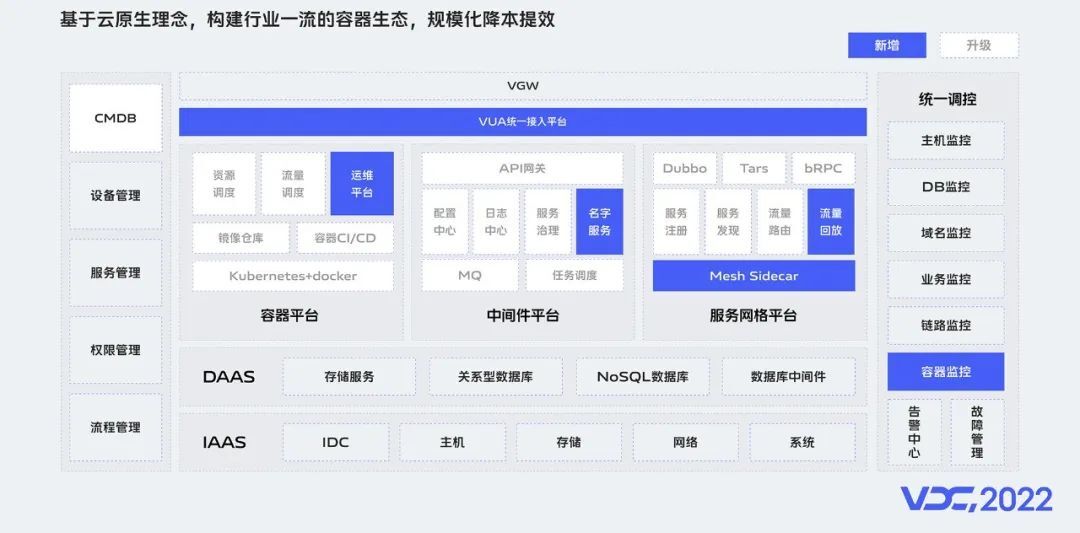
经过算法场景的试点实践和价值分析,我们对内部战略做了升级, 确定基于云原生理念去构建行业一流的容器生态,实现规模化的降本提效目标。
为了更好匹配战略落地,拥抱云原生,我们还对内部技术架构重新规划和升级,新增引入统一流量接入平台、容器运维管理平台、统一名字服务、容器监控等平台和能力,支撑容器生态在公司内部的全面建设和推广。
2.4 面临挑战
2.4.1 集群挑战
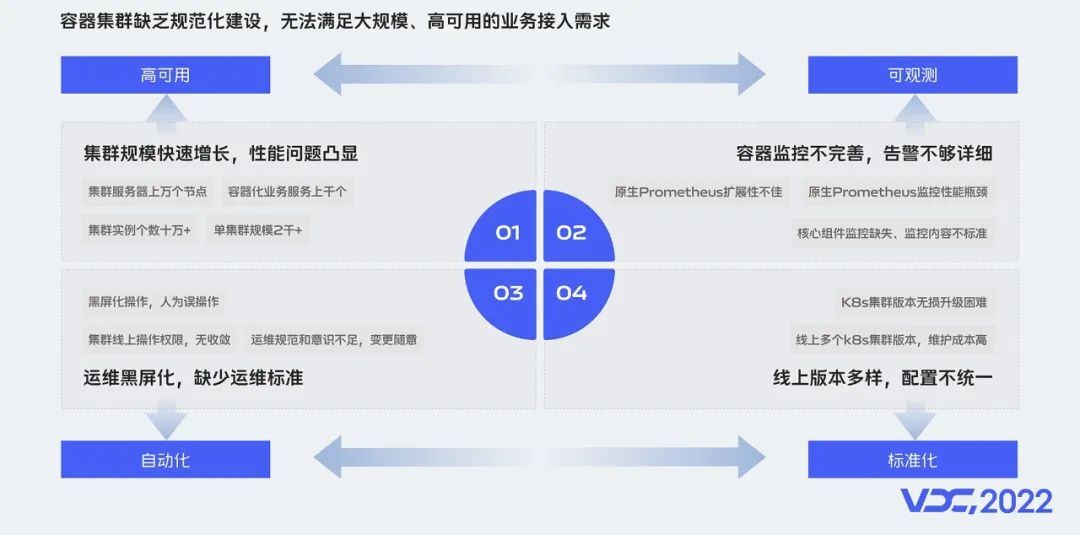
要提供大规模的生产可用的容器服务,容器集群的可用性首先会面临诸多挑战。下面介绍vivo容器化,在生产集群建设过程中遇到的4个比较大的挑战。
-
集群规模快速增长:vivo集群服务器规模上万个宿主机节点,管理的集群数十个,单集群规模2千+,实例数10万+,对集群性能和机器管理挑战极大。
-
集群运维、运营和标准化:由于早期集群管理不规范,黑屏化操作和人为误操作等问题层出不穷,集群运维人员每天因为各种救火忙得焦头烂额。
-
集群容器监控架构和可观测性:随着集群规模快速增长,容器的监控组件面临极大压力,对容器监控的采集、存储和展示,提出更高的要求。
-
线上K8s版本升级迭代:面对Kubernetes版本的快速迭代,需要实现给飞行的飞机换引擎。
针对挑战,我们的应对方案分别是:高可用、可观测、标准化和自动化。其中容器监控和k8s版本无损升级的挑战,vivo公众号有详细技术方案的介绍,本文侧重介绍集群高可用和运维自动化两部分。
