很久没有更文章了,主要是没有找到zero-shot learning(ZSL)方面我特别想要分享的文章,且中间有一段时间在考虑要不要继续做这个题目,再加上我懒 (¬_¬),所以一直拖到了现在。
最近科研没什么进展,就想着写一个ZSL的入门性的文章,目的是为了帮助完全没有接触过这方面,并有些兴趣的同学,能在较短的时间对ZSL有一定的认识,并且对目前的发展情况有一定的把握。
在此之前,需要提到的是:无论是论文笔记,还是总结性的读物,都包含了作者自己的理解和二次加工,想要做出好的工作必定需要自己看论文和总结。
零次学习(zero-shot learning)基本概念
每次在实验室做工作汇报的时候,总会把ZSL的基本概念讲一遍,但是每次的效果都不是很好,工作都讲完了,提的第一个问题依然是:ZSL到底是什么?这让我一度认为我的表达能力有问题。。。。。。不过回忆起我第一次接触这个题目的时候,也花了挺长的时间才搞清楚到底在做一件什么事情,那篇入门的文章[1]看了很久才基本看懂。因此,我尽量用最简单的,不带任何公式的方式来讲一下这到底是个什么问题。
假设小暗(纯粹因为不想用小明)和爸爸,到了动物园,看到了马,然后爸爸告诉他,这就是马;之后,又看到了老虎,告诉他:“看,这种身上有条纹的动物就是老虎。”;最后,又带他去看了熊猫,对他说:“你看这熊猫是黑白色的。”然后,爸爸给小暗安排了一个任务,让他在动物园里找一种他从没见过的动物,叫斑马,并告诉了小暗有关于斑马的信息:“斑马有着马的轮廓,身上有像老虎一样的条纹,而且它像熊猫一样是黑白色的。”最后,小暗根据爸爸的提示,在动物园里找到了斑马(意料之中的结局。。。)。
上述例子中包含了一个人类的推理过程,就是利用过去的知识(马,老虎,熊猫和斑马的描述),在脑海中推理出新对象的具体形态,从而能对新对象进行辨认。(如图1所示)ZSL就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力。
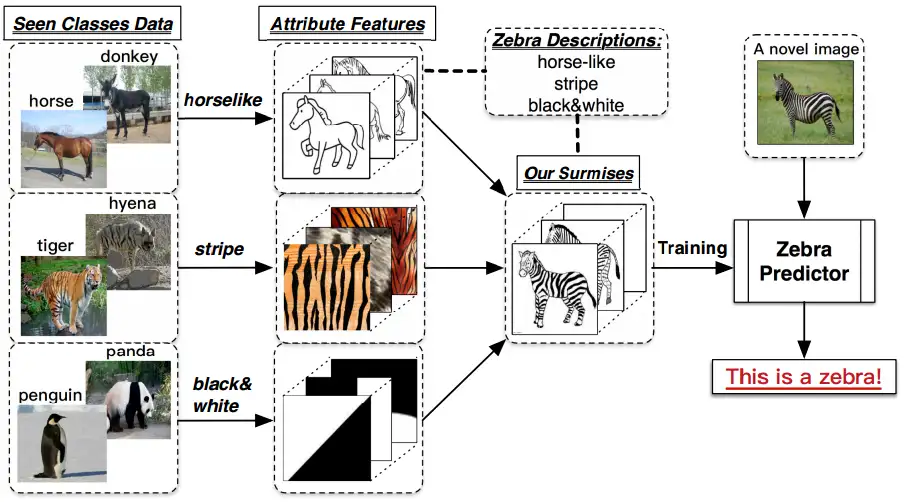 图1 ZSL概念图[17]
图1 ZSL概念图[17]
如今深度学习非常火热,使得纯监督学习在很多任务上都达到了让人惊叹的结果,但其限制是:往往需要足够多的样本才能训练出足够好的模型,并且利用猫狗训练出来的分类器,就只能对猫狗进行分类,其他的物种它都无法识别。这样的模型显然并不符合我们对人工智能的终极想象,我们希望机器能够像上文中的小暗一样,具有通过推理,识别新类别的能力。
ZSL就是希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。这样的能力听上去很具有吸引力,那么到底是怎么实现的呢?
