Telegraf简介
Telegraf是一个基于插件的开源指标采集工具。本身是为InfluxDB(一款时序数据库)量身打造的数据收集器,但是它过于优秀,能够将抓取的数据写到很多地方,尤其在时序数据库领域,很多时序数据库都能够与它配合使用。通常,它每隔一段时间抓取一批指标数据(比如机器的CPU使用情况,磁盘的IO,网络情况,MySQL服务端的的会话数等等)并将他们发送到时序数据库、消息队列中或者自定义导出到某个地方。供下游的应用处理(比如报警)。Telegraf也能够对外提供一个服务,等待客户端推送数据。
它与logstash类似,只不过logstash是收集日志的。telegraf是收集指标的。
官方提供了300多个可选的插件,另外Telegraf是易于拓展的,如果官方的插件无法满足你的需求,你随时可以在Telegraf的基础上写出自己的插件。
安装部署Telegraf
官方下载页面:https://portal.influxdata.com/downloads/
我的服务器是centos的,所以选择centos安装:
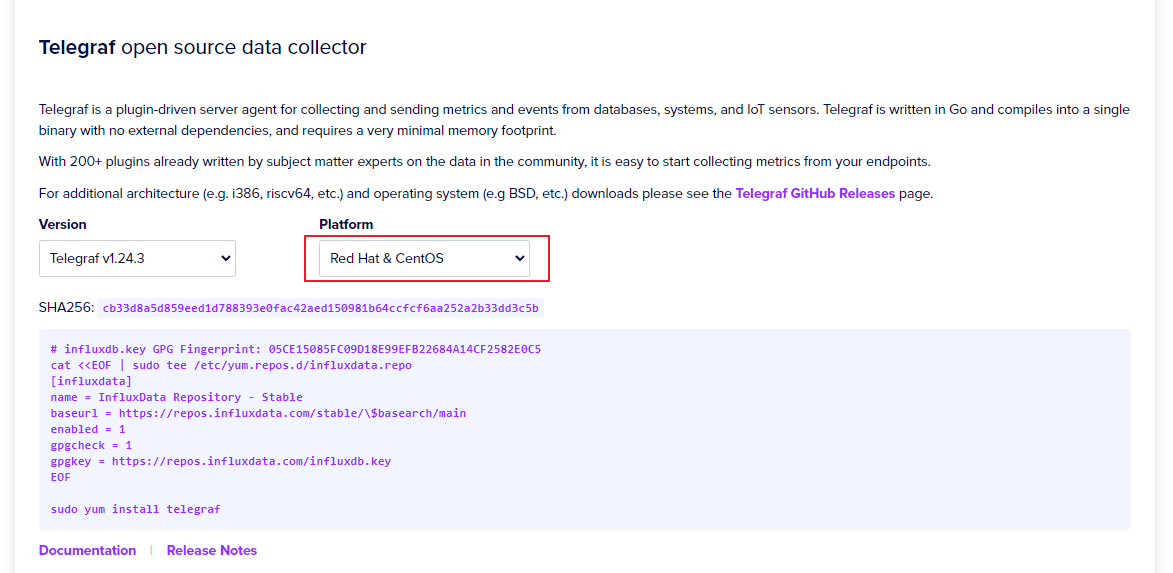
# influxdb.key GPG Fingerprint: 05CE15085FC09D18E99EFB22684A14CF2582E0C5
cat <<EOF | sudo tee /etc/yum.repos.d/influxdata.repo
[influxdata]
name = InfluxData Repository - Stable
baseurl = https://repos.influxdata.com/stable/\$basearch/main
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
EOF
sudo yum install telegraf -y
