接触MySQL数据库的小伙伴一定避不开索引,索引的出现是为了提高数据查询的效率,就像书的目录一样。
某一个SQL查询比较慢,你第一时间想到的就是“给某个字段加个索引吧”,那么索引是什么?是如何工作的呢?一起静下心来,耐心看完这篇文章吧,干货不啰嗦,相信你一定会有所收获。
一、索引模型
模型也就是数据结构,常见的三种模型分别是哈希表、有序数组和搜索树。
了解MySQL的朋友已经知道,现在MySQL默认使用的是InnoDB存储引擎,使用的是B+树索引数据结构。所以这个话题我们简单介绍,不作过多篇幅解释,只需了解为什么InnoDB选择B+树作为索引的数据结构。
1.1 哈希表
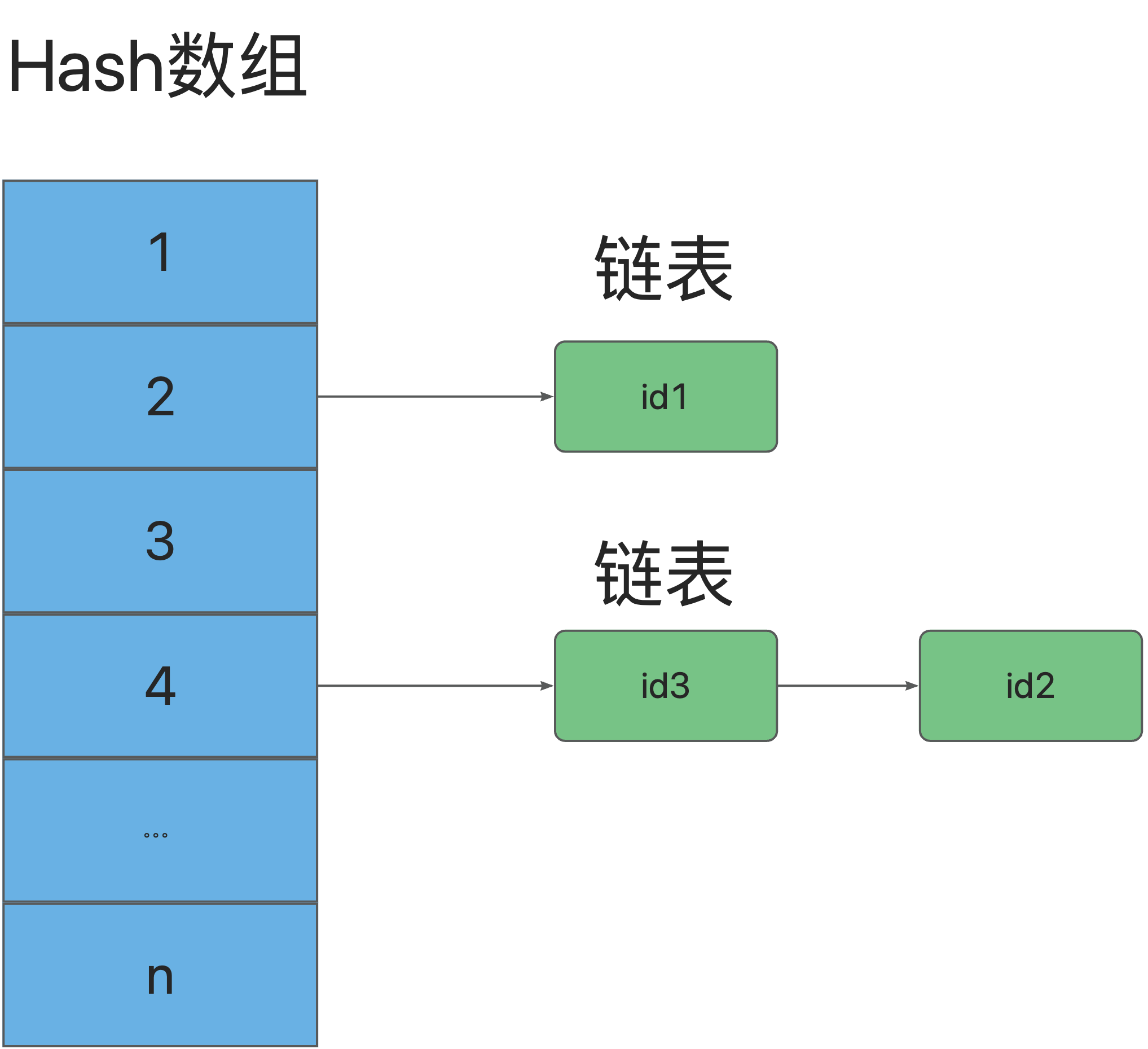
key-value键值对存储结构,哈希思路非常easy,给定key,通过哈希函数命中value。了解HashMap的都知道,哈希表不可避免的会发生同值冲突,所以需要通过链表跟在数组后面。
哈希表的特点是插入速度很快,只需要通过hash找到对应数组,发生冲突就在链表往后追加。但缺点也正是因为无序,导致查询速度很慢,几乎全部扫描一遍。
1.2 有序数组
有序数组非常简单,递增顺序保存。查询时可以使用二分法,时间复杂度O(log(N)),但是更新数据就很麻烦,往中间插入一个数据就必须挪动后面所有的记录,成本很高。

1.3 B+树
B+树衍生于二叉搜索树,没错,大学数据结构中的二叉搜索树,课堂的熟悉感是不是都回来了~
二叉搜索树的特点是:每个节点的左儿子小于父节点,右儿子大于父节点。所以查询搜索的时间复杂度是O(log(N)),为了维持O(log(N))查询复杂度,需要保证这棵树是平衡二叉树,所以更新的时间复杂度也是O(log(N))。
