1 内存(RAM)和磁盘(如HDD或SSD)的读写速度差异
内存(RAM)和磁盘(如HDD或SSD)的读写速度差异很大,这是因为它们基于完全不同的技术和物理原理。内存的访问速度远快于磁盘。
-
内存(RAM):数据是直接在CPU可以快速访问的内存芯片上进行读写的。内存访问的延迟通常在几十纳秒(ns)范围内,数据传输速率可以达到每秒几十到几百GB。
-
硬盘驱动器(HDD):基于旋转磁盘的存储设备,读写数据需要移动磁头到正确的位置,这个过程相对较慢。HDD的平均访问延迟通常在几毫秒(ms)范围,数据传输速率一般在每秒几十到几百MB。
-
固态硬盘(SSD):虽然SSD是基于闪存的,速度比HDD快很多,但通常仍然比RAM慢。SSD的访问延迟通常在几十到几百微秒(μs)范围,数据传输速率可以达到每秒几百MB到几GB。
大体上,内存的速度比HDD快约10,000倍到100,000倍,比SSD快约100倍到1000倍。这些数字只是粗略估计,实际性能会根据具体硬件和操作的不同而有所变化。
因此,当你比较像Redis(内存数据库)和MySQL(通常存储在HDD或SSD上)这样的系统时,Redis在数据访问速度上有显著优势,这是它被广泛用于需要高速读写的场景(如缓存)的原因之一。
2 Linux网络配置文件
[root@hspEdu100 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="2e5a5c25-b0b3-489a-aecd-1461cf86d9d8"
DEVICE="ens33"
ONBOOT="yes"
#IP 地址
#IPADDR=192.168.200.130
#网关
#GATEWAY=192.168.200.2
#域名解析器
#DNS1=192.168.200.2
#IP 地址
IPADDR="192.168.198.135"
#网关
GATEWAY="192.168.198.2"
#域名解析器
DNS1="192.168.198.2"
#域名解析器,只写下面这个dns 解析失败
DNS2="8.8.8.8"
#子网掩码,不写默认就是255.255.255.0
NETMASK="255.255.255.0"
# 你希望 NetworkManager 接管并应用 ifcfg-ens33 文件中的配置
NM_CONTROLLED="yes"
3 安装Redis的过程以及启动redis的命令
#启动redis的命令
[root@hspEdu100 redis-6.2.6]# /usr/local/bin/redis-server /etc/redis.conf
#以下是查看端口和进程号的方式 查看是否启动成功
ps -aux | grep redis
netstat -anp | grep redis
netstat -anp | more
简略的redis安装过程如下:
#安装C语言环境gcc
[root@hspEdu100 ~]# yum install gcc
#编译redis
[root@hspEdu100 redis-6.2.6]# make
#安装redis
[root@hspEdu100 redis-6.2.6]# make install
[root@hspEdu100 redis-6.2.6]# cp redis.conf /etc/redis.conf
#修改配置信息 修改/etc/redis.con 后台启动 设置 daemonize no 改成 yes,并保存退出。 即设置为守护进程,运行完之后退出控制台,使其在后台运行,不影响其他指令的执行
[root@hspEdu100 redis-6.2.6]# vi /etc/redis.conf
#启动redis的命令
[root@hspEdu100 redis-6.2.6]# /usr/local/bin/redis-server /etc/redis.conf
#查看redis是否启动,是否在6379端口监听
[root@hspEdu100 redis-6.2.6]# ps -aux | grep redis
root 17163 0.0 0.3 162412 6684 ? Ssl 20:41 0:00 /usr/local/bin/redis-server 127.0.0.1:6379
root 17314 0.0 0.0 112728 988 pts/0 S+ 20:57 0:00 grep --color=auto redis
#查看redis是否启动,是否在6379端口监听
[root@hspEdu100 redis-6.2.6]# netstat -anp | grep redis
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 17163/redis-server
tcp6 0 0 ::1:6379 :::* LISTEN 17163/redis-server
#查看redis是否启动,是否在6379端口监听
[root@hspEdu100 redis-6.2.6]# netstat -anp | more
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp6 0 0 ::1:6379 :::* LISTEN 17163/redis-server
详细的redis安装过程如下:
#安装C语言环境gcc
[root@hspEdu100 ~]# yum install gcc
已加载插件:fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* base: mirror.aktkn.sg
* extras: mirror.aktkn.sg
* updates: mirror.aktkn.sg
软件包 gcc-4.8.5-44.el7.x86_64 已安装并且是最新版本
无须任何处理
[root@hspEdu100 ~]# gcc --version
gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Copyright © 2015 Free Software Foundation, Inc.
本程序是自由软件;请参看源代码的版权声明。本软件没有任何担保;
包括没有适销性和某一专用目的下的适用性担保。
[root@hspEdu100 ~]# cd /opt
[root@hspEdu100 opt]# ls
firefox-60.2.2-1.el7.centos.x86_64.rpm idea jdk mysql nginx-1.20.2.tar.gz rh tomcat VMwareTools-10.3.10-1395
[root@hspEdu100 opt]# ls
firefox-60.2.2-1.el7.centos.x86_64.rpm idea jdk mysql nginx-1.20.2.tar.gz redis-6.2.6.tar.gz rh tomcat VMwa
[root@hspEdu100 opt]# ll
总用量 152364
-rw-r--r--. 1 root root 95103108 10月 9 2018 firefox-60.2.2-1.el7.centos.x86_64.rpm
drwxr-xr-x. 3 root root 4096 1月 28 03:25 idea
drwxr-xr-x. 2 root root 4096 1月 28 02:35 jdk
drwxr-xr-x. 2 root root 4096 1月 28 03:52 mysql
-rw-r--r--. 1 root root 1062124 2月 6 02:45 nginx-1.20.2.tar.gz
-rw-r--r--. 1 root root 2476542 4月 7 20:20 redis-6.2.6.tar.gz
drwxr-xr-x. 2 root root 4096 10月 31 2018 rh
drwxr-xr-x. 4 root root 4096 2月 8 05:57 tomcat
-rw-r--r--. 1 root root 56431201 6月 13 2019 VMwareTools-10.3.10-13959562.tar.gz
drwxr-xr-x. 9 root root 4096 6月 13 2019 vmware-tools-distrib
-rw-r--r--. 1 root root 911021 1月 14 17:09 浴衣.jpg
[root@hspEdu100 opt]# tar -zxvf redis-6.2.6.tar.gz
[root@hspEdu100 opt]# ls
firefox-60.2.2-1.el7.centos.x86_64.rpm nginx-1.20.2.tar.gz tomcat
idea redis-6.2.6 VMwareTools-10.3.10-13959562.tar.gz
jdk redis-6.2.6.tar.gz vmware-tools-distrib
mysql rh 浴衣.jpg
[root@hspEdu100 opt]# cd redis-6.2.6/
[root@hspEdu100 redis-6.2.6]# ls
00-RELEASENOTES CONTRIBUTING INSTALL README.md runtest-cluster sentinel.conf TLS.md
BUGS COPYING Makefile redis.conf runtest-moduleapi src utils
CONDUCT deps MANIFESTO runtest runtest-sentinel tests
#编译redis
[root@hspEdu100 redis-6.2.6]# make
[root@hspEdu100 bin]# pwd
/usr/local/bin
[root@hspEdu100 bin]# cd /opt
[root@hspEdu100 opt]# ls
firefox-60.2.2-1.el7.centos.x86_64.rpm nginx-1.20.2.tar.gz tomcat
idea redis-6.2.6 VMwareTools-10.3.10-13959562.tar.gz
jdk redis-6.2.6.tar.gz vmware-tools-distrib
mysql rh 浴衣.jpg
[root@hspEdu100 opt]# cd redis-6.2.6/
[root@hspEdu100 redis-6.2.6]# ls
00-RELEASENOTES CONTRIBUTING INSTALL README.md runtest-cluster sentinel.conf TLS.md
BUGS COPYING Makefile redis.conf runtest-moduleapi src utils
CONDUCT deps MANIFESTO runtest runtest-sentinel tests
#安装redis
[root@hspEdu100 redis-6.2.6]# make install
cd src && make install
make[1]: 进入目录“/opt/redis-6.2.6/src”
CC Makefile.dep
make[1]: 离开目录“/opt/redis-6.2.6/src”
make[1]: 进入目录“/opt/redis-6.2.6/src”
Hint: It's a good idea to run 'make test' ;)
INSTALL redis-server
INSTALL redis-benchmark
INSTALL redis-cli
make[1]: 离开目录“/opt/redis-6.2.6/src”
[root@hspEdu100 redis-6.2.6]# cd /usr/local/bin/
[root@hspEdu100 bin]# ls
genhash redis-benchmark redis-check-aof redis-check-rdb redis-cli redis-sentinel redis-server
[root@hspEdu100 bin]# cd /opt/redis-6.2.6/
[root@hspEdu100 redis-6.2.6]# ls
00-RELEASENOTES CONTRIBUTING INSTALL README.md runtest-cluster sentinel.conf TLS.md
BUGS COPYING Makefile redis.conf runtest-moduleapi src utils
CONDUCT deps MANIFESTO runtest runtest-sentinel tests
[root@hspEdu100 redis-6.2.6]# cp redis.conf /etc/redis.conf
[root@hspEdu100 redis-6.2.6]# vi /etc/redis.conf
[root@hspEdu100 redis-6.2.6]# /usr/local/bin/redis-server /etc/redis.conf
[root@hspEdu100 redis-6.2.6]# netstat -anp | grep redis
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 17163/redis-server
tcp6 0 0 ::1:6379 :::* LISTEN 17163/redis-server
[root@hspEdu100 redis-6.2.6]# netstat -anp | more
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 17163/redis-server
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 1/systemd
tcp 0 0 0.0.0.0:6000 0.0.0.0:* LISTEN 7448/X
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN 7979/dnsmasq
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 7057/sshd
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 7058/cupsd
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN 11541/sshd: root@pt
tcp 0 36 192.168.198.135:22 192.168.198.1:59047 ESTABLISHED 11541/sshd: root@pt
tcp 0 0 192.168.198.135:22 192.168.198.1:54485 ESTABLISHED 12539/sshd: root@no
tcp6 0 0 :::3306 :::* LISTEN 7816/mysqld
tcp6 0 0 ::1:6379 :::* LISTEN 17163/redis-server
4 Redis使用 【redis-cli】
1 连接到 redis-server的两种方式
[root@hspEdu100 redis-6.2.6]# cd /usr/local/bin/
[root@hspEdu100 bin]# ls
genhash redis-benchmark redis-check-aof redis-check-rdb redis-cli redis-sentinel redis-server
#连接和退出redis的方式1 不指定端口,即使用默认的6379端口进行连接
[root@hspEdu100 bin]# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> quit
[root@hspEdu100 bin]#
#连接和退出redis的方式2 指定端口进行连接(适合修改过默认端口的情况,修改过端口的就必须指定端口进行连接)
#否则连接失败,因为如果不指定端口,就会使用默认的6379端口进行连接
[root@hspEdu100 bin]# redis-cli -p 6379
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> quit
[root@hspEdu100 bin]#
2 环境变量中包含 /usr/local/bin 目录 因此在任何目录下输入redis-server /etc/redis.conf都可以启动成功
#查看环境变量
[root@hspEdu100 bin]# env
PATH=/usr/local/java/jdk1.8.0_261/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
3 关闭redis-server 服务的指令shutdown的三种使用方式:
1 不指定端口 默认关闭的就是6379端口的 redis-server redis-cli shutdown
[root@hspEdu100 bin]# redis-cli shutdown
[root@hspEdu100 bin]# ps -aux | grep redis
root 17623 0.0 0.0 112724 988 pts/0 S+ 21:28 0:00 grep --color=auto redis
2 指定端口关闭 6379端口的 redis-server redis-cli -p 6379 shutdown
[root@hspEdu100 bin]# redis-server /etc/redis.conf
[root@hspEdu100 bin]# ps -aux | grep redis
root 17701 0.0 0.3 162412 6628 ? Ssl 21:34 0:00 redis-server 127.0.0.1:6379
root 17707 0.0 0.0 112724 984 pts/0 S+ 21:34 0:00 grep --color=auto redis
[root@hspEdu100 bin]# redis-cli -p 6379 shutdown
[root@hspEdu100 bin]# ps -aux | grep redis
root 17718 0.0 0.0 112724 988 pts/0 S+ 21:35 0:00 grep --color=auto redis
3 使用redis-cli指令进入redis-server内部关闭redis-server shutdown
[root@hspEdu100 bin]# redis-server /etc/redis.conf
[root@hspEdu100 bin]# ps -aux | grep redis
root 17663 0.0 0.3 162412 6624 ? Ssl 21:32 0:00 redis-server 127.0.0.1:6379
root 17669 0.0 0.0 112724 984 pts/0 S+ 21:32 0:00 grep --color=auto redis
[root@hspEdu100 bin]# redis-cli
127.0.0.1:6379> shutdown
not connected> quit
[root@hspEdu100 bin]# ps -aux | grep redis
root 17681 0.0 0.0 112724 988 pts/0 S+ 21:32 0:00 grep --color=auto redis
4 修改端口的方式 修改/etc/redis.conf 文件的 port 即可
[root@hspEdu100 bin]# vi /etc/redis.conf
# Accept connections on the specified port, default is 6379 (IANA #815344).
# If port 0 is specified Redis will not listen on a TCP socket.
port 6379 #即修改这里,使用端口号6379进行全局搜索字段即可 即命令行模式输入`/6379`
5 quit/exit 退出redis客户端 redis数据还在,shutdown结束redis-server 数据也还在
当你使用SHUTDOWN命令结束Redis服务器时,数据依然会被保存到磁盘上。SHUTDOWN命令会执行以下操作:
-
停止所有客户端连接:断开与所有客户端的连接。
-
执行数据持久化操作:如果Redis配置了持久化(RDB、AOF或两者都有),
SHUTDOWN命令会触发最终的数据持久化过程。这意味着,Redis会将内存中的数据保存到磁盘上的数据文件中。-
RDB(Redis数据库文件):在
SHUTDOWN时,会创建一个内存数据快照,并将其保存到磁盘上的.rdb文件中。 -
AOF(追加文件):如果启用了AOF持久化,Redis会确保AOF文件完整地反映了所有写操作,然后才关闭服务器。
-
-
退出Redis服务:完成所有必要的持久化操作后,Redis服务器将安全地退出。
因此,当你重新启动Redis服务器时,它可以从持久化文件(RDB或AOF)中重新加载数据,恢复到SHUTDOWN命令执行时的状态。这保证了即使在服务器关闭后,你的数据也不会丢失。
127.0.0.1:6379> set k1 king1
OK
127.0.0.1:6379> get k1
"king1"
127.0.0.1:6379> quit
[root@hspEdu100 bin]# redis-cli
127.0.0.1:6379> keys *
1) "k1"
127.0.0.1:6379> exit
[root@hspEdu100 bin]# redis-cli
127.0.0.1:6379> shutdown
not connected> quit
[root@hspEdu100 bin]# ps -aux | grep redis
root 29605 0.0 0.0 112724 984 pts/0 S+ 19:01 0:00 grep --color=auto redis
[root@hspEdu100 bin]# redis-server /etc/redis.conf
[root@hspEdu100 bin]# ps -aux | grep redis
root 29607 0.0 0.1 162412 2688 ? Ssl 19:01 0:00 redis-server 127.0.0.1:6379
root 29613 0.0 0.0 112724 988 pts/0 S+ 19:01 0:00 grep --color=auto redis
[root@hspEdu100 bin]# redis-cli
127.0.0.1:6379> keys *
1) "k1"
127.0.0.1:6379>
6 Redis命令
TTL是"Time to Live"的缩写,中文意思是“生存时间”。
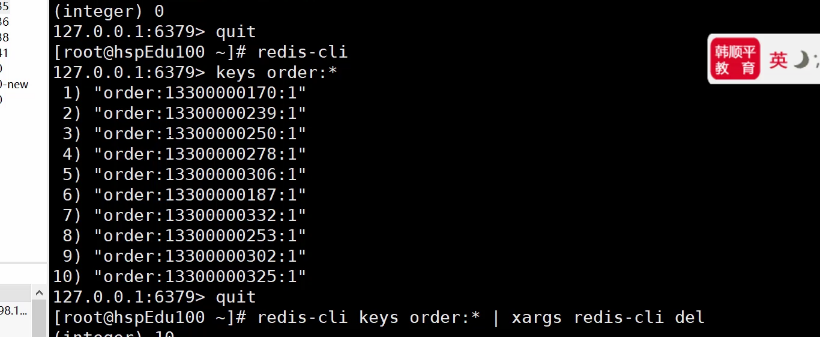
6.1 del指令进行模糊匹配删除Redis key 的方法
#del 指令不支持 *模糊匹配,会删除失败
del order:*
#使用管道指令,将keys 查询到的结果作为参数交给下一个指令继续操作,模糊匹配删除Redis key
redis-cli keys order:* | xargs redis-cli del
6.2 在Redis中,你可以使用EXISTS命令来判断某个键是否存在。该命令会返回1表示键存在,返回0表示键不存在。
以下是使用示例:
EXISTS key_name
例如,如果要检查名为user:12345的键是否存在,可以执行以下命令:
EXISTS user:12345
如果user:12345存在,则会返回1;如果不存在,则返回0。
String命令
| 命令 | 缩写全称 | 中文意思 |
|---|---|---|
| SET | Set | 设置指定 key 的值 |
| GET | Get | 获取指定 key 的值 |
| GETRANGE | Get Range | 返回 key 中字符串值的子字符 |
| GETSET | Get Set | 将给定 key 的值设为 value ,并返回 key 的旧值 |
| GETBIT | Get Bit | 对 key 所储存的字符串值,获取指定偏移量上的位 |
| MGET | Multiple Get | 获取所有(一个或多个)给定 key 的值 |
| SETBIT | Set Bit | 对 key 所储存的字符串值,设置或清除指定偏移量上的位 |
| SETEX | Set with EXpiration | 设置 key 的值为 value 同时将过期时间设为 seconds |
| SETNX | Set if Not eXists | 只有在 key 不存在时设置 key 的值 |
| SETRANGE | Set RANGE | 从偏移量 offset 开始用 value 覆写给定 key 所储存的字符串值 |
| STRLEN | STRing LENgth | 返回 key 所储存的字符串值的长度 |
| MSET | Multiple SET | 同时设置一个或多个 key-value 对 |
| MSETNX | Multiple SET if Not eXists | 同时设置一个或多个 key-value 对,仅当所有 key 都不存在时 |
| PSETEX | Precise SET with EXpiration | 以毫秒为单位设置 key 的生存时间 |
| INCR | INCrement | 将 key 中储存的数字值增一 |
| INCRBY | INCrement BY | 将 key 所储存的值加上给定的增量值 |
| INCRBYFLOAT | INCrement BY FLOAT | 将 key 所储存的值加上给定的浮点增量值 |
| DECR | DECrement | 将 key 中储存的数字值减一 |
| DECRBY | DECrement BY | 将 key 所储存的值减去给定的减量值 |
| APPEND | APPEND | 将 value 追加到 key 原来的值的末尾 |
这个表格包含了缩写中含有的单词本身,它们的简单中文解释以及音标。
| 缩写单词 | 中文解释 | 音标 |
|---|---|---|
| Set | 设置,安装 | /sɛt/ |
| Get | 获取,得到 | /ɡɛt/ |
| Range | 范围,区间 | /reɪndʒ/ |
| Bit | 位,比特 | /bɪt/ |
| Multiple | 多个的,多重的 | /ˈmʌltɪpl/ |
| Expiration | 过期,到期 | /ˌɛkspəˈreɪʃən/ |
| Exists | 存在 | /ɪɡˈzɪsts/ |
| Increment | 增加,增量 | /ˈɪnkrəmənt/ |
| Decrement | 减少,减量 | /ˈdɛkrɪmənt/ |
| Append | 追加,附加 | /əˈpɛnd/ |
| Precise | 精确的,准确的 | /prɪˈsaɪs/ |
| Float | 浮动的,浮点 | /floʊt/ |
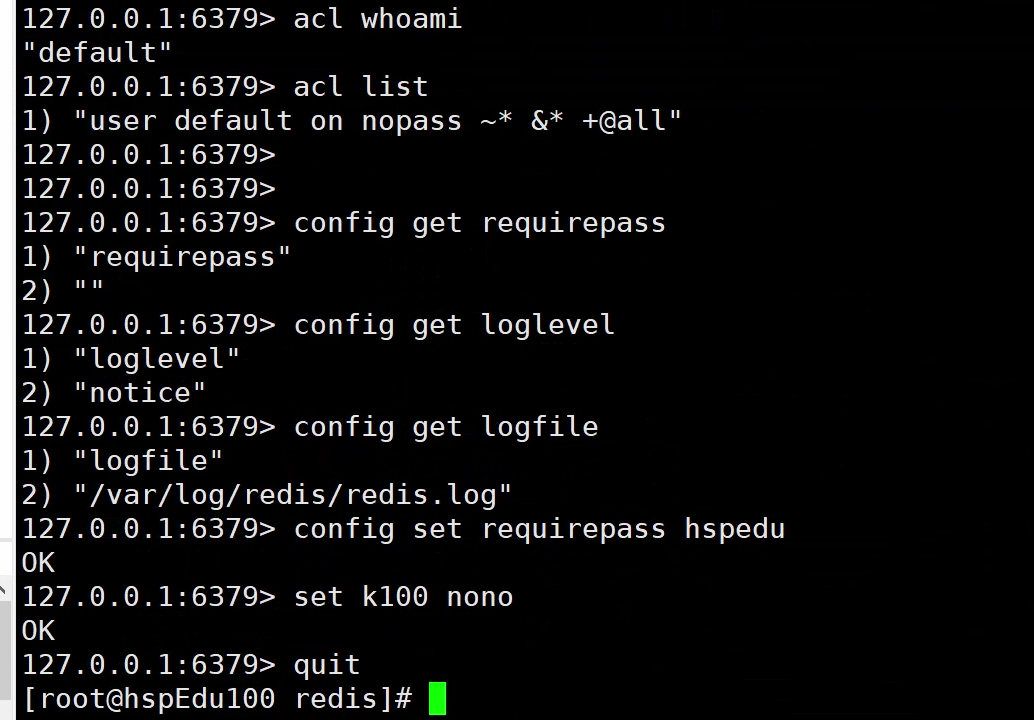
config 命令
# 获取配置文件中的信息
config get requirepass
config get loglevel
config get logfile
# 临时设置配置文件中的信息 退出客户端在重新登录才生效!
config set requirepass hspedu
expire命令注意点
当你在 Redis 中使用 EXPIRE 命令给一个键设置过期时间时,如果时间参数是负数,那么键会被立即删除。这就是为什么在你将 k1 的过期时间设置为 -1 后,使用 TTL 命令检查时显示 -2。-2 表示键不存在。
下面是一些关键点解释:
-
EXPIRE key seconds: 这个命令用于设置键的过期时间(单位是秒)。如果设置的秒数为正数,键将在指定的秒数后自动删除。如果秒数是负数,Redis 会立即删除该键。 -
TTL key: 这个命令返回键到期的剩余时间(单位是秒)。如果键不存在,返回-2;如果键存在但没有设置过期时间,返回-1。 -
在你的例子中:
-
首先,
expire k1 30设置了k1的过期时间为 30 秒,命令返回(integer) 1表示成功设置。 -
然后,连续两次检查
k1的剩余生存时间 (ttl k1),数值在逐渐减少。 -
接着,
expire k1 -1立即删除了k1,之后ttl k1返回-2表示k1不再存在。
-
-
最后你使用
keys *命令查看所有的键,发现k1已经被删除了。
所以,使用负数作为 EXPIRE 命令的时间参数确实会导致键的立即过期和删除。这可以作为一种快速删除键的方法,尤其是在需要立即清理数据时非常有用。
指令 set key value nx ex seconds
设置锁的同时指定该锁的过期时间,防止死锁
这个指令是原子性的,防止 setnx key value / expire key seconds 两条指令, 中间执行被打断过期时间到后会自动删除
7 none 不存在
127.0.0.1:6379> type k1
string
127.0.0.1:6379> type k10
none
8 在Redis的命令行界面(CLI)中,默认是没有代码补全功能的。这是因为Redis CLI主要设计为一个简单的命令行工具,用于快速测试和操作数据,而没有集成更高级的特性,如代码补全。
然而,有几种方法可以获得更好的Redis操作体验,包括代码补全:
-
使用第三方工具: 存在一些第三方的Redis客户端和工具,如Redis Desktop Manager, Redsmin, 或RDM等,这些工具通常提供了一个更丰富的用户界面,包括代码补全、数据可视化等高级功能。
-
使用IDE插件: 一些集成开发环境(IDE)提供了Redis插件,这些插件可能包含代码补全、语法高亮等功能。例如,Visual Studio Code(VSCode)有多个Redis插件可供选择。
-
使用高级终端: 某些高级终端(如iTerm2 for macOS)或Shell环境(如Zsh或Fish)可以配置以支持自动补全功能,包括对Redis命令的补全。这通常需要一定程度的自定义配置。
-
编写自定义脚本: 如果你倾向于使用命令行工具并且熟悉Shell脚本编程,你可以编写自定义脚本来为Redis CLI添加代码补全功能。这可能包括设置别名、编写函数来包装
redis-cli命令,或者利用现有的Shell代码补全框架。
虽然Redis自带的CLI在代码补全方面有限,但通过上述方法,你可以获得更丰富的开发和操作体验。选择哪种方法取决于你的个人喜好、操作系统和工作流程。
9 Redis只有使用shutdown关闭后再重启才会生效,如果不使用shutdown指令,而是直接使用redis-server指令重启redis,不会报错,但其实这时还是上次启动的redis,实际上没有重启
Redis只有使用shutdown关闭后再重启修改的配置文件配置才会生效,如果不使用shutdown指令,而是直接使用redis-server指令重启redis,不会报错,其实重启失败了,其实这时还是上次启动的redis,实际上没有重启
redis-cli
redis-server /etc/redis.conf
redis-cli shutdown
redis-server /etc/redis.conf
10 redis备份文件 dump.rdb 及备份文件位置说明
修改 /etc/redis.conf
# 默认情况下,在使用 redis-server /etc/redis.conf 指令启动redis的目录
# ,在使用shutdown指令后,生成dump.rdb文件对redis数据进行自动备份
# dir ./
# 修改为不论在哪个目录启动,关闭数据库即shutdown时,都到指定目录 /root/ 备份redis数据
dir /root/
#手动备份/生成/更新 dump.rdb文件的指令
#阻塞的
save
#非阻塞的
bgsave
11 redis.conf 中的save属性,如果设置为save "" ,在shutdown后,还会触发rdb的自动持久化吗?会
在 Redis 的配置文件 redis.conf 中,save 指令用于配置自动快照(snapshotting)的条件,即在多少秒和多少次键值对变更后自动保存数据到磁盘(RDB文件)。这种机制是 Redis 进行数据持久化的一种方式,被称为 RDB 持久化。
如果你在 redis.conf 中设置 save 为:
save ""
这意味着禁用了基于时间和变更次数的自动快照。具体到 Redis 关闭时的行为,这里需要区分两种情况:
-
正常关闭(如执行
SHUTDOWN命令): 在这种情况下,即使save配置为空(即所有的自动快照条件都被移除),Redis 依然会执行一次 RDB 快照。这是因为SHUTDOWN命令默认会触发保存操作,除非使用SHUTDOWN NOSAVE明确指定不保存。 -
异常终止: 如果 Redis 因为崩溃或其他非正常方式终止,且
save参数被设置为空,那么不会有自动的快照文件生成,这将导致数据丢失。
因此,如果你的配置中 save 被设置为 "",在正常使用 SHUTDOWN 命令关闭 Redis 时仍然会有 RDB 文件生成,保证了数据的持久化。但如果要避免任何自动保存,可以使用 SHUTDOWN NOSAVE 命令。如果担心数据丢失情况,建议定期使用 BGSAVE 命令手动触发 RDB 快照,或者考虑启用 AOF(Append Only File)持久化策略。
save "" 只禁用了基于时间和变更次数的自动快照?对shutdown的自动保存机制没有影响?
是的,你的理解是正确的。在 Redis 配置中将 save 设置为 save "" 确实仅仅禁用了基于时间间隔和键值对变更次数的自动快照机制。这意味着在正常运行时,Redis 不会因为达到某些操作阈值而自动进行 RDB 快照。
然而,这种设置对 SHUTDOWN 命令时的行为没有影响。当使用 SHUTDOWN 命令(不带任何参数)正常关闭 Redis 服务时,无论 save 配置如何,Redis 默认都会进行一次 RDB 快照以保存当前的全部数据到磁盘。这是一个设计上的选择,确保了即使在禁用自动快照的情况下,正常关闭数据库也不会导致数据丢失。
要避免在关闭时保存数据,可以使用带 NOSAVE 参数的 SHUTDOWN 命令,如:
SHUTDOWN NOSAVE
这条命令会使 Redis 服务器关闭而不进行任何形式的数据持久化。
因此,save "" 的设置确实只影响了自动快照的触发条件,而非关闭时的持久化行为。如果需要控制关闭时的持久化,应使用相应的 SHUTDOWN 命令参数来明确指定。
12 修复Redis数据,AOF持久化的磁盘文件
#修复Redis AOF文件的指令如下
redis-check-aof --fix /root/appendonly.aof
redis如果RDB和AOF同时开启,那么默认是从AOF恢复数据的,如果AOF文件损坏了,redis-server启动不起来。需要对AOF文件进行修复,再从AOF文件恢复数据到内存。
127.0.0.1:6379> shutdown
not connected> quit
[root@hspEdu100 ~]# ps -aux | grep redis
root 81411 0.0 0.0 112724 988 pts/0 S+ 15:20 0:00 grep --color=auto redis
[root@hspEdu100 ~]# redis-server /etc/redis.conf
[root@hspEdu100 ~]# ps -aux | grep redis
root 81419 0.0 0.0 112724 988 pts/0 S+ 15:21 0:00 grep --color=auto redis
[root@hspEdu100 ~]# redis-cli
Could not connect to Redis at 127.0.0.1:6379: Connection refused
not connected> quit
[root@hspEdu100 ~]#
[root@hspEdu100 ~]# redis-check-aof --fix /root/appendonly.aof
0x 9c: Expected prefix '*', got: 'h'
AOF analyzed: size=166, ok_up_to=156, ok_up_to_line=39, diff=10
This will shrink the AOF from 166 bytes, with 10 bytes, to 156 bytes
Continue? [y/N]: y
Successfully truncated AOF
13 Redis 同步频率设置/写回策略分为三种:
-
appendfsync always(谨慎使用):
每条 Redis 操作命令都会写入磁盘,最多丢失一条数据
始终同步,每次 Redis 的写入都会立刻记入磁盘/日志;性能较差但数据完整性比较好
-
appendfsync everysec(默认):
每秒同步,每秒记入磁盘/日志一次,如果宕机,本秒的数据可能丢失。
-
appendfsync no(不推荐):
不主动进行同步,把同步时机交给操作系统,由操作系统决定何时写入磁盘,Linux 默认 30s 写入一次数据至磁盘
14 如何理解AOF的数据一致性要强于RDB?
redis如果RDB和AOF同时开启,那么默认是从AOF恢复数据的 (AOF的数据一致性要强于RDB,默认情况下从AOF恢复数据,如果宕机的情况下,丢失数据最多就是1s内的数据,AOF数据一致性更强一些,因此作者设计时,可能是考虑的这个)
在 Redis 中,数据持久化主要有两种方式:RDB (Redis Database) 和 AOF (Append Only File)。理解 AOF 持久化提供的数据一致性优势相对于 RDB 持久化,需要对两者的工作原理有一个清晰的了解。
RDB 持久化
工作原理:
-
RDB 持久化通过创建数据集的内存快照来工作,在预定的时间间隔内(根据配置的规则如
save 30 5,即30秒内至少5个键被修改)执行。 -
当快照发生时,Redis 会 fork 出一个子进程,子进程会将当前内存中的数据集写入到一个临时 RDB 文件中。写入完成后,这个临时文件会替换掉旧的 RDB 文件。
数据一致性:
-
RDB 的缺点在于数据恢复只能回到最后一次快照的时间点。这意味着如果 Redis 服务器在两次快照之间失败了,那么自最后一次快照以来的所有数据变更都会丢失。
-
因此,RDB 更适用于对数据一致性要求不是非常高的场合,或者可以接受分钟级数据丢失的场景。
AOF 持久化
工作原理:
-
AOF 持久化记录每个写操作命令,并追加到 AOF 文件的末尾。这意味着每一个对数据库做出的更改都会即时被记录。
-
默认情况下,AOF 文件的更新策略为每秒同步一次,但可以配置为更频繁(甚至每次操作后)或者从不同步(这会增加数据丢失的风险)。
数据一致性:
-
AOF 提供了比 RDB 更高的数据一致性,因为所有的操作都被记录下来,可以重新执行这些操作来恢复数据。在配置为每次操作后同步时,AOF 可以实现零数据丢失。
-
AOF 文件通常会比 RDB 文件大,且恢复速度可能比从 RDB 恢复要慢,但提供了更好的数据安全保障。
结论
AOF 持久化方式的数据一致性之所以强于 RDB,主要是因为 AOF 会记录每一条写命令并根据配置实时同步,这减少了数据丢失的风险。相比之下,RDB 通过周期性快照来持久化数据,如果 Redis 在两次快照之间发生故障,那么这段时间内的所有数据更改都将丢失。
因此,如果业务场景对数据的实时性和一致性要求极高,推荐使用 AOF 持久化;如果是对性能要求更高,且可以容忍短时间内的数据丢失,可以考虑使用 RDB 持久化,或者两者结合使用以达到最优的效果。
15 悲观锁和乐观锁
悲观锁和乐观锁并不是特定于 Redis 或 MySQL 的概念,而是广泛应用于多种数据库和数据存储系统中的并发控制技术。这两种锁的机制各有特点,用于处理数据在多用户环境下的安全性和一致性问题。让我们详细了解它们在不同系统中的应用:
悲观锁
概念:悲观锁是一种保守的锁策略,假设最坏的情况,即在数据处理过程中,总是假设其他线程会尝试修改同样的数据。因此,悲观锁在数据处理前就会先锁定数据,直到事务完成才释放锁。这种策略适用于写操作多的环境,可以避免数据修改冲突。
应用:
-
MySQL:在传统的关系数据库管理系统(RDBMS)中,如 MySQL,悲观锁通常通过
SELECT FOR UPDATE语句实现,该语句在读取一条记录时,会对其加上排它锁(Exclusive Lock),直到事务结束。 -
Redis:Redis 并不内置传统的悲观锁支持,但可以通过其他机制实现类似功能,例如使用
SETNX命令(set if not exists)模拟锁的行为。
乐观锁
概念:乐观锁是一种宽松的锁策略,基于冲突在大多数情况下不会发生的假设。它允许多个事务几乎同时进行,只在事务提交时检查是否有冲突。如果发现冲突,事务可以选择重试或者放弃。乐观锁通常使用数据版本(version)控制或时间戳来实现。
应用:
-
MySQL:乐观锁在 MySQL 中通常不是直接由数据库引擎提供,而是通过在数据库表中使用一个版本号或时间戳字段实现。当更新数据时,会检查版本号是否发生变化,若未变化,则执行更新并增加版本号。
-
Redis:Redis 支持乐观锁机制,主要通过
WATCH命令实现。使用WATCH可以监视一个或多个键,如果在执行事务的EXEC命令前这些键被其他命令改动过,那么事务将失败。
总结
悲观锁和乐观锁都不是 Redis 或 MySQL 特有的;它们是通用的并发控制策略,广泛应用于不同的数据库和数据存储系统中。选择使用悲观锁还是乐观锁取决于应用场景的具体需求,例如操作的冲突率、性能要求、数据一致性需求等因素。在实际应用中,这两种锁策略有时会结合使用,以达到最优的性能和数据一致性。
16 watch 和 unwatch
A客户端先执行exec操作
127.0.0.1:6379> watch k1
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> incrby k1 4000
QUEUED
127.0.0.1:6379(TX)> exec
1) (integer) 4120
127.0.0.1:6379>
B客户端后执行exec操作
127.0.0.1:6379> watch k1
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> unwatch #在开启的multi事务中执行unwatch不可行,如果监控的k1已经被改变了
#,该事务会直接被打断,而不会执行到unwatch! 即被打断的事务中组队的命令一条也不会执行!!!
QUEUED
127.0.0.1:6379(TX)> incrby k1 2
QUEUED
127.0.0.1:6379(TX)> exec
(nil)
127.0.0.1:6379> get k1
"4120"
127.0.0.1:6379>
17 在 Java Web 应用中,使用 jQuery 或任何静态资源(如 CSS、JavaScript、图片等),这些资源的加载和引用都遵循同一基本规则:它们必须位于 Web 应用的可公开访问的目录中,通常是 web 目录下,而不是 WEB-INF 目录下。
关于 WEB-INF 目录
WEB-INF 目录用于存放应用的配置文件、类文件和库文件(JAR文件),以及不能直接由浏览器访问的其他资源(如 JSP 文件等)。这个目录的内容不会被 Web 容器(如 Tomcat)直接公开访问,是用来存放应用的“内部”资源。
关于静态资源的访问
对于静态资源,如 JavaScript 文件、CSS 文件或图片,它们应该放在 WEB-INF 外的某个目录中。常见的做法是在 Web 应用的根目录下创建如 script、css、img 等文件夹,以便这些资源可以被公开访问。例如:
-
Web 应用目录结构示例
/webapp
/WEB-INF
web.xml
/classes
/lib
/script
/jquery
jquery-3.1.0.js
/css
/images
在这种结构中,jQuery 文件位于 /script/jquery 目录下,可以通过相对 URL 路径直接访问。
关于您的 HTML 页面
您的 HTML 示例中引用的 jQuery 脚本路径是:
<script type="text/javascript" src="script/jquery/jquery-3.1.0.js"></script>
这里的路径 script/jquery/jquery-3.1.0.js 是相对于 Web 应用的根目录的。因此,您应该确保 script 目录位于应用的根目录下(即与 WEB-INF 同级),而不是在 WEB-INF 目录下。
结论
确保将 script 目录(及其中的 jquery 目录和文件)放置在 Web 应用的根目录下,而不是 WEB-INF 目录下。这样,jQuery 文件和其他静态资源就可以被用户的浏览器正常访问。如果放在 WEB-INF 下,浏览器将无法加载这些资源,因为这个目录是不对外公开的。
18 Servlet 规范
Servlet 规范是由 Java 社区过程(Java Community Process,JCP)提出的一系列标准,旨在定义 Java Servlet 技术的各种方面,包括 Servlet 的生命周期、与Web容器(如Tomcat, Jetty)的交互方式、目录结构等。Servlet 规范的目的是确保不同开发者开发的 Web 应用组件能够在所有遵循这些规范的 Web 容器上无缝运行。
主要内容
1. Servlet 生命周期
-
加载和实例化:容器负责加载 Servlet 类,并创建其实例。
-
初始化:通过调用
init()方法完成初始化。init方法只被调用一次。 -
请求处理:每接收一个请求,容器可能使用单独的线程调用
service()方法。service()方法根据请求的类型(GET、POST 等),进一步调用doGet(),doPost()等方法。 -
销毁:当容器关闭或容器需要释放资源时,
destroy()方法被调用,执行清理工作。
2. 目录结构和特殊文件
Servlet 规范定义了Web应用的标准目录结构,这在部署到任何兼容的Web容器时都是必须遵守的:
-
/WEB-INF:-
web.xml:部署描述文件,定义 Servlet、过滤器、监听器、安全配置等。 -
/classes:存放编译后的.class文件,即 Servlet 和其他类文件。 -
/lib:存放应用所需的 JAR 文件。根据规范,这个目录必须命名为lib(而不是libs或其他任何名称),且所有 JAR 文件必须直接位于此目录下,不支持子目录。
-
-
静态资源(HTML, CSS, JavaScript等)和 JSP 文件通常位于
WEB-INF目录外,以便可以直接被客户端请求访问。
3. Servlet 容器和服务器通信
-
Servlet 容器负责管理 Servlet 的生命周期,处理请求,以及维护和服务器的通信。
-
容器也负责会话管理、安全性、多线程管理等。
4. 安全性
-
Servlet 规范包括用于声明式安全配置的规则,允许开发者在
web.xml中配置安全约束。
Servlet API
Servlet API 提供了多个重要的接口和类,包括但不限于:
-
javax.servlet.Servlet -
javax.servlet.http.HttpServlet -
javax.servlet.ServletRequest -
javax.servlet.ServletResponse -
javax.servlet.Filter -
javax.servlet.http.HttpSession
兼容性和版本
-
Servlet 技术从 1997 年的 Servlet 1.0 发展至今,最新的主要版本是 Servlet 4.0,随 Java EE 8 一起发布。
-
每个版本的发布都可能包括新的功能、性能改进、安全性增强以及规范更新。
总结
Servlet 规范为 Java Web 开发提供了一套标准的规则和接口,确保开发的 Web 应用可以跨多个服务器和容器平台移植和运行。遵循这些规范可以帮助开发者编写更稳定、更安全、更高效的 Web 应用。
19 npm(Node Package Manager)介绍
npm(Node Package Manager)是JavaScript的包管理器,主要用于管理Node.js的模块,是目前世界上最大的开源库生态系统。npm不仅用于安装和管理包,还可以用来管理项目依赖关系和发布JavaScript工具和库。以下是npm的一些核心功能和特点:
-
包管理:
-
安装包:通过
npm install <package_name>命令可以安装一个或多个npm包到你的项目中。 -
更新包:通过
npm update命令可以更新项目依赖的包。 -
卸载包:通过
npm uninstall <package_name>命令可以从项目中卸载不再需要的包。
-
-
依赖管理:
-
npm通过
package.json文件管理项目的依赖关系。在这个文件中,你可以指定项目需要依赖的库及其版本号,npm会自动安装和更新这些依赖。 -
package-lock.json或npm-shrinkwrap.json文件用来锁定依赖的具体版本,确保开发、测试和生产环境中使用的依赖保持一致。
-
-
npm命令:
-
npm init: 初始化新项目,创建package.json文件。 -
npm start,npm test,npm run: 分别用于启动项目、运行测试和执行定义在package.json中的脚本。
-
-
存储库:
-
npm的官方存储库(registry)是一个庞大的网络数据库,包含了超过一百万个开源包。这些包可以是小到一个函数,大到完整的框架或工具库。
-
-
使用场景:
-
除了Node.js,npm也广泛用于前端JavaScript的开发,支持Angular、React和Vue.js等框架的包管理。
-
npm还可以用来安装命令行工具,比如Angular CLI、Create React App等。
-
npm因其高效的依赖管理和庞大的生态系统而在JavaScript社区中非常受欢迎,几乎成为现代Web开发的标准实践。
20 npm(Node Package Manager)和yum(Yellowdog Updater Modified)的区别
npm(Node Package Manager)和yum(Yellowdog Updater Modified)虽然都是包管理器,但它们服务于不同的操作系统和编程环境。以下是两者的主要区别:
1. 目标语言和平台
-
npm:
-
专门为JavaScript开发设计,主要用于管理Node.js项目中的包。
-
用于前端(如React, Angular, Vue.js)和后端(Node.js)JavaScript项目的依赖管理。
-
-
yum:
-
为基于Linux的系统(如Fedora、RedHat、CentOS)设计的包管理器。
-
主要用于安装、更新、搜索和管理Linux系统上的软件包和其依赖。
-
2. 依赖处理
-
npm:
-
自动处理项目的依赖问题,可以递归地下载和安装所有必需的依赖。
-
使用
package.json和package-lock.json文件管理项目依赖。
-
-
yum:
-
自动解析和处理软件包之间的依赖关系,安装所需的所有依赖软件包。
-
依赖不仅限于库,还包括系统组件和应用程序。
-
3. 包的类型和存储库
-
npm:
-
管理的是代码库,主要是各种JavaScript库和框架。
-
使用的是npm公共仓库,这是世界上最大的软件注册表。
-
-
yum:
-
管理的是整个软件包,这些软件包可能包括二进制文件、库、配置文件等。
-
通常使用由各个Linux发行版维护的多个仓库。
-
4. 命令和操作
-
npm的操作包括
install,update,uninstall,run,start,test等,针对项目开发流程的不同阶段。 -
yum的操作包括
install,update,remove,list,search等,更多关注于系统级的包管理。
5. 使用场景
-
npm:
-
主要用于软件开发过程中的包管理,特别是Web开发和Node.js环境。
-
对开发者友好,支持快速迭代和模块化开发。
-
-
yum:
-
用于系统管理员管理操作系统层面的软件包,包括系统工具和服务器应用程序。
-
确保系统的稳定性和安全性,支持系统级的更新和依赖管理。
-
总结来说,npm和yum各自在其领域内发挥着重要作用。npm适用于JavaScript和Web开发的环境,而yum则适用于Linux系统的软件管理。这两个工具的选择和使用依赖于你的具体需求和操作环境。
21 yum(Yellowdog Updater Modified)和rpm(RPM Package Manager)是Linux系统中用于包管理的两种工具
yum(Yellowdog Updater Modified)和rpm(RPM Package Manager)是Linux系统中用于包管理的两种工具,它们的关系可以通过它们的功能和用途来理解:
-
RPM:
-
基本概念:RPM是一种包管理系统,用来管理Linux下的软件包。它能够安装、卸载、验证、查询和更新计算机上的软件包。
-
包格式:RPM软件包是以
.rpm为后缀的文件,包含了编译好的软件及其文件和元数据(如版本信息、描述、依赖关系等)。 -
操作范围:RPM本身主要处理单个包及其安装过程,但它不处理包之间的依赖关系。如果一个软件包依赖于另一个未安装的包,RPM不会自动安装依赖的包,用户需要手动解决依赖问题。
-
-
YUM:
-
基本概念:YUM是基于RPM的包管理器,用于更高级的包管理操作。它是为了解决RPM包依赖问题而设计的。
-
功能:YUM使得管理软件包变得更加容易,它自动处理并解决软件包之间的依赖关系,自动下载和安装所有必需的依赖包。
-
工作方式:YUM通过使用存储库中的元数据来处理依赖关系,这些存储库是集中存储和分发软件包的服务器。YUM检查所有可用的包,计算依赖关系,并进行必要的安装和更新。
-
总结来说,RPM是一个基础的包管理工具,它可以进行软件包的安装和卸载等基本操作,但不处理依赖。而YUM则建立在RPM之上,提供自动处理依赖关系和其他高级功能的能力。可以把RPM视为工具集的基础,而YUM是在此基础上的扩展,使得包管理更加自动化和用户友好。
22 解释lua脚本为什么可以解决火车票超卖和库存遗留问题
在讨论秒杀系统中如何利用 Lua 脚本来解决超卖(overselling)和库存遗留(inventory leftover)问题之前,我们需要理解这两个问题的本质:
-
超卖问题:在高并发环境下,多个请求同时查询到有库存,导致实际卖出的票数超过了原本的库存数量。
-
库存遗留问题:由于并发和请求处理延迟,系统可能未能即时更新库存状态,导致实际上可售的票未完全销售出去。
在SecKillRedisByLua类中使用的 Lua 脚本可以有效解决上述问题,原因如下:
原子性
Lua 脚本在 Redis 中执行时具有原子性,即脚本执行过程中不会被其他 Redis 命令打断。这是因为 Redis 是单线程的,任何时候只能执行一个命令或一个脚本。因此,使用 Lua 脚本执行复杂的命令序列(如检查库存、减少库存、记录用户等)可以确保这一系列操作要么全部完成,要么全部不做,不会因并发执行而出现中断或数据不一致的情况。
脚本逻辑分析
local userid=KEYS[1];
local ticketno=KEYS[2];
local stockKey='sk:'..ticketno..":ticket";
local usersKey='sk:'..ticketno..":user";
local userExists=redis.call("sismember",usersKey,userid);
if tonumber(userExists)==1 then
return 2;
end
local num= redis.call("get" ,stockKey);
if tonumber(num)<=0 then
return 0;
else
redis.call("decr",stockKey);
redis.call("sadd",usersKey,userid);
end
return 1
分步解释:
-
用户和票种标识:通过
KEYS[1]和KEYS[2]接受用户 ID 和票号。 -
构建键名:分别为库存和用户购买记录构建 Redis 键名。
-
检查用户购买情况:查询是否已经记录过该用户的购买行为,如果是,则返回 2,表示不能重复购买。
-
查询库存数量:获取当前票的库存数量。
-
库存判断与操作:如果库存为 0 或以下,返回 0,表示票已卖光。否则,减少库存数量并记录用户的购买行为。
-
返回结果:最后根据操作的结果返回不同的状态码,1 表示抢票成功。
解决问题的机制
-
防止超卖:通过在单个原子操作中检查库存并直接减库,确保不会因为并发读取同一库存值而导致卖出超过实际库存的票。
-
防止库存遗留:即使在极高的请求量下,每次操作都确保库存状态的实时和正确更新,避免了因处理延迟导致的库存未能及时更新的问题。
通过将关键操作组合进一个原子性的 Lua 脚本中,在高并发环境下,Lua 脚本提供了一种高效且错误率低的解决方案,使得系统能够准确地处理每一个购票操作,从而精确地维护库存状态,有效避免了超卖和库存遗留问题。
23 Lua 脚本在 Redis 中的核心机制和特点
Lua 脚本在 Redis 中的使用机制有几个关键方面,它们共同确保了脚本的高效性和原子性,特别是在高并发环境中处理像秒杀这样的敏感操作时。以下是 Lua 脚本在 Redis 中的核心机制和特点:
1. 单线程执行
Redis 服务器是单线程的,这意味着在任何给定的时刻,只有一个命令或一个 Lua 脚本在执行。因此,当 Lua 脚本执行时,不会有其他命令插入执行脚本的命令序列中。这保证了脚本中的多个操作(如读取、写入、判断等)作为一个整体原子性地执行,无需额外的同步或锁机制。
2. 原子性
由于 Redis 的单线程特性,Lua 脚本的执行是原子的。这意味着一旦脚本开始执行,它会完成所有操作后才处理其他命令。这个特性是处理并发数据操作时非常重要的,因为它防止了竞态条件(race conditions),即多个进程或线程同时修改数据导致的数据不一致问题。
3. 性能优势
执行 Lua 脚本可以减少网络往返次数。通常,一个业务逻辑(如库存检查和更新)可能需要多个 Redis 命令,逐个发送这些命令会产生多次网络延迟。而将这些命令组合到一个 Lua 脚本中,一次发送和执行,可以显著减少网络延时,提高效率。
4. 脚本的预加载和SHA1校验码
-
预加载:Lua 脚本可以预先加载到 Redis 服务器中,每个脚本通过计算其内容的 SHA1 校验码来唯一标识。这样做的好处是,脚本只需上传一次,之后可以通过其 SHA1 校验码快速调用,无需再次发送整个脚本内容。
-
调用方式:预加载后,可以使用
EVALSHA命令通过脚本的 SHA1 校验码执行它,而不是每次都发送整个脚本代码,这样进一步优化了性能。
5. 错误处理和调试
虽然 Lua 脚本提供了原子操作的优势,但脚本本身仍可能编写错误。Redis 提供了调试工具如 redis-cli --ldb 来调试 Lua 脚本。错误处理通常需要在脚本中明确检查条件,并返回错误状态或信息。
6. 脚本的限制和安全性
-
限制:为防止恶意或效率低下的脚本长时间占用服务器,Redis 对 Lua 脚本执行时间有严格限制。如果脚本执行时间过长,可以通过配置强制终止。
-
安全性:由于脚本有很高的执行权限,错误的脚本可能导致数据损失或服务中断。因此,编写脚本时需要小心谨慎,确保逻辑正确。
通过这些机制,Lua 脚本在 Redis 中为数据操作提供了一个高效、安全、且原子性强的执行环境,特别适合处理那些需要多步操作并且对数据一致性要求极高的场景。
1 解释lua脚本为什么可以解决火车票超卖和库存遗留问题
核心代码如下:
package com.hspedu.seckill.redis;
import com.hspedu.seckill.util.JedisPoolUtil;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
/**
* @author yangda
* @create 2024-04-13-21:26
* @description: 使用Lua脚本完成秒杀, 可以同时解决超卖和库存遗留问题!
*/
public class SecKillRedisByLua {
/**
* 老师说明
* 1. 这个脚本字符串是在 lua 脚本上修改的, 但是要注意不完全是字符串处理
* 2. 比如 : 这里我就使用了 \" , 还有换行使用了 \r\n
* 3. 这些都是细节,如果你直接包 lua 脚本粘贴过来,不好使,一定要注意细节
* 4. 如果写的不成功,就在老师这个代码上修改即可
*/
static String secKillScript = "local userid=KEYS[1];\r\n" +
"local ticketno=KEYS[2];\r\n" +
"local stockKey='sk:'..ticketno..\":ticket\";\r\n" +
"local usersKey='sk:'..ticketno..\":user\";\r\n" +
"local userExists=redis.call(\"sismember\",usersKey,userid);\r\n" +
"if tonumber(userExists)==1 then \r\n" +
" return 2;\r\n" +
"end\r\n" +
"local num= redis.call(\"get\" ,stockKey);\r\n" +
"if tonumber(num)<=0 then \r\n" +
" return 0;\r\n" +
"else \r\n" +
" redis.call(\"decr\",stockKey);\r\n" +
" redis.call(\"sadd\",usersKey,userid);\r\n" +
"end\r\n" +
"return 1";
//使用lua脚本完成秒杀的核心方法
public static boolean doSecKill(String uid, String ticketNo) {
//先从redis连接池,获取连接
JedisPool jedisPoolInstance = JedisPoolUtil.getJedisPoolInstance();
Jedis jedis = jedisPoolInstance.getResource();
//就是将lua脚本进行加载。即加载到内存
String sha1 = jedis.scriptLoad(secKillScript);
//result是根据指定的sha1校验码,执行缓存在redis服务器的脚本
Object result = jedis.evalsha(sha1, 2, uid, ticketNo);
//这里就是根据lua脚本中写的逻辑 从redis执行完lua脚本后返回的值
String resString = String.valueOf(result);
//根据lua脚本执行返回的结果,做相应的处理
if ("0".equals(resString)) {
System.out.println("票已经卖光了...");
jedis.close();
return false;
}
if ("2".equals(resString)) {
System.out.println("不能重复购买...");
jedis.close();
return false;
}
if ("1".equals(resString)) {
System.out.println("抢票成功...");
jedis.close();
return true;
} else {
System.out.println("抢票失败.......");
jedis.close();
return false;
}
}
}
提取出来的lua脚本如下:
local userid=KEYS[1]; -- 获取传入的第一个参数
local ticketno=KEYS[2]; -- 获取传入的第二个参数
local stockKey='sk:'..ticketno..:ticket; -- 拼接 stockKey
local usersKey='sk:'..ticketno..:user; -- 拼接 usersKey
local userExists=redis.call(sismember,usersKey,userid); -- 查看在 redis 的
usersKey set 中是否有该用户
if tonumber(userExists)==1 then
return 2; -- 如果该用户已经购买, 返回 2
end
local num= redis.call("get" ,stockKey); -- 获取剩余票数
if tonumber(num)<=0 then
return 0; -- 如果已经没有票, 返回 0
else
redis.call("decr",stockKey); -- 将剩余票数-1
redis.call("sadd",usersKey,userid); -- 将抢到票的用户加入 set
end
return 1 -- 返回 1 表示抢票成功
在讨论秒杀系统中如何利用 Lua 脚本来解决超卖(overselling)和库存遗留(inventory leftover)问题之前,我们需要理解这两个问题的本质:
-
超卖问题:在高并发环境下,多个请求同时查询到有库存,导致实际卖出的票数超过了原本的库存数量。
-
库存遗留问题:由于并发和请求处理延迟,系统可能未能即时更新库存状态,导致实际上可售的票未完全销售出去。
在SecKillRedisByLua类中使用的 Lua 脚本可以有效解决上述问题,原因如下:
原子性
Lua 脚本在 Redis 中执行时具有原子性,即脚本执行过程中不会被其他 Redis 命令打断。这是因为 Redis 是单线程的,任何时候只能执行一个命令或一个脚本。因此,使用 Lua 脚本执行复杂的命令序列(如检查库存、减少库存、记录用户等)可以确保这一系列操作要么全部完成,要么全部不做,不会因并发执行而出现中断或数据不一致的情况。
脚本逻辑分析
local userid=KEYS[1];
local ticketno=KEYS[2];
local stockKey='sk:'..ticketno..":ticket";
local usersKey='sk:'..ticketno..":user";
local userExists=redis.call("sismember",usersKey,userid);
if tonumber(userExists)==1 then
return 2;
end
local num= redis.call("get" ,stockKey);
if tonumber(num)<=0 then
return 0;
else
redis.call("decr",stockKey);
redis.call("sadd",usersKey,userid);
end
return 1
分步解释:
-
用户和票种标识:通过
KEYS[1]和KEYS[2]接受用户 ID 和票号。 -
构建键名:分别为库存和用户购买记录构建 Redis 键名。
-
检查用户购买情况:查询是否已经记录过该用户的购买行为,如果是,则返回 2,表示不能重复购买。
-
查询库存数量:获取当前票的库存数量。
-
库存判断与操作:如果库存为 0 或以下,返回 0,表示票已卖光。否则,减少库存数量并记录用户的购买行为。
-
返回结果:最后根据操作的结果返回不同的状态码,1 表示抢票成功。
解决问题的机制
-
防止超卖:通过在单个原子操作中检查库存并直接减库,确保不会因为并发读取同一库存值而导致卖出超过实际库存的票。
-
防止库存遗留:即使在极高的请求量下,每次操作都确保库存状态的实时和正确更新,避免了因处理延迟导致的库存未能及时更新的问题。
通过将关键操作组合进一个原子性的 Lua 脚本中,在高并发环境下,Lua 脚本提供了一种高效且错误率低的解决方案,使得系统能够准确地处理每一个购票操作,从而精确地维护库存状态,有效避免了超卖和库存遗留问题。
2 也就是说上面的那一段lua脚本,每来一个客户端请求,就会在redis执行一次,同时这个lua脚本执行要么全部成功要么全部失败,同时具有原子性,对吗
是的,你的理解是正确的。让我们再详细解释一下这个 Lua 脚本如何在每个客户端请求时工作,以及它如何确保原子性和事务完整性:
每次客户端请求的执行
每当有客户端(比如一个用户尝试从一个在线秒杀活动购买票)发起请求时,该 Lua 脚本会被触发执行一次。脚本的执行是在 Redis 服务器端进行的,客户端仅需通过一个命令调用即可(通常是 EVALSHA 命令加上脚本的 SHA1 校验码)。这个过程包括以下几个步骤:
-
脚本加载和调用:
-
首次使用时,脚本通过
scriptLoad方法加载到 Redis,并得到一个 SHA1 校验码。 -
后续请求通过这个校验码来调用已加载的脚本,避免重复传输脚本代码。
-
-
脚本执行:
-
对于每个请求,脚本接收用户 ID 和票种编号作为参数。
-
脚本首先检查该用户是否已经购买过此票种。
-
然后检查当前的票库存。
-
根据库存情况,脚本会递减库存并标记用户已购买,或者返回一个错误/失败状态。
-
原子性和事务完整性
Lua 脚本在 Redis 中的执行是原子性的,这意味着脚本中的所有操作要么全部执行成功,要么全部不执行。这一点非常关键,因为它直接关系到数据的一致性和业务逻辑的正确性:
-
原子性:
-
脚本中的所有 Redis 命令在执行时不会被其他 Redis 命令中断。
-
这包括检查用户是否已购票、检查票的库存、递减库存和记录用户购买。
-
-
事务完整性:
-
如果脚本在执行任何命令时发生错误(比如库存键不存在),整个脚本的执行将被视为无效,所有修改都不会被应用。
-
这保证了不会出现因部分执行而导致的数据不一致问题。
-
这种机制特别适合处理秒杀这类需求,因为秒杀要求高效处理大量并发请求,同时必须确保不会发生超卖或销售数据错误。使用 Lua 脚本可以有效减少常规多命令事务处理中可能出现的延迟和错误,提高系统的响应速度和可靠性。
3 解释一下这里为什么不需要加锁了?常规的解决方法,不是需要对要被修改的数据加锁吗?比如这里的火车票的库存量
在传统的并发环境中,确实常常需要对将要修改的数据(如库存量)进行加锁,以防止多个进程或线程同时修改同一数据导致的问题(例如超卖)。加锁是为了确保在某段时间内,只有一个操作能够读取并修改目标数据,完成后其他操作才能继续。
然而,在 Redis 使用 Lua 脚本的场景中,加锁的机制并不是必需的,原因包括:
1. Redis 的单线程模型
Redis 是一个基于内存的数据结构存储,它本质上是单线程的。这意味着在任何时刻,无论执行多少命令,都是由一个单一的线程顺序执行的。因此,当一个 Lua 脚本被执行时,Redis 会处理完整个脚本中的所有命令,期间不会插入其他命令或访问,直到该脚本完成执行。
2. Lua 脚本的原子性
由于 Redis 的这种单线程特性,Lua 脚本执行具有原子性。原子性意味着脚本中的所有操作(读取库存、修改库存、记录购买等)都是在一个不可分割的独立单元中执行的。脚本一旦开始执行,就会连续执行到结束,期间不会被其他任何命令所中断。这等同于一个自动的锁定机制,保证了数据的一致性和完整性。
3. 避免死锁和简化设计
在多线程或分布式系统中,加锁操作需要小心处理,以避免死锁或降低性能问题。使用 Redis Lua 脚本可以自然地避免这些复杂性,因为它内部就通过命令序列保证了操作的原子性,无需外部的锁机制。
4. 性能优势
处理高并发请求时,加锁可能会显著降低性能,因为锁定操作需要时间,并且锁定期间其他线程或进程必须等待,这会增加响应时间。相比之下,Lua 脚本的使用最大化了 Redis 的性能,因为它减少了不必要的上下文切换和锁竞争。
5. 事务性操作
尽管 Redis 的命令通常是原子的,但是涉及多步操作(如检查并更新库存)的过程不是原子的。Lua 脚本的引入实质上是将这些步骤封装为一个原子操作,避免了在步骤之间进行的任何其他命令插入,从而模拟了“事务”的效果。
总之,Redis 通过 Lua 脚本提供了一种高效的方式来处理可能需要加锁的复杂并发操作。它不仅保证了数据操作的原子性,还通过其内部的单线程执行模型自然地避免了并发冲突和锁的需求,这使得在设计高并发应用程序(如秒杀系统)时,可以实现更高的效率和可靠性。
4 也就是说这里假设在客户端有300个请求并发过来,到了lua这里也会变为单线程的,这300个线程一个一个的执行,对吗?此时就不会出现并发问题,即超卖问题,也就不再需要对要修改的火车票库存加锁了,因为每次都是单线程的操作同时lua脚本具有原子性
是的,您的理解是正确的。让我们详细解析这个过程,以便更清晰地理解 Redis 和 Lua 脚本如何处理并发请求,尤其是在如秒杀这种高并发场景下。
并发请求处理
假设有300个客户端请求同时发起,试图对同一个火车票库存进行操作。在传统的多线程或分布式数据库环境中,这可能会引起竞态条件,需要通过锁机制来管理并发以防止数据冲突(如超卖)。但在 Redis 使用 Lua 脚本的情况下,处理方式如下:
-
请求到达 Redis:
-
这300个请求可能几乎同时到达 Redis 服务器,但由于 Redis 是单线程的,这些请求将在接收时被排队。
-
-
Lua 脚本执行:
-
Redis 从队列中取出一个请求并执行相关的 Lua 脚本。Lua 脚本中包含的所有命令(如检查用户是否已购买、检查库存、修改库存等)作为一个整体单元执行。这个执行过程是原子的,即不可被其他命令中断。
-
脚本确保在操作库存前,先检查库存是否足够,然后再进行递减。这个过程在单个脚本执行中完成,没有其他请求可以在脚本执行的中间阶段进行干预。
-
-
原子性保障:
-
由于 Lua 脚本的原子性,每个请求都完整地执行,没有任何其他操作可以在脚本检查库存和修改库存之间插入。这就像自动加了一个锁,保证了在修改数据之前,数据不会被其他请求修改。
-
-
脚本完成后处理下一个请求:
-
一旦一个请求的脚本执行完毕,Redis 会取下一个请求并执行其 Lua 脚本。这个过程会依次处理所有请求。
-
结果
在这种机制下,即使是高并发的请求,也能保证每个请求都正确地按顺序处理,且每次处理都是在数据状态最新的情况下进行的。这样就有效避免了超卖问题,因为:
-
每次减库存前都会检查库存是否足够。
-
不需要外部的锁机制,因为脚本的原子性本身就保证了操作的完整性和一致性。
-
性能更高,因为减少了锁竞争和上下文切换的开销。
因此,利用 Redis 的 Lua 脚本处理并发操作不仅可以提高效率,还可以简化并发控制的复杂性,是处理类似秒杀场景的理想选择。这种模式确保了即使在极高的并发请求下,也能保持数据的一致性和系统的稳定性。
5 这难道不会降低效率吗?并发变为了单线程的了,并发请求转变为单线程顺序处理
确实,将并发请求转变为单线程顺序处理,从理论上讲,可能会给人一种效率降低的印象。但在 Redis 和其 Lua 脚本的应用场景中,这种做法实际上依然保持了高效率,原因有以下几点:
1. 高效的内存操作
Redis 是一个基于内存的键值存储系统,所有的数据操作都是在内存中进行的,这使得数据访问非常快速。内存操作的速度远比磁盘(即使是 SSD)快得多,因此即便是单线程,其数据处理速度也足够应对大多数高并发场景。
2. 消除锁开销
在多线程环境中,管理并发通常需要使用锁来同步不同线程对共享数据的访问。锁机制不仅增加了开发的复杂度,还可能引入死锁和竞争状态等问题,特别是在高并发的情况下,锁的开销(包括获取锁、等待锁、释放锁的时间)可以显著影响性能。Redis 通过执行单线程操作消除了这些开销,从而在很大程度上提升了效率。
3. 原子操作减少中断和冲突
使用 Lua 脚本使得可以在单个原子操作中执行多个命令,这样不仅减少了因网络延迟带来的多次往返调用,也避免了操作之间的潜在冲突。例如,一个标准的库存检查和更新操作如果分开进行,可能在高并发下遇到多个请求同时检查库存足够但实际上库存已经不足的情况。
4. 避免上下文切换
多线程和多进程系统需要操作系统进行上下文切换,切换过程中包括保存一个任务的状态和加载另一个任务的状态。这些上下文切换在高并发环境下可以成为性能瓶颈。Redis 的单线程模型避免了这种上下文切换,从而更有效率地利用CPU时间。
5. 专门的用途和优化
Redis 和 Lua 脚本通常用于处理特定类型的任务(如会话管理、队列、实时计数、快速数据缓存、秒杀等),这些任务通常涉及到小块数据的快速操作,Redis 针对这些操作进行了优化。
结论
尽管从并发转为单线程听起来像是降低了处理能力,但由于上述因素,Redis 在处理大量请求时实际上能够提供非常高的性能。此外,Redis 的这种模型简化了并发数据处理的复杂性,使得开发者可以更专注于业务逻辑本身而不是底层的同步和锁问题。当然,如果遇到极端的高并发场景超过了 Redis 的处理能力,可以通过架构上的优化如增加更多的 Redis 实例,并通过分片或复制来进一步扩展系统的处理能力。
6 redis测试秒杀时使用到的命令
127.0.0.1:6379> smembers sk:bj_cd:user
(empty array)
127.0.0.1:6379> get sk:bj_cd:ticket
"588"
127.0.0.1:6379> set sk:bj_cd:ticket 600
OK
127.0.0.1:6379> get sk:bj_cd:ticket
"600"
127.0.0.1:6379> smembers sk:bj_cd:user
(empty array)
127.0.0.1:6379> get sk:bj_cd:ticket
"0"
127.0.0.1:6379> smembers sk:bj_cd:user
#使用ab工具在Linux下模拟高并发 一共发出1000个请求,每批次发出300个并发
[root@hspEdu100 ~]# ab -n 1000 -c 300 -p ~/postfile -T application/x-www-form-urlencoded http://192.168.198.1:8080/seckill/secKillServlet
#使用ab工具在Linux下模拟高并发 一共发出1000个请求,每批次发出300个并发
[root@hspEdu100 ~]# ab -n 1000 -c 300 -p ~/postfile -T application/x-www-form-urlencoded http://192.168.198.1:8080/seckill/secKillServlet
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 192.168.198.1 (be patient)
Completed 100 requests
Completed 200 requests
Completed 300 requests
Completed 400 requests
Completed 500 requests
Completed 600 requests
Completed 700 requests
Completed 800 requests
Completed 900 requests
Completed 1000 requests
Finished 1000 requests
Server Software: Apache-Coyote/1.1
Server Hostname: 192.168.198.1
Server Port: 8080
Document Path: /seckill/secKillServlet
Document Length: 4 bytes
Concurrency Level: 300
Time taken for tests: 0.890 seconds
Complete requests: 1000
Failed requests: 400 #重点看这里!!!
(Connect: 0, Receive: 0, Length: 400, Exceptions: 0)
Write errors: 0
Total transferred: 125400 bytes
Total body sent: 194000
HTML transferred: 4400 bytes
Requests per second: 1123.97 [#/sec] (mean)
Time per request: 266.911 [ms] (mean)
Time per request: 0.890 [ms] (mean, across all concurrent requests)
Transfer rate: 137.64 [Kbytes/sec] received
212.94 kb/s sent
350.58 kb/s total
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 19 18.0 14 61
Processing: 60 173 57.3 161 318
Waiting: 60 168 58.8 153 316
Total: 81 192 65.4 167 337
Percentage of the requests served within a certain time (ms)
50% 167
66% 216
75% 232
80% 258
90% 300
95% 313
98% 323
99% 327
100% 337 (longest request)
[root@hspEdu100 ~]#
24 redis主从复制
1 redis的主从复制 比如一主二仆 ,是基于rdb的还是aof的?
Redis 的主从复制机制是一种强大的功能,允许多个 Redis 服务器之间进行数据的同步。在一个典型的一主二从(一主两仆)的配置中,一个 Redis 服务器作为主节点,而其他两个服务器作为从节点。主节点负责处理写操作,而从节点则复制主节点的数据并可以处理读请求,这样可以提升读操作的性能并提供数据的高可用性。
复制的实现机制
Redis 的复制过程既可以基于 RDB(Redis Database Backup)文件,也可以结合 AOF(Append Only File)日志,具体步骤如下:
-
初始同步:
-
当从节点初次连接到主节点时,它们会进行一次初始同步。主节点首先创建一个当前数据的快照,通常是一个 RDB 文件,并将这个文件传输给从节点。
-
从节点接收到 RDB 文件后,会加载这个文件来重建数据,确保起点的数据状态与主节点一致。
-
-
命令传播:
-
一旦初始同步完成,主节点会继续将所有写命令以命令流的形式发送给从节点。这些命令是从主节点的命令历史中获取的,无论主节点是使用 RDB 模式、AOF 模式,还是两者兼用。
-
从节点执行接收到的写命令,从而保持与主节点的数据一致。
-
RDB vs AOF
-
RDB(Redis Database Backup):RDB 是一种持久化机制,通过创建数据集的时间点快照来实现。在复制过程中,RDB 文件用于进行全量复制。
-
AOF(Append Only File):AOF 是另一种持久化方式,记录每个写操作的日志。在 Redis 正常运行中,AOF 文件可以用来恢复操作历史。AOF 通常用于数据恢复,确保数据的完整性,但在主从复制的初始同步中,主要还是使用 RDB 文件来实现。
复制的选择
虽然复制过程基于 RDB 进行初始数据同步,但在复制期间主节点对数据的所有更改(无论是通过 AOF 还是直接操作)都会被序列化为命令并发送到从节点。因此,复制过程本身是独立于持久化机制的。这意味着无论主节点使用的是 RDB、AOF 还是两者兼用,从节点都能通过复制过程接收到所有数据修改命令,并实时地保持数据一致性。
结论
Redis 的主从复制机制,特别是在一主二从的配置中,主要是利用 RDB 文件来进行初始同步,然后通过命令传播(基于写命令的流)来维持从节点的数据更新。这种机制确保了数据的高可用性和一致性,同时提供了读写分离的能力,优化了读取性能。
2 我在/etc/redis.conf 中配置了 save 30 5 ,dir /root/ , 同时appendonly yes ,appendfilename "appendonly.aof", 此时使用redis主从复制需要注意哪些隐藏的问题/细节
在配置 Redis 进行主从复制时,同时启用 RDB 快照和 AOF 持久化策略,虽然提供了两重数据安全保障,但也引入了一些需要特别注意的问题和细节。下面是在使用这种配置时需要注意的几个关键点:
1. 持久化文件的存储位置
你提到配置中使用了 dir /root/ 作为持久化文件的存储目录。这可能带来一些潜在问题:
-
权限问题:
/root/目录通常属于root用户,并且对其他用户的访问权限是非常限制的。如果 Redis 服务不是以root用户身份运行,那么它可能无法正确写入这个目录,导致持久化失败。 -
安全性问题:将数据文件存储在
/root/目录中可能不是一个安全的做法,因为这增加了对根用户目录的潜在风险。
2. RDB 和 AOF 的同步策略
你的配置 save 30 5 指的是如果至少有 5 个 key 被修改,在 30 秒内进行一次 RDB 快照。同时,appendonly yes 表示启用了 AOF 持久化。这种配置虽然为数据安全提供了双重保证,但也有以下潜在问题:
-
性能问题:AOF 文件因为每个写操作都要记录,可能会在高写入负载下对 IO 性能产生影响。尽管 Redis 有多种 AOF 重写策略来减小文件大小,频繁的写操作和同步到磁盘操作仍可能导致性能瓶颈。
-
数据恢复:在恢复时,如果同时存在 AOF 和 RDB 文件,Redis 会优先使用 AOF 文件来恢复数据,因为它保证了更高的数据完整性和持久性。
3. 主从复制中的持久化行为
-
初始同步:主节点在初始同步给从节点的时候,默认会发送 RDB 文件。如果主节点配置了 AOF,但从节点优先使用 RDB 文件进行同步,那么在高速写入的环境下,初始同步完成后,可能还需要应用 AOF 文件中累积的写操作来实现最终的数据一致性。
-
复制延迟:如果主节点的写负载非常高,从节点可能会因为应用写命令日志(来自 AOF)而出现延迟。尤其是当 AOF 重写在发生时,可能会加剧这种延迟。
4. 备份和恢复策略
-
文件备份:由于你的配置将持久化文件放在了
/root/目录,确保这个位置的数据可以被定期备份并且可以安全恢复是非常关键的。 -
策略选择:考虑是否需要同时使用 RDB 和 AOF。例如,如果对数据完整性要求极高,应继续使用 AOF。如果对恢复速度有更高要求,或许可以优先考虑 RDB。
5. 配置建议
-
修改持久化目录:考虑将
dir改为非/root/目录,例如使用/var/lib/redis,这是一个常用的选择,通常默认具有适当的权限设置。 -
资源监控:持续监控 Redis 服务器的内存和磁盘 I/O 使用情况,确保性能不被持久化策略所拖累。
-
安全性:保证 AOF
和 RDB 文件的安全性,特别是在使用的目录权限应当被严格控制。
总之,当你配置 Redis 的主从复制并同时启用 RDB 和 AOF 持久化时,要综合考虑性能、数据安全性及操作的复杂度,合理配置以达到最佳的运行效果。
3 Redis 的 AOF (Append Only File) 持久化配置中涉及的写策略
对于 Redis 的 AOF (Append Only File) 持久化配置中涉及的写策略,确实有些误解需要澄清。Redis 提供了几种不同的 AOF 刷新到磁盘的策略,可以在 redis.conf 配置文件中通过 appendfsync 指令进行设置。这些策略包括:
1. 每次写操作后同步(appendfsync always)
这是最安全但也是最慢的策略,因为它要求每次写操作后都将数据立即同步到磁盘。这确保了即使在系统崩溃的情况下也不会丢失任何数据,但对于 I/O 性能的影响是最大的,特别是在高写负载下。
2. 每秒同步一次(appendfsync everysec)
这是默认的策略,它在安全性和性能之间提供了一个较好的平衡。在这种模式下,AOF 缓冲区的数据最多每秒写入磁盘一次。这意味着在极端情况下,可能会丢失最后一秒的数据,但对于大多数应用场景来说,这已经足够安全,同时对性能的影响相对较小。
3. 由操作系统决定(appendfsync no)
在这种配置下,Redis 将写操作的决定权交给操作系统,不强制每次操作后或每秒进行同步。这可能是所有选项中对性能影响最小的,但同时也是最不安全的。数据的同步完全依赖于操作系统的 I/O 调度和缓存策略,可能导致在系统崩溃时丢失更多的数据。
因此,当提到 AOF 可能对 I/O 性能产生影响的描述时,主要是指在 appendfsync always 模式下的表现。而默认的 appendfsync everysec 确实是一个折中的选择,它在确保数据安全性和维持较高的性能之间做了平衡。
如果你的系统可以容忍高达一秒的数据丢失,在大多数情况下 appendfsync everysec 是推荐的配置,因为它显著减少了对磁盘 I/O 的压力,同时仍然保持了较高的数据完整性。这种配置特别适合写入密集型的应用,可以有效缓解连续写入带来的性能负担。
4 在配置 Redis 主从复制时,确实会涉及到多个细节和潜在的配置错误,其中一个典型的错误就是不恰当地处理持久化文件的配置。如果一主二从的 Redis 配置中出现了使用相同持久化文件路径的情况,如您提到的所有实例都指向 /root/appendonly.aof,这将会引起严重的问题。
为什么会出现问题?
1. 文件写入冲突:
-
如果多个 Redis 实例(主和从)配置为写入同一个 AOF 文件,它们的写操作会相互冲突,因为每个实例都会尝试更新这一文件。这不仅会导致数据损坏,还可能引发各种不可预测的同步错误。
2. 权限和路径问题:
-
使用
/root/目录本身就可能存在权限问题,非 root 用户的 Redis 服务可能无法访问或写入/root/appendonly.aof文件。 -
即使权限足够,多个实例写同一文件也会因为文件锁和写入管理问题导致性能极度下降。
正确的配置方法
每个 Redis 实例应该有自己独立的持久化文件设置。这样做不仅可以避免写入冲突,还可以确保数据的安全性和完整性。
1. 不同的持久化文件路径:
-
主节点和每个从节点应配置为使用不同的持久化文件路径。例如:
-
主节点:
/var/lib/redis/master/appendonly.aof -
从节点1:
/var/lib/redis/slave1/appendonly.aof -
从节点2:
/var/lib/redis/slave2/appendonly.aof
-
-
这种配置方式确保了每个节点的操作不会相互干扰。
2. 使用适当的目录:
-
避免使用
/root/作为持久化文件的存储路径,常见的做法是使用/var/lib/redis/,并根据实例的角色设置子目录。
3. 权限设置:
-
确保 Redis 进程有足够的权限读写其持久化目录和文件。通常,Redis 服务会以其特定的用户身份运行(如
redis用户),需要确保这个用户对应的目录有合适的读写权限。
结论
-
独立文件:确保每个 Redis 实例使用独立的持久化文件,以避免多实例间的写入冲突和数据损坏。
-
目录管理:合理规划文件存储的目录结构,避免使用可能引起权限问题的目录,如
/root/。 -
监控与调优:持续监控 Redis 实例的性能和数据一致性,及时调整配置以应对可能的性能问题或数据异常。
通过这种方式,您可以有效地管理 Redis 的主从复制环境,避免因配置错误引起的性能和数据问题。
5 在您提供的配置情况下,即所有Redis实例(一主二从)都使用同一个AOF文件(/root/appendonly.aof)以及存储在/root/目录中,可能会引发多个严重问题。下面详细分析这些问题及提供测试这些问题的方法:
可能出现的问题
1. 文件访问权限问题:
-
/root/是 Linux 系统中的根用户目录,通常只有 root 用户有权限访问。 -
如果 Redis 服务不是以 root 用户身份运行,那么 Redis 进程可能无法访问或写入
/root/appendonly.aof,导致启动失败或在运行时发生错误。
2. 文件写入冲突:
-
所有实例写同一个 AOF 文件会导致写入冲突和数据损坏。Redis设计为每个实例维护自己的数据文件,多个实例写入同一文件会破坏文件结构,引起不可预测的错误。
3. 数据一致性问题:
-
即使从技术上能够写入同一个AOF文件,来自不同实例的数据写入也可能导致数据不一致,例如命令顺序混乱或重复写入,这将使得数据恢复变得复杂且易出错。
4. 性能问题:
-
多个实例竞争同一个文件会造成严重的性能瓶颈。文件系统必须处理来自不同进程的频繁写操作请求,增加了I/O等待时间,大幅降低性能。
测试这些问题的方法
测试文件权限问题:
-
启动测试:
-
尝试以非root用户身份启动Redis服务,并观察是否能成功启动。
-
查看Redis日志文件,通常位于
/var/log/redis/下,检查是否有关于文件权限的错误信息。
-
测试文件写入冲突和数据一致性问题:
-
并发写入测试:
-
配置一主二从,每个实例都指向同一个AOF文件。
-
使用压力测试工具如
redis-benchmark或自定义脚本,模拟高并发写入操作。 -
观察期间和之后的日志文件,查找可能的错误信息或警告,如 AOF 写入失败、数据损坏等。
-
重启所有Redis实例,检查数据是否能够一致性地恢复。
-
测试性能问题:
-
性能监控:
-
在进行并发写入测试时,使用工具如
iostat,vmstat和htop监控系统I/O性能和CPU使用情况。 -
比较所有实例指向同一AOF文件与指向不同AOF文件的性能差异。
-
解决方案建议
-
修改持久化文件路径:确保每个Redis实例使用独立的持久化文件,例如使用不同的子目录存储各自的
appendonly.aof文件。 -
调整目录权限:如果确有需要使用
/root/目录,确保Redis进程运行的用户有适当的访问权限。更安全的做法是使用其他如/var/lib/redis/的通用目录。 -
持续监控与评估:定期通过日志和性能监控工具评估Redis实例的运行状态和性能,及时调整配置以应对发现的问题。
通过上述测试和调整,可以有效地诊断和解决配置中可能存在的问题,确保Redis环境的稳定性和高效性。
6 这里的配置下如果重新启动各个不同端口的redis-server时 默认都是从同一个AOF文件恢复数据到内存对吗?是的
这里所说的配置如下:
即同时使用rdb和aof,aof默认为一秒同步一次 aof文件的位置这三个端口6379,6380,6381的redis-server 都放在dir `/root/appendonly.aof`
我在/etc/redis.conf 中配置了 save 30 5 ,dir /root/ , 同时appendonly yes ,appendfilename "appendonly.aof", 此时使用redis主从复制需要注意哪些隐藏的问题/细节
如果一主二从的Redis配置中,所有实例都指定从同一个AOF文件(例如/root/appendonly.aof)恢复数据,那么在重新启动时,理论上确实是这样的情况:每个实例都会尝试从这个指定的AOF文件读取数据以恢复到各自的内存中。然而,这样的配置是非常不建议的,因为它会引起多个问题,尤其是在数据一致性和文件访问上。但对于您的直接问题,我会提供一个清晰的答案。
确认问题的回答
是的,在您的配置下,如果没有其他限制或错误,一主二从的Redis实例会在重新启动时尝试从同一AOF文件(/root/appendonly.aof)恢复数据。这意味着:
-
主实例和每个从实例都会读取相同的AOF文件来构建起初启动时的数据状态。
-
由于所有实例都配置为使用相同的AOF文件路径,它们在启动时独立地尝试解析并应用该文件中记录的所有写命令。
潜在的问题
尽管理论上这种配置是可行的(即每个实例都从同一个文件恢复数据),但实际操作中可能遇到的问题包括:
-
文件锁和并发访问:如果多个实例几乎同时启动,并尝试读同一个物理文件,可能会因操作系统的文件锁策略而导致性能问题或读取冲突。
-
数据恢复的完整性:由于AOF文件是追加写入的,如果文件在某些写入时刻被破坏(例如,由于硬件故障、系统崩溃等),可能无法完整恢复数据。
-
性能影响:从同一个AOF文件恢复,特别是文件很大时,可能导致显著的性能瓶颈和启动延迟。
测试和验证方法
为了验证这一行为并识别可能的问题,您可以:
-
监控日志:查看Redis启动日志,确认是否有关于AOF文件读取的错误或警告信息。
-
性能监控:在实例启动时使用系统监控工具(如
htop,iostat等),观察CPU和磁盘I/O的使用情况,评估从一个AOF文件恢复数据时的性能影响。 -
数据一致性检查:在所有实例启动后,检查各实例数据的一致性,验证是否所有命令都被正确执行和恢复。
建议
建议为每个Redis实例配置独立的持久化文件路径,这不仅避免了上述问题,还可以确保系统的稳定性和数据的安全性。如果实在需要从同一个AOF文件启动多个Redis实例(这在实际应用中极为罕见且不推荐),应确保启动过程中管理好文件访问同步和性能优化。
25 Redis集群搭建
1 搭建Redis集群的命令
当您使用 redis-cli 创建 Redis 集群时,命令应包括所有参与的节点地址和端口号,以及每个主节点的副本(从节点)数量。在您的示例中,看起来您希望创建一个包含三个主节点和三个从节点的集群,每个主节点有一个副本。这里是整理好格式的命令:
redis-cli --cluster create 192.168.198.135:6379 192.168.198.135:6380 192.168.198.135:6381 192.168.198.135:6389 192.168.198.135:6390 192.168.198.135:6391 --cluster-replicas 1
redis-cli --cluster create --cluster-replicas 1 \
192.168.198.135:6379 \
192.168.198.135:6380 \
192.168.198.135:6381 \
192.168.198.135:6389 \
192.168.198.135:6390 \
192.168.198.135:6391
这个命令的解释如下:
-
redis-cli --cluster create:这是创建 Redis 集群的基本命令。 -
--cluster-replicas 1:这指定了集群中每个主节点将有一个副本(从节点)。这意味着如果您有三个主节点,您还需要有三个从节点来满足这个副本要求。 -
接下来是所有参与集群的 Redis 实例的 IP 地址和端口号。在这个例子中,所有的实例都部署在
192.168.198.135这个IP上,但使用不同的端口(6379, 6380, 6381, 6389, 6390, 6391)。
在执行此命令时,redis-cli 工具会与这些实例交互,配置它们形成一个集群,其中三个实例将被配置为主节点,另外三个实例将被配置为相应的从节点。
注意:在创建集群之前,请确保每个参与的 Redis 实例已经被正确配置为集群模式,包括启用集群支持并设置适当的集群配置参数。此外,执行此命令时,您可能会被提示确认集群的创建,因为这将清除所有目标实例上的所有数据。
2 Redis集群搭建中 主从redis服务器 的对应关系说明
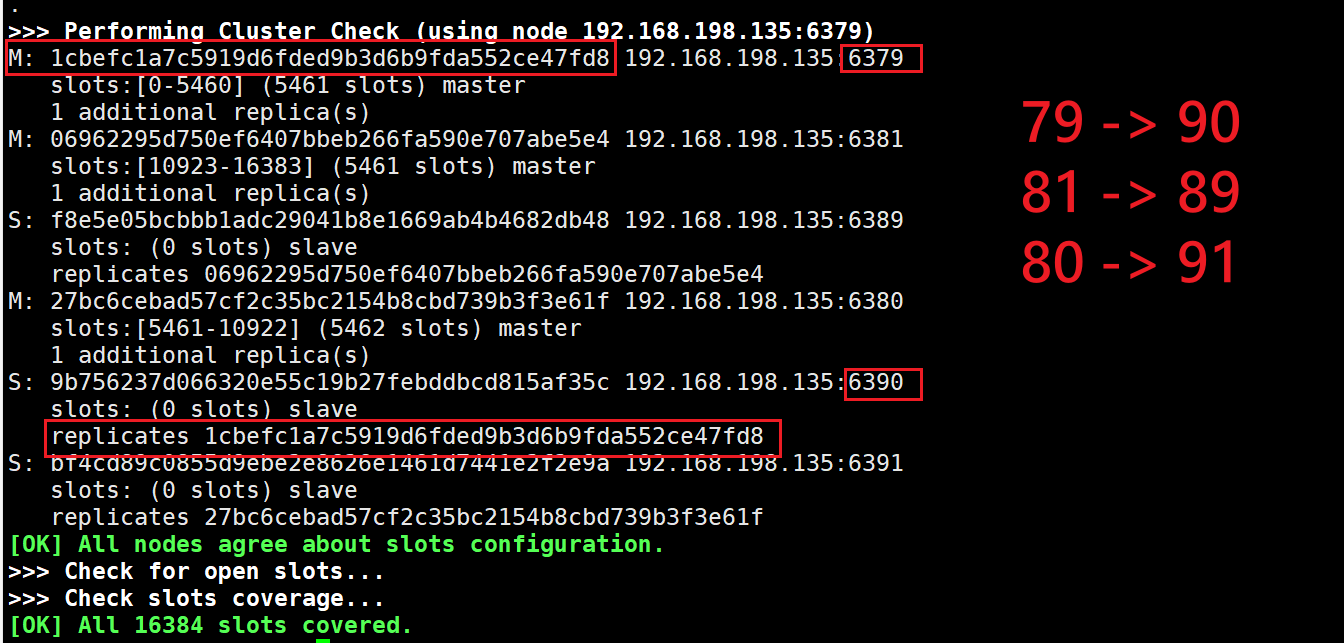
3 可以通过{}来定义组的概念,从而使 key 中{}内相同内容的键值对放到一个slot 中去
192.168.198.135:6380> mset k4 v4 k5 v5 k6 v6
(error) CROSSSLOT Keys in request don't hash to the same slot
192.168.198.135:6380> mset k4{order} v4 k5{order} v5 k6{order} v6
-> Redirected to slot [16025] located at 192.168.198.135:6381
OK
192.168.198.135:6381> keys *
1) "k6{order}"
2) "k5{order}"
3) "k1"
4) "k4{order}"
192.168.198.135:6381>
在 Redis Cluster 中使用了一种叫做 哈希标签 的技术,这使得拥有相同标签的键会被散列到同一个槽(slot)中,进而确保它们存储在同一个节点上。这里使用的 {order} 就是这种哈希标签的示例。
哈希标签的工作原理
在 Redis 集群中,每个键都通过 CRC16 哈希算法对键名进行哈希,然后取模 16384(Redis 集群的槽总数)来决定该键属于哪个槽。当键名中包含 {...} 形式的哈希标签时,哈希函数只会对 {} 中的内容进行哈希计算,这意味着所有带有相同哈希标签内容的键都会落在同一个槽中。
示例解释
在您的示例中:
mset k4{order} v4 k5{order} v5 k6{order} v6
-
k4{order},k5{order},k6{order}:这三个键都包含相同的哈希标签{order},因此它们被计算哈希值时只计算{order},这导致所有这些键都映射到了同一个槽(slot 16025)。 -
被重定向:你最初向端口 6380 发送命令,但由于这些键属于槽 16025,该槽被映射到了端口 6381 上的节点,所以 Redis 客户端被自动重定向到了 6381 端口的节点。
-
存储在同一个节点:
k4{order},k5{order},k6{order}因为属于同一个槽,所以被存储在同一个 Redis 节点上。
使用哈希标签的好处
-
事务支持:Redis 集群不支持跨多个键的事务,除非这些键落在同一个槽中。使用哈希标签可以使涉及多个键的操作(如事务或 Lua 脚本操作)可能执行。
-
数据局部性:保证相关的数据存储在同一节点上,有助于减少因为远程键访问导致的延迟。
注意事项
虽然哈希标签提供了确保键分布到同一个槽的方法,但过度使用或不当使用可能会导致槽的数据分布不均,影响集群的性能和扩展性。合理设计键名和使用哈希标签对于维护一个高效和平衡的 Redis 集群至关重要。
4 查询集群中的值 命令
1) 指令 : CLUSTER KEYSLOT <key> 返回 key 对应的 slot 值
2) 指令 : CLUSTER COUNTKEYSINSLOT <slot> 返回 slot 有多少个 key
3) 指令 : CLUSTER GETKEYSINSLOT <slot><count> 返回 count 个 slot 槽中的键
192.168.198.135:6381> keys *
1) "k6{order}"
2) "k5{order}"
3) "k1"
4) "k4{order}"
192.168.198.135:6381> cluster keyslot k1
(integer) 12706
192.168.198.135:6381> cluster keyslot k4{order}
(integer) 16025
192.168.198.135:6381> cluster countkeysinslot 12706
(integer) 1
192.168.198.135:6381> cluster countkeysinslot 16025
(integer) 3
192.168.198.135:6381> cluster getkeysinslot 16025 1
1) "k4{order}"
192.168.198.135:6381> cluster getkeysinslot 16025 2
1) "k4{order}"
2) "k5{order}"
192.168.198.135:6381> cluster getkeysinslot 16025 3
1) "k4{order}"
2) "k5{order}"
3) "k6{order}"
192.168.198.135:6381>
5 优雅的关闭redis集群的指令
[root@hspEdu100 ~]# ps -aux | grep redis
root 114817 0.0 0.1 240752 3684 ? Ssl 4月14 0:51 redis-server *:6379 [cluster]
root 114834 0.0 0.1 164972 3472 ? Ssl 4月14 0:49 redis-server *:6380 [cluster]
root 114852 0.0 0.1 242800 3596 ? Rsl 4月14 0:51 redis-server *:6390 [cluster]
root 114858 0.1 0.1 242800 3648 ? Rsl 4月14 0:52 redis-server *:6391 [cluster]
root 115623 0.1 0.1 245872 3668 ? Ssl 00:46 0:49 redis-server *:6381 [cluster]
root 115683 0.1 0.1 252016 3536 ? Ssl 00:49 0:46 redis-server *:6389 [cluster]
root 122986 0.0 0.0 112724 988 pts/2 S+ 13:50 0:00 grep --color=auto redis
[root@hspEdu100 ~]# redis-cli -p 6379 shutdown
[root@hspEdu100 ~]# redis-cli -p 6380 shutdown
[root@hspEdu100 ~]# redis-cli -p 6381 shutdown
[root@hspEdu100 ~]# redis-cli -p 6389 shutdown
[root@hspEdu100 ~]# redis-cli -p 6390 shutdown
[root@hspEdu100 ~]# redis-cli -p 6391 shutdown
[root@hspEdu100 ~]# ps -aux | grep redis
root 123057 0.0 0.0 112724 984 pts/2 S+ 13:57 0:00 grep --color=auto redis
如果对数据的完整性极端敏感,考虑使用 redis-cli shutdown 以确保数据持久化逻辑符合特定的业务需求。
在您的情况中,看起来您尝试使用 killall 和 redis-cli 命令来关闭 Redis 服务,但遇到了一些问题。下面我将详细解释如何正确地关闭 Redis 集群的各个节点。
关闭 Redis 集群的正确步骤:
1. 使用 redis-cli shutdown 命令 (最优先考虑)
每个 Redis 服务器实例都可以通过 redis-cli 工具和 shutdown 命令单独关闭。您需要为每个端口执行一次命令:
redis-cli -p 6379 shutdown
redis-cli -p 6380 shutdown
redis-cli -p 6381 shutdown
redis-cli -p 6389 shutdown
redis-cli -p 6390 shutdown
redis-cli -p 6391 shutdown
这些命令将逐个关闭监听在各个指定端口上的 Redis 服务器实例。
2. 使用 kill 命令
如果由于某种原因 redis-cli shutdown 命令不起作用,您可以使用 kill 命令发送 SIGTERM 信号来优雅地关闭进程:
kill 114817 114834 114852 114858 115623 115683
如果需要强制关闭,可以使用 kill -9:
kill -9 114817 114834 114852 114858 115623 115683
killall redis-server
避免的错误
-
使用
killall错误:killall需要一个进程名而不是 PID,因此killall redis-server可能是您想要的命令。killall 114817是不正确的,因为 114817 是 PID,不是进程名称。 -
错误的
redis-cli命令格式:redis-cli -p 63* shutdown和redis-cli shutdown -p 63*是语法错误。redis-cli不支持端口号的模糊匹配。
检查 Redis 是否成功关闭
关闭所有实例后,您可以通过 ps -aux | grep redis 来检查是否还有 Redis 进程在运行。如果命令输出为空,则表明所有 Redis 实例都已成功关闭。
ps -aux | grep redis
总结
确保使用正确的命令和方法来关闭您的 Redis 集群实例是很重要的。根据您的系统配置和权限,选择使用 redis-cli shutdown 或 kill 命令。如果遇到权限问题(如使用非 root 用户尝试关闭运行在高权限端口的服务),您可能需要以 root 用户执行这些命令。
使用 killall redis-server 命令可以关闭所有正在运行的 Redis 服务进程,但是否能够“优雅地”关闭取决于 killall 命令的默认行为和具体的系统配置。
如何 killall 工作:
-
默认信号:在大多数 Unix-like 系统上,
killall命令默认发送SIGTERM(信号15)到所有名为redis-server的进程。SIGTERM信号告诉进程应当终止运行,它允许进程优雅地清理资源(如关闭文件描述符、通知客户端等),然后正常退出。 -
优雅关闭:对于 Redis 而言,接收到
SIGTERM信号时,它会尝试执行一个优雅的关闭,包括:-
完成所有正在处理的命令。
-
将当前数据持久化到磁盘(如果启用了 AOF 或 RDB 持久化)。
-
关闭网络连接。
-
释放内存和其他资源。
-
注意事项:
-
数据安全:使用
killall redis-server关闭 Redis 过程中,如果 Redis 配置为使用 AOF 持久化并且设置了每秒同步,那么数据应该是安全的。因为 Redis 会在接收到SIGTERM信号后,将内存中的数据刷写到 AOF 文件中。但如果 AOF 配置为在每次写入后同步,这可能导致在高负载情况下关闭过程中性能较低。 -
批量处理的风险:
killall命令会同时发送信号到所有匹配的进程,这意味着所有的 Redis 服务器将几乎在同一时间开始它们的关闭序列。在极端情况下,这可能会暂时增加对机器资源(如 CPU 和磁盘 I/O)的需求,尤其是当多个实例都尝试持久化大量数据到磁盘时。
测试优雅关闭:
为了验证 Redis 是否确实在收到 SIGTERM 信号后进行了优雅关闭,可以检查 Redis 日志文件(通常位于 /var/log/redis/ 或指定的日志文件路径),查找有关关闭的记录,确认是否完成了数据持久化和正常退出的相关日志条目。
结论:
是的,使用 killall redis-server 通常可以优雅地关闭 Redis,前提是 Redis 正确响应了 SIGTERM 信号。然而,建议在生产环境中使用更可控的方法(例如逐一关闭每个实例或使用专门的维护脚本),以更精细地管理关闭过程和最小化任何潜在的风险。如果对数据的完整性极端敏感,考虑使用 redis-cli shutdown 以确保数据持久化逻辑符合特定的业务需求。
26 redis实现分布式锁
1 实现redis分布式锁的代码以及分析
/**
* 编写方法,使用Redis分布式锁,完成对key 为num的数据的+1操作
* 测试如下:使用ab工具模拟高并发
* [root@hspEdu100 ~]# ab -n 1000 -c 100 http://192.168.198.1:8080/redisTest/lock
*/
@GetMapping("/lock")
public void lock() {
//先得到一个uuid值,作为锁的值,防止误删其他用户的锁
String uuid = UUID.randomUUID().toString();
//1. 获取锁/设置锁 key->lock :
// redisTemplate.opsForValue().setIfAbsent() 就相当于执行 setnx 指令
// Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "ok");
//设置锁的同时设置过期时间为3秒,防止在业务代码中因异常退出
// ,没有执行到释放锁的语句 redisTemplate.delete("lock"); 造成死锁。
// 注意设置的过期时间,一定要比执行业务代码所有的时间长一些,否则会造成获取锁控制不住了,造成锁紊乱
// Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "ok",3, TimeUnit.MICROSECONDS);//微秒
// Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "ok",3, TimeUnit.MILLISECONDS); //毫秒
// Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "ok",3, TimeUnit.SECONDS); //秒
// 将前面得到的uuid值,作为锁的值
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 3, TimeUnit.SECONDS); //秒
if (lock) { //true, 说明获取锁/设置锁成功
// key 为 num 的数据 要事先在redis初始化
Object value = redisTemplate.opsForValue().get("num");
//判断返回的value是否有值
if (null == value || !StringUtils.hasText(value.toString())) {
/**
* 返回值类型: 返回值 vs 没返回值
* 如果方法有返回值,则必须在方法声明时,指定返回值的类型。同时,方法中,需要使用
* return关键字来返回指定类型的变量或常量:“return 数据”。
* 如果方法没返回值,则方法声明时,使用void来表示。通常,没返回值的方法中,就不需要
* 使用return.但是,如果使用的话,只能“return;”表示结束此方法的意思。
*/
//如果 value没有值 直接返回,即结束方法
return;
}
//value有值,就将其转为int类型
// int num = Integer.parseInt((String) value);
int num = Integer.parseInt(value.toString());
//将num+1 再重新设置回redis,注意这里使用的是前加加
redisTemplate.opsForValue().set("num", ++num);
//1释放锁 - lock
// redisTemplate.delete("lock");
//2释放锁 - lock。为了防止误删除其他用户的锁,先判断当前的锁是不是前面获取/设置到redis的锁,如果相同,再释放
// if (uuid.equals((String) redisTemplate.opsForValue().get("lock"))){
// redisTemplate.delete("lock");
// }
//3释放锁=====使用 lua 脚本来锁, 控制删除原子性========
// 定义 lua 脚本
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
// 使用 redis 执行 lua 执行
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script);
// 设置一下返回值类型 为 Long
// 因为删除判断的时候,返回的 0,给其封装为数据类型。如果不封装那么默认返回 String 类型,
// 那么返回字符串与 0 会有发生错误。
redisScript.setResultType(Long.class);
// 第一个是 script 脚本 ,第二个需要判断的 key,第三个就是 key 所对应的值
// 老 韩 解 读 Arrays.asList("lock") 会 传 递 给 script 的 KEYS[1] , uuid 会 传 递 给 ARGV[1] , 其它的小伙伴应该很容易理解
redisTemplate.execute(redisScript, Arrays.asList("lock"), uuid);
} else { //设置锁/获取锁失败,就休眠100ms,再重新设置锁/获取锁
try {
Thread.sleep(100);
lock(); //递归,重新执行
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
在 Redis 操作中使用 Lua 脚本可以确保执行命令的原子性。原子性是指在给定的命令序列中,所有命令作为一个单一的不可分割的工作单位执行,即命令序列要么完全执行,要么完全不执行。这对于涉及多步操作的情况非常重要,例如在分布式锁的实现中,我们需要确保检查锁和释放锁的操作不能被其他命令中断,以防止数据竞态和潜在的错误。
解释 Lua 脚本的使用
在提供的 Java 代码中,使用 Lua 脚本是为了安全地释放分布式锁。该脚本确保只有持有锁的实例(即设置锁时使用的 UUID)能够释放锁,避免了以下情况:
-
锁自动过期后,一个客户端尝试释放已经被另一个客户端获得的锁。
-
客户端在业务处理较长时锁过期,随后尝试释放已经不属于它的锁。
Lua 脚本详解
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
-
KEYS[1]:这是 Lua 脚本中使用的第一个键,对应 Java 代码中Arrays.asList("lock")的"lock"。这是锁的键名。 -
ARGV[1]:这是传递给 Lua 脚本的第一个参数,对应 Java 代码中传递的uuid。这是锁的值,即锁持有者的唯一标识。
逻辑解释:
-
redis.call('get', KEYS[1]):这部分从 Redis 中获取"lock"键的值。 -
== ARGV[1]:这部分检查获取到的锁值是否等于传入的uuid。 -
如果相等(即锁的当前持有者尝试释放锁),则执行
redis.call('del', KEYS[1])删除锁。 -
如果不相等,返回
0,表示锁未被删除(通常因为锁的值不匹配)。
Java 代码详解
相关的 Java 代码部分如下:
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(script); // 设置 Lua 脚本
redisScript.setResultType(Long.class); // 设置返回值类型为 Long
redisTemplate.execute(redisScript, Arrays.asList("lock"), uuid); // 执行脚本
-
DefaultRedisScript<Long>:定义一个RedisScript对象,其执行结果期望是一个Long类型。 -
setScriptText(script):这将 Lua 脚本内容设置为前面定义的字符串。 -
setResultType(Long.class):指明脚本执行后的返回类型是Long,这对应 Lua 脚本的返回值(删除操作返回的是影响的键的数量,通常是0或1)。 -
execute方法执行脚本,其中:-
Arrays.asList("lock"):指定脚本中用到的键列表,这里是"lock"键。 -
uuid:传递给脚本的参数,用以验证锁的持有者身份。
-
使用 Lua 脚本的方法提高了操作的原子性和安全性,避免了多个并发客户端之间的干扰和潜在的数据不一致问题。
2 为什么需要指定 setResultType(Long.class)
在使用 Spring Data Redis 的 RedisTemplate 来执行 Lua 脚本时,指定 setResultType 是重要的一步,因为它影响如何从 Redis 响应中解析返回值。解释和展开这一点需要考虑到 Java 类型系统与 Lua 脚本返回值之间的兼容性以及 RedisTemplate 的序列化和反序列化机制
-
类型安全:
-
Java 类型系统: Java 是一种强类型语言,意味着每个变量和表达式的类型都是在编译时已知的。为了保证类型安全,需要在运行时知道变量的类型。
-
Lua 脚本返回值处理: Lua 脚本的返回值可以是任何基本类型,如数字、字符串、布尔值等。当 Lua 脚本执行完毕后,Redis 将这个值作为响应发送回客户端(这里的客户端是
RedisTemplate)。RedisTemplate需要知道如何将这些原始类型的响应转换成 Java 中的对象。
-
-
反序列化过程:
-
当执行 Lua 脚本时,
RedisTemplate通过连接发送脚本到 Redis 服务器,并等待执行结果。 -
返回的数据类型需要与
RedisTemplate中配置的反序列化器兼容。如果脚本的预期返回类型与setResultType指定的类型不匹配,将导致反序列化失败,可能抛出异常,如类型转换异常。
-
-
默认行为和错误:
-
默认反序列化类型:如果不显式指定
setResultType,RedisTemplate可能会使用它配置的默认反序列化器来处理返回的数据。例如,如果默认使用StringRedisSerializer,那么它会尝试将所有返回值解析为字符串。 -
类型不匹配:如果 Lua 脚本返回一个整数(如删除操作的返回,表示被删除的键的数量),而反序列化器期望一个字符串,就会发生类型转换错误。这是因为字节序列无法被正确地解释为字符串,从而可能抛出
JsonParseException或其他类型的数据格式异常。
-
-
示例场景:
-
假设 Lua 脚本设计为返回删除键的数量(返回类型为整数)。如果
setResultType被错误地设置为String.class,或者没有设置而使用默认的字符串反序列化器,那么执行脚本后的反序列化过程将期望一个字符串格式的输入,而实际上接收到的是整数的字节表示,导致反序列化失败。
-
实践建议
为了避免类型不匹配和反序列化错误,开发者应当:
-
明确知道 Lua 脚本返回的数据类型,并据此设置正确的
setResultType。 -
根据操作的具体需求(如检查、删除键等),选择合适的返回类型(
Long、Boolean、List等)。 -
在
RedisTemplate的使用中,始终保持对数据类型的严格管理,以确保数据的一致性和程序的稳定性。
通过上述措施,可以有效利用 RedisTemplate 执行复杂的 Redis 操作,同时保障操作的原子性和程序的健壮性。
3 在 Redis 中使用 Lua 脚本来执行一系列操作,如检查键的值并基于该值决定是否删除该键,提供了一种强大的原子操作手段。原子性意味着一旦启动,该脚本内的操作序列将连续执行,中间不会被其他命令打断。这是通过 Redis 的脚本执行特性保证的:
如何保证原子性:
-
单线程执行:
-
Redis 服务器是单线程的。这意味着在任何给定时刻,只有一个命令或脚本在执行。因此,当一个 Lua 脚本在执行时,Redis 不会同时执行其他任何命令,直到该脚本完成。这确保了脚本中的所有操作都是连续执行的,无法被其他操作插入。
-
-
Lua 脚本的特性:
-
当 Redis 执行一个 Lua 脚本时,它会将整个脚本作为一个单一的命令来处理。所有的操作(如获取键、比较值、删除键等)都在脚本的控制下,连续无间断地执行。这消除了在操作中进行外部干预(如键值在检查和删除之间被修改)的可能性。
-
Lua 脚本例子详解:
考虑这个 Lua 脚本,它用来安全地释放分布式锁:
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
这个脚本执行以下步骤,全部作为一个原子操作:
-
redis.call('get', KEYS[1]):获取指定键(KEYS[1],这里是"lock")的当前值。 -
== ARGV[1]:比较这个值是否等于提供的 UUID(ARGV[1]),即检查当前客户端是否是锁的持有者。 -
redis.call('del', KEYS[1]):如果比较为真(即,锁的持有者尝试解锁),则删除该键,从而释放锁。 -
return 0:如果当前值不匹配,返回0,表示锁未被删除。
效果:
通过这种方式,Lua 脚本中的所有命令都在一个执行块中处理,这保证了以下几点:
-
一致性:在检查键的值和可能的删除操作之间不会有任何状态改变。
-
无干扰:脚本执行期间,不会有其他客户端操作可以更改键的状态。
-
高效:由于所有操作都在内存中完成,且由单个脚本执行,这大大提高了操作的效率和响应速度。
总结:
使用 Lua 脚本是处理需要原子性保证的 Redis 操作的推荐方法,特别是在涉及多步骤或条件操作时。它简化了代码逻辑,减少了网络往返次数,并通过服务器端原子性保证提高了操作的安全性和可靠性。这对于分布式锁的实现尤为重要,确保了锁的正确性和效率。
4也就是说在这段Lua脚本中查到的lock的值 和 java代码中设置的uuid相同,那么删除的就是这个uuid对应的锁对吗
是的,你理解得完全正确。在这段 Lua 脚本和 Java 代码的协同工作中,确保只有锁的持有者(即设置锁时使用的 UUID)能够删除锁是关键的安全性措施。这样做防止了所谓的 "wrongful lock release",即错误地释放了不属于当前进程/线程设置的锁。下面是如何通过这种机制来确保操作安全性的详细解释:
Java 代码部分
在 Java 代码中:
String uuid = UUID.randomUUID().toString(); // 生成一个唯一的标识符
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 3, TimeUnit.SECONDS); // 尝试设置锁
-
生成 UUID:
-
每次调用
lock()方法时,都会生成一个全新的 UUID。这个 UUID 用作锁的值,确保每个尝试获取锁的操作都有一个独一无二的标识。
-
-
尝试获取锁:
-
使用
setIfAbsent方法尝试设置锁,这个方法对应 Redis 的SETNX命令(Set if Not eXists)。它只在键"lock"不存在时(即没有其他客户端持有锁时)设置键,并赋值为这个 UUID。同时设置键的过期时间,防止锁永久占用。
-
Lua 脚本部分
在 Lua 脚本中:
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
-
检查锁持有者:
-
脚本首先通过
get命令检查"lock"锁的当前值(即当前持有者的 UUID)。KEYS[1]在这里是"lock",ARGV[1]是传递给脚本的 UUID。
-
-
条件删除:
-
如果
get命令返回的 UUID 与传入的 UUID 匹配(即当前尝试解锁的客户端确实是锁的持有者),那么执行del命令删除锁。这释放了锁,允许其他客户端获取。 -
如果不匹配,返回
0,锁不会被释放。
-
安全性和原子性
-
安全性:
-
只有锁的持有者才能释放锁。这防止了一个客户端意外或恶意释放另一个客户端的锁,这是在高并发环境下特别重要的。
-
-
原子性:
-
Lua 脚本在 Redis 中以原子方式执行,意味着在脚本执行期间不会有其他 Redis 操作插入。这确保了锁的检查和释放是连续的,不会因为并发操作而导致的状态变更。
-
通过结合 UUID 和 Lua 脚本,这种实现方式提供了一个既安全又高效的分布式锁方案,减少了因并发错误操作可能导致的问题,是在分布式系统中处理共享资源的一个常见模式。
27 Redis 的 ACL(Access Control List,访问控制列表)系统
在 Redis 的 ACL(Access Control List,访问控制列表)系统中,每个条目定义了一个用户可以执行的命令和访问的键模式。在你提供的 ACL 配置命令输出中:
1) "user default on nopass ~* &* +@all"
这条命令涉及到几个关键部分,解释如下:
-
user default:-
default是 Redis 中的默认用户名称,这意味着对于未进行特别配置的连接,将应用这个用户的规则。
-
-
on:-
这指用户是启用状态。对应的,
off表示用户被禁用。
-
-
nopass:-
这表明访问此用户不需要密码验证。
-
-
~*:-
这是一个键模式(key pattern),
~*表示用户可以访问任何键。~是引入键模式的标识符,*是一个通配符,匹配所有键。
-
-
&*:-
这是一个频道模式(channel pattern),用于发布/订阅操作。
&*表示用户可以订阅或发布到任何频道。&是引入频道模式的标识符,*同样是一个通配符,匹配所有频道。
-
-
+@all:-
这指定了用户可执行的命令集。
+@all表示用户有权执行所有命令。+是添加命令的标识,@all是一个命令组标识符,包括 Redis 所有命令的集合。
-
综上,这条 ACL 规则配置了一个名为 default 的用户,该用户无需密码即可连接,可以操作任何键,可以发布和订阅任何频道,并且可以执行 Redis 的所有命令。这基本上给予了该用户完全的权限,通常用于开发环境或信任环境中,但在生产环境中使用时需要谨慎,因为这可能会导致安全风险。
28 ACL 操作命令整理
从你提供的详细事务日志和命令中,我们可以得到 Redis ACL(访问控制列表)操作的精简概述,并突出显示关键命令及其效果。
关键ACL命令和操作
1. 列出所有ACL规则
127.0.0.1:6379> acl list
此命令列出所有用户的ACL设置。例如:
1) "user default on nopass ~* &* +@all"
2) "user jack on #... ~cached:* &* -@all +get +set"
3) "user tom off &* -@all"
-
default: 默认用户,无密码,可以访问所有键(
~*),订阅所有频道(&*),并执行所有命令(+@all)。 -
jack: 激活状态,指定密码,只能获取(
+get)和设置(+set)以 "cached:" 开头的键。 -
tom: 禁用状态,无法执行任何命令。
2. ACL 分类查询
127.0.0.1:6379> acl cat
此命令显示所有可用的命令分类,例如 keyspace, read, write 等。
3. 查看特定分类的命令
127.0.0.1:6379> acl cat string
显示指定分类下的所有命令,如 get, set 等。
4. 查看当前用户
127.0.0.1:6379> acl whoami
显示当前通过认证的用户。
5. 添加用户
127.0.0.1:6379> acl setuser tom
添加一个名为 "tom" 的用户,初始状态可能无特定权限。
6. 修改用户权限
127.0.0.1:6379> acl setuser jack on >password ~cached:* +get
设置 "jack" 用户,密码为 "password",限制访问以 "cached:" 开头的键,只能执行 get 命令。
7. 用户认证
127.0.0.1:6379> auth jack password
以 "jack" 用户名和 "password" 密码进行认证。
8. 删除用户
127.0.0.1:6379> acl deluser tom
删除名为 "tom" 的用户。
示例操作和其效果
-
Jack 无法运行除
get和set外的任何命令,也只能对键名以 "cached:" 开头的键进行操作。尝试访问其他键或执行其他命令会收到NOPERM错误。 -
Tom 被禁用,无法执行任何操作。
-
当 Jack 的权限被更新以包括
set命令后,他可以对 "cached:" 开头的键进行设置操作。
这些操作展示了 Redis ACL 的灵活性和强大的细粒度访问控制,允许管理员根据需要精确控制每个用户的权限。
标签:脚本,AOF,随手,Redis,redis,笔记,Lua,root From: https://www.cnblogs.com/kapai/p/18182910