2.4.2 平台挑战
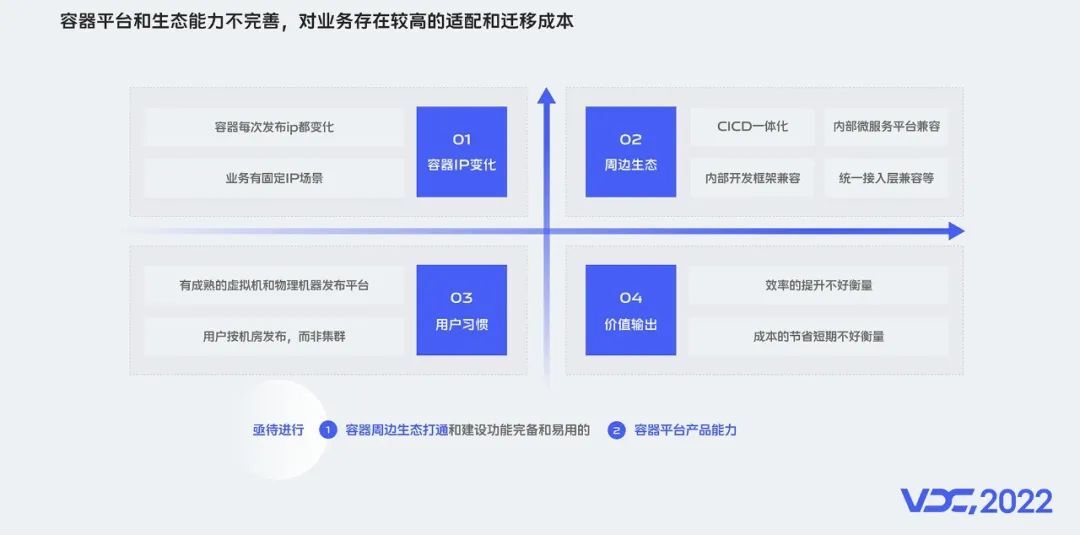
除了集群稳定性的挑战,平台也将面临各种挑战,由于容器平台和周边生态能力不完善,对业务存在较高的适配和迁移成本。总结起来我们遇到的挑战主要有4点:
-
容器IP的变化:k8s早期把业务都设计成无状态的,其原生实现是每次发布容器的IP都会变化,这对部分依赖固定IP的传统业务不太友好,业务改造成本较高。
-
周边生态的适配和兼容:包括发布系统、中间件微服务平台、内部开发框架和流量接入层等
-
用户使用习惯:vivo有比较成熟的发布平台,用户习惯按机房发布,习惯资源分配和发布分开操作。
-
价值输出:运维研发效率的提升不好量化,容器成本优势短期不好衡量。
上面这些挑战,推动我们要进行容器周边生态打通,同时通过增强容器平台产品能力,来适配各种业务场景,降低用户的迁移成本。
2.5 最佳实践
2.5.1 容器集群高可用建设
接下来,介绍vivo在容器集群高可用建设中的最佳实践,我们是从故障预防、故障发现和故障恢复,3个维度来构建容器集群可用性保障体系的。
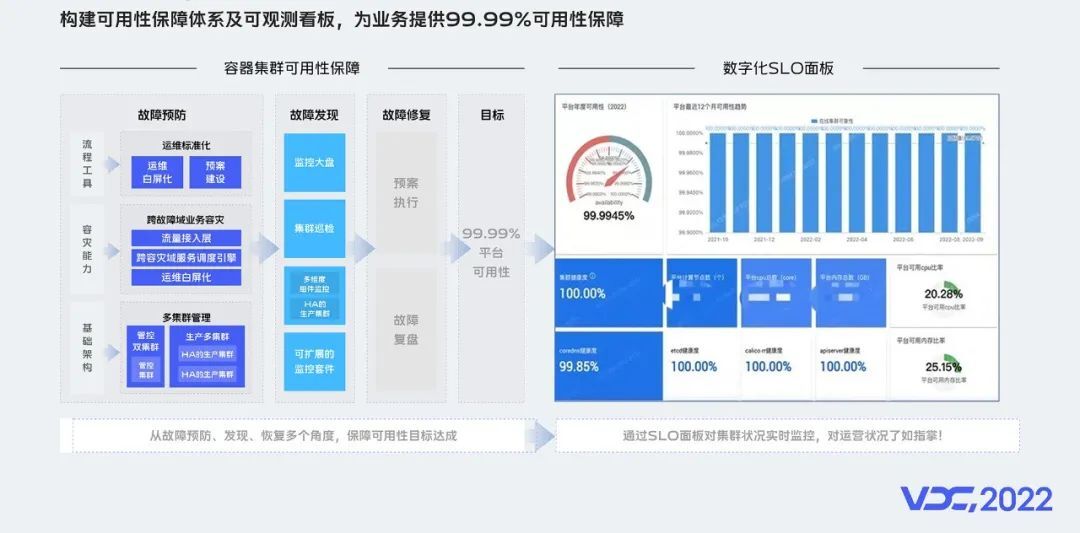
1、在故障预防上,我们分别从流程工具、容灾能力和基础架构3个方面来进行建设:
-
流程工具:主要包含故障预案和故障演练,以及通过建设运维管理平台,来实现运维标准化、白屏化和自动化。
-