但是平衡二叉树的缺点在于随着数据的增加,整棵树的层级越来越高,考虑叶子节点的数据总是在内存中,那么树层级越多意味着需要多次的磁盘寻址。一棵100万数据量节点的平衡二叉树,树高H=log2(N+1) - 1=log2(1000000+1)-1=20,一次查询可能需要访问20个数据节点,磁盘随机读一个数据块大约10ms,总计需要20个10ms时间找到一行数据,难以接受!
为了减少尽量少的读磁盘,二叉树就演变为了N叉树,N是多少,取决于数据块的大小。如果MySQL数据表中你创建了一个整数类型的索引,这个N差不多是1200,树高是4时,整棵树可以存储1200的3次方,也就是17亿数据,查找一个数据只需要访问3次磁盘,很nice~
二、索引维护
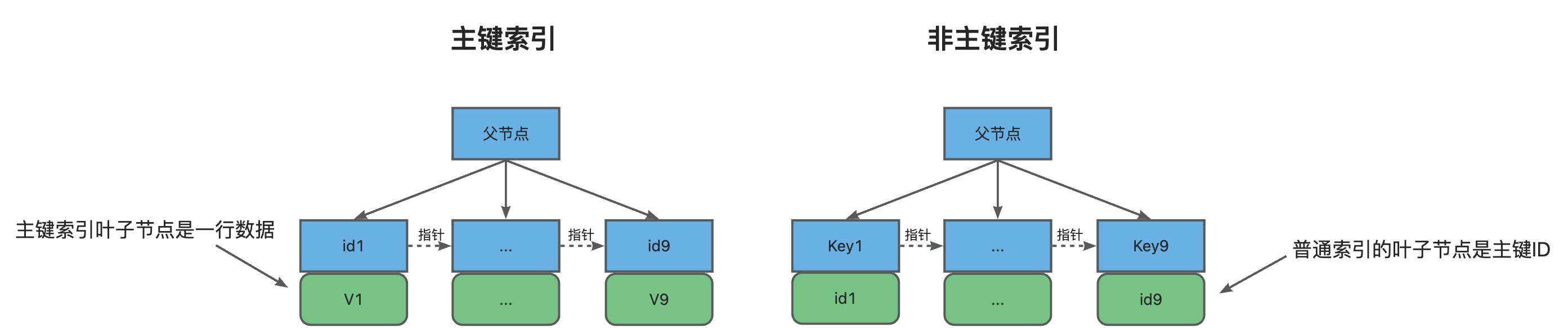
每个索引在InnoDB中都对应一棵B+树。
根据叶子节点的内容,索引类型分为主键索引和非主键索引。主键索引又称为聚簇索引,叶子节点中存储的是整行数据。
非主键索引的叶子节点中存储的是主键的值。所以,如果你的SQL语句查询时用到的索引不是主键,那么就会有一次普通索引找到叶子节点中的主键ID,再进行回表获取数据。因此,我们在查询时应尽量使用主键查询。
B+树为了维护索引有序性,是有代价的,如果新插入的数据在数据页中有空位置且后面没有数据,可以直接插入;如果在500和700中间插入600,则需要挪动700及后面的数据,空出位置;更糟糕的是,如果数据页已经满了,则需要新申请一个新的数据页,然后挪动数据,这就是页分裂。有分裂就有合并,对应的就是删除数据场景。性能很受影响!
