前言
很多人对进程、线程没有什么概念,面试的时候也说不出其中的核心内涵。
所以,今天我打算花点篇幅把进程和线程讲清楚。
01 CPU与内存
**CPU **大家都知道是计算机的中央运算单元,用来计算的。
CPU从内存里面读取一条一条的代码指令,然后根据指令来执行运算(加,减,乘,除,复制数据等)。
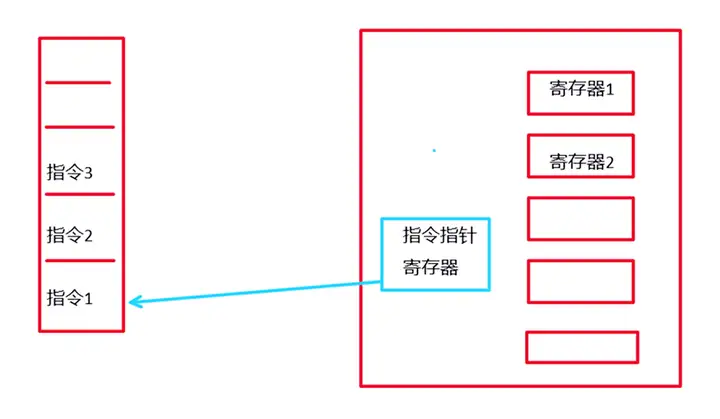
CPU在运算的过程中一些数据存放在CPU的寄存器和内存里面。
CPU里面有各种寄存器,各司其职。指令指针寄存器存放的是当前执行到那条代码指令了。代码指令是写完程序后被编译器编译成二进制指令代码
02 内核与虚拟内存
电脑或手机开机以后,上电跑启动代码,运行OS内核,内核里也有线程,这个我们把它叫做内核态。
内核启动以后, 内核将物理内存管理起来。内核提供虚拟内存管理机制给每个进程(应用程序App)内存服务。
它的思路是什么呢?每个进程(应用App) 都有自己的虚拟内存空间,注意这里的空间只是一个数字空间,没有划分实际的物理内存。
这样做的好处是多个进程(应用App)内存都是独立的相互不影响,物理内存只有一个,多个进程(应用App)不会因为直接使用物理内存而冲突。

那么OS是如何管理物理内存的呢?进程(应用App)需要内存的时候,OS分配一块虚拟内存(起点---终点),然后OS在从自己管理的物理内存里面分配出来物理内存页,然后通过一个MMU的单元,将分配的虚拟内存与物理内存页映射起来,这样,读写虚拟内存地址最终通过映射来使用物理内存地址,这样每个进程之间的内存是独立的,安全的。每个进程会把虚拟内存空间分成4个段(代码段, 数据端,堆,栈)
代码段:用来存放进程(应用App)的代码指令。
数据端:用来存放全局变量的内存。
堆:调用os的malloc/free 来动态分配的内存。
栈:用来存放局部变量,函数参数,函数调用与跳转。
每个进程(应用App)相当于一个容器,所有应用App里面需要的资源和机制都在进程里面。
线程是OS独立调度执行的单元,OS调度执行的单位就是线程,线程需要以进程作为容器和使用进程相关的环境。
应用态没有进程就不会有线程。
03 进程与线程
上面说过进程是容器,应用态的线程必须要基于进程来创建出来。
那么进程与线程他们之间到底是一个什么样的关系,接下来我们来分析一下。
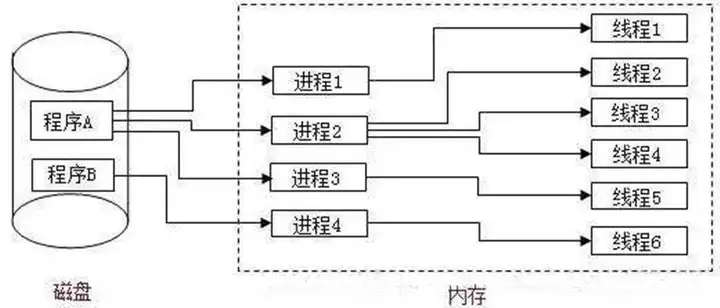
例如"在桌面上双击打开一个App", 桌面App程序会调用OS的系统调用接口fork,让OS 创建一个进程出来,OS为你准备好进程的结构体对象,将这个App的文件(xxx.exe, 存放编译好的代码指令)加载到进程的代码段,同时OS会为你创建一个线程(main thread), 在代码里面,还可以调用OS的接口,来创建多个线程,这样OS就可以调度这些线程执行了。
虚拟内存空间是进程的概念,那么线程如何使用的呢?各线程使用共享进程的代码段,数据段,堆,每个线程在进程的栈空间创建一个属于自己的栈空间。
所以这样就得到一些结论如下:
每个线程共享进程的代码段内存空间,所以我们编写多线程代码的时候,可以在任何线程调用任何函数。
每个线程共享进程的数据段内存空间,所以我们编写多线程代码的时候,可以在任何线程访问全局变量。
每个线程共享进程的堆,所以我们编写多线程代码的时候,可以在一个线程访问另外一个线程new/malloc出来的内存对象。
每个线程都有自己的栈的空间,所以可以独立调用执行函数(参数,局部变量,函数跳转)相互之间不受影响。

