目录
- 1 转换算子(transformer)(将旧的RDD包装成新RDD)
- 1.1 单值类型
- 1.2 双值类型
- 1.3 键值类型
- 1.3.1 partitionBy(按照指定规则重新分区)
- 1.3.2 groupByKey(分组)
- 1.3.3 reduceByKey(分组+聚合, 单个无法聚合)
- 1.3.4 aggregateByKey(分组+聚合, 区分分区间&分区内的逻辑. 需要初始值)
- 1.3.5 foldByKey(分组+聚合, 统一分区间&分区内逻辑. 需要初始值)
- 1.3.6 combineByKey(分组+聚合, 区分分区间&分区内的逻辑. 无需初始值)
- 1.3.7 reduceByKey、foldByKey、aggregateByKey、combineByKey 的区别
- 1.3.8 sortByKey
- 1.3.9 join
- 1.3.10 leftOuterJoin
- 1.3.11 cogroup
- 2 行动算子(action)
1 转换算子(transformer)(将旧的RDD包装成新RDD)
1.1 单值类型
1.1.1 map
多个分区之间是并行的,分区内的数据是串行执行的
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd: RDD[Int] = sparkContext.makeRDD(
List(1, 2, 3, 4)
)
// val mapRDD: RDD[Int] = rdd.map((num: Int) => { num * 2 })
// val mapRDD: RDD[Int] = rdd.map((num: Int) => num * 2)
// val mapRDD: RDD[Int] = rdd.map((num) => num * 2)
// val mapRDD: RDD[Int] = rdd.map(num => num * 2)
val mapRDD: RDD[Int] = rdd.map(_ * 2)
mapRDD.collect().foreach(println)
sparkContext.stop()
}
1.1.2 mapPartition
- 数据处理的角度
- Map 算子是分区内一个数据一个数据的执行,类似于串行操作
- 而 mapPartitions 算子 是以分区为单位进行批处理操作
- 功能的角度
- Map 算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据
- MapPartitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变, 所以可以增加或减少数据
- 性能的角度
- Map 算子因为类似于串行操作,所以性能比较低,而是 mapPartitions 算子类似于批处理,所以性能较高
- mapPartitions 算子会长时间占用内存,那么这样会导致内存可能不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用。使用 map 操作
val rdd: RDD[Int] = sparkContext.makeRDD(
List(1, 2, 3, 4), 2
)
// map是
val mapRDD: RDD[Int] = rdd.mapPartitions(iter => {
println(">>>>>>>>>>>>>>>>")
iter.map(_ * 2)
})
1.1.3 mapPartitionsWithIndex
特性:
- 将待处理的数据以分区为单位发送到计算节点进行处理
- 这里的处理是指可以进行任意的处理,哪怕是过滤数据
- 在处理时同时可以获取当前分区索引
// 如下示例:跳过分区0的数据
val dataRDD1 = dataRDD.mapPartitionsWithIndex(
(index, datas) => {
if (index == 0) {
Nil.iterator
} else {
datas.map(index, _)
}
}
)
1.1.4 flatMap
将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射
val dataRDD = sparkContext.makeRDD(List(
List(1,2),List(3,4)
),1)
val dataRDD1 = dataRDD.flatMap(
list => list
)
1.1.5 glom
将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
// 这里rdd分成了两个分区1,2 & 3,4
val rdd: RDD[Int] = sparkContext.makeRDD(
List(1, 2, 3, 4), 2
)
// 运行到这里应该就变成了 [[1, 2], [3, 4]]
val glomRDD: RDD[Array[Int]] = rdd.glom()
glomRDD.collect().foreach(data => println(data.mkString(",")))
