查询SQL语句执行频率
查询 mysql 服务启动时长
SHOW STATUS LIKE 'uptime';
下列输出表示服务启动了276324秒
+---------------+--------+
| Variable_name | Value |
+---------------+--------+
| Uptime | 276324 |
+---------------+--------+
查询全局SQL执行的频率
-- 执行了多少次select
SHOW GLOBAL STATUS LIKE 'com_select';
-- 执行了多少次insert
SHOW GLOBAL STATUS LIKE 'com_insert';
-- 执行了多少次update
SHOW GLOBAL STATUS LIKE 'com_update';
-- 执行了多少次delete
SHOW GLOBAL STATUS LIKE 'com_delete';
查询InnoDB引擎的数据库SQL执行频率
SHOW GLOBAL STATUS LIKE 'Innodb_rows_%';
输出
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| Innodb_rows_deleted | 0 |
| Innodb_rows_inserted | 7682 |
| Innodb_rows_read | 4022470 |
| Innodb_rows_updated | 0 |
+----------------------+---------+
定位低效的查询SQL
慢查询记录
查看实时执行进程
mysql> SHOW PROCESSLIST;
在执行时,一条sql正在执行中,就可以看到SQL的执行情况:

如果发现正在执行的Time时间过长,我们就可以把这条低效的SQL拿来进行优化。
执行计划EXPLAIN
概述
EXPLAIN是SQL语句执行的分析器,在执行一条SQL语句时,我们可以使用EXPLAIN命令查看SQL语句的执行计划,从而知道SQL语句时如何执行的。
在使用EXPLAIN时,我们只需要在执行的SQL语句前面加上EXPLAIN就可以打印执行计划:
EXPLAIN SELECT * FROM app_user WHERE email = '100@qq.com';