假设我们的模型已经能够识别马,老虎和熊猫了,现在需要该模型也识别斑马,那么我们需要像爸爸一样告诉模型,怎样的对象才是斑马,但是并不能直接让模型看见斑马。所以模型需要知道的信息是马的样本、老虎的样本、熊猫的样本和样本的标签,以及关于前三种动物和斑马的描述。将其转换为常规的机器学习,这里我们只讨论一般的图片分类问题:
(1)训练集数据Xtr 及其标签 Ytr ,包含了模型需要学习的类别(马、老虎和熊猫),这里和传统的监督学习中的定义一致;
(2)测试集数据 Xte 及其标签 Yte ,包含了模型需要辨识的类别(斑马),这里和传统的监督学习中也定义一直;
(3)训练集类别的描述 Atr ,以及测试集类别的描述 Ate ;我们将每一个类别 yi∈Y ,都表示成一个语义向量 ai∈A 的形式,而这个语义向量的每一个维度都表示一种高级的属性,比如“黑白色”、“有尾巴”、“有羽毛”等等,当这个类别包含这种属性时,那在其维度上被设置为非零值。对于一个数据集来说,语义向量的维度是固定的,它包含了能够较充分描述数据集中类别的属性。
在ZSL中,我们希望利用 Xtr 和 Ytr 来训练模型,而模型能够具有识别 Xte 的能力,因此模型需要知道所有类别的描述 Atr 和 Ate 。ZSL这样的设置其实就是上文中小暗识别斑马的过程中,爸爸为他提供的条件。
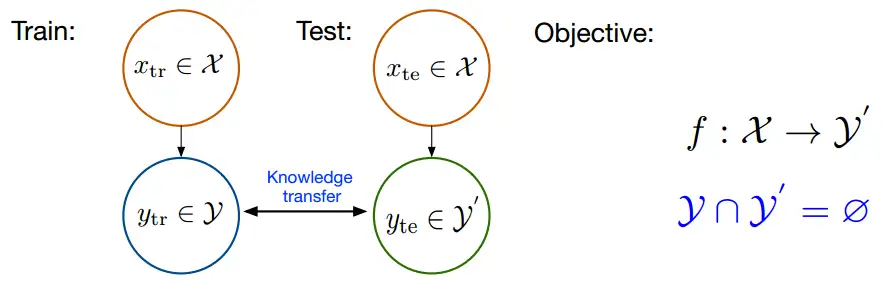 图2 ZSL设置图[16]
图2 ZSL设置图[16]
如图2,可以较为直观地了解ZSL的设置。
讲到这,很多同学可能会问:
(1)类别的描述 A 到底是怎么获取的?
答:有人工专家定义的,也有通过海量的附加数据集自动学习出来的,但前者的效果目前要好很多。
(2)这样做让人觉得有点失望呀!我希望模型能够在没有斑马样本的情况下,识别斑马,而现在,虽然我不需要为模型提供斑马的样本,但是却要为每一个类别添加一种描述,更离谱的是我还需要斑马(测试集)的描述,这个过程并没有想象中智能诶!
