数据强一致
主从数据一致性检查
计算节点提供数据节点中的主从存储节点一致性校验的功能。需要校验的主备存储节点属于同一个数据节点。
主从数据一致性检查,可校验主库与从库各个表的表结构是否相同,表数据是否一致,主从是否延迟。当表数据在主库与从库间仅有少量的数据不一致时,主从数据一致性检查可定位到不一致的数据行主键值。
登录计算节点的管理端(3325端口),执行show @@masterslaveconsistency命令,即可查看表在主库和备库上是否一致:
mysql> show @@masterslaveconsistency;
+------+------------+-------+--------+-----------------------------------------------------------------------------------------------------+
| db | table | dn | result | info |
+------+------------+-------+--------+-----------------------------------------------------------------------------------------------------+
| DB_T | FB_STUDENT | dn_04 | NO | 存在数据不一致, 因为 存储节点: 5, 表: FB_STUDENT, MySQL错误: Table 'db252.fb_student' doesn't exist |
| DB_A | SP | dn_04 | NO | 表: SP在节点: 4存在数据不一致,列: ID, 分布区间为: 0-17;, 并且不一致行唯一键为: (ID) :(2),(1) |
| DB_T | JOIN_Z | | YES | |
+------+------------+-------+--------+-----------------------------------------------------------------------------------------------------+
3 row in set (0.07 sec)
结果中显示逻辑库DB_T中的JOIN_Z表,在所有节点的主备存储节点之间,数据是一致的。表结构如下:
- db:逻辑库名称。
- table:表名称。
- dn:数据节点名称;当表在主备存储节点不一致时,此列会显示数据节点名称;
- result:校验结果为YES,表示该表在主备存储节点之间是一致的;为NO,表示该表在主备存储节点之间不一致,同时会在info输出不一致的信息;UNKNOWN,表示未知错误,可能存在表结构不一致的情况,主从复制中断都可能出现UNKNOWN。
- info:当主从数据一致时,无信息输出;当主从数据不一致时,会有以下几种信息:
| 名称 | 信息 |
|---|---|
| 表的大量数据不一致 | Table: ... in datanode: ... exist a large amount of data inconsistency |
| 表的部分数据不一致 | Table : ... in datanode: ... exist data inconsistency where ID in range:...;and inconsistent rows' primary key (...) |
| 从库表不存在 | exist data inconsistency, because DS: ... Table '...' doesn't exist |
| 表索引不存在 | DN: ... not exsit index of table:... |
| 主从故障检测(例如从机Slave_SQL_Running: NO状态) | DN: ... ERROR! Check your replication. |
| 主从延迟超过10S | DN:... delay too much,can't check master-slave data consistency |
| 延迟超过2S | Replication latency is more than 2s, Master-Slave consistency detection result may be incorrect or cannot be detected in datanode: |
全局自增序列
全局自增序列,是指表的AUTO_INCREMENT列在整个系统中的各个节点间有序自增。计算节点提供全局AUTO_INCREMENT的支持,当表中包含AUTO_INCREMENT列,并且在server.xml文件中,将参数autoIncrement设置为非0(1或2))时,即可以像使用MySQL的AUTO_INCRMENT一样使用计算节点的全局AUTO_INCREMENT。配置示例如:
<property name="autoIncrement">1</property>
参数设置为0
若将参数autoIncrement设置为0,则自增字段在存储节点内维护;在表类型为分片表时,表现较明显,可能存在同一分片表,不同存储节点间自增序列重复的情况。
例如:customer为auto分片表,分片字段为id,且name定义为自增序列。则name的自增特性由各个存储节点控制:
mysql> create table customer(id int ,name int auto_increment primary key);
mysql> insert into customer values (1,null),(2,null),(3,null),(4,null);
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates:0 Warnings: 0
mysql> select * from customer;
+----+------+----- +
| id | name | DNID |
+----+------+----- +
| 4 | 1 | 1001 |
| 2 | 1 | 1006 |
| 3 | 1 | 1004 |
| 1 | 1 | 1008 |
+----+------+----- +
4 rows in set (0.00 sec)
参数设置为1
若将参数autoIncrement设置为1,则由计算节点接管所有表的自增,可以保证全局自增。
<property name="autoIncrement">1</property>
例如:customer为auto分片表,分片字段为id,且name定义为自增序列。则name的自增特性由计算节点控制,可实现全局自增:
mysql> create table customer(id int ,name int auto_increment primary key);
mysql> insert into customer values (1,null),(2,null),(3,null),(4,null);
Query OK, 4 rows affected (0.01 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * From customer order by id;
+----+------+------+
| id | name | DNID |
+----+------+------+
| 1 | 1 | 1008 |
| 2 | 2 | 1006 |
| 3 | 3 | 1004 |
| 4 | 4 | 1001 |
+----+------+------+
4 rows in set (0.00 sec)
若将参数autoIncrement设置为1,自增字段类型必须为INT或BIGINT,否则建表提示warning:
mysql> create table table_test(id tinyint auto_increment primary key);
Query OK, 0 rows affected, 1 warning (0.05 sec)
Warning (Code 10212): auto_increment column must be bigint or int