在执行查询计划后会输出以上的一条数据,其中:
1)id 序列号
表结构的执行序列号,序号一样就从上而下执行,序号不同值,值越大优先级越高,先执行;
一般简单查询只会有一条记录,连接查询、子查询会根据查询的层次出现多条记录,这时序号就会就会不同。
2)select_type 查询类型
如果是连接查询,嵌套查询的,每层查询的类型可能不一样;
| select_type值 | 说明 |
|---|---|
| SIMPLE | 简单查询(不使用UNION或子查询) |
| PRIMARY | 查询中包含子查询的,最外层标记为PRIMARY |
| UNION | 第二个SELECT出现在UNION之后,则被标记为UNION |
| UNION RESULT | 在UNION结果中查询 |
| SUBQUERY | 在SELECT或者WHERE中包含子查询的查询 |
| DERIVED | 在FROM列表中包含子查询 |
3)table 引用表
输出行所引用的表的名称,可能还会出现以下值:
- <unionM,N>:引用union结果,M,N表示进行union的两条记录的ID;
- <derivedN>:引用了ID为N的派生结果,例如,派生表可能来自FROM中的子查询;
- <subqueryN>:引用了ID为N的子查询结果。
4)partitions 匹配分区
如果表设置了分区,会显示数据从哪些分区中查询,多个分区使用逗号隔开。
5)type 联结类型
显示查询使用了何种类型,按照从最佳到最坏类型排序;
-
NULL:不访问任何表,比如直接打印
NOW()函数,就不查询任何表; -
system:一次就查询到了,查询系统表才会出现;
-
const:通过索引一次就查询到了,通常使用了主键索引、唯一索引的记录查询时会出现;
-
eq_ref:常见连接查询,查询的结果只出现一条记录;
-
ref:根据非唯一索引进行条件查询,匹配到查询条件的所有行;
-
range:根据检索的条件,搜索到指定范围的数据,常见为WHRER出现范围查询;
-
index:遍历了索引树,但是没有去遍历数据,速度比遍历数据快一点;
-
all:遍历了全表的数据,查询最慢;
一般保证查询至少达到range级别,最好能达到ref。
6)possible_keys 可使用索引
表示数据可以从哪些索引中检索数据。
7)key 选择索引
MySQL在possible_keys中最终选择了那一key进行检索数据。
8)key_len 键长度
MySQL决定使用的key的长度。
9)ref 比较列
显示将哪些列或常量与键列中命名的索引进行比较,以从表中选择行。
10)rows 查询行数
根据表统计信息以及索引选用情况,大致估算出找到所需的记录所需要扫描的记录数。
11)filtered 过滤百分比
按表条件过滤的表行的估计百分比。最大值为100,这意味着没有发生行过滤,从100开始减小的值表示过滤量增加。
12)Extra 扩展信息
- Using filesort:如果MySQL无法使用索引完成排序而使用了文件排序,需要优化;
- Using temporary:使用了临时表来来保存了结果,在排序或者分组时没有使用索引,需要优化;
- Using index condition:从索引中检索到数据的坐标,需要回表查询到具体数据。
- Using index:从索引中检索到数据,一般保持这个,不需要做优化;
- Using where:使用了where条件查询到的,但是没有使用索引,建议给查询条件添加索引;
PROFILES 分析
显示当前会话过程中执行的语句资源使用信息,一般在调试中使用,比较耗费资源,生产环境不要使用。
我们先使用have_profiling变量查看mysql是否支持PROFILES,如果输出yes,表示支持:
SELECT @@have_profiling;
查看当前回话是否开启了profiling,0表示未开启:
SELECT @@profiling;
当前回话 开启/关闭profiling
-- 开启profiling
SET profiling=1;
-- 关闭profiling
SET profiling=0;
我们先开启profiling,然后执行我们需要分析的SQL语句:
-- 执行SQL
SELECT * FROM `app_user` WHERE `name`='用户14' OR `phone`='18620769501';
-- 分析
SHOW PROFILES;
输出内容如下:
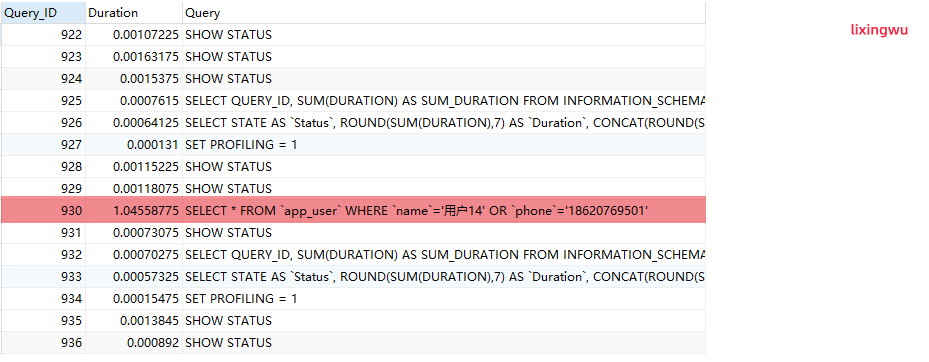
由图片我们可知,上面执行的sql语句,耗时约1.045,如果还想查看每一步执行的耗时,可以使用下面语句:
SHOW PROFILE FOR QUERY 930;
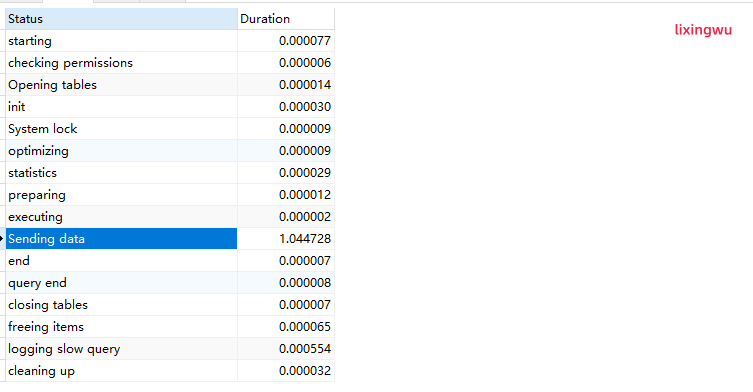
其中 930 是 SHOW PROFILES 记录的Query_ID。
trace分析
查看优化器如何选择执行计划的,和PROFILES一样,trace分析非常消耗资源,不建议在生产环境开启。
我们先开启trace分析器,把输出的内容改成json字符串:
-- 开启trace分析器
SET optimizer_trace="enabled=on",end_markers_in_json=on;
-- 设置记录的trace的最大值
SET optimizer_trace_max_mem_size=1000000;
在调试完成后记得关闭trace分析器:
SET optimizer_trace="enabled=off";
我们现在执行一条需要分析的SQL语句,让trace分析器来进行分析:
SELECT * FROM app_user WHERE id = 2;
分析结果记录到了 information_schema.optimizer_trace 系统表中,我们查询一下即可得到分析结果:
SELECT * FROM information_schema.optimizer_trace;

