内存是什么?
内存就是计算机的存储空间,用于存储程序的指令、数据和状态。在 C 语言中,内存被组织成一系列的字节,每个字节都有一个唯一的地址。程序中的变量和数据结构存储在这些字节中。根据变量的类型和作用域,内存分为几个区域,如栈(stack)、堆(heap)和全局/静态存储区。
内存编址
计算机的内存是一块用于存储数据的空间,由一系列连续的存储单元组成,就像下面这样,
byte 作为内存寻址的最小单元,也就是给每个 byte 一个编号,这个编号就叫内存的地址。
内存地址空间
上面我们说给内存中每个 byte 唯一的编号,那么这个编号的范围就决定了计算机可寻址内存的范围。
所有编号连起来就叫做内存的地址空间,这和大家平时常说的电脑是 32 位还是 64 位有关。
早期 Intel 8086、8088 的 CPU 就是只支持 16 位地址空间,寄存器和地址总线都是 16 位,这意味着最多对 2^16 = 64 Kb 的内存编号寻址。
这点内存空间显然不够用,后来,80286 在 8086 的基础上将地址总线和地址寄存器扩展到了20 位,也被叫做 A20 地址总线。
当时在写 mini os 的时候,还需要通过 BIOS 中断去启动 A20 地址总线的开关。
但是,现在的计算机一般都是 32 位起步了,32 位意味着可寻址的内存范围是 2^32 byte = 4GB。
所以,如果你的电脑是 32 位的,那么你装超过 4G 的内存条也是无法充分利用起来的。
好了,这就是内存和内存地址空间。
变量的本质
有了内存,接下来我们需要考虑,int、double 这些变量是如何存储在 0、1 单元格的。 在 C 语言中我们会这样定义变量:
int a = 999;
char c = 'c';
当你写下一个变量定义的时候,实际上是向内存申请了一块空间来存放你的变量。 我们都知道 int 类型占 4 个字节,并且在计算机中数字都是用补码(不了解补码的记得去百度)表示的。
999 换算成补码就是:0000 0011 1110 0111
这里有 4 个byte,所以需要四个单元格来存储:
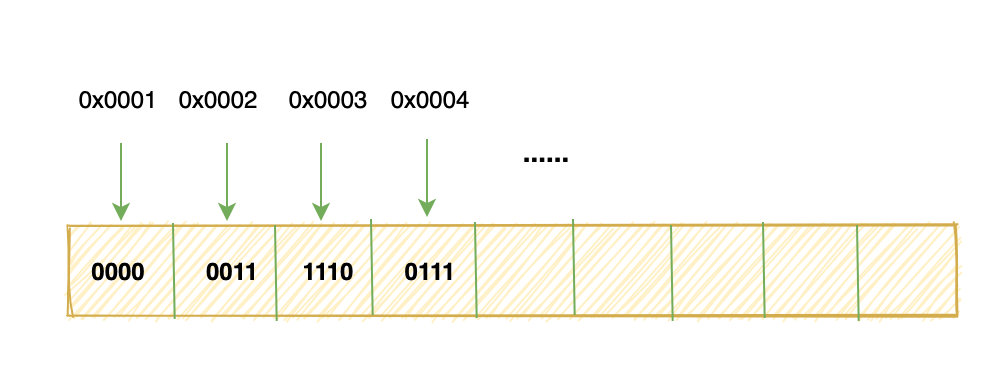
有没有注意到,我们把高位的字节放在了低地址的地方。 那能不能反过来呢? 当然,这就引出了大端和小端。 像上面这种将高位字节放在内存低地址的方式叫做大端 反之,将低位字节放在内存低地址的方式就叫做小端。
深入理解C/C++指针
指针是什么东西?
变量放在哪?
上面我说,定义一个变量实际就是向计算机申请了一块内存来存放。那如果我们要想知道变量到底放在哪了呢?可以通过运算符&来取得变量实际的地址,这个值就是变量所占内存块的起始地址。大概会是像这样的一串数字:0x7ffcad3b8f3c
指针本质
上面说,我们可以通过&符号获取变量的内存地址,那获取之后如何来表示这是一个地址,而不是一个普通的值呢? 也就是在 C 语言中如何表示地址这个概念呢? 对,就是指针,你可以这样:
int *pa = &a;
pa 中存储的就是变量 a 的地址,也叫做指向 a 的指针。
为什么我们需要指针?直接用变量名不行吗?:变量是变量地址的符号化,变量是为了让我们编程时更加方便,对人友好,可计算机可不认识什么变量 a,它只知道地址和指令。编译器会自动维护一个映射,将我们程序中的变量名转换为变量所对应的地址,然后再对这个地址去进行读写。
解引用
pa中存储的是a变量的内存地址,那如何通过地址去获取a的值呢?这个操作就叫做解引用,在 C 语言中通过运算符 就可以拿到一个指针所指地址的内容了。比如pa就能获得a的值。我们说指针存储的是变量内存的首地址,那编译器怎么知道该从首地址开始取多少个字节呢?这就是指针类型发挥作用的时候,编译器会根据指针的所指元素的类型去判断应该取多少个字节。如果是 int 型的指针,那么编译器就会产生提取四个字节的指令,char 则只提取一个字节,以此类推。
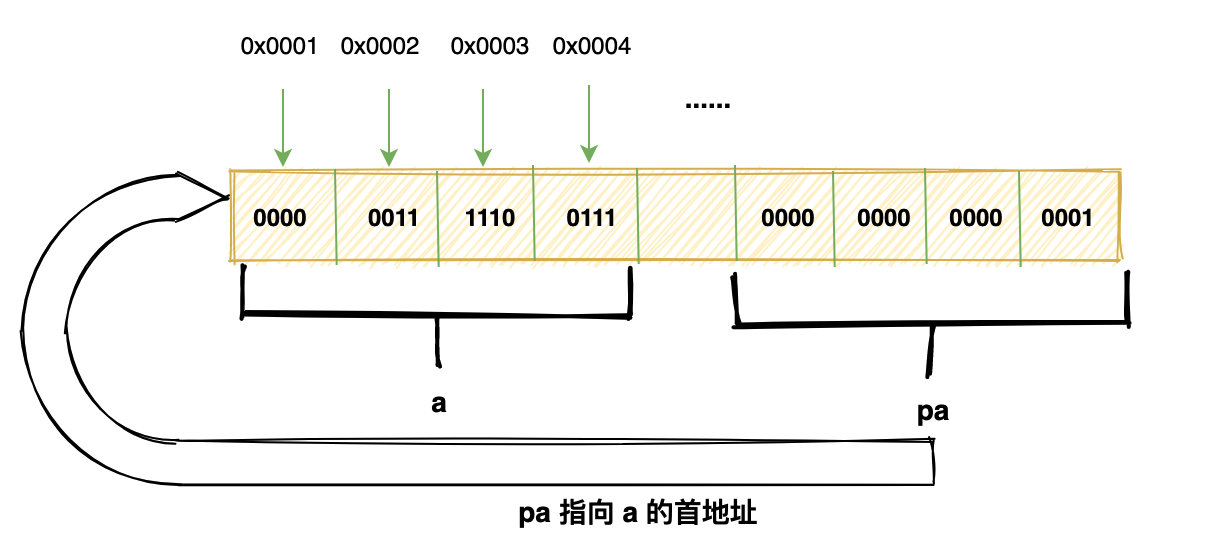
pa 指针首先是一个变量,它本身也占据一块内存,这块内存里存放的就是 a 变量的首地址。
当解引用的时候,就会从这个首地址连续划出 4 个 byte,然后按照 int 类型的编码方式解释。
活学活用
float f = 1.0;
short c = *(short*)&f;
实际上,从内存层面来说,f 什么都没变。
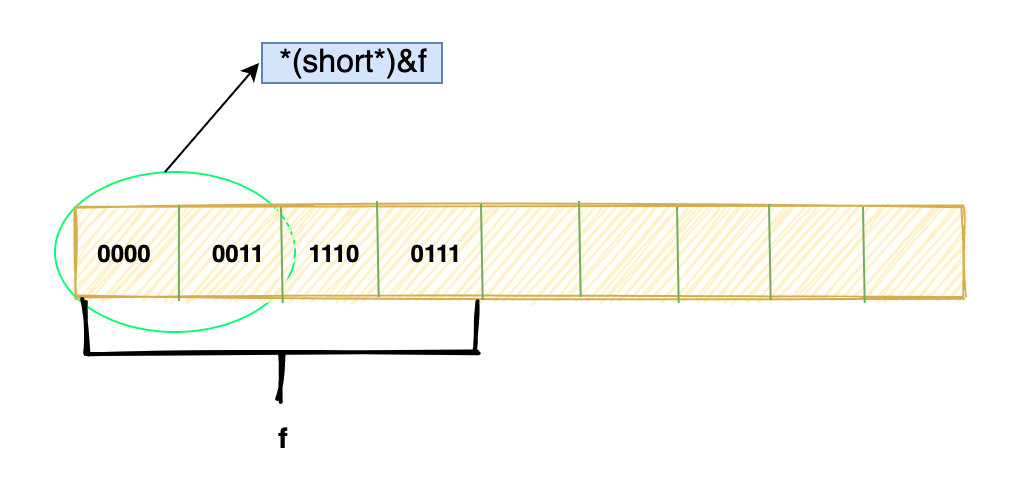
假设这是f 在内存中的位模式,这个过程实际上就是把 f 的前两个byte 取出来然后按照 short 的方式解释,然后赋值给 c。 详细过程如下:
&f取得f的首地址(short*)&f
最后当去解引用的时候(short)&f时,编译器会取出前面两个字节,并且按照 short 的编码方式去解释,并将解释出的值赋给 c 变量。
这个过程 f的位模式没有发生任何改变,变的只是解释这些位的方式。当然,这里最后的值肯定不是 1,至于是什么,大家可以去真正算一下。 那反过来,这样呢?
