一.内存对齐
内存对齐的好处
-
某些情况下,可能需要多次访存,比如64位CPU,每次最多可获取8B,现在有一个8B长的变量,如果没有对齐,可能前6B存在前一个地址,后2B存在另一个地址,两次才能取出,如果对齐,那就只需要访存一次
-
可能会破坏访存的原子性,常见的就是
long long并发时的错误
-
某些ARM CPU不支持未对齐的内存访问(我没碰到过)
-
可能会造成性能问题
- 在 ARM v6/7 上未对齐的访问通常需要许多额外的周期才能完成
- 在现代的 x86 处理器上,未对其的内存访问没有明显的性能损失。在这篇对 Intel SandyBridge 架构(酷睿 2xxx 系列,奔腾 G6xx 系列)的测试文章里提到
there is noperformance penalty for reading or writing misaligned memory operands - 不仅如此,在这篇文章的测试中,在一些 workload 下,未对齐的内存访问甚至比对齐的访问更快!
二.平台内存对齐
64位平台,变量的地址最好是8B对齐的
三.结构体对齐
1.对齐规则
- 数据类型的对齐:结构体中的成员变量按照自身的大小进行对齐。例如,
int按照 4 字节对齐,double按照 8 字节对齐,char按照 1 字节对齐。 - 对齐边界:结构体的起始地址必须是其最大成员的对齐边界的倍数。换句话说,
结构体的大小必须是最大成员大小的整数倍。 - 填充字节:为了满足对齐要求,编译器可能会插入填充字节,使得成员变量正确对齐。
以下面几个结构体为例
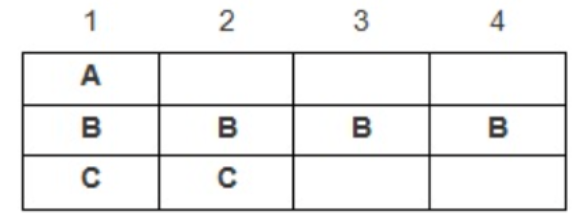
案例1
struct test{
char a;
int b;
short c;
}test1;
这个结构体中,最长的变量长度为4B
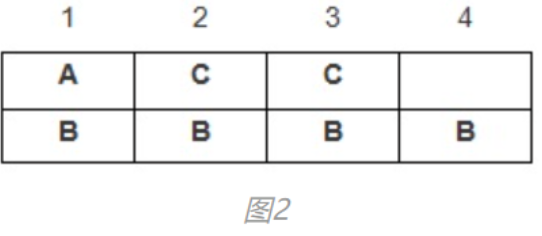
案例2
struct test{
char A;
short C;
int B;
}test2;
为什么需要填充?
填充才能保证内存对齐
为什么结构体的大小必须是最大成员大小的整数倍?
在这篇回答中,找到了一个可能的原因,以这个结构体为例
struct st{
int32_t a;
int8_t b;
};
struct st arr[N];
如果不对齐为整数倍,那么占用5B,如果对齐,那就是8B,但是如果不填充,当对数组访问时,arr[1].a就会有4B放在arr[0].b中,导致cross line,从而对齐失败,
所以第二条实际上还是为了内存对齐,如果没有第二条,还是存在未对齐的隐患。
四.保证内存对齐的简单算法
#include <stddef.h>
#include <stdlib.h>
int posix_memalign(void **memptr, size_t alignment, size_t size) {
if (alignment % sizeof(void*) != 0 || (alignment & (alignment - 1)) != 0) {
// 对齐要求必须是void*大小的倍数,并且是2的幂次
return EINVAL; // 参数错误
}
void* ptr = malloc(size + alignment - 1);
if (ptr == NULL) {
return ENOMEM; // 内存分配失败
}
uintptr_t addr = (uintptr_t)ptr;
uintptr_t aligned_addr = (addr + alignment - 1) & ~(alignment - 1);
// 为了保存原始指针地址,需要将指针地址存储在指针指针(memptr)指向的位置
*(void**)memptr = (void*)aligned_addr;
return 0; // 成功
}
-
为什么是void*的倍数
void*的大小一般是机器字长,所以含义就是首先必须和机器字长对齐 -
如何检测出是2的幂次
2的幂次数有个特性,那就是只有最高位是1,剩下的都是0,比如8,
而减去1后,又变成最高位是0,剩下都是1
8: 1000 8-1: 0111此时求与,如果结果是0,那就是有2的幂次,否则就不是,
这是只有2的幂次具有的性质
-
如何保证对齐到
alignment(addr + alignment - 1) & ~(alignment - 1);