Flink调优之前,必须先看懂的TaskManager内存模型
Task Manager内存模型
Flink的程序运行在内存中。不管是我们在学习C语言、Java语言的时候,我们都很想知道程序到底是如何管理内存的。Flink程序也一样,当我们写完Flink程序,我们需要为Flink程序分配运行的资源,那针对什么样的数据量,需要分配多少内存,以及将来在程序运行的过程中,出现性能瓶颈的地方,如何调整优化等等,我们都非常有必要先学习、理解Flink的内存管理。
我们知道,Flink不管是运行在Standalone或者是YARN集群,都需要运行对应的Job Manager和Task Manager。所以,而且Flink也是可以基于内存进行迭代式计算的计算框架,而要能够达到高效运行Flink Job的目的,Flink自身必须要能够提供优秀的内存管理,以此来保证利用更小的资源、并保证Job执行的稳定性。
在我之前写的这篇文章里,当场打脸面试官,Flink流处理任务到底啥时候释放?,大家可以看到,Flink的Task都是运行在Task Manager中的。所以Task Manager的内存管理效率,直接决定了任务的执行效率。
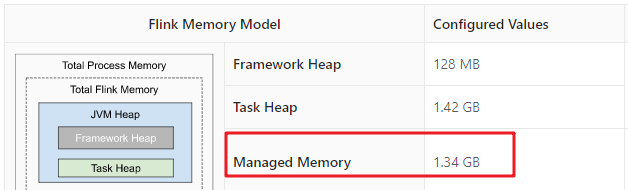
在Web UI中,点开任意的一个Task Manager,我们可以看到该Task Manager的相关资源信息。例如:该Task Manager能够使用的物理内存是6.64GB、JVM堆内存的大小是1.55GB、以及Flink管理的内存是1.34GB。
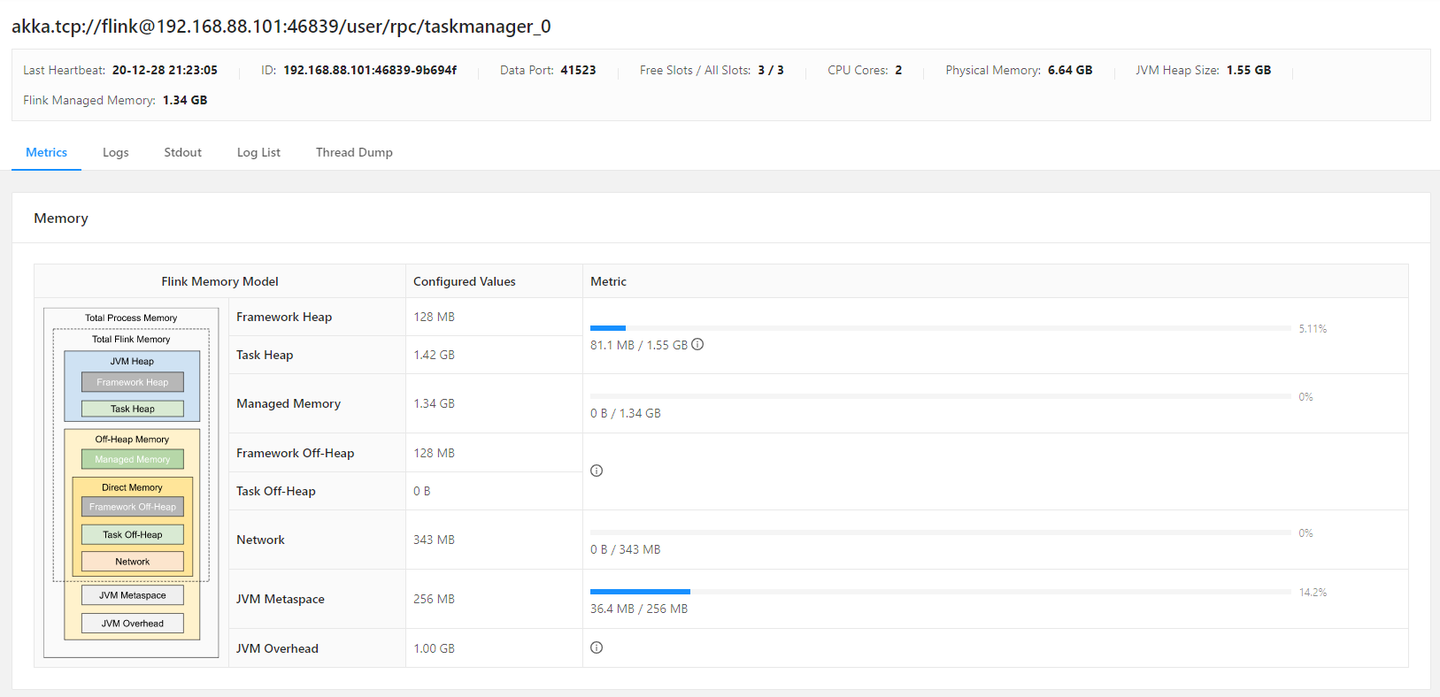
其中,有一个Flink Memory Model的图,它清晰地描述了Flink的Task Manager进程的内存区域。Task Manager的内存模型相对于Job Manager是要复杂一些的。因为它是任务运行的地方。

