基础知识
● 下列属于 CPU 中算术逻辑单元的部件是(1)。
(1)A、程序计数器
B、加法器
C、指令寄存器
D、指令译码器
参考答案:(1)B
● 在 CPU 和主存之间设置高速缓存(Cache)的目的是为了解决(2)的问题。
(2)A、主存容量不足
B、主存与外存储器速度不匹配
C、主存与 CPU 速度不匹配
D、外设访问效率
参考答案:(2)C
● 在计算机外部设备和主存之间直接传送而不是由 CPU 执行程序指令进行数据传送的控制方式称为(3)。
(3)A、程序查询方式
B、中断方式
C、并行控制方式
D、DMA 方式
参考答案:(3)D
● 以下关于磁盘碎片整理程序的描述中,正确的是(4)。
(4)A、磁盘碎片整理程序的作用是延长磁盘的使用寿命
B、用磁盘碎片整理程序可以修复磁盘中的坏扇区,使其可以重新使用
C、用磁盘碎片整理程序可以对内存进行碎片整理,以提高访问内存速度
D、用磁盘碎片整理程序对磁盘进行碎片整理,以提高访问文件的速度
参考答案:(4)D
在Windows系统中,磁盘碎片整理程序可以分析本地卷,以及合并卷上的可用空间使其成为连续的空闲区域,从而使系统可以更高效地访问文件或文件夹。
● 在常见的数据结构中,(5)是只能通过访问它的端来实现数据存储和检索的一种线性数据结构,它的修改遵循先进后出的原则: (6)是一种先进先出的线性表。(7)是取值范围受限的线性表。
(5)A、链表 B、队列 C、栈 D、串
(6)A、链表 B、队列 C、栈 D、串
(7)A、链表 B、队列 C、栈 D、串
参考答案:(5)C (6)B (7)D
● 二叉树遍历是按照某种策略访问树中的每个节点,且仅访问一次。按照遍历左子树要在遍历右子树之前进行的原则,根据访问(8)位置的不同, 可得到二叉树的前序、中序和后序三种遍历方法。
(8)A、根节点 B、导航节点 C、叶子结点 D、兄弟节点
参考答案:(8)A
● 以下有关霍夫曼树的说法中,错误的是(9)。
(9)A、霍夫曼树又被称为最优二叉树
B、霍夫曼树是一种带权路径长度最短的树
C、具有 n 个叶子节点的权值为 W1,W2, ... Wn的最优二叉树是唯一的
D、霍夫曼树可以用来进行通信电文的编码和解码
参考答案:(9)C
霍夫曼树不唯一
● 查找算法中,(10)要求查找表进行顺序存储并且按照关键字有序排列,一般不进行表的插入与删除操作。
(10)A、顺序查找
B、 折半查找
C、 分块查找
D、动态查找
参考答案:(10)B
● 以下关于字典攻击的说法中,不正确的是(11)。
A、字典攻击比暴力破解更加高效
B、使用密码盐技术可以大大增加字典攻击的搜索空间
C、字典攻击主要用于破解密码
D、如果密码盐泄露,字典攻击就会和不加盐时的效果一样
参考答案:(11)D
字典攻击:在破解密码或密钥时,逐一尝试用户自定义词典中的可能密码(单词或短语)的攻击方式。与暴力破解的区别是,暴力破解会逐一尝试所有可能的组合密码,而字典式攻击会使用一个预先定义好的单词列表(可能的密码)。
密码盐:在密码学中,是指通过在密码任意固定位置插入特定的字符串,让散列后的结果和使用原始密码的散列结果不相符,这种过程称之为“加盐”。
如果密码盐泄露,字典攻击就会和不加盐时的效果是不一样的,而且使用密码盐技术可以大大增加字典攻击的搜索空间。
● 以下关于哈希函数的说法中,不正确的是(12)。
(12)A、哈希表是根据键值直接访问的数据结构
B、随机预言机是完美的哈希函数
C、哈希函数具有单向性
D、哈希函数把固定长度输入转换为变长输出
参考答案:(12)D
Hash,一般翻译为散列、杂凑,或音译为哈希,是把任意长度的输入通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
哈希表是根据键(Key)而直接访问在内存存储位置的数据结构。
在密码学里面,随机预言机(英语:Random oracle)是一部预言机,对任何输入都回传一个真正均匀随机的输出,不过对相同的输入,该预言机每次都会用同一方法输出。换句话说,随机预言机是一个将所有可能输入与输出作随机映射的函数。
● 以下关于拒绝服务攻击的叙述中,不正确的是(13)。
A、拒绝服务攻击的目的是使计算机或者网络无法提供正常的服务
B、拒绝服务攻击是通过不断向计算机发起请求来实现的
C、拒绝服务攻击会造成用户密码的泄露
D、 DDos 是一种拒绝服务攻击形式
参考答案:(13)C
拒绝服务攻击即是攻击者想办法让目标机器停止提供服务,是黑客常用的攻击手段之一。
最常见的DoS攻击有计算机网络带宽攻击和连通性攻击。带宽攻击指以极大的通信量冲击网络,使得所有可用网络资源都被消耗殆尽,最后导致合法的用户请求无法通过。连通性攻击指用大量的连接请求冲击计算机,使得所有可用的操作系统资源都被消耗殆尽,最终计算机无法再处理合法用户的请求。
分布式拒绝服务攻击DDoS是一种基于DoS的特殊形式的拒绝服务攻击,是一种分布的、协同的大规模攻击方式。
拒绝服务攻击并不会造成用户密码的泄露。
● 下列不属于社会工程学攻击的是(14)。
(14)A、攻击者编造一个故事使受害者信服,从而透露秘密消息
B、攻击者伪造一条来自银行或其他金融机构的需要“验证”登录的消息
C、攻击者通过搭线窃听方式窃取了从网络节点 A 发送到网络节点 B 的消息
D、通过电话以知名人士的名义去推销诈骗
参考答案:(14)C
