京东面试:mysql分库分表,深度翻页太慢,如何解决?
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、shein 希音、shopee、百度、网易的面试资格,遇到很多很重要的面试题:
mysql分库分表,深度翻页太慢,如何解决?
分库分表后,分页查询太慢了,如何优化?
前几天 小伙伴面试 京东,遇到了这个问题。但是由于 没有回答好,导致面试挂了。
小伙伴面试完了之后,来求助尼恩。
遇到mysql 深度翻页这个问题,该如何才能回答得很漂亮,才能 让面试官刮目相看、口水直流。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典》V145版本PDF集群,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,后台回复:领电子书
单表场景,limit深度分页存在的严重性能问题
大家的业务接口,常常是分页接口,这样的接口,如果碰到深度分页,都会有慢sql性能问题。
一个小伙伴反馈,他们公司今年3月份时候,线上发生一次大事故。主要后端服务器发生宕机,所有接口超时。宕机半小时后,又自动恢复正常。但是过了2小时,又再次发生宕机。
通过接口日志定位,发现MySQL数据库无法响应服务器。
被刷到7000多页,偏移量(offset)高达20w多。
每当这条SQL执行时,数据库CPU直接打满。
查询时间超过1分钟才有响应。
由于慢查询导致数据库CPU使用率爆满,其他业务的数据库请求无法得到及时响应,接口超时。最后,拖垮主服务器。
所以说,limit深度分页存在的严重性能问题。
MySQL Limit 语法格式:
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset- 1
分页查询时,我们会在 LIMIT 后面传两个参数,一个是偏移量(offset),一个是获取的条数(limit)。
当偏移量很小时,查询速度很快,但是当 offset 很大时,查询速度就会变慢。
假设有一张 300w 条数据的表,对其进行分页查询。
select * from user where sex = 'm' order by age limit 1, 10 // 32.8ms
select * from user where sex = 'm' order by age limit 10, 10 // 34.2ms
select * from user where sex = 'm' order by age limit 100, 10 // 35.4ms
select * from user where sex = 'm' order by age limit 1000, 10 // 39.6ms
select * from user where sex = 'm' order by age limit 10000, 10 // 5660ms
select * from user where sex = 'm' order by age limit 100000, 10 // 61.4 秒
select * from user where sex = 'm' order by age limit 1000000, 10 // 273 秒- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到,随着偏移量(offset)的增加,查询时间变得越长。
上例中,当偏移的起始位置超过10万时,分页查询的时间超过61秒。
当偏移量超过100万时,查询时间竟然长达273秒。
对于普通的业务而言,超过1秒的查询是绝对不可以忍受的。
从上例中,我们可以总结出:LIMIT分页查询的时间与偏移量值成正比。
当偏移量越大时,查询时间越长。
这种情况,会随着业务的增加,数据的增多,会越发的明显。那么,如何优化这种情况呢?答案是,索引覆盖。
问题: 为什么 mysql 深度分页会很慢?
包括两层,server层和存储引擎层
server层:查询缓存,解析sql语句生成语法树,执行sql。在执行sql中包括预处理器,优化器和执行器。
-
预处理器:将查询字段展开(如select * 展开为具体字段)并检查字段是否合法
-
优化器:指定sql执行计划,如选择合适的索引
-
执行器:与存储引擎层交互,执行sql语句
存储引擎层 Engine层:如InnoDB和MyISAM。以InnoDB为例,访问B+树数据结构获取记录(聚簇索引,二级索引等的访问都在存储引擎层)

