文章很长,且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
希音面试:Redis脑裂,如何预防?你能解决吗?(看这篇就够了)
尼恩特别说明: 尼恩的文章,都会在 《技术自由圈》 公号 发布, 并且维护最新版本。 如果发现图片 不可见, 请去 《技术自由圈》 公号 查找
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题:
什么 Redis的脑裂问题?
什么Redis的脑裂, 后果是什么? 如何解决?
Redis脑裂,如何预防?你能解决吗?
最近有小伙伴在面试 希音,又遇到了相关的面试题。小伙伴懵了,因为没有遇到过,所以支支吾吾的说了几句,面试官不满意,面试挂了。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V171版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,回复:领电子书
1:什么是脑裂问题?
脑裂(Split-Brain)是一个形象的比喻,好比“大脑分裂”,也就是本来一个“大脑”被拆分了两个或多个“大脑”。
在分布式系统中,因为网络分区或节点故障导致节点之间的通信断开,进而导致数据一致性问题。
在一个高可用集群中,当多个服务器在指定的时间内,由于网络的原因无法互相检测到对方,而各自形成一个新的小规模集群,并且各小集群当中,会选举新的master节点,都对外提供独立的服务。
由于网络断裂的原因,一个高可用集群中,实际上分裂为多个小的集群,这种情况就称为裂脑。
也有的人称之为分区集群,或者大脑垂直分隔,互相接管对方的资源,出现多个Master的情况,都可以称为脑裂。
裂脑之后的后果是,可能会导致服务器端的数据不一致,或造成数据的丢失
借助一个简单的 6个节点的 Zookeeper 集群为例,介绍一下脑裂。
这个要求,与ZooKeeper 的默认解决脑裂的策略有关系。
现在,为了高可用,将一个由 6 个节点的 zkServer 集群,部署在了两个机房,具体如下图:
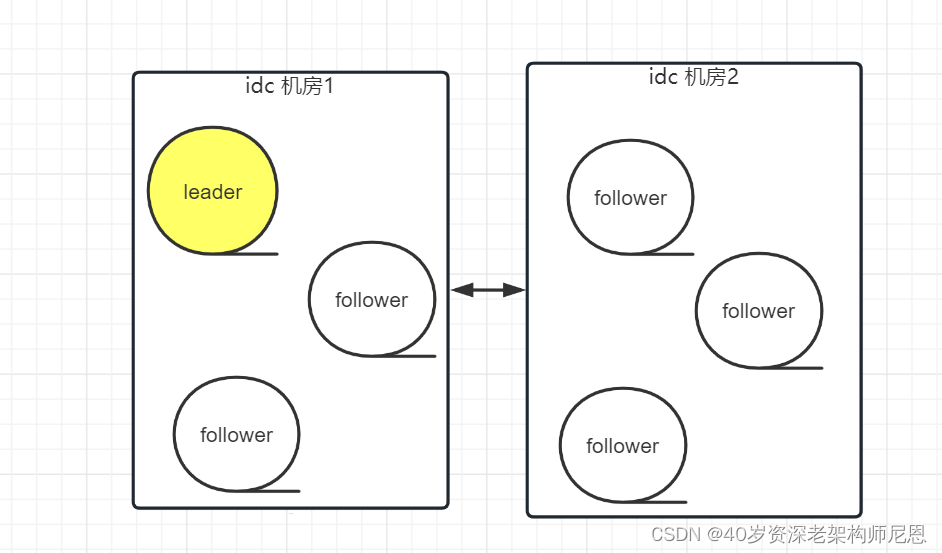
正常情况下,此集群只会有一个 Leader,并且 集群的Leader节点通过投票选举的。就是集群通过选举的规则所有节点中选出来的,简称为选主。
如果意外的情况发生: 两个机房之间, 发生断网,结果如何呢?
这里有两个子网络,一个子网是3个节点,
发生断网后,一个大的集群, 其实被分割为 2个小的集群,每个小的集群各自3个节点,
2个小的集群 选举出各自的leader,对外提供服务, 发生脑裂。

