最近碰到棘手的问题: 以太网进行iperf测试时, 发生了SMMU (System Memory Management Unit)访问异常导致内核崩溃. 原本只是内部测试发现, 后面在试验车上也概率性的出现. 问题发生的概率还不小. 很严重. 只能先从头把一些基本概念与流程梳理清楚. 好在最后还是找到了原因并解决了. 松了口气, 才有时间把整个问题的来龙去脉细细的总结下, 算是一个SMMU相关问题的案例.
首先来看看问题的发生的背景.
问题背景
问题发生在利用iperf做网络性能测试的时候, 测试系统(采用高通8155平台, 内置一个EMAC芯片, 最高支持1Gbps速率)作为客户端:
iperf -c 172.20.2.33 -p 8989 -f m -R
这里加-R参数表示客户端作为数据接收方(奇怪的是, 测试不加-R参数就不会有问题, 这也说明只有在接收数据的过程才会出现问题), 而服务端是发送方:
iperf -s -p 8989 -f m
这么测试几十个小时就很快出现了, 抓取到的问题堆栈如下. 前面的日志是SMMU相关的寄存器状态打印, 后面是内核调用堆栈.
[53480.526297] arm-smmu 15000000.apps-smmu: FAR = 0x00000000a2a2a000
[53480.533192] arm-smmu 15000000.apps-smmu: PAR = 0x0000000000000000
[53480.540466] arm-smmu 15000000.apps-smmu: FSR = 0x40000402 [TF W SS ]
[53480.547750] arm-smmu 15000000.apps-smmu: TTBR0 = 0x000f00035bbaa000
[53480.554990] arm-smmu 15000000.apps-smmu: TTBR1 = 0x000f000000000000
[53480.562192] arm-smmu 15000000.apps-smmu: SCTLR = 0x00c000e7 ACTLR = 0x00000000
[53480.570572] arm-smmu 15000000.apps-smmu: CBAR = 0x0001f300
[53480.576741] arm-smmu 15000000.apps-smmu: MAIR0 = 0xf404ff44 MAIR1 = 0x00000000
[53480.585071] arm-smmu 15000000.apps-smmu: Unhandled context fault: iova=0xa2a2a000, cb=14, fsr=0x40000402, fsynr0=0x7e0013, fsynr1=0x0
[53480.597668] arm-smmu 15000000.apps-smmu: soft iova-to-phys=0x0000000000000000
[53480.605440] arm-smmu 15000000.apps-smmu: SOFTWARE TABLE WALK FAILED! Looks like 15000000.apps-smmu accessed an unmapped address!
[53480.617935] arm-smmu 15000000.apps-smmu: hard iova-to-phys (ATOS) failed
[53480.625147] arm-smmu 15000000.apps-smmu: SID=0x3c0
[53480.630332] arm-smmu 15000000.apps-smmu: Unhandled arm-smmu context fault!
[53480.638310] ------------[ cut here ]------------
[53480.638324] kernel BUG at /home/jenkins/.jenkins/workspace/SourceCode/kernel/msm-4.14/drivers/iommu/arm-smmu.c:1762!
[53480.649128] [KERN Warning] ERROR/WARN forces debug_lock off!
[53480.649135] [KERN Warning] check backtrace:
[53480.649151] CPU: 0 PID: 319 Comm: irq/386-arm-smm Tainted: G S O 4.14.170+ #2
[53480.649160] Hardware name: Qualcomm Technologies, Inc. SA8155P v2 PM8150 ADP-STAR model-D55 (DT)
[53480.649171] Call trace:
[53480.649215] dump_backtrace+0x0/0x1f4
[53480.649226] show_stack+0x20/0x2c
[53480.649241] dump_stack+0xe4/0x134
[53480.649255] debug_locks_off+0x54/0x88
[53480.649268] oops_enter+0x14/0x20
[53480.649275] die+0x38/0x16c
[53480.649284] bug_handler+0x50/0x88
[53480.649293] brk_handler+0x6c/0xb4
[53480.649301] do_debug_exception+0x7c/0x114
[53480.649309] el1_dbg+0x18/0x74
[53480.649321] arm_smmu_context_fault+0x8e0/0x944
[53480.649332] irq_thread_fn+0x2c/0x70
[53480.649340] irq_thread+0xc0/0x144
[53480.649350] kthread+0x128/0x138
[53480.649357] ret_from_fork+0x10/0x18
[53480.649367] Internal error: Oops - BUG: 0 [#1] PREEMPT SMP
从堆栈来看大致可以了解到, 这是由于SMMU监测到某个模块非法的访问DMA地址后, 引起了内核崩溃. 那么, 为何有这个错误SMMU访问错误? 这个错误又是哪个模块导致的? 是在什么情况下引起的SMMU内存错误了? 这不得不从SMMU本身说起.
