目录
1 查询操作
1.1 定义
MongoDB 查询文档使用 find() 方法
find() 方法以非结构化的方式来显示所有文档。
MongoDB 查询数据的语法格式如下:
db.collection.find(query, projection)
相关参数:
query:可选,使用查询操作符指定查询条件projection:可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)
若不指定projection,则默认返回所有键,指定projection格式如下(0:不显示,1:显示),有两种模式,但是两种模式不可混用db.collection.find(query, {title: 1, by: 1})inclusion模式 指定返回的键,不返回其他键db.collection.find(query, {title: 0, by: 0})exclusion模式 指定不返回的键,返回其他键
比如:_id键默认返回,需要主动指定_id:0才会隐藏
1.2 查询操作
1.2.1 pretty
如果需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
>db.col.find().pretty()
pretty() 方法以格式化的方式来显示所有文档。
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
1.2.2 MongoDB 与 RDBMS Where 语句比较
如果熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {<key>:<value>} |
db.col.find({"by":"test"}).pretty() | where by = 'test' |
| 小于 | {<key>:{$lt:<value>}} |
db.col.find({"likes":{$lt:50}}).pretty() | where likes < 50 |
| 小于或等于 | {<key>:{$lte:<value>}} |
db.col.find({"likes":{$lte:50}}).pretty() | where likes <= 50 |
| 大于 | {<key>:{$gt:<value>}} |
db.col.find({"likes":{$gt:50}}).pretty() | where likes > 50 |
| 大于或等于 | {<key>:{$gte:<value>}} |
db.col.find({"likes":{$gte:50}}).pretty() | where likes >= 50 |
| 不等于 | {<key>:{$ne:<value>}} |
db.col.find({"likes":{$ne:50}}).pretty() | where likes != 50 |
1.2.3 MongoDB AND OR条件
1.2.3.1 AND条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件
语法格式如下:
>db.col.find({key1:value1, key2:value2}).pretty()
以下实例通过 by 和 title 键来查询数据
> db.col.find({"by":"test", "title":"MongoDB 教程"}).pretty()
以上实例中类似于 WHERE 语句:WHERE by='test' AND title='MongoDB 教程'
1.2.3.2 OR 条件
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
>db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
以下实例中,我们演示了查询键 by 值为 test 或键 title 值为 MongoDB 教程 的文档。
>db.col.find({$or:[{"by":"test"},{"title": "MongoDB 教程"}]}).pretty()
1.2.3.3 AND 和 OR 联合使用
以下实例演示了 AND 和 OR 联合使用,类似常规 SQL 语句为:where likes>50 AND (by = 'test' OR title = 'MongoDB 教程')
>db.col.find({"likes": {$gt:50}, $or: [{"by": "test"},{"title": "MongoDB 教程"}]}).pretty()
1.2.4 $type
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
MongoDB中可以使用的类型如下表所示:
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃。 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
如果想获取 合中 为 String 的数据,可以使用以下命令:
db.col.find({"title" : {$type : 2}})
或 'string'必须以字符串形式
db.col.find({"title" : {$type : 'string'}})
1.2.5 分页排序
1.2.5.1 分页limit
如果需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
limit()方法基本语法如下所示:
>db.COLLECTION_NAME.find().limit(NUMBER)
注意:如果没有指定limit()方法中的参数则显示集合中的所有数据。
1.2.5.2 分页skip
我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
skip() 方法脚本语法格式如下:
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