● Linux 系统中,文件的权限表示为“-rw-rw-rw-”,下列说法正确的是(15)。
(15)A、文件所有者拥有读、写和执行权限
B、文件所在组用户拥有读、写和执行权限
C、其他组用户拥有读和写权限
D、其他组用户拥有读和执行权限
参考答案:(15)C
Linux中,权限的格式:-rw-rw-rw-
(1)第0位确定文件类型(说明: -:普通文件, d:目录,l : 连接文件, c: 字符设备文件[键盘,鼠标] ,b: 块设备文件[硬盘] ) 。
(2)第1-3位确定所有者(该文件的所有者)拥有该文件的权限。 R: 读权限 , w : 写权限 ,x: 执行权限 (-表示没有)。
(3)第4-6位确定所属组(同用户组的)拥有该文件的权限 。
(4)第7-9位确定其他用户拥有该文件的权限 。
● 根据《计算机软件保护条例》的规定,著作权法保护的计算机软件是指(16)。
(16)A、程序及其相关文档
B、处理过程及开发平台
C、开发软件所用的算法
D、开发软件所用的操作方法
参考答案:(16)A
● 以下计算机软件著作权权利中,不可以转让的是(17)。
(17)A、发行权
B、复制权
C、署名权
D、信息网络传播权
参考答案:(17)C
署名权即表明开发者身份的权利以及在软件上署名的权利,它不受时间的限制,也不因权利人的死亡或者消失而消灭。
● 操作系统的功能可分为相互配合、协调工作的 5 大部分,其中不含(18) 。
(18)A、进程管理
B、文件管理
C、存储管理
D、事务管理
参考答案:(18)D
操作系统主要包括以下几个方面的功能:
①进程管理,其工作主要是进程调度,在单用户单任务的情况下,处理器仅为一个用户的一个任务所独占, 进程管理的工作十分简单。但在多道程序或多用户的情况下,组织多个作业或任务时,就要解决处理器的调度、 分配和回收等问题 。
②存储管理分为几种功能:存储分配、存储共享、存储保护 、存储扩张。
③设备管理分有以下功能:设备分配、设备传输控制 、设备独立性。
④文件管理:文件存储空间的管理、目录管理 、文件操作管理、文件保护。
⑤作业管理是负责处理用户提交的任何要求。
● 操作系统中,短期调度指的是(19)。
(18)A、作业调度
B、进程调度
C、线程调度
D、 CPU 调度
参考答案:(19)B
长期调度,又称为作业调度或高级调度,这种调度将已进入系统并处于后备状态的作业按某种算法选择一个或一批,为其建立进程,并进入主机,当该作业执行完毕时,还负责回收系统资源,在批处理系统中,需要有作业调度的过程,以便将它们分批地装入内存,在分时系统和实时系统中,通常不需要长期调度。它的频率比较低,主要用来控制内存中进程的数量。
中期调度,又称为交换调度。它的核心思想是能将进程从内存或从CPU竞争中移出,从而降低多道程序设计的程度,之后进程能被重新调入内存,并从中断处继续执行,这种交换的操作可以调整进程在内存中的存在数量和时机。其主要任务是按照给定的原则和策略,将处于外存交换区中的就绪状态或等待状态的进程调入内存,或把处于内存就绪状态或内存等待状态的进程交换到外存交换区。
短期调度,又称为进程调度、低级调度或微观调度。这也是通常所说的调度,一般情况下使用最多的就是短期调度。它的主要任务是按照某种策略和算法将处理机分配给一个处于就绪状态的进程,分为抢占式和非抢占式。
● 线程可以实现在(20)。①内核空间;②用户空间;③ 虚拟空间;④物理空间
(20)A、①③
B、②③
C、①②
D、③④
参考答案:(20)C
根据操作系统内核是否对线程可感知,可以把线程分为内核线程和用户线程。
用户线程由应用程序所支持的线程实现,内核意识不到用户级线程的实现。内核级线程又称为内核支持的线程。
所以,线程可以实现在内核空间和用户空间。
● 操作系统中进行资源分配和独立运行的基本单位是(21)。
(21)A、进程
B、管程
C、线程
D、程序
参考答案:(21)A
进程观点把操作系统看作是由若干个可以同时独立运行的程序和一个对这些程序进行协调的核心所组成的系统,这些同时运行的程序称为进程。进程是系统进行资源分配和调度的独立单位。
● 程序设计语言的基本成分包括数据、运算、控制和(22)。 数据是程序操作的对象,按照数据组织形式可以分为多种类型,其中枚举属于(23)类型: 数组属于(24)类型。
A、存储 B、分配 C、传输 D、函数
A、基本 B、用户定义 C、构造 D、特殊
A、基本 B、用户定义 C、构造 D、特殊
参考答案:(22)C(23)B(24)C
程序设计语言的基本成分包括数据、运算、控制和传输,数据是程序操作的对象,按照数据组织形式可以分为多种类型,其中枚举属于用户定义类型, 数组属于构造类型。
● 传统过程模型中,(25)首先引入了风险管理。
(25)A、瀑布模型
B、螺旋模型
C、V 模型
D、原型化模型
参考答案:(25)B
软件开发模型是软件开发的全部过程、活动和任务的结构框架,用以指导软件的开发。螺旋模型综合了瀑布模型和演化模型的优点,并增加了风险分析,沿着螺线由内向外,每旋转一圈,就得到原型的一个新版本。
● 以下有关测试的说法中,错误的是(26)。
(26)A、测试证明了程序的正确性
B、测试无法执行穷举测试,只能做选择测试
C、测试工作需要制定测试计划,按计划执行测试工作
D、白盒测试方法用于单元测试环节
参考答案:(26)A