什么是SMMU
简单来说, SMMU(System Memory Management Unit)是ARM为外设访问系统RAM提供了一种类似于MMU的虚拟内存访问机制, 外设可以通过DMA直接访问RAM, 而无需CPU的干预. 如此, 外设可以通过一个虚拟的地址即可访问物理地址(可以不连续), 做到了不同外设之间IO地址空间的彼此独立与隔离. 因此, SMMU也通常被称为IOMMU(Input/Output MMU).
下图是从ARM SMMU Spec手册里的一张SMMU简图: SMMU为设备与RAM之间构建了一个设备虚拟地址(IOVA)与物理地址之间的映射关系, 每次执行DMA数据传输的时候, 都要通过SMMU将IOVA地址翻译成对应的物理地址.
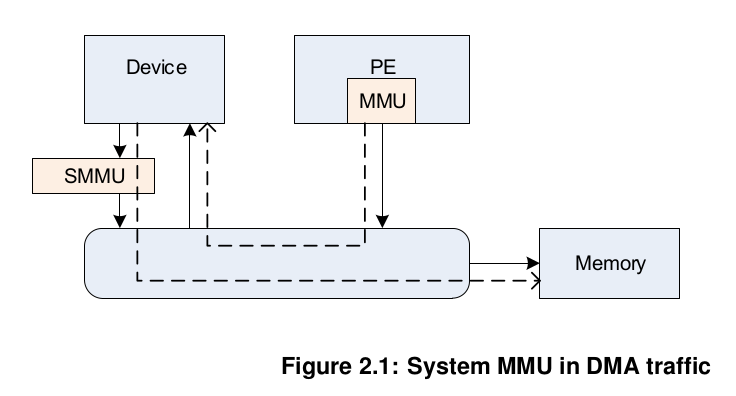
那么对于设备驱动来说, 如何使用SMMU了? 不妨来看下SMMU相关的API.
arm_iommu_create_mapping: 配置设备所要使用的VA(Virtual Address, 虚拟地址)的范围arm_iommu_attach_device: 将分配好的VA地址范围与设备绑定, 并开启SMMU地址转换dma_map_single/dma_unmap_single: 分配/去除某个DMA地址, 这种方式是异步的, 常用于一次性传输的场景(传输完成后DMA的映射即解除了)dma_alloc_coherent/dma_free_coherent: 一致性(consistent), 同步(synchronous)的DMA内存分配方法, 确保CPU与设备的数据始终是同步的, 一般用于需要常驻内存的一些数据
这里不对IOMMU的代码做深入分析了. 有关IOMMU相关的流程可以参考内核代码:
- kernel/drivers/iommu: SMMU驱动, 用于配置SMMU, 为设备驱动提供接口
- kernel/arch/arm64/mm: 与平台相关的SMMU的页表分配的实现
有了这些SMMU的基础知识, 我们就来分析下最开始那个问题.
SMMU访问异常问题分析
继续来看下问题的日志. 堆栈的前面一部分是有关SMMU的状态寄存器:
-
FSR(
Fault Status Register)表示SMMU错误的类型(转换/权限等), 这里的值0x40000402 [TF W SS ], 说明是一个写操作时引起的页表访问错误 -
FAR(
Fault Address Register): 表示发生错误的IO虚拟地址 -
PAR(
Physical Address Register): 发生错误时查找到的物理地址, 这里是全0, 说明相应的IOVA地址没有映射 -
TTBRm(Translation Table Base Address):
- TTBR0: 保存Translation Table0的基地址
- TTBR1: 保存Translation Table1的基地址
重点看下如下两行日志, 我们可以知道发生内存映射异常的IOVA地址是0xa2a2a000, 对应的SID是0x3c0(SID是对应设备使用SMMU映射内存时的标识),SID一般在设备树DTS的配置中指定的.
