转载请注明出处❤️
作者:测试蔡坨坨
原文链接:caituotuo.top/747a74ea.html
你好,我是测试蔡坨坨。
对于测试同学来说,除了知道测试基础知识外,还需要掌握一些测试基本技能,主要有Linux、数据库、计算机网络等,在此之前我们已经讨论过Linux基础知识以及在实际工作中的应用,可参考往期文章「学会 Linux,看完这篇就行了!」。
今天,我们就来聊一聊数据库,数据库是大学本科计算机系核心课程之一,其重要性不言而喻。
数据库在面试中基本属于必考内容,最多的就是手写SQL或口述SQL,面试官会给你出一个场景,比如班级、分数、课程之类的,一般考察表查询语句居多,例如多表查询、连接查询、子查询等。所以,当你准备转行踏入IT行业的时候,就首先需要掌握数据库。
本文主要科普作为一枚测试应该知道的数据库理论基础知识,知道这些不仅可以在面试时加分,而且可以加深你对数据库的理解,而不是仅仅停留在只会写几个SQL上面。
测试人员对于数据库理论知识的学习,肯定不需要像开发那么深入,但是一些基本的内容需要知道并掌握,简单来说,数据库基础,看完接下来的文章并搞明白就完全够用了。
当然,关于数据库进阶知识,比如数据库索引、事务、数据库三大范式、数据库调优、存储过程等内容也会在后续的文章中与大家讨论。
作为测试,数据库在日常工作中的权重占比还是比较大的,主要有以下几个应用场景:
-
项目部署及部署完后数据的准备
开发配置好环境,但是没有连接数据库,就需要我们自己新建数据库并连接。
已经建好数据库,但是没有创建数据表,就需要我们自己创建数据表。
已经创建好数据库和数据表,但是数据表中没有数据,就需要我们自己添加数据。
数据表中有数据,但是数据量不够,开发只提供一两条样例数据,测试就需要大量造数据。
项目的后台管理没有注册功能,就需要我们自己手动向数据表中插入用户名和密码。
-
在前端页面增删改查,查看数据库是否做了相应更新,核对数据存储的准确性
举栗1:在CRM项目中,新建客户以后,在数据库的表中查看是否与新建的客户信息一致。
举栗2:支付交易产生的订单可以从数据库中查看订单是否真实存储,数据信息是否一致。
-
对数据直接操作来满足测试用例所需的极限场景
比如有些场景像CRM项目中的新建客户功能,我们只是要验证一个输入框的边界值,但是却需要在前端页面一直新建,一直提交保存,每次新建都需要填写暂时不需要测试的必填项,太麻烦,就可以直接去修改数据表中对应的字段值。
-
性能测试或自动化测试通过脚本产生大量数据时,查看数据库是否批量有效存储
-
通过操作数据库优化测试用例,提升测试效率
-
前端输入框字段报错时,可能是数据库参数类型设置有误或字段长度不够,就可以打开数据库查看字段参数类型和长度是否正确
-
性能测试,通过优化SQL语句或表结构来提高系统的性能,例如慢查询等
-
造数据场景,构造某些用例的前置条件
举栗1:统计年盈利额,需要1~12月都需要数据,不可能一个需求测一年吧,就可以在数据库中直接插入数据。
举栗2:手机号注册时,通过改数据库表字段非唯一状态来重复使用一个手机号,进行反复注册。
举栗3:通过修改金额、价格等用来做支付测试,比如原本需要100¥,就可以通过修改数据为0.01¥。
举栗4:会员积分,就可以在数据库直接修改积分,看是否达到会员。
-
理解如何通过接口操作数据库
-
做测试结构分析时,可以通过数据库搞清楚数据流向,哪个表放哪个字段什么时候在哪里展示
and so on ……
以上,仅列举了一些日常工作中比较常见的场景,供大家参考。
同时欢迎评论区补充哦~
紧接着,就来介绍一下数据库以及常用的SQL语句。
认识数据库
什么是数据库?
数据库的英文单词:Database ,简称DB。
数据库方向的岗位叫DBA(Database Administrat),也就是数据库管理员,专门和数据库打交道的,属于运维工程师的一个分支,主要负责业务数据库从设计、测试到部署交付的全生命周期管理。
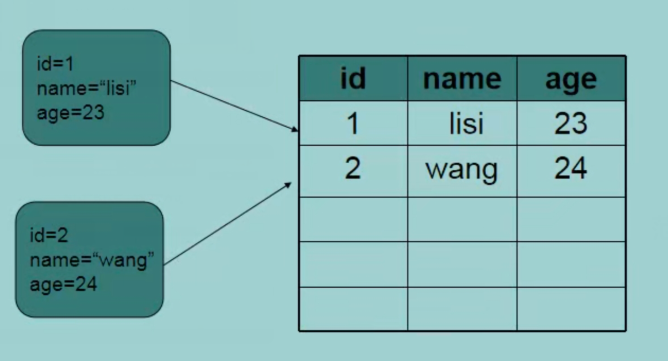
数据库实际上就是一个文件集合,是一个存储数据的仓库,本质就是一个文件系统,数据库是按照特定的格式把数据存储起来,用户可以对存储的数据进行增删改查操作。
简单概括,数据库就是用于存储和管理数据的仓库。
具体来说,就是前端页面用户输入的数据通过接口传给后端,然后存储到数据库中,同时也支持从数据库中取数据传给前端页面做一个展示。
数据库的两大分类
-
关系型数据库:是建立在关系模型基础上的数据库,比如MySQL、Oracle、SQL Server、DB2、PostgreSQL等,还有一些国产的数据库比如达梦数据库、神通数据库、人大金仓数据库等。
-
非关系型数据库(NO SQL):通常指数据之间无关系的数据库,比如MongoDB、Redis,以键值对的方式存储。
新手入门该学习哪个数据库?
