1.8.7 Spark与Iceberg整合写操作
1.8.7.1 INSERT INTO
"insert into"是向Iceberg表中插入数据,有两种语法形式:"INSERT INTO tbl VALUES (1,"zs",18),(2,"ls",19)"、"INSERT INTO tbl SELECT ...",以上两种方式比较简单,这里不再详细记录。
1.8.7.2 MERGE INTO
Iceberg "merge into"语法可以对表数据进行行级更新或删除,在Spark3.x版本之后支持,其原理是重写包含需要删除和更新行数据所在的data files。"merge into"可以使用一个查询结果数据来更新目标表的数据,其语法通过类似join关联方式,根据指定的匹配条件对匹配的行数据进行相应操作。"merge into"语法如下:
MERGE INTO tbl t
USING (SELECT ...) s
ON t.id = s.id
WHEN MATCHED AND ... THEN DELETE //删除
WHEN MATCHED AND ... THEN UPDATE SET ... //更新
WHEN MATCHED AND ... AND ... THEN UPDATE SET ... //多条件更新
WHEN NOT MATCHED ADN ... THEN INSERT (col1,col2...) VALUES(s.col1,s.col2 ...)//匹配不上向目标表插入数据
具体案例如下:
- 首先创建a表和b表,并插入数据
val spark: SparkSession = SparkSession.builder().master("local").appName("SparkOperateIceberg")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/sparkoperateiceberg")
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions")
.getOrCreate()
//创建一张表 a ,并插入数据
spark.sql(
"""
|create table hadoop_prod.default.a (id int,name string,age int) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.a values (1,"zs",18),(2,"ls",19),(3,"ww",20)
""".stripMargin)
//创建另外一张表b ,并插入数据
spark.sql(
"""
|create table hadoop_prod.default.b (id int,name string,age int,tp string) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.b values (1,"zs",30,"delete"),(2,"李四",31,"update"),(4,"王五",32,"add")
""".stripMargin)
- 使用MERGE INTO 语法向目标表更新、删除、新增数据
这里我们计划将b表与a表匹配id,如果b表中tp字段是"delete"那么a表中对应的id数据删除,如果b表中tp字段是"update",那么a表中对应的id数据其他字段进行更新,如果a表与b表id匹配不上,那么将b表中的数据插入到a表中,具体操作如下:
//将表b 中与表a中相同id的数据更新到表a,表a中没有表b中有的id对应数据写入增加到表a
spark.sql(
"""
|merge into hadoop_prod.default.a t1
|using (select id,name ,age,tp from hadoop_prod.default.b) t2
|on t1.id = t2.id
|when matched and t2.tp = 'delete' then delete
|when matched and t2.tp = 'update' then update set t1.name = t2.name,t1.age = t2.age
|when not matched then insert (id,name,age) values (t2.id,t2.name,t2.age)
""".stripMargin)
spark.sql("""select * from hadoop_prod.default.a """).show()
最终结果如下:
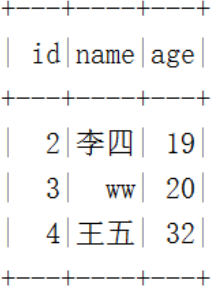
注意:更新数据时,在查询的数据中只能有一条匹配的数据更新到目标表,否则将报错。
关于我的 INSERT INTO 测试代码和结果如下:
package com.shujia.spark.iceberg
import org.apache.spark.sql.SparkSession
object MergeInto {
def main(args: Array[String]): Unit = {
/**
*
* MERGE INTO tbl t
* USING (SELECT ...) s
* ON t.id = s.id
* WHEN MATCHED AND ... THEN DELETE //删除
* WHEN MATCHED AND ... THEN UPDATE SET ... //更新
* WHEN MATCHED AND ... AND ... THEN UPDATE SET ... //多条件更新
* WHEN NOT MATCHED ADN ... THEN INSERT (col1,col2...) VALUES(s.col1,s.col2 ...)//匹配不上向目标表插入数据
*
*/
val spark: SparkSession = SparkSession
.builder()
.appName("test")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://master:9000/spark")
.getOrCreate()
//首先创建a表和b表,并插入数据
//创建一张表 a ,并插入数据
spark.sql(
"""
|create table if not exists hadoop_prod.default.a (id int,name string,age int) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.a values (1,"zs",18),(2,"ls",19),(3,"ww",20)