[53480.585071] arm-smmu 15000000.apps-smmu: Unhandled context fault: iova=0xa2a2a000, cb=14, fsr=0x40000402, fsynr0=0x7e0013, fsynr1=0x0
....
[53480.625147] arm-smmu 15000000.apps-smmu: SID=0x3c0
查看内核的DTS配置, iommus这个对应了设备节点SMMU的配置;可以看到发生问题的设备正是以太网:
emac_emb_smmu: emac_emb_smmu {
compatible = "qcom,emac-smmu-embedded";
iommus = <&apps_smmu 0x3C0 0x0>;
qcom,iova-mapping = <0x80000000 0x40000000>;
};
理清楚这些SMMU的日志只是第一步, 但是对于为何会发生SMMU访问异常还是毫无头绪. 这个只能通过阅读驱动源代码弄清楚以太网网卡数据的接收流程才能一步步揭开迷雾了.
对于目前的以太网网卡来说, 一般采用ring buffer(环形缓冲区)的形式来接收数据; 驱动在初始化的时候为网卡的ring buffer预分配DMA内存, 用于接收数据. 总体来收, 网卡的数据接收流程有如下三个步骤:
- 网卡需要传数据时, 获取到当前的缓冲区对应的DMA内存地址(IOVA)后, 通过SMMU向对应的RAM地址传输数据
- 发送完成后, 通过中断告知驱动有数据需要接收
- CPU接收到中断后, 驱动会把DMA的映射解除, 数据交由CPU处理; 接着驱动把对应的数据发送到协议栈继续处理
那么, 问题来了, SMMU是何时收到DMA访问异常错误的了? 是在第三个步骤, 驱动解除DMA地址映射后, 有地方再次尝试使用该DMA地址导致的吗? 从驱动的逻辑来看, 每次传送完成, DMA地址与RAM地址解除映射后, 没有地方会再次尝试获取该DMA地址了(对应buffer的DMA地址已经置空). 退一步说, 如果是驱动使用的时候发生的问题, 那么异常的堆栈应该会打印出来, 但是现在只有SMMU相关的日志.
所以, 问题的源头只能是在网卡通过SMMU往对应的DMA地址发送数据的时候, 就是说如果网卡给DMA传输数据的大小超过了预分配的buffer的大小的话, SMMU会发现对应的DMA地址没有映射到物理地址, 从而报错. 解决问题的办法也很简单, 只需要把buffer大小由原来的1538修改为2048(2kb)就可以了:
-#define DWC_ETH_QOS_ETH_FRAME_LEN (ETH_FRAME_LEN + ETH_FCS_LEN + VLAN_HLEN + PADDING_ISSUE)
+#define DWC_ETH_QOS_ETH_FRAME_LEN (1<<11)
修改后再次验证, 问题不再出现. 但这里有个问题, DMA的buffer大小为何设置成2kb而不是其他如4kb了? 这个实际跟以太网网卡(EMAC)本身的设计有关, 一般以太网的一帧数据是一个MTU(一般是1500, 如果有VLAN数据, 则会多4个字节), 但为何网卡传输的一帧数据会超过设定的MTU大小, 这个目前咨询了供应商仍然没有得到答案(供应商怀疑是发送端给到的一帧数据超过了最大的MTU 1538, 这个结论仍然值得怀疑).
从高通给的一些问题案例来说, 一般SMMU都是由于需要传输的数据大小与实际的buf大小不一致导致的. 总的说来, SMMU的问题看起来十分棘手, 但只要把基本的概念与原理弄清楚, 把代码流程梳理完整, 解决这类问题并不是件十分困难的事情.
标签:DMA,SMMU,apps,smmu,访问,内存,arm,15000000 From: https://www.cnblogs.com/linhaostudy/p/18352213