进程
进程的提出是为什么?
因为程序,计算机中运行程序是并不止一个的,为了如何方便地管理这些程序,操作系统提出了进程这个抽象的概念,相当于每一个进程都有一个运行中的程序
进程能够同时执行是为什么?
CPU的调度,也就是操作系统提出的上下文切换,通过保存和恢复进程在运行中的状态,使进程可以暂停切换,从而实现进程对CPU资源的占用
进程之间为什么是安全隔离的?
因为进程所运行的实际物理内存是隔离开的,因为运用到了独立的虚拟地址
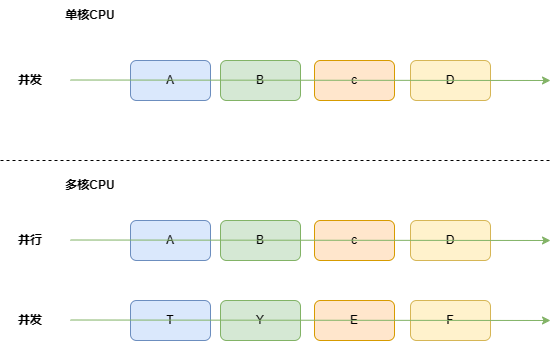
1.1并发与并行
-
并发指的其实是伪并发,因为同一时刻CPU只能执行某一个进程,但在宏观的时间内,可能因为CPU处理程序的速度非常快,导致在极短时间内运行了许多个进程
-
而并行是多核CPU才会出现的情况,每一个CPU在同一时刻都在运行着进程,尽管这些进程之间可能并不具备关系,但在人类的视野中,这些进程就是一起运行的.
1.2进程的状态
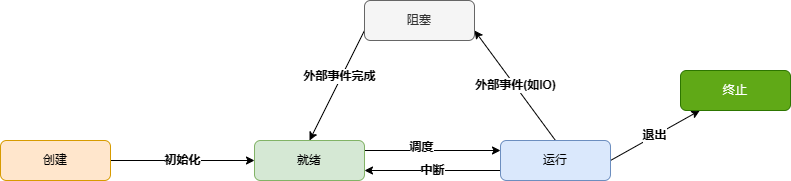
现代计算机并发与并行一般是都会发生的,但是这样也无法避免进程之间的切换,所以进程处了运行的状态,还具备其他状态
-
创建(Created):当进程被创建时,它处于创建状态。在这个阶段,操作系统会为进程分配必要的资源,并进行初始化设置。
-
就绪(Ready):在就绪状态下,进程已经准备好执行,但还没有被调度器选中执行。它等待分配CPU时间片以便执行。
-
运行(Running):当操作系统将CPU时间片分配给进程时,进程进入运行状态。在运行状态下,进程正在执行其指令。
-
阻塞(Blocked):当进程在执行过程中遇到某些阻塞事件(例如等待用户输入、等待磁盘读写完成等)时,进程会进入阻塞状态。在阻塞状态下,进程无法继续执行,直到阻塞事件完成。
-
终止(Terminated):进程完成其执行或被操作系统终止时,进程进入终止状态。在这个状态下,进程释放占用的资源,并等待操作系统从进程表中删除。
阻塞的进程是否会继续占用页?
- 答案是:并不会,运行的进程一定放在物理内存里的页中,如果阻塞还将程序放入内存,不仅降低了内存的利用率,也很不符合阻塞进程的性质,所以意味着会换出,将阻塞的进程状态挂起或者切换为就绪态,将就绪的状态挂起
1.3进程控制块(PCB)
-
进程控制块是用来保存进程状态的数据结构:
#include <unistd.h> #include <sys/types.h> struct pcb { pid_t pid; // 进程ID uid_t uid; // 用户ID gid_t gid; // 组ID unsigned long state; // 进程状态 unsigned long priority; // 进程优先级 // 其他进程相关的信息和字段 // ... };在windows系统中可以用任务管理器查看相关进程的信息,在Linux系统中,可以使用
pc,例如:ps aux:显示所有用户的所有进程信息。ps -ef:显示所有进程的详细信息。ps -p <PID>:显示指定PID的进程信息。
这意味这这种数据结构随着进程的消失而销毁,
-
每个进程的PCB之间没有被组织起来吗?
struct pcb* next; // 指向下一个PCB的指针程序的阻塞状态和就绪状态,以及运行状态是我们所需要关心的,于是每个PCB就会被关联起来,形成链表,就绪状态的进程,PCB就会被关联起来,阻塞状态的PCB也会被关联起来,而某些运行时的PCB也会被关联起来,这个要根据操作系统而定.

