目录
InnoDB 架构
下图显示了组成 InnoDB 存储引擎架构的内存和磁盘结构。有关每个结构的信息:
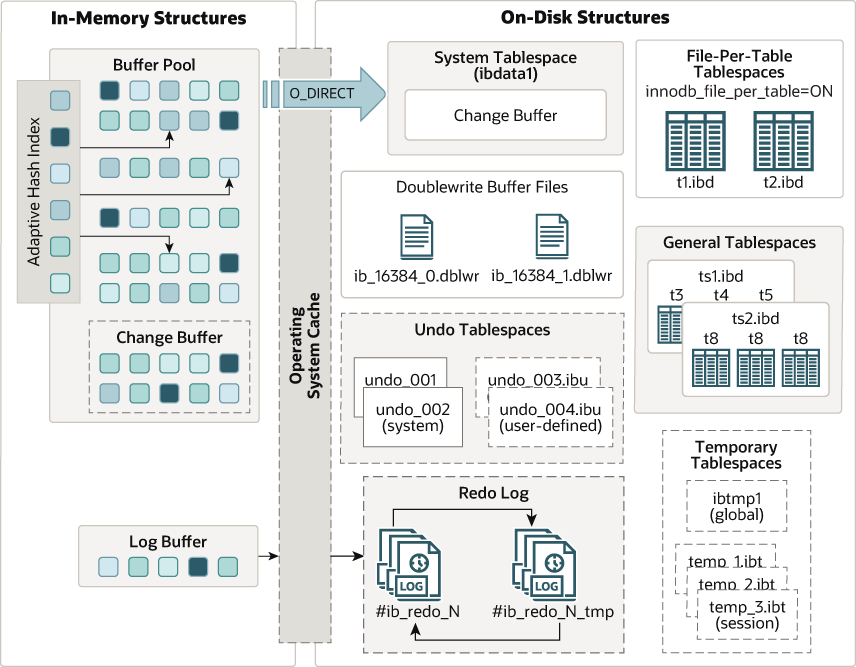
概念
page
页(Page):InnoDB 在磁盘(data files)和内存(buffer pool)之间传输数据的基本单位。
一个页(Page)可以包含一个或多个行(row),这具体取决于每行中有多少数据,如果一行不能完全放入一页,InnoDB 会设置额外的指针式数据结构,以便有关该行的信息可以存储在一页中。
在每页中容纳更多数据的一种方法是使用压缩行格式(compressed row format),对于使用 BLOB 或大型文本字段的表,紧凑行格式允许将这些大型列与行的其余部分分开存储,从而减少不引用这些列的查询的 I/O 开销和内存使用量。
为了提升 I/O 吞吐量,InnoDB 的读取和写入操作,都是按照一个或多个页进行的,会一次性读取或写入一个范围。
page size
通过选项 innodb_page_size 控制可以修改 page size,其默认值为:16384,即 16KB。
默认的 16KB 页面大小或更大的空间,适用于各种工作负载,特别是涉及全表扫描的查询和涉及批量更新的 DML 操作。
对于涉及许多小型写入的 OLTP 工作负载,较小的页面大小可能更有效,当单个页面包含许多行时,可能会面临竞争等问题。
对于 SSD 存储设备来说,较小的页面也可能会更高效,因为,SSD 存储设备通常使用较小的块大小。
保持 InnoDB 的页面大小接近存储设备的块大小,可以最大限度地减少重写到磁盘的未更改数据量。
InnoDB 内存架构
Buffer Pool
缓冲池(Buffer Pool)是主内存中的一个区域,InnoDB 在被访问时,会缓存表和索引数据。缓冲池允许直接从内存访问经常使用的数据,从而加快处理速度,在专用服务器上,高达 80% 的物理内存通常分配给缓冲池。
为了提高大容量读取操作的效率,缓冲池被划分为可以容纳多个行(row)的页(page)。为了提高缓存管理的效率,缓冲池中的页(page)通过链表管理;使用最近最少使用 (LRU) 算法的变体,很少使用的数据会从缓存中老化。
缓冲池 LRU 算法
缓冲池使用 LRU 算法的变体作为链表进行管理。当需要空间向缓冲池添加新页面时,最近最少使用的页面将被逐出,并将新页面添加到链表的中间。
这种中点插入策略将链表视为两个子链表:
-
头部:是最近访问的新(“年轻”)页面的子链表
-
尾部:是最近访问较少的旧页面的子链表
缓冲池链表的结构,如下:
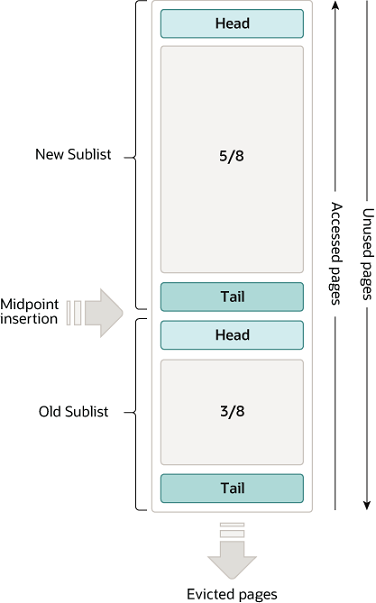
该算法将经常使用的页面保留在 new 子链表中。old 子链表包含不常用的页面,这些页面是被驱逐的候选页面。
默认情况下,该算法的运行策略如下:
-
缓冲池的 3/8 专用于 old 子链表;
-
链表的中点是 new 子链表的尾部与 old 子链表的头部相交的边界;
-
当 InnoDB 将一个数据页读入缓冲池时,它最初将其插入到链表的中点,即 old 子链表的头部;
用户启动的操作(如,SQL查询)会触发数据页的读取,或者,数据页会作为 InnoDB 自动执行的预读操作的一部分被加载到缓冲池。
-
访问 old 子链表中的页,会使其“年轻化”,它将被移动到 new 子链表的头部;
注意,这个数据页被访问,分两种情况:
-
如果该页是因为用户启动的操作需要而被读取的,则第一次访问会立即发生,并且该页会变为年轻页。
-
如果该页是由于预读操作而读取该页,则第一次访问不会立即发生,并且,在该页被逐出之前可能根本不会发生。
-
-