// 以下为打印结果
1,2
3,4
1.1.6 groupBy
val dataRDD = sparkContext.makeRDD(List(1,2,3,4),1)
val dataRDD1 = dataRDD.groupBy(
_%2 )
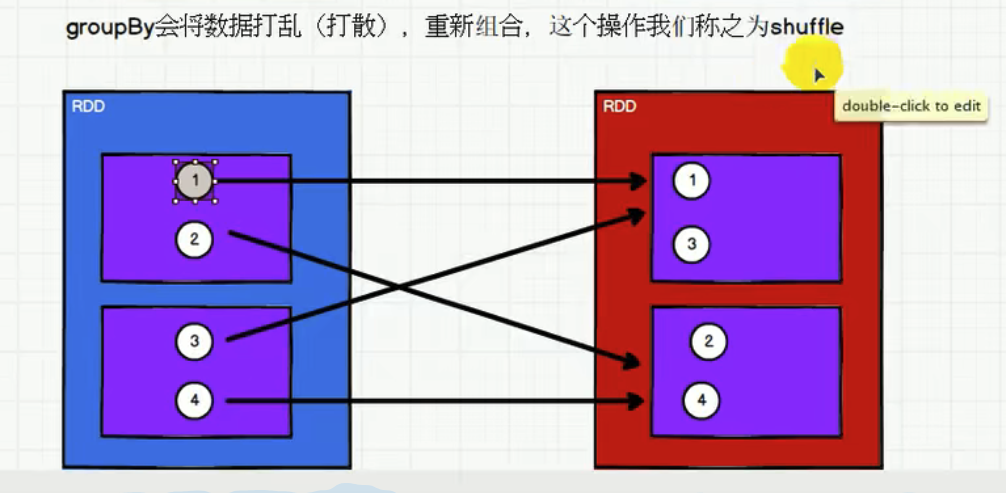
将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样 的操作称之为 shuffle。极限情况下,数据可能被分在同一个分区中 一个组的数据在一个分区中,但是并不是说一个分区中只有一个组
1.1.7 filter
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4
),1)
val dataRDD1 = dataRDD.filter(_%2 == 0)
将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。 当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜
1.1.8 sample
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4
),1)
// 抽取数据不放回(伯努利算法)
// 伯努利算法:又叫 0、1 分布。例如扔硬币,要么正面,要么反面。
// 具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不 要
// 第一个参数:抽取的数据是否放回,false:不放回
// 第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取;
// 第三个参数:随机数种子
val dataRDD1 = dataRDD.sample(false, 0.5)
// 抽取数据放回(泊松算法)
// 第一个参数:抽取的数据是否放回,true:放回;false:不放回
// 第二个参数:重复数据的几率,范围大于等于 0.表示每一个元素被期望抽取到的次数
// 第三个参数:随机数种子
val dataRDD2 = dataRDD.sample(true, 2)
使用场景
主要出现数据倾斜时,使用该函数,数据倾斜主要发生在有shuffle操作时。数据重新整理后,可能会出现一个区的数据量很少,另一个数据量很大的情况,这种情况称为“数据倾斜”,导致一个节点的计算量较大,一个计算节点计算量较少,影响最终的处理效率。为了避免这种情况,可以在shuffle之前,进行sample操作,查看数据源中那些数据较多,提取处理。
1.1.9 distinct
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4,1,2
),1)
val dataRDD1 = dataRDD.distinct()
val dataRDD2 = dataRDD.distinct(2)
// 底层实现逻辑
map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
1.1.10 coalesce
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4,1,2
),6)
val dataRDD1 = dataRDD.coalesce(2)
根据数据量缩减分区,用于大数据集过滤后,提高小数据集的执行效率。当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少 分区的个数,减小任务调度成本
1.1.11 repartition
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4,1,2
),2)
val dataRDD1 = dataRDD.repartition(4)
该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true。无论是将分区数多的 RDD 转换为分区数少的 RDD,还是将分区数少的 RDD 转换为分区数多的 RDD,repartition 操作都可以完成,因为无论如何都会经 shuffle 过程
1.1.12 sortBy
val dataRDD = sparkContext.makeRDD(List(
1,2,3,4,1,2
),2)
val dataRDD1 = dataRDD.sortBy(num=>num, false, 4)
该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理 的结果进行排序,默认为升序排列。排序后新产生的 RDD 的分区数与原 RDD 的分区数一 致。中间存在 shuffle 的过程
1.2 双值类型
1.2.1 union(并集, 不去重)
两个RDD的数据类型必须一致
val rdd1: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4))
