随着时间的积累,应用的使用用户不断增加,数据规模也越来越大,往往数据库查询操作会成为影响用户使用体验的瓶颈,此时使用缓存往往是解决这一问题非常好的手段之一。Spring 3开始提供了强大的基于注解的缓存支持,可以通过注解配置方式低侵入的给原有Spring应用增加缓存功能,提高数据访问性能。
在Spring Boot中对于缓存的支持,提供了一系列的自动化配置,使我们可以非常方便的使用缓存。下面我们通过一个简单的例子来展示,我们是如何给一个既有应用增加缓存功能的。
快速入门
下面我们将使用使用Spring Data JPA访问MySQL一文的案例为基础。这个案例中包含了使用Spring Data JPA访问User数据的操作,利用这个基础,我们为其添加缓存,来减少对数据库的IO,以达到访问加速的作用。如果您还不熟悉如何实现对MySQL的读写操作,那么建议先阅读前文,完成这个基础案例的编写。
先简单回顾下这个案例的基础内容:
User实体的定义
@Entity |
User实体的数据访问实现
public interface UserRepository extends JpaRepository<User, Long> {
|
为了更好的理解缓存,我们先对该工程做一些简单的改造。
application.properties文件中新增spring.jpa.show-sql=true,开启hibernate对sql语句的打印。如果是1.x版本,使用spring.jpa.properties.hibernate.show_sql=true参数。- 修改单元测试类,插入User表一条用户名为AAA,年龄为10的数据。并通过findByName函数完成两次查询,具体代码如下:
@RunWith(SpringRunner.class) |
在没有加入缓存之前,我们可以先执行一下这个案例,可以看到如下的日志:
Hibernate: select user0_.id as id1_0_, user0_.age as age2_0_, user0_.name as name3_0_ from user user0_ where user0_.name=? |
两次findByName查询都执行了两次SQL,都是对MySQL数据库的查询。
引入缓存
第一步:在pom.xml中引入cache依赖,添加如下内容:
<dependency> |
第二步:在Spring Boot主类中增加@EnableCaching注解开启缓存功能,如下:
@EnableCaching |
第三步:在数据访问接口中,增加缓存配置注解,如:
@CacheConfig(cacheNames = "users") |
第四步:再来执行以下单元测试,可以在控制台中输出了下面的内容
Hibernate: insert into user (age, name, id) values (?, ?, ?) |
到这里,我们可以看到,在调用第二次findByName函数时,没有再执行select语句,也就直接减少了一次数据库的读取操作。
为了可以更好的观察,缓存的存储,我们可以在单元测试中注入CacheManager。
@Autowired |
使用debug模式运行单元测试,观察CacheManager中的缓存集users以及其中的User对象的缓存加深理解。
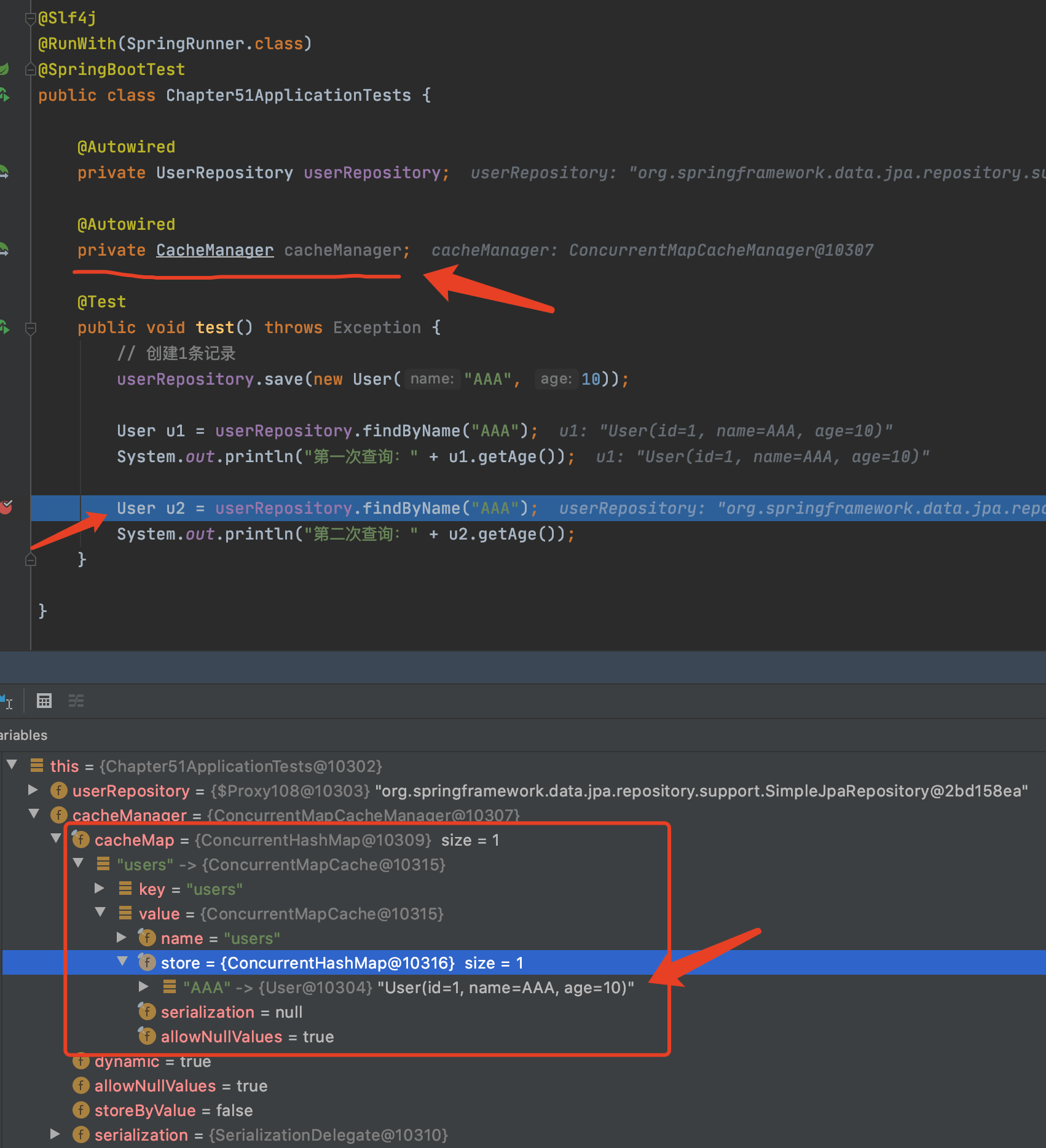