随着数据库的运行,缓冲池中未访问的页会通过向链表尾部移动而“老化”。new 子链表 和 old 子链表中的页会随着其他的页更新而老化。当页面在中点插入时,old 子链表中的页也会老化。最终,未使用的页到达 old 子链表的尾部并被驱逐。
默认情况下,因查询而读取的页,会立即移动到 new 子链表中,这意味着它们在缓冲池中停留的时间更长。
执行全表扫描会将大量的数据放入缓冲池,并逐出等量的旧数据,即使新数据不再使用。如,执行 mysqldump 操作或不带 WHERE 子句的 SELECT 的语句。同样,由后台预读线程(read-ahead background thread)加载且仅访问一次的页,也会被移动到 new 子链表的头部。
这些情况,都可能会将经常使用的页推送到 old 子链表,并在 old 子链表中被驱逐。
缓冲池配置
我们可以如下方式配置缓冲池,以提高性能:
-
理想情况下,我们可以将缓冲池的大小设置为尽可能大的值,为服务器上的其他进程留下足够的内存来运行,而不会出现过多的分页。缓冲池越大,就越InnoDB像内存数据库,从磁盘读取数据一次,然后在后续读取时从内存访问数据;
-
在内存充足的 64 位系统上,我们可以将缓冲池拆分为多个部分,以最大程度地减少并发操作之间对内存结构的争用;
-
我们可以将频繁访问的数据保留在内存中,而不管操作活动是否突然出现峰值,这些操作会将大量不经常访问的数据带入缓冲池;
-
我们可以控制如何以及何时执行预读请求,以异步方式将页面预取到缓冲池中,以预测即将需要的页面;
-
我们可以控制何时发生后台刷新以及是否根据工作负载动态调整刷新速率;
-
我们可以配置如何 InnoDB 保留当前缓冲池状态,以避免服务器重新启动后出现过长的预热期。
Change Buffer
当二级索引页不在缓冲池中时,写缓冲区(change buffer)它会缓存二级索引页的更改。缓冲的更改可能由 INSERT、UPDATE 或 DELETE 操作 (DML) 产生的,稍后当其他读取操作将索引页加载到缓冲池中时,这些更改将被合并。
change Buffer 是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(Buffer changes),等未来数据被读取时,再将数据合并(Merge)恢复到缓冲池中的技术。写缓冲的目的是降低写操作的磁盘 IO,提升数据库性能。
change Buffer 的结构如下:
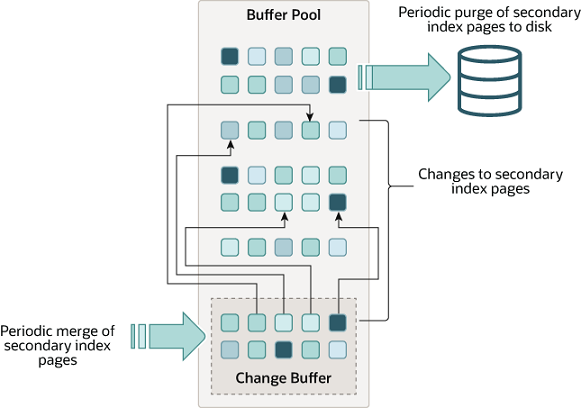
在内存中,change Buffer 占用缓冲池中的一部分;同时,在磁盘上,change Buffer 也是系统表空间的一部分,当数据库服务器关闭时,索引的变更将被刷盘到系统表空间中。
与聚集索引不同,二级索引通常不具有唯一性,并且插入二级索引的顺序相对随机。同样,删除和更新可能会影响索引树上不相邻的二级索引页。当其他操作将受影响的页读入缓冲池时,稍后合并缓存中的修改可以避免从磁盘将辅助索引页读入缓冲池所需的大量随机访问 I/O。
当 InnoDB 的索引列具有唯一约束时,对索引列的修改,就必须进行唯一性检查,就需要将磁盘上索引页读入 buffer pool,此时,就可以直接通过 buffer pool 修改,而不需要通过 change buffer 机制更改。
当系统运行缓慢,或者在服务缓慢关闭期间,清除(purge)操作会定期将被更新的索引页写入磁盘。与立即将每个值写入磁盘相比,清除操作可以更有效地写入一系列索引值的磁盘块。
当有许多受影响的行和大量的二级索引需要更新时,change Buffer 合并可能需要几个小时。在此期间,磁盘 I/O 会增加,这可能会导致磁盘绑定的查询显着减慢。提交事务后,甚至在服务器关闭并重新启动后,更改缓冲区合并也可能继续发生。
change Buffer 中缓存的数据类型由 innodb_change_buffering 变量控制。