软件测试的目的是发现软件的错误,验证软件是否满足用户需求,并通过分析软件错误产生的原因,以帮助发现当前开发工作所采用的软件过程的缺陷,以便进行软件过程改进。软件测试不能发现软件中的所有错误,也不可能保证软件完全正确。
● 在软件设计中通常用耦合度和内聚度作为衡量模块独立程度的标准,耦合程度最高的是(27)耦合:内聚程度最高的是(28)内聚。
(27)A、数据 B、内容 C、标记 D、公共
(28)A、顺序 B、功能 C、时间 D、逻辑
参考答案:(27)B(28)B
耦合程度从低到高的顺序为:非直接耦合、数据耦合、标记耦合、控制耦合、外部耦合、公共耦合和内容耦合。最好的是非直接耦合,没有直接联系,模块之间不相互依赖于对方。最差的是内容耦合,一个模块访问了另一个模块的内部数据。
内聚程度从高到低的顺序为:功能内聚、顺序内聚、通信内聚、过程内聚、瞬时内聚、逻辑内聚和偶然内聚。
所以,在软件设计中通常用耦合度和内聚度作为衡量模块独立程度的标准,耦合程度最高的是内容耦合;内聚程度最高的是功能内聚。
● 采用 ADSL 接入 Internet,用户端接入介质为(29),使用的网络为(30)。
(29)A、双绞线 B、红外线 C、同轴电缆 D、光纤
(30)A、电话网 B、电视网 C、 DDN 专线 D、 5G 无线广域网
参考答案:(29)A(30)A
1989年在贝尔实验室诞生的ADSL是xDSL家族成员中的一员,被誉为“现代信息高速公路上的快车”。它因其下行速率高、频带宽、性能优等特点而深受广大客户的喜爱,成为继MODEM、ISDN之后的又一种全新更快捷,更高效的接入方式。它是运行在原有普通电话线上的一种新的高速宽带技术。
事实上,ADSL的传输技术中,ADSL用其特有的调制解调硬件来连接现有双绞线连接的各端。
● 在 TCP/IP 协议栈中,应用层协议数据单元为(31)。
(31)A、消息 B、段 C、用户数据报 D、帧
参考答案:(31)A
在TCP/IP协议栈中,应用层协议数据单元为消息或者报文。其中段是传输层,用户数据报是网络层,帧是数据链路层。物理层是比特流。
应用层——消息、报文(message)
传输层——数据段(segment)
网络层——分组、数据包(packet)
链路层——帧(frame)
物理层——比特流
● Telnet 服务的默认端口号是(32)。
(32)A、20 B、21 C、22 D、23
参考答案:(32)A
在 UNIX/Linux 系统中,telnet 服务的默认端口是 23,ftp 的端口号是 21和20。
● 关系型数据库是(33)的集合,表是(34) 的集合。
(33)A、表 B、记录 C、码 D、属性
(34)A、约束 B、记录 C、码 D、索引
参考答案:(33)A(34)B
● 属性指的是表中的一个(35)。
(35)A、记录 B、列 C、元组 D、码
参考答案:(35)B
● 对于两个关系 E 和 F,(36)的运算结果的任一 元组, 同时属于 E 和 F。
(36)A、E×F B、EUF C、E∩F D、E-F
参考答案:(36)C
● 在一个关系表中,个表的行代表(37)。
(37)A、关系 B、外码 C、元组 D、属性
参考答案:(37)C
● 关系的完整性约束不包含(38)。
(38)A、实体完整性
B、参照完整性
C、属性完整性
D、用户定义完整性
参考答案:(38)C
● 在一个关系型数据库中,参照完整性约束可以通过(39)来实现。
(39)A、主码
B、候选码
C、外码
D、锁
参考答案:(39)C
● 关系型数据库中常用的查询语言不包括(40)。
(40)A、域关系演算
B、元组关系演算
C、导航式语言
D、关系代数
参考答案:(40)C
● 一个取值域是原子的,是指该域的元素是(41)单元。
(41)A、不同的
B、不可分的
C、常量
D、不可见的
参考答案:(41)B
● 假设有两个数据库表,product 表和 market 表,分别存放商品信息和市场需求信息。对 SQL 语句:
select * fom product, market where product.p_id = marke.p_id 的结果描述正确的是(42)。如果想从 market 表中移除 m_id 为 MO3 的记录,语句(43)是正确的。如果要收回 GRANT SELECT ON product to role_A WITH GRANT OPTION 语句给 role_A 赋予的权限,使用语句(44)。在 product 表、market 表初始数据不变的情况下,以下 SQL 语句返回的结果有(45)条记录。
SELECT product.p_id
FROM product
WHERE productp num>( SELECT sum (arketm need)
FROM market
WHERE markerp id = productp. id)
(42)A、 查找市场所需商品的信息
B、查找所有市场信息
C、查找所有商品信息
D、查找市场所需的商品信息以及相应的市场需求信息
(43)A、 REMOVE FROM market WHERE m_id='M03'
B、 DROP FROM market WHERE m_id='M03'
C、 DELETE FROM market WHERE m_id='M03'
D、 UPDATE FROM market WHERE m_id='M03'
(44)A、 REVOKE SELECT ON product FROM role A