short c = 1;
float f = *(float*)&c;
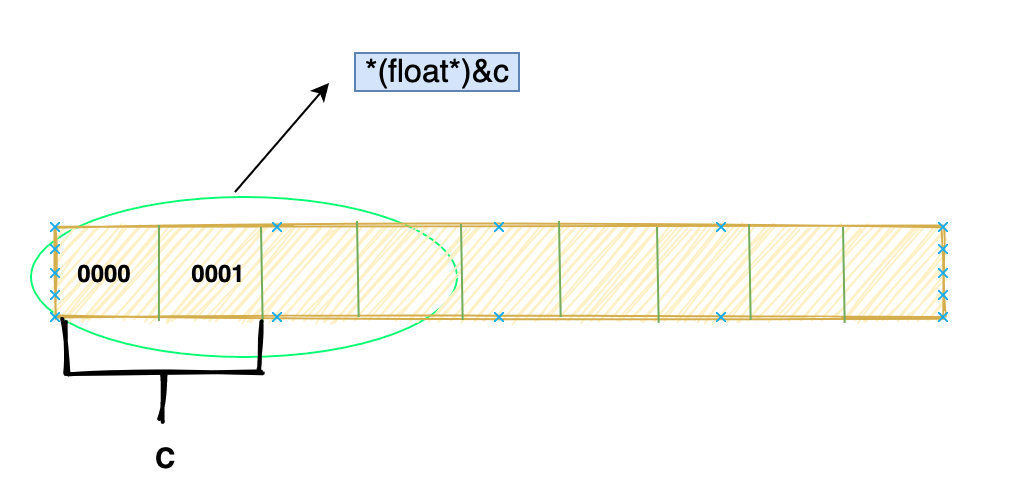
具体过程和上述一样,但上面肯定不会报错,这里却不一定。
为什么?
(float*)&c会让我们从c 的首地址开始取四个字节,然后按照 float 的编码方式去解释。 但是c是 short 类型只占两个字节,那肯定会访问到相邻后面两个字节,这时候就发生了内存访问越界。当然,如果只是读,大概率是没问题的。
但是,有时候需要向这个区域写入新的值,比如:
*(float*)&c = 1.0;
那么就可能发生 coredump,也就是访存失败。另外,就算是不会 coredump,这种也会破坏这块内存原有的值,因为很可能这是是其它变量的内存空间,而我们去覆盖了人家的内容,肯定会导致隐藏的 bug。如果你理解了上面这些内容,那么使用指针一定会更加的自如。
结构体和指针
结构体内包含多个成员,这些成员之间在内存中是如何存放的呢?比如:
struct fraction {
int num; // 整数部分
int denom; // 小数部分
};
struct fraction fp;
fp.num = 10;
fp.denom = 2;
这是一个定点小数结构体,它在内存占 8 个字节(这里不考虑内存对齐),两个成员域是这样存储的:
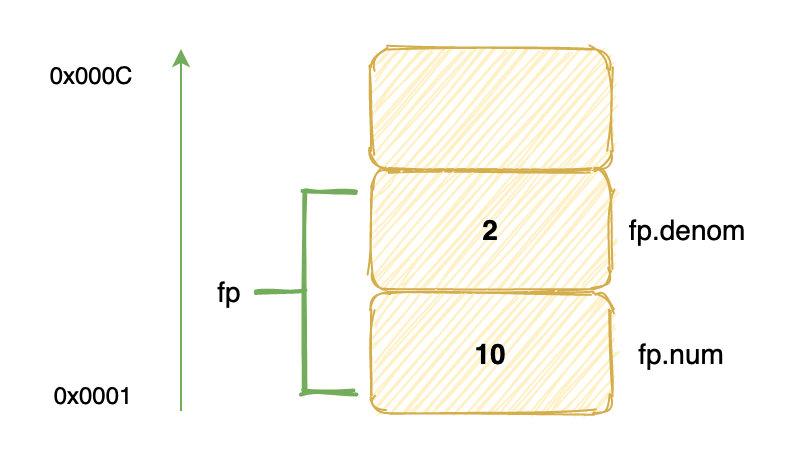
我们把 10 放在了结构体中基地址偏移为 0 的域,2 放在了偏移为 4 的域。
接下来我们做一个正常人永远不会做的操作:
((fraction*)(&fp.denom))->num = 5;
((fraction*)(&fp.denom))->denom = 12;
printf("%d\n", fp.denom); // 输出多少?
上面这个究竟会输出多少呢?自己先思考下噢~
接下来我分析下这个过程发生了什么:
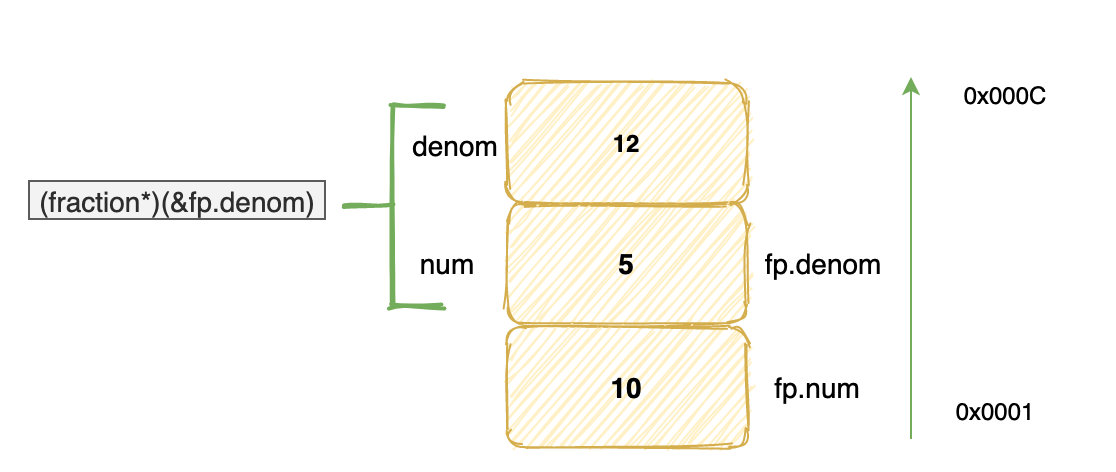
首先,&fp.denom表示取结构体 fp 中 denom 域的首地址,然后以这个地址为起始地址取 8 个字节,并且将它们看做一个 fraction 结构体。
在这个新结构体中,最上面四个字节变成了 denom 域,而 fp 的 denom 域相当于新结构体的 num 域。
多级指针
int a;
int *pa = &a;
int **ppa = &pa;
int ***pppa = &ppa;
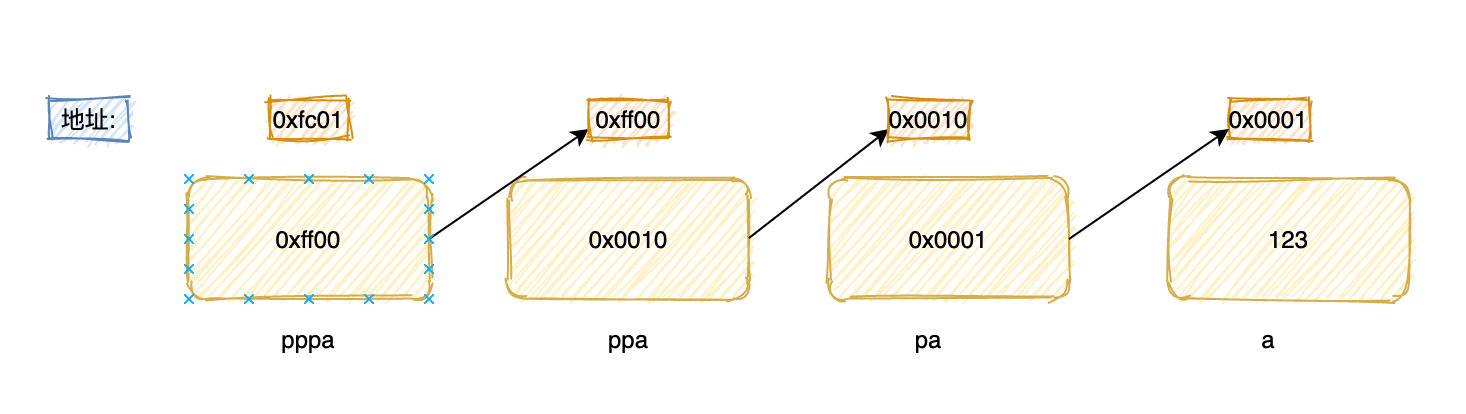
不管几级指针有两个最核心的东西:
- 指针本身也是一个变量,需要内存去存储,指针也有自己的地址
- 指针内存存储的是它所指向变量的地址
指针与数组
数组是 C 自带的基本数据结构,彻底理解数组及其用法是开发高效应用程序的基础。数组和指针表示法紧密关联,在合适的上下文中可以互换。
如下:
int array[10] = {10, 9, 8, 7};
printf("%d\n", *array); // 输出 10
printf("%d\n", array[0]); // 输出 10
printf("%d\n", array[1]); // 输出 9
printf("%d\n", *(array+1)); // 输出 9
int *pa = array;
printf("%d\n", *pa); // 输出 10
printf("%d\n", pa[0]); // 输出 10
printf("%d\n", pa[1]); // 输出 9
printf("%d\n", *(pa+1)); // 输出 9
在内存中,数组是一块连续的内存空间:
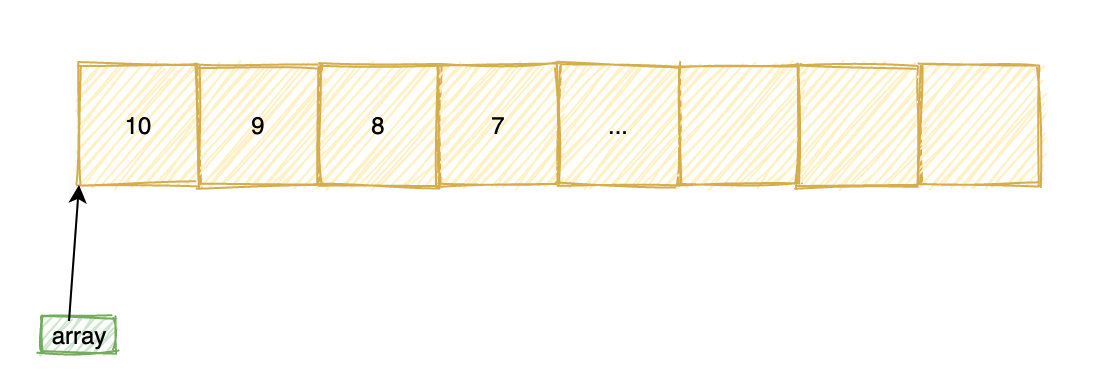
第 0 个元素的地址称为数组的首地址,数组名实际就是指向数组首地址,当我们通过array[1]或者*(array + 1) 去访问数组元素的时候。
实际上可以看做 address[offset],address 为起始地址,offset 为偏移量,但是注意这里的偏移量offset 不是直接和 address相加,而是要乘以数组类型所占字节数,也就是: address + sizeof(int) * offset。
学过汇编的同学,一定对这种方式不陌生,这是汇编中寻址方式的一种:基址变址寻址。
看完上面的代码,很多同学可能会认为指针和数组完全一致,可以互换,这是完全错误的。
尽管数组名字有时候可以当做指针来用,但数组的名字不是指针
sizeof差别
最典型的地方就是在 sizeof:
printf("%u", sizeof(array));
printf("%u", sizeof(pa));
第一个将会输出 40,因为 array包含有 10 个int类型的元素,而第二个在 32 位机器上将会输出 4,也就是指针的长度。
站在编译器的角度讲,变量名、数组名都是一种符号,它们都是有类型的,它们最终都要和数据绑定起来。变量名用来指代一份数据,数组名用来指代一组数据(数据集合),它们都是有类型的,以便推断出所指代的数据的长度。
对,数组也有类型,我们可以将 int、float、char 等理解为基本类型,将数组理解为由基本类型派生得到的稍微复杂一些的类型,数组的类型由元素的类型和数组的长度共同构成。而 sizeof 就是根据变量的类型来计算长度的,并且计算的过程是在编译期,而不会在程序运行时。
编译器在编译过程中会创建一张专门的表格用来保存变量名及其对应的数据类型、地址、作用域等信息。sizeof 是一个操作符,不是函数,使用 sizeof 时可以从这张表格中查询到符号的长度。
所以,这里对数组名使用sizeof可以查询到数组实际的长度。pa 仅仅是一个指向 int 类型的指针,编译器根本不知道它指向的是一个整数,还是一堆整数。虽然在这里它指向的是一个数组,但数组也只是一块连续的内存,没有开始和结束标志,也没有额外的信息来记录数组到底多长。