上面说了这么多数据库,而目前企业中使用最多的就是MySQL和Oracle数据库,后者因为是收费的,所以互联网公司尤其是中小型企业使用最多的就是MySQL数据库,数据库的学习其实和编程语言一样,当你熟练掌握其中一种时,其他的也就分分钟上手了。
因此,推荐初学者从MySQL数据库开始学习。
MySQL简介
- MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发。
- 世界上最流行的几款数据库之一。
- 优点:是一款轻量级数据库、免费、开源、适用于中大型网站。
- MySQL默认端口号:3306。
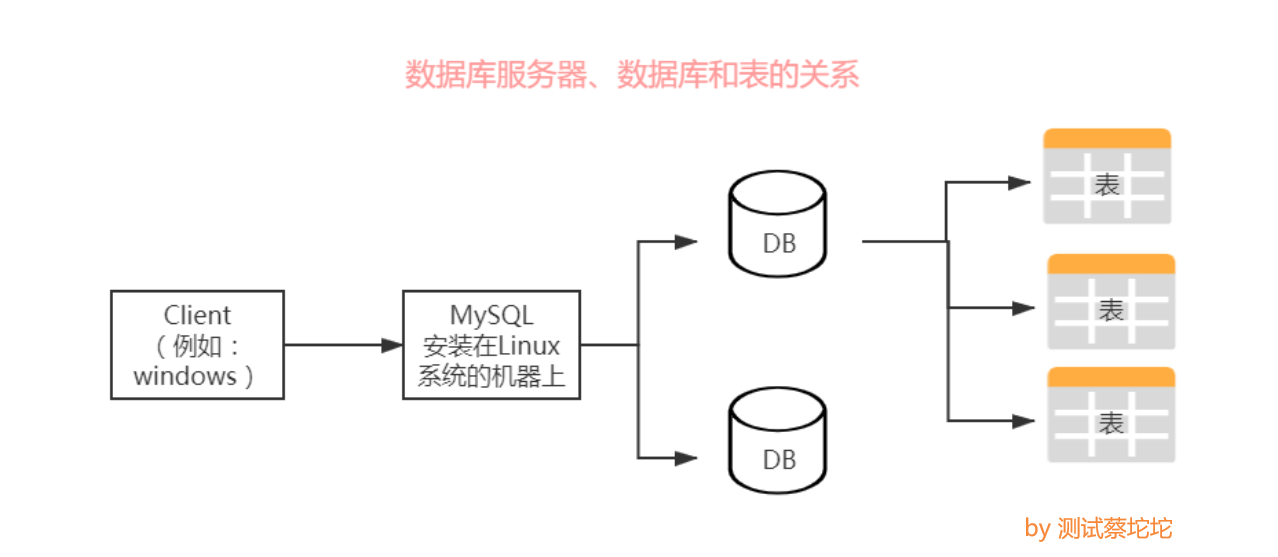
数据库服务器、数据库和表的关系
-
所谓安装数据库服务器,只是在机器上装一个数据库管理系统(比如: MySQL、Oracle、SQL Server),用来管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
-
为保存应用中实体的数据,一般会在数据库创建多个表,以保存程序中实体的数据。
Xshell、Xftp、Navicat
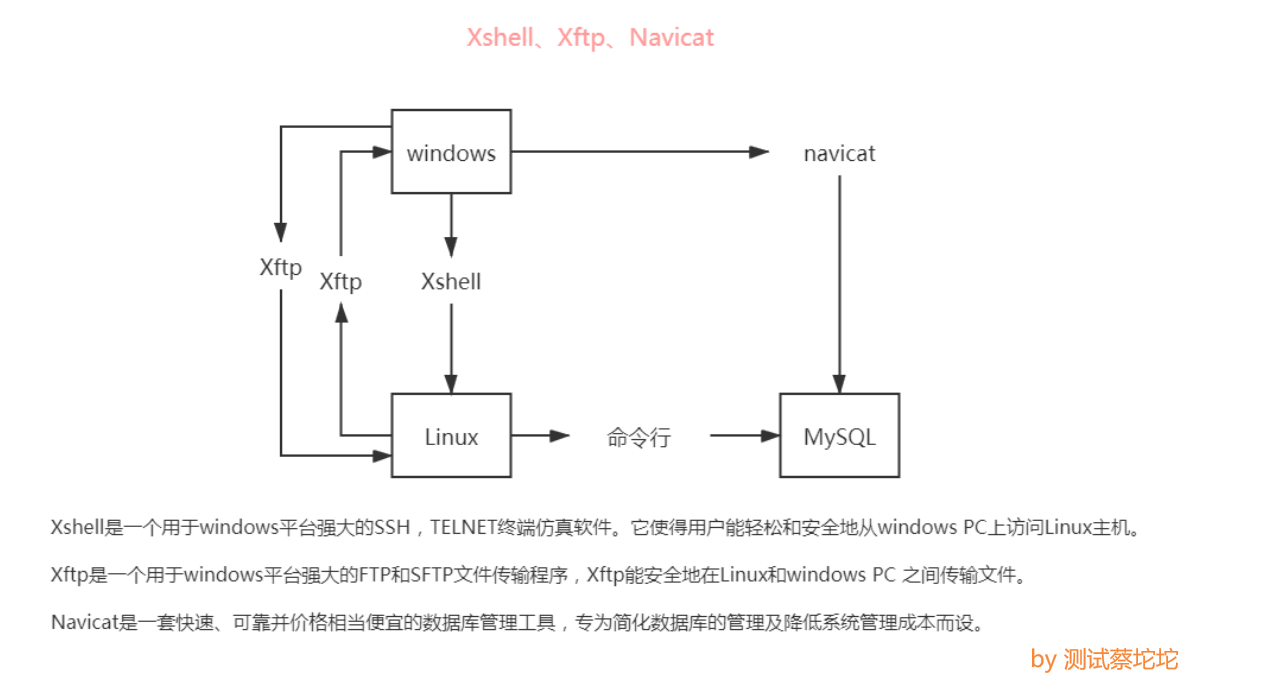
PS:Xshell或Xftp连接Linux服务器默认端口:22
SQL介绍
Structured Query Language:结构化查询语言。
SQL是专门为数据库而建立的操作命令集,是一种功能齐全的数据库语言。在使用它时,只需要发出“做什么”命令,“怎么做”是不用使用者考虑的。
SQL语法特点
- 不区分大小写。
- 关键字、字段名、表名需要用空格或逗号隔开。
- 每一个SQL语句是用分号结尾。
- 语句可以写一行也可以分开写多行。
如何自学数据库
在哪里练习?想要练习数据库需要首先需要有数据的环境,有以下两种方法:
-
本地安装一个数据库,例如MySQL
-
推荐在线练习SQL网站:www.nowcoder.com/ta/sql
可以在线练习SQL实战,会根据你的输入实时判断对错,不会的话还可以参考别人写的SQL语句。
数据库常用操作命令
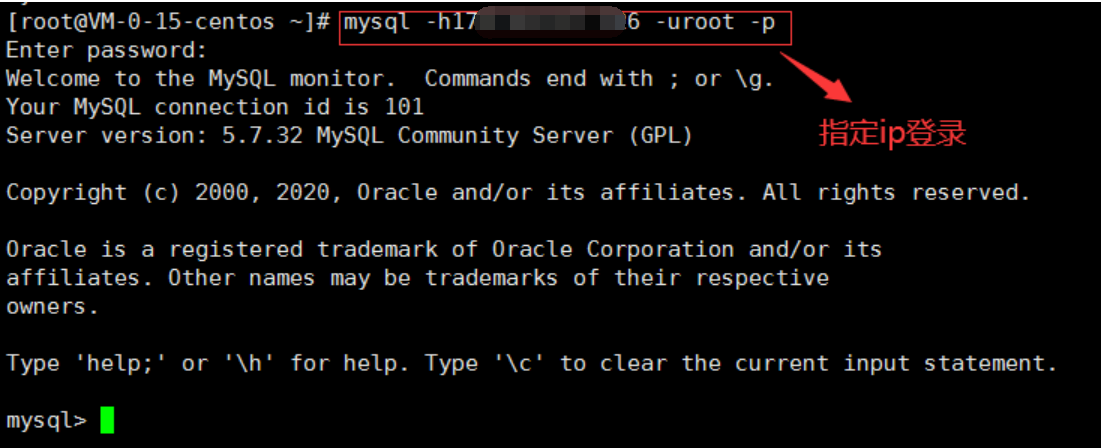
1. MySQL登录
mysql -uroot -p密码
mysql -uroot -p(回车)
Enter password: (输入密码)

mysql -hip -P端口 -uroot -p
mysql --host=ip --user=root --password=密码
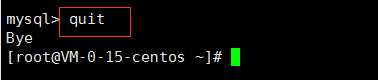
2. MySQL退出
-
exit

-
quit
3. 创建、查看、删除、使用数据库
-
创建数据库命令
-
创建数据库:
格式:create database [数据库名称];
例如:
create database caituotuo; -
创建数据库,并指定字符集:
格式:create database [数据库名称] character set [字符集名];
例如:
create database caituotuo character set utf8; -
创建数据库,并指定字符集、排序规则:
格式:create database [数据库名称] character set [字符集名] collate [排序规则];
例如:
create database caituotuo character set utf8 collate utf8_general_ci;
-
-
查看数据库命令
-
显示所有数据库:
show databases; -
模糊查询数据库:
show databases like '%tuotu%'; -
查看查询某个数据库的创建语句、字符集:
格式:show create database [数据库名称];
例如:
show create database caituotuo;
-
-
删除数据库命令
格式:drop database [数据库名称];
例如:
drop database caituotuo; -
选中某个数据库
格式:use [数据库名称];
例如:
use caituotuo;PS:这个命令可以不加分号。
4. 创建、查看、删除、修改数据表
数据在数据库中的存储方式
表中列的数据类型——数值型
| 类型 | 大小 | 用途 |
|---|---|---|
| TINYINT | 1字节 | 小整数值 |
| SMALLINT | 2字节 | 大整数值 |
| MEDIUMINT | 3字节 | 大整数值 |
| INT或INTEGER | 4字节 | 大整数值 |