容灾能力:主要是构建业务跨故障域容灾能力,保障集群故障时,服务和业务流量能跨集群调度和快速一键迁移等。
-
基础架构:主要是通过屏蔽用户对底层集群的感知,一个机房多套集群,一个业务同时部署在多个集群上,避免单集群故障对业务造成影响。
2、在故障发现上,我们主要是通过,自建的监控大盘、日常集群巡检、核心组件监控、集群外拨测等措施,对故障及时发现和处理,降低对业务影响。
3、在故障恢复上,主要是基于前面的故障预案,快速恢复,及时止损,并做好故障的复盘,不断改进我们的故障预防和发现机制,沉淀宝贵经验。
另外,集群的可观测性是可用性保障的一个重要依据,我们通过建设自己的SLO面板,对集群状态实时地进行监控,只有对运营状况了如指掌,才能做到稳如泰山,沉着应对一切变化。
2.5.2 容器集群自动化运维
除了容器集群自身稳定性建设,在运维自动化方面,我们建设了容器多集群管理平台,实现集群配置标准化,核心运维场景白屏化,来提升运维效率。
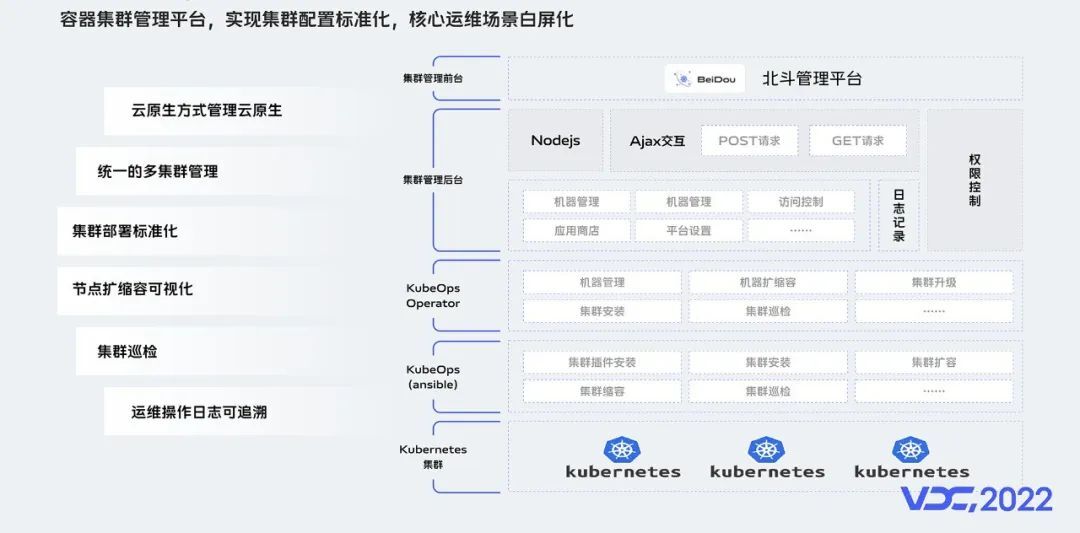
我们的容器集群管理平台,是以云原生的方式来管理云原生,简单来说,就是基于k8s的operator机制,实现k8s on k8s。
当前,我们的平台已经能够实现多集群的统一纳管,集群部署也是自动化、标准化的,还实现了底层IAAS层打通,集群节点能全流程化、可视化的一键扩缩容,而集群巡检功能,可以帮助我们及时发现集群的问题和隐患。
通过平台进行日常运维和操作,不仅能提升效率,也具备审计能力,有操作和变更日志可追溯,便于问题定位。
