作者:vivo 互联网服务器团队- Feng Xiang
在日常业务开发工作中我们经常会遇到一些根据业务规则做决策的场景。为了让开发人员从大量的规则代码的开发维护中释放出来,把规则的维护和生成交由业务人员,为了达到这种目的通常我们会使用规则引擎来帮助我们实现。
本篇文章主要介绍了规则引擎的概念以及Kie和Drools的关系,重点讲解了Drools中规则文件编写以及匹配算法Rete原理。文章的最后为大家展示了规则引擎在催收系统中是如何使用的,主要解决的问题等。
一、业务背景
1.1 催收业务介绍
消费贷作为vivo钱包中的重要业务板块当出现逾期的案件需要处理时,我们会将案件统计收集后导入到催收系统中,在催收系统中定义了一系列的规则来帮助业务方根据客户的逾期程度、风险合规评估、操作成本及收益回报最大原则制定催收策略。例如“分案规则” 会根据规则将不同类型的案件分配到不同的队列,再通过队列分配给各个催收岗位和催收员,最终由催收员去进行催收。下面我会结合具体场景进行详细介绍。
1.2 规则引擎介绍
1.2.1 问题的引入
案例:根据上述分案规则我们列举了如下的规则集:
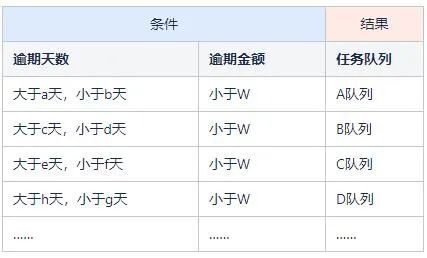
代码实现:将以上规则集用代码实现
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
if(overdueDays>a && overdueDays<b && overdueAmt <W){
taskQuene = "A队列";
}
else if(overdueDays>c && overdueDays<d && overdueAmt <W){
taskQuene = "B队列";
}
else if(overdueDays>e && overdueDays<f && overdueAmt <W){
taskQuene = "C队列";
}
else if(overdueDays>h && overdueDays<g && overdueAmt <W){
taskQuene = "D队列";
}
……
|
业务变化:
- 条件字段和结果字段可能会增长而且变动频繁。
- 上面列举的规则集只是一类规则,实际上在我们系统中还有很多其他种类的规则集。
- 规则最好由业务人员维护,可以随时修改,不需要开发人员介入,更不希望重启应用。
问题产生:可以看出如果规则很多或者比较复杂的场景需要在代码中写很多这样if else的代码,而且不容易维护一旦新增条件或者规则有变更则需要改动很多代码。
此时我们需要引入规则引擎来帮助我们将规则从代码中分离出去,让开发人员从规则的代码逻辑中解放出来,把规则的维护和设置交由业务人员去管理。
1.2.2 什么是规则引擎
规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件, 实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。
通过接收数据输入解释业务规则,最终根据业务规则做出业务决策。常用的规则引擎有:Drools,easyRules等等。本篇我们主要来介绍Drools。
二、Drools