Flink的Task Manager是一个JVM进程。通过Linux的ps命令,我们可以看到Task Manager的进程启动命令。如下所示:
/opt/jdk1.8.0_241//bin/java -XX:+UseG1GC -Xmx1664299798 -Xms1664299798 -XX:MaxDirectMemorySize=493921243 -XX:MaxMetaspaceSize=268435456 -Dlog.file=/opt/flink-1.12.0/log/flink-root-taskexecutor-0-node2.log …(其他省略)我们可以看到Flink启动的Java进程,指定使用的是G1 GC来进垃圾回收。并且桶-Xmx来指定,当前最大的堆内存为1.5GB,通过-Xms来指定初始的堆内存大小,也为1.5GB。还有NIO buffer的大小为500M左右,还有就是Metaspace最大扩容内存为256MB。
这也说明,我们的Task都将运行在这一各名为Task Manager的JVM进程中。接下来,我们来分析以下该JVM进程的内部结构。
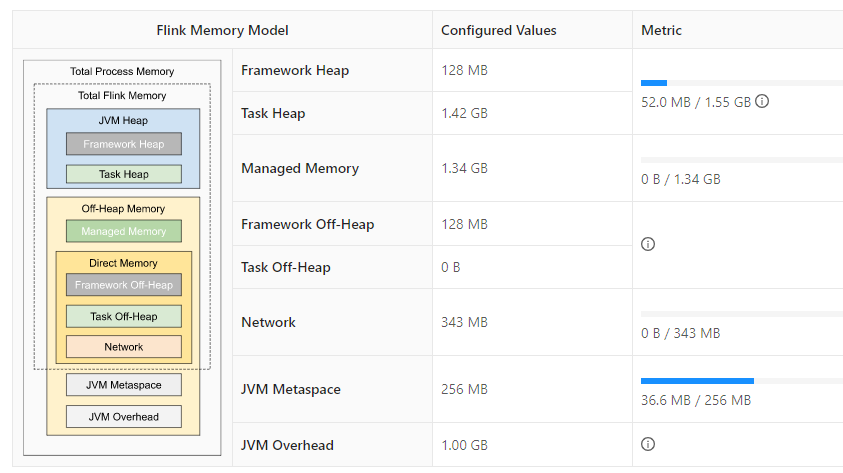
Task Manager的内存模型,分为5大部分:堆内存、堆外内存、直接内存、MetaSpace内存以及JVM Overhead内存。我们把所有内存加在一起:刚好就是4GB。也就是整个Task Manger JVM所占用的内存为4GB。
为什么是4GB呢?
因为在flink-conf.yml中配置的taskmanager.memory.process.size = 4096m,也就是4个G。
# The total process memory size for the TaskManager.
#
# Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.
