- MySQL约束

注释
-- 单行注释 /*多行注释*/ # 井号注释MySQL命令执行顺序
FROM > ON > JOIN WHERE > GROUP BY > HAVING + 聚合函数 > SELECT > ORDER BY > LIMIT数据库设计——DDL
show databases; -- 查看当前所有的数据库 use [数据库名]; -- 打开指定的数据库 show tables; -- 查看所有的表 describe/desc [表名]; -- 显示表的信息 create database [数据库名]; -- 创建一个数据库,不容许重名 select database(); -- 查看当前操作的数据库 exit -- 退出连接数据库
/*创建数据库*/ CREATE DATABASE [if not exists] db_name CHARACTER SET gbk COLLATE gbk_chinese_ci; /*修改数据库*/ ALTER DATABASE db_name [CHARACTER SET gbk] -- 可选 [COLLATE gbk_chinese_ci]; -- 可选 /*删除数据库*/ DROP DATABASE [if exists] db_name;表
- CREATE 创建表
/*基本格式*/ CREATE TABLE [if not exists] tb_name( 字段名 字段类型 [约束] [auto_increment] [comment "备注"], stu_code char(10) not null primary key, name char(10) not null, gender tinyint(1) not null )CHARACTER SET 字符集 COLLATE 校对规则 ENGINE 引擎; /*复制其他表*/ CREATE TABLE stu1 LIKE stu2; 或 CREATE TABLE stu1 AS (SELECT * FROM stu2); -- 后者仅复制表的数据
- ALTER 修改表
/*基本格式*/ ALTER TABLE t_name ['选项']; -- 若要同时进行多个操作,只需将每个选项用','隔开 /*选项:*/ -- 1.插入新列,FIRST|AFTER用于指明新列插入的位置 ADD 列定义1 [FIRST|AFTER 列名], ADD 列定义2 [FIRST|AFTER 列名], ... ; -- 2.更改表中某列的默认值或删除默认值,花括号不用写 ALTER 列名 SET DEFAULT 默认值; 或 DROP DEFAULT; -- 3.更改列名,必须指定类型 CHANGE oldname newname 类型 [FIRST|AFTER 列名], CHANGE ...; -- 4.修改列属性 MODIFY 列定义1 [FIRST|AFTER 列名], MODIFY ...; -- 5.删除列 DROP 列名; -- 6.表重命名 RENAME 新表名; {不用ALTER:RENAME TABLE 旧表名 TO 新表名;} -- 7.按某列排序 ORDER BY 列名;数据库操作语句——DML
- INSERT 插入一个新记录到表里面
/*往表中插入单条或多条记录(不指定字段默认包含全部字段)*/ INSERT INTO 表名[(字段列表)] VALUES (属性1,属性2...属性n), (...); -- 将'表1'数据插入'表2'中 INSERT INTO 表2 SELECT * FROM 表1;
- UPDATE 修改基本表中的记录
/*基本格式*/ UPDATE [LOW_PRIORITY] [IGNORE] 表名 SET 字段1=expr1 [,字段2=expr2 ...] [WHERE 条件] -- 不加条件默认修改所有记录 [ORDER BY ...] [LIMIT row_count];
- DELETE 删除基本表中的记录