2.1 整体介绍
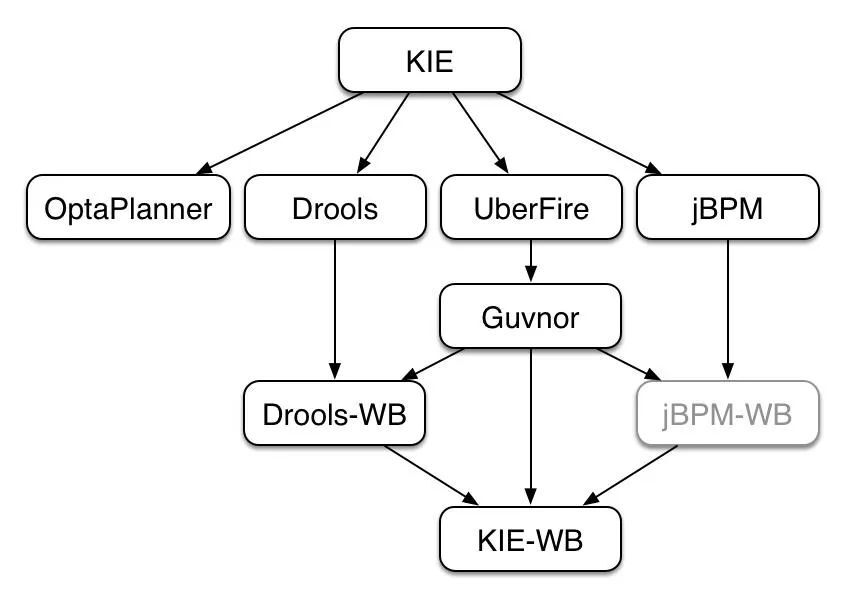
2.1.1 KIE介绍
在介绍Drools之前我们不得不提到一个概念KIE,KIE(Knowledge Is Everything)是一个综合性项目,将一些相关技术整合到一起,同时也是各个技术的核心,这里面就包含了今天要讲到的Drools。
技术组成:
- Drools是一个业务规则管理系统,具有基于前向链和后向链推理的规则引擎,允许快速可靠地评估业务规则和复杂的事件处理。
- jBPM是一个灵活的业务流程管理套件,允许通过描述实现这些目标所需执行的步骤来为您的业务目标建模。
- OptaPlanner是一个约束求解器,可优化员工排班、车辆路线、任务分配和云优化等用例。
- UberFire是一个基于 Eclipse 的富客户端平台web框架。
2.1.2 Drools介绍
Drools 的基本功能是将传入的数据或事实与规则的条件进行匹配,并确定是否以及如何执行规则。
Drools的优势:基于Java编写易于学习和掌握,可以通过决策表动态生成规则脚本对业务人员十分友好。
Drools 使用以下基本组件:
- rule(规则):用户定义的业务规则,所有规则必须至少包含触发规则的条件和规则规定的操作。
- Facts(事实):输入或更改到 Drools 引擎中的数据,Drools 引擎匹配规则条件以执行适用规则。
- production memory(生产内存):用于存放规则的内存。
- working memory(工作内存):用于存放事实的内存。
- Pattern matcher(匹配器):将规则库中的所有规则与工作内存中的fact对象进行模式匹配,匹配成功后放入议程中
- Agenda(议程):存放匹配器匹配成功后激活的规则以准备执行。
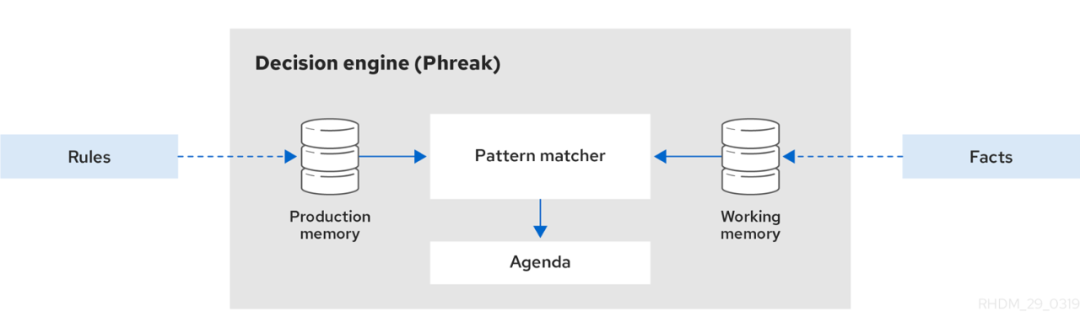
当用户在 Drools 中添加或更新规则相关信息时,该信息会以一个或多个事实的形式插入 Drools 引擎的工作内存中。Drools 引擎将这些事实与存储在生产内存中的规则条件进行模式匹配。
当满足规则条件时,Drools 引擎会激活并在议程中注册规则,然后Drools 引擎会按照优先级进行排序并准备执行。
2.2 规则(rule)
2.2.1 规则文件解析
DRL(Drools 规则语言)是在drl文本文件中定义的业务规则。主要包含:package,import,function,global,query,rule end等,同时Drools也支持Excel文件格式。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
package //包名,这个包名只是逻辑上的包名,不必与物理包路径一致。
import //导入类 同java
function // 自定义函数
query // 查询
global // 全局变量
rule "rule name" // 定义规则名称,名称唯一不能重复
attribute // 规则属性
when
// 规则条件
then
// 触发行为
end
rule "rule2 name"
...