taskmanager.memory.process.size: 4096m大家,也看到了,Flink提示我们说,这是所有分配给Task Manger进程的总内存大小。我们可以将此总内存大小调整为6GB,我们再观察对下Flink的内存模型图。
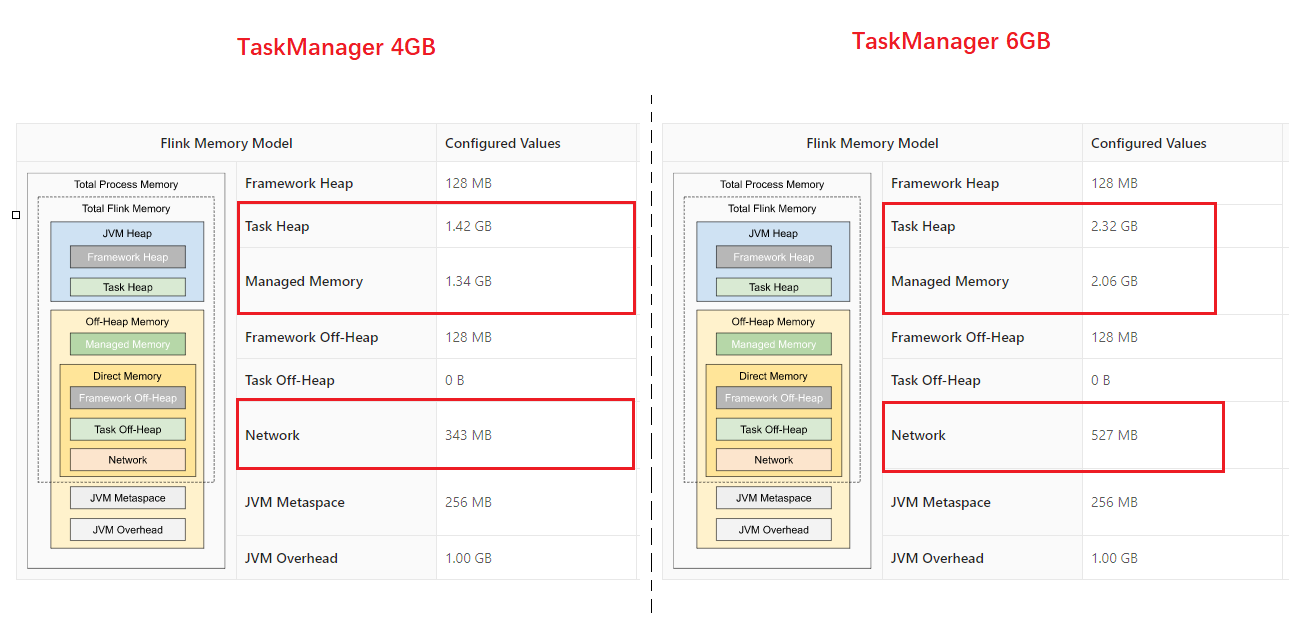
大家可以看到,但我们把TaskManager的process size设置为时,Task Heap、Managed Memory、Network的内存都提升了。
好接下来,我们就走进Task Manager JVM内存内部,看看具体的某个内存区域是用来做什么以及怎么分配的。
Heap、Native memory、Direct Memory
Heap
使用Java代码new出来的对象说占用的内存都是存放在Heap(堆)内存中,它由JVM垃圾收集器维护。
Native Memory/Off-Heap
NativeMemory或者是Off-heap是在进程地址空间内分配的内存,这部分内存不再堆内。JVM的GC是不会自动回收这个部分的内存的。
Direct Memory
Direct Memory是off-heap Big Memory的实现,能够在内存中序列化大批量的Java对象,并且不影响JVM GC性能。
Total Process Memory与Total Flink Memory
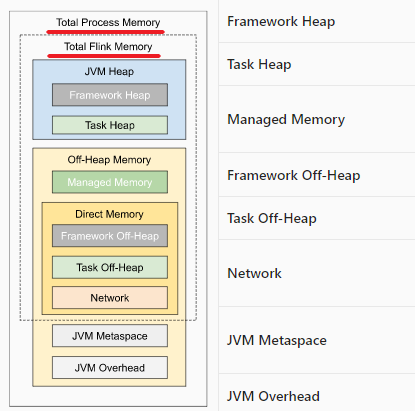
在上面这幅图中,有一个Total Process Memory和一个Total Flink Memory。Total Process Memory表示整个Task Manager的进程内存,所有这张图的内存加在一块就是Total Process Memory。taskmanager.memory.process.size: 4096m,这个配置就是对Task Manager配置总的使用内存的all in one配置。
而Total Flink Memory表示Task Executor消耗的所有内存,也就是除了JVM Metaspace和JVM Overhead其他的加在一起就是Total Flink Memory。Task Executor是专门负责执行Flink任务的,可以执行多个任务。通过查看Flink TaskManager的日志,可以说Task Executor这个组件实现了非常重要的一些功能。
Connecting to ResourceManager akka.tcp://flink@node1:6123/user/rpc/resourcemanager_* 连接资源管理器Receive slot request 652af8f1335064faef95a2f4980c7ab7 for job
接收ResourceManager发出的slot请求Allocated slot for 652af8f1335064faef95a2f4980c7ab7.