|
""".stripMargin)
//创建另外一张表b ,并插入数据
spark.sql(
"""
|create table if not exists hadoop_prod.default.b (id int,name string,age int,tp string) using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.b values
| (1,"zs",30,"delete")
|,(2,"李四",31,"update")
|,(4,"王五",32,"add")
|
""".stripMargin)
/**
*
* 使用MERGE INTO 语法向目标表更新、删除、新增数据
*
* 这里我们计划将b表与a表匹配id,如果b表中tp字段是"delete"那么a表中对应的id数据删除,
* 如果b表中tp字段是"update",那么a表中对应的id数据其他字段进行更新,如果a表与b表id匹配不上,
* 那么将b表中的数据插入到a表中,具体操作如下:
*/
//将表b 中与表a中相同id的数据更新到表a,表a中没有表b中有的id对应数据写入增加到表a
spark.sql(
"""
|merge into hadoop_prod.default.a t1
|using (select id,name ,age,tp from hadoop_prod.default.b) t2
|on t1.id = t2.id
|when matched and t2.tp = 'delete' then delete
|when matched and t2.tp = 'update' then update set t1.name = t2.name,t1.age = t2.age
|when not matched then insert (id,name,age) values (t2.id,t2.name,t2.age)
|
""".stripMargin)
spark.sql("""select * from hadoop_prod.default.a """).show()
/**
*
* 进过测试报错如下:
*Exception in thread "main" java.lang.UnsupportedOperationException:
* MERGE INTO TABLE is not supported temporarily.
*
* 翻译:
*Exception in thread "main" java.lang.UnsupportedOperationException: MERGE INTO TABLE is not supported temporarily.
*线程“main”java.lang.UnsupportedOperationException:暂时不支持MERGE INTO TABLE。
*
*/
//spark 提交任务的命令
//spark-submit --master yarn --class com.shujia.spark.iceberg.MergeInto spark-1.0.jar
}
}
1.8.7.3 INSERT OVERWRITE
"insert overwrite"可以覆盖Iceberg表中的数据,这种操作会将表中全部数据替换掉,建议如果有部分数据替换操作可以使用"merge into"操作。
对于Iceberg分区表使用"insert overwrite"操作时,有两种情况,第一种是“动态覆盖”,第二种是“静态覆盖”。
- 动态分区覆盖:
动态覆盖会全量将原有数据覆盖,并将新插入的数据根据Iceberg表分区规则自动分区,类似Hive中的动态分区。
- 静态分区覆盖:
静态覆盖需要在向Iceberg中插入数据时需要手动指定分区,如果当前Iceberg表存在这个分区,那么只有这个分区的数据会被覆盖,其他分区数据不受影响,如果Iceberg表不存在这个分区,那么相当于给Iceberg表增加了个一个分区。具体操作如下:
- 创建三张表
创建test1分区表、test2普通表、test3普通表三张表,并插入数据,每张表字段相同,但是插入数据不同。
//创建 test1 分区表,并插入数据
spark.sql(
"""
|create table hadoop_prod.default.test1 (id int,name string,loc string)
|using iceberg
|partitioned by (loc)
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.test1 values (1,"zs","beijing"),(2,"ls","shanghai")
""".stripMargin)
//创建 test2 普通表,并插入数据
spark.sql(
"""
|create table hadoop_prod.default.test2 (id int,name string,loc string)
|using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.test2 values (10,"x1","shandong"),(11,"x2","hunan")
""".stripMargin)
//创建 test3 普通表,并插入数据
spark.sql(
"""
|create table hadoop_prod.default.test3 (id int,name string,loc string)
|using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.test3 values (3,"ww","beijing"),(4,"ml","shanghai"),(5,"tq","guangzhou")
""".stripMargin)
- 使用insert overwrite 读取test3表中的数据覆盖到test2表中
//使用insert overwrite 读取test3 表中的数据覆盖到test2 普通表中
spark.sql(
"""
|insert overwrite hadoop_prod.default.test2
|select id,name,loc from hadoop_prod.default.test3
""".stripMargin)