|
-
function
规则文件中的方法和我们平时代码中定义的方法类似,提升规则逻辑的复用。
使用案例:
| 1 2 3 4 5 6 7 8 9 10 |
function String hello(String applicantName) {
return "Hello " + applicantName + "!";
}
rule "Using a function"
when
// Empty
then
System.out.println( hello( "James" ) );
end
|
-
query
DRL 文件中的查询是在 Drools 引擎的工作内存中搜索与 DRL 文件中的规则相关的事实。在 DRL 文件中添加查询定义,然后在应用程序代码中获取匹配结果。查询搜索一组定义的条件,不需要when或then规范。
查询名称对于 KIE 库是全局的,因此在项目中的所有其他规则查询中必须是唯一的。返回查询结果ksession.getQueryResults("name"),其中"name"是查询名称。
使用案例:
规则:
| 1 2 3 4 5 6 7 |
query "people under the age of 21"
$person : Person( age < 21 )
end
QueryResults results = ksession.getQueryResults( "people under the age of 21" );
System.out.println( "we have " + results.size() + " people under the age of 21" );
|
-
全局变量global
通过 KIE 会话配置在 Drools 引擎的工作内存中设置全局值,在 DRL 文件中的规则上方声明全局变量,然后在规则的操作 ( then) 部分中使用它。
使用案例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
List<String> list = new ArrayList<>();
KieSession kieSession = kiebase.newKieSession();
kieSession.setGlobal( "myGlobalList", list );
global java.util.List myGlobalList;
rule "Using a global"
when
// Empty
then
myGlobalList.add( "My global list" );
end
|
-
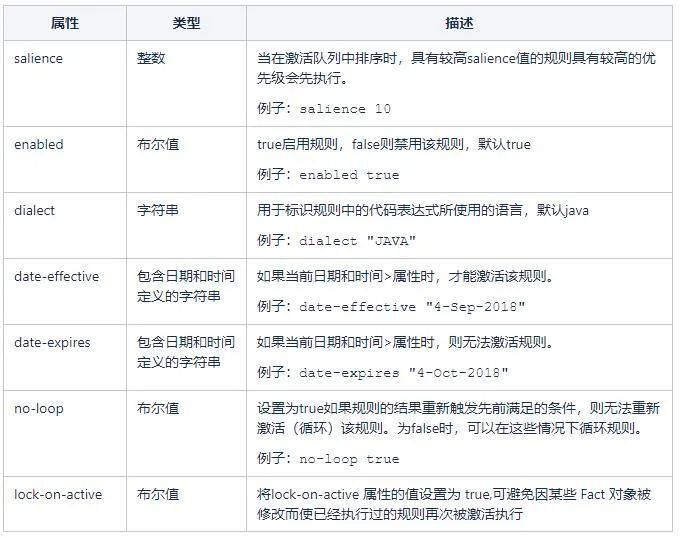
规则属性
-
模式匹配
当事实被插入到工作内存中后,规则引擎会把事实和规则库里的模式进行匹配,对于匹配成功的规则再由 Agenda 执行推理算法中规则的(then)部分。
-
when
规则的“when”部分也称为规则的左侧 (LHS)包含执行操作必须满足的条件。如果该when部分为空,则默认为true。如果规则条件有多个可以使用(and,or),默认连词是and。如银行要求贷款申请人年满21岁,那么规则的when条件是Applicant(age < 21)
| 1 2 3 4 5 6 7 |
rule "Underage"
when
application : LoanApplication()//表示存在Application事实对象且age属性满足<21
Applicant( age < 21 )
then
// Actions
end
|
-
then
规则的“then”部分也称为规则的右侧(RHS)包含在满足规则的条件部分时要执行的操作。如银行要求贷款申请人年满 21 岁(Applicant( age < 21 ))。不满足则拒绝贷款setApproved(false)
| 1 2 3 4 5 6 7 |
rule "Underage"
when
application : LoanApplication()
Applicant( age < 21 )
then
application.setApproved( false );
end
|
-
内置方法
Drools主要通过insert、update方法对工作内存中的fact数据进行操作,来达到控制规则引擎的目的。
操作完成之后规则引擎会重新匹配规则,原来没有匹配成功的规则在我们修改完数据之后有可能就匹配成功了。
注意:这些方法会导致重新匹配,有可能会导致死循环问题,在编写中最好设置属性no-loop或者lock-on-active属性来规避。
(1)insert:
作用:向工作内存中插入fact数据,并让相关规则重新匹配
| 1 2 3 4 5 6 7 8 |
rule "Underage"
when
Applicant( age < 21 )
then
Applicant application = new application();
application.setAge(22);
insert(application);//插入fact重新匹配规则,age>21的规则直接被触发
end
|
(2)update:
作用:修改工作内存中fact数据,并让相关规则重新匹配
| 1 2 3 4 5 6 7 8 |
rule "Underage"
when
Applicant( age < 21 )
then