val rdd2: RDD[Int] = sparkContext.makeRDD(List(3, 4, 5, 6))
// 并集 1,2,3,4,3,4,5,6
val rdd3: RDD[Int] = rdd1.union(rdd2)
println(rdd3.collect().mkString(","))
1.2.2 intersection(交集)
两个RDD的数据类型必须一致
val rdd1: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4))
val rdd2: RDD[Int] = sparkContext.makeRDD(List(3, 4, 5, 6))
// 交集 3,4
val rdd4: RDD[Int] = rdd1.intersection(rdd2)
println(rdd4.collect().mkString(","))
1.2.3 subtract(差集)
两个RDD的数据类型必须一致
val rdd1: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4))
val rdd2: RDD[Int] = sparkContext.makeRDD(List(3, 4, 5, 6))
// 差集 1,2
val rdd5: RDD[Int] = rdd1.subtract(rdd2)
println(rdd5.collect().mkString(","))
1.2.4 zip(拉链)
val rdd1: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4))
val rdd2: RDD[Int] = sparkContext.makeRDD(List(3, 4, 5, 6))
// 拉链 (1,3),(2,4),(3,5),(4,6)
val rdd6: RDD[(Int, Int)] = rdd1.zip(rdd2)
println(rdd6.collect().mkString(","))
将两个 RDD 中的元素,以键值对的形式进行合并。其中,键值对中的 Key 为第 1 个 RDD 中的元素,Value 为第 2 个 RDD 中的相同位置的元素
1.3 键值类型
键值类型会将RDD通过隐式转换implicit转换成PairRDDFunctions来调用键值类型相关的方法
1.3.1 partitionBy(按照指定规则重新分区)
val rdd: RDD[(Int, Int)] = sparkContext.makeRDD(List(1, 2, 3, 4)).map((_, 1))
val value: RDD[(Int, Int)] = rdd.partitionBy(new HashPartitioner(2))
- 如果重复使用同一个分区器
- 内部有检查,如果重复使用同一个分区器,第二次之后的就不会重新分区了
- 内置的分区器
- HashPartitioner
- RangePartitioner
1.3.2 groupByKey(分组)
将数据源的数据根据 key 对 value 进行分组
val dataRDD1 =
sparkContext.makeRDD(List(("a",1),("b",2),("c",3)))
val dataRDD2 = dataRDD1.groupByKey()
val dataRDD3 = dataRDD1.groupByKey(2)
val dataRDD4 = dataRDD1.groupByKey(new HashPartitioner(2))
1.3.3 reduceByKey(分组+聚合, 单个无法聚合)
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3)))
val dataRDD2 = dataRDD1.reduceByKey(_+_)
val dataRDD3 = dataRDD1.reduceByKey(_+_, 2)
- 可以将数据按照相同的 Key 对 Value 进行聚合。
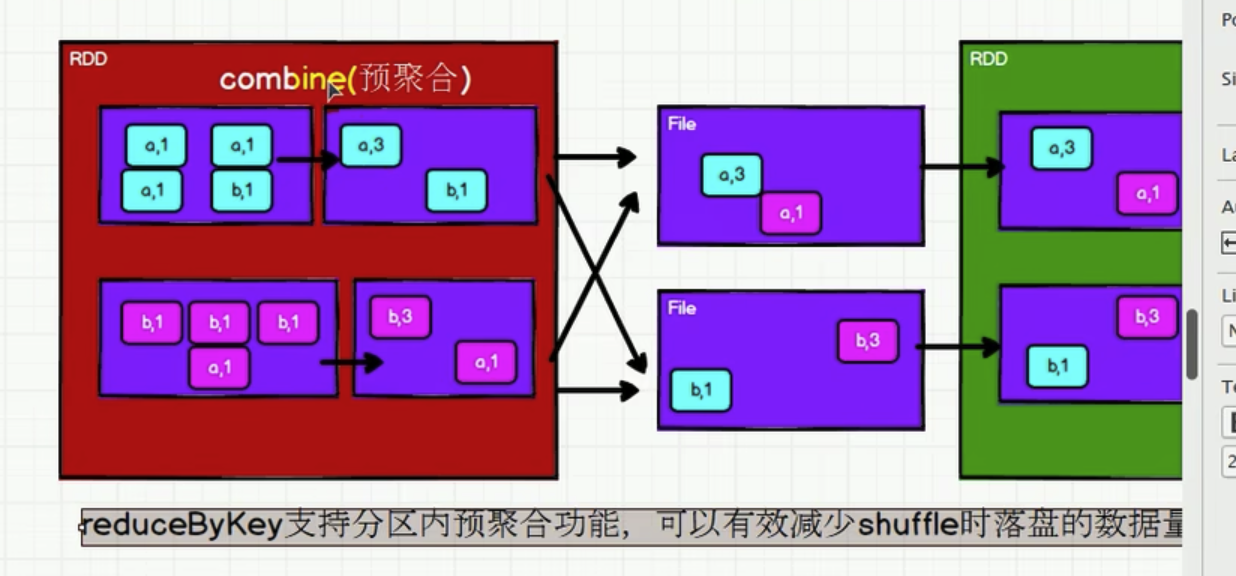
- reduceByKey内部有shuffle的操作。所有shuffle的操作都需要落盘,防止内存溢出
- reduceByKey 和 groupByKey 的区别
- 性能角度: reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的 数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较 高。
- 功能角度:reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚 合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那 么还是只能使用 groupByKey
1.3.4 aggregateByKey(分组+聚合, 区分分区间&分区内的逻辑. 需要初始值)
reduceByKey 分区内和分区间的聚合规则是一样的。但是aggregateByKey可以分别指定分区内和分区间的规则