//查询 test2 表中的数据
spark.sql(
"""
|select * from hadoop_prod.default.test2
""".stripMargin).show()
Iceberg 表 test2结果如下:

- 使用insert overwrite 读取test3表数据,动态分区方式覆盖到表test1
// 使用insert overwrite 读取test3表数据 动态分区方式覆盖到表 test1
spark.sql(
"""
|insert overwrite hadoop_prod.default.test1
|select id,name,loc from hadoop_prod.default.test3
""".stripMargin)
//查询 test1 表数据
spark.sql(
"""
|select * from hadoop_prod.default.test1
""".stripMargin).show()
Iceberg 表 test1结果如下:

- 静态分区方式,将iceberg表test3的数据覆盖到Iceberg表test1中
这里可以将test1表删除,然后重新创建,加载数据,也可以直接读取test3中的数据静态分区方式更新到test1。另外,使用insert overwrite 语法覆盖静态分区方式时,查询的语句中就不要再次写入分区列,否则会重复。
//删除表test1,重新创建表test1 分区表,并插入数据
spark.sql(
"""
|drop table hadoop_prod.default.test1
""".stripMargin)
spark.sql(
"""
|create table hadoop_prod.default.test1 (id int,name string,loc string)
|using iceberg
|partitioned by (loc)
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.test1 values (1,"zs","beijing"),(2,"ls","shanghai")
""".stripMargin)
spark.sql("select * from hadoop_prod.default.test1").show()
Iceberg 表 test1结果如下:

//注意:指定静态分区"jiangsu",静态分区下,就不要在查询 “loc" 列了,否则重复
spark.sql(
"""
|insert overwrite hadoop_prod.default.test1
|partition (loc = "jiangsu")
|select id,name from hadoop_prod.default.test3
""".stripMargin)
//查询 test1 表数据
spark.sql(
"""
|select * from hadoop_prod.default.test1
""".stripMargin).show()
Iceberg 表 test1结果如下:

注意:使用insert overwrite 读取test3表数据 静态分区方式覆盖到表 test1,表中其他分区数据不受影响,只会覆盖指定的静态分区数据。
进过测试 INSERT OVERWRITE 我的测试代码及结果如下:
package com.shujia.spark.iceberg
import org.apache.spark.sql.SparkSession
object InsertOverwrite {
def main(args: Array[String]): Unit = {
/*
"insert overwrite"可以覆盖Iceberg表中的数据,这种操作会将表中全部数据替换掉,
建议如果有部分数据替换操作可以使用"merge into"操作。
对于Iceberg分区表使用"insert overwrite"操作时,有两种情况,第一种是“动态覆盖”,第二种是“静态覆盖”。
动态分区覆盖:
动态覆盖会全量将原有数据覆盖,并将新插入的数据根据Iceberg表分区规则自动分区,类似Hive中的动态分区。
静态分区覆盖:
静态覆盖需要在向Iceberg中插入数据时需要手动指定分区,如果当前Iceberg表存在这个分区,
那么只有这个分区的数据会被覆盖,其他分区数据不受影响,如果Iceberg表不存在这个分区,
那么相当于给Iceberg表增加了个一个分区。具体操作如下:
*/
val spark: SparkSession = SparkSession
.builder()
.appName("test")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://master:9000/spark")
.getOrCreate()
/**
*
* 删除表
*/
//删除表test1,重新创建表test1 分区表,并插入数据
spark.sql(
"""
|drop table if exists hadoop_prod.default.test1
""".stripMargin)
spark.sql(
"""
|drop table if exists hadoop_prod.default.test2
""".stripMargin)
spark.sql(
"""
|drop table if exists hadoop_prod.default.test3
""".stripMargin)
//创建test1分区表、test2普通表、test3普通表三张表,并插入数据,每张表字段相同,但是插入数据不同。
//创建 test1 分区表,并插入数据
spark.sql(
"""
|create table if not exists hadoop_prod.default.test1 (id int,name string,loc string)
|using iceberg
|partitioned by (loc)
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.test1 values (1,"zs","beijing"),(2,"ls","shanghai")
""".stripMargin)
//创建 test2 普通表,并插入数据
spark.sql(
"""
|create table if not exists hadoop_prod.default.test2 (id int,name string,loc string)