Applicant application = new application();
application.setAge(22);
insert(application);//插入fact重新匹配规则,age>21的规则直接被触发
end
|
比较操作符
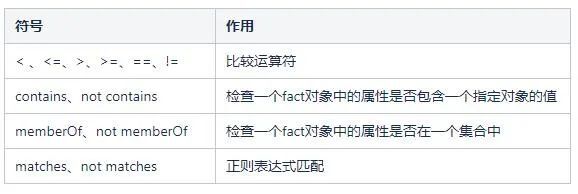
2.3 工程引入
2.3.1 配置文件的引入
需要有一个配置文件告诉代码规则文件drl在哪里,在drools中这个文件就是kmodule.xml,放置到resources/META-INF目录下。
说明:kmodule是6.0 之后引入的一种新的配置和约定方法来构建 KIE 库,而不是使用之前的程序化构建器方法。
| 1 2 3 4 5 6 7 8 9 10 11 |
<kmodule xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="KBase1" default="true" packages="org.domain.pkg1">
<ksession name="KSession2_1" type="stateful" default="true"/>
<ksession name="KSession2_2" type="stateless" default="false"/>
</kbase>
<kbase name="KBase2" default="false" packages="org.domain.pkg2, org.domain.pkg3">
<ksession name="KSession3_1" type="stateful" default="false">
</ksession>
</kbase>
</kmodule>
|
-
Kmodule 中可以包含一个到多个 kbase,分别对应 drl 的规则文件。
-
Kbase 是所有应用程序知识定义的存储库,包含了若干的规则、流程、方法等。需要一个唯一的name,可以取任意字符串。
KBase的default属性表示当前KBase是不是默认的,如果是默认的则不用名称就可以查找到该 KBase,但每个 module 最多只能有一个默认 KBase。
KBase下面可以有一个或多个 ksession,ksession 的 name 属性必须设置,且必须唯一。
-
packages 为drl文件所在resource目录下的路径,多个包用逗号分隔,通常drl规则文件会放在工程中的resource目录下。
2.3.2 代码中的使用
KieServices:可以访问所有 Kie 构建和运行时的接口,通过它来获取的各种对象(例如:KieContainer)来完成规则构建、管理和执行等操作。
KieContainer:KieContainer是一个KModule的容器,提供了获取KBase的方法和创建KSession的方法。其中获取KSession的方法内部依旧通过KBase来创建KSession。
KieSession:KieSession是一个到规则引擎的对话连接,通过它就可以跟规则引擎通讯,并且发起执行规则的操作。例如:通过kSession.insert方法来将事实(Fact)插入到引擎中,也就是Working Memory中,然后通过kSession.fireAllRules方法来通知规则引擎执行规则。
| 1 2 3 4 5 6 7 |
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();
KieBase kBase1 = kContainer.getKieBase("KBase1"); //获取指定的KBase
KieSession kieSession1 = kContainer.newKieSession("KSession2_1"); //获取指定的KSession
kieSession1.insert(facts);//规则插入到工作内存
kSession.fireAllRules();//开始执行
kSession.dispose();//关闭对话
|
说明:以上案例是使用的Kie的API(6.x之后的版本)
2.4 模式匹配算法-RETE
Rete算法由Charles Forgy博士发明,并在1978-79年的博士论文中记录。Rete算法可以分为两部分:规则编译和运行时执行。
编译算法描述了如何处理生产内存中的规则以生成有效的决策网络。在非技术术语中,决策网络用于在数据通过网络传播时对其进行过滤。
网络顶部的节点会有很多匹配,随着网络向下延伸匹配会越来越少,在网络的最底部是终端节点。
关于RETE算法官方给出的说明比较抽象,这里我们结合具体案例进行说明。
2.4.1 案例说明
假设有以下事实对象:
A(a1=1,a2="A")
A(a1=2,a2="A2")
B(b1=1,b2="B")
B(b1=1,b2="B2")
B(b1=2,b2="B3")
C(c1=1,c2="B")
现有规则:
| 1 2 3 4 5 6 7 8 |
rule "Rete"
when
A(a1==1,$a:a1)
B(b1==1,b1==$a,$b:b2)
C(c2==$b)
then
System.out.print("匹配成功");
end
|
Bete网络:
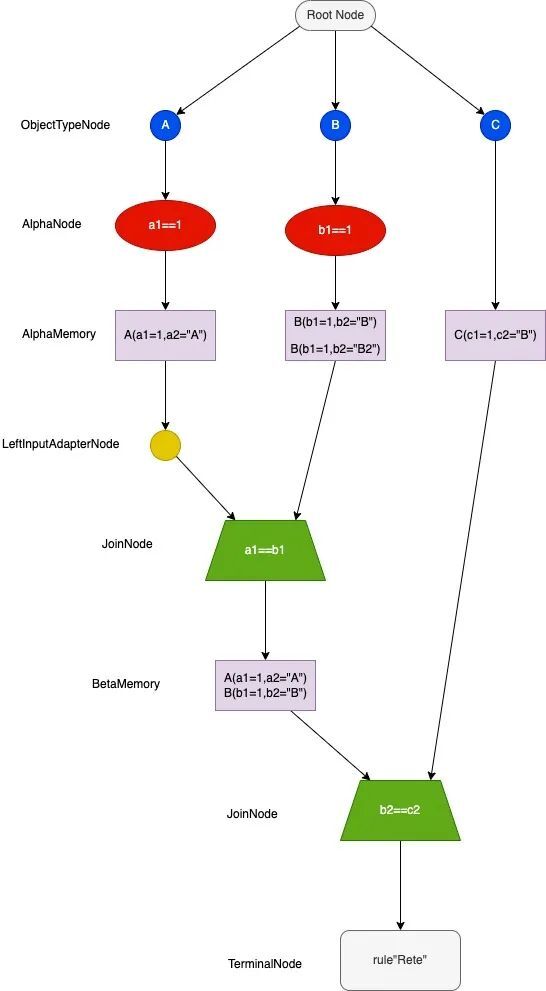
2.4.2 节点说明
1.Root Node:根节点是所有对象进入网络的地方