答:的确,在我们的想象中,我们期待的智能是:只给机器马、老虎和熊猫,然后它就可以识别斑马了,这样多爽,多神奇。但我们回过头去,再想想小暗的思考过程,如果爸爸不告诉小暗关于斑马的任何信息,那么当小暗看见斑马的时候,并不会知道它是什么,只是小暗能够描述它:“这是一匹有着黑白颜色条纹的马。”这里,有同学可能又会说:至少我们可以不用告诉小暗类别的描述呀,但是ZSL就不行。其实,我们是需要告诉小暗类别描述的,或者说小暗在之前就学习到了类别描述,比如怎样的图案是“条纹”,怎样的颜色称为“黑白色”,这样的属性定义。对于一个模型来说,它就像刚出生的婴儿,我们需要教会它这些属性的定义。
(3)就算是这样,需要实现定义这个描述 A 还是很蛋疼的一件事情。
答:(1)中就有提到,描述 A 可以自动学习,我们将小暗已经掌握的知识描述为一个知识库,这个知识库里就有对各种属性的定义;而能够模仿人类知识库的最好东西就是“百度百科”,“维基百科”等等各种百科,我们可以利用百科中的各种定义,生成类别的定义,这方面侧重于NLP,因此不进一步讨论。
在此,我们小小总结一下ZSL问题的定义。利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
目前的研究方式
在上文中提到,要实现ZSL功能似乎需要解决两个部分的问题:第一个问题是获取合适的类别描述 A ;第二个问题是建立一个合适的分类模型。
目前大部分工作都集中在第二个问题上,而第一个问题的研究进展比较缓慢。个人认为的原因是, 目前A 的获取主要集中于一些NLP的方法,而且难度较大;而第二个问题能够用的方法较多,比较容易出成果。
因此,接下来的算法部分,也只介绍研究分类模型的方法。
数据集介绍
先介绍数据集,是因为希望在算法介绍部分,直接给出实例,让大家能够直接上手,这里顺便插个沐神
@李沐 的感悟。
虽然在我认识的人里,好些人能够读一篇论文或者听一个报告后就能问出很好的问题,然后就基本弄懂了。但我在这个上笨很多。读过的论文就像喝过的水,第二天就不记得了。一定是需要静下心来,从头到尾实现一篇,跑上几个数据,调些参数,才能心安地觉得懂了。例如在港科大的两年读了很多论文,但现在反过来看,仍然记得可能就是那两个老老实实动手实现过写过论文的模型了。即使后来在机器学习这个方向又走了五年,学习任何新东西仍然是要靠动手。——李沐(MXNet开发者)
(1)Animal with Attributes(AwA)官网:Animals with Attributes
提出ZSL定义的作者,给出的数据集,都是动物的图片,包括50个类别的图片,其中40个类别作为训练集,10个类别作为测试集,每个类别的语义为85维,总共有30475张图片。但是目前由于版权问题,已经无法获取这个数据集的图片了,作者便提出了AwA2,与前者类似,总共37322张图片。
(2)Caltech-UCSD-Birds-200-2011(CUB)官网:Caltech-UCSD Birds-200-2011
全部都是鸟类的图片,总共200类,150类为训练集,50类为测试集,类别的语义为312维,有11788张图片。
(3)Sun database(SUN)官网:SUN Database
总共有717个类别,每个类别20张图片,类别语义为102维。传统的分法是训练集707类,测试集10类。
(4)Attribute Pascal and Yahoo dataset(aPY)官网:Describing Objects by their Attributes
共有32个类,其中20个类作为训练集,12个类作为测试集,类别语义为64维,共有15339张图片。
(5)ILSVRC2012/ILSVRC2010(ImNet-2)
利用ImageNet做成的数据集,由ILSVRC2012的1000个类作为训练集,ILSVRC2010的360个类作为测试集,有254000张图片。它由 4.6M 的Wikipedia数据集训练而得到,共1000维。
上述数据集中(1)-(4)都是较小型(small-scale)的数据集,(5)是大型(large-scale)数据集。虽然(1)-(4)已经提供了人工定义的类别语义,但是有些作者也会从维基语料库中自动提取出类别的语义表示,来检测自己的模型。
这里给大家提供一些已经用GoogleNet提取好的数据集图片特征,大家可以比较方便地使用。Zero-Shot Learing问题数据集分享(GoogleNet 提取)
基础算法介绍