所以对 pa 使用 sizeof 只能求得的是指针变量本身的长度。也就是说,编译器并没有把 pa 和数组关联起来,pa 仅仅是一个指针变量,不管它指向哪里,sizeof求得的永远是它本身所占用的字节数。
二维数组
大家不要认为二维数组在内存中就是按行、列这样二维存储的,实际上,不管二维、三维数组... 都是编译器的语法糖。
存储上和一维数组没有本质区别,举个例子:
int array[3][3] = {{1, 2,3}, {4, 5,6},{7, 8, 9}};
array[1][1] = 5;
1 2 3 4 5 6 7 8 9
和一维数组没有什么区别,都是一维线性排列。 当我们像 array[1][1]这样去访问的时候,编译器会怎么去计算我们真正所访问元素的地址呢? 为了更加通用化,假设数组定义是这样的: int array[n][m]
访问 array[a][b],计算方式就是array + (a * m + b), 这个就是二维数组在内存中的本质,其实和一维数组是一样的,只是语法糖包装成一个二维的样子。
void指针
应用场景
void 指针最大的用处就是在 C 语言中实现泛型编程,因为任何指针都可以被赋给 void 指针,void 指针也可以被转换回原来的指针类型, 并且这个过程指针实际所指向的地址并不会发生变化。 比如:
int num;
int *pi = #
printf("address of pi: %p\n", pi);
void* pv = pi;
pi = (int*) pv;
printf("address of pi: %p\n", pi);
这两次输出的值都会是一样:

平常可能很少会这样去转换,但是当你用 C 写大型软件或者写一些通用库的时候,一定离不开 void 指针,这是 C 泛型的基石,比如 std 库里的 sort 函数申明是这样的:
void qsort(void *base,int nelem,int width,int (*fcmp)(const void *,const void *));
所有关于具体元素类型的地方全部用 void 代替。
不能对 void 指针解引用
int num;
void *pv = (void*)#
*pv = 4; // 错误
因为解引用的本质就是编译器根据指针所指的类型,然后从指针所指向的内存连续取 N 个字节,然后将这 N 个字节按照指针的类型去解释。
比如 int *型指针,那么这里 N 就是 4,然后按照 int 的编码方式去解释数字。
但是 void,编译器是不知道它到底指向的是 int、double、或者是一个结构体,所以编译器没法对 void 型指针解引用。
快速搞懂指针声明
int p; // 普通变量
int *p; // 普通指针
int p[3]; // 数组
int* p[3]; //指针数组
int (*p)[3]; //数组指针
int **p; // 二级指针
int p(int); //普通函数
int (*p)(int); // 函数指针
int* (*p(int))[3];
/* p 开始,先与()结合,说明 p 是一个函数。然后进入()里面,与int结合,说明函数有一个整型变量参数。然后再与外面的 * 结合,说明函数返回的是一个指针。之后到最外面一层,先与[]结合,说明返回的指针指向的是一个数组。接着再与结合,说明数组里的元素是指针,最后再与int结合,说明指针指向的内容是整型数据。所以 p 是一个参数为一个整数据且返回一个指向由整型指针变量组成的数组的指针变量的函数。*/
简单总结下如何解释复杂一点的 C 语言声明(暂时不考虑 const 和 volatile):
指针声明阅读顺序
- 先抓住 标识符(即变量名或者函数名)
- 从距离标识符最近的地方开始,按照优先顺序解释派生类型(也就是指针、数组、函数),顺序如下:
- 用于改变优先级的括弧
- 用于表示数组的[],用于表示函数的()
- 用于表示指针的
-
解释完成派生类型,使用“of”、“to”、“returning”将它们连接起来。
-
最后,追加数据类型修饰符(一般在最左边,int、double等)。
数组元素个数和函数的参数属于类型的一部分。应该将它们作为附属于类型的属性进行解释。
c/c++内存分区
一般来说,程序运行时,代码、数据等都存放在不同的内存区域,这些内存区域从逻辑上做了划分,大概以下几个区域:代码区、全局/静态存储区、栈区、堆区和常量区。在 CSAPP 第九章虚拟内存,就将内存分为堆、bss、data、txt、栈等区域。
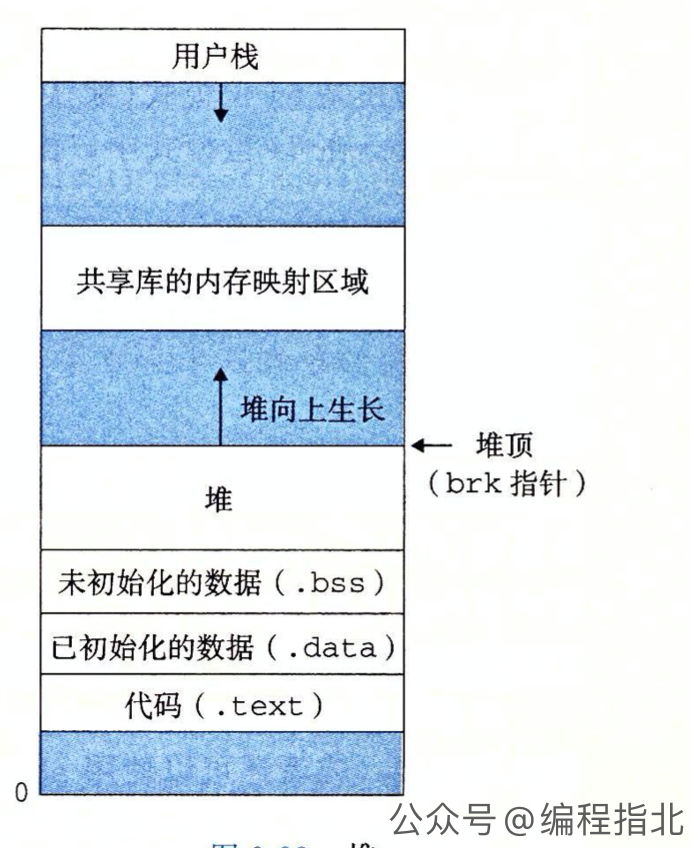
代码(.text)区
就是 .text 段, 代码区存放程序的二进制代码,它是只读的,以防止程序在运行过程中被意外修改。
#include <iostream>
int main() {
std::cout << "Hello, World!" << std::endl;
return 0;
}
比如上面这段代码中的 main 函数,编译为二进制后,函数的逻辑就存放在代码区。
当然这段区域也有可能包含一些只读的常数变量,例如字符串常量等。
全局/静态存储区(.bss, .data)
全局变量和静态变量都存放在全局/静态存储区。以前在 C 语言中全局变量又分为初始化的和未初始化的,分别放在上面图中的 .bss 和 .data 段,但在 C++里面没有这个区分了,他们共同占用同一块内存区,就叫做全局存储区。
这个区域的内存在程序的生命周期几乎都是全局的,举例:
#include <iostream>
int globalVar = 0; // 全局变量
void function() {
static int staticVar = 0; // 静态变量
staticVar++;
std::cout << staticVar << std::endl;
}
int main() {
function();
function();
return 0;
}
globalVar是一个全局变量,staticVar是一个静态变量,它们都存放在全局/静态存储区。
栈区(stack)