limit在深度翻页场景下变成了: 全表扫描+ 文件排序 filesort
limit 是执行在server 层,而不是innodb层。
也就是说, 在server层 需要获取到 全部的 limit_cout 的结果,在发送给客户端时,才会进行limit操作。
比如如下sql
select * from user where sex = 'm' order by age limit 1000000, 10 // 273 秒- 1
- 2
server 层 在执行器调存储引擎api获取到一条数据时,会查看数据是否是第1000000 以后条数据,如果不是,就不会发送到客户端,只进行limit_cout 计数。
server 层 直到10001才会发送到客户端。也就是说,执行 limit m n语句的场景下, Engine层 实际上也会访问前m条数据,然后返回后n条数据。
正是因为 Engine层 limit会扫描每条记录,因此如果我们查询的字段需要回表扫描,每一次查询都会拿着age列的二级索引查到的主键值去回表,limit 1000000 就会回表1000000 次,效率极低。
所以如果我们使用explain查看查询计划:
explain select * from user where sex = 'm' order by age limit 1000000, 10- 1
其往往不会走age索引,而是全表扫描+filesort,为什么? 因为优化器认为选择age索引的效率,甚至不如全表扫描+文件排序filesort。
所以,当翻页靠后时,查询会变得很慢,因为随着偏移量的增加,我们需要排序和扫描的非目标行数据也会越来越多,这些数据再扫描后都会被丢弃。
单表场景 limit 深度分页 的优化方法
对于LIMIT分页查询的性能优化,主要思路是利用索引覆盖字段定位数据,然后再取出内容。
不使用索引覆盖,查询耗时情况:
SELECT * FROM `tbl_works` WHERE `status`=1 LIMIT 100000, 10 // 78.3 秒- 1
1)子查询分页方式
SELECT * FROM tbl_works
WHERE id >= (SELECT id FROM tbl_works limit 100000, 1)
LIMIT 20 // 54ms- 1
- 2
- 3
子查询分页方式,首先通过子查询和索引覆盖定位到起始位置ID,然后再取所需条数的数据。
缺点是,不适用于结果集不以ID连续自增的分页场景。
在复杂分页场景,往往需要通过过滤条件,筛选到符合条件的ID,此时的ID是离散且不连续的。
如果使用上述的方式,并不能筛选出目标数据。
当然,我们也可以对此方法做一些改进,首先利用子查询获取目标分页的 ids,然后再根据 ids 获取内容。
根据直觉将SQL改造如下:
SELECT * FROM tbl_works
WHERE id IN (SELECT id FROM tbl_works limit 100000, 10)
// 错误信息:
// This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'- 1
- 2
- 3
- 4
- 5
然而,并不尽人意。我们得到一个错误提示。
错误信息的含义是,子查询不能有 limit操作。于是,我们对SQL进行了改造,对子查询包了一层:
SELECT t1.* FROM tbl_works t1
WHERE t1.id in (SELECT t2.id from (SELECT id FROM tbl_works limit 100000, 10) as t2) // 53.9ms- 1
- 2
执行成功,且查询效率很高。
但是,这种写法非常繁琐。
我们可以使用下面的 join 分页方式,达到相同的优化效果。实际上,两者的原理是相同的。
2)join 分页方式
SELECT * FROM tbl_works t1
JOIN (SELECT id from tbl_works WHERE status=1 limit 100000, 10) t2
ON t1.id = t2.id // 53.6 ms- 1
- 2
- 3
这条SQL的含义是,通过自连接与join定位到目标 ids,然后再将数据取出。
在定位目标 ids时,由于 SELECT的元素只有主键 ID,且status 存在索引,因此MySQL只需在索引中,就能定位到目标 ids,不用在数据文件上进行查找。
因而,查询效率非常高。
索引覆盖(Cover Index)
