看到medium的文章:https://medium.com/a-journey-with-go/go-how-to-reduce-lock-contention-with-the-atomic-package-ba3b2664b549
点开一看发现居然需要vip...于是就去谷歌上搜“Go: How to Reduce Lock Contention with the Atomic Package”于是就出现了不少译文,成功白嫖!
文章里也就写了一个例子,也就是并发赋值一个全局slice,之后打印出来看结果是否跟预期的一样。当然是不一样的,毕竟slice并不是并发安全的。
之后就举例用sync.RWMutex与atomic.Value进行对比,来举例说明atomic比mutex要快一点。不过我在文章末尾看到这一句话:
在这种情况下,
atomic包肯定会带来优势。但是,在某些方面可能会降低性能。例如,如果你要存储一张大地图,每次更新地图时都要复制它,这样效率就很低。
这句话我并不是很明白,因为当我点开atomic.Value的时候,发现内部是一个interface{}。那么存储的时候会发生复制吗?他的内部又是怎么实现的?
于是就谷歌看到了下面这篇类似于源码剖析的文章:
这篇文章写的好好啊,我直接一下子就看懂了atomic.Value的工作原理,以及他是如何使用for循环和CAS与中间态(^uintptr(0))巧妙地达到了原子性的Store。
atomic.Value最重点的地方是第一次存储,因为要确定类型。这个时候会存在并发风险,所以采用了atomic.CAS与中间态来控制,使得只会有一个地方能修改他的类型。类型确定了以后,就只需要原子性地赋值就可以了。
似乎有点懂了他的原理了,就是通过空转(循环)与状态来完成并发控制,假设任务都处理飞快,以至于空转时间根本微乎其微。
不过我还是没有搞懂最开始的疑问...于是我就去原文下面看,看是否会有什么提示,结果翻到了一个老哥对与原文的疑问:
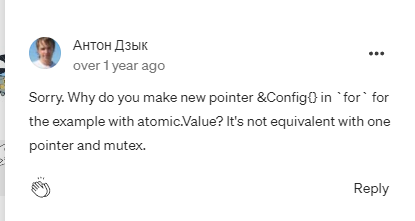
也就是,在原文用atomic.Value举例的时候采用了局部对象:
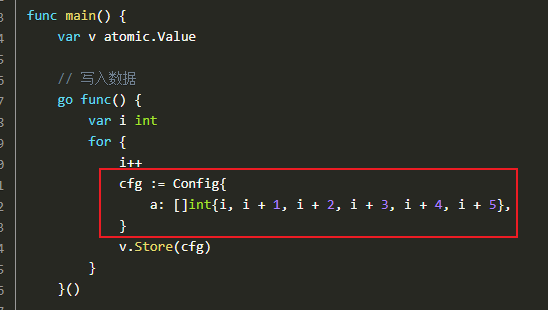
我们都知道,局部对象被引用的话,GC并不会回收,所以并不会有per-for的问题,具体可以看我说per-for跟per-iteration的文章。所以就导致了我们的输出跟mutex的结果一致。但是当我们用应该使用的写法,如下:
package main
import (
"fmt"
"sync"
"sync/atomic"
)
type Config struct {
a []int
}
func main() {
var v atomic.Value
cfg := &Config{}
// 写入数据
go func() {
var i int
for {
i++
cfg.a = []int{i, i + 1, i + 2, i + 3, i + 4, i + 5} //这一块改成跟mutex一样的写法
v.Store(cfg)
}
}()
// 读取数据
var wg sync.WaitGroup
for n := 0; n < 4; n++ {
wg.Add(1)
go func() {
for n := 0; n < 100; n++ {
cfg := v.Load()
fmt.Printf("%#v\n", cfg)
}
wg.Done()
}()
}
wg.Wait()
}
发现结果似乎并不像我们所想的那样:

仍然会出现一开始的并发问题...
艹狠狠地上当了,之后我看了一下atomic.Value的使用场景:
https://blog.csdn.net/q895431756/article/details/111063656
发现这篇博客里面也有提到这个坑点,也就是atomic.Value里面存储引用类型仍然会导致并发问题。想想也是,毕竟atomic.Value里面存的是指针,指向的东西的内容还是能被改变的。所以如果你要存最好存的是数值类型....
一瞬间就变鸡肋了很多,似乎只能在状态结构体里面去使用了。
这样我就懂了原文最开始说的,在地图更新的时候,他存储的是一个二维数组,而不是slice,而数组他是数值类型的,你每次修改的话,必然需要拿一个局部变量去存,这样就导致了庞大的复制。从而导致效率低下...
atomic.Value类型,感觉不是很有用的样子捏
标签:并发,cfg,Value,互斥,Atomic,go,atomic From: https://www.cnblogs.com/Vikyanite/p/16955387.html