val rdd: RDD[(String, Int)] = sparkContext.makeRDD(List(
("a", 1),
("a", 4),
("a", 3),
("a", 5),
), 2)
rdd.aggregateByKey(0)( // 0是初始值,主要用于当碰见第一个key的时候,和value进行分区内计算
(t1, t2) => math.max(t1, t2), // 分区内的逻辑
(t1, t2) => t1 + t2) // 分区间的逻辑
.collect()
.foreach(println)
// 输出结果:
(a,9)
1.3.5 foldByKey(分组+聚合, 统一分区间&分区内逻辑. 需要初始值)
当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey
val rdd: RDD[(String, Int)] = sparkContext.makeRDD(List(
("a", 1),
("a", 4),
("a", 3),
("a", 5),
), 2)
rdd.aggregateByKey(0)( // 0是初始值,主要用于当碰见第一个key的时候,和value进行分区内计算
(t1, t2) => t1 + t2) // 分区内 & 分区间的逻辑
.collect()
.foreach(println)
1.3.6 combineByKey(分组+聚合, 区分分区间&分区内的逻辑. 无需初始值)
最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。类似于 aggregate(),combineByKey()允许用户返回值的类型与输入不一致
val rdd: RDD[(String, Int)] = sparkContext.makeRDD(List(
("a", 88),
("b", 4),
("a", 1),
("b", 5),
("a", -99),
("b", -1),
), 2)
// 计算平均值
rdd.combineByKey(
v => (v, 1), // 第一个参数,将RDD[(String, Int)]中的value转换成一个 tuple
(t1: (Int, Int), v) => { // 分区内的数据处理, 将该 tuple 和其他value进行处理,返回新的tuple
(t1._1 + v, t1._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => { // 分区间的数据处理。将分区间的多个tuple进行合并
(t1._1 + t2._1, t1._2 + t2._2)
},
)
.mapValues(t => t._1.toFloat / t._2)
.collect()
.foreach(println)
// 输出结果
(b,2.6666667)
(a,-3.3333333)
1.3.7 reduceByKey、foldByKey、aggregateByKey、combineByKey 的区别
- reduceByKey
- 相同 key 的第一个数据不进行任何计算
- 分区内和分区间计算规则相同
- foldByKey
- 相同 key 的第一个数据和初始值进行分区内计算
- 分区内和分区间计算规则相同
- AggregateByKey
- 相同 key 的第一个数据和初始值进行分区内计算
- 分区内和分区间计算规则可以不相同
- CombineByKey
- 当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构
- 分区内和分区间计算规则不相同
1.3.8 sortByKey
在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口(特质),返回一个按照 key 进行排序
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3)))
val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(true)
val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(false)
1.3.9 join
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的(K,(V,W))的 RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (3, 6)))
rdd.join(rdd1).collect().foreach(println)
1.3.10 leftOuterJoin
类似于 SQL 语句的左外连接
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3)))
val dataRDD2 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3)))
val rdd: RDD[(String, (Int, Option[Int]))] = dataRDD1.leftOuterJoin(dataRDD2)