2.进程的创建:fork
Linux的进程创建方式在早期是通过调用fork接口,从而让已有的进程分裂
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
fork接口不带任何参数,而返回值是当前进程的PID,所以当每次调用时,都会为该进程创建一个一模一样的新进程,所以这就是分裂的由来,由父进程调用fork函数创建一个新进程,而这个新进程就是子进程.
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t pid;
// 创建子进程
pid = fork();
if (pid < 0) {
// fork() 出错
fprintf(stderr, "Fork failed\n");
return 1;
} else if (pid == 0) {
// 子进程代码
printf("This is the child process\n");
// 子进程执行其他操作...
} else {
// 父进程代码
printf("This is the parent process\n");
// 父进程执行其他操作...
}
return 0;
}
- 父进程执行
fork()调用时,操作系统会创建一个新的子进程,并将子进程的PID返回给父进程。 - 父进程中,
fork()返回的值大于0,表示当前进程是父进程。 - 子进程中,
fork()返回的值为0,表示当前进程是子进程。
至于fork的底层源码实现,个人能力有限,可以参考Linux0.11源码解析.
由于子进程在fork的过程中获取了完全相同的拷贝,例如,寄存器和内存的一些信息,PCB的一些内容等,因此两个进程都会去使用read操作读取文件内容
2.1什么是文件描述符
先来看这段代码:
#include <stdio.h>
int main() {
FILE *file;
file = fopen("example.txt", "r");
if (file == NULL) {
printf("Failed to open the file.\n");
return 1;
}
// 文件已成功打开,进行读取或写入操作
fclose(file); // 关闭文件
return 0;
}
程序在调用fopen时,会返回一个索引(非负的整数),意味着每一个文件都对应着不同的文件描述符,但这并不意味着多个描述符不能指向一个文件,例如复制的文件,dup,在某些特定的场景,文件描述符可以发挥出很多作用,文件描述符同样也存在着一张表去管理,通过文件描述符,操作系统可以定位到所需要的资源.
#include <unistd.h>
#include <fcntl.h>
int main() {
int fd1 = open("file.txt", O_RDONLY);
if (fd1 < 0) {
// 处理文件打开失败的情况
return 1;
}
int fd2 = dup(fd1);
// 现在fd1和fd2都指向同一个打开的文件
// 进行文件读取等操作...
close(fd1);
close(fd2);
return 0;
}
-
因此,可以将文件描述符表划分为系统级和进程级以及文件系统的(i-node)级别的
-
回过头看,文件描述符和fork之间有什么关系:
子进程会继承父进程的文件描述符,因为是拷贝的缘故,他们各自进程的文件描述符表是独立的副本,而不等同于一个文件
-
-
文件描述符里存在什么:
前面仅仅是简单的说了一下,可能部分人就认为是文件的索引了,例如某个程序可能需要调用example.txt文件,那这个文件描述符就是用来描述这些文件的,所以仅仅通过索引并不能完全实现
- 文件描述符值:每个文件描述符在表中有一个唯一的值,通常是一个非负整数。
- 文件指针:文件指针指向打开文件的数据结构或相关信息,用于进行文件操作。这可以是文件的内存映射、文件控制块或其他形式的结构体。
- 文件状态标志:记录文件的状态信息,如是否可读、可写、是否已到达文件末尾等。
- 文件偏移量:表示当前文件读写位置的偏移量。读写操作将从该位置开始,同时会更新偏移量的值。
- 文件打开模式和权限:记录了打开文件时指定的访问模式和权限。
-
因此子进程和父进程存在对文件冲突的原因,面对这个问题,Linux系统在对文件进行
read操作时会进行加锁,同样,因为偏移量相同,如果读到同一文件,他们会修改相应的偏移量.
3.进程的执行:exec
当子进程由父进程创建完成之后,因为子进程需要去执行自己的任务,为了实现这一目标,Linux提供了exec接口,exce大概有7种实现方式,我们仅拿一种举例:
#include <unistd.h>
int execve(const char *pathname,char *const argv[],char *const envp[]);
-
第一个参数代表的含义就是程序的路径,比如某个exe文件在某个路径下,第二个参数是这个进程所需要的参数(什么参数?)
- char *const argv[]: 文件描述符,优先级及资源共享等.
-
第三个参数是为进程定义的环境变量.
现在让我们看一下C语言中main函数
#include <stdio.h>
int main(int argc, char *argv[]) {
printf("Number of command-line arguments: %d\n", argc);
printf("Command-line arguments:\n");
for (int i = 0; i < argc; i++) {
printf("argv[%d]: %s\n", i, argv[i]);
}
return 0;
}
如果将上述exe文件命名为example:
./example arg1 arg2 arg3
则输出将为:
Number of command-line arguments: 4
Command-line arguments:
argv[0]: ./example
argv[1]: arg1
argv[2]: arg2
argv[3]: arg3
- 一般情况下与编译器也可能有关,就例如我拿自身电脑所示,放在了项目的bin目录下的debug目录下的可执行文件.因此argv[0]就会输出..\bin\Debug\name可执行文件
也就是说通过主函数中传递的参数其实就可以确定磁盘中的位置.