如果索引包含所有满足查询需要的数据的索引,成为索引覆盖(Covering Index),也就是平时所说的不需要回表操作。
索引覆盖(Index Covering)是指一个查询可以完全通过索引来执行,而无需访问实际的数据行。
在数据库中,通常查询语句包含了一系列的条件,这些条件用于筛选出符合特定条件的数据行。
如果这些条件能够通过索引直接定位到符合条件的数据行,而无需访问实际的数据页,那么就称为索引覆盖。
比如我们有这样一条SQL语句:
select name,age,level from user where name = "AAA" and age 17- 1
那么,我们添加一个联合索引,覆盖所有的查询内容, 联合索引如下
key `idx_nal` (`name`,`age`,`level`) using btree- 1
有了这个联合索引,我们在搜索的时候,只需要通过索引就能够拿到我们需要的全部数据了。
简单的说,索引覆盖覆盖所有需要查询的字段(即,大于或等于所查询的字段)。MySQL可以通过索引获取查询数据, 这样就避免了回表,不需要读取数据行。
索引覆盖注意事项:
1.如果一个索引包含了需要查询的所有字段,那么这个索引就是覆盖索引。
2.MySQL 只能使用B+Tree索引做覆盖索引,因为只有B+树能存储索引列值
索引覆盖的好处:
- 索引大小远小于数据行大小。因而,如果只读取索引,则能极大减少对数据访问量。
- 索引按顺序储存。对于IO密集型的范围查询会比随机从磁盘读取每一行数据的IO要少。
- 避免对主键索引的二次查询。二级索引的叶子节点包含了主键的值,如果二级索引包含所要查询的值,则能避免二次查询主键索引(聚簇索引,聚簇索引既存储了索引,也储存了值)。
单表场景 limit 深度分页 总结
通过利用索引覆盖,能极大的优化了Limit分页查询的效率。
在真正的实践中,除了使用索引覆盖,优化查询速度外,我们还可以使用 Redis 缓存,将热点数据进行缓存储存。
背景描述的事故,我们考虑了时间成本和业务复杂度后,最后采取的是限制分页和增加缓存。
所谓的限制分页,即在不影响阅读体验的前提下,只允许用户可以查看前几千条的数据。
经测验,偏移量较小时的查询效率较令人满意,查询效率接近使用索引覆盖查询的速度。
分表场景,limit深度分页存在的严重性能问题
大家知道 ,当一个表(比如订单表) 达到500万条或2GB时,需要考虑水平分表。
具体请参见尼恩架构团队的文章:
比如大型的电商系统中的订单服务,业务量很少时,单库单表基本扛得住,但是随着时间推移,数据量越来越多,订单服务在读写的性能上逐渐变差。
这个时候,选择了分库分表;至于如何拆分,分片键如何选择等等细节。 请看尼恩的文章:
100亿级数据存储架构:MYSQL双写 + HABSE +Flink +ES综合大实操
这里也介绍是,是Sharding-JDBC 的 limit深度分页 执行逻辑和性能问题。
Sharding-JDBC从多个分表获取分页数据,与单表分页的执行逻辑,本质是不同的。
分表分页场景下的 分页逻辑, 并不是: 简单的去 每个分表取到同样的数量的数据, 简单归并+挑选 。
分表分页场景下的 分页逻辑,要从 0开始去每一个分表 获取到 limit 全部的数据, 而不是从offset 开始。
如果是深度分页, 比如说:
select * from user where sex = 'm' order by age limit 1000000, 10 // 273 秒- 1
- 2
那么要去每一个 分表 获取到 limit 全部的1000000 + 10 条 数据 , 会导致每一个分表都走 全表扫描+ 文件排序 filesort , 每一个分表的性能都很低。
当然,尼恩在这里带大家首先要解决的问题是: 为什么 表分页场景下的 分页逻辑,要从 0开始去每一个分表 获取到 limit 全部的数据, 而不是从offset 开始。
假设每10条数据为一页,取第2页数据。
在分片环境下获取LIMIT 10, 10,归并之后再根据排序条件取出前10条数据是不正确的。
举例说明,若SQL为:
SELECT score FROM t_score ORDER BY score DESC LIMIT 1, 2;- 1
下图展示了不进行SQL的改写的分页执行结果:
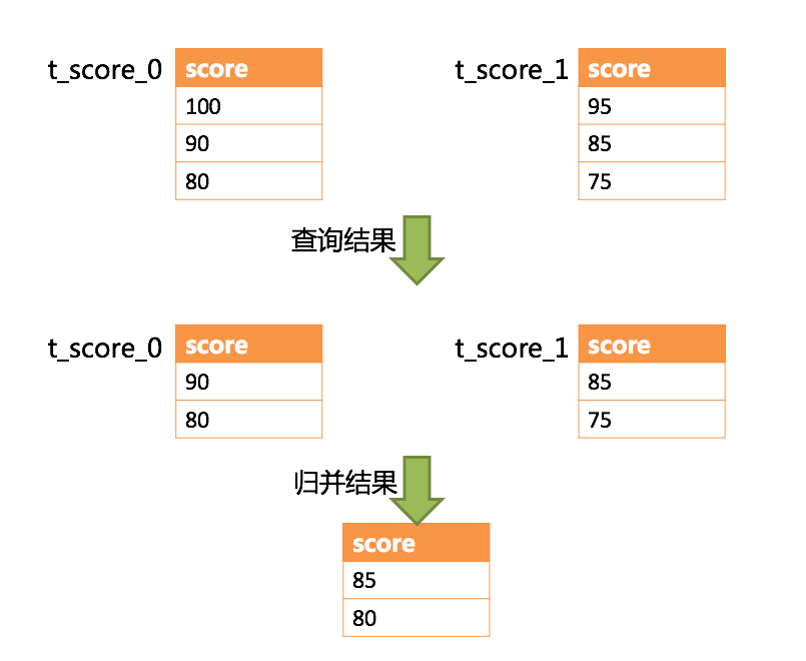
通过图中所示,想要取得两个表中共同的按照分数排序的第2条和第3条数据,理论上,应该是95和90。
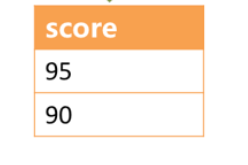
实际上呢?