/*基本格式*/ DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM 表名 [WHERE 条件] [ORDER BY ...] [LIMIT row_count]; /*清除所有记录*/ DELETE FROM 表名; | TRUNCATE TABLE 表名;数据库查询语句——DQL
/*基本格式*/ SELECT [ALL | DISTINCT] {* | table.* | [table.field1[as alias1][,table.field2[as alias2][,...]]} -- 要查询的字段 FROM tb_name [as table_alias] [left | right | inner join table_name2] -- 联合查询 [WHERE ...] -- 指定结果需满足的条件 [GROUP BY ...] -- 指定结果按照哪几个字段来分组 [HAVING] -- 过滤分组后的记录必须满足的次要条件 [ORDER BY 字段 排序方式, ...] -- 排序查询 [LIMIT {[offset,]row_count | row_countOFFSET offset}]; -- 分页查询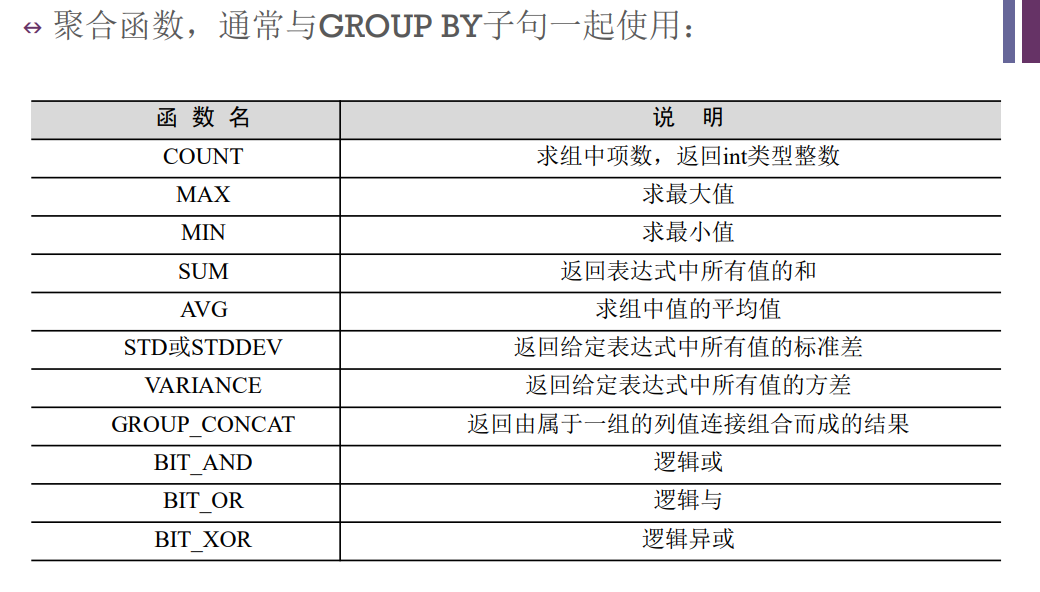
- 1、单表查询
SELECT 字段1,字段2,..,字段n FROM 表1; /*查询整张表的记录*/ SELECT * FROM 表名; /*别名--字段和表均可起别名,给表起别名可以方便SELECT语句的编写*/ SELECT studentkey AS 学号,name AS 姓名 FROM stu AS 学生表; /*聚合函数*/ SELECT COUNT(*) AS 学生人数 FROM stu; -- C OUNT()不计入条件值为NULL的记录
- 条件查询——WHERE子句
关于
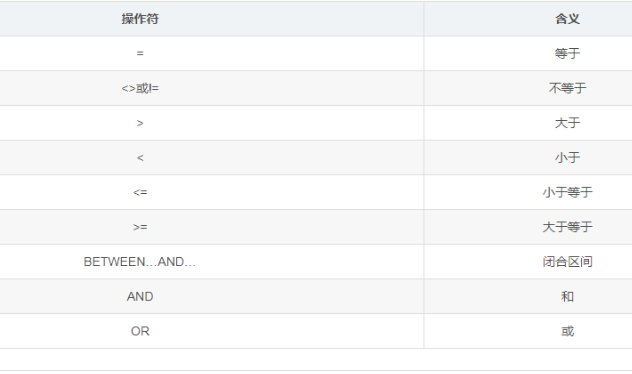
WHERE的条件语句:/*逻辑判断*/ AND--&& OR--||,NOT和!不能直接替换 SELECT 属性列表 FROM 表名 WHERE [筛选条件]; 例1:使用聚合函数,查询表score中101课程的最高分和最低分(成绩字段--result,编号字段--courseid) SELECT MAX(result),MIN(result) FROM score WHERE courseid='101'; /*模式匹配符`%`和`_`,通常与LIKE搭配使用*/ % 可以指代多个字符 _ 则只能指代一个字符 例子:查询名字倒数第二个字为d的同学 SELECT `StudentNo`,`StudentName` FROM student WHERE `StudentName` LIKE '%d_'; /*NULL值判断,如果符合则返回true,否则返回false*/ WHERE 字段 IS NULL WHERE 字段 IS NOT NULL /*枚举查询 IN,NOT IN*/ - IN (属性1,属性2...属性n):查找字段值在属性表中匹配的记录 - NOT IN (...):查找与属性表中不匹配的记录 【注】:枚举查询优化较差,通常使用其他语句代替
- 3、分组查询——GROUP BY子句
/*PS: 分组之后SELECT返回的字段主要包含两类: a. 分组的字段 b. 聚合函数 */ 例1:使用HAVING子句,查找平均成绩在85分以上的学生的学号和平均成绩 SELECT studentkey,AVG(result) FROM score GROUP BY studentkey HAVING AVG(result)>=85; -- 关于WHERE和HAVING子句:HAVING用于分组后再筛选,而WHERE用于分组前查询
- 4、排序查询
/* asc 升序 desc 降序 指定查询的结果按一个或多个条件排序,默认升序,并且当前面字段相同时,才会根据后面的字段排序 */ SELECT *|字段 FROM 表名 ORDER BY 字段1 排序方式, ...;
- 5、分页查询
/* :指定查询的记录从哪条至哪条 - 不包含起始索引,起始索引默认从0开始 - 每页的起始索引 = (查询页号 - 1) * 每页记录数 */ SELECT 字段列表 FROM 表名 LIMIT 起始索引,每页记录数;