|using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.test2 values (10,"x1","shandong"),(11,"x2","hunan")
""".stripMargin)
//创建 test3 普通表,并插入数据
spark.sql(
"""
|create table if not exists hadoop_prod.default.test3 (id int,name string,loc string)
|using iceberg
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.test3 values (3,"ww","beijing"),(4,"ml","shanghai"),(5,"tq","guangzhou")
""".stripMargin)
//使用insert overwrite 读取test3表中的数据覆盖到test2表中 -- 非分区插入非分区
spark.sql(
"""
|insert overwrite hadoop_prod.default.test2
|select id,name,loc from hadoop_prod.default.test3
|
""".stripMargin)
//查询 test2 表中的数据
spark.sql(
"""
|select * from hadoop_prod.default.test2
|
""".stripMargin).show()
// 使用insert overwrite 读取test3表数据 动态分区方式覆盖到表 test1 -- 非分区插入分区表
spark.sql(
"""
|insert overwrite hadoop_prod.default.test1
|select id,name,loc from hadoop_prod.default.test3
""".stripMargin)
//查询 test1 表数据
spark.sql(
"""
|select * from hadoop_prod.default.test1
""".stripMargin).show()
//spark 提交任务的命令
//spark-submit --master yarn --class com.shujia.spark.iceberg.InsertOverwrite spark-1.0.jar
}
}
=======第二部分==========
package com.shujia.spark.iceberg
import org.apache.spark.sql.SparkSession
object InsertOverwrite2 {
def main(args: Array[String]): Unit = {
/*
静态分区方式,将iceberg表test3的数据覆盖到Iceberg表test1中
这里可以将test1表删除,然后重新创建,加载数据,也可以直接读取test3中的数据静态分区方式更新到test1。
另外,使用insert overwrite 语法覆盖静态分区方式时,查询的语句中就不要再次写入分区列,否则会重复。
*/
val spark: SparkSession = SparkSession
.builder()
.appName("test")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://master:9000/spark")
.getOrCreate()
//删除表test1,重新创建表test1 分区表,并插入数据
spark.sql(
"""
|drop table hadoop_prod.default.test1
""".stripMargin)
spark.sql(
"""
|create table hadoop_prod.default.test1 (id int,name string,loc string)
|using iceberg
|partitioned by (loc)
""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.test1 values (1,"zs","beijing"),(2,"ls","shanghai")
""".stripMargin)
spark.sql("select * from hadoop_prod.default.test1").show()
//spark 提交任务的命令
//spark-submit --master yarn --class com.shujia.spark.iceberg.InsertOverwrite2 spark-1.0.jar
}
}
1.8.7.4 DELETE FROM
Spark3.x版本之后支持"Delete from"可以根据指定的where条件来删除表中数据。如果where条件匹配Iceberg表一个分区的数据,Iceberg仅会修改元数据,如果where条件匹配的表的单个行,则Iceberg会重写受影响行所在的数据文件。具体操作如下:
//创建表 delete_tbl ,并加载数据
spark.sql(
"""
|create table hadoop_prod.default.delete_tbl (id int,name string,age int) using iceberg
|""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.delete_tbl values (1,"zs",18),(2,"ls",19),(3,"ww",20),(4,"ml",21),(5,"tq",22),(6,"gb",23)
""".stripMargin)
//根据条件范围删除表 delete_tbl 中的数据
spark.sql(
"""
|delete from hadoop_prod.default.delete_tbl where id >3 and id <6
""".stripMargin)
spark.sql("select * from hadoop_prod.default.delete_tbl").show()
Iceberg 表 delete_tbl结果如下:
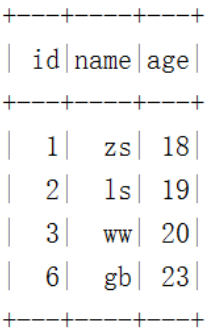
//根据条件删除表 delete_tbl 中的一条数据
spark.sql(
"""