注意,如果二级索引包含降序索引列,或者,主键包含降序索引列,则二级索引不支持 change Buffer。
配置变更缓冲
当对表执行 INSERT、UPDATE 和 DELETE 操作时,索引列的值(特别是二级索引的值)通常处于未排序的顺序,需要大量 I/O 才能使辅助索引保持最新状态。
当索引页不在缓冲池中时,change Buffer 会缓存对辅助索引条目的更改,从而通过不立即从磁盘读取页面来避免昂贵的 I/O 操作。
当索引页加载到缓冲池中时,缓冲的更改将被合并,更新的索引页稍后会刷新到磁盘。当服务器空闲时,或者缓慢关闭期间,InnoDB 主线程会合并缓冲的更改。
因为 change Buffer 可以减少磁盘读取和写入,所以,change Buffer 对于 I/O 密集型工作负载最有价值。例如,具有大量 DML 操作(例如,批量插入)的应用程序可以从 change Buffer 中受益。
但是,change Buffer 占用了缓冲池的一部分,从而减少了可用于缓存数据页的内存。如果工作集几乎适合缓冲池,或者表的二级索引相对较少,则禁用更改缓冲可能会很有用。如果工作数据集完全适合缓冲池,则 change Buffer 不会施加额外的开销,因为它仅适用于不在缓冲池中的索引页。
innodb_change_buffering
innodb_change_buffering 变量控制 InnoDB 执行更改缓冲的程度。
我们可以启用或禁用 INSERT、DELETE 操作(当索引的记录最初标记为删除时)和清除(purge)操作(当索引的记录被物理删除时)的缓冲。
一次更新操作是一个插入操作和一个删除操作的组合。
| System Variable | innodb_change_buffering |
|
|---|---|---|
| Default Value | all |
默认值,缓冲插入、删除标记操作和清除(purge)操作。 |
| Valid Values | none |
不缓冲任何操作。 |
inserts |
缓冲区插入操作。 | |
deletes |
缓冲区删除标记操作。 | |
changes |
缓冲插入和删除标记操作。 | |
purges |
缓冲后台发生的物理删除操作。 |
innodb_change_buffer_max_size
innodb_change_buffer_max_size 变量控制 change buffer 占用整个 buffer pool 的百分比。
其默认值为:25,即默认占用 25% 的内存,可以配置的范围:\([0, 50]\)
change Buffer 的适用场景
-
适合开启 change buffer 的场景
-
数据表大部分是非唯一索引;
-
业务是写多读少,或者不是写后立刻读取。
这两类场景,可以使用写缓冲,将原本每次写入都需要进行磁盘 IO 的 SQL,优化定期批量写磁盘,例如,账单流水业务。
-
-
不适合开启 change buffer 的场景
-
数据表的列都是唯一索引;
-
写入一个数据后,会立刻读取它。
这两类场景,在写操作进行时(进行后),本来就要进行进行页读取,相应的页面原本就要入缓冲池,此时,写缓存反倒成了负担,增加了复杂度。
-
自适应哈希索引
自适应哈希索引(Adaptive Hash Index)
Log Buffer
InnoDB 磁盘架构
表
索引
表空间
双写缓冲区
Doublewrite Buffer
Redo Log
Undo Log
参考:
标签:Buffer,缓冲,链表,索引,InnoDB,内存,change,结构 From: https://www.cnblogs.com/larry1024/p/17628908.html