栈区用于存储函数调用时的局部变量、函数参数以及返回地址。当函数调用完成后,分配给这个函数的栈空间会被释放。例如:
#include <iostream>
void function(int a, int b) {
int localVar = a + b;
std::cout << localVar << std::endl;
}
int main() {
function(3, 4);
return 0;
}
在这个例子中,a、b和localVar都是局部变量,它们存放在栈区。
当 function 函数调用结束后,对应的函数栈所占用的空间(参数 a、b,局部变量 localVar等)都会被回收。
堆区(Heap)
堆区是用于动态内存分配的区域,当使用new(C++)或者malloc(C)分配内存时,分配的内存块就位于堆区。
我们需要手动释放这些内存,否则可能导致内存泄漏。例如:
#include <iostream>
int main() {
int* dynamicArray = new int[10]; // 动态分配内存
// 使用动态数组...
delete[] dynamicArray; // 释放内存
return 0;
}
常量区(.rodata)
常量区用于存储常量数据,例如字符串字面量和其他编译时常量。这个区域通常也是只读的。例如:
#include <iostream>
int main() {
char* c="abc"; // abc在常量区,c在栈上。
return 0;
}
c++指针和引用的区别
指针和引用在 C++ 中都用于间接访问变量,但它们有一些区别:
- 指针是一个变量,它保存了另一个变量的内存地址;引用是另一个变量的别名,与原变量共享内存地址。
- 指针(除指针常量)可以被重新赋值,指向不同的变量;引用在初始化后不能更改,始终指向同一个变量。
- 指针可以为 nullptr,表示不指向任何变量;引用必须绑定到一个变量,不能为 nullptr。
- 使用指针需要对其进行解引用以获取或修改其指向的变量的值;引用可以直接使用,无需解引用。
#include <iostream>
int main() {
int a = 10;
int b = 20;
// 指针
int *p = &a;
std::cout << "Pointer value: " << *p << std::endl; // 输出:Pointer value: 10
p = &b;
std::cout << "Pointer value: " << *p << std::endl; // 输出:Pointer value: 20
// 引用
int &r = a;
std::cout << "Reference value: " << r << std::endl; // 输出:Reference value: 10
// r = &b; // 错误:引用不能被重新绑定
int &r2 = b;
r = r2; // 将 b 的值赋给 a,r 仍然引用 a
std::cout << "Reference value: " << r << std::endl; // 输出:Reference value: 20
return 0;
}
从汇编看引用和指针
引用会被c++编译器当做const指针来进行操作。
先分别用指针和引用来写个非常熟悉的函数swap
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
// 引用版
void swap(int &a, int &b) {
int temp = a;
a = b;
b = temp;
}
直接gcc -S 输出汇编
# 引用版汇编
__Z4swapRiS_: ## @_Z4swapRiS_
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movq %rdi, -8(%rbp) # 传入的第一个参数存放到%rbp-8 (应该是采用的寄存器传参,而不是常见的压栈)
movq %rsi, -16(%rbp) # 第二个参数 存放到 %rbp-16
movq -8(%rbp), %rsi # 第一个参数赋给 rsi
movl (%rsi), %eax # 以第一个参数为地址取出值赋给eax,取出*a暂存寄存器
movl %eax, -20(%rbp) # temp = a
movq -16(%rbp), %rsi # 将第二个参数重复上面的
movl (%rsi), %eax
movq -8(%rbp), %rsi
movl %eax, (%rsi) # a = b
movl -20(%rbp), %eax # eax = temp
movq -16(%rbp), %rsi
movl %eax, (%rsi) # b = temp
popq %rbp
retq
.cfi_endproc
## -- End function
在来一个函数调用引用版本swap
void call() {
int a = 10;
int b = 3;
int &ra = a;
int &rb = b;
swap(ra, rb);
}
__Z4callv: ## @_Z4callv
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
subq $32, %rsp
leaq -8(%rbp), %rax # rax中是b的地址
leaq -4(%rbp), %rcx # rcx中是a的地址
movl $10, -4(%rbp)
movl $3, -8(%rbp) # 分别初始化a、b
movq %rcx, -16(%rbp) # 赋给ra引用
movq %rax, -24(%rbp) # 赋给rc引用
movq -16(%rbp), %rdi # 寄存器传参, -16(%rbp)就是rcx中的值也就是a的地址
movq -24(%rbp), %rsi # 略
callq __Z4swapRiS_
addq $32, %rsp