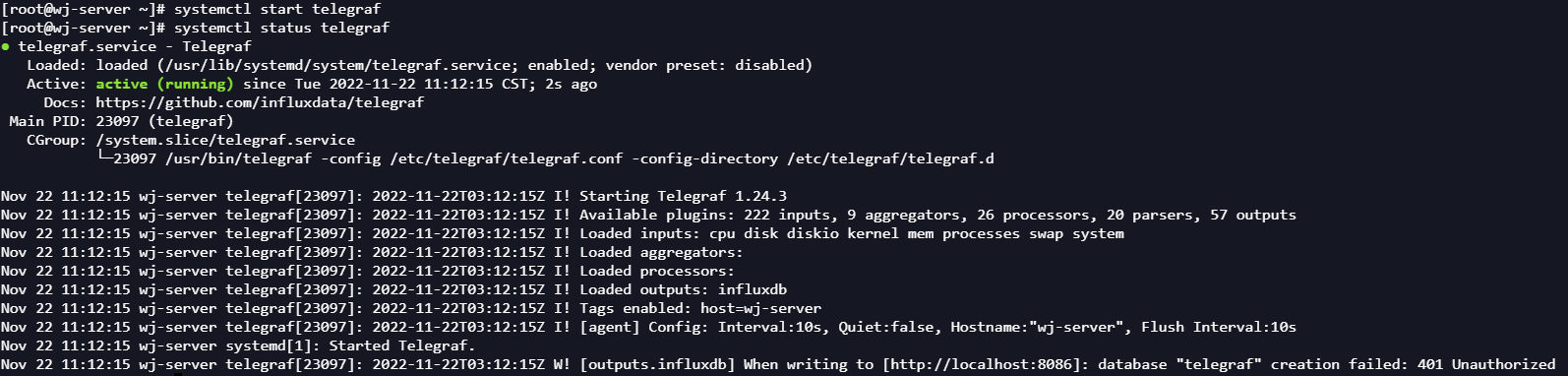
启动telegraf:
systemctl start telegraf
systemctl status telegraf
极简入门
示例1:收集cpu时序数据
创建一个目录,专门放telegraf的配置文件。
mkdir -p /opt/module/telegraf_conf
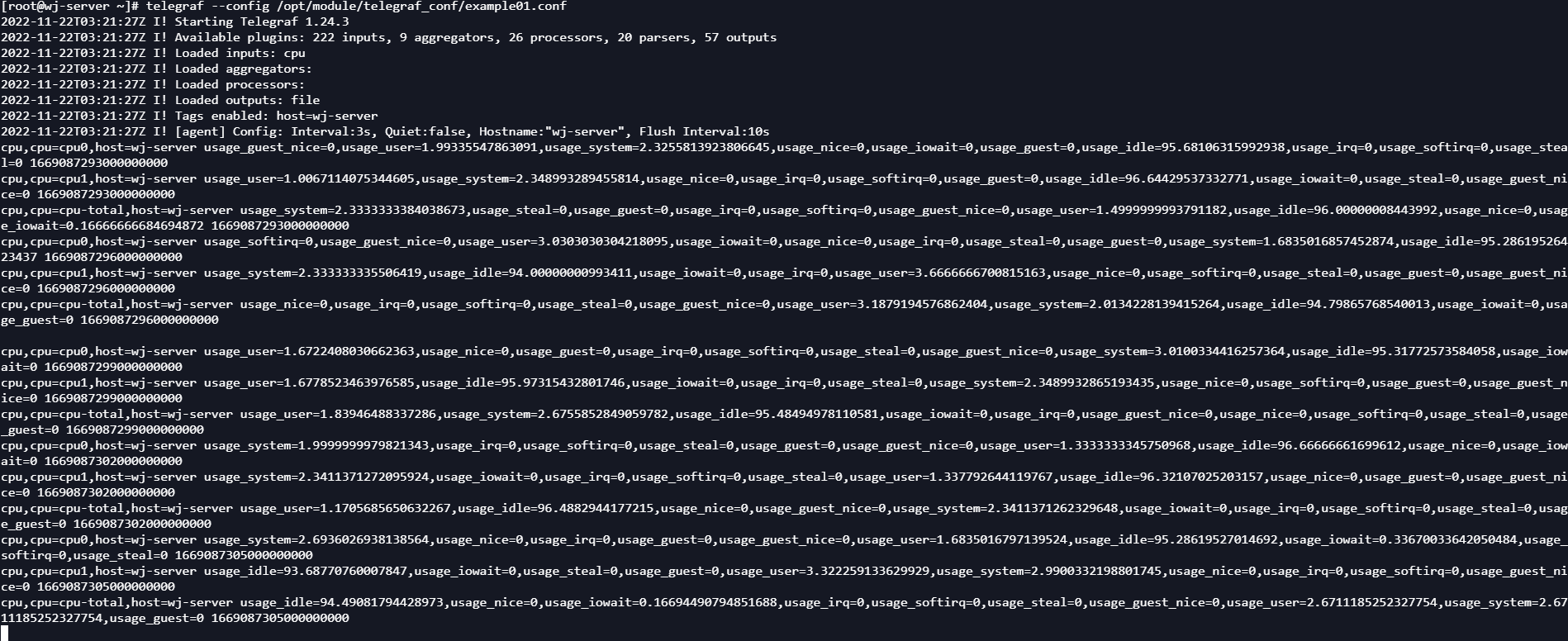
vim /opt/module/telegraf_conf/example01.conf
#输入以下内容
[agent]
interval = "3s"
[[inputs.cpu]]
percpu = true
totalcpu = true
collect_cpu_time = false
report_active = false
core_tags = false
[[outputs.file]]
files = ["stdout"]
配置文件内容是每隔3S采集一次CPU监控信息,并把信息输出到linux标准输出(控制台)中。
运行,观察控制台输出:
telegraf --config /opt/module/telegraf_conf/example01.conf
基本说明
配置文件:
example01.conf配置文件涉及到3个配置块。
[ agent ] 这里面是一些涉及全局的配置。此处我们设置interval="3s",意思是让配置文件中的所有input插件每隔3秒去采集一次指标。interval的默认值是10秒。
[[ inputs.cpu ]] 这是一个input输入组件,这里的配置是说我们导出的指标会包含每一个CPU核的使用情况,而且还包含所有CPU总的使用情况。