B、 REVOKE SELECT ON product FROM role ACASCADE
C、 REVOKE SELECT ON product FROM role A WITH GRANT OPTION
D、 REVOKE SELECT ON producet FROM role AALL
(45)A、0 B、1 C、2 D、3
参考答案:(42)D(43)C(44)B(45)D
● 关系模式 R<{A,B,C.D},{ (A→B, A→D, D→A,B→C}>最高属于(46),原因是该模式存在(47)。
(46)A、 INF B、2NF C、3NF D、 BCNF
(47)A、主属性对码的部分函数依赖
B、非主属性对码的部分函数依赖
C、主属性对码的传递函数依赖
D、非主属性对码的传递函数依赖
参考答案:(46)B(47)D
● 关系模式 R<U, D>中,D 为 R 的函数依赖和多值依赖的集合。将 R 分解为两个关系模式 R1<U1,,D1>和 R2<U2,D2>,则以下说法中错误的是(48)。
(48)A、如果 U1∩U2→U1-U2成立,那么此分解具有无损连接性
B、如果 U1∩U2→→U1-U2 成立,那么此分解具有无损连接性
C、如果 U1∩U2→U1-U2 不成立,那么此分解不具有无损连接性
D、如果 U1∩U2→→U1-U2 不成立,那么此分解不具有无损连接性
参考答案:(48)C
将R分解为两个关系模式R1<U1,D1>和R2<U2,D2>,如果U1∩U2→U1-U2或者U1∩U2→U2-U1成立,那么此分解具有无损连接性。
所以如果U1∩U2→U1-U2不成立,那么此分解不具有无损连接性,这个说法是片面的,是错误的。
● 下列关于 BCNF 的描述,正确的是(49)。
(49)A、 BCNF 不满足列的原子性
B、 BCNF 中存在非主属性对码的部分依赖
C、 BCNF 中存在非主属性对码的传递依赖
D、BCNF 中每个函数依赖左部都包含码
参考答案:(49)D
满足BCNF的定义为:BCNF中每个函数依赖左部都包含码。
● 关系模式 R<U>中,X、Y、Z 是 U 的子集。下列关于多值依赖描述中正确的是(50) 。
(50)A、若 X→→Y 为平凡的多值依赖,则 U-X-Y 为空集
B、若 X→→Y 为平凡的多值依赖,则 Y 是 X 的子集
C、若 X→→Y 且 Y→→Z,则 X→→Z
D、若 X→→Y,则 X→Y
参考答案:(50)D
多值函数依赖的定义为:在R( U,F )中 , 其属性集为U。X ,Y,Z是U的子集,并且Z=U-X-Y。当且仅当对R(U)的任何一个关系r,给定一组属性(X,Z)的值 , 有一组Y值,这组Y值仅仅决定于X值而与其他属性Z(U-X-Y)的值无关 , 那么称Y多值依赖于X或X多值决定Y , 记为:X→→Y
具有6种性质:
对称性 : X→→Y , 则X→→Z,其中Z=U−X−Y
传递性 : X→→Y , Y →→Z , 则 X→→Z − Y
函数依赖可以看作多值依赖的特殊情况
若X→→Y , X →→Z , 则 X→→YZ
若X→→Y , X →→Z , 则 X→→Y ∩ Z
若X→→Y , X →→Z , 则 X→→Z − Y
平凡的多值依赖:如果Z为空,就是平凡的多值依赖;如果Z不为空,就是非平凡的多值依赖。
● 事务 T1 将数据库中的 A 值从 50 改为 30,事务 T2 读 A 值为 30,事务 T1又将刚才的操作撤销,A 值恢复为 50。这种情况属于(51), 是由于数据库系统在(52)方面的不当引起的,能解决此问题的方法是(53)。
(51)A、丢失修改 B、不可重复读 C、读脏数据 D、幻影现象
(52)A、并发控制 B、完整性约束 C、安全性控制 D、数据库的恢复
(53)A、 一级封锁协议和二级封锁协议
B、二级封锁协议和三级封锁协议
C、级封锁协议和三级封锁协议
D、一级封锁协议、二级封锁协议和三级封锁协议
参考答案:(51)C(52)A(53)D
一级封锁协议:事务T在修改数据对象R之前必须先对其加X锁,直到事务结束才释放。
二级封锁协议: 在一级封锁协议的基础上,事务T在读取R之前先对其加S锁,读完后即可释放S锁。
三级封锁协议:在一级封锁协议的基础上,事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。
一级封锁协议解决了丢失修改,二级封锁协议解决了脏读,三级封锁协议解决了不可重复读。
| X锁(排它锁) | S锁(共享锁) | 解决的一致性问题 | |||||
|---|---|---|---|---|---|---|---|
| 申请 | 释放 | 申请 | 释放 | 丢失修改 | 读"脏"数据 | 不可重复读 | |
| 一级封锁 | 事务开始 | 事务结束 | √ | ||||
| 二级封锁 | 事务开始 | 事务结束 | 读数据前 | 读完后立即 | √ | √ | |
| 三级封锁 | 事务开始 | 事务结束 | 事务开始 | 事务结束 | √ | √ | √ |
● 事务具有 ACID 特性,其中 C 是指事务的(54)。
(54)A、原子性
B、持续性
C、隔离性
D、一致性
参考答案:(54)D
原子性(Atomicity) 、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
