链接redis
方式一:
redis-cli -h 192.168.88.129 -p 6379 -a root
方式二:
redis-cli -h 192.168.88.129 -p 6379
AUTH root
redis通用命令
help @string 查看帮助
keys * 查询所有key
MSET k v k1 v1 批量插入
exists 确定一个键是否存在
常见
| 常见命令 | 信息 |
|---|---|
| help @string | 查看帮助 |
| keys * | 查询所有key(*所有 ) |
| MSET k v k1 v1 | 批量插入 |
| exists name | 确定一个键是否存在Determine if a key exists |
| EXPIRE | 给一个值设置一个有效期 |
| TTL name | 查看key剩余有效期 |
1string
| string类型常见命令 | 信息 |
|---|---|
| set name zhangsan | 设置键值(name为键,zhangsan为值) |
| get name | 通过键获取值 |
| MSET k v k1 v1 | 批量插入 |
| MSET k1 k2 name | 批量获取 |
| INCR | 让一个整形的key自增1 |
| INCRBY | 让一个整形的key自增并指定步长 |
| INCRBYFLOAT | 让一个浮点型的数字自增并指定步长 |
| SETNX | 添加一个String类型的键值对,前提是这个key不存在,否则不执行 |
| SETEX | 添加一个String类型的键值对,并指定有效期 |
2hash
| Hash通用命令 | 信息 |
|---|---|
| HSET key field value | 添加或者修改hash类型key的field的值 |
| HGET key field | 获取一个hash类型key的field的值 |
| HMSET | 批量添加多个hash类型key的field的值 |
| HMGET | 批量获取多个hash类型key的field的值 |
| HGETALL | 获取一个hash类型的key中的所有的field和value |
| HKEYS | 获取一个hash类型的key中的所有的field |
| HINCRBY | 让一个hash类型key的字段值自增并指定步长 |
| HSETNX | 添加一个hash类型的key的field值,前提是这个field不存在,否则不执行 |
3list
| list通用命令 | 信息 |
|---|---|
| LPUSH key element ... | 向列表左侧插入一个或多个元素 |
| LPOP key | 移除并返回列表左侧的第一个元素,没有则返回nil |
| RPUSH key element ... | 向列表右侧插入一个或多个元素 |
| RPOP key | 移除并返回列表右侧的第一个元素 |
| LRANGE key star end | 返回一段角标范围内的所有元素 |
| BLPOP和BRPOP | 与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil |
4set
| set通用命令 | 信息 |
|---|---|
| SADD key member ... | 向set中添加一个或多个元素 |
| SREM key member ... | 移除set中的指定元素 |
| SCARD key | 返回set中元素的个数 |
| SISMEMBER key member | 判断一个元素是否存在于set中 |
| SMEMBERS | 获取set中的所有元素 |
| SINTER key1 key2 ... | 求key1与key2的交集 |
| SDIFF key1 key2 ... | 求key1与key2的差集 |
| SUNION key1 key2 .. | 求key1和key2的并集 |
5SortedSet
| SortedSet通用命令 | 信息 |
|---|---|
| ZADD key score member | 添加一个或多个元素到sorted set ,如果已经存在则更新其score值 |
| ZREM key member | 删除sorted set中的一个指定元素 |
| ZSCORE key member | 获取sorted set中的指定元素的score值 |
| ZRANK key member | 获取sorted set 中的指定元素的排名 |
| ZCARD key | 获取sorted set中的元素个数 |
| ZCOUNT key min max | 统计score值在给定范围内的所有元素的个数 |
| ZINCRBY key increment member | 让sorted set中的指定元素自增,步长为指定的increment值 |
| ZRANGE key min max | 按照score排序后,获取指定排名范围内的元素 |
| ZRANGEBYSCORE key min max | 按照score排序后,获取指定score范围内的元素 |
| ZDIFF.ZINTER.ZUNION | 求差集.交集.并集 |
- 升序获取sorted set 中的指定元素的排名:ZRANK key member
- 降序获取sorted set 中的指定元素的排名:ZREVRANK key memeber
stream
6stream
7.4 Redis消息队列-基于Stream的消息队列
Stream 是 Redis 5.0 引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
发送消息的命令:

例如:

读取消息的方式之一:XREAD

例如,使用XREAD读取第一个消息:
XREAD阻塞方式,读取最新的消息:

在业务开发中,我们可以循环的调用XREAD阻塞方式来查询最新消息,从而实现持续监听队列的效果,伪代码如下
注意:当我们指定起始ID为$时,代表读取最新的消息,如果我们处理一条消息的过程中,又有超过1条以上的消息到达队列,则下次获取时也只能获取到最新的一条,会出现漏读消息的问题
STREAM类型消息队列的XREAD命令特点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
7.5 Redis消息队列-基于Stream的消息队列-消费者组
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。具备下列特点:
创建消费者组:
key:队列名称
groupName:消费者组名称
ID:起始ID标示,$代表队列中最后一个消息,0则代表队列中第一个消息
MKSTREAM:队列不存在时自动创建队列
其它常见命令:
删除指定的消费者组
XGROUP DESTORY key groupName
给指定的消费者组添加消费者
XGROUP CREATECONSUMER key groupname consumername
删除消费者组中的指定消费者
XGROUP DELCONSUMER key groupname consumername
从消费者组读取消息:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
- group:消费组名称
- consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
- count:本次查询的最大数量
- BLOCK milliseconds:当没有消息时最长等待时间
- NOACK:无需手动ACK,获取到消息后自动确认
- STREAMS key:指定队列名称
- ID:获取消息的起始ID:
">":从下一个未消费的消息开始
其它:根据指定id从pending-list中获取已消费但未确认的消息,例如0,是从pending-list中的第一个消息开始
消费者监听消息的基本思路:
STREAM类型消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次
最后我们来个小对比
7.1 Redis消息队列-认识消息队列
什么是消息队列:字面意思就是存放消息的队列。最简单的消息队列模型包括3个角色:
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息
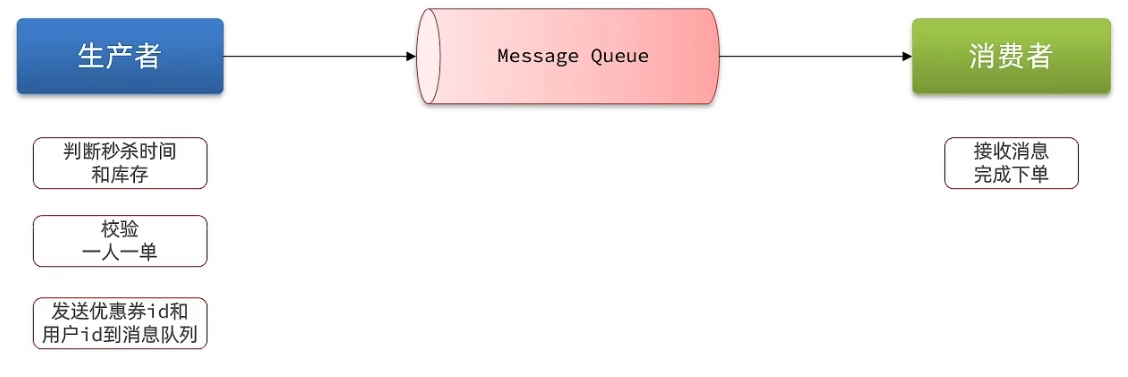
使用队列的好处在于 解耦:所谓解耦,举一个生活中的例子就是:快递员(生产者)把快递放到快递柜里边(Message Queue)去,我们(消费者)从快递柜里边去拿东西,这就是一个异步,如果耦合,那么这个快递员相当于直接把快递交给你,这事固然好,但是万一你不在家,那么快递员就会一直等你,这就浪费了快递员的时间,所以这种思想在我们日常开发中,是非常有必要的。
这种场景在我们秒杀中就变成了:我们下单之后,利用redis去进行校验下单条件,再通过队列把消息发送出去,然后再启动一个线程去消费这个消息,完成解耦,同时也加快我们的响应速度。
这里我们可以使用一些现成的mq,比如kafka,rabbitmq等等,但是呢,如果没有安装mq,我们也可以直接使用redis提供的mq方案,降低我们的部署和学习成本。
7.2 Redis消息队列-基于List实现消息队列
基于List结构模拟消息队列
消息队列(Message Queue),字面意思就是存放消息的队列。而Redis的list数据结构是一个双向链表,很容易模拟出队列效果。
队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。
不过要注意的是,当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此这里应该使用BRPOP或者BLPOP来实现阻塞效果。