1.1:脑裂严重后果:
发生脑裂后,系统被分割成两个或多个独立的子系统,每个子系统可能会独立选举出自己的领导节点(Leader)。
由于不同的子系统可能会对相同的数据进行修改, 这种情况可能导致数据不一致和操作冲突。
所以: 脑裂的严重后果是:数据一致性的丧失,这对于依赖精确数据进行操作的系统来说是致命的。
例如,在银行系统中,如果账户余额记录因为脑裂而不一致,可能导致用户资金被错误处理。
为了避免脑裂问题,Zookeeper采用了过半机制(Quorums),即只有集群中超过半数节点投票才能选举出Leader。
Redis 脑裂,在原理上和 Zookeeper 脑裂,ES 脑裂 ,本质上都是类似的:
具体请参见尼恩的文章:
聊聊:什么脑裂? 照此文作答,面试官献上膝盖,秒发offer
Redis 脑裂,和Redis 集群的模式有关。
所以,在介绍脑裂之前,尼恩先给大家梳理一下Redis的四大集群模式,以及它们各自的应用场景,然后基于不同的模式,介绍脑裂问题。
2:Redis的四大集群模式
Redis的部署模式主要包括以下几种:
一、单机
二、主从复制
三、哨兵
四、集群
2.1: 单机部署
单机部署只有一台Redis实例,如果这台服务器宕机,服务也将随之中止,而且,由于数据没有进行备份,安全性也将大打折扣。

单机部署 应用场景
单机部署的复杂性较低,对于学习或者测试的目的,这种部署模式还是比较合适的,
而且,单机部署也是其它复杂部署模式的起点。
2.2:主从复制
主从复制将一个Redis服务器上的数据复制到其他服务器上,前者称为Master也就是master,后者为Slave也就是从节点,Master主要负责数据的写操作,Slave主要进行数据的读操作。
通过主从复制可以实现数据备份、读写分离、故障恢复等功能。

主从复制可以有多个从节点,在数据同步的过程中,它会存在一定的延迟,同时,异步的数据复制也不保证强一致性。如果master宕机,需要手动把从节点切换为master。
主从复制 应用场景
- 数据备份和容灾恢复:通过从节点备份master的数据,实现数据冗余。
- 读写分离:将读操作分发到从节点,减轻master压力,提高系统性能。
- 在线升级和扩展:在不影响master的情况下,通过增加从节点来扩展系统的读取能力。
总结:主从复制模式适合数据备份、读写分离和在线升级等场景,但在master故障时需要手动切换,不能自动实现故障转移。如果对高可用性要求较高,可以考虑使用哨兵模式或Cluster模式。
2.3:哨兵模式
哨兵模式是在主从复制基础上加入了哨兵节点,实现了自动故障转移。哨兵节点是一种特殊的Redis节点,它会监控master和从节点的运行状态。
当master发生故障时,哨兵节点会自动从从节点中选举出一个新的master,并通知其他从节点和客户端,实现故障转移。
主从复制有一个较为明显的缺点,就是master宕机后,系统不会自动切换,还需要人工介入,针对这样的情况,哨兵模式就应运而生了,它非常重要的一个优点就是能够实现自动故障转移。

当然,哨兵模式也并非完美的解决方案,除了实际存储数据的服务器,它还需要额外的哨兵服务,这样就增加了运维成本,同时,所有的数据都存放在一台机器(没有进行分片),使得存储的容量也有了限制。
哨兵模式场景应用
哨兵模式适用于以下场景:
- 高可用性要求较高的场景:通过自动故障转移,确保服务的持续可用。
- 数据备份和容灾恢复:在主从复制的基础上,提供自动故障转移功能。
哨兵模式在主从复制模式的基础上实现了自动故障转移,提高了系统的高可用性。
然而,它仍然无法实现数据分片。如果需要实现数据分片和负载均衡,可以考虑使用Cluster模式。
2.4: 集群模式
Redis集群使用哈希槽的方式将数据进行分片,分开存放在不同的机器上,这样就大大提升了系统存储的容量和性能。每个master还可以有多个从节点,如果master宕机,从节点自动提升为master。