|delete from hadoop_prod.default.delete_tbl where id = 2
""".stripMargin)
spark.sql("select * from hadoop_prod.default.delete_tbl").show()
Iceberg 表 delete_tbl结果如下:

测试DELECT FROM 测试代码及结果如下:
package com.shujia.spark.iceberg
import org.apache.spark.sql.SparkSession
object DeleteFrom {
def main(args: Array[String]): Unit = {
/*
Spark3.x版本之后支持"Delete from"可以根据指定的where条件来删除表中数据。
如果where条件匹配Iceberg表一个分区的数据,Iceberg仅会修改元数据,如果where条件匹配的表的单个行,\
则Iceberg会重写受影响行所在的数据文件。具体操作如下:
*/
val spark: SparkSession = SparkSession
.builder()
.appName("test")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://master:9000/spark")
.getOrCreate()
//创建表 delete_tbl ,并加载数据
spark.sql(
"""
|create table if not exists hadoop_prod.default.delete_tb2 (id int,name string,age int) using iceberg
|""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.delete_tb2 values
|(1,"zs",18),(2,"ls",19),(3,"ww",20),(4,"ml",21),(5,"tq",22),(6,"gb",23),(7,"gx",00)
|
""".stripMargin)
spark.sql("select * from hadoop_prod.default.delete_tb2").show()
//根据条件范围删除表 delete_tbl 中的数据
// spark.sql(
// """
// |
// |delete from hadoop_prod.default.delete_tb2 where id >3 and id <6
// |
// """.stripMargin)
spark.sql("select * from hadoop_prod.default.delete_tb2").show()
//根据条件删除表 delete_tbl 中的一条数据
spark.sql(
"""
|delete from hadoop_prod.default.delete_tb2 where id = 2
""".stripMargin)
spark.sql("select * from hadoop_prod.default.delete_tb2").show()
//spark 提交任务的命令
//spark-submit --master yarn --class com.shujia.spark.iceberg.DeleteFrom spark-1.0.jar
/**
*
* 进过测试:报错-错误信息如下:
*
* Exception in thread "main" org.apache.spark.sql.AnalysisException:
* Cannot delete from table hadoop_prod.default.delete_tb2 where [GreaterThan(id,3), LessThan(id,6)]
*
* 翻译:
* 线程“main”org.apache.spark.sql中出现异常。AnalysisException:
* 无法从表hadoop_prod.default中删除。delete_tb2其中[大于(id,3),小于(id,6)]
*
*
*/
}
}
1.8.7.5 UPDATE
Spark3.x+版本支持了update更新数据操作,可以根据匹配的条件进行数据更新操作。操作如下:
//创建表 delete_tbl ,并加载数据
spark.sql(
"""
|create table hadoop_prod.default.update_tbl (id int,name string,age int) using iceberg
|""".stripMargin)
spark.sql(
"""
|insert into hadoop_prod.default.update_tbl values (1,"zs",18),(2,"ls",19),(3,"ww",20),(4,"ml",21),(5,"tq",22),(6,"gb",23)
""".stripMargin)
通过“update”更新表中id小于等于3的数据name列改为“zhangsan”,age列改为30,操作如下:
//更新 delete_tbl 表
spark.sql(
"""
|update hadoop_prod.default.update_tbl set name = 'zhangsan' ,age = 30
|where id <=3
""".stripMargin)
spark.sql(
"""
|select * from hadoop_prod.default.update_tbl
""".stripMargin).show()
Iceberg 表 update_tbl结果如下:

1.8.7.6 DataFrame API 写入Iceberg表
Spark向Iceberg中写数据时不仅可以使用SQL方式,也可以使用DataFrame Api方式操作Iceberg,建议使用SQL方式操作。
DataFrame创建Iceberg表分为创建普通表和分区表,创建分区表时需要指定分区列,分区列可以是多个列。创建表的语法如下:
df.write(tbl).create() 相当于 CREATE TABLE AS SELECT ...
df.write(tbl).replace() 相当于 REPLACE TABLE AS SELECT ...
df.write(tbl).append() 相当于 INSERT INTO ...
df.write(tbl).overwritePartitions() 相当于动态 INSERT OVERWRITE ...