自增序列1模式可保证全局唯一且严格正向增长,但不保证自增连续性。
参数设置为2
若将参数autoIncrement设置为2,则由计算节点接管所有表的自增。在此模式下,当计算节点模式为集群模式且表中包含自增序列时,仅保证自增序列全局唯一与长期看相对递增,但不保证自增的连续性(短时间内不同节点间自增值会交错)。计算节点智能控制自增特性,进而帮助提升集群模式下计算节点的性能。若计算节点模式为高可用或单节点模式,则设置为2与设置为1的结果相同。
例如:若现有Primary计算节点A,Secondary计算节点B和Secondary计算节点C,设置批次大小(prefetchBatchInit)初始值为100,则计算节点A的自增序列预取区间为[1,100],计算节点B的预取区间为[101,200]以及计算节点C的预取区间为[201,300],即:
mysql> create table test(id int auto_increment primary key,num int);
在计算节点A上执行:
mysql> insert into test values(null,1),(null,2),(null,3),(null,4);
mysql> select * from test order by id;
+----+-----+
| id | num |
+----+-----+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
+----+-----+
提示
自增序列预取范围为[1,100]
在计算节点B上执行:
mysql> insert into test values(null,1),(null,2),(null,3),(null,4);
mysql> select * from test order by id;
+-----+-----+
| id | num |
+-----+-----+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 101 | 1 |
| 102 | 2 |
| 103 | 3 |
| 104 | 4 |
+-----+-----+
提示
自增序列预取范围为[101,200]
在计算节点C上执行:
mysql> insert into test values(null,1),(null,2),(null,3),(null,4);
mysql> select * from test order by id;
+-----+-----+
| id | num |
+-----+-----+
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 101 | 1 |
| 102 | 2 |
| 103 | 3 |
| 104 | 4 |
| 201 | 1 |
| 202 | 2 |
| 203 | 3 |
| 204 | 4 |
+-----+-----+
提示
自增序列预取范围为[201,300]
在以下两种情况会判断是否重新预取批次并重新计算下一批次大小,由此来调整合适当前业务环境的批次大小:
1.若当前批次使用率达到隐藏参数generatePrefetchCostRatio配置的已消耗比例,则开始预取下一批次。例如若已消耗比例为90%,当前批次大小为100,现自增值已经达到90,则此时开始预取下一批次。
2.从取到批次时间开始计算,若已经到达超时废弃时间prefetchValidTimeout,则根据当前批次使用率判断是否预取下一批次。例如若设置已消耗比例为90%,当前批次大小为100,现自增值已经达到80,此时达到超时时间且当前批次使用率达到配置的已消耗比例的50%,则开始预取下一批次。
当前允许用户插入指定自增值,无论自增值的大小是否大于批次大小,都能保证自增值的全局有序递增。例如当前批次大小为100,插入小于批次大小的自增值:
在计算节点A上执行:
mysql> insert into test values(null,1);
mysql> insert into test values (11,5);
mysql> insert into test values(null,1);
mysql> select * from test order by id;
+----+-----+
| id | num |
+----+-----+
| 1 | 1 |
| 11 | 5 |
| 12 | 1 |
+----+-----+
在计算节点B上执行:
mysql> insert into test values(null,1);
+-----+-----+
| id | num |
+-----+-----+
| 1 | 1 |
| 11 | 5 |
| 12 | 1 |
| 101 | 1 |
+-----+-----+
注意
自增序列2模式可保证全局唯一且长时间范围看是大致正向增长,不保证自增连续性;
对于自增序列的字段类型范围计算节点也可以感知,超过范围计算节点行为同存储节点一致;
若将参数autoIncrement设置为2,自增字段类型必须为bigint,否则建表失败:
mysql> create table table_test(id tinyint auto_increment primary key);
ERROR 10212 (HY000): auto_increment column must be bigint
参数设置为3或4
将参数autoIncrement设置为3或4,满足垂直表带自增的情况,自增值由存储节点处理,不由计算节点接管垂直表的自增。除垂直表带自增外,参数3和4分别与1和2处理模式一致,即autoIncrement=3时相当于autoIncrement=1+垂直表自增不进行处理;autoIncrement=4时相当于 autoIncrement=2+垂直表自增不进行处理。
数据强一致性(XA事务)
在关系集群数据库系统中,数据被拆分后,同一个事务可能会操作多个数据节点,产生跨库事务。在跨库事务中,事务被提交后,若事务在其中一个数据节点COMMIT成功,而另一个数据节点COMMIT失败;已经完成COMMIT操作的数据节点,数据已被持久化,无法再修改;而COMMIT操作失败的数据节点,数据已丢失,这种情况会导致数据节点间的数据不一致。
计算节点利用存储节点提供的外部XA事务,可解决跨库事务场景中,数据的强一致性:要么所有节点的事务都COMMIT,要么所有的节点都ROLLBACK,以及提供完全正确的SERIALIZABLE和REPEATABLE-READ隔离级别支持。
使用XA事务
在计算节点中,默认情况下,XA事务是关闭的。要使用XA事务,需在server.xml文件中,将属性enableXA设置为TRUE:
<property name="enableXA">true</property>
重新启动计算节点后方能生效。若XA事务开关被修改后,未重启计算节点直接进行动态加载,修改结果不会生效且会在计算节点日志中有INFO信息:
Can't reset XA in reloading, please restart the hotdb to enable XA
计算节点在开启XA事务功能后,对于应用程序或者客户端命令操作都是透明的,SQL命令,事务流程没有任何变化,可像普通事务一样使用。用START TRANSACTION或者BEGIN,SET AUTOCOMMIT=0开启事务, COMMIT或ROLLBACK提交或者回滚事务;开启自动提交也同样支持。
在系统中使用计算节点的XA事务,为保证事务的强一致性,需注意以下几点:
-
存储节点版本必须为5.7.17及以上。因为5.7.17之前的版本,存储节点在处理XA事务时,存在缺陷。因此在开启XA模式下,若计算节点启动时检测到存在任意存储节点版本低于5.7.17则计算节点启动失败;若启动计算节点后添加低于5.7.17的存储节点,动态加载将失败;若启动计算节点前低于5.7.17的存储节点无法连接,即使启动后重新连接成功,该存储节点仍然为不可用且动态加载将失败。以上情况都将输出ERROR级别的日志提示:Currently in XA mode, MySQL version is not allowed to be lower than 5.7.17.