可以看到,在第一次调用findByName函数之后,CacheManager将这个查询结果保存了下来,所以在第二次访问的时候,就能匹配上而不需要再访问数据库了。
Cache配置注解详解
回过头来我们再来看这里使用到的两个注解分别作了什么事情:
@CacheConfig:主要用于配置该类中会用到的一些共用的缓存配置。在这里@CacheConfig(cacheNames = "users"):配置了该数据访问对象中返回的内容将存储于名为users的缓存对象中,我们也可以不使用该注解,直接通过@Cacheable自己配置缓存集的名字来定义。@Cacheable:配置了findByName函数的返回值将被加入缓存。同时在查询时,会先从缓存中获取,若不存在才再发起对数据库的访问。该注解主要有下面几个参数:value、cacheNames:两个等同的参数(cacheNames为Spring 4新增,作为value的别名),用于指定缓存存储的集合名。由于Spring 4中新增了@CacheConfig,因此在Spring 3中原本必须有的value属性,也成为非必需项了key:缓存对象存储在Map集合中的key值,非必需,缺省按照函数的所有参数组合作为key值,若自己配置需使用SpEL表达式,比如:@Cacheable(key = "#p0"):使用函数第一个参数作为缓存的key值,更多关于SpEL表达式的详细内容可参考官方文档condition:缓存对象的条件,非必需,也需使用SpEL表达式,只有满足表达式条件的内容才会被缓存,比如:@Cacheable(key = "#p0", condition = "#p0.length() < 3"),表示只有当第一个参数的长度小于3的时候才会被缓存,若做此配置上面的AAA用户就不会被缓存,读者可自行实验尝试。unless:另外一个缓存条件参数,非必需,需使用SpEL表达式。它不同于condition参数的地方在于它的判断时机,该条件是在函数被调用之后才做判断的,所以它可以通过对result进行判断。keyGenerator:用于指定key生成器,非必需。若需要指定一个自定义的key生成器,我们需要去实现org.springframework.cache.interceptor.KeyGenerator接口,并使用该参数来指定。需要注意的是:该参数与key是互斥的cacheManager:用于指定使用哪个缓存管理器,非必需。只有当有多个时才需要使用cacheResolver:用于指定使用那个缓存解析器,非必需。需通过org.springframework.cache.interceptor.CacheResolver接口来实现自己的缓存解析器,并用该参数指定。
除了这里用到的两个注解之外,还有下面几个核心注解:
@CachePut:配置于函数上,能够根据参数定义条件来进行缓存,它与@Cacheable不同的是,它每次都会真是调用函数,所以主要用于数据新增和修改操作上。它的参数与@Cacheable类似,具体功能可参考上面对@Cacheable参数的解析@CacheEvict:配置于函数上,通常用在删除方法上,用来从缓存中移除相应数据。除了同@Cacheable一样的参数之外,它还有下面两个参数:allEntries:非必需,默认为false。当为true时,会移除所有数据beforeInvocation:非必需,默认为false,会在调用方法之后移除数据。当为true时,会在调用方法之前移除数据。