● 数据库恢复操作的基本原理是(55)。
A、存取控制 B、 加密 C、完整性约束 D、 冗余
参考答案:(55)D
● 数据库系统在运行过程中可能会发生 CPU 故障,这属于(56)。在此类故障的恢复过程中,需要根据日志进行的操作为(57) 。
(55)A、事务故障
B、系统故障
C、介质故障
D、指令故障
(56)A、 UNDO
B、 REDO
C、 UNDO+REDO
D、后备副本+UNDO+REDO
参考答案:(56)B(57)C
数据库系统在运行过程中可能会发生CPU故障,这属于系统故障。在此类故障的恢复过程中,需要根据日志进行的操作为undo+redo。
● 关于触发器, 下面说法中正确的是(58)。
(58)A、 触发器可以实现完整性约束
B、触发器不是数据库对象
C、用户执行 SELECT 语句时可以激活触发器
D、触发器不会导致无限触发链
参考答案:(58)A
● 关于存储过程,下面说法中错误的是(59)。
(59)A、 存储过程可用于实施企业业务规则
B、存储过程可以有输入输出参数
C、存储过程可以使用游标
D、存储过程由数据库服务器自动执行
参考答案:(59)D
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,它存储在数据库中,一次编译后永久有效,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。
主要作用包括了:提供了在服务器端快速执行 SQL 语句的有效途径;存储过程降低了客户端和服务器之间的通信量;方便实施企业规则,当企业规则发生变化时只要修改存储过程,而无需修改其他应用程序。
● 如果一个事务已获得数据项 R 上的共享锁,则其他事务(60)。
(60)A、 可获得 R 上的排它锁
B、可获得 R 上的共享锁
C、不能获得 R 上的锁
D、待该共享锁释放后才可获得 R 上的锁
参考答案:(60)B
(1)排他锁(简记X锁),又称写锁。若事务T对数据对象A 加上X锁,则只允许T读取和修改A,其他任何事务不能再对A加任何类型的锁,直到T释放A上的锁。
(2)共享锁(简记S锁),又称读锁。若事务T对数据对象A加上S锁。则其他事务只能对A 加S锁,不能再加X锁,直到T释放A上的S锁。
● 在数据库管理系统中,以下 SQL 语句书写顺序正确的是(61)。
(61)A、 SELECT→FROM→GROUP BY→WHERE
B、 SELECT→FROM→WHERE→GROUP BY
C、 SELECT→WHERE→GROUP BY→FROM
D、 SELECT→WHERE→FROM→GROUP BY
参考答案:(61)B
● E-R 图向关系模式转换时,实体标识符转换为关系的(62)。
(62)A、码
B、元组
C、记录
D、约束
参考答案:(62)B
E-R 图向关系模式转换时:
(1)将每个实体类型转换成一个关系模式
(2)实体的属性即为关系模式的属性
(3)实体标识符即为关系模式的键
关系模式的键也可以称为码
● OLTP 指的是(63),OLAP 指的是(64)。
(63)A、联机事务处理 B、联机分析处理 C、实时事务处理 D、批量事务处理
(64)A、联机事务处理 B、联机分析处理 C、实时事务处理 D、批量事务处理
参考答案:(63)A(64)B
● SQL 语言中,NULL 值代表(65)。
(50)A、空字符串
B、数值 0
C、空值
D、空指针
参考答案:(65)C
● 在数据库系统中,使数据恢复到故障发生前的一致状态的机制称为(66)。
(66)A、恢复机制
B、备份机制
C、封锁机制
D、事务机制
参考答案:(66)B
● 通过将一个关系拆分成两个更小的关系来使其满足范式时,必须(67)来保持数据的完整性约束。
(67)A、用相同的属性使两个子关系互相关联
B、移除两个子关系中所有的函数依赖
C、封锁机制
D、事务机制
参考答案:(67)A
● 下列描述中,(68)不是分布式数据库数据透明性的表现形式。
(68)A、代码透明性
B、分片透明性
C、位置透明性
D、模型透明性
参考答案:(68)A
分布式数据库的透明性包括了分片透明、分配透明(复制透明、位置透明)、映像透明(模型透明)。
● 分布式数据库的 CAP 理论指的是:对于一个分布式数据库系统,一致性、可用性和分区容错性这三个特点,最多只能满足(69)个。
(69)A、0
B、1
C、2
D、3
参考答案:(69)C
● NOSQL 数据库的四大分类是指(70)。
(70)A、键值存储数据库,列存储数据库,文档型数据库,关系型数据库
B、列存储数据库,文档型数据库,关系型数据库,分布式数据库
C、键值存储数据库,列存储数据库,文档型数据库,图数据库
D、列存储数据库,文档型数据库,关系型数据库,图数据库
参考答案:(70)C
