聚合操作之分组、过滤

MongoDB 中聚合(aggregate)主要用于处理多个文档(诸如统计平均值,求和等),并返回计算后的数据结果。
- 对多个文档进行分组
- 对分组的文档执行操作并返回单个结果
- 分析数据变化
语法:db.集合名称.aggregate([{管道:{表达式}}])
管道命令之$group
按照某个字段进行分组
$group是所有聚合命令中用的最多的一个命令,用来将集合中的文档分组,可用于统计结果
使用示例如下
db.stu.aggregate(
{$group:
{
_id:"$country",
counter:{$sum:1}
}
}
)其中注意点:
db.db_name.aggregate是语法,所有的管道命令都需要写在其中_id表示分组的依据,按照哪个字段进行分组,例如:需要使用$gender表示选择这个字段进行分组$sum:1表示把每条数据作为1进行统计,统计的是该分组下面数据的条数
常用表达式
表达式:处理输⼊⽂档并输出 语法:表达式:'$列名' 常⽤表达式:
$sum: 计算总和, $sum:1 表示以⼀倍计数$avg: 计算平均值$min: 获取最⼩值$max: 获取最⼤值$push: 在结果⽂档中插⼊值到⼀个数组中
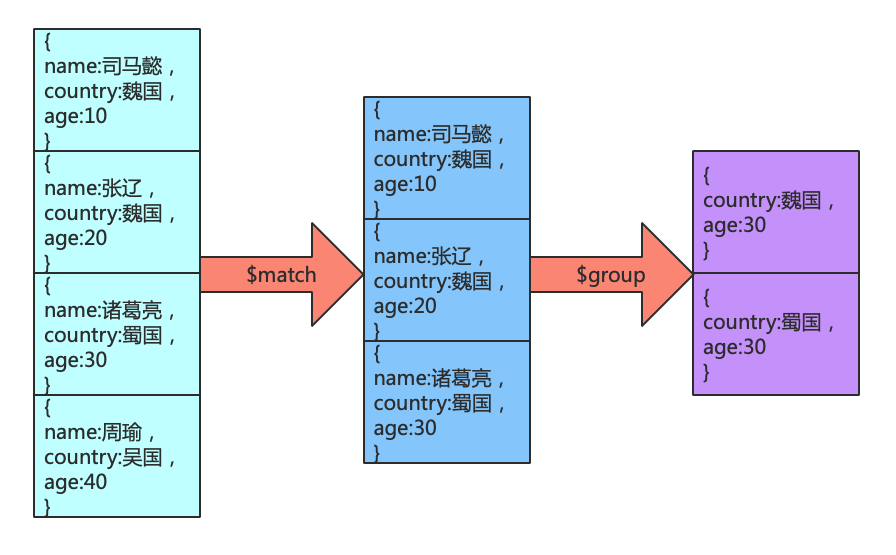
管道命令之$match
$match用于进行数据的过滤,是在能够在聚合操作中使用的命令,和find区别在于$match 操作可以把结果交给下一个管道处理,而find不行
使用示例如下:
-
查询年龄大于20的人
db.person.aggregate([ {$match:{age:{$gt:20}}} ])查询年龄大于20的魏国的人数
-
db.person.aggregate([ {$match:{age:{$gt:20}}}, {$group:{_id:"$country",counter:{$sum:1}}} ])