邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.
https://github.com/nndl/practice-in-paddle/
第2章 机器学习概述
机器学习(Machine Learning,ML)就是让计算机从数据中进行自动学习,得到某种知识(或规律)。作为一门学科,机器学习通常指一类问题以及解决这类问题的方法,即如何从观测数据(样本)中寻找规律,并利用学习到的规律(模型)对未知或无法观测的数据进行预测。
在学习本章内容前,建议您先阅读《神经网络与深度学习》第 2 章:机器学习概述的相关内容,关键知识点如图2.1所示,以便更好的理解和掌握相应的理论知识,及其在实践中的应用方法。
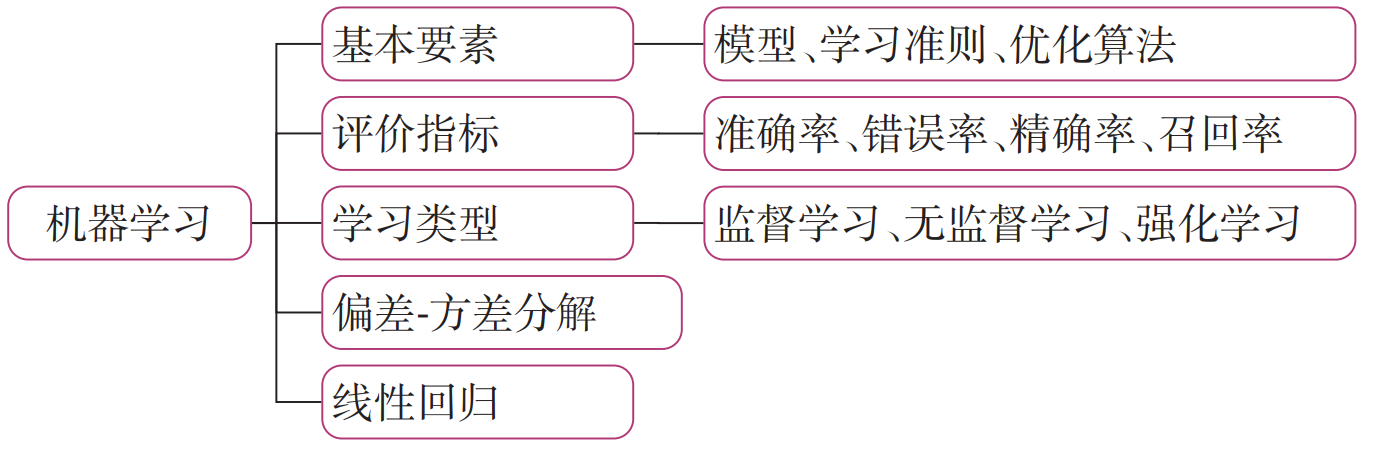
本章内容基于《神经网络与深度学习》第 2 章:机器学习概述 相关内容进行设计,主要包含两部分:
- 模型解读:介绍机器学习实践五要素(数据、模型、学习准则、优化算法、评估指标)的原理剖析和相应的代码实现。通过理论和代码的结合,加深对机器学习的理解;
- 案例实践:基于机器学习线性回归方法,通过数据处理、模型构建、训练配置、组装训练框架Runner、模型训练和模型预测等过程完成波士顿房价预测任务。
2.1 机器学习实践五要素
要通过机器学习来解决一个特定的任务时,我们需要准备5个方面的要素:
- 数据集:收集任务相关的数据集用来进行模型训练和测试,可分为训练集、验证集和测试集;
- 模型:实现输入到输出的映射,通常为可学习的函数;
- 学习准则:模型优化的目标,通常为损失函数和正则化项的加权组合;
- 优化算法:根据学习准则优化机器学习模型的参数;
- 评价指标:用来评价学习到的机器学习模型的性能.
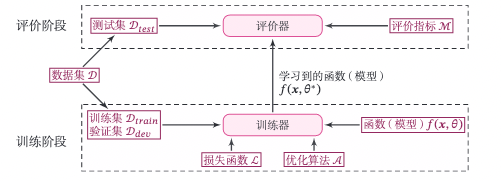
图2.2给出实现一个完整的机器学习系统的主要环节和要素。从流程角度看,实现机器学习系统可以分为两个阶段:训练阶段和评价阶段。训练阶段需要用到训练集、验证集、待学习的模型、损失函数、优化算法,输出学习到的模型;评价阶段也称为测试阶段,需要用到测试集、学习到的模型、评价指标体系,得到模型的性能评价。
在本节中,我们分别对这五个要素进行简单的介绍。
《神经网络与深度学习》第 2.2 节详细介绍了机器学习的三个基本要素:“模型”、“学习准则”和“优化算法”.在机器学习实践中,“数据”和“评价指标”也非常重要.因此,本书将机器学习在实践中的主要元素归结为五要素.
2.1.1 数据
在实践中,数据的质量会很大程度上影响模型最终的性能,通常数据预处理是完成机器学习实践的第一步,噪音越少、规模越大、覆盖范围越广的数据集往往能够训练出性能更好的模型。数据预处理可分为两个环节:先对收集到的数据进行基本的预处理,如基本的统计、特征归一化和异常值处理等;再将数据划分为训练集、验证集(开发集)和测试集。
- 训练集:用于模型训练时调整模型的参数,在这份数据集上的误差被称为训练误差;
- 验证集(开发集):对于复杂的模型,常常有一些超参数需要调节,因此需要尝试多种超参数的组合来分别训练多个模型,然后对比它们在验证集上的表现,选择一组相对最好的超参数,最后才使用这组参数下训练的模型在测试集上评估测试误差。
- 测试集:模型在这份数据集上的误差被称为测试误差。训练模型的目的是为了通过从训练数据中找到规律来预测未知数据,因此测试误差是更能反映出模型表现的指标。
数据划分时要考虑到两个因素:更多的训练数据会降低参数估计的方差,从而得到更可信的模型;而更多的测试数据会降低测试误差的方差,从而得到更可信的测试误差。如果给定的数据集没有做任何划分,我们一般可以大致按照7:3或者8:2的比例划分训练集和测试集,再根据7:3或者8:2的比例从训练集中再次划分出训练集和验证集。
需要强调的是,测试集只能用来评测模型最终的性能,在整个模型训练过程中不能有测试集的参与。
2.1.2 模型
有了数据后,我们可以用数据来训练模型。我们希望能让计算机从一个函数集合 \(\mathcal{F} = \{f_1(\boldsymbol{x}), f_2(\boldsymbol{x}), \cdots \}\)中
自动寻找一个“最优”的函数\(f^∗(\boldsymbol{x})\) 来近似每个样本的特征向量 \(\boldsymbol{x}\) 和标签 \(y\) 之间
的真实映射关系,实际上这个函数集合也被称为假设空间,在实际问题中,假设空间\(\mathcal{F}\)通常为一个参数化的函数族
其中\(f(\boldsymbol{x} ; \theta)\)是参数为\(\theta\)的函数,也称为模型,
标签:pred,模型,boldsymbol,paddle,NNDL,train,实验,test From: https://www.cnblogs.com/hbuwyg/p/16617442.html