2.one-input-node(单输入节点)
【ObjectTypeNode】:对象类型节点是根节点的后继节点,用来判断类型是否一致
【AlphaNode】:用于判断文本条件,例如(name == "cheddar",strength == "strong")
【LeftInputAdapterNode】:将对象作为输入并传播单个对象。
3.two-input-node(双输入节点)
【BetaNode】:用于比较两个对象,两个对象可能是相同或不同的类型。上述案例中用到的join node就是betaNode的一种类型。join node 用于连接左右输入,左部输入的是事实对象列表,右部输入一个事实对象,在Join节点按照对象类型或对象字段进行比对。BetaNodes 也有内存。左边的输入称为 Beta Memory,它会记住所有传入的对象列表。右边的输入称为 Alpha Memory,它会记住所有传入的事实对象。
4.TerminalNode:
表示一条规则已匹配其所有条件,带有“或”条件的规则会为每个可能的逻辑分支生成子规则,因此一个规则可以有多个终端节点。
2.4.3 RETE网络构建流程
- 创建虚拟根节点
- 取出一个规则,例如 "Rete"
- 取出一个模式例如a1==1(模式:就是指when语句的条件,这里when条件可能是有几个更小的条件组成的大条件。模式就是指的不能再继续分割下去的最小的原子条件),检查参数类型(ObjectTypeNode),如果是新类型则加入一个类型节点;
- 检查模式的条件约束:对于单类型约束a1==1,检查对应的alphaNode是否已存在,如果不存在将该约束作为一个alphaNode加入链的后继节点;
- 若为多类型约束a1==b1,则创建相应的betaNode,其左输入为LeftInputAdapterNode,右输入为当前链的alphaNode;
- 重复4,直到该模式的所有约束处理完毕;
- 重复3-5,直到所有的模式处理完毕,创建TerminalNode,每个模式链的末尾连到TerminalNode;
- 将(Then)部分封装成输出节点。
2.4.4 运行时执行
- 从工作内存中取一工作存储区元素WME(Working Memory Element,简称WME)放入根节点进行匹配。WME是为事实建立的元素,是用于和非根结点代表的模式进行匹配的元素。
- 遍历每个alphaNode和ObjectTypeNode,如果约束条件与该WME一致,则将该WME存在该alphaNode的匹配内存中,并向其后继节点传播。
- 对每个betaNode进行匹配,将左内存中的对象列表与右内存中的对象按照节点约束进行匹配,符合条件则将该事实对象与左部对象列表合并,并传递到下一节点。
- 和3都完成之后事实对象列表进入到TerminalNode。对应的规则被触活,将规则注册进议程(Agenda)。
- 对Agenda里的规则按照优先级执行。
2.4.5 共享模式
以下是模式共享的案例,两个规则共享第一个模式Cheese( $cheddar : name == "cheddar" )
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
rule "Rete1"
when
Cheese( $cheddar : name == "cheddar" )
$person : Person( favouriteCheese == $cheddar )
then
System.out.println( $person.getName() + " likes cheddar" );
end
rule "Rete2"
when
Cheese( $cheddar : name == "cheddar" )
$person : Person( favouriteCheese != $cheddar )
then
System.out.println( $person.getName() + " does not like cheddar" );
end
|
网络图:(左边的类型为Cheese,右边类型为Person)
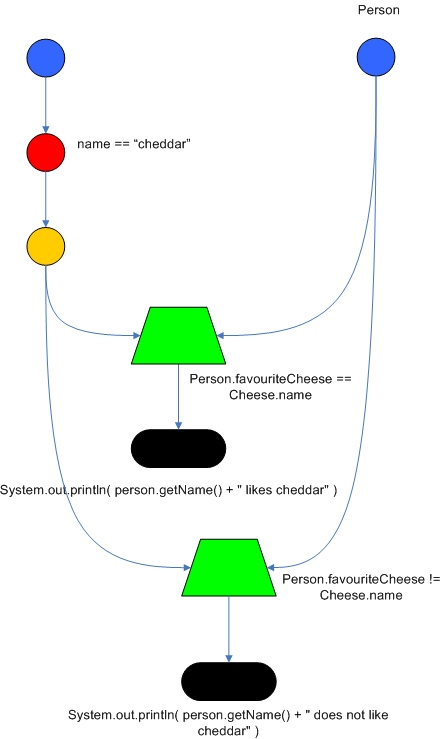
2.4.6 小结
rete算法本质上是通过共享规则节点和缓存匹配结果,获得性能提升。
【状态保存】:
事实集合中的每次变化,其匹配后的状态都被保存到alphaMemory和betaMemory中。在下一次事实集合发生变化时(绝大多数的结果都不需要变化)通过从内存中取值,避免了大量的重复计算。
Rete算法主要是为那些事实集合变化不大的系统设计的,当每次事实集合的变化非常剧烈时,rete的状态保存算法效果并不理想。
【节点共享】:
例如上面的案例不同规则之间含有相同的模式,可以共享同一个节点。
【hash索引】:
每次将 AlphaNode 添加到 ObjectTypeNode 后继节点时,它都会将文字值作为键添加到 HashMap,并将 AlphaNode 作为值。当一个新实例进入 ObjectType 节点时,它不会传播到每个 AlphaNode,而是可以从HashMap 中检索正确的 AlphaNode,从而避免不必要的文字检查。
存在问题:
- 存在状态重复保存的问题,匹配过多个模式的事实要同时保存在这些模式的节点缓存中,将占用较多空间并影响匹配效率。
- 不适合频繁变化的数据与规则(数据变化引起节点保存的临时事实频繁变化,这将让rete失去增量匹配的优势;数据的变化使得对规则网络的种种优化方法如索引、条件排序等失去效果)。
- rete算法使用了alphaMemory和betaMemory存储已计算的中间结果, 以牺牲空间换取时间, 从而加快系统的速度。然而当处理海量数据与规则时,beta内存根据规则的条件与事实的数目而成指数级增长, 所以当规则与事实很多时,会耗尽系统资源。
在Drools早期版本中使用的匹配算法是Rete,从6.x开始引入了phreak算法来解决Rete带来的问题。
关于phreak算法可以看官方介绍:https://docs.drools.org/6.5.0.Final/drools-docs/html/ch05.html#PHREAK
三、催收业务中的应用
3.1 问题解决
文章开头问题引出的例子中可以通过编写drl规则脚本实现,每次规则的变更只需要修改drl文件即可。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
package vivoPhoneTaskRule;
import com.worldline.wcs.service.rule.CaseSumNewWrapper;
rule "rule1"
salience 1
when
caseSumNew:CaseSumNewWrapper(overdueDD > a && overdueDD < b && overdueAmt <= W)
then
caseSumNew.setTaskType("A队列");
end
rule "rule2"
salience 2
when
caseSumNew:CaseSumNewWrapper(overdueDD > c && overdueDD < d && overdueAmt <= W)
then
caseSumNew.setTaskType("B队列");
end
rule "rule3"
salience 3
when
caseSumNew:CaseSumNewWrapper(overdueDD > e && overdueDD < f && overdueAmt <= W)
then
caseSumNew.setTaskType("C队列");
end
rule "rule4"
salience 4
when
caseSumNew:CaseSumNewWrapper(overdueDD > h && overdueDD < g && overdueAmt > W)
then
caseSumNew.setTaskType("D队列");
end
|
产生一个新的问题:
虽然通过编写drl可以解决规则维护的问题,但是让业务人员去编写这样一套规则脚本显然是有难度的,那么在催收系统中是怎么做的呢,我们继续往下看。
3.2 规则的设计
3.2.1 决策表设计
催收系统自研了一套决策表的解决方案,将drl中的条件和结果语句抽象成结构化数据进行存储并在前端做了可视化页面提供给业务人员进行编辑不需要编写规则脚本。例如新增规则:
将逾期天数大于a天小于b天且逾期总金额小于等于c的案件分配到A队列中。
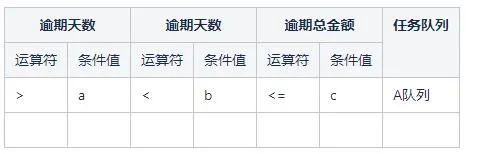
表中的每一行都对应一个rule,业务人员可以根据规则情况进行修改和添加,同时也可以根据条件定义对决策表进行拓展。
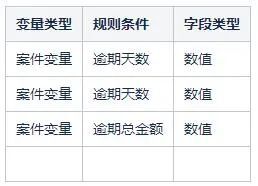
决策表的主要构成:

- 规则条件定义:定义了一些规则中用到的条件,例如:逾期天数,逾期金额等。
- 规则结果定义:定义了一些规则中的结果,例如:分配到哪些队列中,在队列中停留时间等。
- 条件字段:在编辑一条规则时,需要用到的条件字段(从条件定义列表中选取)。
- 比较操作符与值:比较操作符包括:< 、<=、>、>=、==、!=,暂时不支持contain,member Of,match等。
条件值目前包含数字和字符。条件字段+比较操作符+值,就构成了一个条件语句。
-
结果:满足条件后最终得到的结果也就是结果定义中的字段值。
3.2.2 规则生成
催收系统提供了可视化页面配置来动态生成脚本的功能(业务人员根据条件定义和结果定义来编辑决策表进而制定相应规则)。
核心流程:

1.根据规则类型解析相应的事实对象映射文件,并封装成条件实体entitys与结果实体resultDefs,文件内容如下图:
事实对象映射xml
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
<rule package="phoneTask">
<entitys>
<entity note="collectionCaseInfo" cls="com.worldline.wcs.service.rule.FactWrapper" alias="caseSumNew">
<attribute attr="caseSumNew.overdueDD" />
<attribute attr="caseSumNew.totalOverdueAmt"/>
</entity>
</entitys>
<resultDefs>
<resultDef key="1" seq="1" enumKey="ruleTaskType">
<script><![CDATA[caseSumNew.setTaskType("@param");]]></script>