● A database system is a ollction of itererelated data and a set of programs that allow users to access and modify these data. A major purpose of a database system is to provide users with an(71)view of the data. That is, the system hides certain details of how the data are stored and maintained. For the system to be usable, it must retrieve data(72)。The need for efficiency has led designers to use complex data(73)to represent data in the database. Since many database-system users are not computer trained, developers hide the complexity from users through several levels of abstraction, to simplify users' interactions with the system. Physical level is the lowest level of abstraction that describes(74)the data are actually stored. Logical level is the next-higher level of abstraction that describes(75)data are stored in the database, and what relationships exist among those data. View level is the highest level of abstraction that describes only part of the entire database.
(71)A、 abstract B、physical C、 administrator D、 operator
(72)A、 completely B、 safely C、 usefully D、 efficiently
(73)A、 files B、 structures C、 graphs D、 flows
(74)A、 how B、 what C、 which D、 when
(75)A、 how B、 what C、 which D、 when
参考答案:(71)A (72)D (73)B (74)A(75)B
数据库系统是相互关联的数据和一组允许用户访问和修改这些数据的程序的集合。数据库系统的主要目的是向用户提供数据的抽象视图。也就是说,系统隐藏了数据存储和维护的某些细节。为了使系统可用,必须高效地检索数据。对效率的需求导致设计人员使用复杂的数据结构来表示数据库中的数据。由于许多数据库系统用户不是经过计算机训练的,因此开发人员通过几个抽象层次向用户隐藏复杂性,以简化用户与系统的交互。物理层是描述数据实际存储方式的最低抽象层。逻辑层是描述数据库中存储的数据以及这些数据之间存在什么关系的下一个更高抽象级别,视图级别是只描述整个数据库的一部分的最高抽象级别。
应用技术
● 试题一:阅读下列说明,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】
某小区快递驿站代为收发各家快递公司的包裹,为规范包裹收发流程,提升效率,需要开发一个信息系统。请根据下述需求描述完成该系统的数据库设计。
【需求描述】
(1)记录快递公司和快递员的信息。快递公司信息包括公司名称、地址和一个电话;快递员信息包括姓名、手机号码和所属公司名称。一个快递公司可以有若干快递员,一个快递员只能属于一家快递公司。
(2)记录客户信息,客户信息包括姓名、手机号码和客户等级。驿站对客户进行等级评定,等级高的客户在驿站投递包裹有相应的优惠。
(3)记录包裹信息,便于快速查找和管理。包裹信息包括包裹编号、包裹到达驿站时间、客户手机号码和快递员手机号码。快递驿站每个月根据收发的包裹数量,与各快递公司结算代收发的费用。
【概念模型设计】
根据需求阶段收集的信息,设计的实体联系图(不完整)如图1-1所示。
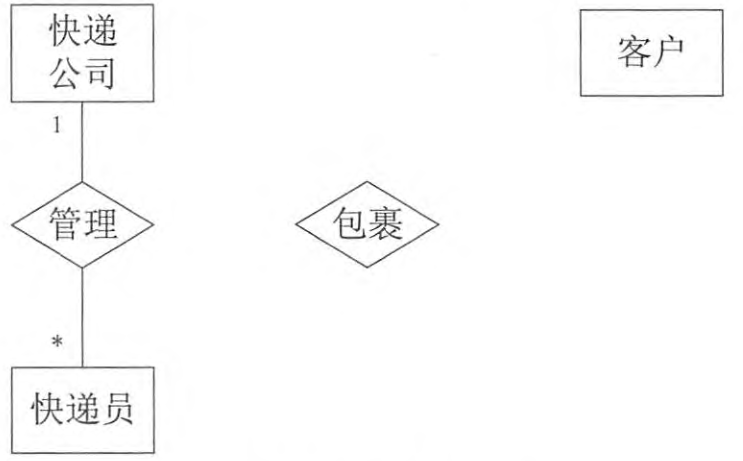
图1-1实体联系图
【逻辑结构设计】
根据概念模型设计阶段完成的实体联系图,得出如下关系模式(不完整 ):
快递公司(公司名称,地址,电话)
快递员(姓名,快递员手机号码, (a) )
客户(姓名,客户手机号码,客户等级)
包裹(编号,到达时间, (b) , 快递员手机号码)
【问题1】 (6分)
根据问题描述,补充图1-1的实体联系图。
参考答案:
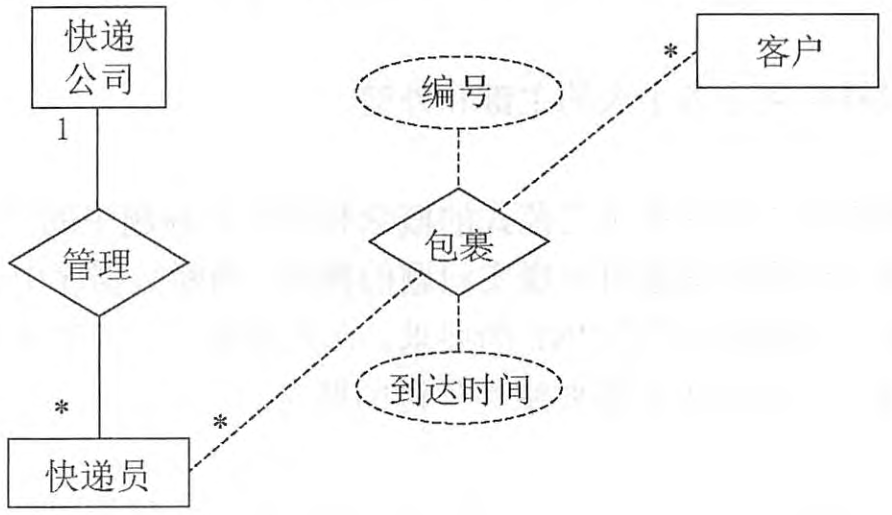
【问题2】 (4分)
补充逻辑结构设计结果中的(a)、(b) 两处空缺及完整性约束关系。
参考答案:
(a)公司名称
(b)客户手机号码
【问题3】 (5分)
若快递驿站还兼有代缴水电费业务,请增加新的“水电费缴费记录"实体,并给出客户和水电费缴费记录之间的“缴纳”联系,对图1-1进行补充。“水电费缴费记录”实体包括编号、客户手机号码、缴费类型、金额和时间,请给出“水电费缴费记录”的关系模式,并说明其完整性约束。
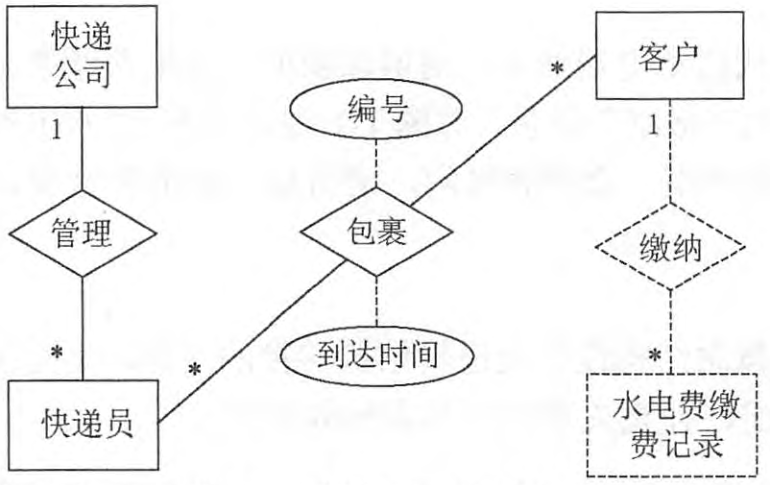
参考答案:
水电费缴费记录(编号,客户手机号码,缴费类型,金额,时间)。
主码:编号
外码:客户手机号码