popq %rbp
retq
清楚了! 我们可以看到给引用赋初值也就是把所绑定对象的地址赋给引用所在内存,和指针是一样的。
__Z4swapPiS_: ## @_Z4swapPiS_
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movq %rdi, -8(%rbp)
movq %rsi, -16(%rbp)
movq -8(%rbp), %rsi
movl (%rsi), %eax
movl %eax, -20(%rbp)
movq -16(%rbp), %rsi
movl (%rsi), %eax
movq -8(%rbp), %rsi
movl %eax, (%rsi)
movl -20(%rbp), %eax
movq -16(%rbp), %rsi
movl %eax, (%rsi)
popq %rbp
retq
.cfi_endproc
## -- End function
简单总结
-
引用只是C++语法糖,可以看作编译器自动完成取地址、解引用的指针常量
-
引用区别于指针的特性都是编译器约束完成的,一旦编译成汇编就和指针一样
-
由于引用只是指针包装了下,所以也存在风险,比如如下代码:
int *a = new int; int &b = *a; delete a; b = 12; // 对已经释放的内存解引用 -
引用由编译器保证初始化,使用起来较为方便(如不用检查空指针等)
-
尽量用引用代替指针
-
引用没有顶层const即int & const,因为引用本身就不可变,所以在加顶层const也没有意义; 但是可以有底层const即 const int&,这表示引用所引用的对象本身是常量
-
指针既有顶层const(int * const--指针本身不可变),也有底层const(int * const--指针所指向的对象不可变)
-
有指针引用--是引用,绑定到指针, 但是没有引用指针--这很显然,因为很多时候指针存在的意义就是间接改变对象的值,但是引用本身的值我们上面说过了是所引用对象的地址,但是引用不能更改所引用的对象,也就当然不能有引用指针了。
-
指针和引用的自增(++)和自减含义不同,指针是指针运算, 而引用是代表所指向的对象对象执行++或--
指针传递、值传递、引用传递
值传递(value passing)
值传递是将实参的值传递给形参。在这种情况下,函数内对形参的修改不会影响到实参。
#include <iostream>
void swap_value(int a, int b) {
int temp = a;
a = b;
b = temp;
}
int main() {
int x = 10;
int y = 20;
swap_value(x, y);
std::cout << "x: " << x << ", y: " << y << std::endl; // 输出:x: 10, y: 20
return 0;
}
引用传递
引用传递是将实参的引用传递给形参。在这种情况下,函数内对形参的修改会影响到实参。
#include <iostream>
void swap_reference(int &a, int &b) {
int temp = a;
a = b;
b = temp;
}
int main() {
int x = 10;
int y = 20;
swap_reference(x, y);
std::cout << "x: " << x << ", y: " << y << std::endl; // 输出:x: 20, y: 10
return 0;
}
指针传递
指针传递是将实参的地址传递给形参。在这种情况下,函数内对形参的修改会影响到实参。
#include <iostream>
void swap_pointer(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
int main() {
int x = 10;
int y = 20;
swap_pointer(&x, &y);
std::cout << "x: " << x << ", y: " << y << std::endl; // 输出:x: 20, y: 10
return 0;
}
其实,关于值传递、指针传递等有很多争论,比如指针传递这个,本质上也是值传递,只不过传递的值是一个指针而已,所以就看你从什么角度去看待这个问题。
值传递与引用传递,传的是什么?
在网上看到过很多讨论 Java、C++、Python 是值传递还是引用传递这类文章。
参数传递无外乎就是传值(pass by value),传引用(pass by reference)或者说是传指针。
传值还是传引用可能在 Java、Python 这种语言中常常会困扰一些初学者,但是如果你有 C/C++背景的话,那这个理解起来就是 so easy。
今天我就从 C 语言出发,一次性把 Java、Python 这些都给大家讲明白
堆、栈
要注意,这“堆”和“栈”并不是数据结构意义上的堆(Heap,一个可看成完全二叉树的数组对象)和 栈(Stack,先进后出的线性结构)。这里说的堆栈是指内存的两种组织形式,堆是指动态分配内存的一块区域,一般由程序员手动分配,比如 Java 中的 new、C/C++ 中的 malloc 等,都是将创建的对象或者内存块放置在堆区。
而栈是则是由编译器自动分配释放(大概就是你申明一个变量就分配一块相应大小的内存),用于存放函数的参数值,局部变量等。
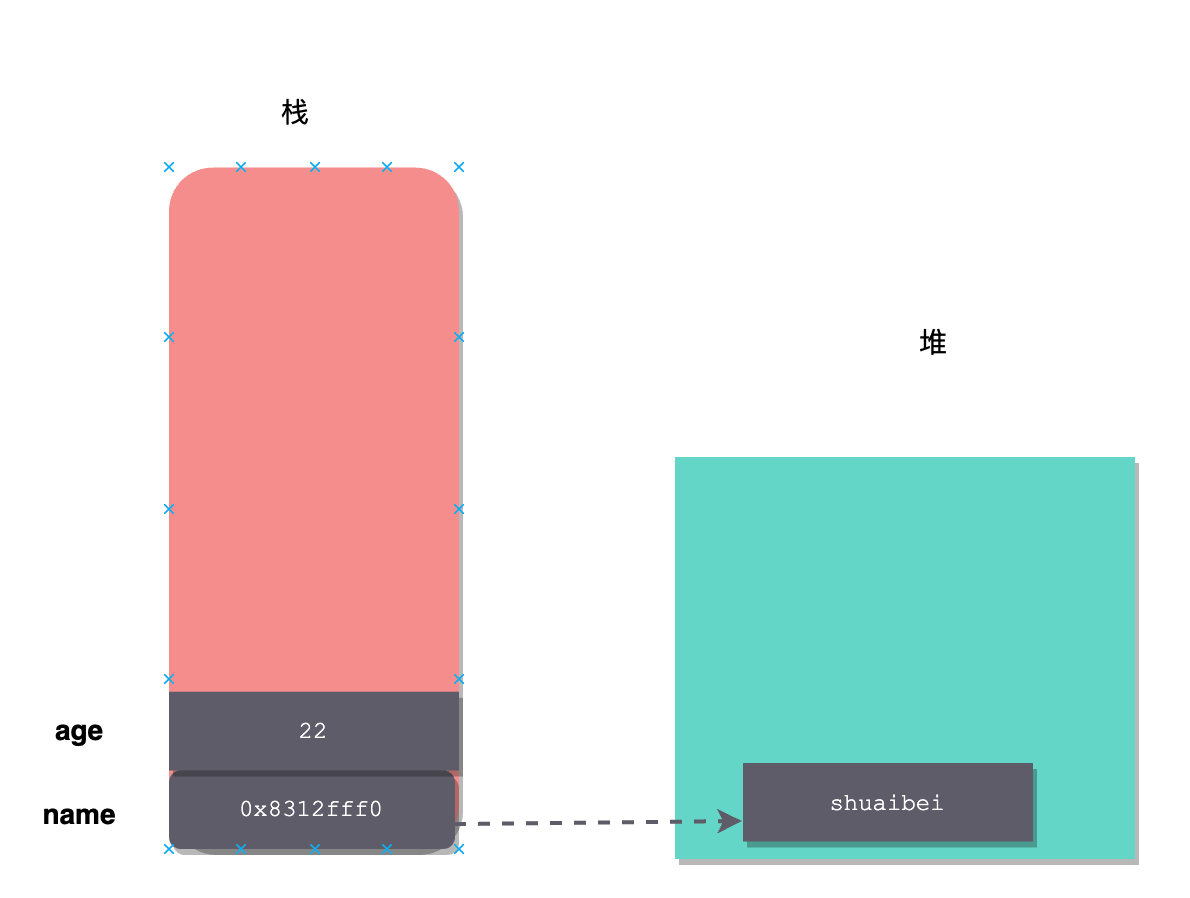
就拿 Java 来说吧,基本类型(int、double、long这种)是直接将存储在栈上的,而引用类型(类)则是值存储在堆上,栈上只存储一个对对象的引用。
举个栗子:
int age = 22;
String name = new String("shuaibei");
这两个变量存储图如下:
如果,我们分别对age、name变量赋值,会发生什么呢?
age = 18;
name = new String("xiaobei");
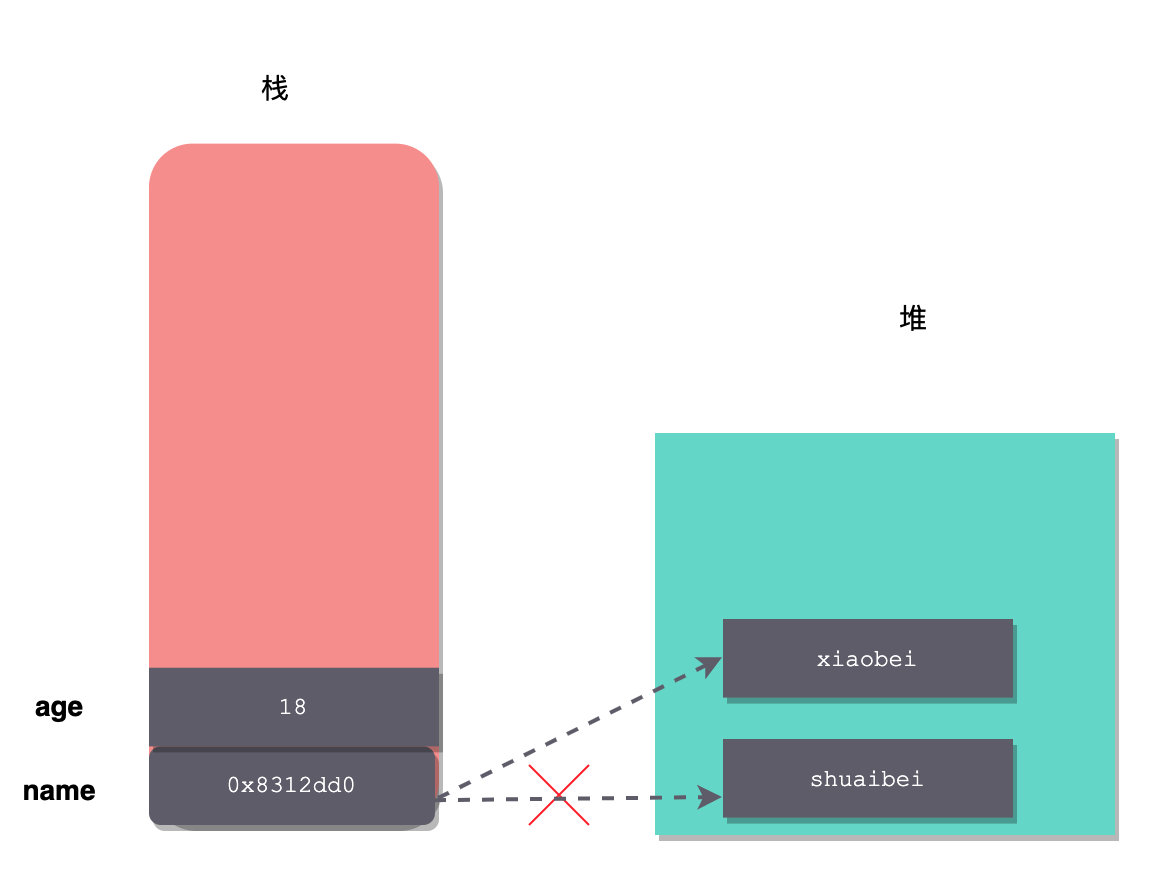
age 仅仅是将栈上的值修改为 18,而 name 由于是 String 引用类型,所以会重新创建一个 String 对象,并且修改 name,让其指向新的堆对象。(细心的话,你会发现,图中 name 执行的地址我做了修改)
然后,之前那个对象如果没有其它变量引用的话,就会被垃圾回收器回收掉。这里也要注意一点,我创建 String 的时候,使用的是 new,如果直接采用字符串赋值,比如:
String name = "shuaibei"
那么是会放到 JVM 的常量池去,不会被回收掉,这是字符串两种创建对象的区别,不过这里我们不关注。Java 中引用这东西,和 C/C++ 的指针就是一模一样的嘛,只不过 Java 做了语义层包装和一些限制,让你觉得这是一个引用,实际上就是指针。
函数调用栈
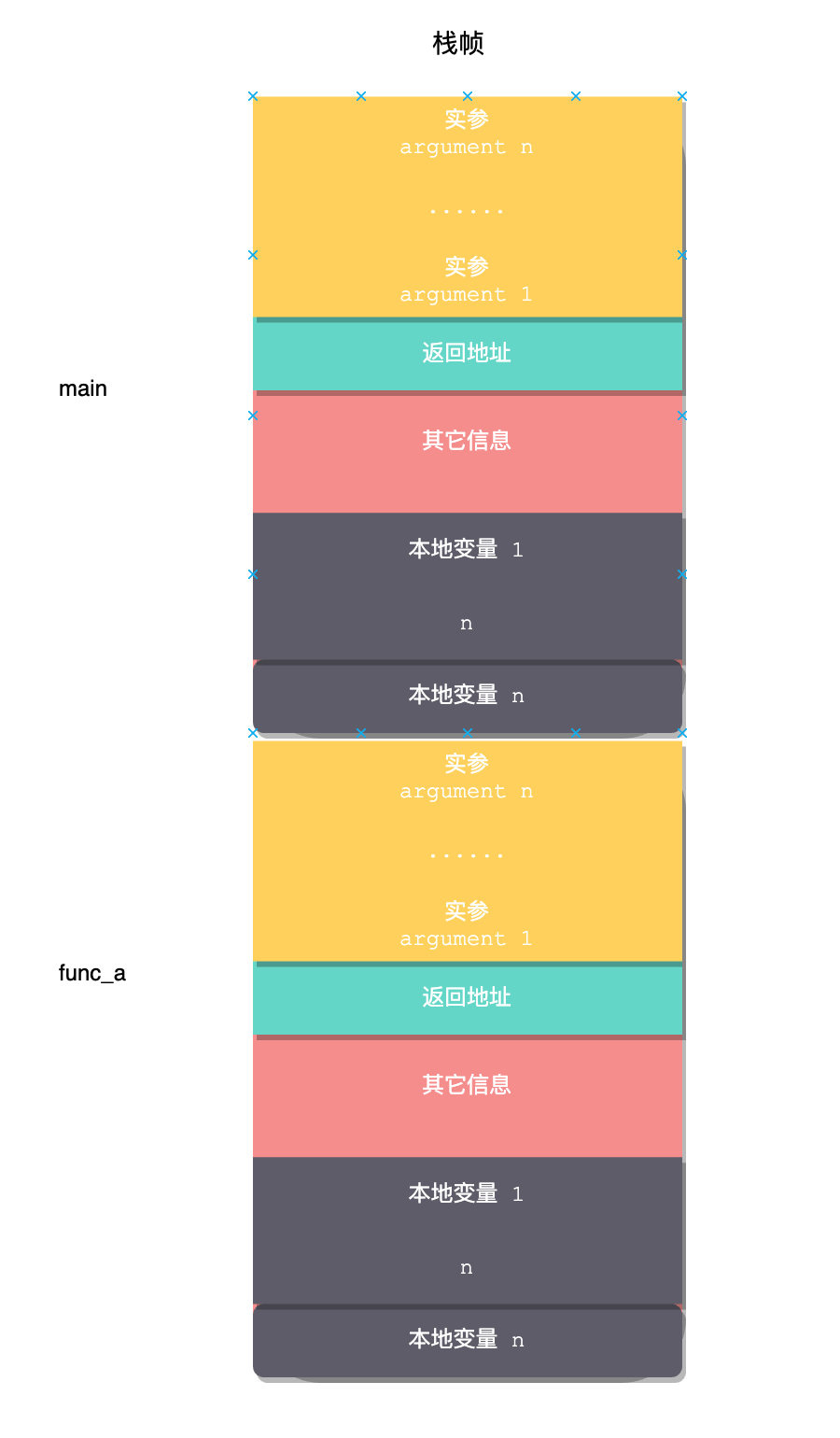
一个函数需要在内存上存储哪些信息呢?参数、局部变量,理论上这两个就够了,但是当多个函数相互调用的时候,就还需要机制来保证它们顺利的返回和恢复主调函数的栈结构信息。
那这部分就包括返回地址、ebp寄存器(基址指针寄存器,指向当前堆栈底部) 以及其它需要保存的寄存器。所以一个完整的函数调用栈大概长得像下面这个样子:

那,多个函数调用的时候呢?
简单来说就是叠罗汉,这是两个函数栈:
面这段代码在main函数内调用了func_a函数
int func_a(int a, int *b) {
a = 5;
*b = 5;
};
int main(void) {
int a = 10;
int b = 10;
func_a(a, &b);
printf("a=%d, b=%d\n", a, b);
return 0;
}
// 输出
a=10, b=5
那么func_a(a, &b) 这个过程,在函数调用栈上究竟是怎么样的呢?
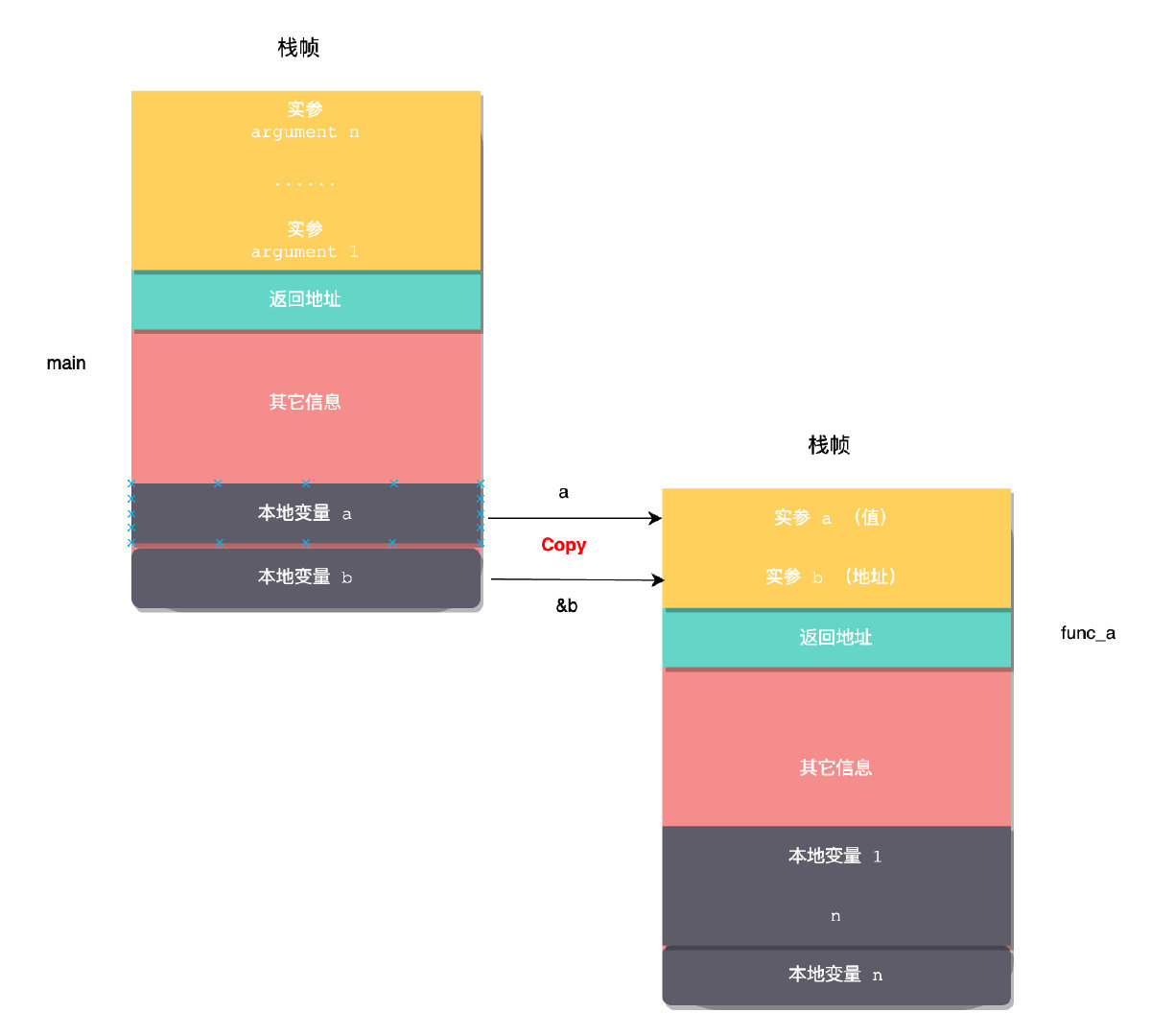
就像上图所示,编译器会生成一段函数调用代码。将 main 函数内变量 a 的值拷贝到 func_a 函数参数 a 位置。将变量 b的地址,拷贝到 func_a 函数参数 b 的位置。记住这张图,这是函数参数传递的本质,没有其它方式,just copy!copy 意味着是副本,也就是在子函数的参数永远是主调函数内的副本。决定是值传递还是所谓的引用传递,在于你 copy 的到底是一个值,还是一个引用(的值。
c++ RAII思想
什么是RAII
资源获取即初始化(Resource Acquisition Is Initialization,简称 RAII)是一种 C++ 编程技术,它将在使用前获取(分配的堆内存、执行线程、打开的套接字、打开的文件、锁定的互斥量、磁盘空间、数据库连接等有限资源)的资源的生命周期与某个对象的生命周期绑定在一起。
确保在控制对象的生命周期结束时,按照资源获取的相反顺序释放所有资源。同样,如果资源获取失败(构造函数退出并带有异常),则按照初始化的相反顺序释放所有已完全构造的成员和基类子对象所获取的资源。
这利用了核心语言特性(对象生命周期、作用域退出、初始化顺序和堆栈展开),以消除资源泄漏并确保异常安全。
RAII 的原理
RAII的核心思想就是:利用栈上局部变量的自动析构来保证资源一定会被释放。
因为我们平常 C++ 编程过程中,经常会忘了释放资源,比如申请的堆内存忘了手动释放,那么就会导致内存泄露。
还有一些常见是程序遇到了异常,提前终止了,我们的资源也来不及释放。
但是变量的析构函数的调用是由编译器保证的一定会被执行,所以如果资源的获取和释放与对象的构造和析构绑定在一起,就不会有各种资源泄露问题。
RAII 类实现步骤
一般设计实现一个 RAII 类需要四个步骤:
- 设计一个类封装资源,资源可以是内存、文件、socket、锁等等一切
- 在构造函数中执行资源的初始化,比如申请内存、打开文件、申请锁
- 在析构函数中执行销毁操作,比如释放内存、关闭文件、释放锁
- 使用时声明一个该对象的类,一般在你希望的作用域声明即可,比如在函数开始,或者作为类的成员变量
实例
下面写一个 RAII 示例,用来演示使用 RAII 思想包装文件的操作,假设我们需要在程序中使用一个文件:
#include <iostream>
#include <fstream>
int main() {
std::ifstream myfile("example.txt"); // 换自己的文件路径
if (myfile.is_open()) {
std::cout << "File is opened." << std::endl;
// do some work with the file
}
else {
std::cout << "Failed to open the file." << std::endl;
}
myfile.close();
return 0;
}
上面这个例子中,手动打开和关闭了文件。
如果在程序执行的过程中发生了异常或者程序提前退出,可能会导致文件没有被关闭,从而产生资源未释放等问题。
现在使用 RAII 来改进这个例子,通过定义一个包含文件句柄的类,在类的构造函数中打开文件,在析构函数中关闭文件:
#include <iostream>
#include <fstream>
class File {
public:
File(const char* filename) : m_handle(std::ifstream(filename)) {}
~File() {
if (m_handle.is_open()) {
std::cout << "File is closed." << std::endl;
m_handle.close();
}
}
std::ifstream& getHandle() {
return m_handle;
}
private:
std::ifstream m_handle;
};
int main() {
File myfile("example.txt");
if (myfile.getHandle().is_open()) {
std::cout << "File is opened." << std::endl;
// do some work with the file
}
else {
std::cout << "Failed to open the file." << std::endl;
}
return 0;
}
这样,在程序退出时,File类的析构函数会自动被调用,从而自动关闭文件,即使程序提前退出或者发生异常,也不会产生内存泄漏等问题.
用 RAII 思想包装 mutex
在 C++ 中,可以使用 RAII 思想来包装 mutex,确保在多线程编程中始终能安全锁定和解锁互斥量,这个用得非常多,可以在很多开源项目中看到这样的包装。
#include <iostream>
#include <mutex>
#include <thread>
class LockGuard {
public:
explicit LockGuard(std::mutex &mtx) : mutex_(mtx) {
mutex_.lock();
}
~LockGuard() {
mutex_.unlock();
}
// 禁止复制
LockGuard(const LockGuard &) = delete;
LockGuard &operator=(const LockGuard &) = delete;
private:
std::mutex &mutex_;
};
// 互斥量
std::mutex mtx;
// 多线程操作的变量
int shared_data = 0;
void increment() {
for (int i = 0; i < 10000; ++i) {
// 申请锁
LockGuard lock(mtx);
++shared_data;
// 作用域结束后会析构 然后释放锁
}
}
int main() {
std::thread t1(increment);
std::thread t2(increment);
t1.join();
t2.join();
std::cout << "Shared data: " << shared_data << std::endl;
return 0;
}
上面定义了一个 LockGuard 类,该类在构造函数中接收一个互斥量(mutex)引用并对其进行锁定,在析构函数中对互斥量进行解锁。
这样,我们可以将互斥量传递给 LockGuard 对象,并在需要保护的代码块内创建该对象,确保在执行保护代码期间始终正确锁定和解锁互斥量。
在 main 函数中,用两个线程同时更新一个共享变量,通过 RAII 包装的 LockGuard 确保互斥量的正确使用。
C++ 智能指针解析
为什么需要智能指针
众所周知,Java 和 C/C++ 中间隔着一堵由内存动态分配和垃圾回收机制所围成的墙。
java 大佬们经常吐槽 C++ 没有垃圾回收(Gabage Collector)机制,而 C++ 爱好者也经常攻击 Java 限制太死,不够灵活。
其实 Java 并不是最早实践内存动态分配和垃圾自动回收机制的语言,这个构想在 1960 年就已经在MIT 的教学语言 Lisp 中提出。
在 C/C++ 中最为灵活的工具就是指针了,但指针也是很多噩梦的源头,内存泄露(memory leak)和内存非法访问应该算是 C++ 程序员的家常便饭了。
但是又不能抛弃指针带来的灵活性,不过幸好 C++ 里有了智能指针,虽然在使用上有局限性,但是能够最大程度减少程序员手动管理指针生命周期的负担。
指针的强大很大程度上源于它们能追踪动态分配的内存。通过指针来 管理这部分内存是很多操作的基础,包括一些用来处理复杂数据结构 的操作。要完全利用这些能力,需要理解C的动态内存管理是怎么回 事。
C++是面向内存编程,Java是面向数据结构编程。
C++里,内存是裸露的,可以拿到地址,随意徜徉,增了删了,没人拦你,等到跑的时候再崩给你看。
Java里,能操作的都是设计好的数据结构,array有长度,String不可变,每一个都是安全的,在内存和程序员之间,隔着JVM,像是包住了边边角角的房间,随便小孩折腾,不会受伤。
Java程序员是孩子,嚷嚷要这个那个,玩完了就丢,JVM是家长,买买买,还要负责收拾。有的孩子熊点,屋子很乱,收拾起来费劲,但房子还在。
C++程序员是神,操纵着江河湖海,日月星辰,但能力越大,责任越大,万一新来的神比较愣,手一滑,宇宙就退出了。
新手写C++,像是抱着一捆指针,在浩瀚的内存中裸奔。跑着跑着,有的针掉了,不知踪影,内存就泄露了;跑着跑着,突然被人逮住,按在地上打的error纷飞,内存就越界了;终于到了,舒了口气,把针插在脚下,念出咒语,
“delete”
系统就崩溃了
C/C++ 常见的内存错误
在实际的 C/C++ 开发中,我们经常会遇到诸如 coredump、segmentfault 之类的内存问题,使用指针也会出现各种问题,比如:
- 野指针:未初始化或已经被释放的指针被称为野指针
- 空指针:指向空地址的指针被称为空指针
- 内存泄漏:如果在使用完动态分配的内存后忘记释放,就会造成内存泄漏,长时间运行的程序可能会消耗大量内存。
- 悬空指针:指向已经释放的内存的指针被称为悬空指针
- 内存泄漏和悬空指针的混合:在一些情况下,由于内存泄漏和悬空指针共同存在,程序可能会出现异常行为。
- ...
智能指针
而智能指针是一种可以自动管理内存的指针,它可以在不需要手动释放内存的情况下,确保对象被正确地销毁。
这种指针可以显著降低程序中的内存泄漏和悬空指针的风险。智能指针的核心思想就是 RAII, C++中,智能指针常用的主要是两个类实现:
- std::unique_ptr
- std::shared_ptr
std::unique_ptr
std::unique_ptr是一个独占所有权的智能指针,它保证指向的内存只能由一个unique_ptr拥有,不能共享所有权。
当unique_ptr超出作用域时,它所指向的内存会自动释放。
#include <memory>
#include <iostream>
int main() {
std::unique_ptr<int> ptr(new int(10));
std::cout << *ptr << std::endl; // 输出10
// unique_ptr在超出作用域时自动释放所拥有的内存
return 0;
}
std::shared_ptr
std::shared_ptr是一个共享所有权的智能指针,它允许多个shared_ptr指向同一个对象,当最后一个shared_ptr超出作用域时,所指向的内存才会被自动释放。
#include <memory>
#include <iostream>
int main() {
std::shared_ptr<int> ptr1(new int(10));
std::shared_ptr<int> ptr2 = ptr1; // 通过拷贝构造函数创建一个新的shared_ptr,此时引用计数为2
std::cout << *ptr1 << " " << *ptr2 << std::endl; // 输出10 10
// ptr2超出作用域时,所指向的内存不会被释放,因为此时ptr1仍然持有对该内存的引用
return 0;
}
总的来说,智能指针可以提高程序的安全性和可靠性,避免内存泄漏和悬空指针等问题。
但需要注意的是,智能指针不是万能的,也并不是一定要使用的,有些场景下手动管理内存可能更为合适。
深入理解 C++ shared_ptr之手写
正如这篇文章 智能指针 (opens new window)所说,智能指针是一种可以自动管理内存的指针,它可以在不需要手动释放内存的情况下,确保对象被正确地销毁。
可以显著降低程序中的内存泄漏和悬空指针的风险。
而用得比较多的一种智能指针就是 shared_ptr ,从名字也可以看出来,shared 强调分享,也就是指针的所有权不是独占。
shared_ptr 的使用
shared_ptr 的一个关键特性是可以共享所有权,即多个 shared_ptr 可以同时指向并拥有同一个对象。当最后一个拥有该对象的 shared_ptr 被销毁或者释放该对象的所有权时,对象会自动被删除。这种行为通过引用计数实现,即 shared_ptr 有一个成员变量记录有多少个 shared_ptr 共享同一个对象。
#include <iostream>
#include <memory>
class MyClass {
public:
MyClass() { std::cout << "MyClass 构造函数\n"; }
~MyClass() { std::cout << "MyClass 析构函数\n"; }
void do_something() { std::cout << "MyClass::do_something() 被调用\n"; }
};
int main() {
{
std::shared_ptr<MyClass> ptr1 = std::make_shared<MyClass>();
{
std::shared_ptr<MyClass> ptr2 = ptr1; // 这里共享 MyClass 对象的所有权
ptr1->do_something();
ptr2->do_something();
std::cout << "ptr1 和 ptr2 作用域结束前的引用计数: " << ptr1.use_count() << std::endl;
} // 这里 ptr2 被销毁,但是 MyClass 对象不会被删除,因为 ptr1 仍然拥有它的所有权
std::cout << "ptr1 作用域结束前的引用计数: " << ptr1.use_count() << std::endl;
} // 这里 ptr1 被销毁,同时 MyClass 对象也会被删除,因为它是最后一个拥有对象所有权的 shared_ptr
return 0;
}
MyClass 构造函数
MyClass::do_something() 被调用
MyClass::do_something() 被调用
ptr1 和 ptr2 作用域结束前的引用计数: 2
ptr1 作用域结束前的引用计数: 1
MyClass 析构函数
引用计数如何实现的
说起 shared_ptr 大家都知道引用计数,但是问引用计数实现的细节,不少同学就回答不上来了,其实引用计数本身是使用指针实现的,也就是将计数变量存储在堆上,所以共享指针的shared_ptr 就存储一个指向堆内存的指针,文章后面会手动实现一个 shared_ptr。
shared_ptr 的 double free 问题
double free 问题就是一块内存空间或者资源被释放两次。
那么为什么会释放两次呢?
double free 可能是下面这些原因造成的:
- 直接使用原始指针创建多个 shared_ptr,而没有使用 shared_ptr 的 make_shared 工厂函数,从而导致多个独立的引用计数。
- 循环引用,即两个或多个 shared_ptr 互相引用,导致引用计数永远无法降为零,从而无法释放内存。
如何解决 double free
解决 shared_ptr double free 问题的方法:
- 使用 make_shared 函数创建 shared_ptr 实例,而不是直接使用原始指针。这样可以确保所有 shared_ptr 实例共享相同的引用计数。
- 对于可能产生循环引用的情况,使用 weak_ptr。weak_ptr 是一种不控制对象生命周期的智能指针,它只观察对象,而不增加引用计数。这可以避免循环引用导致的内存泄漏问题。
#include <iostream>
#include <memory>
class B; // 前向声明
class A {
public:
std::shared_ptr<B> b_ptr;
~A() {
std::cout << "A destructor called" << std::endl;
}
};
class B {
public:
std::shared_ptr<A> a_ptr;
~B() {
std::cout << "B destructor called" << std::endl;
}
};
int main() {
{
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
a->b_ptr = b; // A 指向 B
b->a_ptr = a; // B 指向 A
} // a 和 b 离开作用域,但由于循环引用,它们的析构函数不会被调用
std::cout << "End of main" << std::endl;
return 0;
}
上面这种循环引用问题可以使用std::weak_ptr来避免循环引用。
std::weak_ptr不会增加所指向对象的引用计数,因此不会导致循环引用。
下面
标签:std,管理,int,chunk,C++,内存,ptr,指针 From: https://www.cnblogs.com/sfbslover/p/18402615