由于执行的SQL只能从每个表中获取第2条和第3条数据,即:
-
从t_score_0表中获取的是90和80;
-
从t_score_0表中获取的是85和75。
因此进行结果归并时,只能从获取的90,80,85和75之中进行归并,那么,无论怎么实现,结果归并之后,都不可能获得正确的结果。
正确的做法:
是将分页条件改写为LIMIT 0, 3,取出所有前两页数据,再结合排序条件计算出正确的数据。
下图展示了进行SQL改写之后的分页执行结果。

回到问题: 为什么 表分页场景下的 分页逻辑,要从 0开始去每一个分表 获取到 limit 全部的数据, 而不是从offset 开始。
答案是: 为了合并之后的结果不出错,每一个分表的查询是必须0开始, 归并之后的结果才不会错。
分表场景下 功能和性能的冲突:从0开始的性能瓶颈
注意,这里有个大问题:
为了结果不出错,归并之前的查询,是0开始, 结果才可能是对的。
所以,询偏移量过大的分页会导致数据库获取数据性能低下,
以MySQL为例:

如果不是分库分表,这句SQL会使得MySQL在无法利用索引的情况下跳过1000000条记录后,再获取10条记录,其性能可想而知。
然而, 在分库分表的情况下(假设分为2个库),为了保证数据的正确性,SQL会改写为:

所以, 分库分表场景, Sharding-JDBC 需要将偏移量前的记录全部取出,归并排序后,挑选最后10条记录。
这会在数据库本身就执行很慢的情况下,进一步加剧性能瓶颈。
因为原SQL仅需要传输10条记录至客户端,而改写之后的SQL则会传输1,000,010 * 2的记录至客户端。
Sharding-JDBC的性能优化措施
那么,Sharding-JDBC会将全量的记录(如1,000,010 * 2 记录) 都全部加载至内存吗?
不会,这样加载,会占用大量内存而导致内存溢出。
Sharding-JDBC 知道了问题所在,本身也会做优化。
Sharding-JDBC的性能优化措施,主要如下:
(1)采用流式处理 + 归并排序的方式来避免内存的过量占用。
由于SQL改写不可避免的占用了额外的带宽,但并不会导致内存暴涨。
与直觉不同,大多数人认为Sharding-JDBC会将1,000,010 * 2记录全部加载至内存,进而占用大量内存而导致内存溢出。
但由于每个结果集的记录是有序的,因此Sharding-JDBC每次仅获取各个分片的当前结果集记录,驻留在内存中的记录仅为当前路由到的分片的结果集的当前游标指向而已。
对于本身即有序的待排序对象,归并排序的时间复杂度仅为O(n),性能损耗很小。
(2)Sharding-JDBC对仅落至多分片的查询进行进一步优化。
落至单分片查询的请求并不需要改写SQL也可以保证记录的正确性,因此在此种情况下,Sharding-JDBC并未进行SQL改写,从而达到节省带宽的目的。
一般情况下,性能慢,都是第一种情况。
当然,流式查询的也是有弊端的
采用游标查询的方式的缺点很明显。
流式(游标)查询需要注意:当前查询会独占连接!
必须先读取(或关闭)结果集中的所有行,然后才能对连接发出任何其他查询,否则将引发异常!