</resultDef>
</resultDefs>
</rule>
|
2.根据规则类型查询规则集完整数据
3.将规则集数据与xml解析后的对象进行整合,拼装成一个drl脚本
4.将拼装好的脚本保存到数据库规则集表中
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
/**
* 生成规则脚本
* rule规则基本信息:包括规则表字段名定义等
* def 业务人员具体录入规则集的条件和结果等数据
*/
public String generateDRLScript(DroolsRuleEditBO rule, DroolsRuleTableBO def) {
//解析事实对象映射XML文件,生成条件定义与结果定义
RuleSetDef ruleSetDef = RuleSetDefHelper.getRuleSetDef(rule.getRuleTypeCode());
// 1.声明规则包
StringBuilder drl = new StringBuilder("package ").append(rule.getRuleTypeCode()).append(";\n\n");
HashMap<String, String> myEntityMap = Maps.newHashMap(); // k,v => caseSumNew,CaseSumNewWrapper
// 2.导入 entity 对应执行类
ruleSetDef.getEntitys().forEach(d -> {
String cls = d.getCls();
drl.append("import ").append(cls).append(";\n\n");
myEntityMap.put(d.getAlias(), cls.substring(cls.lastIndexOf('.') + 1));
});
// 3.规则脚本注释
drl.append("// ").append(rule.getRuleTypeCode()).append(" : ").append(rule.getRuleTypeName()).append("\n");
drl.append("// version : ").append(rule.getCode()).append("\n");
drl.append("// createTime : ").append(DateUtil.getSysDate(DateUtil.PATTERN_TIME_DEFAULT)).append("\n\n");
Map<String, String> myResultMap = def.getResultDefs().stream().collect(Collectors.toMap(DroolsRuleCondBO::getCondKey, DroolsRuleCondBO::getScript));
// 4.写规则
AtomicInteger maxRowSize = new AtomicInteger(0); // 总规则数
rule.getTables().forEach(table -> {
String tableCode = table.getTableCode();
table.getRows().stream().filter(r -> !Objects.equals(r.getStatus(), 3))
.forEach(row -> {
// 3.1.规则属性及优先级
drl.append("// generated from row: ").append(row.getRowCode()).append("\n");
//TODO 需要保证row.getRowSort()不重复,否则生成同样的规则编号
drl.append("rule \"").append(rule.getRuleTypeCode()).append("_").append(tableCode).append("_TR_").append(row.getRowSort()).append("\"\n"); // pkg_tableCode_TR_rowSort
drl.append("\tsalience ").append((maxRowSize.incrementAndGet())).append("\n");
// 4.2.条件判定
drl.append("\twhen\n");
// 每个entity一行,多条件合并
// when=condEntityKey:cls(condKeyMethod colOperator.drlStr colValue), 其中cls=myEntityMap.value(key=condEntityKey)
drl.append(
row.getColumns()
.stream().collect(Collectors.groupingBy(d -> d.getCondition().getCondEntityKey()))
.entrySet().stream()
.map(entityType -> "\t\t" + entityType.getKey() + ":" + myEntityMap.get(entityType.getKey()) + "(" +
entityType.getValue().stream()