2.5.3 容器平台架构升级
为适应业务容器化在内部的快速普及和推广,我们升级了vivo的容器平台架构。

新的架构分为4层,容器+k8s则作为基础的统一底座,向下对接公司IAAS层的基础设施,向上提供容器产品和平台能力,并通过开放API供上层调用和定制自己的上层逻辑。
API之上是容器支持的各种服务类型,包括在线服务、中间件服务、大数据计算、算法训练、实时计算等,最上面是为vivo互联网各个业务进行赋能。
基于这套容器平台架构,业务能实现资源隔离部署、快速交付和按需使用,同时也具备更好的弹性伸缩能力。对平台,我们可以统一资源的调度,实现资源的分时复用、在离线混部等,来提升资源的利用率。
2.5.4 容器平台能力增强
vivo内部容器化场景比较多样化,为了让业务能够安心、低成本的接入和使用容器的能力,在推广过程中,我们基于开源+自研做了容器的适配和原生能力的增强。
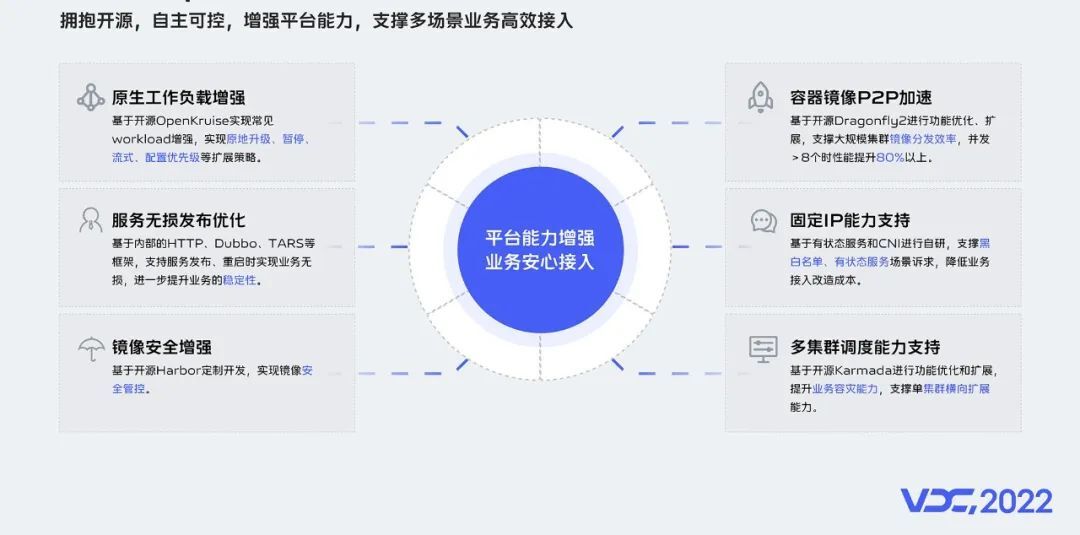
下面对6个产品能力增强进行简单的分享:
-
云原生工作负载增强:基于开源的openkruise,对原生deployment、statefulset等workload进行了增强,实现诸如原地升级、发布暂停、流式和配置优先级等扩展能力。
-
服务无损发布增强:基于内部框架和平台自主研发,实现HTTP、RPC等协议框架的流量无损发布。
-
容器镜像安全:基于开源的Harbor定制开发,实现容器镜像安全扫描和卡控能力。