04 OS如何调度线程的
CPU一般会有多个核心,每个核心都调度一个线程执行。
CPU有几个核心,最多同时可调度几个线程(多核能让电脑更快就是这个原理)。
OS的功能就是要在合适的时候分配CPU核心来调度合适的线程。
为了能实现多任务并发,OS不允许一个OS核心长期固定调度一个线程。
OS是如何调度CPU核心来执行各个线程呢?

OS会根据线程的优先级分配每次调度最多执行的时间片,这个时间一到,无论如何都要重新调度一次线程(也许还是调度到这个线程,这个不重要)。
除了时间片以外,线程会等待某些条件(磁盘读取文件,网卡发送完数据,线程休眠, 等待用户操作)这样也会把这个线程挂起,OS会重新找一个新的线程继续执行,只到挂起的这个线程的条件满足了,重新把这个线程放到可调度队列里面,这个线程又有机会被OS调度CPU核心来执行。
当我们打开电脑的任务管理器,你会发现很多线程的CPU占有率为0%, 说明这些线程都由于某些条件而挂起了,没有被OS调度。
每个线程“随时随地”都可能被OS中断执行,并调度到其它的线程执行。
OS是如何保证一个线程在调度出去后,再重新调度回来能继续之前的数据状态来执行呢?
OS是这么做的:每个线程都会有一个运行时的环境(运行时CPU的每个寄存器的值、栈独立。栈的内存数据不会变。数据段、堆共用,可能调度回来会变)。
当OS要把某个CPU核心调度出去给其它线程的时候,首先会把当前线程的运行环境(寄存器的值等)保存到内存,然后调度到其它线程,等再次调度回来的时候,再把原来保存到内存的寄存器的值,再设置会CPU核心的寄存器里面,这样就回到了调度出去之前的进度。
因为多线程之间共用了代码段(代码段只读,不会改),数据段(全局变量调度回来后,可能被其它线程篡改,不是调度之前的那个值了),堆(调度回来后,动态内存分配的对象内存数据可能被其它线程出篡改),调度回来后,栈上的数据是不变的,因为每个线程都有自己的栈空间。线程调度前后哪些会变,哪些不变你要清楚。这样你写多线程代码的时候才能清晰。
线程调度的开销就是:保存上下文执行环境,内核态运行算法决定接下来调度那个线程,切换这个线程的上下文环境。
05 线程锁的核心原理是什么?
多线程切换的时候,栈、代码段的数据不会变,数据段与堆的数据切换前后可能会发生改变,这个就造成了"竞争", 如果某些关键数据,在执行代码的时候,不允许这种竞争性的改变,怎么办呢?这个时候多线程就给了一个机制,这个机制就是锁,那么锁的原理是什么?接下来我来这你详细讲解。

例如: 我编写一个函数
funcA() {
lock(锁) // 要保护的数据的逻辑部分。
…
unlock(锁)
}当线程A调用FuncA(),线程B也调用FUNCA(),OS如何设计锁能保证他们竞争的唯一性的呢?我们把具体过程来分析一下。
假设线程A调用funcA();它获取了锁,执行到中间某个代码的时候,时间片用完了,被OS调度出去,OS调度线程B来执行funcA(), 当线程B跑到lock(锁),发现这个锁已经被线程A拿了,此时,线程B会主动把自己挂起到锁这个“事件”上(等着锁释放)。
OS从新调度线程执行,当重新调度到线程A的时候,线程A执行,执行完成以后,释放掉这个锁,那么线程B又从等待这个锁的队列,到线程调度的就绪队列,又可被OS调度到,等线程A调度出去后,线程B去lock这个锁,就占用了这个锁,然后继续执行。这样就保证了lock/unlock之间的代码永远只有一个线程跑进去了。这样保护了这段代码里面相关的数据和逻辑。
进程与线程各位老铁一定要掌握好,这样写程序才能做到心中用代码。
好了,今天的分享就到这里,谢谢大家收看,我们下期再见。
最后,给大家分享一下咱们涵盖cocos、unity、laya...一系列的游戏实战大礼包,今天全部免费提供给大家,点击下方即可获取:
标签:讲清楚,调度,线程,内存,进程,OS,CPU From: https://www.cnblogs.com/liuwenyi/p/17805625.html