.filter(col -> StringUtils.isNotBlank(col.getColValue())) // 排除无效条件
.sorted(Comparator.comparing(col -> col.getCondition().getCondSort())) // 排序
.map(col -> {
String condKey = col.getCondition().getCondKey();
String condKeyMethod = condKey.substring(condKey.indexOf('.') + 1);
String[] exec = ParamTypeHelper.get(col.getColOperator()).getDrlStr(condKeyMethod, col.getColValue());
if (exec.length > 0) {
return Arrays.stream(exec).filter(StringUtils::isNotBlank).collect(Collectors.joining(" && "));
}
return null;
})
.collect(Collectors.joining(" && ")) + ")\n"
)
.collect(Collectors.joining()));
// 4.3.规则结果
drl.append("\tthen\n");
row.getResults().forEach(r -> {
String script = myResultMap.get(r.getResultKey());
drl.append("\t\t").append(script.replace("@param", r.getResultValue())).append("\n"); // 使用 resultValue 替换 @param
});
drl.append("end\n\n");
});
});
return drl.toString();
}
|
3.2.3 规则执行
核心流程:

| 1 2 3 4 5 6 7 8 9 |
//核心流程代码:
KnowledgeBuilder kb = KnowledgeBuilderFactory.newKnowledgeBuilder();
kb.add(ResourceFactory.newByteArrayResource(script.getBytes(StandardCharsets.UTF_8)), ResourceType.DRL); //script为规则脚本
InternalKnowledgeBase base = KnowledgeBaseFactory.newKnowledgeBase();
KieSession ksession = base.newKieSession();
AgendaFilter filter = RuleConstant.DroolsRuleNameFilter.getFilter(ruleTypeCode);//获取一个过滤器
kSession.insert(fact);
kSession.fireAllRules(filter);
kSession.dispose();
|
- 根据规则类型从规则集表中查询drl脚本
- 将脚步添加至KnowledgeBuilder中构建知识库
- 获取知识库InternalKnowledgeBase(在新版本中对应 Kmodule中的Kbase)
- 通过InternalKnowledgeBase创建KieSession会话链接
- 创建AgendaFilter来制定执行某一个或某一些规则
- 调用insert方法将事实对象fact插入工作内存
- 调用fireAllRules方法执行规则
- 最后调用dispose关闭连接
四、总结
本文主要由催收系统中的一个案例引出规则引擎Drools,然后详细介绍了Drools的概念与用法以及模式匹配的原理Rete算法。最后结合催收系统给大家讲解了Drools在催收系统中是如何使用的。
通过规则引擎的引入让开发人员不再需要参与到规则的开发与维护中来,极大节约了开发成本。通过自研的催收系统可视化决策表,让业务人员可以在系统中灵活配置维护规则而不需要每次编写复杂的规则脚本,解决了业务人员的痛点。系统本质上还是执行的规则脚本,我们这里是把脚本的生成做了优化处理,先通过可视化页面录入规则以结构化的数据进行存储,再将其与规则定义进行整合拼装,最终由系统自动生成规则脚本。
当前催收系统中的规则引擎仍然存在着一些问题,例如:
- 催收系统通过动态生成脚本的方式适合比较简单的规则逻辑,如果想实现较为复杂的规则,需要写很多复杂的代码,维护成本比较高。
- 催收系统虽然使用的drools7.x版本,但是使用的方式依然使用的是5.x的程序化构建器方法(Knowledge API)
- 催收系统目前规则固定页面上只能编辑无法新增规则,只能通过初始化数据库表的方式新增规则。
后续我们会随着版本的迭代不断升级优化,感谢阅读。
参考文档:
分享 vivo 互联网技术干货与沙龙活动,推荐最新行业动态与热门会议。 转 https://www.cnblogs.com/vivotech/p/16921060.html 标签:Drools,贷后,when,rule,催收,drl,规则,append From: https://www.cnblogs.com/wl-blog/p/16940919.html