[[ outputs.file ]] 这是一个output输出组件,这里我们用了一个名为file的输出组件,不过files参数设为了 stdout (标准输出)也就是控制台,这样程序运行起来我们应该可以看到数据打印在控制台上。
控制台输出内容:
首先输出的是Telegraf进程的描述信息:

(1)当前Telegraf的版本号为1.23.2
(2)加载的input插件列表(目前就1个):cpu
(3)加载的aggregator插件列表(目前没有)
(4)加载的processors插件列表(目前没有)
(5)加载的output插件列表(目前就1个):file
(6)Tags enable,开启了全局的标签集,全局的指标数据都会加上host=wj-server这个标签
(7)agent Config,全局配置
-
Interval : 3s,所有的input组件每3s采集一次指标数据,
-
Quiet:false,不使用安静模式运行。
-
Hostname:"wj-server",机器名称wj-server
-
Flush Interval:10s 所有的output组件每10s输出一次指标数据。所以,telegraf运行后,你应该每隔10秒,看到控制台上有一批输出。
数据输出:
在Telegraf的配置内容输出完毕后,我们可以看到一堆密密麻麻的数据。你会发现它不像json,也不像csv。这其实是Telegraf内置的数据结构,叫做InfluxDB行协议。
关于InflushDB行协议可参考:InfluxDB(2):行协议
示例2:启用处理插件
接下来,我们在example01.conf的基础上稍作改进,编写一个新的配置文件example02.conf。
vim /opt/module/telegraf_conf/example02.conf
[agent]
interval = "3s"
flush_interval = "5s"
[global_tags]
user="wj"
[[inputs.cpu]]