-
容器镜像加速:基于开源dragonfly2定制扩展,让大规模集群镜像的分发性能提升80%以上。
-
IP固定能力增强:基于有状态服务和CNI进行自研,支撑黑白名单、有状态服务场景诉求,降低业务接入改造成本。
-
多集群管理能力增强:基于开源Karmada进行功能优化和扩展,提升业务容灾能力,支撑单集群横向扩展能力。
当然,在充分享受开源红利的同时,我们也持续地参与开源协同,回馈社区。在使用和自研的过程中,我们也把自己生产实践过程中发现的问题和积累的经验提交到社区,例如Dragonfly2、Karmada等。
2.5.5 容器CICD一体化
除了平台能力的增强,容器平台作为一个PaaS平台,需要和周边的生态打通,才能让业务更好的迁移和使用,其中最重要的就是发布系统的打通,也就是CICD平台。
几乎每个科技公司都会有自己的CICD,它是一个DevOps自动化的工具,可进行业务构建和编排部署的流水线。
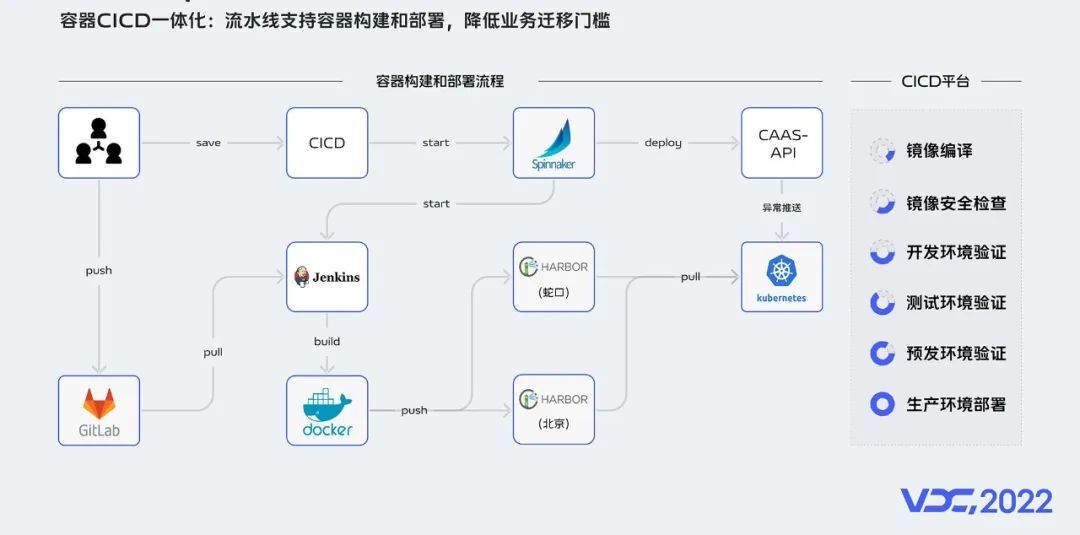
vivo的CICD平台底层架构是基于JenKins+Spinnaker实现的,整个容器构建和部署流程如下:
-
首先,用户在CICD平台上创建好发布过程的流水线配置并保存。
-
其次,CI环节可实现和内部GitLab对接,拉取代码,基于jenkins进行代码编译和镜像构建,构建好的镜像经过安全扫描后,推送到开发环境的镜像仓库。
-