● 试题二:阅读下列说明,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】
某市居委会在新冠病毒疫情期间需分配社区人员到辖区内各个小区,协助小区物业人员进行业主出入登记及体温检测工作。居委会为高效完成工作并记录必要的工作信息,设计了相应的数据库。其中有一个表用来记录工作人员在各个小区的分布情况及每天工作时长。表的结构如下:
人员分配(人员编号,人员姓名,小区编号,物业经理姓名,人员职责)。
其中人员编号和小区编号唯一,人员职责用于记录该人员需配合小区完成的工作,假设每个人员在同一个小区只负责一项工作,但在不同小区可以负责不同的工作。请回答以下问题。
【问题1】 (6分)
给出人员分配表中成立且左侧只有一个属性的所有函数依赖关系。题中设计的人员分配表是否满足2NF,请用100字以内的文字说明原因。
参考答案:
包含的函数依赖有:
人员编号→人员姓名
小区编号→物业经理姓名
不是2NF
因为人员分配表的主键是(人员编号,小区编号),存在非主属性对码的部分依赖。
【问题2】 (3分)
如果要将人员分配表规范化为满足3NF,请用100字以内的文字简要说明解决方案。
参考答案:
拆分为三个表:
人员表(人员编号,人员姓名)
小区表(小区编号,物业经理姓名)
责任表(人员编号,小区编号,人员职责)
【问题3】 (6 分)
请给出问题2设计结果中各个表的主键和外键。
参考答案:
人员表的主键为人员编号,无外键。
小区表的主键为小区编号,无外键。
责任表的主键为(人员编号,小区编号),外键是人员编号和小区编号。
● 试题三:阅读下列说明,回答问题1至问题4,将解答填入答题纸的对应栏内。
【说明】
某订单管理系统的部分数据库关系模式如下:
客户:CUSTOMERS(Cno, Cname, Cage, Csex),各属性分别表示客户编号、客户姓名、年龄和性别;
商品:GOODS(Gno, Gname, Gprice, Gorigin),各属性分别表示商品编号、商品名称、单价和产地;
订单:ORDERS(Ono, Cno, Gno, Oprice, Onumber),各属性分别表示订单编号、客户编号、商品编号、顾客购买商品的单价和数量。
有关关系模式的说明如下:
(1)下画线标出的属性是表的主键。
(2)商品表中的Gprice是商品的当前价格,可能会发生变动;订单表中的Oprice是订单成交时的商品单价。
(3)一个订单只包含一位顾客购买的一种商品;其商品数量至少1件,最多99件。
根据以上描述,回答下列问题,将SQL语句的空缺部分补充完整。
【问题1】(3分)
请将下面创建订单表的SQL语句补充完整,要求定义实体完整性约束、参照完整性约束,以及其他完整性约束。
CREATE TABLE ORDERS (
Ono CHAR(20) PRIMARY KEY,
Cno CHAR(10) (a),
Gno CHAR(15) (b),
Oprice NUMERIC(7,2),
Onumber SMALLINT (c) );
参考答案:
(a):REFERENCES CUSTOMERS(Cno)
(b):REFERENCES GOODS(Gno)
(c):CHECK(Onumber >=1 AND Onumber <=99)
【问题2】(5分)
查询所有订单的详细情况,要求输出订单号(Ono)、 客户姓名(Cname)、 商品名称(Gname)、单价(Oprice)、数量(Onumber)和金额(Oamount), 查询结果按照金额从大到小排列。此功能由下面的SQL语句实现,请补全。
SELECT Ono, Cname, Gname, Oprice, Onumber,(d) AS Oamount
FROM CUSTOMERS,ORDERS, GOODS
WHERE (e) AND (f)
(g) BY (h) ;
参考答案:
(d):Oprice * Onumber
(e):ORDERS.Cno =CUSTOMERS.Cno
(f):ORDERS.Gno = GOODS.Gno
(g):ORDER
(h):Oamount DESC
【问题3】(5分)
创建已售商品信息视图,给出已售商品的编号(Gno)、名称(Gname)、订单个数(Onum)及平均每单的商品数量(GAnum)。此视图的创建语句如下,请补全。
CREATE (i ) GOODS_SOLD AS
SELECT ORDERS.Gno AS Gno,MIN (GOODS.Gname) AS Gname,
(j) AS Onum,_(k) AS GAnum .
FROM ORDERS,GOODS
WHERE ORDERS.Gno = GOODS . Gno .
(l ) BY__ (m);
参考答案:
(i):VIEW
(j):COUNT(Ono)
(k):AVG(Onumber)
(l):GROUP
(M):ORDERS.Gno
【问题4】(2分)
查询未售出商品的编号和名称。此功能由下面的SQL语句实现,请补全。
SELECT Gno, Gname
EROM (n)
(o)
SELECT Gno , Gname
EROM GOODS SOLD;
参考答案:
(n):GOODS
(o):EXCEPT
● 试题四:阅读下列说明,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】