执行一个流式查询后,数据库访问框架就不负责关闭数据库连接了,需要应用在取完数据后需要自己关闭。
由于MySQL_Server不知道客户端什么时候将数据消费完,而自身的对应表可能会有DML写入操作,此时MySQL_Server需要建立一个临时空间来存放需要拿走的数据。
因此对于当你启用useCursorFetch 读取 大表的时候,会看到MySQL上的几个现象:
-
IOPS 飙升,因为需要返回的数据需要写入到临时空间中,存在大量的 IO 读取和写入,此流程可能会引起其它业务的写入抖动
-
磁盘空间飙升,写入临时空间的数据会在读取完成或客户端发起 ResultSet#close 操作时由 MySQL_Server 回收
-
客户端 JDBC 发起sql_query,可能会有长时间等待,这段时间为MySQL_Server准备数据阶段。
但是 普通查询等待时间与游标查询等待时间原理上是不一致的: 前者是在读取网络缓冲区的数据,没有响应到业务层面;后者是 MySQL 在准备临时数据空间,没有响应到 JDBC
-
数据准备完成后,进行到传输数据阶段,网络响应开始飙升,IOPS 由"写"转变为"读"
分表场景+大表场景,limit严重性能问题 如何解决?
虽然有流式查询,但是分表场景+大表场景,limit深度翻页还是存在的严重性能问题 ,基本上是分页越大后续的查询越耗资源并且越慢,如何解决呢?
优化方案1: 禁止跳页查询法
由于LIMIT并不能通过索引查询数据,
因此如果可以保证ID的连续性,通过ID进行分页是比较好的解决方案:

或者:通过记录上次查询结果的最后一条记录的ID,进行下一页的查询:

如果不是id列, 假设排序的列为col,禁止跳页查询法的两个步骤大致如下:
(1)用正常的方法取得第一页数据,并得到第一页记录的 max_col 最大值;
(2)每次翻页,将 order by col offset X limit Y; 改写成 下面的语句
order by col where col>$max_col limit Y;- 1
以保证每次只返回一页数据,性能为常量。
优化方法2:二次查询法
假设排序的列为col,二次查询法的两个步骤大致如下:
(1)分页偏移量平均 offset/N(分片数) ,将 order by col offset X limit Y; 改写成
order by col offset X/N limit Y;- 1
(2)多页返回,找到最小值col_min 和 最大 值 col_max;
(3)between二次查询
order by col between col_min and col_i_max;- 1
(4)设置虚拟col_min,找到col_min在各个分表的offset,从而得到col_min在全局的offset;
(5)得到了col_min在全局的offset,自然得到了全局的offset X limit Y;
二次查询法的一个例子
例子:分表结构
CREATE TABLE `student_time_0` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`name` varchar(200) COLLATE utf8_bin DEFAULT NULL,
`age` tinyint(3) unsigned DEFAULT NULL,
`create_time` bigint(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=674 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
有这样的三个表
student_time_0,student_time_1,student_time_2,
以 user_id 作为分表键,根据表数量取模作为分表依据
这里先构造点数据,
insert into student_time (`name`, `user_id`, `age`, `create_time`) values (?, ?, ?, ?)- 1
主要是为了保证 create_time 唯一,比较好说明问题,
int i = 0;
try (
Connection conn = dataSource.getConnection();
PreparedStatement ps = conn.prepareStatement(insertSql)) {
do {
ps.setString(1, localName + new Random().nextInt(100));
ps.setLong(2, 10086L + (new Random().nextInt(100)));
ps.setInt(3, 18);
ps.setLong(4, new Date().getTime());
int result = ps.executeUpdate();
LOGGER.info("current execute result: {}", result);
Thread.sleep(new Random().nextInt(100));
i++;
} while (i <= 2000);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
三个表的数据分别是 673,678,650,各个表数据不一样,
接下来,做一个这样的分页查询
select * from student_time ORDER BY create_time ASC limit 1000, 5;- 1
student_time 对于我们使用的 sharding-jdbc 来说当然是逻辑表, sharding-jdbc 会改写为
select * from student_time ORDER BY create_time ASC limit 0, 1005;- 1
即使如 sharding-jdbc 对于合并排序的优化做得比较好,也还是需要传输那么大量的数据,并且查询也耗时,那么有没有解决方案呢