1.3.11 cogroup
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("a",2),("c",3)))
val dataRDD2 = sparkContext.makeRDD(List(("a",1),("c",2),("c",3)))
val value: RDD[(String, (Iterable[Int], Iterable[Int]))] =
dataRDD1.cogroup(dataRDD2)
2 行动算子(action)
所谓的行动算子,其实就是触发作业(Job)执行的方法,底层代码调用的是环境对象的runJob方法。再底层会创建ActiveJob, 并提交执行

2.1 reduce(两两聚合)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 聚合数据
val reduceResult: Int = rdd.reduce(_+_)
println(reduceResult)
// 返回值
10
2.2 collect
将不同分区中的数据,按顺序采集到drive中
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 收集数据到 Driver
rdd.collect().foreach(println)
2.3 count
返回 RDD 中元素的个数
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 返回 RDD 中元素的个数
val countResult: Long = rdd.count()
2.4 first
返回第一个元素
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 返回 RDD 中元素的个数
val firstResult: Int = rdd.first() println(firstResult)
2.5 take
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 返回 RDD 中元素的个数
val takeResult: Array[Int] = rdd.take(2) println(takeResult.mkString(","))
2.6 takeOrdered(先排序再take)
val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4))
// 返回 RDD 中元素的个数
val result: Array[Int] = rdd.takeOrdered(2)
2.7 aggregate
分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 8)
// 将该 RDD 所有元素相加得到结果
//val result: Int = rdd.aggregate(0)(_ + _, _ + _) val result: Int = rdd.aggregate(10)(_ + _, _ + _)
2.8 fold
aggregate 的简化版操作, 分区内和分区间的规则一致
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val foldResult: Int = rdd.fold(0)(_+_)
2.9 countByKey
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2,
"b"), (3, "c"), (3, "c")))
// 统计每种 key 的个数
val result: collection.Map[Int, Long] = rdd.countByKey()
2.10 countByValue
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2,
"b"), (3, "c"), (3, "c")))
// 统计每种 key 的个数
val result: collection.Map[Int, Long] = rdd.countByValue()
2.11 save相关算子
// 保存成 Text 文件
rdd.saveAsTextFile("output")
// 序列化成对象保存到文件
rdd.saveAsObjectFile("output1")
// 保存成 Sequencefile 文件
rdd.map((_,1)).saveAsSequenceFile("output2")
2.12 foreach(分布式遍历)
分布式遍历 RDD 中的每一个元素,调用指定函数
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 收集后打印 rdd.map(num=>num).collect().foreach(println)
println("****************")
// 分布式打印 rdd.foreach(println)