percpu = true
totalcpu = true
collect_cpu_time = false
report_active = false
core_tags = false
[[processors.converter]]
[processors.converter.tags]
measurement = ["cpu"]
[[outputs.file]]
files = ["stdout"]
运行telegraf:
telegraf --config /opt/module/telegraf_conf/example02.conf
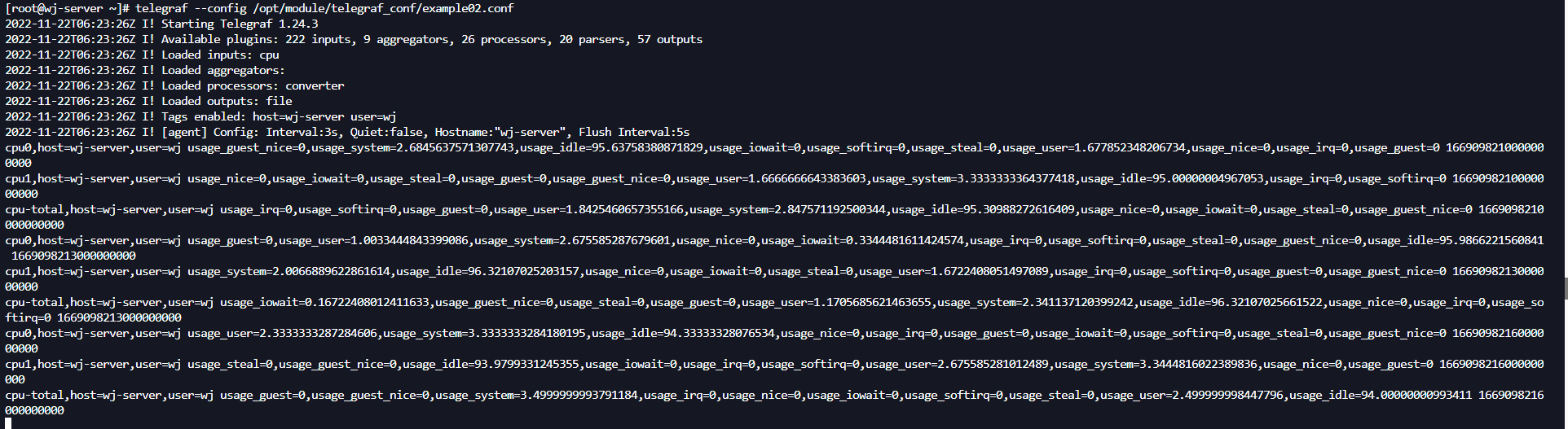
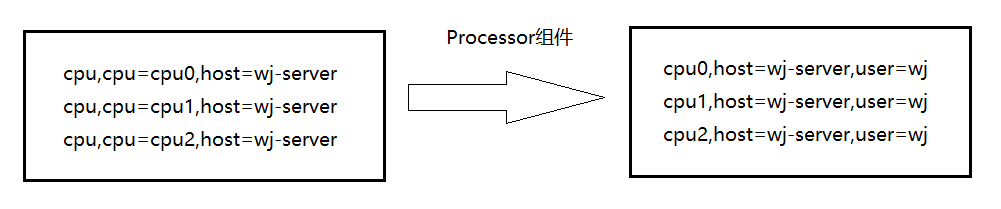
可以观察到,输出的行的测量名称变了。(CPU标签里面的值替换成测量名称)
插件文档:Plugin directory | Telegraf 1.24 Documentation (influxdata.com)
首先注意,如果你正在使用Telegraf的1.23版本,那么你看插件文档的时候,也应该去看1.23版本的文档。这是因为Go语言开发的项目,会把整个项目涉及的东西编译到一个单独的二进制可执行文件中。
而且这个可执行文件里面写的全部都是本地码(native-code),不需要专门的Go语言执行环境,操作系统环境直接可以让它运行起来。
介于此,Telegraf的插件和框架核心代码是编译在一块的,它们都在一个可执行文件中。
因此v1.23中特有的插件,前面的版本就不会有,除非把旧版本的Telegraf源码下下来,然后把想要的插件源码写进去再重新编译。
注意!上面说的是Telegraf的内置插件,Telegraf还为我们留了一个exec Input插件,通过这个插件,我们可以和外部的捕捉指标数据的插件进行集成.