TRACE 中大概分为3块:
- join_preparation:准备阶段,主要包括查询语句转换
- join_optimization:优化阶段,处理where条件、依赖检查、索引评估、扫描行数统计,评估执行计划
- join_execution:执行阶段,优化后执行
优化 INSERT 语句
- 在MySQL中,插入多条数据,应该尽量避免使用多个INSERT语句;可以使用多值插入的方式,这种方式大大减少客户端和数据库服务连接的次数,比单独执行多个INSERT语句效率高。
-- 低效的插入
INSERT INTO `login_user`(`loginName`,`loginPwd`) VALUES('1014','12134');
INSERT INTO `login_user`(`loginName`,`loginPwd`) VALUES('1015','12134');
INSERT INTO `login_user`(`loginName`,`loginPwd`) VALUES('1016','12134');
-- 高效的插入
INSERT INTO `login_user`(`loginName`,`loginPwd`)
VALUES('1014','12134'),('1015','12134'),('1016','12134');
- 在事务中进行插入,避免每次插入都进行提交,如果数据量比较大,可进行分段提交。
-- 低效的插入
INSERT INTO `login_user`(`loginName`,`loginPwd`) VALUES('1017','12134'),('1018','12134');
INSERT INTO `user_info`(`userId`,`mobile`) VALUES(1,'13800001017'),(1,'13800001018');
-- 使用手动事务提交,高效的插入
BEGIN;
INSERT INTO `login_user`(`loginName`,`loginPwd`) VALUES('1019','12134'),('1020','12134');
INSERT INTO `user_info`(`userId`,`mobile`) VALUES(1,'13800001019'),(1,'13800001020');
COMMIT;
ORDER BY 优化
- 在排序时尽量避免回表查询。在根据索引进行排序时,查询的字段如果没有添加索引,会导致排序使用文件排序,索引失效;
-- 索引失效,进行文件排序
EXPLAIN SELECT * FROM `app_user` ORDER BY `name`;

- 如果查询的字段有索引,排序时会直接使用索引,不需要进行文件排序,效率较高。
-- 使用索引排序
EXPLAIN SELECT `id`,`name` FROM `app_user` ORDER BY `name`;

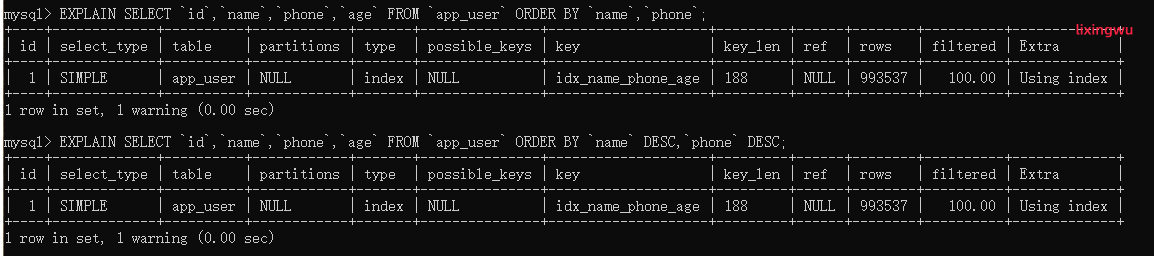
- 多字段排序,要么同时使用升序,要么同时使用降序,多字段避免使用不同的排序。
-- 多字段同排序
EXPLAIN SELECT `id`,`name`,`phone`,`age` FROM `app_user` ORDER BY `name`,`phone`;
EXPLAIN SELECT `id`,`name`,`phone`,`age` FROM `app_user` ORDER BY `name` DESC,`phone` DESC;
-- 多字段不同排序,会使用文件排序
EXPLAIN SELECT `id`,`name`,`phone`,`age` FROM `app_user` ORDER BY `name` DESC,`phone` ASC;

- filesort排序优化,MySQL在进行文件排序filesort时,会根据变量
max_length_for_sort_data来判断使用什么样的排序算法,小于这个变量使用单路排序,大于这个变量使用双路排序;我们可以在配置文件中适当调大这个值,让filesort更容易使用单路排序,但需要注意的是这会导致消耗资源增加。
-- 查看使用排序算法的分界值,单位:字节
SHOW VARIABLES LIKE 'max_length_for_sort_data';
-- 查看排序缓存的大小,单位:字节
SHOW VARIABLES LIKE 'sort_buffer_size';

GROUP BY 优化
- MySQL在进行
GROUP BY时,会先进行排序操作,我们可以手动禁止排序,让TA直接进行分组操作。
-- 未添加缓存,未去除排序,自动使用了文件排序
EXPLAIN SELECT * FROM app_user GROUP BY `age`;

-- 未添加缓存,禁止自动排序操作,耗时更短
EXPLAIN SELECT * FROM app_user GROUP BY `age` ORDER BY NULL;

- 使用索引字段进行分组和排序,也可避免使用文件排序。
-- 未使用索引字段进行分组
EXPLAIN SELECT `password`,COUNT(`password`) FROM app_user GROUP BY `password`;