分配slotReceived task CHAIN DataSource
接收任务链Un-registering task and sending final execution state FINISHED to JobManager for task Reduce
取消任务注册,并发送任务的执行状态给JobManager
…
大家可以看到,Task Manager中的Task Executor扮演了非常重要的角色。Task Manager上资源的分配、任务的执行都是由Task Executor来实现的。而这个Total Flink Memory就表示Task Executor能够使用的内存总量。这个内存总量除了JVM Metaspace和JVM overhead(后续,我再介绍这两个部分的内存空间)。
我们可以通过taskmanager.memory.flink.size来指定Flink Task Executor一共能够使用的内存。Flink官方也建议我们不要同时配置taskmanager.memory.process.size和taskmanager.memory.process.size。
# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.
taskmanager.memory.flink.size: 1280m
JVM Heap
JVM Heap中分为两大部分,一个是Flink 框架所需要使用的堆内存,还有一个是每个Task运行所需的对内存。
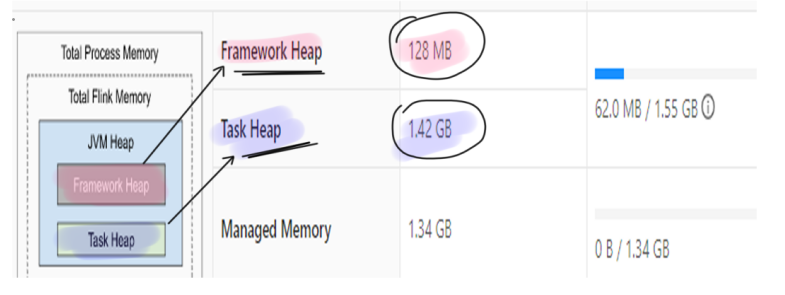
我们可以看到,当前Flink TaskManager框架自身配置的内存是128MB。而Task Heap配置的内存是1.42GB。当前Task Manager没有运行任何的Job,一共只占用了62MB的内存。
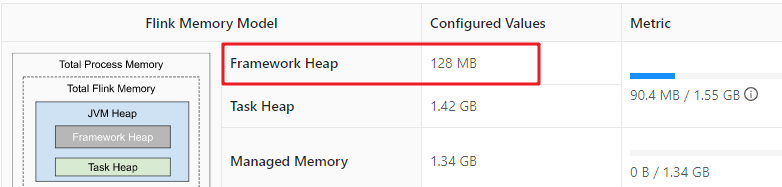
Framework Heap
Framework heap其实是为Task Executor本身所配置的堆内存大小,因为Task Executor本身也是一个Java。Framework Heap是Flink框架保留的,是不会用来执行Task的。该堆的大小由taskmanager.memory.framework.heap.size参数控制,它的运行所需资源比较轻量级,默认为128M。
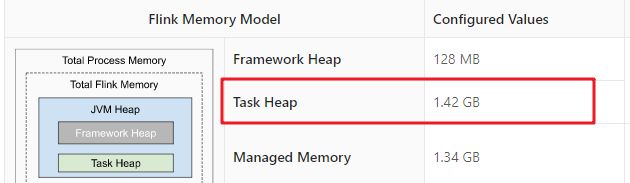
Task Heap
Task Heap Memory是专门用于执行Flink任务的堆内存空间。该堆的大小由taskmanager.memory.task.heap.size参数指定。这个参数的默认为:Total Flink Memory – Framework Heap – Task off-heap memory – Managed Memory – Network Memory。
Managed Memory Off-Heap Memory
Managed Memory是由Flink直接管理的off-heap内存,它主要用于排序、哈希表、中间结果缓存、RocksDB的backend。其实它是Task Executor管理的off-heap内存。它可以由taskmanager.memory.managed.size 参数直接配置指定,默认是不配置的。默认是通过
taskmanager.memory.managed.fraction配置的因子(默认0.4)来设置Managed off-heap memory,默认为Total Flink Memory的40%。
Direct Memory
Framework Off-heap Memory
Task Executor保留的off-heap memory,不会分配给任何slot。可以通过taskmanager.memory.framework.off-heap.size参数指定,默认为128M。
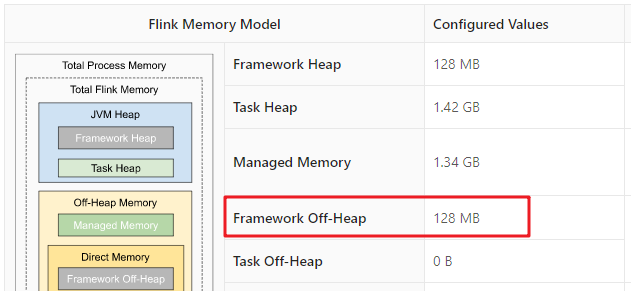