Telegraf命令行用法
Telegraf安装好之后,就可以使用telegraf命令了。
用法:
telegraf [ 命令 ]
telegraf [ 选项 ]
命令
config : 将完整的示例配置打印到标准输出(stdout 控制台)
version : 将版本号打印到标准输出(stdout 控制台)
选项
| 参数 | 描述 |
|---|---|
| --aggregator-filter <filter> | 筛选要启用聚合器,分隔符为 |
| --config <file> | 要加载的配置文件 |
| --config-directory <directory> | 包含其他配置文件的目录。其中的配置文件名需要以.conf收尾 |
| --deprecation-list | 打印所有已弃用的插件或插件选项。 |
| --watch-config | 在本地的配置文件更改时,重启Telegraf进程,监听方式使用的是文件系统的通知或者轮询文件。--watch-config功能默认是关闭的。 |
| --plugin-directory <directory> | 插件目录,会以递归的方式搜索这个目录,来找到可用的插件,找到的插件会被加载。插件文件的后缀是.so |
| --debug | 启动debug级别的日志文件 |
| --input-filter <filter> | 过滤要启用的输入插件,分隔符为 : 。 |
| --input-list | 打印可用的输入插件 |
| --output-filter | 过滤要启用的输出插件,分隔符为 : 。 |
| --output-list | 打印可用的输出插件 |
| --pidfile <file> | 要将pid写入到哪个文件。 |
| --pprof-addr <address> | pprof地址,默认情况下禁用。pprof是Go中分析程序运行性的工具,它能够提供各种性能数据。比如,内存分配情况的采样信息、对上内存的使用情况采样信息等。 |
| --processor-filter <filter> | 筛选要启用的filter插件,插件之间使用 : 分隔。 |
| --quiet | 在安静模式下运行 |
| --section-filter <filter> | 这个参数和config命令一起使用才有意义。过滤要打印的配置段(agent,global_tags,outputs,processors,aggregators和inputs)。配置段之间用 : 分隔。 |
| --sample-config | 打印完整的示例配置(和config命令的作用一样) |
| --once | 收集一次指标,写出,然后退出进程。 |
| --test | 收集一次指标并打印一次,然后退出进程。 |
| --test-wait | telegraf进程在test或once模式下,进行一次input所需要的秒数。 |
| --usage <plugin> | 打印插件的用法。(比如:telegraf --usage mysql) |
| --version | 打印Telegraf的版本号 |
运行单个的Telegraf配置文件并打印到控制台:(只打印一次,测试配置文件内容)
telegraf --config /opt/module/telegraf_conf/example02.conf --test

生成仅定义了CPU输入和InfluxDB输出的配置文件:
telegraf --input-filter cpu --output-filter influxdb config
运行一个配置文件中的所有插件:
telegraf --config telegraf.conf
运行Telegraf时开启pprof:
telegraf --config /opt/module/telegraf_conf/example02.conf --pprof-addr localhost:6060

使用远程配置:
Telegraf的--cofnig参数还能指定一个URL,让telegraf通过网络远程获取配置文件。