-
存储节点及配置库需开启半同步复制(额外注意:开启XA模式时,不允许使用MGR复制模式),当开启半同步复制时,不建议开双1(innodb_flush_log_at_trx_commit = 1,sync_binlog = 1)模式,两者同时开启也会影响性能;
-
部署和使用XA强一致模式,需配置数据节点的高可用,并注意在主机故障切换从机后,原主机不可重用,不可直接在计算节点中标记其为可用,后续必须重新部署原主机,才可标记为可用。
-
XA事务的完整支持serializable、repeatable read、read committed,暂不支持read uncommitted,但当前端隔离级别设置为read committed时,需参考参数allowRCWithoutReadConsistentInXA说明, 注意避免读写强一致性的问题。
-
开启XA模式,使用HINT后,因计算节点无法控制HINT语句修改的内容,后续跟这个连接相关的任何操作计算节点都不再控制隔离级别的正确性。
-
开启XA模式,RC隔离级别下允许在事务中引入新的节点,即隔离级别需开RC(参数值1)或XA模式下特殊的RC(参数值4),其余隔离级别则需满足前后节点一致 ,否则引入新节点会报request a new backend connection in an active xa transaction is not supported
特别说明
XA模式下:参照SQL99标准,begin/start
transaction会立即开启一个事务。也即在XA模式打开的情况下,beginstart transaction将等同于start
transaction with consistent snapshot。
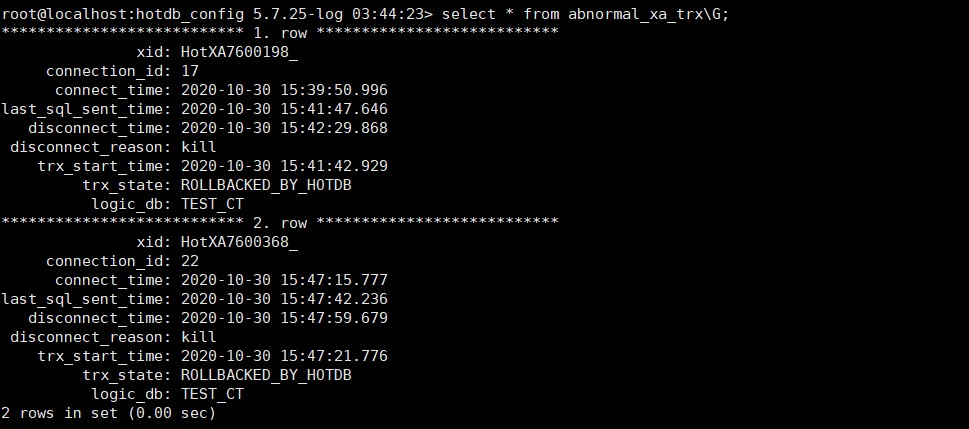
XA模式下前端连接断开时会将事务的状态记录到日志及配置库中,也可以直接通过服务端口执行SHOW ABNORMAL_XA_TRX查看是否需要重做事务。
2020-10-30 15:42:29.857 [WARN] [MANAGER] [$NIOExecutor-2-10] cn.hotpu.hotdb.manager.response.v(39) - [thread=$NIOExecutor-2-10,id=17,user=root,host=127.0.0.1,port=3323,localport=58902,schema=TEST_CT]killed by manager
2020-10-30 15:42:29.857 [INFO] [INNER] [$NIOExecutor-2-10] cn.hotpu.hotdb.server.d.c(1066) - XATransactionSession in [thread=$NIOExecutor-2-10,id=17,user=root,host=127.0.0.1,port=3323,localport=58902,schema=TEST_CT]'s query will be killed due to a kill command, current sql:null
2020-10-30 15:42:29.859 [INFO] [CONNECTION] [$NIOExecutor-2-10] cn.hotpu.hotdb.server.b(3599) - [thread=$NIOExecutor-2-10,id=17,user=root,host=127.0.0.1,port=3323,localport=58902,schema=TEST_CT] will be closed because a kill command.

特别说明