从性能角度看,如果采用主键自增刚好符合索引有序的特点,每次插入数据都是追加,不会挪动数据也不会触发页分裂。
从存储空间角度看,主键长度越小,索引的叶子节点就越小,占用空间越小。如整型只要4个字节,长整型(bigint)就是8字节。这也是为什么不建议大家用随机数作为主键的原因。
三、索引利用
我们以一条SQL语句执行流程来看索引是怎么提高查询效率的。
selcect * from T where k between 1 and 3;假定主键索引和k索引树分别是:
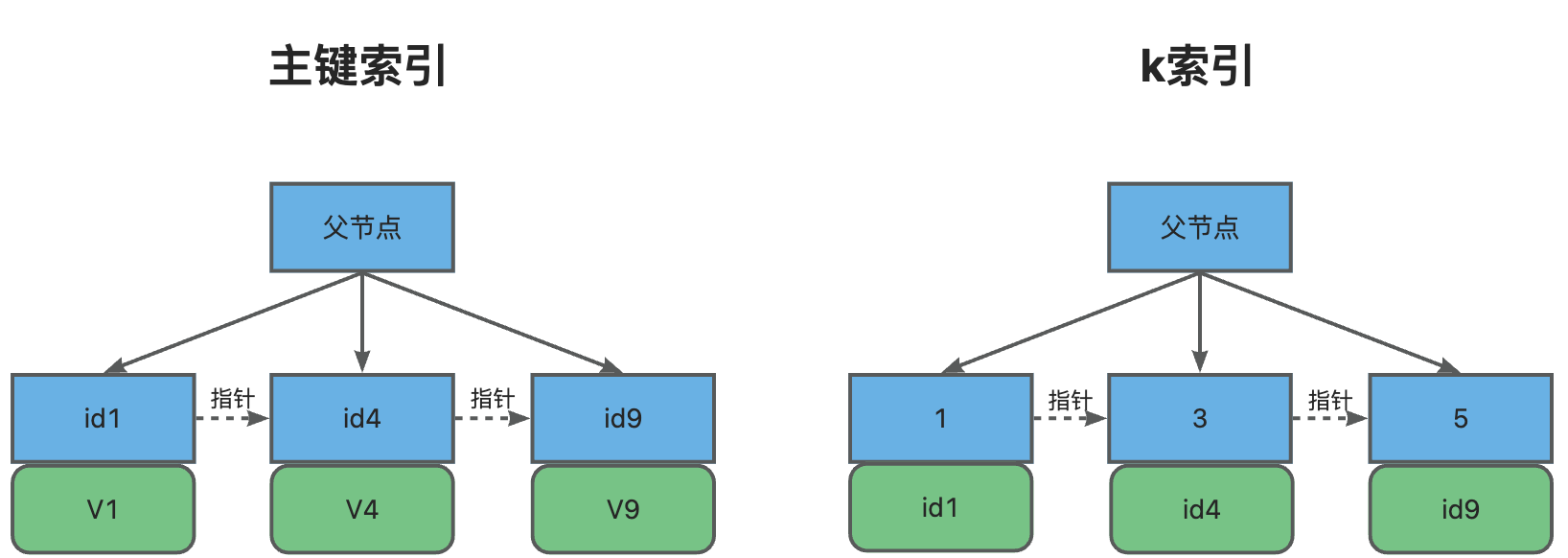
这条SQL查询的执行流程:
1、在k索引树上找到k=1的记录,取得主键ID=1
2、到主键索引树上查到ID=1对应的V1
3、在k索引树继续取下一个值k=3,取得主键ID=4
4、到主键索引树上查到ID=4对应的V4
5、在k索引树上取下一个值k=5,不满足查询条件,循环结束。
可以看到,这条SQL查询了k索引树3次,回表2次。这里你一定会想,能不能优化索引,避免回表呢?