telegraf --config http://localhost:8080/example01.conf
获取配置文件,而且数据也能够正常输出,但是不能监听配置的变化。
输出示例配置文件:
telegraf --input-filter cpu:mem --processor-filter converter --aggregator-filter minmax --output-filter file config
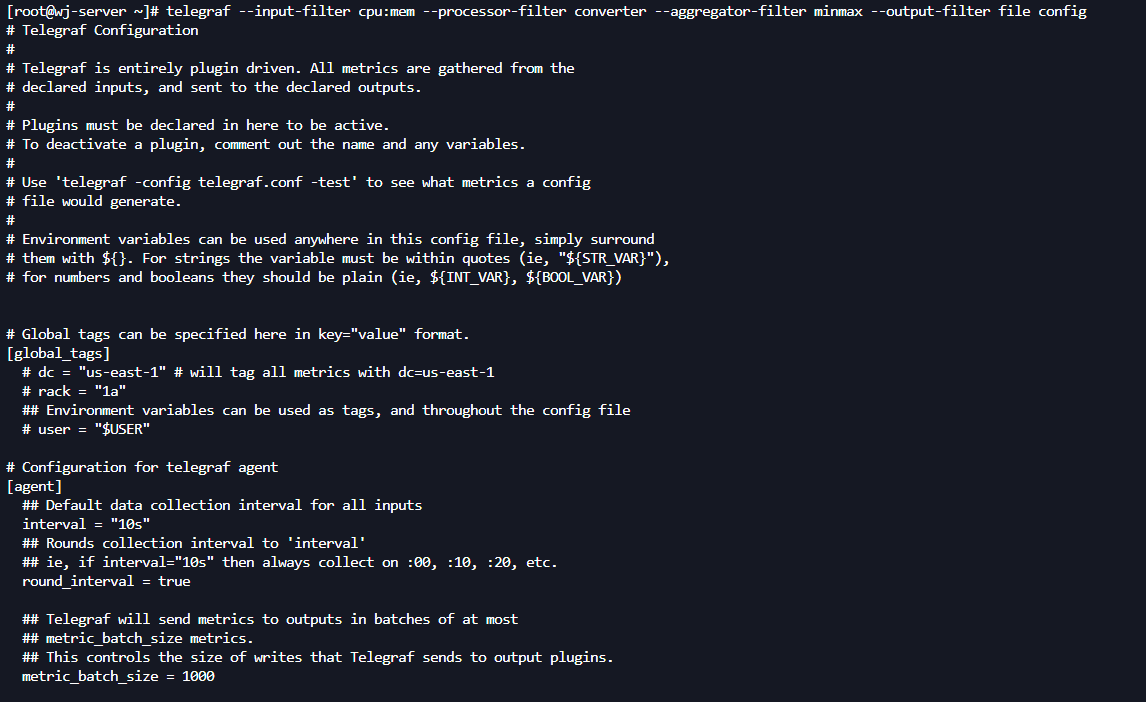
配置文件参数
Agent配置
| 配置名 | 直 译 | 解释 |
|---|---|---|
| interval | 间隔 | 所有的input组件采集数据的间隔时间 |
| round_interval | 间隔取整 | 将采集的间隔时间取整。比如,如果interval设置为10s,但我们在1分02秒启动了telegraf服务,那么采集的时间会取整到1分10秒,1分20秒,1分30秒 |
| metric_batch_size | 指标 批大小 | telegraf一批次从output组件向外发送数据的大小,网络不稳定时可以减小此参数。 |
| metric_buffer_limit | 指标 缓冲区 | telegraf会为每个output插件创建一个缓冲区,来缓存指标数据,并在output成功将数据发送后,将成功发送的数据从缓冲区删除。所以,metriac_buffer_limit参数应该至少是metric_batch_size参数的两倍 |
| collection_jetter | 采集抖动 | 这个参数会在采集的时间点上加一个随机的抖动,这样可以避免很多插件同时查询一些消耗资源的指标,从而对被观测的系统产生不可忽视的影响。 |
| flush_interval | 刷新间隔 | 所有output的输出间隔,这个参数不应该设的比interval(所有input组件的采集间隔)小。最大的实际发送间隔将会是 |
| flush_jitter | 刷新抖动 | 对output的输出时间加上一个随机的抖动,这主要是为了避免大量的Telegraf实例在同样的时间同时执行写入操作,出现较大的写入峰值。比如,flush_jitter设为5s,flush_interval设为10s意味着会在10~15秒的时候进行一次输出。 |
| precision | 精度 | 精度配置确定从输入插件接收的点中保留多少时间戳精度。所有传入的时间戳都被阶段为给定的精度。然后Telegraf用零填充截断的时间戳以创建纳秒时间戳,输出插件将以纳秒为单位发出时间戳。有效的精度为ns,us,ms和s。 例如:如果精度设置为ms,则纳秒时间戳1480000000123456789将被截断为1480000000123毫秒精度,然后用0填充以生成新的,不太精确的纳秒时间戳1480000000123000000。输出插件不会进一步更改时间戳。如果是服务型的输出插件会忽略这个设置。 |
| logfile | 日志文件 | 自定义的日志名称, |
| debug | 调试 | 使用debug模式运行Telegraf |
| quiet | 安静 | 安静地运行Telegraf,只会提示错误信息 |
| logtarget | 日志目标 | 该配置用来空值日志的目标。它可以是"file","stderr"之一,如果是在Windows系统上,它还可以设为"eventlog"。设置为"file"时,输入文件由 logfile 配置项决定。 |
| logfile | 日志文件 | 指定logtarget指定为"file"时的日志文件名。如果设置为空,那么日志会输出到stderr上。 |
| logfile_rotation_interval | 日志轮转间隔 | 日志轮转间隔,多长时间开启一个新的日志文件,如果设置为0,那么就不按时间进行轮转。 |
| logfile_rotation_max_size | 日志轮转大小 | 当正在使用的日志文件的大小超过该值时,开启一个新的日志文件。当设置为0,表示不按照日志文件的大小进行日志轮转。 |