具体操作如下:
//1.准备数据,使用DataFrame Api 写入Iceberg表及分区表
val nameJsonList = List[String](
"{\"id\":1,\"name\":\"zs\",\"age\":18,\"loc\":\"beijing\"}",
"{\"id\":2,\"name\":\"ls\",\"age\":19,\"loc\":\"shanghai\"}",
"{\"id\":3,\"name\":\"ww\",\"age\":20,\"loc\":\"beijing\"}",
"{\"id\":4,\"name\":\"ml\",\"age\":21,\"loc\":\"shanghai\"}")
import spark.implicits._
val df: DataFrame = spark.read.json(nameJsonList.toDS)
//创建普通表df_tbl1,并将数据写入到Iceberg表,其中DF中的列就是Iceberg表中的列
df.writeTo("hadoop_prod.default.df_tbl1").create()
//查询表 hadoop_prod.default.df_tbl1 中的数据,并查看数据存储结构
spark.read.table("hadoop_prod.default.df_tbl1").show()
Iceberg 表 df_tbl1结果如下:

Iceberg 表 df_tbl1存储如下:
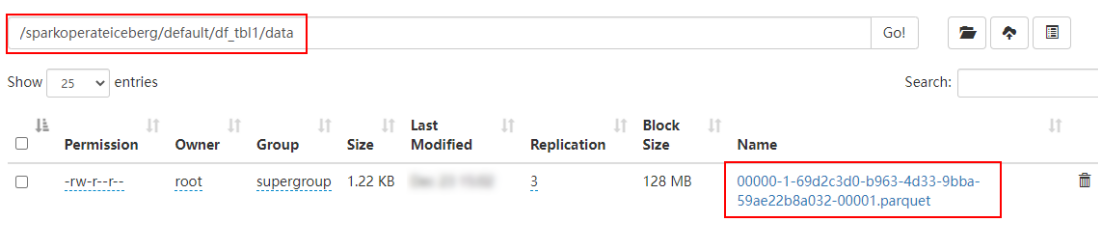
//创建分区表df_tbl2,并将数据写入到Iceberg表,其中DF中的列就是Iceberg表中的列
df.sortWithinPartitions($"loc")//写入分区表,必须按照分区列进行排序
.writeTo("hadoop_prod.default.df_tbl2")
.partitionedBy($"loc")//这里可以指定多个列为联合分区
.create()
//查询分区表 hadoop_prod.default.df_tbl2 中的数据,并查看数据存储结构
spark.read.table("hadoop_prod.default.df_tbl2").show()
Iceberg 分区表 df_tbl2结果如下:

Iceberg 分区表 df_tbl2存储如下:

1.8.8 Structured Streaming实时写入Iceberg
目前Spark中Structured Streaming只支持实时向Iceberg中写入数据,不支持实时从Iceberg中读取数据,下面案例我们将使用Structured Streaming从Kafka中实时读取数据,然后将结果实时写入到Iceberg中。
- 创建Kafka topic
启动Kafka集群,创建“kafka-iceberg-topic”
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic kafka-iceberg-topic --partitions 3 --replication-factor 3
- 编写向Kafka生产数据代码
/**
* 向Kafka中写入数据
*/
object WriteDataToKafka {
def main(args: Array[String]): Unit = {
val props = new Properties()
props.put("bootstrap.servers", "node1:9092,node2:9092,node3:9092")
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String,String](props)
var counter = 0
var keyFlag = 0
while(true){
counter +=1
keyFlag +=1
val content: String = userlogs()
producer.send(new ProducerRecord[String, String]("kafka-iceberg-topic", content))
//producer.send(new ProducerRecord[String, String]("kafka-iceberg-topic", s"key-$keyFlag", content))
if(0 == counter%100){
counter = 0
Thread.sleep(5000)
}
}
producer.close()
}
def userlogs()={
val userLogBuffer = new StringBuffer("")
val timestamp = new Date().getTime();
var userID = 0L
var pageID = 0L
//随机生成的用户ID
userID = Random.nextInt(2000)
//随机生成的页面ID
pageID = Random.nextInt(2000);
//随机生成Channel
val channelNames = Array[String]("Spark","Scala","Kafka","Flink","Hadoop","Storm","Hive","Impala","HBase","ML")
val channel = channelNames(Random.nextInt(10))
val actionNames = Array[String]("View", "Register")
//随机生成action行为
val action = actionNames(Random.nextInt(2))
val dateToday = new SimpleDateFormat("yyyy-MM-dd").format(new Date())
userLogBuffer.append(dateToday)
.append("\t")
.append(timestamp)
.append("\t")
.append(userID)
.append("\t")
.append(pageID)
.append("\t")
.append(channel)
.append("\t")
.append(action)
System.out.println(userLogBuffer.toString())
userLogBuffer.toString()
}
}
- 编写Structured Streaming读取Kafka数据实时写入Iceberg
object StructuredStreamingSinkIceberg {
def main(args: Array[String]): Unit = {
//1.准备对象
val spark: SparkSession = SparkSession.builder().master("local").appName("StructuredSinkIceberg")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/structuredstreaming")