| BIGINT | 8字节 | 极大整数值 |
| FLOAT | 4字节 | 单精度浮点数值 |
| DOUBLE | 8字节 | 双精度浮点数值 |
| DECIMAL | 对于DECIMAL(M,D),如果M>D则为M+2,否则为D+2 | 小数值 |
有符号和无符号(UNSIGNED)
在计算机中,可以区分正负的类型,称为有符号类型。
无正负的类型,称为无符号类型。
简单的理解为就是,有符号值可以表示负数、0、正数,无符号值只能为0或者正数。
FLOAT、DOUBLE、DECIMAL
FLOAT(10,2):总长度为10,小数点后有2位。
DOUBLE和DECIMAL也类似。
超出范围会四舍五入。
表中列的数据类型——字符型
- CHAR:定长字符串。CHAR(4) --
' d' - VARCHAR:变长字符串。VARCHAR(4) --
'd' - CHAR的查询效率要高于VARCHAR。
表中列的数据类型——日期型
| 类型 |
|---|
| DATE |
| TIME |
| YEAR |
| DATETIME |
| TIMESTAMP |
TIMESTAMP和DATETIME的异同:
- 相同点:两者都可以用来表示YYYY-MM-DD HH:MM:SS类型的日期。
- 不同点:
- 两者的存储方式不一样:
- 对于TIMESTAMP,它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储。查询时,又将其转化为客户端当前时区进行返回。(PS:中国时区为+8区)
- 而对于DATETIME,不做任何改变,基本上是原样输入和输出。
- 两者所能存储的时间范围不一样:
- TIMESTAMP所能存储的时间范围为:'1970-01-01 00:00:01.000000'到'2038-01-19 03:14:07.999999'
- DATETIME所能存储的时间范围为:'1000-01-01 00:00:00.000000'到'9999-12-31 23:59:59.999999'
- 两者的存储方式不一样:
数据表操作命令
创建表
-
创建表基础命令
-- 格式: CREATE TABLE [表名] ([列名 1 ] [列类型],[列名 2 ] [列类型],[列名 3 ] [列类型] ); -- 例如: CREATE TABLE STU (ID INT,NAME VARCHAR ( 20 );AGE INT );注意:
- 创建表前,要先选中某个数据库(use [数据库名称]);
- 列和列之间用逗号隔开,列内用空格隔开;
- 创建表时,要根据需保存的数据创建相应的列,并根据要存储数据的类型定义相应的列类型。
-
约束条件
约束条件就是给列加一些约束,使该字段存储的值更加符合我们的预期。
约束条件 含义 UNSIGNED 无符号,值从0开始,无负数 ZEROFILL 零填充,当数据的显示长度不够的时候可以使用填补0的效果填充至指定长度,字段会自动添加UNSIGNED NOT NULL 非空约束,表示该字段的值不能为空 DEFAULT 表示如果插入数据时没有给该字段赋值,那么就使用默认值 PRIMARY KEY 主键约束,表示唯一标识,不能为空,且一个表只能有一个主键 AUTO_INCREMENT 自增长,只能用于数值列,默认起始值从1开始,每次增长1 UNITQUE KEY 唯一值,表示该字段下的值不能重复,可以为空,可以有多个 COMMENT 描述 注意:
如果一列同时有UNSIGNED、ZEROFILL、NOT NULL这几个约束,
UNSIGNED、ZEROFILL必须在NOT NULL前面,否则会报错。例子:
create table user_info_tab( user_id int not null auto_increment, user_name char(10), password varchar(10), user_nick varchar(10), card_num bigint, primary key(user_id) );
查看表
-
显示当前数据库中所有表的名字
格式:
show tables; -
显示某张表每一列的属性(列名、数据类型、约束)
格式:desc [数据表名称];
例如:
desc user_info_tab;
删除表
格式:drop table [数据表名称];
例如:
drop table hesheng;
修改表
-
向数据表中添加一列
格式:ALTER TABLE [数据表名称] ADD [列名] [列的数据格式] [约束];
例如:
ALTER TABLE user_info_tab ADD phone VARCHAR(11);PS:
-
默认自动添加到数据表字段的末尾;
-
如果要加在第一列在最后加个FIRST;
-
如果要加在某一列的后面,在最后面加个AFTER某一列列名。
-
-
删除数据表的某一列
格式:ALTER TABLE [数据表名称] DROP [列名];
-
修改列的类型和名称
ALTER TABLE [表名] MODIFY [列名] [数据格式];(列名不变,其他要变)
ALTER TABLE [表名] CHANGE [旧列名] [新列名] [数据格式];(列名也要改变)
5.数据表的增删改查
增(insert)
-- 插入数据
INSERT INTO user_info ( user_id, user_name, PASSWORD, user_nick, card_num )
VALUES
( 1, 'zhangsan', 'abc123', 'zhangsanfeng', 124567894651329785 ),
( 2, 'lisi', '122bbb', 'limochou', 124567894651324567 ),
( 3, 'wangwu', '123aaa', 'wangbaiwan', 214567894651324567 ),
( 4, 'liuqi', '12aaa', 'liuchuanfeng', 214563356651324567 ),
( 5, 'zhangliu', '12aaa', 'zhangwuji', 214563356658966567 );
删(delete)
语法:
- delete from 表名 where 条件
- delete语句不能删除某一列的值。(可以使用 update 表名 set username = "" where userid = 1)
- 使用delete语句仅删除符合where条件的行的数据,不删除表中其他行和表本身。
- truncate user_info_table(直接把数据清空掉)
drop和delete的区别:
- drop是删除数据库、数据表、数据表中的某一列。
- delete是删除某一行数据。
改(update)
语法:
- update [表名] set [列名]=[新值] where [列名]=[某值];
- update语法可以新增、更新原有表行中的各列。
- set子句指示要修改哪些列和要给予哪些值。
- where子句指定应更新哪些行。如果没有where子句,则更新所有的行。
update user_info set username = "poopoo" where userid = 1;
查(select)
文末练习题中会给出查询语句相关示例。
6. 数据表的排序、聚合命令、分组
排序(order by)
-
使用order by子句,对查询结果进行排序。
-
order by 指定排序的列 asc(升序)/desc(降序)。
-
order by 子句一般位于select语句的结尾。
SELECT product_name,weight FROM products_info ORDER BY weight DESC;
聚合命令
-
distinct:对某一列数据去重。
语句:select distinct 列名 from 表名; -- 显示此列不重复的数据
-
count:统计总行数。
-
count(*):包括所有列,返回表中的总行数,在统计结果的时候,不会忽略值为Null的行数。
-
count(1):包括所有列,1表示一个固定值,没有实际含义,在统计结果的时候,不会忽略列值为Null的行数,和count(*)的区别是执行效率不同。
-
count(列名):只包括列名指定列,返回指定列的行数,在统计结果的时候,不统计列值为Null,即列值为Null的行数不统计在内。
-
count(distinct 列名):返回指定列的不重复的行数,在统计结果的时候,会忽略列值为NULL的行数(不包括空字符和0),即列值为NULL的行数不统计在内。
-
count(*)、count(1)、count(列名)执行效率比较:
-
如果列为主键,count(列名)优于count(1)
-
如果列不为主键,count(1)优于count(列名)
-
如果表中存在主键,count(主键列名)效率最优
-
如果表中只有一列,则count(*)效率最优
-
如果表中有多列,且不存在主键,则count(1)效率优于count(*)
-
-
-
MAX:最大值
-
MIN:最小值
-
AVG:平均值
-
SUM:求和
select max(列名) from 表名; select min(列名) from 表名; select avg(列名) from 表名; select sum(列名) from 表名; - 也可以跟where子句 -