如果这条SQL改为selcect id from T where k between 1 and 3;那么就不需要回表了,这时k索引也称为覆盖索引,也就是查询的字段已经在k索引中,无需回表了。
你可能会立即反问,业务中怎么可能刚刚好只查主键呢,那就需要根据实际情况考虑建立联合索引。
3.1 最左前缀原则
每一种查询都新加一个索引,无疑是对索引的浪费。
我们来看(name,age)这个联合索引:
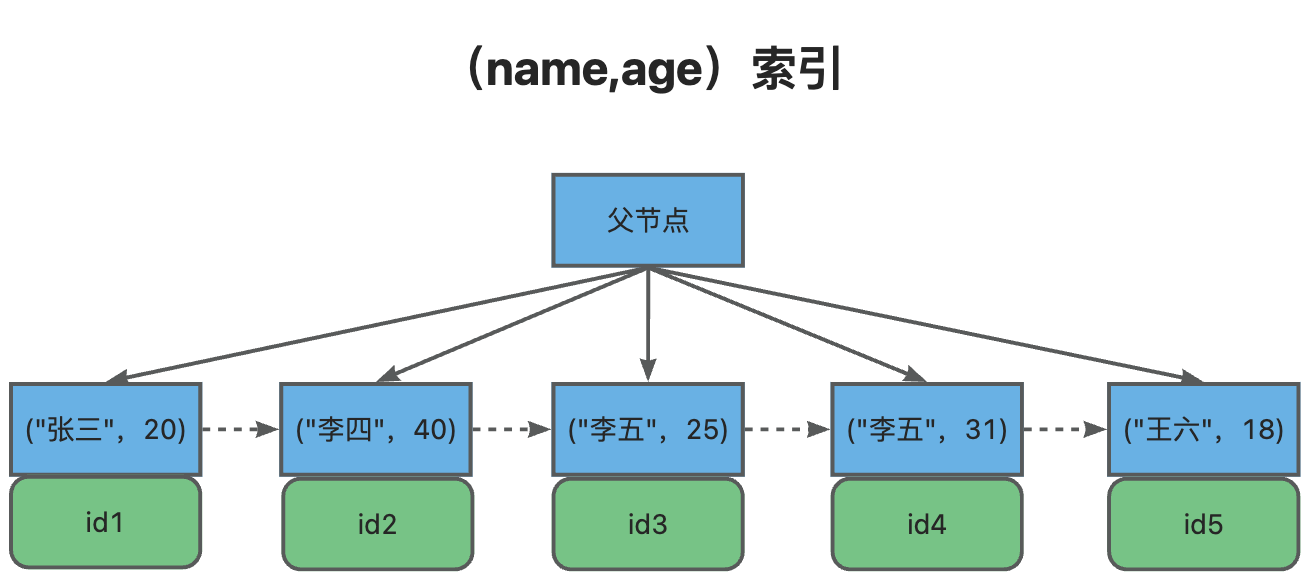
当你查询姓名为“李五”时,可以快速定位到id3,然后向后遍历得到所要的结果。
如果你查询的姓名第一个字是“李”时,可以定位到id2,然后向后遍历得到所要的结果。
所以最左前缀,不仅是联合索引的最左N个字段,也可以是字符串的最左N个字符。
这时你需要根据具体的业务场景,考虑联合索引的顺序问题,当有(name,age)这个联合索引,就无需再单独建立(name)索引了,但是如果查询条件里面只有age,是无法使用(name,age)索引了。
3.2 索引下推
在MySQL5.6之后,引入了索引下推优化,可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤不满足条件的记录,减少回表次数。
SQL语句:
select * from T where name like "李%" and age = 25;

无索引下推机制时,根据最左前缀匹配原则,找到“李%”的name之后,就回表查询主键索引,然后过滤age字段。索引下推机制下,在寻找“李%”name时,会直接判断age=25符合条件的数据,然后回表查询主键索引,减少了2次回表次数。
3.3 唯一索引
唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
知道了唯一索引的概念之后,你也许已经猜到唯一索引的性能可能比不上普通索引,一起来看背后的原因是什么?