在此,只具体介绍最简单的方法,让大家可以快速上手。我们面对的是一个图片分类问题,即对测试集的样本 Xte 进行分类,而我们分类时需要借助类别的描述 A ,由于每一个类别 yi∈Y ,都对应一个语义向量 ai∈A ,因此我们现在可以忘掉 Y ,直接使用 A 。我们把 X (利用深度网络提取的图片特征,比如GoogleNet提取为1024维)称为特征空间(visual feature space),把类别的语义表示 A ,称为语义空间。我们要做的,其实就是建立特征空间与语义空间之间的映射。
对于分类,我们能想到的最简单的形式就是岭回归(ridge regression),俗称均方误差加范数约束,具体形式为:
min||XtrW−Atr||2+ηΩ(W) (1)
其中, Ω() 通常为2范数约束, η 为超参,对 W 求导,并让导为0,即可求出 W 的值。测试时,利用 W 将 xi∈Xte 投影到语义空间中,并在该空间中寻找到离它最近的 ai∈Ate ,则样本的类别为 ai 所对应的标签 yi∈Ytr 。
简单写一个matlab实现。
regression_lambda = 1.0;
W = ridge_regression(param.train_set, param.train_class_attributes, regression_lambda , 1024);
S_test = param.test_set * W;
[zsl_accuracy]= zsl_el(S_test, param.S_te, param);
fprintf('AwA ZSL accuracy on test set: %.1f%%\n', zsl_accuracy*100);我们使用AwA数据集,图片事先利用GoogleNet提取了特征(1024维),在测试集上可以得到59.1%的准确率。
这样一个岭回归之所以有效,是因为训练集类别语义 Atr 与测试集类别语义 Ate 之间存在的密切联系。其实任何ZSL方法有效的基础,都是因为这两者之间具体的联系。
仅仅利用如此naive的方式,得到的结果显然不能满足我们的要求,那么建立更好的模型,则需要进一步了解ZSL问题中,存在着哪些和传统监督分类的差异。
ZSL中存在的问题
在此,介绍一些目前ZSL中主要存在的问题,以便让大家了解目前ZS领域有哪些研究点。
领域漂移问题(domain shift problem)
该问题的正式定义首先由[2]提出。简单来说,就是同一种属性,在不同的类别中,视觉特征的表现可能很大。如图3所示,斑马和猪都有尾巴,因此在它的类别语义表示中,“有尾巴”这一项都是非0值,但是两者尾巴的视觉特征却相差很远。如果斑马是训练集,而猪是测试集,那么利用斑马训练出来的模型,则很难正确地对猪进行分类。
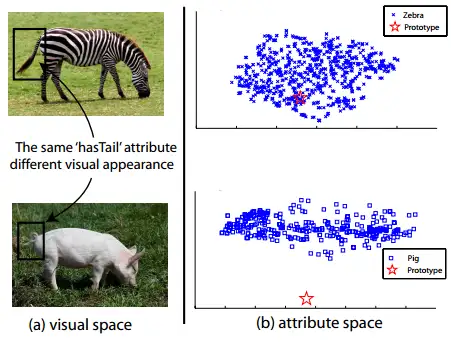 图3 domain shift示意图,图中的prototype表示类别在语义空间中的位置[2]
图3 domain shift示意图,图中的prototype表示类别在语义空间中的位置[2]
枢纽点问题(Hubness problem)
这其实是高维空间中固有的问题:在高维空间中,某些点会成为大多数点的最近邻点。这听上去有些反直观,细节方面可以参考[3]。由于ZSL在计算最终的正确率时,使用的是K-NN,所以会受到hubness problem的影响,并且[4]中,证明了基于岭回归的方法会加重hubness problem问题。
语义间隔(semantic gap)
样本的特征往往是视觉特征,比如用深度网络提取到的特征,而语义表示却是非视觉的,这直接反应到数据上其实就是:样本在特征空间中所构成的流型与语义空间中类别构成的流型是不一致的。(如图4所示)
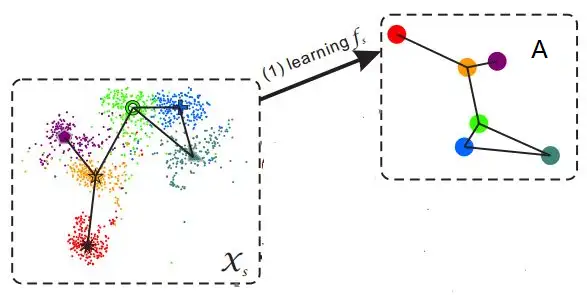 图4 流型不一致示意图[8]
图4 流型不一致示意图[8]
这使得直接学习两者之间的映射变得困难。
还有其他的,比如semantic loss[5]问题,样本通过映射坍塌到一点[6]等,由于还不常研究,在此就不再讨论。
在此,我们给出解决上述三个问题的基本方法,从而更加深度地了解这三个问题。
(1)领域漂移
由于样本的特征维度往往比语义的维度大,所以建立从 X 到 S 的映射往往会丢失信息,为了保留更多的信息,保持更多的丰富性,最流行的做法是将映射到语义空间中的样本,再重建回去,这样学习到的映射就能够得到保留更多的信息。因此,在原来简单岭回归[1]的基础上,可以将目标函数改为:[7]
min||Xtr−WTAtr||2+λ||WXtr−Atr||2 (2)
从目标函数可以看出,这其实完成的是一个简易的自编码器过程,我们简称这个算法为SAE,利用matlab可以轻松对其实现。
lambda1 = 800000;