- 第一个办法禁止跳页,而是只给下一页,那么我们就能把前一次的最大偏移量的 create_time 记录下来,下一页就可以拿着这个偏移量进行查询
- 第二个办法是二次查询法
这个办法的第一步跟前面那个错误的方法或者说不准确的方法一样,先是将分页偏移量平均 1000/3 = 333,根据这个 limit 333,5 在三个表里进行查询
t0
334 10158 nick95 18 1641548941767
335 10098 nick11 18 1641548941879
336 10167 nick51 18 1641548942089
337 10167 nick3 18 1641548942119
338 10170 nick57 18 1641548942169
t1
334 10105 nick98 18 1641548939071 最小
335 10174 nick94 18 1641548939377
336 10129 nick85 18 1641548939442
337 10141 nick84 18 1641548939480
338 10096 nick74 18 1641548939668
t2
334 10184 nick11 18 1641548945075
335 10109 nick93 18 1641548945382
336 10181 nick41 18 1641548945583
337 10130 nick80 18 1641548945993
338 10184 nick19 18 1641548946294 最大- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
第一遍的目标是啥,查出来的最小的 create_time 和最大的 create_time 找出来,然后再去三个表里查询,
其实主要是最小值,因为拿着最小值去查,就能知道这个最小值在每个表里处在什么位置,
order by col between col_min and col_i_max;- 1
接下来,将第一遍查出来的最小的 create_time 和最大的 create_time 找出来,然后再去三个表里查询,
t0
322 10161 nick81 18 1641548939284
323 10113 nick16 18 1641548939393
324 10110 nick56 18 1641548939577
325 10116 nick69 18 1641548939588
326 10173 nick51 18 1641548939646
t1
334 10105 nick98 18 1641548939071
335 10174 nick94 18 1641548939377
336 10129 nick85 18 1641548939442
337 10141 nick84 18 1641548939480
338 10096 nick74 18 1641548939668
t2
297 10136 nick28 18 1641548939161
298 10142 nick68 18 1641548939177
299 10124 nick41 18 1641548939237
300 10148 nick87 18 1641548939510
301 10169 nick23 18 1641548939715- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这里只贴了前五条数据,为了方便知道偏移量,每个分表都使用了自增主键,
我们可以看到前一次查询的最小值分别在其他两个表里的位置分别是 322-1 和 297-1,
那么,对于总体来说,这个时间的起始位置,应该是在 322 - 1 + 334-1 + 297 - 1 = 951,
那么,只要对后面的数据最多每个表查 1000 - 951 + 5 = 54 条数据,再进行合并排序就可以获得最终正确的结果。
这个就是的二次查询法。
可见,二次查询法很麻烦, 不如禁止跳页法,或者 es组合方法,直接,有效。
优化方案3:使用 ES+HBASE 海量NOSQL架构方案
对于海量数据场景,建议使用 ES+HBASE 这样的 海量NOSQL架构方案,具体如下:
100亿级数据存储架构:MYSQL双写 + HABSE +Flink +ES综合大实操
100亿级任务调度篇:从0到1, 从入门到 XXLJOB 工业级使用
高并发搜索ES圣经:从0到1, 从入门到 ElasticSearch 工业级使用
超级底层:10WQPS/PB级海量存储HBase/RocksDB,底层LSM结构是什么?
说在最后:有问题找老架构取经,
通过这个问题的深度回答,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。
很多小伙伴刷完后, 吊打面试官, 大厂横着走。
在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来改简历、做帮扶。
遇到职业难题,找老架构取经, 可以省去太多的折腾,省去太多的弯路。
尼恩指导了大量的小伙伴上岸,前段时间,刚指导一个40岁+被裁小伙伴,拿到了一个年薪100W的offer。
狠狠卷,实现 “offer自由” 很容易的, 前段时间一个武汉的跟着尼恩卷了2年的小伙伴, 在极度严寒/痛苦被裁的环境下, offer拿到手软, 实现真正的 “offer自由” 。
另外,尼恩也给一线企业提供 《DDD 的架构落地》企业内部培训,目前给不少企业做过内部的咨询和培训,效果非常好。

尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
标签:分库,分页,翻页,18,查询,索引,limit,mysql,分表 From: https://www.cnblogs.com/fanwenyan/p/18372913《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