基于List的消息队列有哪些优缺点?
优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点:
- 无法避免消息丢失
- 只支持单消费者
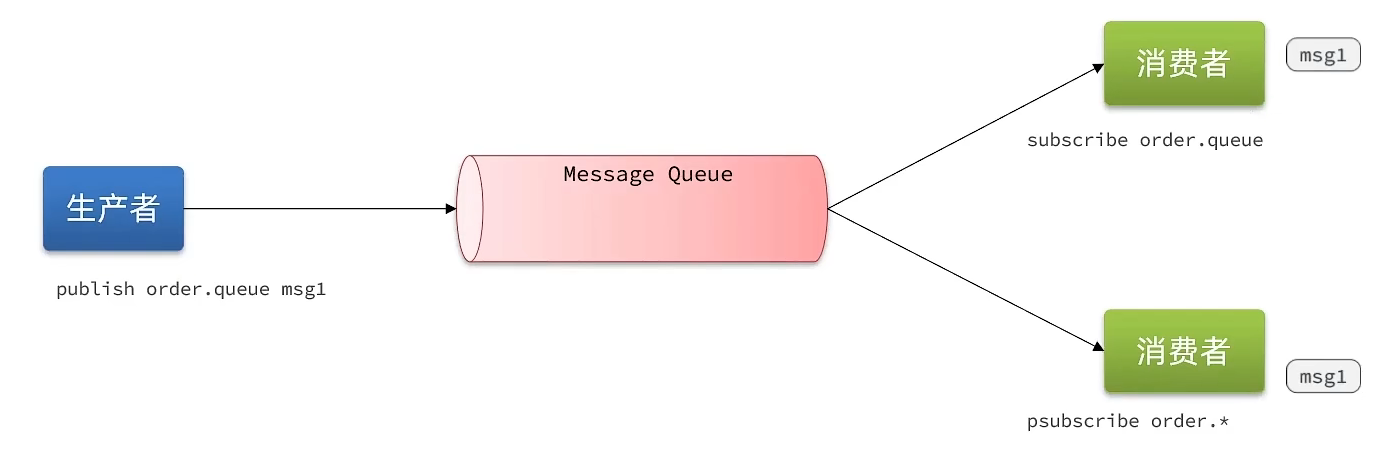
7.3 Redis消息队列-基于PubSub的消息队列
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
SUBSCRIBE channel [channel] :订阅一个或多个频道
PUBLISH channel msg :向一个频道发送消息
PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道
基于PubSub的消息队列有哪些优缺点?
优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
7geo
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命令有:
- GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定member的坐标转为hash字符串形式并返回
- GEOPOS:返回指定member的坐标
- GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.以后已废弃
- GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
- GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
8BitMap
用户一次签到,就是一条记录,假如有1000万用户,平均每人每年签到次数为10次,则这张表一年的数据量为 1亿条
每签到一次需要使用(8 + 8 + 1 + 1 + 3 + 1)共22 字节的内存,一个月则最多需要600多字节
我们如何能够简化一点呢?其实可以考虑小时候一个挺常见的方案,就是小时候,咱们准备一张小小的卡片,你只要签到就打上一个勾,我最后判断你是否签到,其实只需要到小卡片上看一看就知道了
我们可以采用类似这样的方案来实现我们的签到需求。
我们按月来统计用户签到信息,签到记录为1,未签到则记录为0.
把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图(BitMap)。这样我们就用极小的空间,来实现了大量数据的表示
Redis中是利用string类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是 2^32个bit位。
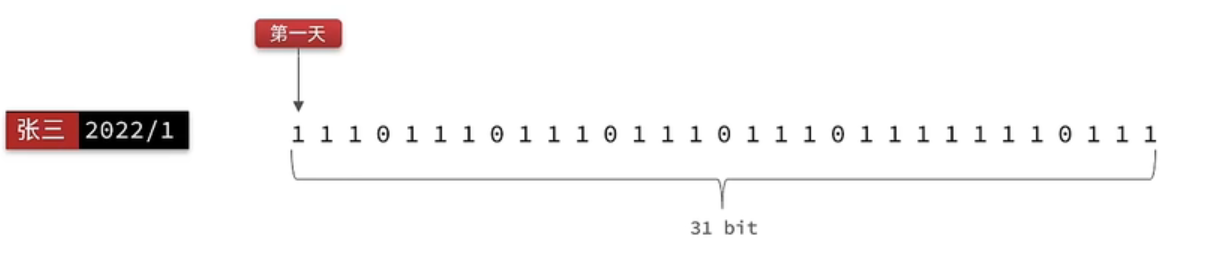
BitMap的操作命令有:
- SETBIT:向指定位置(offset)存入一个0或1
- GETBIT :获取指定位置(offset)的bit值
- BITCOUNT :统计BitMap中值为1的bit位的数量
- BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
- BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
- BITOP :将多个BitMap的结果做位运算(与 、或、异或)
- BITPOS :查找bit数组中指定范围内第一个0或1出现的位置