.getOrCreate()
// spark.sparkContext.setLogLevel("Error")
//2.创建Iceberg 表
spark.sql(
"""
|create table if not exists hadoop_prod.iceberg_db.iceberg_table (
| current_day string,
| user_id string,
| page_id string,
| channel string,
| action string
|) using iceberg
""".stripMargin)
val checkpointPath = "hdfs://mycluster/iceberg_table_checkpoint"
val bootstrapServers = "node1:9092,node2:9092,node3:9092"
//多个topic 逗号分开
val topic = "kafka-iceberg-topic"
//3.读取Kafka读取数据
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServers)
.option("auto.offset.reset", "earliest")
.option("group.id", "iceberg-kafka")
.option("subscribe", topic)
.load()
import spark.implicits._
import org.apache.spark.sql.functions._
val resDF = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)].toDF("id", "data")
val transDF: DataFrame = resDF.withColumn("current_day", split(col("data"), "\t")(0))
.withColumn("ts", split(col("data"), "\t")(1))
.withColumn("user_id", split(col("data"), "\t")(2))
.withColumn("page_id", split(col("data"), "\t")(3))
.withColumn("channel", split(col("data"), "\t")(4))
.withColumn("action", split(col("data"), "\t")(5))
.select("current_day", "user_id", "page_id", "channel", "action")
//结果打印到控制台,Default trigger (runs micro-batch as soon as it can)
// val query: StreamingQuery = transDF.writeStream
// .outputMode("append")
// .format("console")
// .start()
//4.流式写入Iceberg表
val query = transDF.writeStream
.format("iceberg")
.outputMode("append")
//每分钟触发一次Trigger.ProcessingTime(1, TimeUnit.MINUTES)
//每10s 触发一次 Trigger.ProcessingTime(1, TimeUnit.MINUTES)
.trigger(Trigger.ProcessingTime(10, TimeUnit.SECONDS))
.option("path", "hadoop_prod.iceberg_db.iceberg_table")
.option("fanout-enabled", "true")
.option("checkpointLocation", checkpointPath)
.start()
query.awaitTermination()
}
}
注意:以上代码执行时由于使用的Spark版本为3.1.2,其依赖的Hadoop版本为Hadoop3.2版本,所以需要在本地Window中配置Hadoop3.1.2的环境变量以及将对应的hadoop.dll放入window "C:\Windows\System32"路径下。
Structuerd Streaming向Iceberg实时写入数据有以下几个注意点:
- 写Iceberg表写出数据支持两种模式:append和complete,append是将每个微批数据行追加到表中。complete是替换每个微批数据内容。
- 向Iceberg中写出数据时指定的path可以是HDFS路径,可以是Iceberg表名,如果是表名,要预先创建好Iceberg表。
- 写出参数fanout-enabled指的是如果Iceberg写出的表是分区表,在向表中写数据之前要求Spark每个分区的数据必须排序,但这样会带来数据延迟,为了避免这个延迟,可以设置“fanout-enabled”参数为true,可以针对每个Spark分区打开一个文件,直到当前task批次数据写完,这个文件再关闭。
- 实时向Iceberg表中写数据时,建议trigger设置至少为1分钟提交一次,因为每次提交都会产生一个新的数据文件和元数据文件,这样可以减少一些小文件。为了进一步减少数据文件,建议定期合并“data files”(参照1.9.6.9)和删除旧的快照(1.9.6.10)。
- 查看Iceberg中数据结果
启动向Kafka生产数据代码,启动向Iceberg中写入数据的Structured Streaming程序,执行以下代码来查看对应的Iceberg结果:
//1.准备对象
val spark: SparkSession = SparkSession.builder().master("local").appName("StructuredSinkIceberg")
//指定hadoop catalog,catalog名称为hadoop_prod
.config("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.config("spark.sql.catalog.hadoop_prod.type", "hadoop")
.config("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://mycluster/structuredstreaming")
.getOrCreate()
//2.读取Iceberg 表中的数据结果
spark.sql(
"""
|select * from hadoop_prod.iceberg_db.iceberg_table
""".stripMargin).show()