最小生成树
定义
我们定义无向连通图的 最小生成树(Minimum Spanning Tree,MST)为边权和最小的生成树。
注意:只有连通图才有生成树,而对于非连通图,只存在生成森林。
题目
链接
题目描述
如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出 orz。
输入格式
第一行包含两个整数 \(N,M\),表示该图共有 \(N\) 个结点和 \(M\) 条无向边。
接下来 \(M\) 行每行包含三个整数 \(X_i,Y_i,Z_i\),表示有一条长度为 \(Z_i\) 的无向边连接结点 \(X_i,Y_i\)。
输出格式
如果该图连通,则输出一个整数表示最小生成树的各边的长度之和。如果该图不连通则输出 orz。
样例 #1
样例输入 #1
4 5
1 2 2
1 3 2
1 4 3
2 3 4
3 4 3
样例输出 #1
7
提示
数据规模:
对于 \(20\%\) 的数据,\(N\le 5\),\(M\le 20\)。
对于 \(40\%\) 的数据,\(N\le 50\),\(M\le 2500\)。
对于 \(70\%\) 的数据,\(N\le 500\),\(M\le 10^4\)。
对于 \(100\%\) 的数据:\(1\le N\le 5000\),\(1\le M\le 2\times 10^5\),\(1\le Z_i \le 10^4\)。
样例解释:
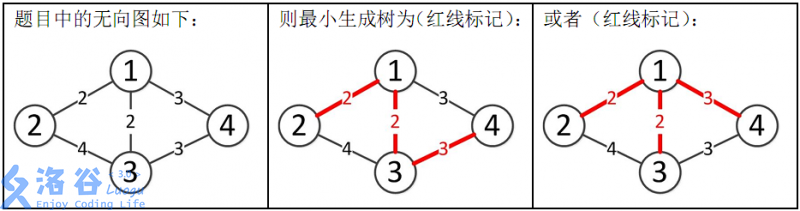
所以最小生成树的总边权为 \(2+2+3=7\)。
前置知识
贪心
贪心算法(英语:greedy algorithm),是用计算机来模拟一个「贪心」的人做出决策的过程。这个人十分贪婪,每一步行动总是按某种指标选取最优的操作。而且他目光短浅,总是只看眼前,并不考虑以后可能造成的影响。
可想而知,并不是所有的时候贪心法都能获得最优解,所以一般使用贪心法的时候,都要确保自己能证明其正确性。
图的存储
直接存边
邻接矩阵
邻接表
链式前向星
并查集
Prim求最小生成树
实现
预先选择一个点,加入生成树中,对当前生成树选择距其他点最小的点,将其加入生成树中,循环直至将所有点加入生成树中,此时该生成树即为最小生成树
证明
从任意一个结点开始,将结点分成两类:已加入的,未加入的。
每次从未加入的结点中,找一个与已加入的结点之间边权最小值最小的结点。
然后将这个结点加入,并连上那条边权最小的边。
重复 \(n-1\) 次即可。
证明:还是说明在每一步,都存在一棵最小生成树包含已选边集。
基础:只有一个结点的时候,显然成立。
归纳:如果某一步成立,当前边集为 \(F\) ,属于 这棵 \(MST\),接下来要加入边 \(e\) 。
如果 \(e\) 属于 \(T\) ,那么成立。
否则考虑 \(T+e\) 中环上另一条可以加入当前边集的边 \(f\) 。
首先, \(f\) 的权值一定不小于 \(e\) 的权值,否则就会选择 \(f\) 而不是 \(e\) 了。
然后, \(f\) 的权值一定不大于 \(e\) 的权值,否则 \(T+e-f\) 就是一棵更小的生成树了。
因此, 和 的权值相等, \(T+e-f\) 也是一棵最小生成树,且包含了 \(F\) 。
Code
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.StreamTokenizer;
import java.util.Arrays;
public class Main {
//加BufferedReader在大量读入数据的情况下可以有效的减少内存占用
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws Exception {
in.nextToken();
return (int) in.nval;
}
//链式前向星存图
static class edge {
//next存储下一条边的编号,to存储该边终点,weight存储该边权值
int next, to, weight;
public edge(int next, int to, int weight) {
this.next = next;
this.to = to;
this.weight = weight;
}
}
//存边,若是无向图,则需要两倍内存
static edge[] edges;
//head[i]存储以i号节点为起点的最后读入的一条边的编号
static int[] head;
//n为顶点数,m为边数,cnt累增来给每条边赋编号
static int n, m, cnt = 0;
//头插法加边
static void add(int u, int v, int w) {
edges[++cnt] = new edge(head[u], v, w);
head[u] = cnt;
}
//prim求最小生成树,以now为起点(实际上选择任意一个节点为起点皆可)
static int prim(int now) {
//vis[i]代表i号节点当前是否被选择
boolean[] vis = new boolean[n + 1];
//dis[i]代表当前的生成树中距离与i号节点的距离
int[] dis = new int[n + 1];
//赋为极大值
Arrays.fill(dis, Integer.MAX_VALUE);
//用now点的所有出边修改dis
dis[now] = 0;
for (int i = head[now]; i != 0; i = edges[i].next) {
if (dis[edges[i].to] > edges[i].weight)
dis[edges[i].to] = edges[i].weight;
}
//最小生成树的所有边的权值
int ans = 0;
//选出n-1条边
for (int k = 1, minn; k < n; ++k) {
//用于判断是否为连通图,若保证连通则可去掉
minn = Integer.MAX_VALUE;
//选上当前点
vis[now] = true;
//选出权值最小的边(贪心思想)
for (int i = 1; i <= n; ++i) {
if (!vis[i] && dis[i] < minn) {
minn = dis[i];
now = i;
}
}
//若minn仍为初值,则说明为非连通图