- 6、MySQL中的流程控制
/*if语句*/ select if(gender=1,'男性员工','女性员工') '性别',count(*) from tb_emp group by gender; /*case-when-else-end语句*/ select (case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管' when 4 then '教导主任' else 'null' end) as 职位,count(*) from tb_emp group by job;连接查询(多表关联查询)
t1 m n t2 m n i1 1 a j1 2 b i2 2 b j2 3 c i3 3 c j3 4 d
- 常用格式
SELECT 字段列表|* FROM 表1 {INNER | LEFT | RIGHT} JOIN 表2 ON 表1.字段x=表2.字段y WHERE 筛选条件; # where用于连接查询后再筛选
- 1、内连接--INNER JOIN
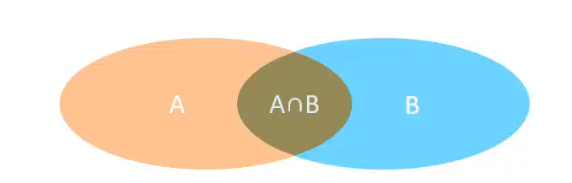
-- 最后返回的结果是两张表同时存在的数据行数,只存在于单张表的数据行并不会返回 例1: SELECT * FROM t1 INNER JOIN t2 ON t1.m=t2.m; ->返回结果:2 | b、3 | c
- 2、外连接
/*外连接之左外连接--LEFT JOIN*/ # 以JOIN左边的表为'主表',右边的为'从表',返回的数据行数以left表为行数,拼接右表中匹配的字段 # 对于左表中的数据行,当右表无匹配时,通常以NULL填充 例2: SELECT * FROM t1 LEFT JOIN t2 ON t1.m=t2.m; ->返回结果:i2|j1 ; i3|j2 ; i1|NULL /*外连接之右外连接--RIGHT JOIN*/ # 以JOIN右边的表为主表,左边的为从表 例3: SELECT * FROM t1 RIGHT JOIN t2 ON t1.m=t2.m; ->返回结果:i2|j1 ; i3|j2 ; NULL|j3
- 3、自连接
自连接即自己和自己连接,相当于和另一张副本表连接 SELECT a.`courseid` AS '父课程',b.`courseid` AS '子课程' FROM course AS a,course AS b WHERE a.`courseid`=b.`pid`;子查询
- 单行子查询
=等于,>大于,>=大于等于,<小于,<=小于等于,!=|<>不等于 -- 查找薪水大于所有员工平均薪水的员工 SELECT employee_id, first_name, last_name, salary FROM employees WHERE salary > ( SELECT AVG(salary) FROM employees); /*子查询返回结果为单行多列*/ -- 查询tb_emp表中'入职日期'、'岗位'都与'张三'相同的员工信息 SELECT * FROM tb_emp WHERE (entrydate,job)= (select entrydate,job FROM tb_emp WHERE name="张三")
- 多行子查询
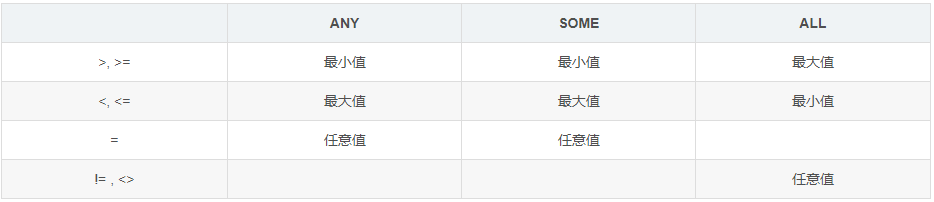
/* [NOT] IN: [不]等于子查询返回值中的任意一个 ANY: 需与单行比较操作符一起使用,表示至少或任一 ALL: 需与单行比较操作符一起使用,表示与子查询的所有值进行比较 */ -- 例1: 返回其它job id中比job id为'IT_PROG’部门任一工资低的员工的员工号姓名、job id以及salary select last_name,job_id,salary from employees where salary < any ( select salary from employees where job_id = 'IT_PROG' ) and job_id <> 'IT_PROG'; -- 例2:将子查询作为一张'临时表'使用 查询入职日期是"2006-01-01"之后的员工信息,及其部门名称 select e.*,d.name from (select * from tb_emp where entrydate > '2006-01-01') e, tb_dept d where e.dept_id=d.id;事务