-- 使用了索引字段进行分组
EXPLAIN SELECT `name`,COUNT(`name`) FROM app_user GROUP BY `name`;

嵌套查询优化
尽量的使用多表连接查询替代子查询,避免子查询产生的中间表。
-- 子查询
EXPLAIN SELECT * FROM user_info WHERE userId IN(
SELECT id FROM user WHERE dept_id=1
);
-- 内连接查询替换子查询
EXPLAIN SELECT i.* FROM user_info AS i
INNER JOIN user AS u ON u.id = i.userId
WHERE u.dept_id=1;
优化OR条件
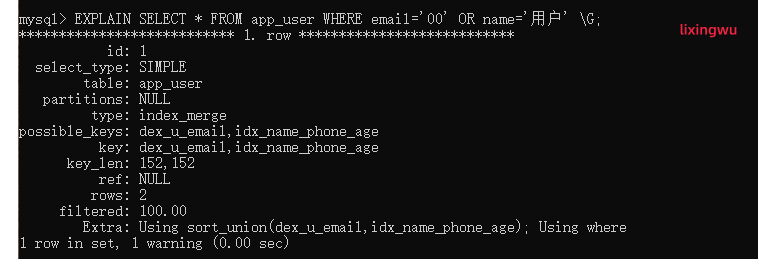
对于包含了OR的查询语句,如果要利用索引,则OR之间的每个条件列都必须使用索引(复合索引也必须满足最左前缀原则);如果没有索引,则应该考虑添加索引。
-- OR,其中age没有索引,全部索引失效
EXPLAIN SELECT * FROM app_user WHERE email='00' OR age=10;

-- OR,email单列索引和name复合索引,都有索引,索引生效
EXPLAIN SELECT * FROM app_user WHERE email='00' OR name='用户';
建议使用UNION替换OR,避免其中有列没有索引,引起全部索引失效。
-- email有索引,age没有索引
-- 1层查询走了索引,2层查询没有走索引,避免了全部索引失效
EXPLAIN SELECT * FROM app_user WHERE email='19@qq.com' UNION SELECT * FROM app_user WHERE age=10;

分页查询优化
在进行分页时,如果在前几页的数据,查询速度还算可以;
但是越往后面,查询的数据就会越慢,这是因为,MySQL会根据条件查询出符合的数据,最后才进行分页操作,而前面查询的记录都被丢弃了,造成了大量的浪费。
假设查询了第9万页的数据,MySQL会查询出9万页的全部数据,然后丢弃前8.9万的数据,返回第9万页的数据。
-- LIMIT 越往后,速度越慢
EXPLAIN SELECT * FROM app_user LIMIT 9000,10;

针对这种情况我们可以,先在索引上完成分页,然后再使用连接查询筛选出数据,全在索引上进行分页。
-- 把分页操作移到索引上去操作,
-- 把以前的993537条记录从数据文件上筛选,修改为在索引上进行筛选
EXPLAIN SELECT * FROM app_user AS u
INNER JOIN (
SELECT id FROM app_user LIMIT 9000,10
) t
ON t.id = u.id;

如果在主键自增的列上,我们可以把分页的页修改为条件,让它直接在条件处就丢弃多余的数据,但是这个情况下,数据顺序不能变动,并且数据自增的序号还不能断层,否则查询的数据就不正确;如果满足条件就使用,此方式查询效率最高。
EXPLAIN SELECT * FROM app_user WHERE id>900000 LIMIT 10;

内存优化
MyISAM 引擎内存使用 key_buffer 缓存索引块,数据块则直接读取磁盘文件,我们可以调整以下参数,让MyISAM 能缓存更多的索引。
- key_buffer_size:缓存索引区大小,一般设置为MySQL内存的四分之一;
- read_buffer_size:每个连接全表扫描缓存;
- read_rnd_buffer_size:每个连接多字段排序缓存;
InnoDB用内存区做缓存池,缓存了索引和数据块,占用内存较大。
- innodb_buffer_pool_size:缓存池的大小,尽量调大;
- innodb_log_buffer_size:用于日志缓存,调大避免在事务期间去进行io操作;
并发参数
- max_connections:允许链接MySQL服务的最大连接数,超过最大限制的将被积压到请求栈中;
- back_log:积压请求栈大小(连接数),超过这个值,连接会直接返回错误;
- table_open_cache:缓存表的数量,一般为 max_connections 乘以关联查询表数;
- thread_cache_size:服务端缓存线程池大小,便于客户端快速连接;
- innodb_lock_wait_timeout:事务行锁等待时间,快速反应的系统调小,大事务的系统调大,此处单位为秒;