if (minn == Integer.MAX_VALUE) return minn;
ans += minn;
//遍历新加入的点的出边,修改dis
for (int i = head[now]; i != 0; i = edges[i].next) {
if (!vis[edges[i].to] && dis[edges[i].to] > edges[i].weight)
dis[edges[i].to] = edges[i].weight;
}
}
return ans;
}
public static void main(String[] args) throws Exception {
n = get();
m = get();
edges = new edge[m << 1 | 1];
head = new int[n + 1];
for (int i = 0, u, v, w; i < m; ++i) {
u = get();
v = get();
w = get();
add(u, v, w);
add(v, u, w);
}
int ans = prim(1);
if (ans == Integer.MAX_VALUE) System.out.println("orz");
else System.out.println(ans);
}
}
Kruskal求最小生成树
实现
对边集排序,依次选择权值最小的边,且加入该边不会产生环,直至加入了 \(n-1\) 条边,如果最终不够 \(n-1\) 条边,则说明该图非连通
证明
思路很简单,为了造出一棵最小生成树,我们从最小边权的边开始,按边权从小到大依次加入,如果某次加边产生了环,就扔掉这条边,直到加入了 \(n-1\) 条边,即形成了一棵树。
证明:使用归纳法,证明任何时候 \(K\) 算法选择的边集都被某棵 \(MST\) 所包含。
基础:对于算法刚开始时,显然成立(最小生成树存在)。
归纳:假设某时刻成立,当前边集为 \(F\) ,令 \(T\) 为这棵 \(MST\) ,考虑下一条加入的边 \(e\) 。
如果 \(e\) 属于 \(T\) ,那么成立。
否则, \(T+e\) 一定存在一个环,考虑这个环上不属于 \(F\) 的另一条边 \(f\) (一定只有一条)。
首先, \(f\) 的权值一定不会比 \(e\) 小,不然 \(f\) 会在 \(e\) 之前被选取。
然后, \(f\) 的权值一定不会比 \(e\) 大,不然 \(T+e-f\) 就是一棵比 \(T\) 还优的生成树了。
所以, \(T+e-f\) 包含了 \(F\) ,并且也是一棵最小生成树,归纳成立。
Code
import java.io.*;
import java.util.Arrays;
public class Main {
//读入,加BufferedReader在大量读入数据的情况下可以有效的减少内存占用
static StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
static int get() throws Exception {
in.nextToken();
return (int) in.nval;
}
//Kruskal直接存边
static class edge {
int from, to, weight;
public edge(int from, int to, int weight) {
this.from = from;
this.to = to;
this.weight = weight;
}
}
//边集
static edge[] edges;
//并查集
static DSU dsu;
static int Kruskal(int n, int m) {
//按边权对边从小到大排序
Arrays.sort(edges, (w1, w2) -> w1.weight - w2.weight);
//选了多少条边
int cnt = 0;
int ans = 0;
//遍历从小到大遍历所有边,如果节点已经加入过生成树中,则跳过
for (int i = 0; i < m; ++i) {
//合并包含from节点与包含to节点的两颗树
//如果可以合并则加入答案
if (dsu.merge(edges[i].from, edges[i].to)) {
ans += edges[i].weight;
//当有n-1条边时,已经满足条件
if (++cnt == n - 1) return ans;
}
}
//若遍历了所有边,即能选择的边不足n-1,则说明该图非连通
return -1;
}
public static void main(String[] args) throws Exception {
int n = get(), m = get();
//由于是直接合并两棵树,所以对于无向图,只用加入一条边
edges = new edge[m];
dsu = new DSU(n);
for (int i = 0; i < m; ++i) {
edges[i] = new edge(get(), get(), get());
}
int ans = Kruskal(n, m);
if (ans == -1) System.out.println("orz");
else System.out.println(ans);
}
}
class DSU {
int[] parent;
public DSU(int n) {
parent = new int[n + 1];
//初始化n个集合
for (int i = 1; i <= n; ++i) parent[i] = i;
}
//一步一步找祖先,并进行路径压缩
public int find(int x) {
return parent[x] == x ? x : (parent[x] = find(parent[x]));
}
//合并两颗树
public boolean merge(int x, int y) {
x = find(x);
y = find(y);
//如果两个点在同一颗树中,则不合并,并返回false
if (x == y) return false;
parent[x] = y;
return true;
}
public boolean same(int x, int y) {
return find(x) == find(y);
}
}