limit
语法:
-
select * from 表名 limit m,n;
-
其中m是指从哪行开始,m从0取值,0表示第一行。
-
n是指从第m+1条开始,取n条。
-
select * from 表名 limit 0,2(从第一行开始,显示两行结果)
-
如果只给定一个参数,它表示返回最大的行数目:
select * from table limit 5;查询前5行
-
limit n 等价于 limit 0,n
-
分组
语法:GROUP BY
-
使用group by子句对列进行分组。
-
还可以使用having子句过滤,having通常跟在group by后,它作用于组。
-
不加having过滤:select 列名,聚合函数 from 表名 where 子句 group by 列名;
-
加上having过滤:select 列名,聚合函数 from 表名 where 子句 group by 列名 having 聚合函数 过滤条件;
-
注意:使用group by后只能展示分组的列名+聚合函数结果,因为其余列已经基于分组这一列合并。
select sum(price), count(user_id), product_id from order_info_table group by product_id having count(user_id) > 2;
7. 数据表的连接查询、子查询
两张表连接查询
INNER JOIN(内连接):获取两个表中字段匹配关系的行的所有信息。
语法:SELECT * FROM [表名] a INNER JOIN [表名] b ON a.[列名] = b.[列名];
例如:
SELECT * FROM user_info_table a INNER JOIN order_info_table b ON a.user_id = b.user_id;
SELECT * FROM user_info_table a INNER JOIN order_info_table b ON a.user_id = b.user_id WHERE b.user_id IS NULL;
LEFT JOIN(左连接):以左表为基准,获取左表所有行的信息,即使右表没有对应匹配的行的信息。右表没有匹配的部分用NULL代替。
语法:SELECT * FROM [表名] a LEFT JOIN [表名] b ON a.[列名] = b.[列名];
SELECT * FROM products_info a LEFT JOIN suppliers_info b ON a.supplier_id = b.supplier_id;
RIGHT JOIN(右连接):与左连接相反,以右表为基准,用于获取右表所有记录,及时左表没有对应匹配的行的所有信息,左表没有匹配的部分用NULL代替。
语法:SELECT * FROM [表名] a RIGHT JOIN [表名] b ON a.[列名] = b.[列名];
SELECT * FROM products_info a RIGHT JOIN suppliers_info b ON a.supplier_id = b.supplier_id;
子查询(嵌套查询)
- 嵌套在其他查询中的查询。
- 语句:select 列名1 from 表1 where 列名2 in (select 列名2 from 表2 where 列名3 = 某某某);
- 注意:一般在子查询中,程序先运行嵌套在最内层的语句,再运行外层。因此在写子查询语句时,可以先测试一下内层的子查询语句是否输出了想要的内容,再一层一层往外测试,增加子查询的正确率。
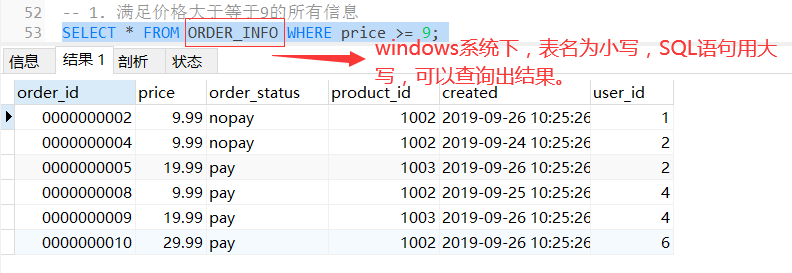
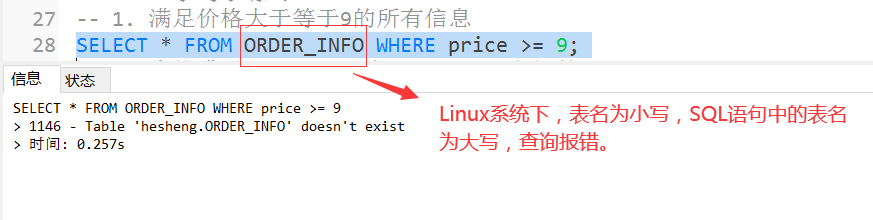
其他注意事项:数据库名和表名在Windows中是大小写不敏感的,但是在大多数类型的UNIX系统中大小写是敏感的。
笔试面试题
一、创建如下要求的表格,并完成相应的题目。
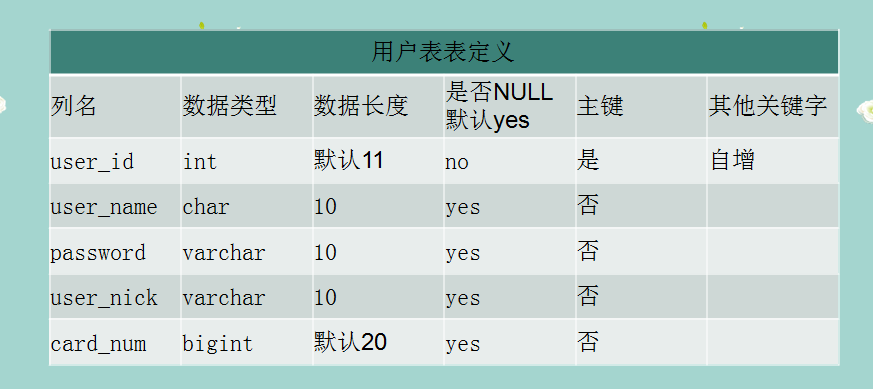
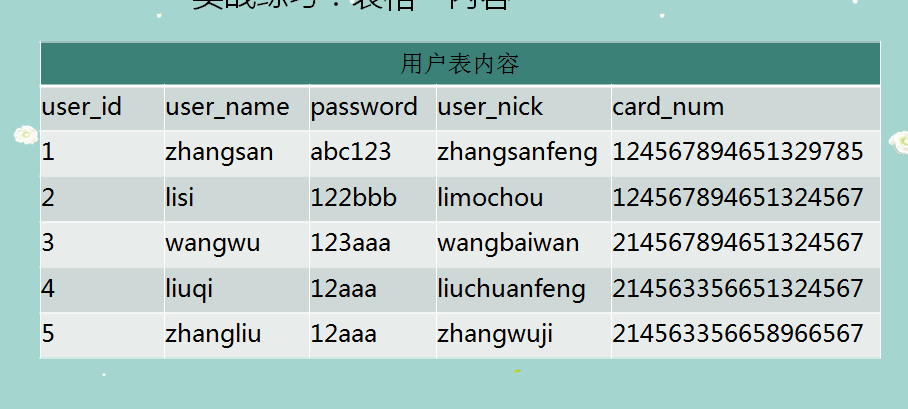
-- 创建表
CREATE TABLE user_info (
user_id INT NOT NULL AUTO_INCREMENT,
user_name CHAR ( 10 ),
password VARCHAR ( 10 ),
user_nick VARCHAR ( 10 ),
card_num BIGINT,
PRIMARY KEY ( user_id )