在高并发、高可用的应用场景下,Redis集群是一个更为“高端”的部署方案,可以较方便地进行水平扩展。
Cluster模式应用场景
- 大规模数据存储:通过数据分片,突破单节点内存限制。
- 高性能要求场景:通过负载均衡,提高系统性能。
- 高可用性要求场景:通过自动故障转移,确保服务的持续可用。
总结:
Cluster模式在提供高可用性的同时,实现了数据分片和负载均衡,适用于大规模数据存储和高性能要求的场景。然而,它的配置和管理相对复杂,且某些复杂的多键操作可能受到限制。
2.5:单机、主从、哨兵和集群 4大模式的PK
总体来说,Redis的常见部署模式有四种:单机、主从、哨兵和集群。
单机模式部署起来最简单,但它不具备高可用的特性,主从复制进了一步,提供了更好的数据安全性,但master宕机后需要人工介入,而哨兵和集群的部署模式是具有高并发、高可用的优点的,对于数据量不是很大的应用场景,可以考虑采用哨兵的部署模式。
下面我们用一张表来总结一下各种部署模式的优缺点:
Redis部署模式大比拼
| 部署模式 | 优点 | 缺点 |
|---|---|---|
| 单机 | 操作简便成本低 | 数据不安全可用性很低 |
| 主从 | 数据有备份可实现读写分离 | 不能实现故障自动切换 |
| 哨兵 | 故障自动切换 | 存储容量受限需要额外的哨兵服务器 |
| 集群 | 可水平扩展高可用性能较好 | 运维及编程的难度增加 |
3: 回到redis 集群的脑裂
包括:
- 哨兵(sentinel)模式下的脑裂
- 集群(cluster)模式下的脑裂
4:哨兵(sentinel)模式下的脑裂问题
哨兵(sentinel)模式下的脑裂,主要是由于网络分区,导致 master、slave 和 sentinel 三类节点处于不同的网络分区。
此时:
- 哨兵无法感知到 master 的存在,会将 slave 提升为 master 节点
- 另外有 客户端 连着老的 master
有新老master 同时提供服务的情况,这就是 哨兵(sentinel)模式下的脑裂问题。 另外, 哨兵(sentinel)模式下的sentinel 集群本身,也有脑裂问题。

脑裂(Split-Brain)是指在分布式系统中,网络分区导致多个节点之间失去联系,形成了两个或多个独立的“脑”,每个脑都认为自己是master,导致数据写入的冲突和不一致。

- 网络故障:在网络故障或不稳定的情况下,master与哨兵或从节点之间的通信可能会中断。这时,哨兵可能会误认为master已宕机。
- 哨兵的选举机制:当哨兵无法与master通信时,会启动选举过程,从现有的从节点中选出一个新的master。如果此时网络恢复,master仍在运行,就会导致出现两个master。
- 假死: 如果master发生假死,也就是进程还在,但是没响应了。 哨兵的故障转移策略在网络异常时会过于敏感,容易在错误的情况下进行master的选举。也就是因为假故障导致又多选一个master出来。
在 Redis 哨兵(sentinel)模式,如果由于网络/假死等原因,导致哨兵无法感知到 master 的存在,哨兵开始选举了新的master。
选举了新的master后,而旧的master恢复过来继续接受写请求,也就是存在两个redis master了,这就是redis的脑裂行为
4.1: 脑裂导致的问题
脑裂导致的三大问题,这里再总结一下:
- 数据不一致: 不同子集之间可能对同一数据进行不同的写入,导致数据不一致。
- 重复写入: 在脑裂问题解决后,不同子集可能尝试将相同的写操作应用到主节点上,导致数据重复。
- 数据丢失: 新 Matser会向slave 实例发送slave of命令,让所有slave 重新进行全量同步,在此之前会先清空实例上的数据,所以在主从切换期间,原slave上执行的写命令也会被清空。
4.2:哨兵机制的三大核心任务
哨兵 对 Redis 实例(master、从节点)运行状态的监控,并能够在master发生故障时通过一系列的机制实现选主及主从切换,实现故障转移,确保整个 Redis 系统的可用性 。
Redis 哨兵具备的能力有如下几个:
- 监控:持续监控 master 、slave 是否处于预期工作状态。
- 自动切换主库:当 Master 运行故障,哨兵启动自动故障恢复流程:从 slave 中选择一台作为新 master。
- 通知:让 slave 执行 replicaof ,与新的 master 同步;并且通知客户端与新 master 建立连接。
如下图所示:

Sentinel 任务一:监控
Sentinel 只是 redis集群中的特殊角色。
在默认情况下,Sentinel 以每秒一次的频率向所有节点(包括 Master、Slave、其他 Sentinel 在内)发送 PING 命令,如果 slave 没有在在规定时间内响应Sentinel 哨兵的 PING 命令,Sentinel 哨兵就认为这哥们可能嗝屁了,就会将他记录为 下线状态 ;
假如 master 没有在规定时间响应 Sentinel 哨兵的 PING 命令,哨兵就判定master下线,开始执行 自动切换 master 的流程。
PING 命令的回复有两种情况:
- 有效回复:返回 +PONG、-LOADING、-MASTERDOWN 任何一种;
- 无效回复:有效回复之外的回复,或者再指定时间内返回任何回复。
为了防止master 假死 ,Sentinel 哨兵设计了 主观下线 和 客观下线 两种暗号。
什么是 主观下线?
哨兵利用 PING 命令来检测master、 slave 的生命状态。
如果是无效回复,哨兵就把这个 slave 标记为 主观下线 。
因为 master还在,slave 的假死对整个 redis集群影响不大, redis集群 依然可以提供服务。
如果检测到是 master完蛋,这时候哨兵 要干大事了。
一旦 master完蛋, 哨兵 不能这么简单的标记 主观下线 ,哨兵 需要 开启新master选举。
当然,一旦启动了master切换,就是一个很重的活儿, 后续的选主投票、同步数据(slave 花时间与新 master 同步数据)都会消耗大量资源。
有可能出现误判,master并没有真的死掉,这样大动干戈就有点 劳民伤财,得不偿失了。
所以Sentinel 哨兵要降低误判的概率,误判一般会发生在集群网络压力较大、网络拥塞,或者是主库本身压力较大的情况下。
如何减少误判:可以使用多个哨兵投票, 采用多实例组成的集群模式进行部署,这就是哨兵集群。
引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。
同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
如下图所示:

什么是 客观下线 ?
哨兵集群中,如果有过半的哨兵判断 master 已经 主观下线 ,这时候才能将 master 标记为 客观下线 。
也就是说这是一个客观事实,master真的死了,至少大部分群众都这么认为,这是集体决策的结果。
一旦 master 被判定为 客观下线 ,才会进一步触发哨兵开始主从切换流程。
如下图所示:

主观下线与客观下线的区别
简单来说,
-
主观下线是 哨兵 认为某个 节点宕机。
-
而客观下线是不但哨兵 认为 某个 节点宕机,而且哨兵集群投票后,达到一定数量的哨兵都认为 节点宕机了。
这里的 一定数量 是一个法定数量(Quorum),是由哨兵监控配置决定的,解释一下该配置:
sentinel monitor <master-name> <master-host> <master-port> <quorum>
# 举例如下:
sentinel monitor mymaster 127.0.0.1 6379 2
这条配置项用于告知哨兵需要监听的master:
- sentinel monitor:代表监控。
- mymaster:代表master的名称,可以自定义。
- 192.168.11.128:代表监控的 master ip,6379 代表端口。
- 2:法定数量,代表只有两个或两个以上的哨兵认为master不可用的时候,才会把 master 设置为客观下线状态,然后进行 failover 操作。
quorum设置为多少呢? 标准就是过半机制,类似Zookeeper。
也就是,当有 N 个哨兵实例时,要有 N/2 + 1 个实例判断 master 为 主观下线 ,才能最终判定 Master 为 客观下线 ,其实就是过半机制。
Sentinel 任务二:切换主库
Sentinel 哨兵的第二个任务,选择新 master。
需要从 redis集群中按照一定规则选择一个slave 为新master。
按照一定的 筛选条件 + 打分 策略,选出 最强王者slave 担任master。
打分 策略 的一个核心指标,就是 主从复制的进度, 进度快的说明 性能最好,网速最高。
如下图所示:

Sentinel 任务三:通知
选主之后, 哨兵 将新 master 的连接信息发送给其他 slave ,并且让 slave 执行 replacaof 命令,和新 master 建立连接,并进行数据复制 新master 的所有数据。
选主之后,还需要将新 master 的连接信息通知整个 Redission 客户端, 让客户端找 master 进行写入。
如下图所示:

4.3:master故障转移的 总体流程
针对master故障的情况,故障转移流程⼤致如下:
- master故障,从节点同步连接中断,主从复制停⽌。(从节点挂了无所谓)
- 哨兵节点通过定期监控发现master出现故障。哨兵节点与其他哨兵节点进⾏协商,达成多数认同master故障的共识。这步主要是防⽌该情况:出故障的不是master,⽽是发现故障的哨兵节点,该情况经常发⽣于哨兵节点的⽹络被孤⽴的场景下。
- 哨兵节点之间使⽤ Raft 算法选举出⼀个领导⻆⾊,由该节点负责后续的故障转移⼯作。
- 哨兵领导者开始执⾏故障转移:从节点中选择⼀个作为新master;让其他从节点同步新master;通知应⽤层(客户端程序)转移到新master。

4.4:哨兵模式的 Sentinel 集群脑裂
可以看出 Redis Sentinel 具有以下⼏个功能:
- 监控:Sentinel 节点会定期检测 Redis 数据节点、其余哨兵节点是否可达。
- 自动故障转移:实现从节点晋升(promotion)为master并维护后续正确的主从关系。
- 通知:Sentinel 节点会将故障转移的结果通知给应⽤⽅。
哨兵也是一个 Redis 进程,其实, redis 哨兵节点只有一个也是可以的,只是:
- 如果只有一个,自身也是很容易出问题的,如果这个哨兵节点挂了,后续 redis 节点也挂了,就无法自动恢复
- 出现误判的概率提高了,毕竟网络传输是容易出现抖动、延迟、丢包之类的,这单个哨兵节点出问题,影响就大了
基本原则:在分布式系统中,应该避免使用“单点”。所以, Redis Sentinel 也需要高可用,做出集群模式。
哨兵节点最好搞奇数个,最少是3个,原因:
-
如果哨兵节点数目为偶数,可能出现两个相等大小的哨兵组认为自己拥有决策权的情况,从而导致系统不能一致地决定哪个Redis实例应该是master。这种情况下,两个哨兵组可能会分别选举出不同的master,造成数据不一致和应用错误。
-
其实和前面讲的Zookeeper 的奇数节点 + 过半选举机制,是一样的。
合理部署 sentinel 的节点个数,以及配置 sentinel 选举的法定人数。
- sentinel 节点个数最好是基数。个数最好 >= 3。
- sentinel 的选举法定人数设置为 ( N/ 2+1 )。
- 配置
# sentinel.conf
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
4.5:哨兵模式下的 redis master脑裂?
如果在 redis 中,形式上就是有了两个 master,记住两个 master 才是脑裂的前提。
哨兵(sentinel)模式下的脑裂

redission 1 个 master 与 3 个 slave 组成的哨兵模式(哨兵独立部署于其它机器),
刚开始时,2 个应用服务器redission 1、redission 2 都连接在 master 上,
如果 master 客观下线,这时 3 个 slave 其中 1 个经过哨兵投票后,提升为新 master,
如果恰好此时 redission 2 仍然连接的是旧的 master,而redission 1 连接到了新的 master 上, 这就是master 脑裂。
天上有两个太阳。

脑裂之后,就会数据就不一致了,下面有两个例子:
1:比如,如果两个 redission 基于setNX指令的分布式锁,可能会拿到相同的锁,因为这个锁,处于不同的 mater上边 ;
2: 比如,如果两个redission 基于incr生成的全局唯一id,也可能出现重复, 因为这个id, 在不同的master上边。
4.6:如何解决 哨兵模式下的 redis master脑裂?
为了避免脑裂的发生,我们尝试这些方法:

-
设置好 哨兵集群 的节点数(奇数): 确保哨兵数量为奇数,以减少误判的可能性。
-
设置好 哨兵集群 Quorum 配置:设定适当的投票规则,确保过半,并以减少误判的可能性。
-
合理设置超时参数:调整哨兵的
down-after-milliseconds和failover-timeout参数,以适应实际网络环境,减少误判。 -
网络隔离与监控:确保网络稳定,监控网络状态和延迟,以便在问题出现时及时处理。
在Redis Sentinel监控系统中,down-after-milliseconds 和 failover-timeout 是两个重要的参数。
-
down-after-milliseconds 参数:这个参数指定了Redis Sentinel在多少毫秒之后认为一个Redis节点是主观下线(Subjectively Down,简称SDOWN)。
如果一个Redis节点在设定的时间内没有响应Sentinel的PING命令,那么Sentinel就会认为该节点是不可达的。
这个时间间隔可以自定义,但必须谨慎设置,因为如果设置得太短,可能会因为网络瞬时故障而误判Redis节点为下线;如果设置得太长,则可能会延迟故障检测。
例如,如果设置为30000毫秒(即30秒),则在30秒内没有收到节点的响应,Sentinel就会认为该节点是SDOWN 。
-
failover-timeout 参数:这个参数定义了故障转移操作的超时时间。
它用于以下几个方面:
- 同一个Sentinel对同一个master执行两次failover之间的时间间隔。
- 当一个slave开始从一个错误的master同步数据时,直到它被更正为从正确的master同步数据的时间。
- 取消正在进行的failover所需的时间。
- 在执行failover时,配置所有slaves指向新的master所需的最大时间。如果超过这个时间,slaves仍然会被配置为指向新的master,但不会按照
parallel-syncs指定的规则进行 。
正确配置这两个参数对于防止误判和确保故障转移过程顺利进行至关重要。
通常,down-after-milliseconds 应该设置得足够长,以避免因为网络瞬时问题而错误地将节点标记为下线,同时failover-timeout 应该设置得足够长,以确保在发生故障时,所有的slaves都能有足够的时间来响应新的master选举并开始复制操作。
5:集群(cluster)模式下的脑裂
Redis Cluster是Redis自带的分布式解决方案,可以在多个节点之间分配数据,实现高可用性和横向扩展。
Redis Cluster将数据分片存储在不同的节点上,并使用Gossip协议进行节点之间的通信和数据同步。
在Redis Cluster中,当网络分区或节点故障发生时,由于数据被分散在不同的节点上,可以确保数据的一致性。并且Redis Cluster会自动进行故障检测和自动故障转移,确保集群的高可用性。

cluster模式下,这种情况要更复杂,例如集群中有6组分片,每给分片节点都有1主1从,
如果出现网络分区时,各种节点之间的分区组合都有可能。
5.1:什么是 cluster 集群 脑裂
看下面的场景:
-
T1 时刻:如果主节点此时发生网络故障,与从节点断开连接了,但主节点与客户端是正常的,客户端依旧向主节点写入数据。
-
T2 时刻:这时集群其他节点发现主节点 失联了,于是 就会从 从节点选出一个leader作为新主节点,这时脑裂就出现了。
-
T3 时刻:突然这时原主节点网络好了,然而此时故障转移已完毕,已经有新主节点了,新master开始接受客户端的写入
-
T4 时刻:那么原主节点就会降级为新主节点的从节点,新主节点会向所有实例发送slave of命令,让所有实例重新全量同步,在全量同步之前,从节点会先清空自己的数据,那么T1 时刻 客户端在原主节点故障期间写入的数据就丢失了。