/*一个事务是一组操作,要么一起成功,要么一起失败,当一个事务中的某次执行失败时,可以通过回滚来恢复数据,当事务执行失败时,不会影响原表中的数据,操作的结果只会作用于当前界面内的副本,保持了事务的一致性*/ begin ; delete from tb_dept where name='学工部'; delete from tb_emp where id=1; select * from tb_dept; commit ; rollback ;
- 四大特性
数据库的优化——索引
索引(index)是帮助数据库
高效获取数据的数据结构,使用空间来换时间,同时也降低了增删改的效率
- 索引结构
默认是
B+树(多路平衡搜索树)结构组织的索引/*主键、唯一约束都会默认创建一个索引,主键索引是性能最高的*/ -- 创建索引 create [unique] index 索引名 on 表名(字段1,...) -- 查看索引 show index from 表名 -- 删除索引 drop index 索引名 on 表名




# 限定查询 LIMIT
- LIMIT n; //只返回查询结果的前n行记录
- LIMIT offset,length; //返回从下标为offset处开始查询,往后的length行记录
- 分页查询公式: LIMIT (pageCount-1)*rowsCount,rowsCount;
pageCount:页码 rowsCount:每页数据行数
## 联合查询 UNION和UNION ALL
UNION-- 自动去除重复行
UNION ALL-- 不去除重复行
【注】:使用UNION时上下 SELECT子句中字段数必须相同
## 唯一 UNIQUE
约束字段值不可重复,但 NULL 值不受约束
## 主键 PRIMARY KEY
唯一+非空:主键修饰的字段不可为空
CREATE TABLE t1
(id int NOT NULL PRIMARY KEY,
...
); 或者
CREATE TABLE t1
(id int NOT NULL,
...,
PRIMARY KEY(id) /*写在字段声明语句的后面*/
);
## 自增长 AUTO_INCREMENT
/*
1.使用auto_increment的字段必须是一个键:UNIQUE | PRIMARY KEY
2.自增长值默认从1开始
3.auto_increment修饰字段可以显式指定字段值,只要满足唯一非空约束即可,且如果字段值>自增长值,则直接将字段值赋值给当前自增长值
4.使用delete删除记录并不会影响自增长值
5.使用'TRUNCATE 表名;'可以删除整表记录,并重置自增长计数器
*/
CREATE TABLE t1(
id int(11) NOT NULL UNIQUE|PRIMARY KEY AUTO_INCREMENT,
...
);
## 外键
/*外键可连接两张表,从而使两张表中的同一个字段同步,进行约束*/
常用格式:
CREATE TABLE t1(
...,
CONSTRAINT 外键名 FOREIGN KEY(cuorseid) cuorseid REFERENCES t2(id),
-- 字段1为当前表中作为外键约束的数据
-- 选择作为外键约束的主表t2的字段id
...
);
【注】
# 外键约束有利有弊
# 优势:
# 1. 添加数据有条件约束,防止添加错误
# 2. 删除数据有条件约束,防止误删
# 劣势:
# 1. 整个数据库成为一坨,操作不便
# 2. 外键约束会降低【数据库】的性能
# 3. 羁绊过多,耦合度太高了
# 心中有外键思想,数据库无外键约束