我们从查询和更新2个角度来分析,唯一索引和普通索引的区别。
查询过程
SQL语句:
select id from T where k = 3;普通索引:查找到满足第一个k=3记录后,向后继续寻找,直到第一个不满足k=3的记录。
唯一索引:由于索引数据的唯一性,查找到第一个满足k=3条件的记录后,停止检索。
对于内存操作来说,两者的性能差别几乎可以忽略。
更新过程
当更新一个数据页时,如果数据页在内存中就直接更新,否则InnoDB会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读入这个数据页了。在下次查询访问这个数据页时,会触发change buffer的merge操作,持久化到磁盘中。除了访问数据页触发merge时,系统有后台线程也会定期merge,在数据库正常关闭时,也会执行merge操作。将更新操作先记录在change buffer,就是为了减少读磁盘,提升SQL语句执行速度。
唯一索引更新不能使用change buffer,而普通索引可以使用。
此时,再执行一条更新语句时,第一种情况时更新的数据页在内存中,这时:
唯一索引:找到需要插入的位置,判断有没有冲突,执行插入,结束;
普通索引:找到需要插入的位置,插入这个值,结束。
可以看出,数据页在内存中的两者操作几乎没有性能差别。
重点来了,如果更新的数据页不在内存中,这时:
唯一索引:将数据页读入内存,判断有没有冲突,执行插入,结束;
普通索引:将更新记录在change buffer,结束。
将数据从磁盘读入内存涉及随机IO的访问,是数据库里面成本最高的操作之一。change buffer因为减少了随机磁盘访问,所以对更新性能的提升是会很明显的。
举个例子,大家感受更深,如果你的业务库有大量插入数据的操作,内存命中率下降明显,系统就会经常处于阻塞状态,更新语句都堵住了。有可能就是因为普通索引改为了唯一索引。
那么怎么判断是不适合用唯一索引呢?
对于写多读少的业务来说,写完之后立即读的概率比较小,此时change buffer效果很好,推荐使用普通索引。
对于一个业务写完之后立即就要访问,将更新操作记录在change buffer之后,由于马上访问这个数据页,会立即出触发merge操作,增加随机访问IO次数,此时,change buffer反而起到了反作用,增加了维护代价,可以使用唯一索引。
四、索引实践
4.1 order by语句
给定一个SQL语句:
select city,name,age from T where city = "杭州" order by name limit 1000;此时你已经很清楚,为了避免全表扫描,需要在city字段上加索引,我们用explain命令看一下这条SQL执行情况:

Extra中的“Using filesort”表示就是需要排序,MySQL会分配一块内存用于排序,称为sort_buffer。这条SQL的执行流程是:
1、初始化sort_buffer,放入name、city、age三个字段
2、从索引city找到第一个满足city="杭州"的主键ID
3、从主键索引中取出行数据,选取select条件中的city、name、age三个字段,放入sort_buffer中
4、从索引city中取下一个记录的主键id
5、重复3、4直到不满足city的查询条件
6、对sort_buffer中的数据按照name进行快速排序
7、按照排序结果取前1000行返回给用户
通过一张图来看流程:
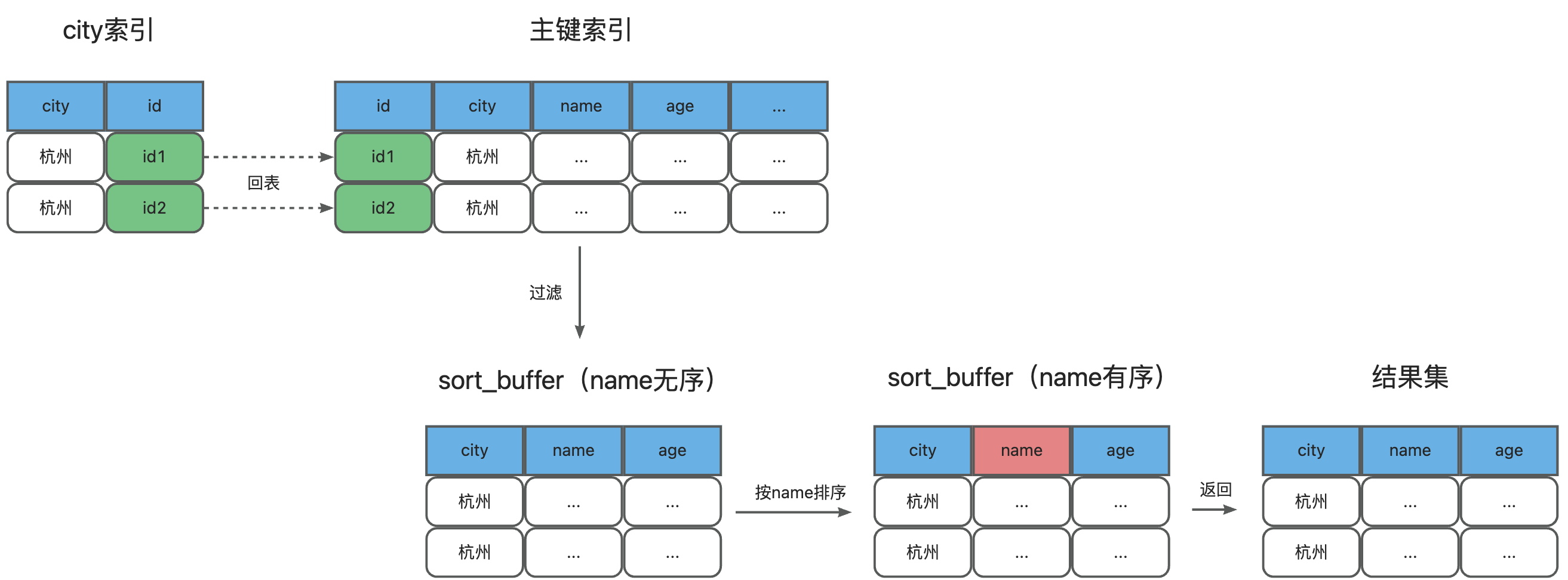
但是sort_buffer不是无限大的,如果排序数据量太大,内存就会放不下,就会用到磁盘临时文件进行排序。
合并多个临时文件一般使用归并排序算法。MySQL的设计思想是:如果内存够用,尽量多利用内存,减少磁盘访问。
4.2 索引选择
其实对于4.1中的SQL语句是可以优化的,不知道你猜到了没有,SQL中过滤条件是city和name,我们可以创建一个(city,name)的联合索引,这样能够保证从city索引中取出来的数据,天然就是按照name递增排序的,此时的流程变为了:

是不是效果好多了,而且查询过程不需要临时表,也不需要排序,我们用explain来验证下:

可以看到,Extra中没有Using filesort了,也就是不需要排序了。而且(city,name)联合索引本身有序,扫描行数由之前的4000行减少到1000行。
你是不是觉得到此为止了?还可以再优化下哦,如果创建一个(city,name,age)的联合索引,那么这个联合索引对于这个SQL来说就成了覆盖索引,流程简化成了这样:
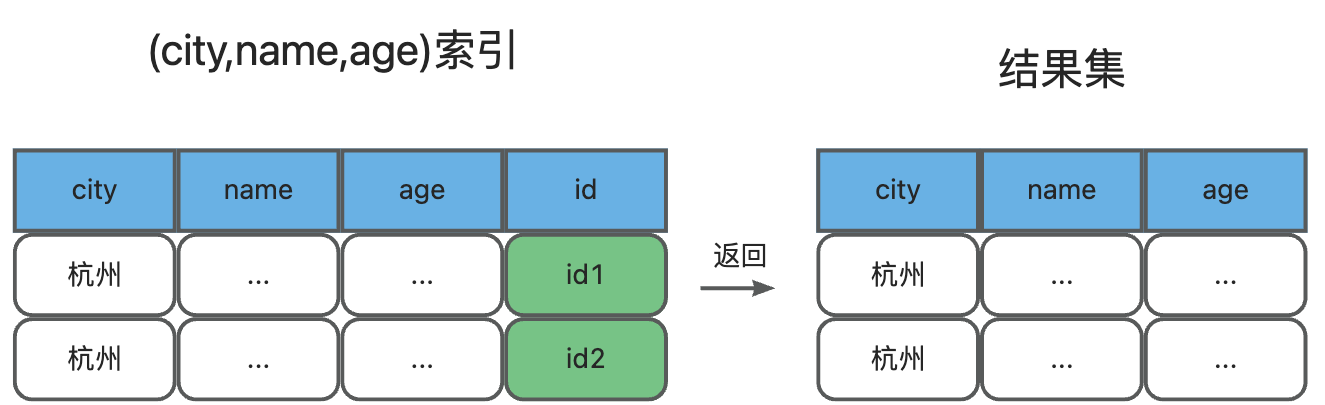
来看一下explain效果:

可以看到,Extra中多了“Using index”,表示使用了覆盖索引,性能上快了很多。
以上是索引选择的一个例子,在大家日常业务开发中会有很多遇到索引的情况,一般可考虑:
•被频繁查询的字段 :我们创建索引的字段应该是查询操作非常频繁的字段。 •被作为条件查询的字段 :被作为 WHERE 条件查询的字段,应该被考虑建立索引。 •频繁需要排序的字段 :索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。 •被经常频繁用于连接的字段 :经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。 •如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。 •尽可能的考虑建立联合索引而不是单列索引。每个索引都需要维护一棵B+树,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。4.3 索引失效
索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这些:
•使用 SELECT * 进行查询,优化器可能会认为全表扫描比索引更高效。 •创建了联合索引,但查询条件未遵守最左匹配原则; •在索引列上进行计算、函数、类型转换等操作; •以 % 开头的 LIKE 查询比如 like '%abc'; •查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;这里可以展开说明函数和类型转换为什么会导致索引失效。
案例一:函数操作
SQL语句:
select count(*) from T where month(modified) = 6这条SQL想要检索modified修改时间在6月份的数据量有多少。
即使modified字段上有索引,你仍会发现SQL语句执行了很久。因为MySQL规定:对字段做了函数计算,就不能使用索引。为什么条件是where modified='2024-06-18’的时候可以用上索引,而改成where month(modified)=6的时候就不行了?