- disconnect_reason: 连接断开原因,如kill前端连接(kill)、TCP连接断开(program err:java.io.IOException: Connection reset by peer)、SQL执行超时(stream closed,read return -1)、空闲超时(idle timeout)等。
- trx_state: 连接断开时的事务状态,包括:
1.ROLLBACKED_BY_HOTDB:在事务中且事务被计算节点回滚(对应非自动提交时应用程序未发出commit命令或commit命令中途丢失);
2.COMMITED_BY_HOTDB:在事务中且事务被计算节点提交(对应非自动提交时,计算节点收到了commit并成功提交,但是在commit中途前端连接断开,因此计算节点未能成功发出ok包)。
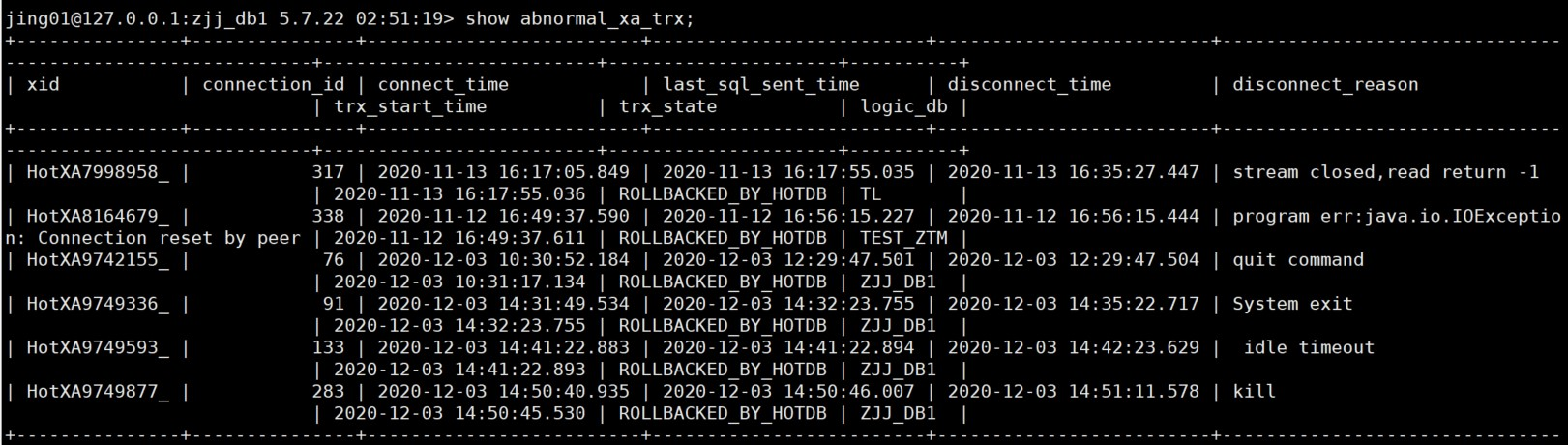
XA事务与读写分离的关系
XA模式下,当开启读写分离时:只有非事务内的单节点的读请求是可分离的,且模式3退化成模式2;
XA模式下,当开启读写分离时:无法保证隔离级别正确性,但能保证数据不丢,且不出现部分提交/部分回滚;
同时使用时,计算节点日志会输出相关Warning提醒。
非确定性函数代理
非确定性函数在使用中,会带来一系列问题,尤其是全局表的数据一致性问题,为此计算节点提供非确定性函数代理的功能。非确定性函数大致分为两类,一类是已知值的时间类函数,如CURDATE()、CURRENT_TIMESTAMP()等,一类是未知值的随机值函数、唯一值函数,如RAND()、UUID()等。
1.对于时间类函数,计算节点进行统一代理。
-
当表的字段类型有DATETIME(或者TIMESTAMP)且无默认值时,由参数timestampProxy控制计算节点的代理范围(默认为自动模式,可选全局处理/自动检测),将此类函数代理为具体值插入到表中;
-
当SELECT/INSERT/UPDATE/DELETE语句中出现curdate()、curtime()等函数时,计算节点将函数代理为具体值插入到表中;
2.对于随机值函数,计算节点针对不同的SQL语句进行不同的代理办法。
3.对于唯一值函数,计算节点进行统一代理。 -
当SELECT/INSERT/UPDATE/DELETE语句中出现uuid()或uuid_short()时,计算节点按照标准的UUIDv1算法代理唯一值;
-
当存储节点和配置库的server_id冲突时,计算节点自动禁用uuid_short()并告知用户手动调整server_id。可参考官网说明:https://dev.mysql.com/doc/refman/5.7/en/replication-options.html。
全局时区
为保证数据的正确性,针对不同存储节点服务器存在设置不同时区,导致数据库中时间类型的数据错误的问题,计算节点 提供对全局时区的支持,包括:
当time_zone参数为具体的相同值或者全为SYSTEM并且system_time_zone全为相同的具体值时,计算节点不做特殊处理,否则计算节点会统一将time_zone设置为固定值:"+8:00"且会记录警告级别的日志(The datasources' time_zones are not consistent);
如登入服务端口后输入命令:
set time_zone = '+0:00';
show variables like '%time_zone';
仍会显示time_zone为'+8:00':
mysql> set time_zone='+0:00';
mysql> show variables like '%time_zone';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| system_time_zone | CST |
| time_zone+08:00 | |
+--------------------+-------+
2 rows in set (0.09 sec)
备份与恢复时,计算节点能保证恢复后时间类型的数据与备份前一致。
全局唯一约束
若开启全局唯一约束功能,计算节点可以保证拥有唯一约束(UNIQUE、PRIMARY KEY)的列在所有节点都是唯一的,包括但不限于以下场景:
- 唯一约束键不是分片字段或不包含分片字段;
- 父子表下,子表与父表的关联字段与子表的唯一约束键不是同一列;
计算节点将全局唯一约束优化精确到表级别,默认为所有未来添加的表关闭全局唯一约束,也可以手动在添加表时为某些表单独关闭/开启全局唯一约束。
可以通过修改server.xml中的如下参数或在管理平台计算节点参数中修改此参数。修改参数只为未来添加的表设置全局唯一的默认值,但并不影响历史数据表的全局唯一性。
<property name="globalUniqueConstraint">false</property><!--全局唯一约束-->

注意
开启该功能后,可能对SQL语句INSERT、UPDATE、DELETE的执行效率有较大影响,可能导致SQL操作延迟增大;还可能导致锁等待和死锁的情况增加。请酌情考虑后注意取舍。
创建表时的表级别控制
添加表信息时可以为某张表单独开启/关闭全局唯一约束;
1.在管理平台上添加表信息时,根据计算节点参数默认显示全局唯一约束开关状态,可手动修改:
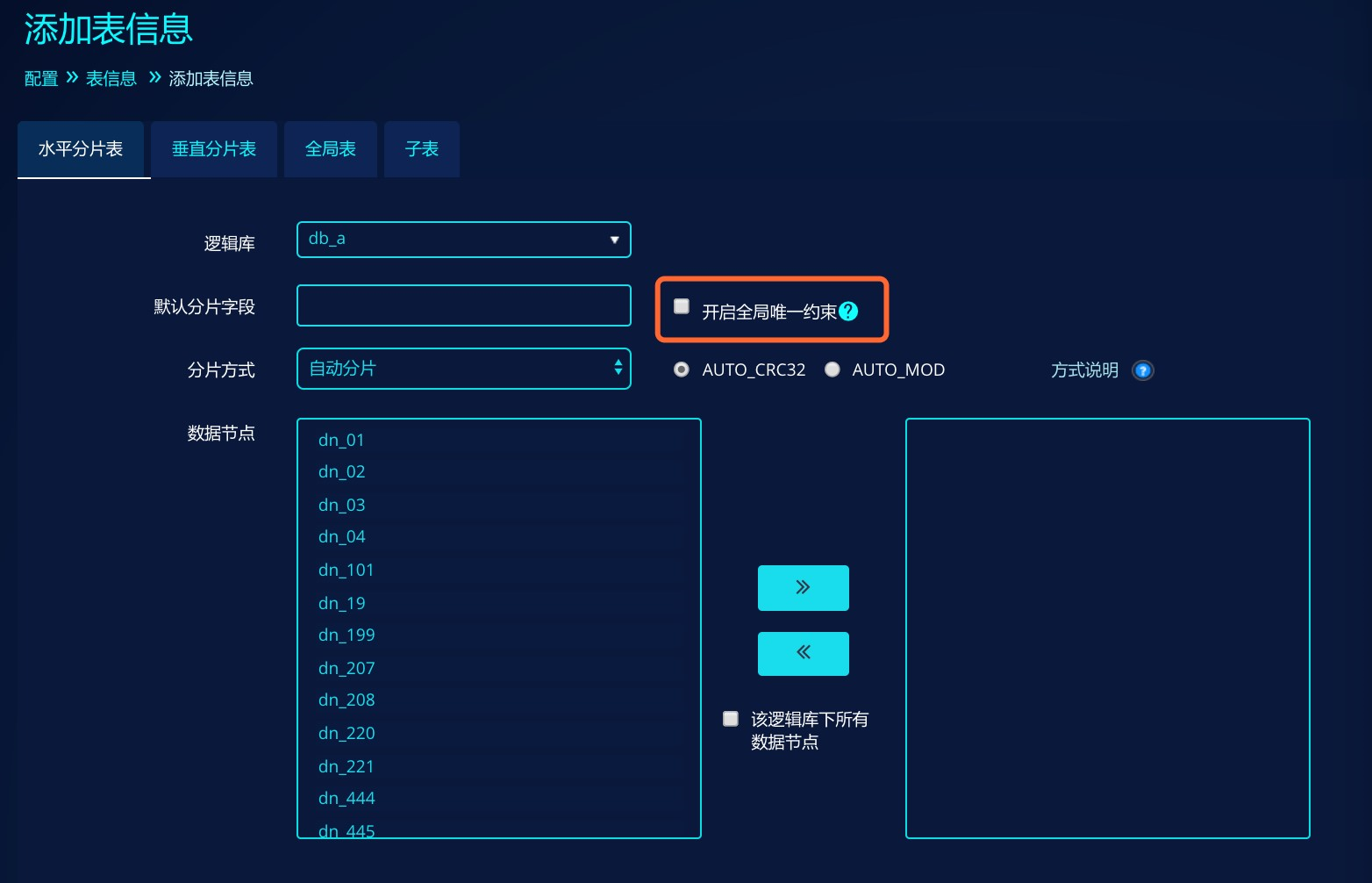
垂直分片表与全局表没有此入口,因为不需要对唯一约束做额外处理。添加完表配置后即可使用建表语句添加表结构后使用。
2.使用自动建表功能,可通过table option GLOBAL_UNIQUE [=] {0 | 1}设置全局唯一约束的开关。例如:
create table test02(id not null auto_increment primary key,a char(8),b decimal(4,2),c int) GLOBAL_UNIQUE=0;
create table test03(id int primary key,id1 int) GLOBAL_UNIQUE =1;
若不使用GLOBAL_UNIQUE [=] {0|1},则默认根据计算节点参数的默认值或在管理平台上添加的表配置设置开启或关闭;若GLOBAL_UNIQUE=1则判断为开启;若GLOBAL_UNIQUE=0则判断为关闭。
-
若GLOBAL_UNIQUE设置与默认值不同,则以GLOBAL_UNIQUE为准;
-
若GLOBAL_UNIQUE设置与管理平台中此表的全局唯一约束配置不同,则会建表失败,并给出error提醒,例如管理平台添加test01时关闭了全局唯一约束:
mysql> create table test01(id int)global_unique=1;
ERROR 10172 (HY000): CREATE TABLE FAILED due to generated table config already in HotDB config datasource. You may need to check config datasource or reload HotDB config.
- 若在垂直分片表或全局表的建表语句中使用GLOBAL_UNIQUE,则会建表成功,但会给出warning信息,因为不需要对其唯一约束做额外处理,例如test03是一张垂直分片表:
mysql> create table test03(id int)**global_unique=1**;
Query OK, 0 rows affected, 2 warnings (0.09 sec)
Warning (Code 10032): Create table without primary key and unique key
Note (Code 10210): Global_unique is not applicable to vertical-sharding tables or global tables.
使用mysqldump时不用担心GLOBAL_UNIQUE对备份结果造成干扰,将GLOBAL_UNIQUE语法解析为注释格式,例如:
mysql> create table test02(id int) GLOBAL_UNIQUE=1;
mysql> show create table test02
+-------+---------------------------------------------------------------+
| Table | Create Table |
+-------+---------------------------------------------------------------+
| test3 | CREATE TABLE `test3` (
`id` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4/*hotdb:020503 global_unique=1*/ |
+-------+---------------------------------------------------------------+
1 row in set (0.00 sec)
将含有GLOBAL_UNIQUE语法的建表语句导入存储节点不会对结果有影响。在计算节点也可以直接用注释语法操作GLOBAL_UNIQUE,使用-c作为存储节点登陆参数允许执行注释。
mysql -c -uroot -proot -h127.0.0.1 -P3323
例如执行如下语句,表示在计算节点会执行GLOBAL_UNIQUE=0:
create table test02(id not null auto_increment primary key,a char(8),b decimal(4,2),c int) /*hotdb:020503 GLOBAL_UNIQUE=0*/;
修改表时的表级别控制
可以在管理平台的表信息管理页面修改表配置:

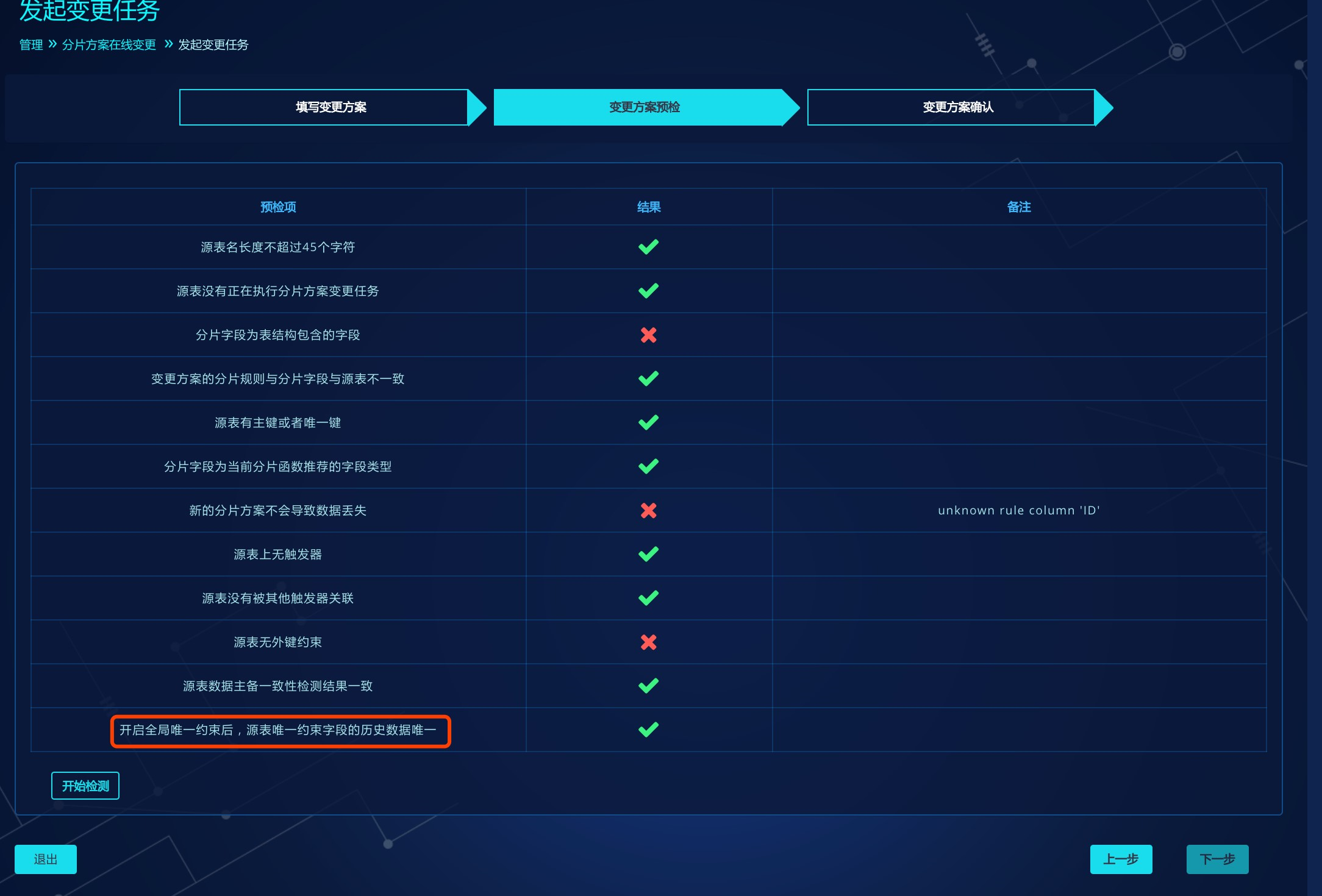
若表结构为已创建的表,全局唯一约束修改为开启状态后,点击动态加载并刷新页面,若出现如下图提示,说明需要到管理端口执行unique @@create,检查此表唯一约束键的历史数据,返回结果是唯一后,计算节点自动创建辅助索引,全局唯一约束方能生效:
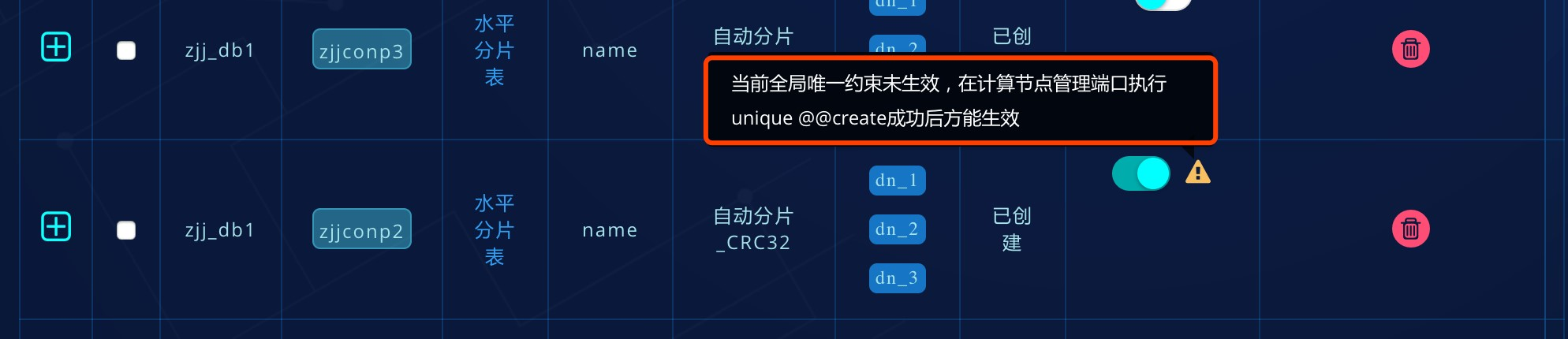
在计算节点通过ALTER TABLE使用GLOBAL_UNIQUE语法,开启全局唯一,同理,出现warning信息说明需要执行unique @@create后方能生效:
mysql> alter table keevey01 global_unique=1;
Query OK, 0 rows affected, 1 warning (0.01 sec)
mysql> show warnings;
+-------+-------+--------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+-------+--------------------------------------------------------------------------------------------------------------------------------------+
