Stream(流)是一个来自数据源的元素队列,元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。数据源:流的来源,可以是集合,数组 等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluentstyle)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
内部迭代: 以前对集合遍历都是通过Iterator或者增强for的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式,流可以直接调用遍历方法。
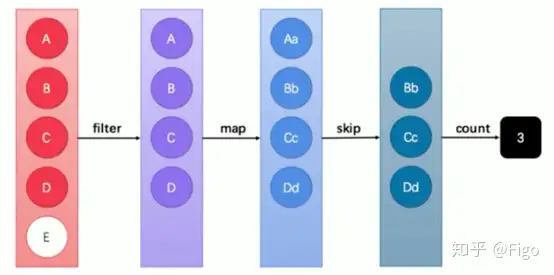
这张图中展示了过滤、映射、跳过、计数等多步操作,这是一种集合元素的处理方案,而方案就是一种“函数模型”。图中的每一个方框都是一个“流”,调用指定的方法,可以从一个流模型转换为另一个流模型。而最右侧的数字3是最终结果。这里的 filter 、 map 、 skip 都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法 count执行的时候,整个模型才会按照指定策略执行操作。而这得益于Lambda的延迟执行特性。
备注:“Stream流”其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)。
当使用一个流的时候,通常包括三个基本步骤:
获取一个数据源(source)→ 数据转换→执行操作获取想要的结果,每次转换原有 Stream 对象不改变,返回一个新的 Stream 对象(可以有多次转换),这就允许对其操作可以像链条一样排列,变成一个管道。
Stream操作
1、获取流:
java.util.stream.Stream<T> 是Java 8新加入的最常用的流接口。(这并不是一个函数式接口。)获取一个流非常简单,有以下几种常用的方式:所有的 Collection 集合都可以通过 stream 默认方法获取流;Stream 接口的静态方法 of 可以获取数组对应的流。
1.1、根据Collection获取流
java.util.Collection 接口中加入了default方法 stream 用来获取流,所以其所有实现类均可获取流。java.util.Collection 接口中加入了default方法 stream 用来获取流,所以其所有实现类均可获取流。
List<String> list = new ArrayList<>();
Stream<String> stream1 = list.stream();
Set<String> set = new HashSet<>();
Stream<String> stream2 = set.stream();1.2、根据Map获取流
java.util.Map 接口不是 Collection 的子接口,且其K-V数据结构不符合流元素的单一特征,所以获取对应的流需要分key、value或entry等情况:
Stream<String> keyStream = map.keySet().stream();
Stream<String> valueStream = map.values().stream();
Stream<Map.Entry<String, String>> entryStream = map.entrySet().stream();1.3、据数组获取流
如果使用的不是集合或映射而是数组,由于数组对象不可能添加默认方法,所以 Stream 接口中提供了静态方法of 。
String[] array = { "张无忌", "张翠山", "张三丰", "张一元" };
Stream<String> stream = Stream.of(array);2、Stream中的常用方法
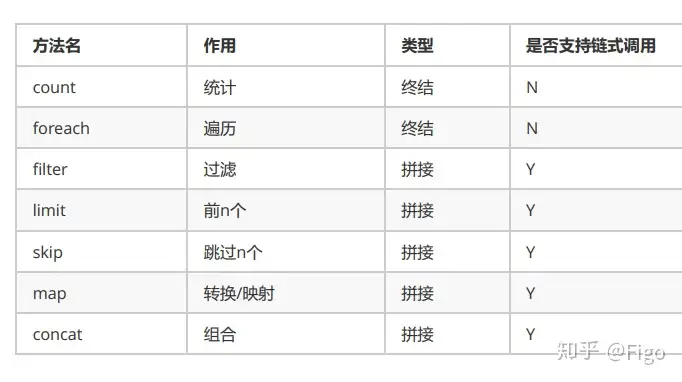
2.1、forEach:逐一处理
void forEach(Consumer<? super T> action);该方法接收一个 Consumer 接口函数,会将每一个流元素交给该函数进行处理。
private static void forEachDemo(){
String[] array = { "张无忌", "张翠山", "张三丰", "张一元" };
Stream<String> stream = Stream.of(array);
stream.forEach(s -> System.out.println(s));
}输出:
forEach ==================
张无忌
张翠山
张三丰
张一元2.2、filter:过滤
Stream<T> filter(Predicate<? super T> predicate);该接口接收一个 Predicate 函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
private static void filterDemo(){
String[] array = { "张无忌", "张三丰", "周芷若" };
Stream<String> stream = Stream.of(array);
Stream<String> result = stream.filter(s -> s.startsWith("张"));
result.forEach(s -> System.out.println(s));
}输出:
filter ==================
张无忌
张三丰2.3、map: 映射
如果需要将流中的元素映射到另一个流中,可以使用 map 方法。
<R> Stream<R> map(Function<? super T, ? extends R> mapper);该接口需要一个 Function 函数式接口参数,可以将当前流中的T类型数据转换为另一种R类型的流。
private static void mapDemo(){
String[] array = {"10", "12", "18"};
Stream<String> stringStream = Stream.of(array);
Stream<Integer> integerStream = stringStream.map(s -> Integer.parseInt(s));
integerStream.forEach(integer -> System.out.println(integer));
}输出:
map ==================
10
12
182.4、count:统计流中的元素个数
正如旧集合 Collection 当中的 size 方法一样,流提供 count 方法来数一数其中的元素个数:
long count();该方法返回一个long值代表元素个数(不再像旧集合那样是int值)。
private static void countDemo(){
String[] array = { "张无忌", "张翠山", "张三丰", "张一元" };
Stream<String> stream = Stream.of(array);
long num = stream.count();
System.out.println(num);
}输出:
count ==================
42.5、limit:取用前几个
limit 方法可以对流进行截取,只取用前n个。
Stream<T> limit(long maxSize);参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。
private static void limitDemo(){