最后,在CD环节,CICD平台会调用容器平台提供的API,进行开发、测试、预发和生产环境的部署操作。
2.5.6 统一流量接入
接下来,介绍容器生态里,最重要的业务流量接入层的打通。
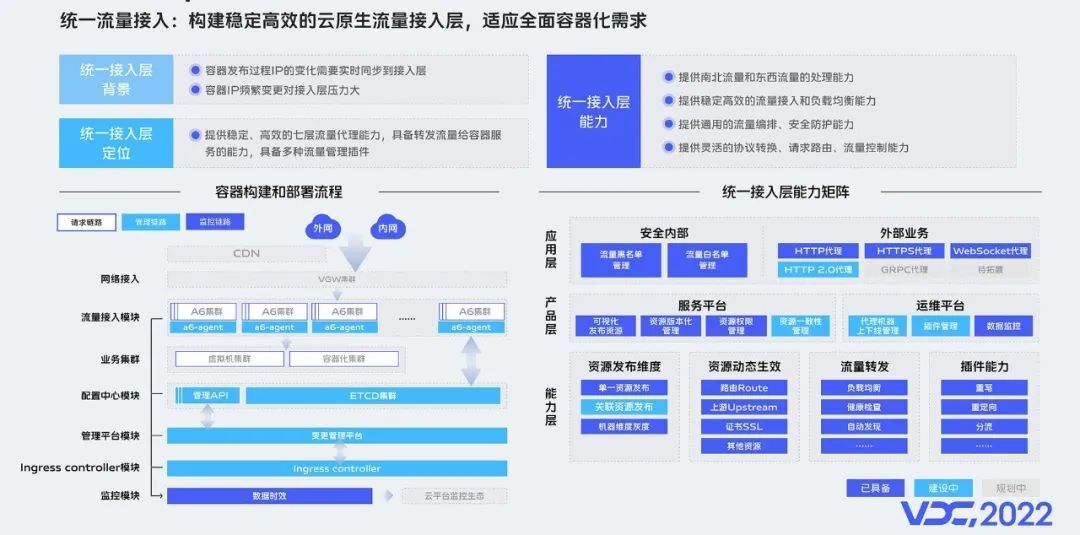
早期,vivo内部是基于Nginx,来实现的南北流量和东西流量的转发。在虚拟机和物理机场景能比较好的支撑,随着容器在内部全面的推广,传统的Nginx架构已不能适配。
主要体现在,容器场景业务实例数量,相比原来虚拟机和物理机成倍数增长,容器发布过程IP的频发变化和状态同步,都会对Nginx集群造成非常大的压力,在业务请求量非常大的情况下,接入层的配置文件刷新和加载,会造成业务的抖动,这是我们不能接受的。
基于这个背景,我们基于APISIX构建了云原生流量接入层,来适应全面容器化的需求。经过一年多的建设,当前我们的统一流量接入平台已经能够很好的支撑容器化的接入,同时具备更好的扩展能力。
2.6 实践成果
2.6.1 产品能力矩阵完善
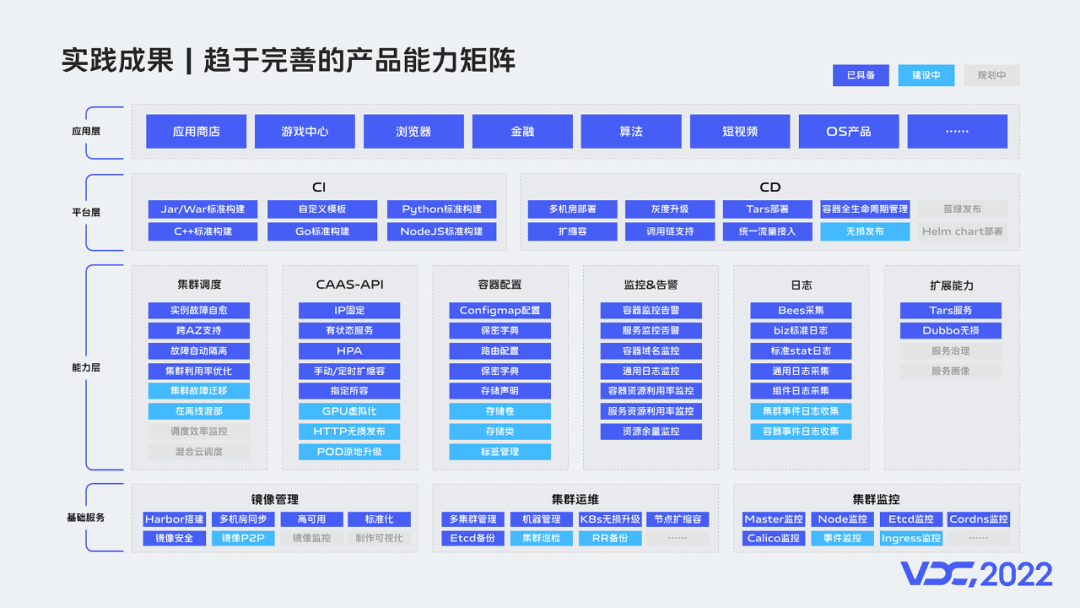
经过多年的打磨和建设,vivo容器产品能力矩阵趋于完善,整个产品能力矩阵,分为4层:
-
基础服务层:包含3类服务,镜像管理、集群运维和集群监控。
-
能力层:包含6个核心能力,分别是集群调度、CAAS-API、容器配置、容器业务监控告警、容器日志和平台扩展能力。
-
平台层:包含2大平台能力,分别是CI和CD。
-
业务层:当前覆盖了vivo互联网所有业务场景。
2.6.2 业务接入成果凸显
接下来,会具体介绍下vivo容器推广情况。

目前容器在vivo内部主要覆盖4大场景,分别是:互联网在线业务、算法在线、大数据计算和AI算法训练等。接下来,会从接入规模和价值来简单介绍。
-
互联网在线服务:内部各个业务线均有大量服务运行在容器上,例如vivo商城、账号、浏览器、快应用、天气等,已经接入服务600+。
-
算法在线服务:当前接入500+服务,3000+服务器,涉及推广搜的各个业务线。
-
大数据计算服务:包含离线计算如Spark,实时计算如Flink、Olap等场景,当前接入集群20+。
-
AI算法训练:主要是提供GPU、CPU异构计算,业务场景如Tensorflow、mpi等场景,算力十几万核,以及若干GPU卡。
业务容器化后,给业务在降本提效上带来的效果非常明显,包括但不限于扩缩容效率、弹性伸缩能力、业务自愈能力、资源成本等方面。
2.7 实践总结
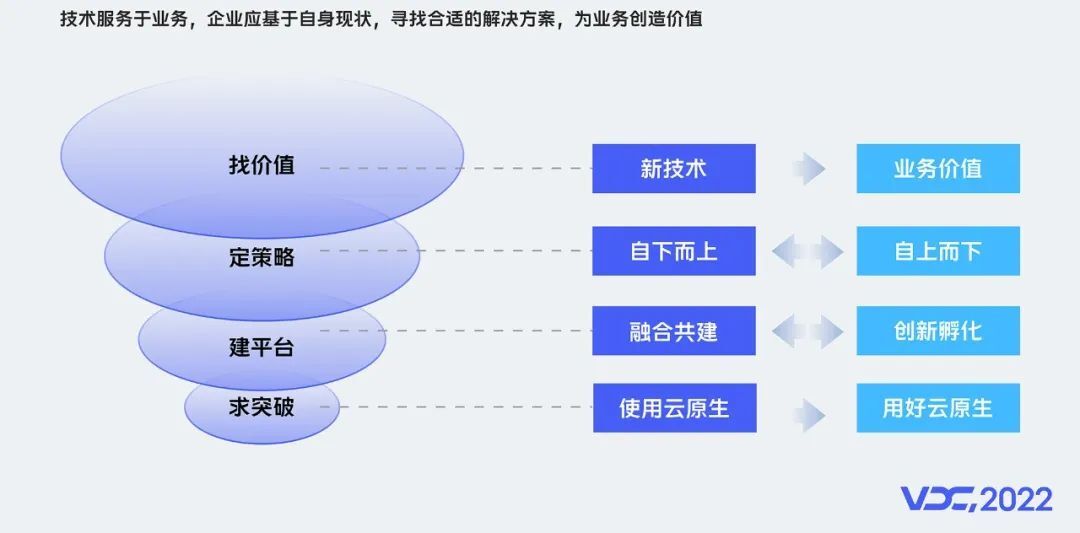
基于我们的探索和实践,可总结为技术价值、推广策略、平台建设和云原生突破4个维度的思考。
-
找价值:关注新技术,但不执着于技术本身,必须结合业务痛点和价值。
-
定策略:自下而上小范围试点探索,产生实际的业务价值,影响自上而下的战略调整。
-
建平台:当已经有比较完善的平台和能力时,要找到容器的切入点,进行融合共建,切忌推到重来;对于需要从0到1建设的新能力,需要果断的孵化创新。
-