某网上销售系统的部分关系模式如下:
订单表:orders(o_no, o_date, o_time, p_no, m no, p_price, nums, amt, status)。其中属性含义分别为:订单号、订单日期、订单时间、产品编码、供应商编码、产品价格、产品数量、订单金额、订单状态(0-未处理、1-已处理、 2-已取消)。
产品表:products(p_no, p_name, p_type, price, m_no, p_nums)。其中属性含义分别为:产品编码、产品名称、产品类型、产品价格、供应商编码、库存数量。
【问题1】(5分)
节假日时,由供应商提供商品打折后的新价格,数据存放在临时表中,该临时表的表名为tmp_prices(不同供应商有不同的临时表),其关系模式如下:
tmp_ prices(P_ no, t_ price,m_ no) ;
后台维护人员需要根据供应商填写在tmp prices中的数据来更新产品表中某些产品的价格。下面是基于游标,用SQL实现的价格更新程序,请补全空缺处的代码。
CREATE PROCEDURE UpdatePrice()
DECLARE
Pno VARCHAR(10);
Pprice real(6,2);
Mno VARCHAR(10);
(a) upPrice IS
SELECT p_no, t_price, m_no FROM tmp_prices;
BEGIN
(b) upPrice ;
LOOP
FETCH upPrice INTO (c) ;
IF NOTFOUND DO BREAK //FETCH 操作无数据
UPDATE products SET price = Pprice WHERE p_no=Pno and m_no=Mno;
if error //error 是由DBMS提供的上一句SQL的执行状态
BEGIN
ROLLBACK;
RETURN -1;
END
END LOOP
CLOSE upPrice;
(d) ;
END
参考答案:
(a):cursor
(b):open
(c):Pno, Pprice, Mno
(d):commit;return 0
【问题2】(6分)
假设用户1和用户2同时购买1份A商品,用户3查询和浏览A商品。三个用户对应事务的部分调度序列如表4-1所示(事务中未进行并发控制),其中TO时刻该A商品的库存数量p_nums为100。
表4-1 事务运行部分调度示意表
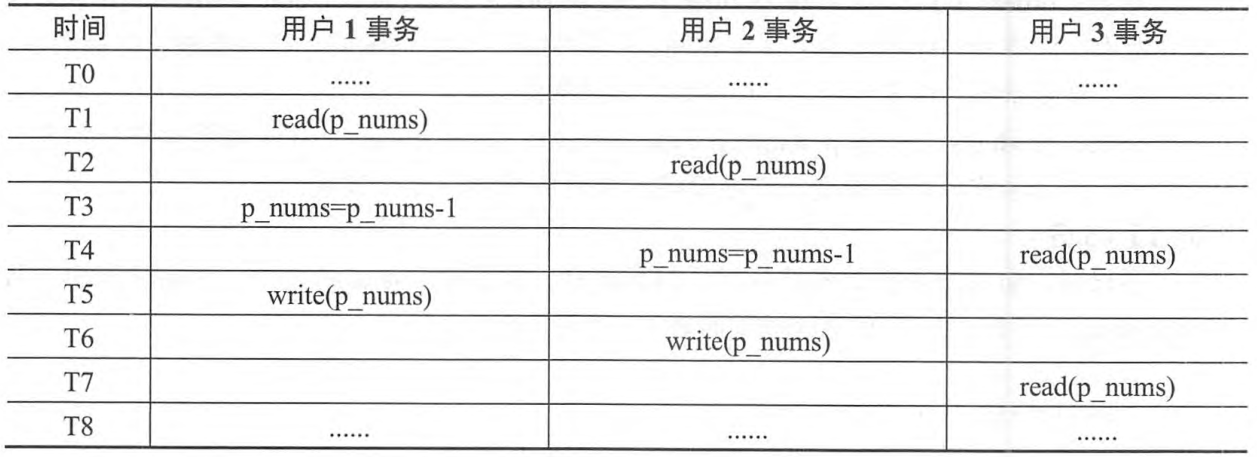
请说明T4、T7时刻,用户3事务读取到的p_nums 数值分别是多少。请说明T8时刻事务调度结果是否正确?若不正确请说明属于哪一种数据不一致性。
参考答案:
T4时刻,p_nums的值为100。
T7时刻,p_nums的值为99。
事务调度结果不正确。
丢失修改。
【问题3】 (4分)
为保证并发事务的正确性,系统要求所有事务需遵循两段锁协议。
(1)请用100字以内的文字简要解释两段锁协议,并说明“两段”的含义。
(2)请说明两段锁协议是否可以避免死锁?如不能避免,应采取什么措施解决死锁问题。
参考答案:
(1)两段锁协议是指同一事物对任何数据进行读写之前必须对数据加锁;在释放一个封锁之后,事务不再申请和获得任何其他锁。
所谓“两段”的含义是:事务分为两个阶段,第一阶段是获得封锁,称为扩展阶段;第二阶段是释放封锁,称为收缩阶段。
(2)两段锁协议不能避免死锁。
解决措施是采用死锁检测机制,发现后按照一定算法解除死锁。
● 试题五:阅读下列说明,回答问题1至问题3,将解答填入答题纸的对应栏内。
【说明】
如果一个数据库恢复系统采用检查点机制,且其日志文件如表5-1所示,第一列表示日志记录编号,第二列表示日志记录内容。<Ti, START>表示事务Ti开始执行,<Ti, COMMIT>表示事务Ti提交,<Ti, D,VI, V2>表示事务Ti将数据项D的值由V1修改为V2。请回答以下问题。
表5-1 日志记录列表
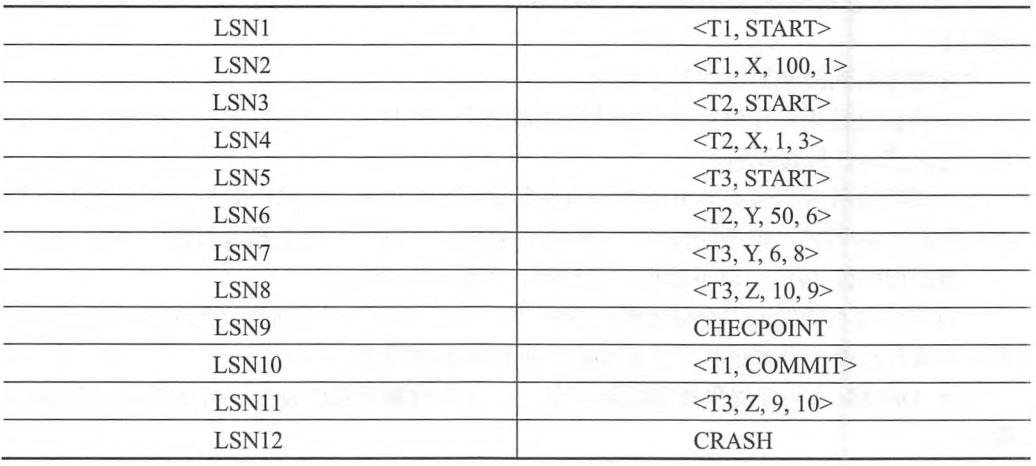
【问题1】 (6分)
假设系统开始执行前X=100,Y=50,Z=10,系统出错恢复后,X、Y、Z各自的数值是多少?
参考答案:
X=1,Y=50,Z=10。
系统出错前,只提交了事务T1,即将数据项X的值由100改为1。
T2和T3事务由于未提交,其中的修改未生效。
【问题2】 (4 分)
系统发生事务故障时,故障恢复有撤销事务(undo)和重做事务(redo)两个操作。请给出系统恢复时需要redo的事务列表和需要undo的事务列表。
参考答案:
需要redo的事务列表:T1。
需要undo的事务列表:T2,T3。
系统恢复的方法为:
①清除尚未完成的事务对数据库的所有修改,undo(撤销)所有未完成的事务(从后往前)。
②将缓冲区中已完成事务提交的结果写入数据库,redo(重做)所有已提交的事务(从前往后)。
T1已完成事务提交,需要redo
T2和T3事务尚未完成,需要undo
【问题3】 (5 分)
请用100字以内的文字,简要描述系统出错后,基于检查点的恢复过程。
参考答案:
步骤1:反向扫描日志文件,确定需要redo的事务和需要undo的事务。
步骤2:对需要undo的事务撤销已经执行的操作。
步骤3:对需要redo的事务重新执行已执行的操作。