| logfile_rotation_max_archives | 最大轮转存档数 | 最大的日志归档数量,每一次日志轮转发生时,都会产生一个新的正在使用的日志文件,和一个归档(旧的不再使用的日志文件) |
| log_with_timezone | 日志时区 | 设置日志记录要使用的时区,或者设为"local"即为本地时间。 |
| hostname | 主机名 | 覆盖默认的主机名,如果不设该值,那么os.Hostname( )的返回值。(os.Hostname)是Go语言标准库中的方法,可以获取当前机器的名称。 |
| omit_hostname | 忽略主机名 | telegraf输出的指标数据中,有一个默认的 |
Input 输入插件通用配置
| 配置名 | 直译 | 解释 |
|---|---|---|
| alias | 别名 | 给一个input插件实例进行命名。 |
| interval | 间隔 | 单个Input组件收集指标的间隔时间,插件中的interval配置比全局的interval配置的优先级要高。 |
| precision | 精度 | 单个Input组件的时间精度,覆盖[agent]中的配置。精度配置确定从输出插件接收的点中保留多少时间戳精度。所有传入的时间戳都被阶段为给定的精度。然后Telegraf用零填充截断的时间戳以创建纳秒时间戳,输出插件将以纳秒为单位发出时间戳。有效的精度为ns,us,ms和s。 例如:如果精度设置为ms,则纳秒时间戳1480000000123456789将被截断为1480000000123毫秒精度,然后用0填充以生成新的,不太精确的纳秒时间戳1480000000123000000。输出插件不会进一步更改时间戳。如果是服务型的输出插件会忽略这个设置。 |
| collection_jitter | 采集抖动 | 单个Input组件的采集抖动 |
| name_override | 重命名 | 覆盖原来的指标名称,默认值为input组件的名称 |
| name_prefix | 名称前缀 | 指定要附加到度量值名称的前缀 |
| name_suffix | 名称后缀 | 指定要附加到度量值名称的后缀 |
| tags | 标签集 | 给当前input数据添加新的标签集。 |
Output 输出插件通用配置
| 配置名 | 直译 | 解释 |
|---|---|---|
| alias | 别名 | 给一个output插件起一个别名 |
| flush_interval | 刷新间隔 | 单个output插件的输出间隔(覆盖全局配置) |
| flush_jitter | 刷新抖动 | 单个output插件的输出时间抖动(覆盖全局配置) |
| metric_batch_size | 指标批次大小 | 一次最多发送多少条数据(会覆盖全局配置) |
| metric_buffer_limit | 指标缓冲区上限 | 未发送数据的缓冲区(会覆盖全局配置) |
| name_override | 重命名 | 覆盖原来的指标名称,默认值为output的名称(我怀疑官网说错了) |
| name_prefix | 名称前缀 | 指标名称的前缀 |
| name_suffix | 名称后缀 | 指标名称的后缀 |
Aggregator 聚合插件通用配置
| 配置名 | 直译 | 解释 |
|---|---|---|
| alias | 别名 | 给一个Aggregator插件的实例命名 |
| period | 期间 | 聚合器对从now-period 到now 之间的数据进行聚合。 |
| delay | 延迟 | 聚合时进行一个小的延迟,防止在对时间戳为1000的数据进行聚合时,上游还在正在发送时间戳为1000的数据 |
| grace | 宽限 | 迟到多久的数据可以进入下一个聚合周期。 |
| drop_original | 删除源 | 默认为false,如果设置为true,袁术的指标数据就会从流水线上删除,不会发给下游的output插件 |
| name_override | 名称覆盖 | 给数据的指标名称重新命名 |
| name_prefix | 名称前缀 | 给指标名称加一个前缀 |
| name_suffix | 名称后缀 | 给指标名称加一个后缀 |
| tags | 标记 | 添加额外的标签集 |
Processor 处理插件通用配置
| 配置名 | 直译 | 解释 |
|---|---|---|
| alias | 别名 | 给Processor插件的示例起一个名字 |
| order | 顺序 | 这是处理器的执行顺序,如果没有制定,那么执行器的顺序就是随机的。注意!不是按照配置文件的先后顺序来的,而是随机。 |
Metric filtering 指标过滤器通用配置
| 配置名 | 直译 | 解释 |
|---|---|---|
| namepass | 名称通过 | 一个glob模式的字符串数组,仅有measurement名称与这个配置的参数能匹配的指标数据可以进入此插件。 |
| namedrop | 名称删除 | 一个glob模式的字符串数组,能匹配上measurement的数据直接删除。 |
| fieldpass | 字段通过 | 一个glob模式的字符串数组,只有能匹配上的字段才能通过 |
| fielddrop | 字段删除 | 一个glob模式的字符串数组,如果匹配上了就删除这个资源。 |
| tagpass | 标签通过 | 一个glob模式的字符串数组,tag能匹配上的数据才能通过 |
| tagdrop | 标签删除 | 一个glob模式的字符串数组,tag能匹配上的数据会被删除 |
| taginclude | 标签包含 | 一个glob模式的字符串数据,能匹配到其中一个的整条数据才能通过。 |
| tagexclude | 标签不含 | tageinclude的反函数 |
配置文件与环境变量
vi /opt/module/telegraf_conf/example3.conf
[agent]
interval = "3s"
[global_tags]
user = "${USER}"
[[inputs.cpu]]
percpu = true
totalcpu = true
collect_cpu_time = false
report_active = false
core_tags = false
[[outputs.file]]
files = ["stdout"]
Telegraf默认的变量声明文件:
/etc/default/telegraf 是Telegraf的默认变量声明文件,你也可以直接在这个文件中声明变量。但优先级不如环境变量高。
vim /etc/default/telegraf
USER=HAHA
运行telegraf程序(需要重启机器)。
或者直接在命令行中生命变量:
USER=HAHA
telegtelegraf --config /opt/module/telegraf_conf/example3.conf --test

Exec插件
官方文档:telegraf/README.md at release-1.24 · influxdata/telegraf · GitHub
exec可以执行命令,并把命令执行的输出当作数据的输入。
示例:
编写一个shell:
vi /tmp/test.sh
#!/bin/sh
echo 'example,tag1=a,tag2=b i=42i,j=43i,k=44i'
编写telegraf配置文件:
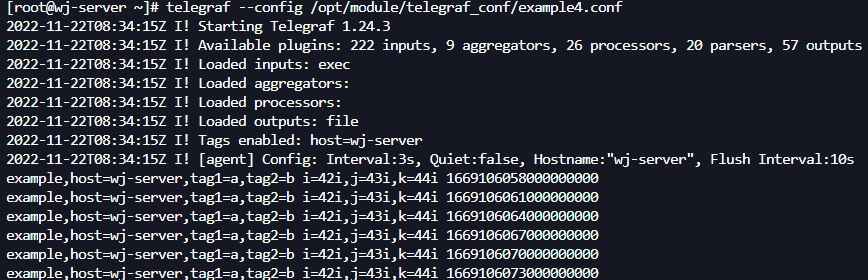
vi /opt/module/telegraf_conf/example4.conf
[agent]
interval = "3s"
[[inputs.exec]]
commands = ["sh /tmp/test.sh"]
timeout = "5s"
data_format = "influx"
[[outputs.file]]
files = ["stdout"]
执行,观察结果:
telegraf --config /opt/module/telegraf_conf/example4.conf