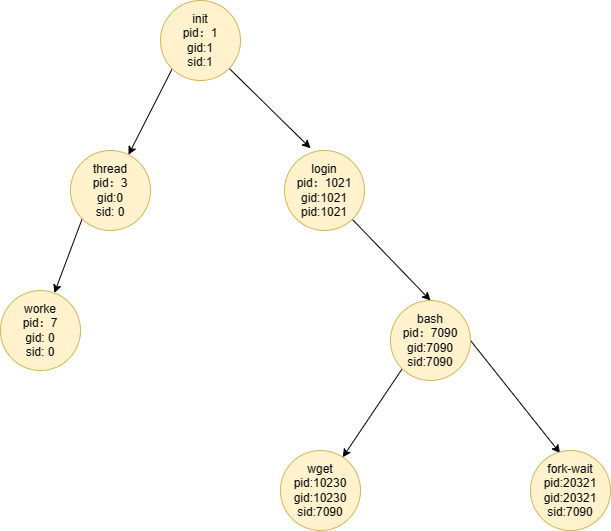
4.进程树
在Linux中我们得知子进程的创建是通过父进程创建的,那我们的父进程是通过谁创建的呢?或者说操作系统的第一个进程是怎么创建的

处于根部的就是init进程,所有的进程都是通过他间接或者直接创造出来的
- 进程间的监控:
wait
wait操作其实本质上是用来对子进程启监控作用,具体的执行步骤是这样的,父进程调用wait操作,暂停执行,等待子进程终止,子进程终止之后,父进程继续运行,并获得子进程的退出状态.
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
例如:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main() {
pid_t pid = fork();
if (pid < 0) {
// Fork失败
fprintf(stderr, "Fork failed\n");
exit(1);
} else if (pid == 0) {
// 子进程执行的代码
printf("Child process executing\n");
exit(0);
} else {
// 父进程等待子进程终止
int status;
wait(&status);
if (WIFEXITED(status)) {
// 子进程正常终止
int exit_status = WEXITSTATUS(status);
printf("Child process exited with status %d\n", exit_status);
}
}
return 0;
}
- 父进程使用
wait函数等待子进程的终止,然后通过WEXITSTATUS宏获取子进程的退出状态。
至于这个宏WEXITSTATUS我是这么理解的wait exit status 也就是等待退出的状态,而他的定义如下:
#include <sys/wait.h>
int WEXITSTATUS(int status);
-
这时候我们来看
exit函数,通常情况exit(0)表示正常退出,而其他值则表示非正常退出,通常情况下我们的C语言程序不会去书写exit(0),而是使用return 0,但这两者在主函数中作用一致,都是用来表示进程正常退出,但在函数中,return仅作返回值返回,而不做进程返回的终止值,同样,这个exit(?)返回的内容也决定了进程返回的不同情况是因为什么原因,因此,我们大概就明白了一个程序的开始运行和结束了.-
言归正传,
wait函数是阻塞的,也就是说,如果没有子进程终止,父进程将一直等待。如果不希望阻塞,可以使用waitpid函数,并指定WNOHANG标志,以非阻塞方式等待子进程的终止。-
因此
wait函数其实可以处理僵尸进程什么是僵尸进程?
-
-
当子进程执行完毕后,它的退出状态(exit status)需要被传递给父进程。为了实现这个机制,操作系统会将子进程的进程控制块(PCB)保留在系统中,同时将子进程的状态设置为"僵尸"(Zombie)状态。
这也就意味着子进程所占用的资源一直保留着,等待着父进程的调用.
5.进程组
是一组相关联的进程的集合。在一个进程组中,每个进程都有一个唯一的进程组ID(PGID)。
通常来说父进程和子进程都是一个进程组,通常来说如果子进程想脱离进程组,只需要去修改PCB中的tgid字段即可,调用setpgid加入一个新的进程组或者创建一个新进程组.
- 会话:进程组的集合,会话将进程组分为前台进组组和后台进程组,因此也有了前台进程和后台进程,这样可以更好地组织和管理进程,例如Windows中的控制终端(cmd),即需要与用户交流的前台进程,同样在Linux中Shell也一样,也有一些后台进程并不需要用户关心,比如驱动程序操作系统内核级程序早在后台启动了,因此也被分为后台级程序.
因此每一个进程都包含进程ID,进程组ID,和会话ID,用来更好地管理进程.