);
-- 插入数据
INSERT INTO user_info ( user_id, user_name, PASSWORD, user_nick, card_num )
VALUES
( 1, 'zhangsan', 'abc123', 'zhangsanfeng', 124567894651329785 ),
( 2, 'lisi', '122bbb', 'limochou', 124567894651324567 ),
( 3, 'wangwu', '123aaa', 'wangbaiwan', 214567894651324567 ),
( 4, 'liuqi', '12aaa', 'liuchuanfeng', 214563356651324567 ),
( 5, 'zhangliu', '12aaa', 'zhangwuji', 214563356658966567 );
-- user_nick长度不够,修改user_nick的长度再重新插入数据
ALTER TABLE user_info MODIFY user_nick VARCHAR ( 20 );
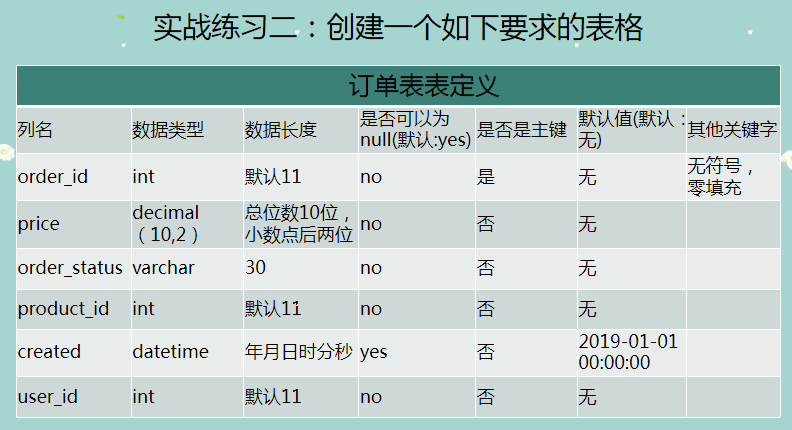

-- 创建订单表
CREATE TABLE order_info (
order_id INT UNSIGNED ZEROFILL NOT NULL,
price DECIMAL ( 10, 2 ) NOT NULL,
order_status VARCHAR ( 30 ) NOT NULL,
product_id INT NOT NULL,
created datetime DEFAULT "2019-01-01 00:00:00",
user_id INT NOT NULL,
PRIMARY KEY ( order_id )
);
-- 插入数据
INSERT INTO order_info
VALUES
( 1, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 1 ),
( 2, 9.99, 'nopay', 1002, '2019-09-26 10:25:26', 1 ),
( 3, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 2 ),
( 4, 9.99, 'nopay', 1002, '2019-09-24 10:25:26', 2 ),
( 5, 19.99, 'pay', 1003, '2019-09-26 10:25:26', 2 ),
( 6, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 3 ),
( 7, 4.99, 'pay', 1001, '2019-09-25 10:25:26', 4 ),
( 8, 9.99, 'pay', 1002, '2019-09-25 10:25:26', 4 ),
( 9, 19.99, 'pay', 1003, '2019-09-26 10:25:26', 4 ),
( 10, 29.99, 'pay', 1002, '2019-09-26 10:25:26', 6 );
-- where子句小练习
-- 1. 满足价格大于等于9的所有信息
SELECT * FROM order_info WHERE price >= 9;
-- 2. 查找满足product_id在1002和1003之间的
SELECT * FROM order_info WHERE product_id BETWEEN 1002 AND 1003;
-- 3. 查找user_id在1、3、5这三个数内的信息
SELECT * FROM order_info WHERE user_id IN (1,3,5);
-- 4. 查找订单状态是已支付的信息
SELECT * FROM order_info WHERE order_status = 'pay';
-- 5. 查找用户名类似于已li开头的信息
SELECT * FROM user_info WHERE user_name LIKE 'li%';
-- 6. 查找用户名中第二个字母是h的信息
SELECT * FROM user_info WHERE user_name LIKE '_h%';
-- 7. 查找用户名中第二个字母不是h的信息
SELECT * FROM user_info WHERE user_name NOT LIKE '_h%';
-- 8. 查找用户名中最后一个字母以i结尾的信息
SELECT * FROM user_info WHERE user_name LIKE '%i';