5.2:cluster 集群 脑裂 解决方案
脑裂的主要原因其实就是哨兵集群认为主节点出现“假故障”了,于是开始主从切换,选举出了新的主节点,这就导致短暂的出现了两个主节点。
redis集群没有过半机制会有脑裂问题,网络分区导致脑裂后多个master对外提供写服务,一旦网络分区恢复,会将其中一个master变为从节点,这时会有大量数据丢失。
redis集群应对脑裂的解决办法应该是取限制原主库接收请求,Redis提供了两个配置项(已翻译):
# 如果有少于 N 个从节点连接且滞后时间小于或等于 M 秒,主节点可以停止接受写入操作。
# 这些 N 个从节点需要处于“在线”状态。
# 滞后时间必须小于或等于指定值,以秒为单位,是从上次接收到的从节点ping的时间计算出来的,
# 通常每秒发送一次。
# 此选项不能保证 N 个副本会接受写入操作,但会限制在不足够的从节点可用时丢失写入的暴露窗口# 到指定的秒数。
# 例如,要求至少有 3 个滞后时间小于或等于 10 秒的从节点,请使用:
min-slaves-to-write 3
min-slaves-max-lag 10
再解释下:
- min-slaves-to-write:主库能进行数据同步的最少从库数量。
- min-slaves-max-lag:主从进行数据复制时,从库给主库发送ACK消息的最大延迟秒数。
这两项必须同时满足,不然主节点会禁止写入操作,这就解决了因脑裂导致数据丢失的问题。
举个例子,我们把min-slaves-to-write设置为1,把min-slaves-max-lag设置为10。
如果Master节点因为某些原因挂了12s,导致集群判断主节点客观下线,开始主从切换。
同时,因为原Master宕机了12s,没有一个(min-slaves-to-write)从节点与主节点之间的数据复制在10s(min-slaves-max-lag)内,不满足配置要求,原Master就无法执行写操作了。
5.3:min-slaves-to-write 参数实验
假设有一个 3主3从集群模式, 使用下面的设置,来做一个简单实验
min-slaves-to-write 1
这个配置:写数据成功最少同步的slave数量 为1 ,比如 每一个节点有三个slave节点,这里可以配置1
含义就是: 如果配置了min-slaves-to-write,健康的slave的个数小于配置项1 ,mater就禁止写入。
master最少得有1个健康的slave存活才能执行写命令。
这个配置虽然不能保证1个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不能写入来避免数据丢失 。
min-slaves-to-write 设置为0关闭该功能。
min-slaves-to-write 验证过程

配置 min-slaves-to-write 1 , 停掉一个slave (8002),在master(8006)上操作

重启salve节点,

再次试验

注意事项
这个配置在一定程度上会影响集群的可用性,
比如slave要是少于1个,这个集群就算leader正常也不能提供服务了,需要根据具体场景权衡选择。
5.4:为什么cluster 集群 脑裂 不能彻底解决?
可以采用min-slaves-to-write和min-slaves-max-lag合理配置尽量规避 Redis脑裂,但无法彻底解决 Redis脑裂 。
为啥?
官方文档所言,redis 并不能保证强一致性(Redis Cluster is not able to guarantee strong consistency).
Redis + Sentinel 集群,是最终一致性产品( In general Redis + Sentinel as a whole are a an eventually consistent system)
对于要求强一致性的应用,更应该倾向于 传统关系型数据库 如mysql ,或者使用强一致性的 协调组件 Zookeeper。
所以,这又回到 redis 的 天生的 短板: Redis 集群是 AP,而不是CP
说在最后:有问题找老架构取经
Redis 脑裂问题,按照尼恩的梳理,进行 深度回答,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
按照两个层面进行 深度回答,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。
很多小伙伴刷完后, 吊打面试官, 大厂横着走。
在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来改简历、做帮扶。前段时间,刚指导一个27岁 被裁小伙,拿到了一个年薪45W的JD +PDD offer,逆天改命。
狠狠卷,实现 “offer自由” 很容易的, 前段时间一个武汉的跟着尼恩卷了2年的小伙伴, 在极度严寒/痛苦被裁的环境下, offer拿到手软, 实现真正的 “offer自由” 。
技术自由的实现路径:
实现你的 架构自由:
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
实现你的 网络 自由:
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
免费获取11个技术圣经PDF:
