安装
# 通过包管理工具安装
pip install sqlalchemy
# 查看安装的版本
In [4]: sqlalchemy.__version__
Out[4]: '2.0.28'
链接数据库
# 链接MySQL
# 链接MySQL的前提是已经安装了mysqlclient
# pip install mysqlclient
In [6]: from sqlalchemy import create_engine
# 语法: "engine://name:password@host/database", [echo]
# 创建引擎链接数据库 mysql代表数据库的类型 root代表用户 123456就是密码 db1代表数据库
# echo=True就表示执行过程中的代码show出来 如果为False就表示不展示出来
# ?charset=utf8 就是用来指定数据库编码集的
# 使用原生sql创建数据库的时候也可以指定编码集
# create database person charset=utf8;
In [7]: engine = create_engine('mysql://root:123456@localhost/db1?charset=utf8', echo=True)
In [8]: connection = engine.connect()
# 链接sqlite
In [9]: from sqlalchemy import create_engine
In [10]: engine = create_engine('sqlite:///test.db', echo=True)
In [11]: connection = engine.connect()
查询数据库
import sqlalchemy # 导入 SQLAlchemy 库
# 创建数据库引擎,echo=True 用于打印日志
engine = sqlalchemy.create_engine("mysql://root:123456@localhost/db1", echo=True)
# 通过引擎连接数据库
conn = engine.connect()
# 准备 SQL 查询语句(不推荐的写法,后面有讲解)
query = sqlalchemy.text("SELECT * FROM player")
# 执行 SQL 查询并获取结果集
result_set = conn.execute(query)
# 获取结果集中的第一条记录
first_message = result_set.first()
# 打印第一条记录
print(first_message)
# 关闭数据库连接
conn.close()
# 释放数据库引擎资源
engine.dispose()
import sqlalchemy # 导入 SQLAlchemy 库
# 创建数据库引擎,echo=True 用于打印日志
engine = sqlalchemy.create_engine("mysql://root:123456@127.0.0.1/db1", echo=True)
# 通过引擎连接数据库
conn = engine.connect()
# 使用上下文管理器确保连接的正确关闭
with conn:
# 准备 SQL 查询语句
query = sqlalchemy.text("select * from player")
# 执行 SQL 查询并获取结果集
result_set = conn.execute(query)
# 获取全部结果 方式1
items = result_set.all()
for item in items:
print(item)
# 遍历结果集并打印每一行 方式2 直接拿到结果集
# for line in result_set:
# print(line)
# 释放数据库引擎资源
engine.dispose()
创建表
使用MetaData,Table,Column以及字段类型在代码中来创建表
- 创建一个meta()
- 通过sqlalchemy.Table()创建表
- sqlalchemy.Table()有三个参数
- 表名
- 创建的meta()对象
- 数据
meta.create_all(engine) 通常在SQLAlchemy中用于在数据库中创建表,如果这些表尚不存在的话。如果数据库中已经存在与create_all尝试创建的表同名的表,SQLAlchemy不会默认引发错误。
相反,SQLAlchemy会跳过创建已经存在的表,并继续处理列表中的下一个表。这通常是安全的行为,因为它可以让你的应用程序在尝试重新创建已存在的表时不会崩溃。
然而,如果你想强制创建所有表,即使它们已经存在(在生产环境中可能不推荐这样做),你可以使用checkfirst参数,并将其设置为False:
meta.create_all(engine, checkfirst=False)
通过这样做,SQLAlchemy将尝试创建每个表,而不管它是否已经存在,这可能会导致错误,如果表的定义与数据库中已存在的表冲突。在生产环境中请谨慎使用此选项。
import sqlalchemy # 导入 SQLAlchemy 库
# 创建数据库引擎,echo=True 用于打印日志
engine = sqlalchemy.create_engine("mysql://root:243204@localhost/db_sqlal", echo=True)
# 创建一个元数据对象
meta = sqlalchemy.MetaData()
# 定义学生表
students = sqlalchemy.Table(
"Students", meta, # 表名为 "Students",关联到元数据对象 meta
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True), # 主键列
sqlalchemy.Column("first_name", sqlalchemy.String(32), nullable=False, unique=True), # 姓氏列,不可为空且唯一
sqlalchemy.Column("last_name", sqlalchemy.String(64), nullable=False) # 名字列,不可为空
)
# 创建所有尚未在数据库中存在的表
meta.create_all(engine)
mysql> desc students;
+------------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| first_name | varchar(32) | NO | UNI | NULL | |
| last_name | varchar(64) | NO | | NULL | |
+------------+-------------+------+-----+---------+----------------+
3 rows in set (0.03 sec)
插入数据
插入一条数据
import sqlalchemy # 导入 SQLAlchemy 库
# 创建数据库引擎,echo=True 用于打印日志
engine = sqlalchemy.create_engine("mysql://root:243204@localhost/db_sqlal", echo=True)
# 创建一个元数据对象
meta = sqlalchemy.MetaData()
# 定义学生表
students = sqlalchemy.Table(
"Students", meta, # 表名为 "Students",关联到元数据对象 meta
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True), # 主键列
sqlalchemy.Column("name", sqlalchemy.String(32), nullable=False, unique=True), # 名字列,不可为空且唯一
sqlalchemy.Column("birthday", sqlalchemy.Date, nullable=False) # 生日列,不可为空
)
# 创建所有尚未在数据库中存在的表
meta.create_all(engine)
# 准备插入语句
students_insert = students.insert()
print(students_insert) # 打印插入语句
# INSERT INTO "Students" (id, name, birthday) VALUES (:id, :name, :birthday)
# 准备插入的数据
insert_amigo = students_insert.values(name="Amigo", birthday="2002-2-22")
# 使用连接对象执行插入操作
with engine.connect() as conn:
# 执行插入操作
result = conn.execute(insert_amigo)
# 打印插入的主键值
print(result.inserted_primary_key)
# (1,)
# 提交事务
conn.commit()
插入多条数据
import sqlalchemy # 导入 SQLAlchemy 库
# 创建数据库引擎,echo=True 用于打印日志
engine = sqlalchemy.create_engine("mysql://root:123456@localhost/db_sqlal", echo=True)
# 创建一个元数据对象
meta = sqlalchemy.MetaData()
# 定义学生表
students = sqlalchemy.Table(
"Students", meta, # 表名为 "Students",关联到元数据对象 meta
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True), # 主键列
sqlalchemy.Column("name", sqlalchemy.String(32), nullable=False, unique=True), # 名字列,不可为空且唯一
sqlalchemy.Column("birthday", sqlalchemy.Date, nullable=False) # 生日列,不可为空
)
# 创建所有尚未在数据库中存在的表
meta.create_all(engine)
# 准备插入语句
students_insert = students.insert()
# 使用连接对象执行批量插入操作
with engine.connect() as conn:
# 执行批量插入操作
# 列表套字典,字典就对应一条记录
conn.execute(students_insert, [
{"name": "Jack", "birthday": "2018-8-18"},
{"name": "Mary", "birthday": "2019-9-19"},
{"name": "Tom", "birthday": "2000-10-10"}
])
# 提交事务
conn.commit()
查询所有记录
-- SQL查询
SELECT * FROM students;
# 函数表达式
students.select()
from db_init import engine, students
with engine.connect() as conn:
query = students.select()
result_set = conn.execute(query)
# 可用循环查询
# for row in result_set:
# print(row[0]) # 可用通过索引获取
# print(row.name) # 可用通过.获取
# 1
# Amigo
# 2
# Jack
# 3
# Mary
# 4
# Tom
# 也可用使用
row = result_set.fetchone()
print(row) # (1, 'Amigo', datetime.date(2002, 2, 22))
# 也可用使用
rows = result_set.fetchall()
print(rows) # 列表套元组 [(2, 'Jack', datetime.date(2018, 8, 18))), (...)), (...))]
条件查询
-- SQL查询
select * from students where birthday > '2008-2-2';
# 函数表达式
students.select().where(students.c.birthday > "2008-2-2")
from db_init import students, engine # 从 db_init 模块导入学生表格对象和数据库引擎对象
# 使用连接对象执行查询操作
with engine.connect() as conn:
# 准备查询语句,筛选出生日在 "2008-2-2" 之后的记录
query = students.select().where(students.c.birthday > "2008-2-2")
# 执行查询操作
result_set = conn.execute(query)
# 打印查询结果
print(result_set.fetchall())
# [(2, 'Jack', datetime.date(2018, 8, 18)), (3, 'Mary', datetime.date(2019, 9, 19))] # 查询结果
可用通过 . 多次查询
from db_init import students, engine # 导入学生表和数据库引擎对象
# 使用连接对象执行查询操作
with engine.connect() as conn:
# 准备查询语句,筛选出生日在 "2008-2-2" 之后且 id 大于 2 的记录
query = students.select().where(students.c.birthday > "2008-2-2").where(students.c.id > 2)
# 执行查询操作
result_set = conn.execute(query)
# 打印查询结果
print(result_set.fetchall()) # 打印查询结果集的所有行
# [(3, 'Mary', datetime.date(2019, 9, 19))] # 查询结果
C
在 SQLAlchemy 中,c 是 Column 对象的一个属性,表示对表格中的列的引用。在 students.c 中,students 是你在 db_init 模块中定义的表格对象,它是 Table 类的一个实例。而 c 则是 ColumnCollection 对象,它包含了表格中所有列的引用。因此,students.c 可以理解为对 students 表格中所有列的引用,你可以通过它来引用表格中的各个列。
例如,在下面的查询语句中:
query = students.select().where(students.c.birthday > "2008-2-2").where(students.c.id > 2)
students.c.birthday 引用了 students 表格中名为 birthday 的列,而 students.c.id 引用了 students 表格中名为 id 的列。这样做的好处是可以在查询中使用列名,而不需要硬编码列的索引或者名字。
and_和or_
在 SQLAlchemy 中,and_ 和 or_ 是用于构建复杂查询条件的函数,它们通常与 where 方法一起使用。
-
and_函数:and_函数用于连接多个查询条件,并且所有的条件都必须为真才能满足整个查询条件。- 它接受任意数量的参数,每个参数都是一个查询条件。
- 例如,
and_(condition1, condition2, ...)表示所有的条件必须都为真。
-
or_函数:or_函数用于连接多个查询条件,只要其中任何一个条件为真就能满足整个查询条件。- 它同样接受任意数量的参数,每个参数都是一个查询条件。
- 例如,
or_(condition1, condition2, ...)表示只要有一个条件为真即可。
这两个函数通常用于构建复杂的查询逻辑,例如同时满足某个条件 A 并且满足条件 B,或者满足条件 C 或者满足条件 D 等等。通过组合 and_ 和 or_ 函数,可以构建出非常灵活和复杂的查询条件。
from db_init import engine, students # 从 db_init 模块导入数据库引擎对象和学生表格对象
from sqlalchemy import and_, or_ # 导入 SQLAlchemy 中的 and_ 和 or_ 函数
# 使用连接对象执行查询操作
with engine.connect() as conn:
# 准备查询语句,筛选出名字为 'Amigo' 或者 id 大于 1 且生日在 "2006-2-2" 之后的记录
query = students.select().where(
or_(
students.c.name == 'Amigo',
and_(
students.c.id > 1,
students.c.birthday > "2006-2-2"
)
)
)
# 执行查询操作
result_set = conn.execute(query)
# 打印查询结果
print(result_set.fetchall())
# [(1, 'Amigo', datetime.date(2002, 2, 22)), (2, 'Jack', datetime.date(2018, 8, 18)), (3, 'Mary', datetime.date(2019, 9, 19))] # 查询结果
更新记录
-- SQL语句
update students set name="Bob" where id=1;
# 函数表达式
# 1.
students.update().where(students.c.id == 1).values(name="Tom")
# 2.
update(students).where(students.c.id == 1).values(name="Tom")
from db_init import students, engine
with engine.connect() as conn:
# 更新这一列的全部
# update_query = students.update().values(sex="女")
# 更新指定的记录
# update_query = students.update().values(name="小满").where(students.c.id == 1)
# 更新名为 "Tom" 的学生的性别为 "男"
update_query = students.update().values(sex="男").where(students.c.name == "Tom")
# 执行更新查询
conn.execute(update_query)
# 提交事务
conn.commit()
根据条件删除记录以及删除全部记录
删除全部记录
-- SQL语句
delete from students;
query = students.delete()
from db_init import students, engine
# 使用数据库引擎建立连接
with engine.connect() as conn:
# 删除全部记录
del_query = students.delete()
# 执行删除查询
conn.execute(del_query)
# 提交事务
conn.commit()
根据条件删除记录
-- SQL语句
delete from students where id == 3;
# 函数表达式
query = students.query.delete().where(students.c.id == 3)
from db_init import students, engine
# 使用数据库引擎建立连接
with engine.connect() as conn:
# 构建删除查询,删除ID为3的学生记录
del_query = students.delete().where(students.c.id == 3)
# 执行删除查询
conn.execute(del_query)
# 提交事务
conn.commit()
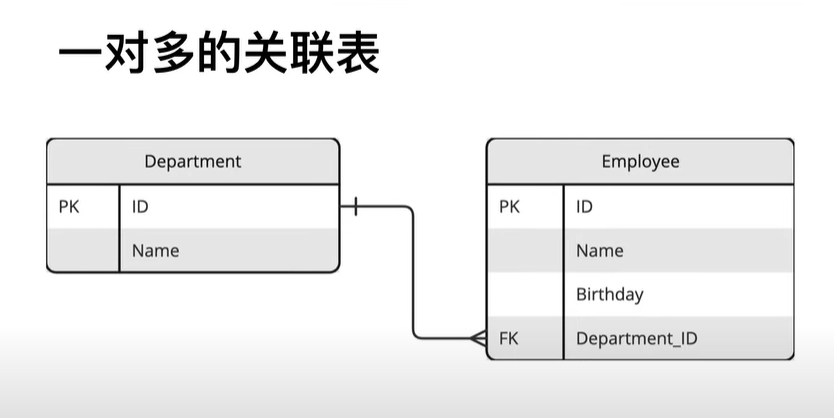
表关联
一对多
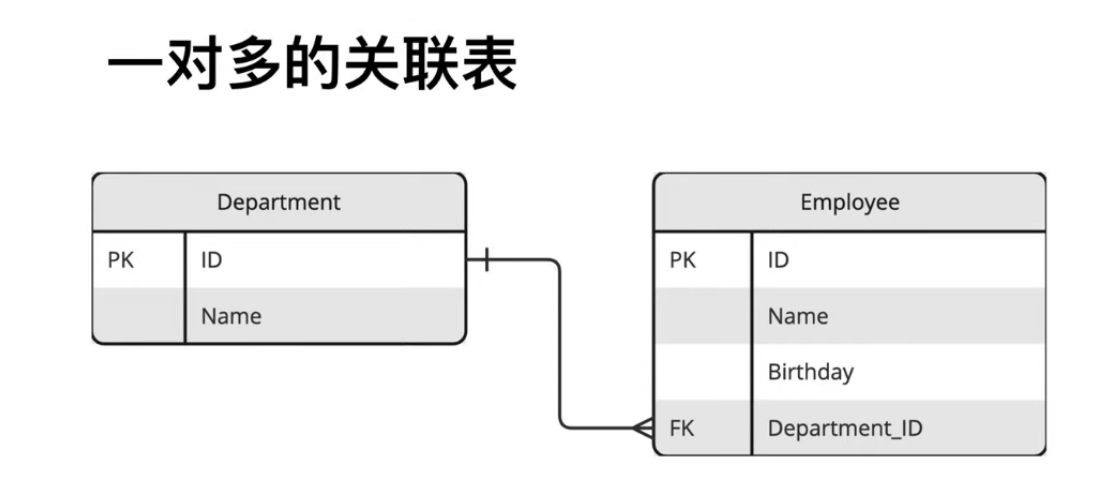
# 创建表 common.py
import sqlalchemy
# 创建 MySQL 数据库引擎
engine = sqlalchemy.create_engine("mysql://root:243204@localhost/db_sqlal", echo=True)
# 创建一个元数据对象
meta_data = sqlalchemy.MetaData()
# 定义部门表
department_table = sqlalchemy.Table(
'department', meta_data,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True), # 部门ID,主键
sqlalchemy.Column('name', sqlalchemy.String(128), unique=True) # 部门名称,唯一
)
# 定义员工表
employee_table = sqlalchemy.Table(
'employee', meta_data,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True), # 员工ID,主键
sqlalchemy.Column("name", sqlalchemy.String(64), nullable=False), # 员工姓名,不允许为空
sqlalchemy.Column("birthday", sqlalchemy.Date, nullable=False), # 员工生日,不允许为空
sqlalchemy.Column("department_id", sqlalchemy.Integer, sqlalchemy.ForeignKey("department.id"), nullable=False) # 部门ID,外键关联到部门表
)
# 创建所有在元数据中定义的表
meta_data.create_all(engine)
# 写入数据
from common import engine, department_table, employee_table
# 使用数据库引擎建立连接
with engine.connect() as conn:
# 向部门表插入初始数据
conn.execute(department_table.insert(), [
{"name": "hr", "id": 1}, # 插入部门 hr,设置其 ID 为 1
{"name": "it", "id": 2} # 插入部门 it,设置其 ID 为 2
])
# 向员工表插入初始数据
conn.execute(employee_table.insert(), [
{"name": "小满", "department_id": 1, "birthday": "2001-4-1"}, # 插入员工小满,所属部门为 hr
{"name": "小乔", "department_id": 2, "birthday": "2002-4-1"}, # 插入员工小乔,所属部门为 it
{"name": "大乔", "department_id": 2, "birthday": "2003-4-1"}, # 插入员工大乔,所属部门为 it
{"name": "阿珂", "department_id": 1, "birthday": "2004-4-1"}, # 插入员工阿珂,所属部门为 hr
{"name": "海月", "department_id": 1, "birthday": "2005-4-1"}, # 插入员工海月,所属部门为 hr
{"name": "貂蝉", "department_id": 2, "birthday": "2006-4-1"}, # 插入员工貂蝉,所属部门为 it
])
# 提交事务
conn.commit()
表关联查询
在SQL中,JOIN操作用于将两个或多个表中的行连接在一起,以便我们可以一起检索相关数据。JOIN操作的基本语法是通过指定两个表之间的连接条件来连接它们。JOIN操作的顺序非常重要,因为它决定了连接的方式以及结果集的内容。
在JOIN操作中,通常有几种常见的JOIN类型,包括:
-
INNER JOIN(内连接):INNER JOIN返回两个表中匹配行的交集。它只返回满足连接条件的行,即两个表中的行必须在连接列上具有匹配的值。
-
LEFT JOIN(左连接):LEFT JOIN返回左表中的所有行,以及右表中匹配行的数据(如果有)。如果右表中没有匹配的行,则在结果中使用NULL填充。
-
RIGHT JOIN(右连接):RIGHT JOIN与LEFT JOIN相反,它返回右表中的所有行,以及左表中匹配行的数据(如果有)。如果左表中没有匹配的行,则在结果中使用NULL填充。
-
FULL JOIN(全连接):FULL JOIN返回两个表中的所有行,无论是否存在匹配。如果没有匹配的行,则使用NULL填充。
连接的顺序是指在JOIN操作中指定表的顺序。通常情况下,首先指定要连接的主表,然后指定要连接的外部表,并且连接条件是基于主表和外部表之间的关系。
例如,在使用INNER JOIN时,连接的顺序会影响结果集的大小和内容。如果A表是主表,B表是外部表,那么A INNER JOIN B与B INNER JOIN A的结果可能是不同的,因为它们指定了不同的连接条件。
总之,连接的顺序取决于所使用的JOIN类型以及数据关系的逻辑。通常,将主表放在JOIN操作的前面,然后是外部表,这样可以更容易地理解连接的逻辑,并确保获得所需的结果。
查询hr部门的所有员工及部门信息
-- 原生SQL语句
mysql> select * from employee inner join department on employee.department_id=department.id where department.name="hr";
+----+--------+------------+---------------+----+------+
| id | name | birthday | department_id | id | name |
+----+--------+------------+---------------+----+------+
| 7 | 小满 | 2001-04-01 | 1 | 1 | hr |
| 10 | 阿珂 | 2004-04-01 | 1 | 1 | hr |
| 11 | 海月 | 2005-04-01 | 1 | 1 | hr |
+----+--------+------------+---------------+----+------+
3 rows in set (0.00 sec)
# 函数写法 简单演示
join = employee_table.join(department_table, department_table.c.id == employee_table.c.department_id)
query = sqlalchemy.select(join).where(department_table.c.name == "hr")
result_set = conn.execute(query)
import sqlalchemy
from common import engine, department_table, employee_table
# 使用数据库引擎建立连接
with engine.connect() as conn:
# join的第一个参数:你要链接谁
# join的第二个参数:关联关系
# 创建一个 JOIN 条件,连接员工表和部门表,条件是员工表中的部门ID等于部门表的ID
join = employee_table.join(department_table, department_table.c.id == employee_table.c.department_id)
# 通过sqlalchemy.select()去查询,查询谁,查询join,这里的join想象成两张表构成的一张大表就行了
# 查询的条件是什么,部门的名字是"hr"
# 创建查询语句,从 JOIN 后的结果中选择所有数据,限定部门名称为 "hr"
query = sqlalchemy.select(join).where(department_table.c.name == "hr")
# 执行查询
result_set = conn.execute(query)
# 打印查询结果
print(result_set.fetchall())
"""
[(7, '小满', datetime.date(2001, 4, 1), 1, 1, 'hr'), (10, '阿珂', datetime.date(2004, 4, 1), 1, 1, 'hr'), (11, '海月', datetime.date(2005, 4, 1), 1, 1, 'hr')]
"""
方式2:因为已经知道属于hr部门了,所以我们的查询结果就不要带上部门了
-- 原生SQL语句
mysql> SELECT employee.id, employee.name, employee.birthday, employee.department_id
-> FROM employee INNER JOIN department ON department.id = employee.department_id
-> WHERE department.name="hr";
+----+--------+------------+---------------+
| id | name | birthday | department_id |
+----+--------+------------+---------------+
| 7 | 小满 | 2001-04-01 | 1 |
| 10 | 阿珂 | 2004-04-01 | 1 |
| 11 | 海月 | 2005-04-01 | 1 |
+----+--------+------------+---------------+
3 rows in set (0.00 sec)
# 函数写法 简单演示
join = employee_table.join(department_table, department_table.c.id == employee_table.c.department_id)
query = sqlalchemy.select(employee_table).select_from(join).where(department_table.c.name=="hr")
result_set = conn.execute(query)
import sqlalchemy
from common import engine, department_table, employee_table
# 使用数据库引擎建立连接
with engine.connect() as conn:
# 创建一个 JOIN 条件,连接员工表和部门表,条件是员工表中的部门ID等于部门表的ID
join = employee_table.join(department_table, department_table.c.id == employee_table.c.department_id)
# 创建查询语句,从 JOIN 后的结果中选择所有数据,限定部门名称为 "hr"
# 这里使用了 select_from() 方法,指定查询的源表为 join
query = sqlalchemy.select(employee_table).select_from(join).where(department_table.c.name=="hr")
# 执行查询
result_set = conn.execute(query)
# 打印查询结果
print(result_set.fetchall())
"""
[(7, '小满', datetime.date(2001, 4, 1), 1), (10, '阿珂', datetime.date(2004, 4, 1), 1), (11, '海月', datetime.date(2005, 4, 1), 1)]
"""
查询员工小满所在的部门信息
-- 原生SQL语句
mysql> select department.id, department.name from department inner join employee on employee.department_id=department.id
where employee.name="小满";
+----+------+
| id | name |
+----+------+
| 1 | hr |
+----+------+
1 row in set (0.00 sec)
# 函数写法 简单演示
join = employee_table.join(department_table, department_table.c.id == employee_table.c.department_id)
query = sqlalchemy.select(department_table).select_from(join).where(employee_table.c.name == "小满")
result_set = conn.execute(query)
import sqlalchemy
from common import engine, department_table, employee_table
# 使用数据库引擎建立连接
with engine.connect() as conn:
# 创建一个 JOIN 条件,连接员工表和部门表,条件是员工表中的部门ID等于部门表的ID
join = employee_table.join(department_table, department_table.c.id == employee_table.c.department_id)
# 创建查询语句,从 JOIN 后的结果中选择所有数据,限定员工名为 "小满"
query = sqlalchemy.select(department_table).select_from(join).where(employee_table.c.name == "小满")
# 执行查询
result_set = conn.execute(query)
# 打印查询结果
print(result_set.fetchall()) # 返回结果
# [(1, 'hr')]
映射类定义与添加记录
映射类的基础declarative_base
这个类是用来定义映射类的基类
from sqlalchemy.ext.declarative import declarative_base
Base = declartive_base()
定义映射类
import sqlalchemy
from sqlalchemy.ext.declarative import declarative_base
# 创建 MySQL 数据库引擎,echo=True表示输出 SQL 语句到控制台
engine = sqlalchemy.create_engine("mysql://root:243204@localhost/db_sqlal", echo=True)
# 创建基础模型类
Base = declarative_base()
# 定义 Person 模型
class Person(Base):
__tablename__ = "person"
id = sqlalchemy.Column(sqlalchemy.Integer, primary_key=True)
name = sqlalchemy.Column(sqlalchemy.String(128), unique=True, nullable=False)
birthday = sqlalchemy.Column(sqlalchemy.Date, nullable=False)
address = sqlalchemy.Column(sqlalchemy.String(255), nullable=True)
# 创建所有表结构
Base.metadata.create_all(engine)
"""
建表语句:
CREATE TABLE person (
id INTEGER NOT NULL AUTO_INCREMENT,
name VARCHAR(128) NOT NULL,
birthday DATE NOT NULL,
address VARCHAR(255),
PRIMARY KEY (id),
UNIQUE (name)
)
"""
基于映射类添加基类
别忘记commit()
使用session代替connection
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
添加单条记录
session = Session()
p = Person(name="小满", birthday="2002-2-22", address="召唤师峡谷")
session.add(p)
# db_init.py
import sqlalchemy
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建 MySQL 数据库引擎,echo=True表示输出 SQL 语句到控制台
engine = sqlalchemy.create_engine("mysql://root:243204@localhost/db_sqlal", echo=True)
# 创建基础模型类
Base = declarative_base()
# 定义 Person 模型
class Person(Base):
__tablename__ = "person"
id = sqlalchemy.Column(sqlalchemy.Integer, primary_key=True)
name = sqlalchemy.Column(sqlalchemy.String(128), unique=True, nullable=False)
birthday = sqlalchemy.Column(sqlalchemy.Date, nullable=False)
address = sqlalchemy.Column(sqlalchemy.String(255), nullable=True)
# 创建所有表结构
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
# query.py
# 从 db_init 模块中导入 Person 模型和 Session 对象
from db_init import Person, Session
# 创建数据库会话
session = Session()
# 创建一个 Person 实例并添加到会话中
p = Person(name="小满", birthday="2020-2-22", address="召唤师峡谷")
session.add(p)
# 提交会话以将数据写入数据库
session.commit()
添加多条记录
- 创建一个列表,把数据都写入到列表里面
- 通过session.add_all(列表)添加即可
session = Session()
data_list = [
Person(name="海月", birthday="2004-2-22", address="召唤师峡谷"),
Person(name="大乔", birthday="2006-2-22", address="召唤师峡谷"),
Person(name="阿珂", birthday="2002-2-22", address="召唤师峡谷"),
]
session.add__all(data_list)
from db_init import Person, Session
# 创建数据库会话
session = Session()
# 创建一个包含多个 Person 实例的列表
data_list = [
Person(name="海月", birthday="2004-2-22", address="召唤师峡谷"),
Person(name="大乔", birthday="2006-2-22", address="召唤师峡谷"),
Person(name="阿珂", birthday="2002-2-22", address="召唤师峡谷")
]
# 将数据列表添加到会话中
session.add_all(data_list)
# 提交会话以将数据写入数据库
session.commit()
映射类查询记录
原始表
mysql> select * from person;
+----+--------+------------+-----------------+
| id | name | birthday | address |
+----+--------+------------+-----------------+
| 1 | 小满 | 2020-02-22 | 召唤师峡谷 |
| 2 | 海月 | 2004-02-22 | 召唤师峡谷 |
| 3 | 大乔 | 2006-02-22 | 召唤师峡谷 |
| 4 | 阿珂 | 2002-02-22 | 召唤师峡谷 |
+----+--------+------------+-----------------+
4 rows in set (0.01 sec)
查询所有的记录
result = session.query(Person).all()
条件查询
result = session.query(Persion).filter(Persion.name="小满")
案例演示
from db_init import Session, Person
from sqlalchemy import and_
session = Session()
# 要查询哪些Person, 要查询所有的Person
result = session.query(Person).all()
print(result) # [<db_init.Person object at 0x000002311F5AEF20>, ..., <db_init.Person object at 0x000002311F5AEE60>]
for line in result:
print(f"name: {line.name} birthday: {line.birthday}")
"""
name: 小满 birthday: 2020-02-22
name: 海月 birthday: 2004-02-22
name: 大乔 birthday: 2006-02-22
name: 阿珂 birthday: 2002-02-22
"""
# 要查询哪些Person, 要查询姓名等于小满的Person
result = session.query(Person).filter(Person.name == '小满')
print('result', type(result)) # result <class 'sqlalchemy.orm.query.Query'>
for line in result:
print(f"name: {line.name} birthday: {line.birthday}")
# name: 小满 birthday: 2020-02-22
result = session.query(Person).filter(
# 要查询哪些Person, 要查询地址等于召唤师峡谷 并且 birthday 小于 2006-1-4的Person
and_(
Person.address == '召唤师峡谷',
Person.birthday < '2006-1-4'
)
)
for line in result:
print(f"name: {line.name} birthday: {line.birthday}")
"""
name: 海月 birthday: 2004-02-22
name: 阿珂 birthday: 2002-02-22
"""
映射类单条记录的查询的返回
原始表
mysql> select * from person;
+----+--------+------------+-----------------+
| id | name | birthday | address |
+----+--------+------------+-----------------+
| 1 | 小满 | 2020-02-22 | 召唤师峡谷 |
| 2 | 海月 | 2004-02-22 | 召唤师峡谷 |
| 3 | 大乔 | 2006-02-22 | 召唤师峡谷 |
| 4 | 阿珂 | 2002-02-22 | 召唤师峡谷 |
+----+--------+------------+-----------------+
4 rows in set (0.01 sec)
使用first() 推荐[√]
- 多条或1条只取一条
- 查询不到不报错 返回None
result = session.filter(Persion < 3).first()
有且只有一条 使用one
查询的结果必须有且只有一条记录才不会报错
- 没有结果会报错
- 多条记录也会报错
result = session.filter(Person.id == 3).one()
使用scalar()
- 如果没有查询到即可会返回None
- 如果只查询到一个记录,会直接得到结果
- 如果查询到多条结果会报错
result = session.filter(Person.id == 3).scalar()
案例演示
from db_init import Person, Session
from sqlalchemy import and_
session = Session()
# 使用first()查询,直接拿到的就是一个结果,如果结果不存在不会报错,而是返回一个None 结果可以直接 . 去获取属性
result = session.query(Person).filter(Person.address == '召唤师峡谷').first()
print(f'name: {result.name} birthday: {result.birthday}')
# name: 小满 birthday: 2020-02-22
# 使用first()查询,查询不到任何结果返回None 可以进一步处理
result = session.query(Person).filter(Person.address == '泉水').first()
if result:
print(f'name: {result.name} birthday: {result.birthday}')
else:
print('没有获取到任何结果')
# 没有获取到任何结果
# 如果使用one() 去查询 拿不到结果会直接报错
# result = session.query(Person).filter(Person.address == '泉水').one()
# print(result) # sqlalchemy.exc.NoResultFound: No row was found when one was required
# 使用one() 去查询 如果查询到的结果不唯一 也会报错
# result = session.query(Person).filter(Person.address == '召唤师峡谷').one()
# print(f'name: {result.name} birthday: {result.birthday}')
# sqlalchemy.exc.MultipleResultsFound: Multiple rows were found when exactly one was required
# 正确查询到唯一的结果 就不会报错
result = session.query(Person).filter(Person.name == '小满').one()
print(f'name: {result.name} birthday: {result.birthday}')
# name: 小满 birthday: 2020-02-22
# 使用scalar() 获取到多条结果 直接报错
# result = session.query(Person).filter(Person.address == '召唤师峡谷').scalar()
# print(result)
# sqlalchemy.exc.MultipleResultsFound: Multiple rows were found when exactly one was required
# 使用scalar() 获取不到任何结果 得到一个None
result = session.query(Person).filter(Person.address == '泉水').scalar()
print(result)
# 如果只查询到一个结果 正常获取到数据
result = session.query(Person).filter(Person.id == '3').scalar()
print(f'name: {result.name} birthday: {result.birthday}')
# name: 大乔 birthday: 2006-02-22
映射类单条记录的修改
- 如果通过方式1这种去操作,需要赋值
- 如果通过update去更新,可以不需要赋值
- 不论哪一种方法,都需要提交事务使其生效 commit()
原始表
mysql> select * from person;
+----+--------+------------+-----------------+
| id | name | birthday | address |
+----+--------+------------+-----------------+
| 1 | 小满 | 2020-02-22 | 召唤师峡谷 |
| 2 | 海月 | 2004-02-22 | 召唤师峡谷 |
| 3 | 大乔 | 2006-02-22 | 召唤师峡谷 |
| 4 | 阿珂 | 2002-02-22 | 召唤师峡谷 |
+----+--------+------------+-----------------+
4 rows in set (0.01 sec)
方式1
# 查询 id 为 1 的 Person 对象
person = session.query(Person).filter(Person.id == 1).one()
# 修改该 Person 对象的地址为 '泉水'
person.address = '泉水'
# 提交会话以保存修改
session.commit()
方式2
# 使用 update 方法直接更新 id 为 1 的 Person 对象的地址为 '泉水'
session.query(Person).filter(Person.id == 1).update({Person.address: '泉水'})
# 提交会话以保存更新
session.commit()
方式3
# 更新所有 id 大于 1 的 Person 对象的地址为 '泉水'
session.query(Person).filter(Person.id > 1).update({Person.address: '泉水'})
# 提交会话以保存更新
session.commit()
案例演示
# 导入会话和 Person 模型
from db_init import Session, Person
# 创建会话对象
# 创建事务
session = Session()
# 查询并更新 id 为 1 的 Person 对象的地址为 '泉水'
person = session.query(Person).filter(Person.id == 1).one()
person.address = "泉水"
# 记得提交事务,不然不生效
session.commit()
# 更新名为 '大乔' 的 Person 对象的姓名为 '小乔'
# 注意:update() 方法返回受影响的行数而不是更新后的对象
rows_affected = session.query(Person).filter(Person.name == '大乔').update({Person.name: '小乔'})
# 记得提交事务,不然不生效
session.commit()
# 更新所有 id 大于 1 的 Person 对象的地址为 '泉水'
# 如果只是单纯的通过update()去更新,那么可以不用写返回值
session.query(Person).filter(Person.id > 1).update({Person.address: '泉水'})
# 记得提交事务,不然不生效
session.commit()
使用新的映射方式 Mapped
使用Mapped来映射字段
class Customers(Base):
__tablename__ = "customers"
id: Mapped[int] = mapped_column(primary_key=True) # 客户ID,主键
name: Mapped[str] = mapped_column(String(128), unique=True, nullable=False) # 客户姓名,唯一且非空
birthday = Mapped[datetime.datetime] # 客户生日
案例演示
# db_init_mapped.py
import datetime
import sqlalchemy
from sqlalchemy.orm import Mapped, mapped_column, sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建数据库引擎
engine = sqlalchemy.create_engine('mysql://root:123456@localhost/db_sqlal?charset=utf8', echo=True)
Base = declarative_base() # 声明基类
class Customers(Base):
__tablename__ = 'customers' # 表名
# 定义列
id: Mapped[int] = mapped_column(primary_key=True) # 主键
name: Mapped[str] = mapped_column(sqlalchemy.String(128), unique=True, nullable=False) # 唯一且非空的字符串
birthday: Mapped[datetime.datetime] # 日期时间类型
# 创建表结构
Base.metadata.create_all(engine)
# 创建会话工厂
Session = sessionmaker(bind=engine)
# query.py
from db_init_mapped import Customers, Session # 导入映射类和会话工厂
session = Session() # 创建会话
# 创建 Customers 实例,注意生日字符串需要转换为 datetime 类型
c = Customers(name='amigo', birthday='2022-2-2')
session.add(c) # 将实例添加到会话中
session.commit() # 提交事务,将更改保存到数据库中
太多重复字段要定义 使用Annotated()
# db_init_mapped.py
import datetime
import sqlalchemy
from sqlalchemy.sql import func
from typing_extensions import Annotated
from sqlalchemy.orm import Mapped, mapped_column, sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建数据库引擎
engine = sqlalchemy.create_engine('mysql://root:123456@localhost/db_sqlal?charset=utf8', echo=True)
Base = declarative_base() # 声明基类
# 定义 Annotated 类型以及对应的列属性
int_pk = Annotated[int, mapped_column(primary_key=True, autoincrement=True)] # 整数主键,自增
required_unique_name = Annotated[str, mapped_column(sqlalchemy.String(128), unique=True, nullable=False)] # 非空唯一名称
# server_defalut 相当于sql语句中的default func.now() 就相当于sql里面的now()函数
timestamp_default_now = Annotated[
datetime.datetime, mapped_column(nullable=False, server_default=func.now())] # 默认当前时间戳
class Customers(Base):
__tablename__ = 'customers' # 表名
# 定义列
id: Mapped[int_pk] # 主键列
name: Mapped[required_unique_name] # 姓名列
birthday: Mapped[datetime.datetime] # 生日列
create_time: Mapped[timestamp_default_now] # 创建时间列,默认为当前时间
# 创建表结构
Base.metadata.create_all(engine) # 创建表结构
# 创建会话工厂
Session = sessionmaker(bind=engine) # 创建会话工厂
# query.py
from db_init_mapped import Customers, Session # 导入映射类 Customers 和会话工厂 Session
session = Session() # 创建数据库会话
# 创建一个新的 Customers 实例,表示一个新的客户
c = Customers(name='Fox', birthday='2009-2-12')
session.add(c) # 将新客户实例添加到会话中
session.commit() # 提交会话,将更改保存到数据库中
orm操作之一对多
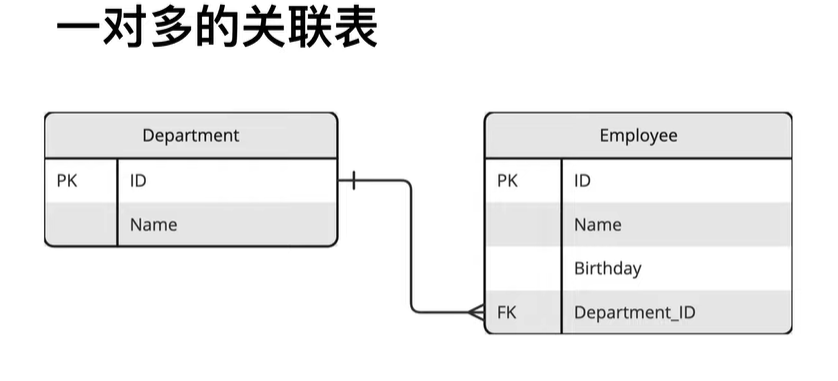
待优化
原因:每一次都要fulsh()
import datetime
import sqlalchemy
from sqlalchemy.sql import func
from typing_extensions import Annotated
from sqlalchemy.orm import Mapped, mapped_column, sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# 创建数据库引擎
engine = sqlalchemy.create_engine('mysql://root:123456@localhost/db_sqlal?charset=utf8', echo=True)
Base = declarative_base() # 声明基类
# 定义 Annotated 类型以及对应的列属性
int_pk = Annotated[int, mapped_column(primary_key=True, autoincrement=True)] # 整数主键,自增
required_unique_name = Annotated[str, mapped_column(sqlalchemy.String(128), unique=True, nullable=False)] # 非空唯一名称
timestamp_default_now = Annotated[
datetime.datetime, mapped_column(nullable=False, server_default=func.now())] # 默认当前时间戳
class Department(Base):
__tablename__ = 'department'
id: Mapped[int_pk] # 主键列
name: Mapped[required_unique_name] # 部门名称列
def __repr__(self):
return f"id: {self.id}, name: {self.name}"
class Employee(Base):
__tablename__ = "employee"
id: Mapped[int_pk] # 主键列
name: Mapped[required_unique_name] # 员工姓名列
birthday: Mapped[timestamp_default_now] # 生日列
dep_id: Mapped[int] = mapped_column(sqlalchemy.ForeignKey("department.id")) # 外键关联部门表的主键
def __repr__(self):
return f"id: {self.id}, dep_id: {self.dep_id}, name: {self.name}, birthday: {self.birthday}"
# 创建表结构
Base.metadata.create_all(engine) # 创建表结构
# 创建会话工厂
Session = sessionmaker(bind=engine) # 创建会话工厂
from db_init import Session, Department, Employee # 导入会话、部门和雇员类
def insert_records(session):
# 创建一个新部门实例并添加到会话中
d1 = Department(name="hr")
session.add(d1)
# 强制刷新以确保主键值已经生成
session.flush()
# 创建一个新雇员实例,将部门的 id 分配给 dep_id 属性,并添加到会话中
e1 = Employee(dep_id=d1.id, name="Amigo", birthday="2012-2-12")
session.add(e1)
# 提交会话,保存更改到数据库中
session.commit()
session = Session()
insert_records(session) # 调用插入记录的函数,并传入会话对象
优化后
- 导入relationship
- 类似这样department: Mapped[Department] = relationship()
- 插入的时候不需要指定外键了,e1 = Employee(department=d1, name="Claier", birthday="2007-2-12")
# db_init.py
import datetime
import sqlalchemy
from sqlalchemy.sql import func
from typing_extensions import Annotated
from sqlalchemy.orm import Mapped, mapped_column, sessionmaker, relationship
from sqlalchemy.ext.declarative import declarative_base
# 创建数据库引擎
engine = sqlalchemy.create_engine('mysql://root:123456@localhost/db_sqlal?charset=utf8', echo=True)
Base = declarative_base() # 声明基类
# 定义 Annotated 类型以及对应的列属性
int_pk = Annotated[int, mapped_column(primary_key=True, autoincrement=True)] # 整数主键,自增
required_unique_name = Annotated[str, mapped_column(sqlalchemy.String(128), unique=True, nullable=False)] # 非空唯一名称
timestamp_default_now = Annotated[
datetime.datetime, mapped_column(nullable=False, server_default=func.now())] # 默认当前时间戳
class Department(Base):
__tablename__ = 'department'
id: Mapped[int_pk] # 主键列
name: Mapped[required_unique_name] # 部门名称列
def __repr__(self):
return f"id: {self.id}, name: {self.name}"
class Employee(Base):
__tablename__ = "employee"
id: Mapped[int_pk] # 主键列
name: Mapped[required_unique_name] # 员工姓名列
birthday: Mapped[timestamp_default_now] # 生日列
dep_id: Mapped[int] = mapped_column(sqlalchemy.ForeignKey("department.id")) # 外键关联部门表的主键
# 这是一个关系字段,不是一个真正的数据库字段
department: Mapped[Department] = relationship()
def __repr__(self):
return f"id: {self.id}, dep_id: {self.dep_id}, name: {self.name}, birthday: {self.birthday}"
# 创建表结构
Base.metadata.create_all(engine)
# 创建会话工厂
Session = sessionmaker(bind=engine)
from db_init import Session, Department, Employee # 导入会话、部门和雇员类
def insert_records(session):
# 创建一个新的部门实例
d1 = Department(name="hr")
# 创建一个新的雇员实例,分配到部门 d1,并设置雇员的姓名和生日
e1 = Employee(department=d1, name="Claier", birthday="2007-2-12")
# 将新创建的雇员实例添加到会话中
session.add(e1)
# 提交会话,将更改保存到数据库中
session.commit()
session = Session()
insert_records(session) # 调用插入记录的函数,并传入会话对象
懒惰查询 lazy 默认是懒惰查询
db_init.py的代码不变
from db_init import Session, Department, Employee # 导入会话、部门和雇员类
def select_employee(session):
emp = session.query(Employee).filter(Employee.name == "Claier").one()
print(emp)
print(emp.department)
# 打印结果
# 再查询一次
# 再打印结果
select_employee(session)
优化懒惰查询 lazy=False
lazy=False: 这表示在访问department属性时,相关的部门对象会立即从数据库加载,而不是在需要时再加载。这是因为lazy=False表示采用了“立即加载”模式,它会在访问属性时立即执行查询,将相关的对象加载到内存中。
# db_init.py
# 这是一个关系字段,不是一个真正的数据库字段
# 添加lazy=False, 其他不变
department: Mapped[Department] = relationship(lazy=False)
# query.py
from db_init import Session, Department, Employee # 导入会话、部门和雇员类
def select_employee(session):
emp = session.query(Employee).filter(Employee.name == "Claier").one()
print(emp)
print(emp.department)
# 打印结果
# 再次打印结果
# 不会多次查询,会优化速度
select_employee(session)
反向查询 backref
backref="employee": 这是一个反向引用,它允许我们从Department对象访问与之相关联的Employee对象。具体来说,backref="employee"定义了在Department类中一个名为employee的属性,通过这个属性我们可以访问到与该部门相关的所有员工对象。
# db_init.py
# 修改的地方,新增了backref="employee"其他地方不变
department: Mapped[Department] = relationship(lazy=False, backref="employee")
# 导入会话、部门和雇员类
from db_init import Session, Department, Employee
def select_department(session):
# 查询 id 为 1 的部门
department = session.query(Department).filter(Department.id==1).first()
# 打印部门信息
print(department)
# 打印该部门下的所有员工
print(department.employee)
# 创建会话对象
session = Session()
# 调用查询部门的函数
select_department(session)
反向查询 back_populates [了解即可]
back_populates 是 SQLAlchemy 中用于定义双向关系的一个参数。它允许您在两个相关的数据模型类之间建立双向关联,使得在一个类中可以方便地访问到与之关联的另一个类的对象。
具体来说,假设有两个数据模型类 A 和 B,它们之间存在一对多的关系,即一个 A 对象可以关联多个 B 对象。使用 back_populates 参数,您可以在 A 类中定义一个属性,用来表示与之关联的 B 对象,同时在 B 类中也定义一个属性,用来表示与之关联的 A 对象。这样,无论是从 A 对象还是从 B 对象出发,都可以方便地访问到对方的对象,实现了双向的关系。
以下是一个简单的示例,演示了如何在两个数据模型类之间使用 back_populates 参数建立双向关系:
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey
from sqlalchemy.orm import relationship, sessionmaker
from sqlalchemy.ext.declarative import declarative_base
engine = create_engine('sqlite:///:memory:', echo=True)
Base = declarative_base()
class A(Base):
__tablename__ = 'a'
id = Column(Integer, primary_key=True)
name = Column(String)
# 定义与 B 类的关联关系,指定 back_populates 参数为 b_list
b_list = relationship("B", back_populates="a")
class B(Base):
__tablename__ = 'b'
id = Column(Integer, primary_key=True)
name = Column(String)
a_id = Column(Integer, ForeignKey('a.id'))
# 定义与 A 类的关联关系,指定 back_populates 参数为 a
a = relationship("A", back_populates="b_list")
Base.metadata.create_all(engine)
Session = sessionmaker(bind=engine)
session = Session()
a1 = A(name='a1')
b1 = B(name='b1', a=a1)
b2 = B(name='b2', a=a1)
session.add_all([a1, b1, b2])
session.commit()
# 通过 A 对象访问与之关联的 B 对象
print(a1.b_list)
# 通过 B 对象访问与之关联的 A 对象
print(b1.a)
print(b2.a)
在这个示例中,类 A 与类 B 之间建立了双向关系。在类 A 中,属性 b_list 表示与之关联的类 B 的对象列表,在类 B 中,属性 a 表示与之关联的类 A 的对象。通过这样的定义,无论是从 A 对象还是从 B 对象出发,都可以方便地访问到对方的对象。
#db_init.py
import datetime
import sqlalchemy
from sqlalchemy.sql import func
from typing_extensions import Annotated
from typing import List
from sqlalchemy.orm import Mapped, mapped_column, sessionmaker, relationship
from sqlalchemy.ext.declarative import declarative_base
# 创建数据库引擎
engine = sqlalchemy.create_engine('mysql://root:123456@localhost/db_sqlal?charset=utf8', echo=True)
Base = declarative_base() # 声明基类
# 定义 Annotated 类型以及对应的列属性
int_pk = Annotated[int, mapped_column(primary_key=True, autoincrement=True)] # 整数主键,自增
required_unique_name = Annotated[str, mapped_column(sqlalchemy.String(128), unique=True, nullable=False)] # 非空唯一名称
timestamp_default_now = Annotated[
datetime.datetime, mapped_column(nullable=False, server_default=func.now())] # 默认当前时间戳
class Department(Base):
__tablename__ = 'department'
id: Mapped[int_pk] # 主键列
name: Mapped[required_unique_name] # 部门名称列
# 关联到 Employee 类,反向引用为 employee
employee: Mapped[List["Employee"]] = relationship(back_populates="department")
def __repr__(self):
return f"id: {self.id}, name: {self.name}"
class Employee(Base):
__tablename__ = "employee"
id: Mapped[int_pk] # 主键列
name: Mapped[required_unique_name] # 员工姓名列
birthday: Mapped[timestamp_default_now] # 生日列
dep_id: Mapped[int] = mapped_column(sqlalchemy.ForeignKey("department.id")) # 外键关联部门表的主键
# 关联到 Department 类,反向引用为 department
department: Mapped[Department] = relationship(lazy=False, back_populates="employee")
def __repr__(self):
return f"id: {self.id}, dep_id: {self.dep_id}, name: {self.name}, birthday: {self.birthday}"
# 创建表结构
Base.metadata.create_all(engine)
# 创建会话工厂
Session = sessionmaker(bind=engine) # 创建会话工厂
orm操作之多对多
- 一个用户可能有多个角色
- 一个角色也可能包含多个用户
- 第三张表
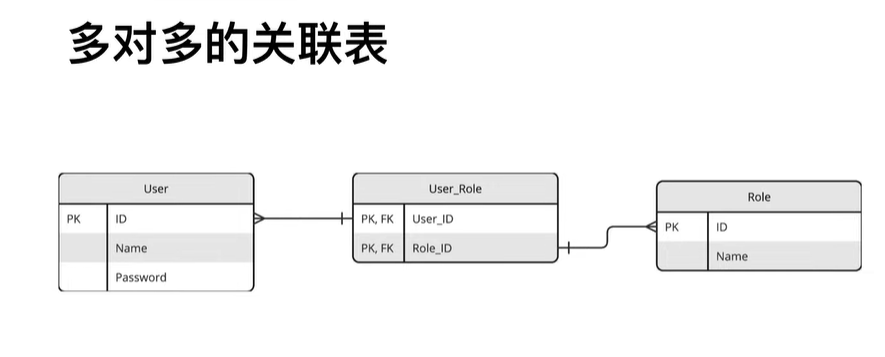
# db_init.py
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Table, create_engine, Column, ForeignKey, String
from sqlalchemy.orm import relationship, sessionmaker, Mapped, mapped_column
from typing_extensions import Annotated
from typing import List
# 创建数据库引擎
engine = create_engine("mysql://root:243204@localhost/db_sqlal?charset=utf8", echo=True)
# 声明基类
Base = declarative_base()
# 定义 Annotated 类型以及对应的列属性
int_pk = Annotated[int, mapped_column(primary_key=True, autoincrement=True)]
required_unique_name = Annotated[str, mapped_column(String(128), unique=True, nullable=False)]
required_string = Annotated[str, mapped_column(String(64), unique=False, nullable=False)]
# 定义关联表
association_table = Table(
"user_role",
Base.metadata,
Column("user_id", ForeignKey("users.id"), primary_key=True),
Column("role_id", ForeignKey("roles.id"), primary_key=True)
)
class Role(Base):
__tablename__ = "roles"
# 角色ID
id: Mapped[int_pk]
# 角色名称
name: Mapped[required_unique_name]
# 与用户关联的关系
# secondary 要关联到哪一张表
users: Mapped[List["User"]] = relationship("User", secondary=association_table, lazy=True, back_populates="roles")
def __repr__(self):
return f"id: {self.id}, name: {self.name}"
class User(Base):
__tablename__ = "users"
# 用户ID
id: Mapped[int_pk]
# 用户名
name: Mapped[required_unique_name]
# 密码
password: Mapped[required_string]
# 与角色关联的关系
roles: Mapped[List[Role]] = relationship("Role", secondary=association_table, lazy=True, back_populates="users")
def __repr__(self):
return f"id: {self.id}, name: {self.name}"
# 创建表结构
Base.metadata.create_all(engine)
# 创建会话工厂
Session = sessionmaker(bind=engine)
from db_init import Role, User, Session
session = Session()
def insert_records(s):
role1 = Role(name="admin")
role2 = Role(name="Operator")
user1 = User(name="小满", password="111")
user2 = User(name="大乔", password="222")
user3 = User(name="海月", password="333")
user1.roles.append(role1)
user1.roles.append(role2)
user2.roles.append(role1)
user3.roles.append(role2)
# 因为这里已经关联到第三张表了,所以只插入用户表就可以了
s.add_all([user1, user2, user3])
s.commit()
def select_users(s):
user = session.query(User).filter(User.id==1).one()
print(user)
print(user.roles)
def select_roles(s):
r = session.query(Role).filter(Role.id==1).one()
print(r)
print(r.users)
# insert_records(session)
select_users(session) # [id: 1, name: admin, id: 2, name: Operator]
select_roles(session) # [id: 1, name: 小满, id: 2, name: 大乔]
orm操作之一对一
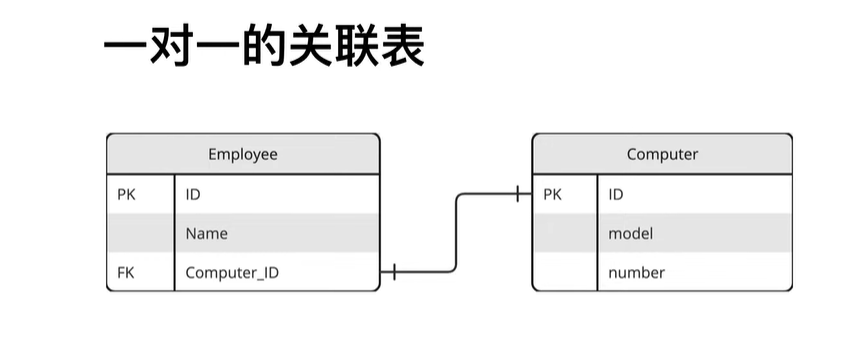
# db_init.py
from sqlalchemy import create_engine, String, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import Mapped, mapped_column, relationship, sessionmaker
from typing_extensions import Annotated
# 创建数据库引擎
engine = create_engine("mysql://root:243204@localhost/db_sqlal?charset=utf8", echo=True)
# 声明基类
Base = declarative_base()
# 定义 Annotated 类型
int_pk = Annotated[int, mapped_column(primary_key=True, autoincrement=True)]
required_unique_string = Annotated[str, mapped_column(String(128), nullable=False, unique=True)]
required_string = Annotated[str, mapped_column(String(64), nullable=False, unique=False)]
# 定义 Employee 类
class Employee(Base):
__tablename__ = "employee"
# 定义列
id: Mapped[int_pk]
name: Mapped[required_unique_string]
computer_id: Mapped[int] = mapped_column(ForeignKey("computer.id"), nullable=True)
# 定义关系,关联到 Computer 类
computer = relationship("Computer", lazy=False, back_populates="employee")
# 定义对象打印格式
def __repr__(self):
return f"id: {self.id}, name: {self.name}"
# 定义 Computer 类
class Computer(Base):
__tablename__ = "computer"
# 定义列
id: Mapped[int_pk]
model: Mapped[required_string]
number: Mapped[required_unique_string]
# 定义关系,关联到 Employee 类
employee = relationship("Employee", lazy=True, back_populates="computer")
# 定义对象打印格式
def __repr__(self):
return f"id: {self.id}, model: {self.model}, number: {self.number}"
# 创建表格
Base.metadata.create_all(engine)
# 创建会话工厂
Session = sessionmaker(bind=engine)
# query.py
from db_init import Computer, Employee, Session
def insert(s):
# 创建三个 Computer 对象
c1 = Computer(model="Dell", number="111")
c2 = Computer(model="Surface", number="222")
c3 = Computer(model="Dell", number="333")
# 创建三个 Employee 对象,并将它们与对应的 Computer 对象关联起来
e1 = Employee(name="小满", computer=c1)
e2 = Employee(name="大乔", computer=c2)
e3 = Employee(name="海月", computer=c3)
# 将创建的对象添加到会话中,并提交事务
s.add_all([e1, e2, e3])
s.commit()
def select(s):
# 查询 id 为 1 的 Employee 对象,并打印出其信息以及关联的 Computer 对象的信息
e = s.query(Employee).filter(Employee.id == 1).scalar()
if e:
print(e) # id: 1, name: 小满
print(e.computer) # id: 1, model: Dell, number: 111
# 查询 id 为 2 的 Computer 对象,并打印出其信息以及关联的 Employee 对象的信息
c = s.query(Computer).filter(Computer.id == 2).scalar()
if c:
print(c) # id: 2, model: Surface, number: 222
print(c.employee) # [id: 2, name: 大乔]
def update_1(s):
# 将 id 为 3 的 Employee 对象的 computer_id 设置为 None
s.query(Employee).filter(Employee.id == 3).update({Employee.computer_id: None})
s.commit()
def update_2(s):
# 查询 id 为 3 的 Computer 和 Employee 对象
c = s.query(Computer).filter(Computer.id == 3).scalar()
e = s.query(Employee).filter(Employee.id == 3).scalar()
# 如果都存在,则将 Employee 对象的 computer 关联更新为查询到的 Computer 对象,并提交事务
if c and e:
e.computer = c
s.commit()
session = Session()
# insert(session)
# select(session)
# update_1(session)
update_2(session)
基于orm的查询
导入必要的模块
from sqlalchemy import select, insert, update, bindparam, delete
from sqlalchemy.orm import outerjoin, aliased
查询单个类 select
# 查询所有部门
select(Department).order_by(Department.name)
from sqlalchemy import select, insert, update, bindparam, delete
from sqlalchemy.orm import outerjoin, aliased
from db_init import Department, Employee, Session
session = Session()
def execute_query(query):
result = session.execute(query)
for row in result:
print(row)
def select_single_target():
query = select(Department).order_by(Department.name)
# 执行查询的结果
execute_query(query)
select_single_target()
查询多个类 使用join 和 别名
# 使用join函数
select(Empolyee, Department).join(Employee.department)
使用别名 aliased
emp_cls = aliased(Employee, name="emp")
dep_cls = aliased(Department, name="dep")
query = select(emp_cls, dep_cls).join(emp_cls.department.of_type(dep_cls))
from sqlalchemy import select, insert, update, bindparam, delete
from sqlalchemy.orm import outerjoin, aliased
from db_init import Department, Employee, Session
session = Session()
def execute_query(query):
"""
执行查询并打印结果。
Args:
query: 要执行的查询对象
"""
result = session.execute(query)
for row in result:
print(row)
def select_with_aliased():
"""
使用别名进行查询。
"""
emp_cls = aliased(Employee, name="emp")
dep_cls = aliased(Department, name="dep")
query = select(emp_cls, dep_cls).join(emp_cls.department.of_type(dep_cls))
execute_query(query)
select_with_aliased()
查询多个类的个别字段 join_form函数
query = select(Department.name, Employee.name).join_form(Employee, Department)
from sqlalchemy import select, insert, update, bindparam, delete
from sqlalchemy.orm import outerjoin, aliased
from db_init import Department, Employee, Session
session = Session()
def execute_query(query):
result = session.execute(query)
for row in result:
print(row)
def select_fields():
# label自己起一个别名,一般不需要指定label 直接Employee.name即可
query = select(Employee.name.label("emp_name"), Department.name.label("dep_name")).join_from(Employee, Department)
execute_query(query)
select_fields()
使用outer join查询
# 使用join函数
query = select(Department, Employee).join(Employee.department, isouter=True)
# 使用outerjoin函数
query = select(Department.name).select(select_form(outerjoin(Department, Employee)))
from sqlalchemy import select, insert, update, bindparam, delete
from sqlalchemy.orm import outerjoin, aliased
from db_init import Department, Employee, Session
session = Session()
def execute_query(query):
result = session.execute(query)
for row in result:
print(row)
def select_fields_outer():
query = select(Employee.name.label("emp_name"), Department.name.label("dep_name"))\
.select_from(outerjoin(Employee, Department))
execute_query(query)
select_fields_outer()
orm查询之where条件
= 条件
dep = session.get_one(Department, 1)
query = select(Employee).where(Employee.department == dep)
def where_obj():
dep = session.get(Department, 1)
# query = select(Employee).where(Employee.department == dep)
query = select(Employee).where(Employee.dep_id == dep.id)
execute_query(query)
!= 条件
dep = session.get_one(Department, 1)
query = select(Empartment).where(Employee.department != dep)
def where_obj():
dep = session.get(Department, 1)
# query = select(Employee).where(Employee.department != dep)
query = select(Employee).where(Employee.dep_id != dep.id)
execute_query(query)
小满是哪一个部门的 contains 条件
emp = session.get_one(Employee, 1)
query = select(Department).where(Department.employees.contains(emp))
def select_contains():
emp = session.get(Employee, 1)
query = select(Department).where(Department.employee.contains(emp))
execute_query(query)
基于orm的批量增删改查
sqlalchemy自带的session
from sqlalchemy.orm import Session
with Session(engine) as session:
...
批量插入 insert
session.execute(
inert(User).values(
[
{"name": "小满", "gender": "女"},
{"name": "阿珂", "gender": "女"}
]
)
)
from sqlalchemy import select, insert, update, bindparam, delete
from sqlalchemy.orm import Session
from db_init import engine, Department, Employee
def batch_insert():
with Session(engine) as session:
session.execute(
insert(Department).values(
[
{"name": "QA"},
{"name": "Sales"}
]
)
)
session.commit()
batch_insert()
带关联的批量插入 使用嵌套select函数
session.execute(
insert(Employee).values(
[
{
"dep_id": select(Department.id).where(Department.name == "it"),
"name": "海月",
"birthday": "2000-1-1"
},
{
"dep_id": select(Department.id).where(Department.name == "hr"),
"name": "貂蝉",
"birthday": "2020-2-2"
}
]
)
)
批量更新 使用update函数
session.execute(
update(User),
[
{"id": 1, "name": "海月"},
{"id": 2, "birthday": "2009-1-1"}
]
)
批量删除 使用delate函数
session.execute(
delete(User).where(User.name.in_(['小满', "阿珂"]))
)
Session与事务控制
Session默认开启事务
使用Session类
from sqlalchemy.orm import Session
with Session(engine) as session: # 这里默认开启事务
dep = Department(name="QA")
session.add(dep)
session.commit()
# 如果产生任何异常,事务将自动执行rollback
自动提交事务
使用begin函数
with Session(engine) as session:
with session.begin():
dep = Department(name="QA")
session.add(dep)
# 这里如果没有异常会自动提交事务
# 这里会自动关闭session
with Session(engine) as session, session.begin():
dep = Department(name="QA")
session.add(dep)
# 这里如果没有异常会自动提交事务
# 这里会自动关闭session
多数据源事务处理
同时开始和提交事务
with Session(engine) as session1, session1.begin(), Session(engine2) as session2, session2.begin():
dep = Department(name="摸鱼部")
session1.add(dep)
user = User(name="小满")
session2.add(user)