-- 9. 查找价格大于8,并且订单状态是已支付的所有信息
SELECT * FROM order_info WHERE price > 8 AND order_status = 'pay';
-- 10.查找用户表中user_nick为null的信息
SELECT * FROM user_info WHERE user_nick IS NULL;
-- 11.查找用户表中user_nick为 not null的信息
SELECT * FROM user_info WHERE user_nick IS NOT NULL;
-- 聚合函数练习
-- 1. 查找订单表中最大的价格,查找订单表中最小的价格
SELECT MAX(price),MIN(price) FROM order_info;
-- 2. 查找订单表中user_id=2的最小价格
SELECT MIN(price) FROM order_info WHERE user_id = 2;
-- 3. 分别列出订单表中user_id=2的最小价格和最大价格
SELECT MIN(price),MAX(price) FROM order_info WHERE user_id = 2;
-- 4. 分别列出订单表中user_id=2的最小价格和最大价格,并把最小价格的展示结果的列名改为"min_price"
SELECT MIN(price) AS min_price,MAX(price) FROM order_info WHERE user_id = 2;
-- 5. 求订单表的价格的平均值,求订单表中user_id=2的价格的平均值
SELECT AVG(price) FROM order_info;
SELECT AVG(price) FROM order_info WHERE user_id = 2;
-- 6. 分别列出订单表中user_id=2的价格的平均值、最小值、最大值
SELECT AVG(price),MIN(price),MAX(price) FROM order_info WHERE user_id = 2;
-- 7. 求订单表中user_id=1的价格的总和
SELECT SUM(price) FROM order_info WHERE user_id = 1;
-- 8. 求订单表中user_id=1或者user_id=3的价格总和
SELECT SUM(price) FROM order_info WHERE user_id = 1 OR user_id = 3;
-- 分组练习
-- 1.首先筛选状态为已支付的订单,然后按照user_id分组,分组后每一组对支付金额进行求和,最终展示user_id和对应组求和金额
SELECT user_id,SUM(price) FROM order_info WHERE order_status = 'pay' GROUP BY user_id;
-- 2.首先筛选状态为支付的订单,然后按照user_id分组,分组后每一组对支付金额进行求和,再过滤求和金额大于10的,最终展示user_id和对应组的求和金额
SELECT user_id,SUM(price) FROM order_info WHERE order_status = 'pay' GROUP BY user_id HAVING SUM(price) > 10;
-- 数据表连接查询和子查询练习
-- 1.查询订单表中的价格大于10元的用户的昵称(小提示:用户昵称在用户表中,订单价格在订单表中)
SELECT a.user_nick FROM user_info a INNER JOIN order_info b ON a.user_id = b.user_id WHERE b.price > 10;
SELECT user_nick FROM user_info WHERE user_id IN (SELECT user_id FROM order_info WHERE price > 10);
-- 2.查询用户名以l开头的用户买过的所有订单id和对应价格(小提示:订单id和对应价格在订单表中,用户名在用户表中)
SELECT o.order_id,o.price FROM order_info o WHERE o.user_id IN (SELECT user_id FROM user_info u WHERE u.user_name LIKE 'l%');
二、创建如下要求的表格,并完成相应的题目。
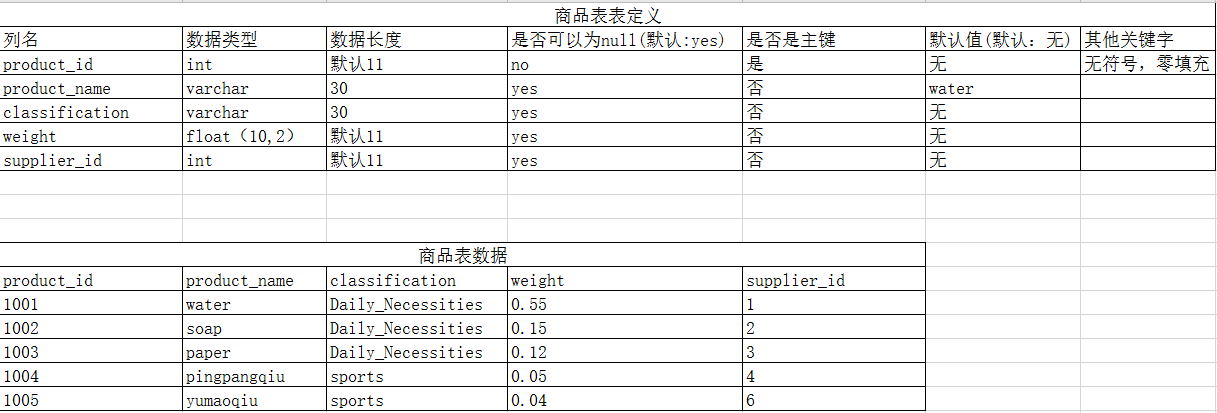
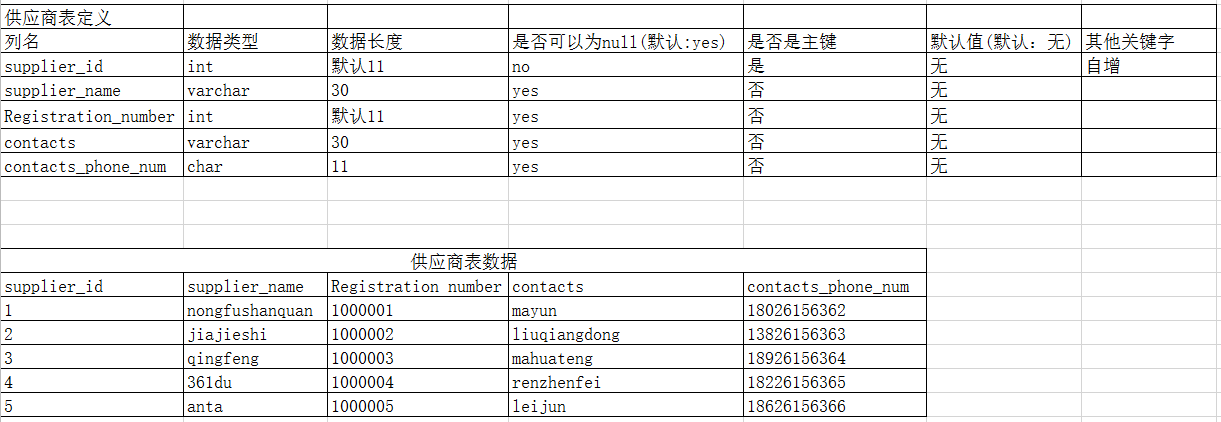