| Note | 10210 | please go to HotDB Server manager port and execute this command: unique @@create, otherwise this global_unique setting doesn't work. |
+-------+-------+--------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
分片方案在线变更
分片方案在线变更时也可以为变更后的表手动开启或关闭全局唯一约束。
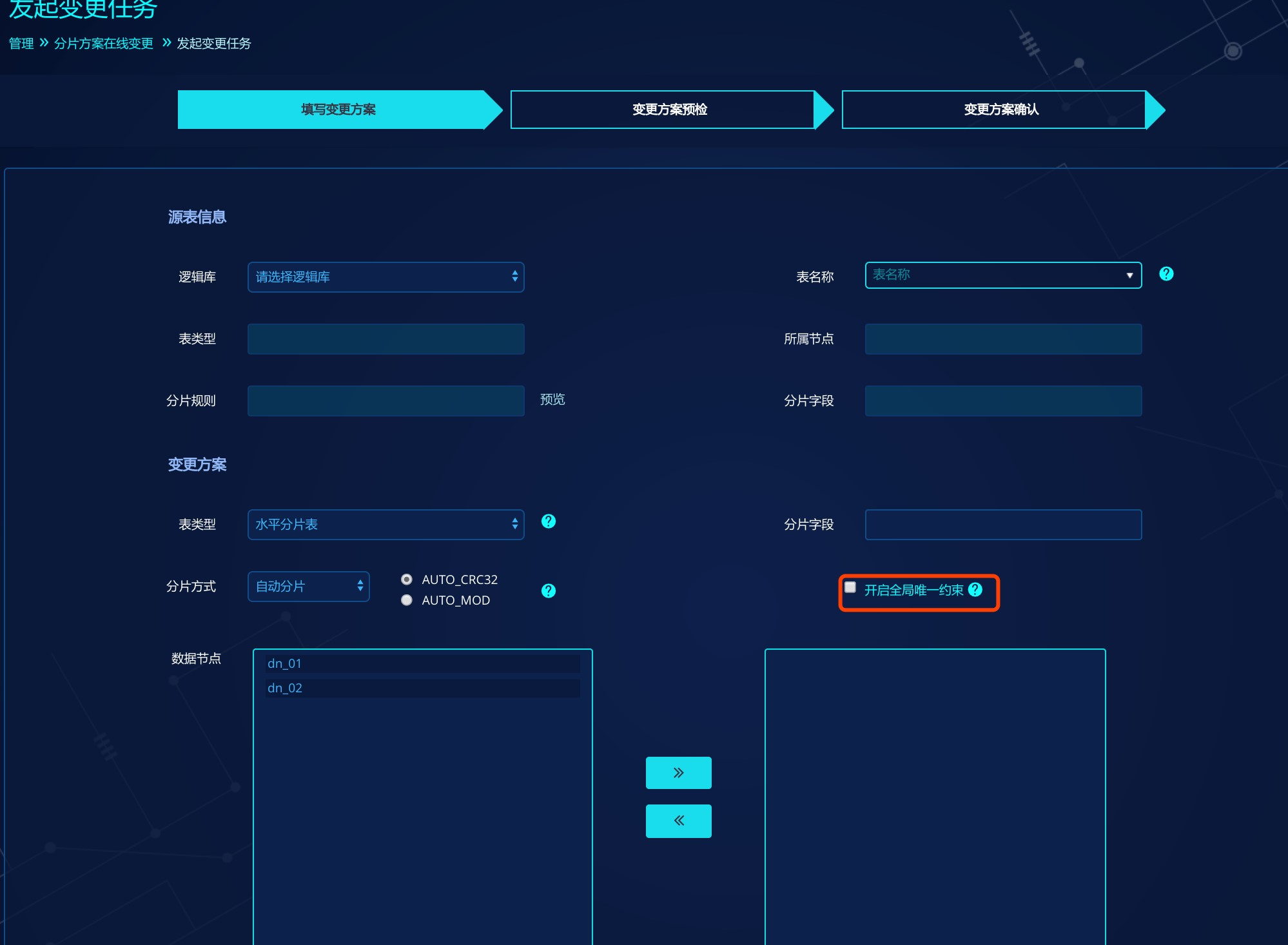
开启后,在变更方案预检会检测此表唯一约束键的历史数据是否唯一,若唯一,则通过测试。
查询时通过辅助索引定位
此功能还支持在SELECT查询语句中不包含分片字段但包含唯一约束字段时,通过查询辅助索引定位到固定节点,将SELECT查询语句仅下发到指定的节点而非所有节点。
<property name="routeByRelativeCol">false</property><!--不包含分片字段时通过辅助索引字段路由-->
此项功能默认关闭,可通过修改server.xml中的routeByRelativeCol参数或在管理平台配置菜单下的计算节点参数配置中添加参数"不包含分片字段时是否开启通过辅助索引字段路由"。
此参数开启后,作用举例如下:现有一个水平分片表table01,分片字段为id,分片规则为auto_mod,执行如下查询语句时:
SELECT * FROM table01 WHERE unique_col = 100; # unique_col是唯一约束列
此查询语句将只下发到 unique_col = 100 的那一个数据节点,而不是所有数据节点
故障切换后的数据正确性保障
无论是异步复制还是半同步复制,都可能会存在这样一种情况:在故障切换全部完成后,原主库恢复,新主库(原从库)复制IO线程可能自动重连并获取到切换前没有获取到的事务,而这样的事务在切换的处理过程中,已经是被认定没有提交成功的事务,不能再继续复制,否则会有数据混乱的风险。
因此增加计算节点参数failoverAutoresetslave,默认关闭。
<property name="failoverAutoresetslave">false</property><!-- 故障切换时,是否自动重置主从复制关系 -->
故障切换后,会暂停原主从之间IO线程,并对原主库每分钟进行一次心跳检测直到原主库恢复正常。原主库恢复正常后,对比原主库的binlog位置,检测原从库(现主库)是否存在切换前没有获取到的事务,若存在,开启此参数则自动重置主从复制关系。若不存在未接收的事务,则重新开启IO线程并不再做任何处理。
注意
检测是否有未接收的事务的前提是主从库都需要开启GTID,否则此参数开启时,故障切换完成会自动重置主从复制关系。
若原主库在心跳检测时重试超过10080次,仍然为不可用状态,此时,参数为开启状态,也会自动重置主从复制关系。
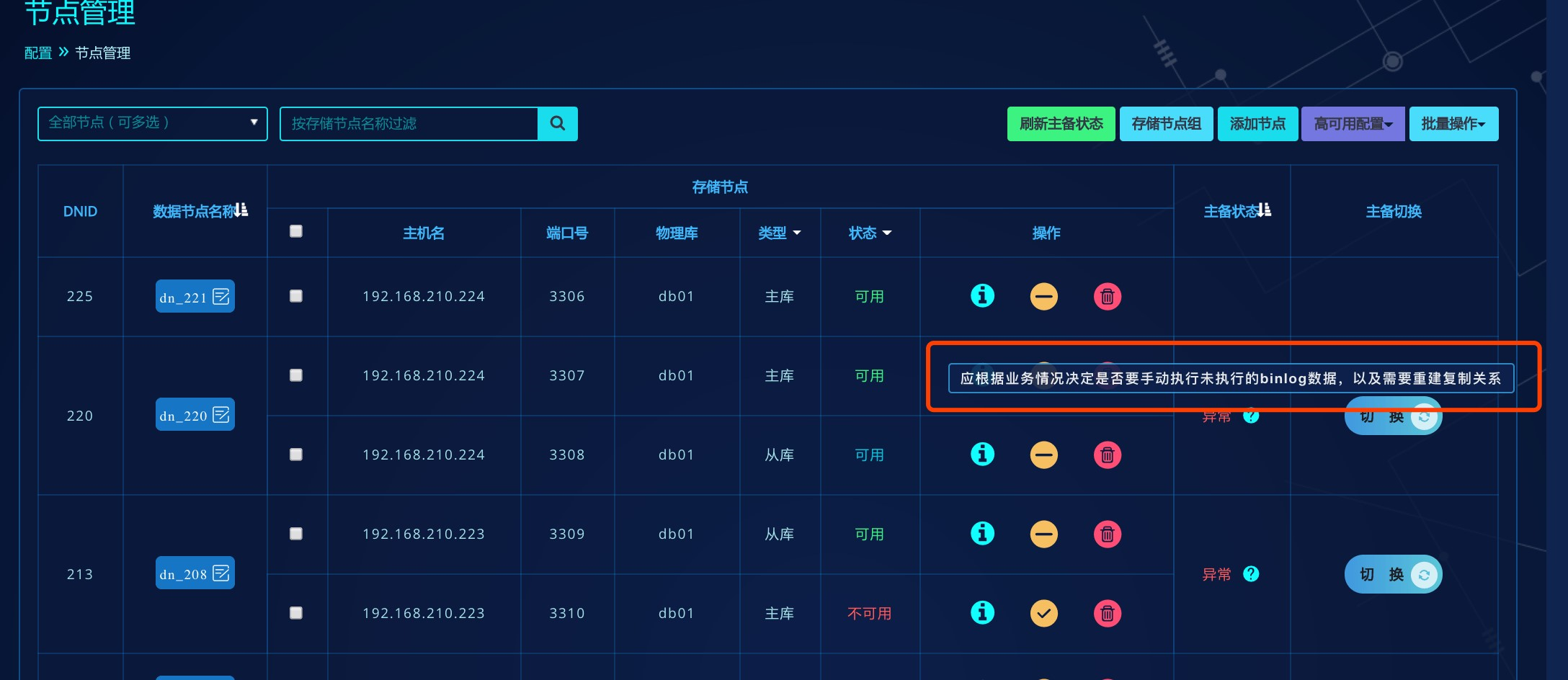
若发生自动重置复制关系后,计算节点记录warning级别的报警日志如下: you should decide whether to
manually execute the unexecuted part of binlog or rebuild the
replication according to the actual situation.,
且管理平台中的主备状态会显示异常,鼠标悬浮显示如图提示信息:
若故障切换完成后,主从库未开启GTID或存在未接收的事务,但此参数为关闭状态,计算节点也会记录warning级别的报警日志如下: DBA is required to deal with the new master, which is the original slave before switching and decide whether to stop replication or continue replication regardless. In addition, there is risk of data error caused by automatic reconnection of replication after manual or unexpected restart of the new master.
注意事项
以下场景中,可能会出现数据不一致的情况,包括主从存储节点的数据不一致,和数据节点之间的数据不一致:
1.人为操作
(1)人为或应用程序直接操作存储节点,可能导致任意类型的不一致;
(2)使用HINT语句操作数据,可能导致任意类型的不一致;
(3)未正确使用外键约束;在不支持的场景下使用存储过程、触发器、视图;未正确使用event等。对于计算节点来说,这些操作相当于"人为或应用程序直接操作存储节点";
(4)强行修改表的配置规则而没有对应调整数据路由,或使用过去遗留的有BUG的分片规则等,可能导致路由不正确;
(5)设置server.xml 参数checkUpdate=false时,即允许更新分片字段,可能导致路由不正确,进而导致数据操作时存在与预期不一致的问题;
(6)未use逻辑库的情况下,执行了连接绑定语句(包括HINT、set [session] foreign_key_checks=0、START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */、set [session] UNIQUE_CHECKS=0等),导致其SQL语句均直接下发至存储节点执行,进而可能导致任意类型的不一致;
2.环境配置
(1)存储节点所在服务器时间不一致,参考timestampProxy设置的模式与场景;
(2)存储节点搭建从机方法不当,例如使用extrabackup备份恢复数据的方式搭建从机;
(3)主从存储节点发行分支、版本不一致;
(4)不合理的存储节点参数设置、复制架构等导致不一致,包括但不限于:使用语句格式的binlog、部分复制、多主复制、配置不正确的二级从、主从或节点间字符集、时区配置不一致等;
(5)在没有开启全局唯一约束的情况下,不含分片字段的唯一键无法保证全局唯一;
3. 异常情况
(1)在做DDL操作时存储节点故障、后端连接异常中断导致存储节点间表结构不一致,表结构不一致在部分时候可能带来更多不一致的数据;
(2)故障切换后,业务上数据正确,但无法完全保证故障的主与切换到的从的数据一致。同时,被标记为"不可用"的存储节点如果操作不当,例如在未校验数据一致性的情况下将其重新标记为"可用"并加入数据节点,会导致不一致;
(3)非XA模式下:计算节点被强杀、存储节点故障、后端连接异常中断导致连接断开所产生的部分提交;
(4)计算节点高可用(HA)模式下,多个服务端口(3323)开启提供服务;
(5)服务器(包括计算节点、存储节点等)磁盘已满等操作系统故障;
(6)计算节点/存储节点 OOM等服务异常;
(7)备份恢复数据时出现异常,例如部分节点backup服务关闭,存储节点出现故障等 ,可能导致数据出现不一致;
4.其他
(1)存储节点自身BUG,可能导致任意类型的数据不一致。应尽量使用稳定的存储节点版本与功能,不能盲目追求存储节点新功能;
(2)计算节点自身BUG,或者设计上还有遗漏的地方,可能导致任意类型的数据不一致。应及时更新至计算节点最新版本;
(3)非XA模式下读到半个事务,主从读写分离读到旧数据等非永久性的不一致。