求突破:在业务容器化过程中,为了快速容器化,我们做了许多的兼容和适配。为了更好的降本提效,未来,我们希望引导用户,实现从使用云原生,到用好云原生的突破。
总的来说,技术服务于业务,企业应基于自身现状,寻找合适的解决方案,并为业务创造价值。
三、vivo对云原生的未来展望
3.1 vivo基础架构发展
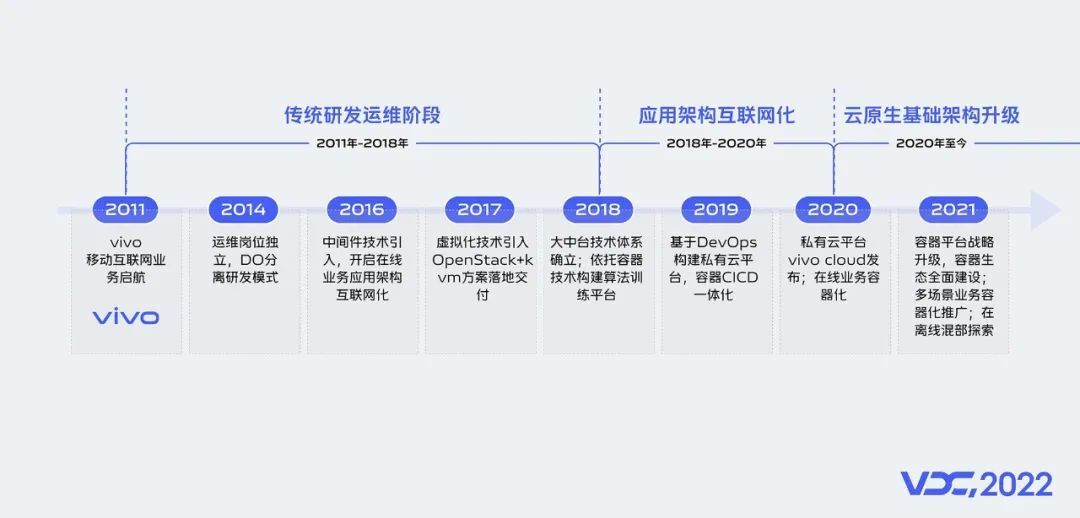
从过去看未来发展,回顾过去10年历程,vivo基础架构的发展经历了3个阶段:
-
阶段一:传统研发运维阶段,从2011到2018年,从早期的do分离研发模式,到基于openstack+kvm的虚拟化方案落地。
-
阶段二:应用架构互联网化阶段,从2018到2020年,容器化开始在vivo内部兴起。
-
阶段三:云原生基础架构演进阶段,从2021年到现在,云原生和容器将会在vivo内部有更多场景的应用和推广,如在离线混部等。
3.2 vivo云原生未来展望

回归事物本源思考,做正确的事,并把事情做正确。不盲从,有定力,基于价值,客观看待新技术发展,大胆假设、小心验证、实践出真知。
vivo云原生的未来,将会朝着3个方向发展,分别是全面容器化、拥抱云原生和在离线混部。
-
我们的愿景是:一次开发到处运行,通过自动运维实现极致效率和成本最优!
-
对开发人员:我们希望大家成为那只遨游海上的蓝色鲸鱼,驮着我们的业务应用,一次构建到处分发,灵活调度和运维。
-
对管理者:我们希望追求效率的同时,能够实现成本最优。