以下实例只会显示第二条文档数据
>db.col.find({},{"title":1,_id:0}).limit(1).skip(1)
{ "title" : "Java 教程" }
注意:skip()方法默认参数为 0 。
limit(n).skip(n)连用相当于关系型数据库中的分页操作
limit(n) 是用来规定显示的条数,而skip(n) 是用来在符合条件的记录中从第一个记录跳过的条数,这两个函数可以交换使用。
比如:find({},{age:1,_id:0}).limit(2).skip(1),在符合条件的文档中,要显示两条文档,显示的位置从跳过第一条记录开始
但是skip和limit方法只适合小数据量分页,如果是百万级效率就会非常低,因为skip方法是一条条数据数过去的,建议使用where_limit过滤处理
这里我们假设查询第100001条数据,这条数据的Amount值是:2399927,我们来写两条语句分别如下:
b.test.sort({"amount":1}).skip(100000).limit(10) 耗时183ms
db.test.find({amount:{$gt:2399927}}).sort({"amount":1}).limit(10) 耗时53ms
1.2.5.3 排序sort
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式
1为升序排列-1是用于降序排列
sort()方法基本语法如下所示:
>db.COLLECTION_NAME.find().sort({KEY:1})
注意:当skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的limit()
1.3 MapReduce
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用。
1.3.1 语法
以下是MapReduce的基本语法:
db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number
}
)
使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将 key 与 value 传递给 Reduce 函数进行处理。
Map 函数必须调用 emit(key, value) 返回键值对。
参数说明:
map:映射函数 (生成键值对序列,作为reduce函数参数)。reduce:统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。out:统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。query:一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)sort和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制limit发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
以下实例在集合 orders 中查找 status:"A" 的数据,并根据 cust_id 来分组,并计算 amount 的总和。
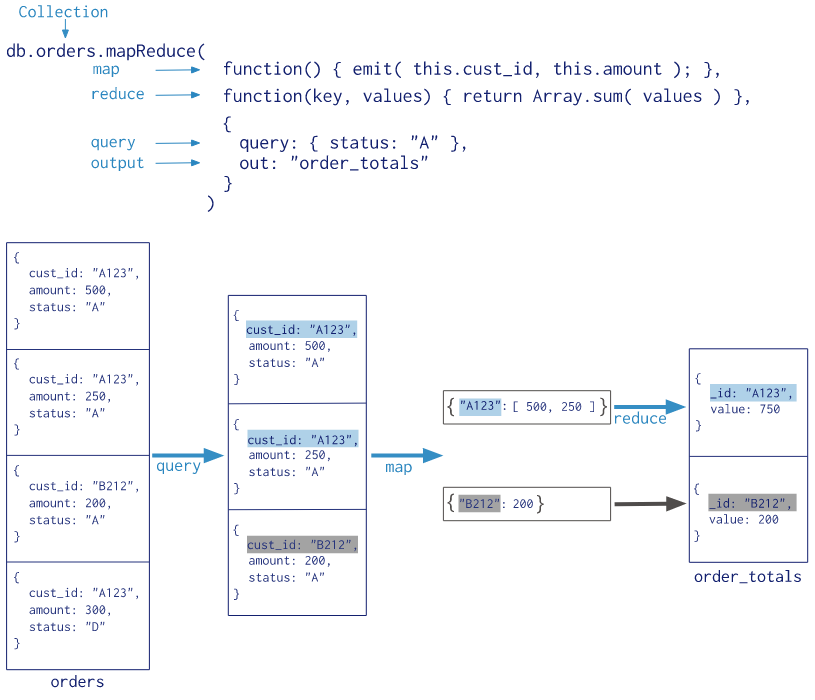
1.3.2 与分组聚合对比
与Aggregate中引用集合中字段区别:
- 在分组聚合
Aggregate函数中,引用原字段用$原字段 - 在
MapReduce中引用原来字段用this,比如:this.age
1.3.3 使用 MapReduce
1.3.3.1 案例一
考虑以下文档结构存储用户的文章,文档存储了用户的 user_name 和文章的 status 字段:
>db.posts.insert([
{
"post_text": "技术文档",
"user_name": "mark",
"status":"active"
},
{
"post_text": "技术文档",
"user_name": "mark",
"status":"active"
},
{
"post_text": "技术文档",
"user_name": "mark",
"status":"active"
},
{
"post_text": "技术文档",
"user_name": "mark",
"status":"active"
},
{
"post_text": "技术文档",
"user_name": "mark",
"status":"disabled"
},
{
"post_text": "技术文档",
"user_name": "test",
"status":"disabled"
},
{
"post_text": "技术文档",
"user_name": "test",
"status":"disabled"
},
{
"post_text": "技术文档",
"user_name": "test",
"status":"active"
}
]);
现在,我们将在 posts 集合中使用 mapReduce 函数来选取已发布的文章(status:"active"),并通过user_name分组,计算每个用户的文章数:
db.posts.mapReduce(
function() { emit(this.user_name,1); },
function(key, values) {return Array.sum(values)},
{
query:{status:"active"},
out:"post_total"
}
)
输出结果为:
{
"result" : "post_total",
"ok" : 1
}
查看输出结果:
db.post_total.find();
{
"_id": "test",
"value": 1
}
{
"_id": "mark",
"value": 4
}
具体参数说明:
result:储存结果的collection的名字,这是个临时集合,MapReduce的连接关闭后自动就被删除了。ok:是否成功,成功为1err:如果失败,这里可以有失败原因
1.3.3.2 案例二
准备脚本
db.user.insertMany([
{"name" : "鲁迅","book" : "呐喊","price" : 38.0,"publisher" : "人民文学出版社"},
{"name" : "曹雪芹","book" : "红楼梦","price" : 22.0,"publisher" : "人民文学出版社"},
{"name" : "钱钟书","book" : "宋诗选注","price" : 99.0,"publisher" : "人民文学出版社"},
{"name" : "钱钟书","book" : "谈艺录","price" : 66.0,"publisher" : "三联书店"},
{"name" : "鲁迅","book" : "彷徨","price" : 55.0,"publisher" : "花城出版社"}
]);
查询每个作者的总计价格
db.user.mapReduce(
function(){emit(this.name,this.price)},
function(key,value){return Array.sum(value)},
{out:"totalPrice"});
查看处理结果
db.totalPrice.find();
{
"_id": "鲁迅",
"value": 22
}
// 2
{
"_id": "钱钟书",
"value": 93
}
// 3
{
"_id": "曹雪芹",
"value": 165
}
或者使用引用的方法(查询每个价格在 40以上的书,并用逗号分隔)
所有函数写在一起
db.user.mapReduce(
function(){emit(this.name,this.book)},
function(key,value){return value.join(',')},
{query:{price:{$gt:40}},out:"books"})
db.books.find();
单独写,然后引用
var map=function(){emit(this.name,this.book)}
var reduce=function(key,value){return value.join(',')}
var options={query:{price:{$gt:40}},out:"books"}
db.user.mapReduce(map,reduce,options);
1.4 runCommand
1.4.1 语法
db.runCommand(
{
mapReduce: <collection>,
map: <function>,
reduce: <function>,
finalize: <function>,
out: <output>,
query: <document>,
sort: <document>,
limit: <number>,
scope: <document>,
jsMode: <boolean>,
verbose: <boolean>,
bypassDocumentValidation: <boolean>,
collation: <document>
}
)
参数含义:
mapReduce:表示要操作的集合map:map函数reduce:reduce函数finalize:最终处理函数out:输出的集合query:对结果进行过滤sort:对结果排序limit:返回的结果数scope:设置参数值,在这里设置的值在map,reduce,finalize函数中可见jsMode:是否将地图执行的中间数据由javascript对象转换成BSON对象,替换为falseverbose:是否显示详细的时间统计信息bypassDocumentValidation:是否绕过文档验证collation:其他一些校对
1.4.2 案例
如下操作,表示执行MapReduce操作重新统计的集合限制返回条数,限制返回条数之后再进行统计操作,如下:
var map=function(){emit(this.name,this.book)}
var reduce=function(key,value){return value.join(',')}
db.runCommand({mapreduce:'user',map,reduce,out:"books",limit:4,verbose:true})
db.books.find()
执行结果:
{ "_id" : "鲁迅", "value" : "呐喊" }
{ "_id" : "曹雪芹", "value" : "红楼梦" }
{ "_id" : "钱钟书", "value" : "谈艺录,宋诗选注" }
这里进行对比发现,因为limit的原因,鲁迅的第一本书不见了
finalize操作表示最终处理函数,如下:f1函数的第一个参数键表示emit中的第一个参数,第二个参数表示reduce的执行结果,我们可以在f1中对这个结果进行再处理
var f1 = function(key,reduceValue){var obj={};obj.author=key;obj.books=reduceValue; return obj}
var map=function(){emit(this.name,this.book)}
var reduce=function(key,value){return value.join(',')}
db.runCommand({mapreduce:'user',map,reduce,out:"books",finalize:f1})
db.books.find()
执行结果:
{ "_id" : "鲁迅", "value" : { "author" : "鲁迅", "books" : "彷徨,呐喊" } }
{ "_id" : "曹雪芹", "value" : { "author" : "曹雪芹", "books" : "红楼梦" } }
{ "_id" : "钱钟书", "value" : { "author" : "钱钟书", "books" : "谈艺录,宋诗选注" } }