其实也很简单,modified索引树的每个节点存储的是“2024-06-18”这样的数据,month(modified)之后的结果是7,无法在索引树中进行检索。最终MySQL选择了全表扫描。
案例二:类型转换
给定SQL语句:
select * from T where age = 20;设定age这个字段上有索引,创建表语句中age是varchar(10),通过explain可以发现,这条SQL走了全表扫描,因为输入的age参数是整数,需要做类型转换。
对于MySQL优化器来说,这条SQL等同于:
select * from T where CAST(a ge AS signed int) = 20;这样就又回到了对索引字段做函数操作,优化器会放弃走树搜索功能。
案例三:编码转换
如果你需要做两张表的联表查询,但是一张表的编码是utf8,另一张表的编码格式是utf8mb4,那么在通过join字段连接时用不上关联字段的索引。utf8中的一个英文字符占用一个字节的存储空间,一个中文占用三个字节的存储空间,不支持4个字节的存储,而utf8mb4支持4个字节的存储,可以更好的支持emoji表情。
所以在连表查询时,MySQL会先将utf8字符串转换为utf8mb4字符集,再做比较。SQL语句变成了:
select * from T1 where CONVERT(T1.age USING utf8mb4)=T2.age.value;这样又回到了对索引字段做函数操作,走不到索引。
五、QA
(1)B树与B+树的区别
数据结构上:B树所有节点都可包含记录,而B+树只有叶子节点存储数据,非叶子节点只用于索引,不存储实际数据。
更新操作上:B+树执行更新需要维护索引的变化以保持有序。
查询性能上:B树通过二分查找,而且是跨层查找,理论上,需要命中的数据离根节点越近性能越高(最好的性能是O(1)),否则需要多次磁盘访问,性能较低。B+树是数据存储在叶子节点,通过链表定位数据的时间复杂度是O(log(N))。
使用场景上:B树适合随机访问的场景,比如文件系统索引;B+树适合范围查询和顺序查询,比如数据库索引。
(2)explain语句
explain语句也称为获取MySQL执行计划信息,展示一条SQL的执行方案。
explain语句执行结构一共有12列,每一列什么含义和如何分析,百度很多,这里不展开解释了。大家也不需要刻意记每个字段什么含义,需要explain时百度下,次数多了自然也就熟悉了。
(3)为什么要限制每张表上的索引数量?
索引可以提高查询效率,是不是一张表上索引越多越好呢,其实不然。索引可以提高效率也可以降低效率,因为MySQL优化器在选择如何优化SQL查询时,会对每一个索引进行评估,以生成一个最好的执行计划,如果同时有很多索引都可以使用,就会增加MySQL优化器生成执行计划的时间,同样会降低查询性能。所以一般建议单表索引不超过5个,根据实际频繁查询的字段设置索引。
(4)索引失效的进一步扩展
我们已经知道MySQL遇到函数转换会使索引失效,那么假定主键id是int类型,如果执行下面SQL语句,会导致全表扫描吗?
select * from T where id = "65535";你可以去数据库尝试下这条SQL,然后通过explain验证下。其实结论很简单,这里进行的是查询条件的value值函数转换(将varchar转换为int),并不是在索引字段id上,自然是命中索引的。
大家在日常中还有遇到什么坑或者经验,欢迎评论区分享
标签:一文,MySQL,查询,索引,SQL,数据,主键,name From: https://www.cnblogs.com/Jcloud/p/18322870