W = SAE(param.train_set', param.train_class_attributes', lambda1);
S_test = param.test_set * NormalizeFea(W');
[zsl_accuracy]= zsl_el(S_test, param.S_te, param);
fprintf('AwA ZSL accuracy on test set: %.1f%%\n', zsl_accuracy*100);依然是在AwA上进行测试,可以得到83.2%的准确率,比简单的岭回归(1)提高了24.1%。自编码器的这个结构目前在ZSL方法中非常流行,稍后我们还会提到。
(2)枢纽点问题
目前对于枢纽点问题的解决主要有两种方法:
a. 如果模型建立的方式为岭回归,那么可以建立从语义空间到特征空间的映射,从而不加深hubness problem对结果的影响[4],也就是说将目标函数(1)改为:
min||Xtr−AtrW||2+ηΩ(W) (3)
在AwA数据集上,这种简单的改变能够得到76.5%的正确率,比原本提高了17.4%。
b.可以使用生成模型,比如自编码器、GAN等,生成测试集的样本,这样就变成了一个传统的监督分类问题,不存在K-NN的操作,所以不存在hubness problem的影响。
(3)语义间隔问题
语义间隔问题的本质是二者的流形结构不一致,因此,解决此问题的着手点就在于将两者的流形调整到一致,再学习两者之间的映射[8]。最简单的方法自然是将类别的语义表示调整到样本的流型上,即用类别语义表示的K近邻样本点,重新表示类别语义即可。
有关ZSL的一些其他的概念
这里将提到一些ZSL涉及到的其他概念。
(1)直推式学习(Transductive setting)
这里的直推式学习其实是指在训练模型的时候,我们可以拿到测试集的数据,只是不能拿到测试集的样本的标签,因此我们可以利用测试集数据,得到一些测试集类别的先验知识。这种设置在迁移学习中很常见。
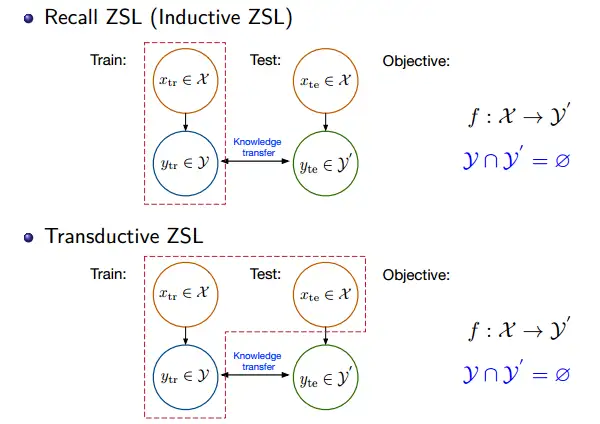 图5 非直推式(inductive)和直推式学习的区别[16]
图5 非直推式(inductive)和直推式学习的区别[16]
(2)泛化的ZSL(generalized ZSL)
上文中提到的ZSL,在测试时使用K-NN进行正确率的评估时,只在测试类别中找最近邻的类别,但是在现实的问题中,拿到的样本也可能属于训练集类别,因此在测试时,同时加入训练集类别。[9]现在的很多方法都开始测试模型在这种设置下的能力。
推荐阅读的论文
我一直不想写ZSL的发展史,因为据我的经验,写了一大段发展史之后,往往大家的兴致不高,而且看完之后一般都不会有什么特别的感觉,基本也记不得什么东西。所以倒不如给大家推荐一些论文,从最早的到目前最新的,使得大家在短时间内能对ZSL的发展有一个大概的概念。
(1)Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer[1]
ZSL问题的开创性文章,当然是必读的喽,而且可以顺便看看别人是如何阐述一个新问题(挖坑)的。
(2)An embarrassingly simple approach to zero-shot learning[10]
有着很强的理论基础,算法简单、有效,虽然已经过去很多年了,但还是目前新工作需要进行对比的方法之一。
(3)Transductive Multi-View Zero-Shot Learning[2]
第一次定义了domain shift问题。
(4)Zero-shot recognition using dual visualsemantic mapping paths[11]
解决semantic gap问题的简单做法。
(5)Predicting visual exemplars of unseen classes for zero-shot learning[12]
从本质的角度出发,将ZSL问题,看作聚类问题,用最简单的方法直接建立映射。
(6)Semantic Autoencoder for Zero-Shot Learning[7]
引入自编码器结构的第一篇文章,直接导致现在出现的新方法大都具有这种结构。
(7)Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly[14]
综述性的文章,总结了17年底以前的方法,提出了新的评价标准,对当时领域发展比较混乱的地方做出了一些更标准的评估。
(8)Zero-Shot Learning via Class-Conditioned Deep Generative Models[6]
将[7]改造为深度模型,并加上一些其他的约束。
(9)Preserving Semantic Relations for Zero-Shot Learning[13]
在自编码器结构的基础上,显示地加入语义类别之间的关系约束。
(10)Recent Advances in Zero-shot Recognition[15]
综述性的文章,读起来很顺畅,可以看看别人是怎么写综述,中顶刊的。
以上几篇文章,是我认为较有代表性,比较值得读的工作。
代码
有很多工作,作者都是提供代码的,我自己也实现了一些工作,如果有时间我会将其整理在一起,方便大家使用。
我自己的看法
我当初做这个课题,纯粹是因为项目的需要,再加上当时并没有想清楚自己要做什么,所以就做着试试了。目前这个领域属于很好发论文的阶段,而且并不需要十分深刻的理解,就能发不错等级的文章,比较容易能够看到它的发展趋势及下一步大家扎堆的地方,很多时候是在拼速度,而不是拼想法。但好发论文,并不代表它发展迅速,在我看来,真正有贡献的工作少之又少,且其对本质的研究发展缓慢。并且,该问题离实际应用还太远,很可能并不属于这个时代。基于这些原因,之前有一段时间很不想再继续这个课题。。。
总结
稍微总结一下,其实我也不知道要总结什么,只是习惯了每篇文章最后都要写个总结。花了大概一天的时间,写了这篇ZSL入门文章。写它一方面是因为希望能够有一篇ZSL的入门性质的读物,为大家提供便利;另一方面就是近期科研不顺,总是怀疑自己不是读书的料,写写文章让自己心情好些。希望大家阅读之后,能够得到一定的帮助吧!
其他
文章仓促之下写的,没有经过什么构思,就是想到哪,写到哪。后面我应该还会修改,添加一些其他的内容,如果大家有什么问题,欢迎评论或者私信。
祝大家科研顺利!为人类理解这个世界做一点点贡献!
参考文献
[1]Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer
[2]Transductive Multi-View Zero-Shot Learning.
[3]Hubness and Pollution: Delving into Class-Space Mapping for Zero-Shot Learning.
[4]Ridge Regression, Hubness, and Zero-Shot Learning.
[5]Zero-Shot Visual Recognition using Semantics-Preserving Adversarial Embedding Network.
[6]Zero-Shot Learning via Class-Conditioned Deep Generative Models.
[7]Semantic Autoencoder for Zero-Shot Learning.
[8]Zero-Shot Recognition using Dual Visual-Semantic Mapping Paths.
[9]An Empirical Study and Analysis of Generalized Zero-Shot Learning for Object Recognition in the Wild.
[10]An embarrassingly simple approach to zero-shot learning
[11]Zero-shot recognition using dual visualsemantic mapping paths
[12]Predicting visual exemplars of unseen classes for zero-shot learning
[13]Preserving Semantic Relations for Zero-Shot Learning
[14]Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly
[15]Recent Advances in Zero-shot Recognition
[16]http://people.duke.edu/~ww107/material/ZSL.pdf
[17]Attribute-Based Synthetic Network (ABS-Net): Learning More From Pseudo Feature Representation
标签:零次,Shot,语义,类别,Zero,ZSL,斑马 From: https://www.cnblogs.com/end/p/16931459.html