String[] array = { "张无忌", "张翠山", "张三丰", "张一元" };
Stream<String> stream = Stream.of(array);
Stream<String> newStream = stream.limit(3);
newStream.forEach(s -> System.out.println(s));
}输出:
limit ==================
张无忌
张翠山
张三丰2.6、skip:跳过前几个
如果希望跳过前几个元素,可以使用 skip 方法获取一个截取之后的新流:
Stream<T> skip(long n);如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。
n必须大于等于0,如果大于当前流中的元素个数,则产生一个空流。
private static void skipDemo(){
String[] array = { "张无忌", "张翠山", "张三丰", "张一元" };
Stream<String> stream = Stream.of(array);
Stream<String> newStream = stream.skip(2);
newStream.forEach(s -> System.out.println(s));
}输出:
skip ==================
张三丰
张一元2.7、concat:组合
如果有两个流,希望合并成为一个流,那么可以使用 Stream 接口的静态方法 concat :
static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)例子:
private static void concatDemo(){
Stream<String> stream1 = Stream.of("张三");
Stream<String> stream2 = Stream.of("李四");
Stream<String> stream = Stream.concat(stream1,stream2);
stream.forEach(s -> System.out.println(s));
}输出:
concat ==================
张三
李四2.8、sorted:排序
Stream<T> sorted()sorted 方法用于对流进行排序。
private static void sortedDemo(){
String[] array = { "张无忌", "张翠山", "张三丰", "张一元" };
Stream<String> stream = Stream.of(array);
stream.limit(3).sorted().forEach(System.out::println);
}输出:
sorted ==================
张三丰
张无忌
张翠山2.9、元素收集
1)收集到List集合:
流对象.collect( Collectors.toList() )获得List集合。
2)收集到Set集合:
流对象.collect( Collectors.toSet() )获得Set集合。
3)收集到数组:
流对象. toArray()由于泛型擦除的原因,返回值类型是Object[]
2.10、分组
groupingBy()方法是Collectors类中的静态方法
public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream)例子:
private static void groupingByDemo(){
List<String> items = Arrays.asList("apple", "apple", "banana", "apple", "orange", "banana", "papaya");
Map<String,Long> result = items.stream()
.collect(Collectors.groupingBy(
Function.identity(),Collectors.counting()
)
);
result.entrySet().stream().forEach(System.out::println);
}输出:
groupingBy ==================
papaya=1
orange=1
banana=2
apple=32.11、分区
public static <T>
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate)partitioningBy() 分区方法,可以看做是分组的一种特殊情况,在分区中key只有两种情况:true或false,目的是将待分区集合按照条件一分为二。
// 按是否以"a'开头分为两部分
private static void partitioningByDemo(){
List<String> items = Arrays.asList("apple", "apple", "banana", "apple", "orange", "banana", "papaya");
Map<Boolean, List<String>> result = items.stream().collect(Collectors.partitioningBy(s -> s.startsWith("a")));
System.out.println(result);
}输出:
partitioningBy ==================
{false=[banana, orange, banana, papaya], true=[apple, apple, apple]}2.12、flagMap
一对多转换,flatMap与map的区别在于 flatMap是将一个流中的每个值都转成一个个流,然后再将这些流扁平化成为一个流。
/*使用map并不能实现我们现在想要的结果,而flatMap是可以的。
这是因为在执行map操作以后,我们得到是一个包含多个字符串(构成一个字符串的字符数组)的流,
此时执行distinct操作是基于在这些字符串数组之间的对比,所以达不到我们希望的目的;
flatMap将由map映射得到的Stream<String[]>,转换成由各个字符串数组映射成的流Stream<String>,
再将这些小的流扁平化成为一个由所有字符串构成的大流Steam<String>,从而能够达到我们的目的。
*/
private static void flagMapDemo(){
// 我们希望输出构成这一数组的所有非重复字符
String[] strings = {"Hello", "World"};
List l1 = Arrays.stream(strings).map(str -> str.split("")).map(str2->Arrays.stream(str2)).distinct().collect(Collectors.toList());
List l2 = Arrays.asList(strings).stream().map(s -> s.split("")).flatMap(Arrays::stream).distinct().collect(Collectors.toList());
System.out.println(l1.toString());
System.out.println(l2.toString());
}输出:
flagMap ==================
[java.util.stream.ReferencePipeline$Head@15975490, java.util.stream.ReferencePipeline$Head@6b143ee9]
[H, e, l, o, W, r, d]和map的区别
public static void main(String[] args) {
List<String> cityListOne = new ArrayList<>();
cityListOne.add("郑州");
cityListOne.add("濮阳");
List<String> cityListTwo = new ArrayList<>();
cityListTwo.add("廊坊");
cityListTwo.add("邢台");
List<String> cityListThree = new ArrayList<>();
cityListThree.add("大同");
cityListThree.add("太原");
List<String> cityListFour = new ArrayList<>();
cityListFour.add("南昌");
cityListFour.add("九江");
Address addressOne = new Address();
addressOne.setProvince("河南");
addressOne.setCityList(cityListOne);
Address addressTwo = new Address();
addressTwo.setProvince("河北");
addressTwo.setCityList(cityListTwo);
Address addressThree = new Address();
addressThree.setProvince("山西");
addressThree.setCityList(cityListThree);
Address addressFour = new Address();
addressFour.setProvince("江西");
addressFour.setCityList(cityListFour);
List<Address> addresseList = new ArrayList<>();
addresseList.add(addressOne);
addresseList.add(addressTwo);
addresseList.add(addressThree);
addresseList.add(addressFour);
//使用map输出所有的城市名称
addresseList.stream()
.map(a -> a.getCityList())
.forEach(cityList->{ cityList.forEach(city -> System.out.print(city));
});
System.out.println("");
//使用flatMap输出所有城市名称
addresseList.stream()
.flatMap(a -> a.getCityList().stream())
.forEach(city -> System.out.print(city));
}map和flagMap结果一样,但map处理方式是在foreach中将cityList作为集合再次循环,而flatMap可以直接将cityList中的城市直接进行循环输出。也就是说flatMap可以获取集合中的集合的流在外层可以直接处理。
2.13、查找
allMatch(Predicate<? super T> predicate)用于检测是否全部都满足指定的参数行为,如果全部满足则返回true
anyMatch(Predicate<? super T> predicate)anyMatch则是检测是否存在一个或多个满足指定的参数行为,如果满足则返回true
noneMatch(Predicate<? super T> predicate)oneMatch用于检测是否不存在满足指定行为的元素,如果不存在则返回true
findFirst()findFirst用于返回满足条件的第一个元素
findAny()findAny相对于findFirst的区别在于,findAny不一定返回第一个,而是返回任意一个
private static void findDemo(){
List<String> items = Arrays.asList("apple", "apple", "banana", "apple", "orange", "banana", "papaya");
Stream<String> stream = items.stream();
System.out.println(stream.allMatch(s -> s.contains("a")));
Stream<String> stream1 = items.stream();
System.out.println(stream1.filter(s -> s.contains("a")).findFirst().get());
Stream<String> stream2 = items.stream();
System.out.println(stream2.filter(s -> s.contains("a")).findAny().get());
}输出:
findMap ==================
true
apple
apple2.14、字符串拼接
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter)参数为连接符,返回值为一个集合。
private static void joinDemo(){
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
System.out.println(list);
System.out.println(list.stream().collect(Collectors.joining(",")));
}输出:
join ==================
[张无忌, 周芷若, 赵敏, 张强, 张三丰]
张无忌,周芷若,赵敏,张强,张三丰2.15、归约
Optional<T> reduce(BinaryOperator<T> accumulator);rudece方法的功能是从一个流中生成一个值,reduce方法参数为一个函数,返回值为Optional对象。
private static void reduceDemo(){
List<Integer> num = Arrays.asList(1, 2, 4, 5, 6, 7);
// 求和
num.stream().reduce((x, y) -> x+y ).ifPresent(System.out::println);
// 求最大值
num.stream().reduce(Integer::max).ifPresent(System.out::println);
}输出:
reduce ==================
25
72.16、去重
Stream<T> distinct();例子;
private static void distinctDemo(){
List<String> items = Arrays.asList("apple", "apple", "banana", "apple", "orange", "banana", "papaya");
Stream stream = items.stream().distinct();
stream.forEach(System.out::println);
}输出:
distinct ==================
apple
banana
orange
papaya