这里说一嘴,Framework所保留的内存,一般是不建议调整的。
Task Off-heap Memory
Task Executor执行的Task所使用的堆外内存。如果在Flink应用的代码中调用了Native的方法,需要用到off-heap内存,这些内存会分配到Off-heap堆外内存中。可以通过指定taskmanager.memory.task.off-heap.size来配置,默认为0。如果代码中需要调用Native Method并分配堆外内存,可以指定该参数。一般不使用,所以大多数时候可以保持0。
Network Memory
Network Memory使用的是Directory memory,在Task与Task之间进行数据交换时(shuffle),需要将数据缓存下来,缓存能够使用的内存大小就是这个Network Memory。它由是三个参数决定:
- taskmanager.memory.network.min:默认为64MB
- taskmanager.memory.network.max:默认为1gb
- taskmanager.memory.network.fraction:默认为0.1
Network Memory有两种配置方式,一种是通过taskmanager.memory.network.fraction参数,也就是Total Flink Memory的百分比,默认为Total Flink Meory的10%。还有一种是通过taskmanager.memory.network.min和taskmanager.memory.network.max指定shuffle缓存在min-max之间的内存空间。如果使用fraction计算出来的Network Meory超出min-max的范围,那么以min-max为准。如果配置的min和max是一样的值,就使用固定的内存大小。
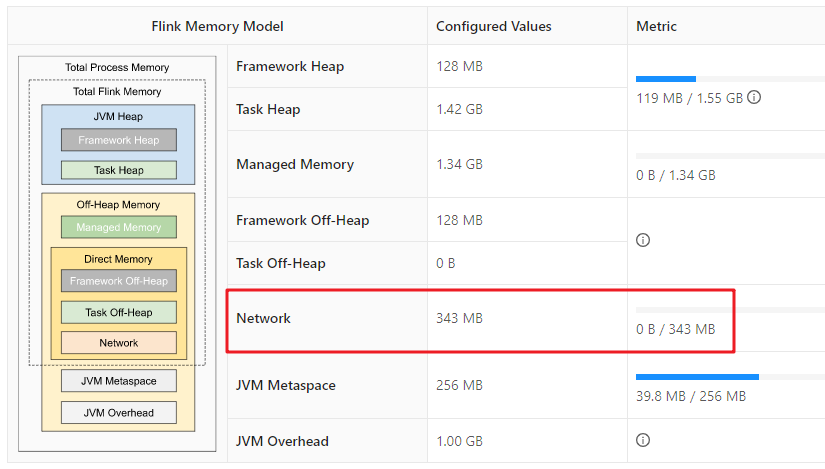
我们来算一下:当前的Total Flink Meory为:3425MB,而network.fraction为0.1,min为64MB,max为1GB,所以好Network Meory在min-max之间,为343MB。
JVM Metaspace Memory
从JDK 8开始,JVM把永久代拿掉了。类的一些元数据放在叫做Metaspace的Native Memory中。在Flink中的JVM Metaspace Memory也一样,它配置的是Task Manager JVM的元空间内存大小。通过taskmanager.memory.jvm-metaspace.size参数配置,默认为256MB。

JVM Overhead
保留给JVM其他的内存开销。例如:Thread Stack、code cache、GC回收空间等等。和Network Memory的配置方法类似。它也由三个配置决定:
- taskmanager.memory.jvm-overhead.min:默认为192MB,
- taskmanager.memory.jvm-overhead.max:默认为1GB
- taskmanager.memory.jvm-overhead.fraction:默认为0.1。

参考文献:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/memory/mem_setup_tm.html
https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/config.html#taskmanager-memory-task-heap-size
原文链接:https://zhuanlan.zhihu.com/p/340345588
标签:Task,Flink,TaskManager,调优,Memory,内存,memory,taskmanager From: https://www.cnblogs.com/sunny3158/p/18544617