-- 1.按照表定义创建商品表+供应商表
-- 2.按照表数据插入所有数据
-- 创建商品表
CREATE TABLE products_info (
product_id INT UNSIGNED ZEROFILL NOT NULL,
product_name VARCHAR ( 30 ) DEFAULT 'water',
classification VARCHAR ( 30 ),
weight FLOAT ( 10, 2 ),
supplier_id INT,
PRIMARY KEY ( product_id )
);
-- 向商品表插入数据
INSERT INTO products_info
VALUES
( 1001, 'water', 'Daily_Necessities', 0.55, 1 ),
( 1002, 'soap', 'Daily_Necessities', 0.15, 2 ),
( 1003, 'paper', 'Daily_Necessities', 0.12, 3 ),
( 1004, 'pingpangqiu', 'sports', 0.05, 4 ),
( 1005, 'yumaoqiu', 'sports', 0.04, 6 );
-- 创建供应商表
CREATE TABLE suppliers_info (
supplier_id INT NOT NULL AUTO_INCREMENT,
supplier_name VARCHAR ( 30 ),
Registration_number INT,
contacts VARCHAR ( 30 ),
contacts_phone_num CHAR ( 11 ),
PRIMARY KEY ( supplier_id )
);
-- 向供应商表插入数据
INSERT INTO suppliers_info
VALUES
( 1, 'nongfushanquan', 1000001, 'mayun', '18026156362' ),
( 2, 'jiajieshi', 1000002, 'liuqiangdong', '13826156363' ),
( 3, 'qingfeng', 1000003, 'mahuateng', '18926156364' ),
( 4, '361du', 1000004, 'renzhenfei', '18226156365' ),
( 5, 'anta', 1000005, 'leijun', '18626156366' );
-- 3.修改供应商id为4的供应商名称为‘hongshuangxi’
UPDATE suppliers_info SET supplier_name = 'hongshuangxi' WHERE supplier_id = 4;
-- 4.查询商品重量大于0.10的商品的名称
SELECT product_name FROM products_info WHERE weight > 0.10;
-- 5.查询商品名称以字母p开头的商品的所有信息
SELECT * FROM products_info WHERE product_name like 'p%';
-- 6.查询商品重量大于0.10,小于0.20的商品名称
SELECT product_name FROM products_info WHERE weight > 0.10 AND weight < 0.20;
-- 7.按照商品分类统计各自的商品总个数,显示每个分类和其对应的商品总个数
SELECT classification,COUNT(classification) FROM products_info GROUP BY classification;
-- 8.将所有商品的名称按照商品重量由高到低显示
SELECT product_name,weight FROM products_info ORDER BY weight DESC;
-- 9.显示所有商品的信息,在右边显示有供应商的商品对应的供应商信息
SELECT * FROM products_info a LEFT JOIN suppliers_info b ON a.supplier_id = b.supplier_id;
-- 10.显示重量大于等于0.15的商品的供应商的联系人和手机号
SELECT s.contacts,s.contacts_phone_num FROM suppliers_info s INNER JOIN products_info p ON s.supplier_id = p.supplier_id and p.weight >= 0.15;