相对于学习Pandas各种数据筛选操作,SQL语法显得更加简洁清晰,若能够将SQL语法与Pandas中对应的函数的使用方法关联起来,对于我们应用Pandas进行数据筛选来讲无疑是一个福音。
本文通过Pandas实现SQL语法中条件过滤、排序、关联、合并、更新、删除等简单及复杂操作,使得我们对方法的理解更加深刻,更加得心应手。
演示数据集
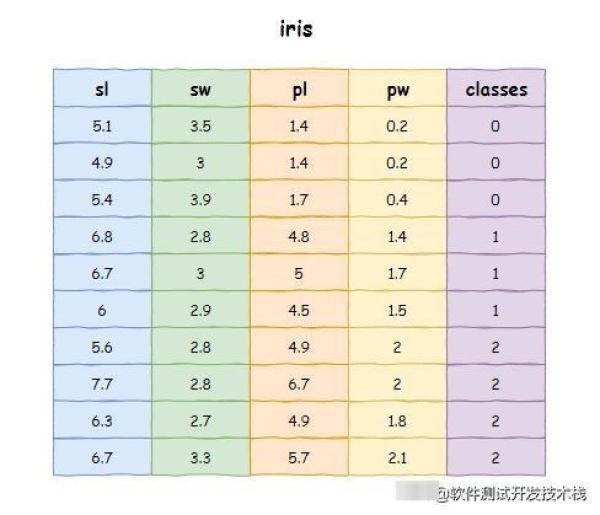
本文采用安德森鸢尾花卉(iris)数据集进行演示,iris数据集包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,因此iris数据集是一个150行*5列的二维表。
我们可以 UCI Iris dataset 中获取或者使用 from sklearn.datasets import load_iris 方式获取,为了演示方便我们只取其中10行数据,如下:
接下来,就让我们一起学习一下,如何Pandas实现SQL语法中条件过滤、排序、关联、合并、更新、删除等数据查询操作。
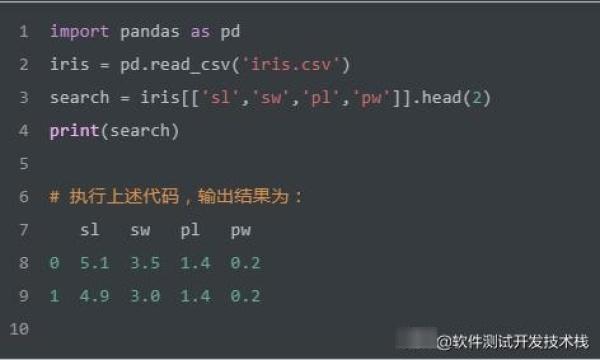
字段查询 SELECT
如上SQL实现返回每行记录的 sl,sw,pl,pw 字段,仅返回2行记录。我们使用Pandas实现如上SQL的功能,代码如下:
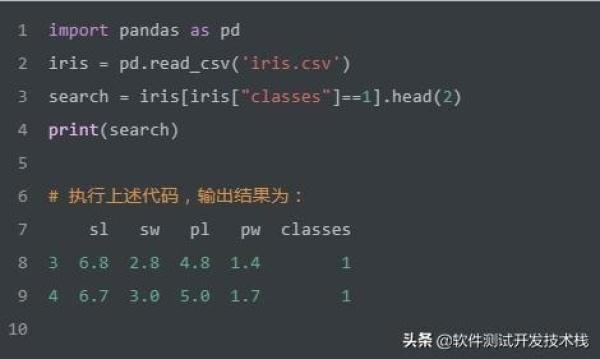
简单的条件过滤查询 WHERE
如上SQL实现了查询满足classes=1的记录,并返回2行。我们使用Pandas实现该SQL,代码如下:
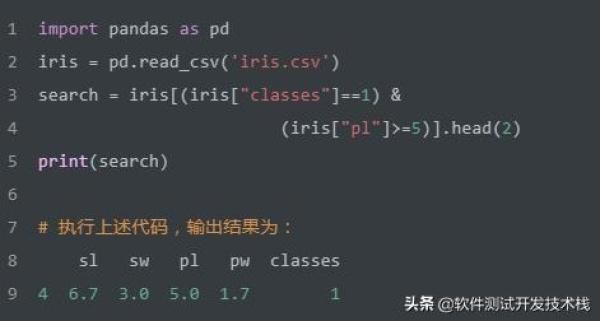
多条件的与或过滤查询 WHERE AND|OR
与关系
如上SQL实现查询同时满足classes=1 和 pl >=5 两个条件的记录,并返回2行。我们使用Pandas实现该SQL,代码如下:
或关系 |
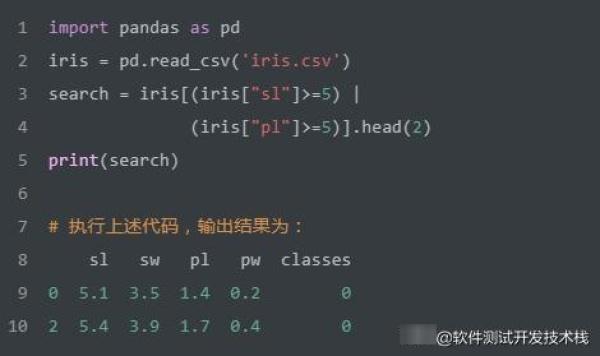
如上SQL实现查询满足 sl >=5 或者 pl >=5 任一条件的记录,返回2行。我们使用Pandas实现该SQL,代码如下:
条件过滤 空值判断
空判断 is null
如上SQL实现查询 sl 字段为NULL的记录,我们使用Pandas实现该SQL,代码如下:
>非空判断 is not null
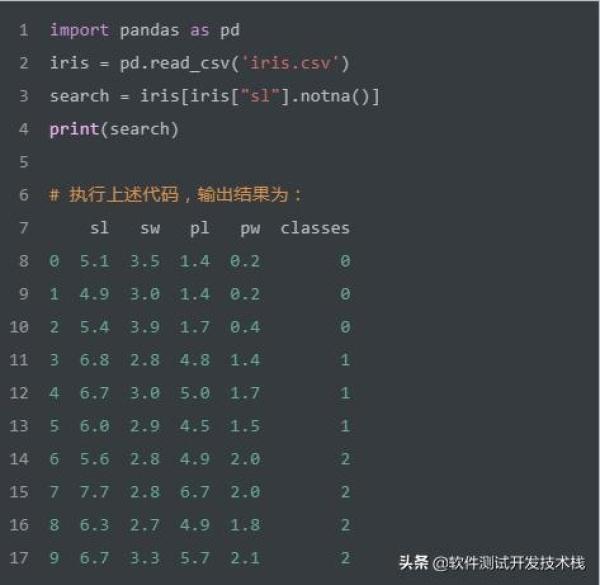
如上SQL实现查询sl字段不为 NULL 的记录。我们使用Pandas实现该SQL,代码如下:
排序 ORDER BY ASC|DESC
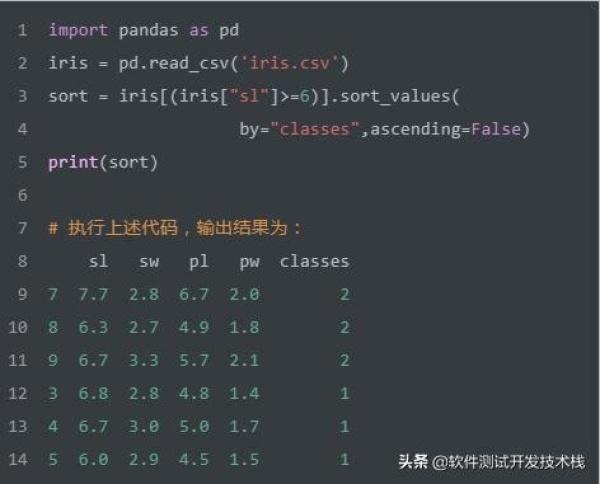
如上SQL实现将满足sl字段值大于等于5的记录,按照classes降序排序。我们使用Pandas实现该SQL,代码如下:
更新 UPDATE
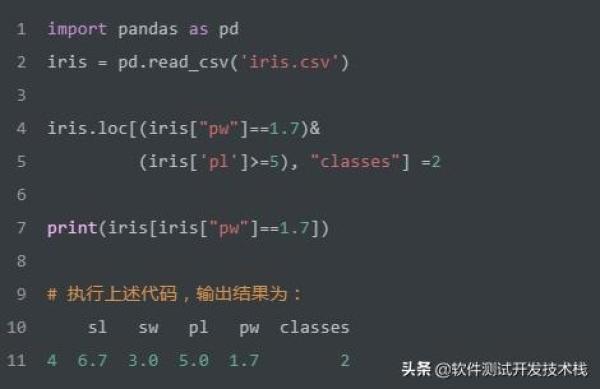
如上SQL实现将同时满足pw = 1.7 和 pl >= 5的记录中的classes字段值更新为2。我们使用Pandas实现该SQL,代码如下:
分组统计 GROUP BY
如上SQL实现 根据classes进行分组,返回classes 及每组数量。我们使用Pandas实现该SQL,代码如下:
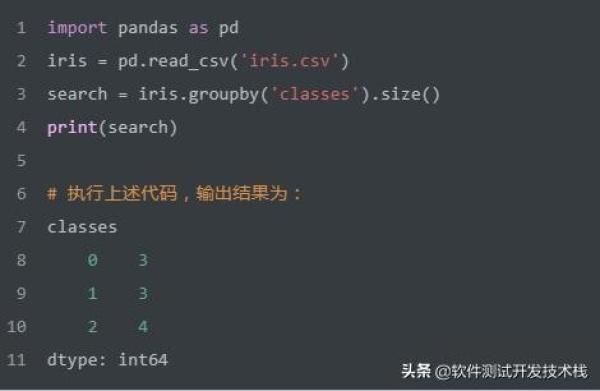
分组统计 聚合输出
如何SQL实现根据classes进行分组,返回classes值,每个分组的pl平均值以及每个分组的sl最大值。我们使用Pandas实现该SQL,代码如下:
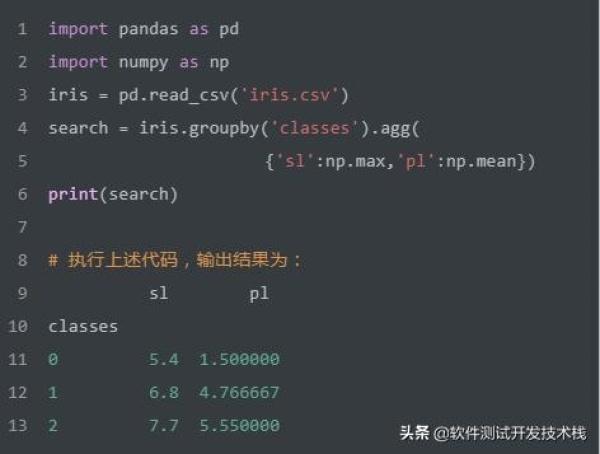
删除
如上SQL实现将同时满足pw = 1.7 和 pl >= 5的记录删除。我们使用Pandas实现该SQL,代码如下:
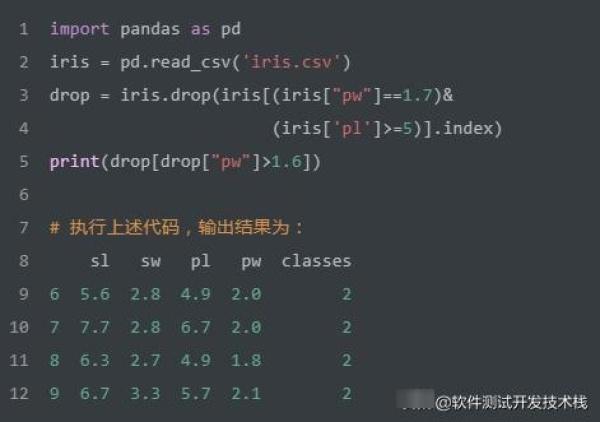
合并查询
接下来介绍如何使用Pandas进行合并查询及多表关联查询,为了演示方便,我们上面示例中的iris数据集,拆分成iris_a,iris_b两部分,如下:
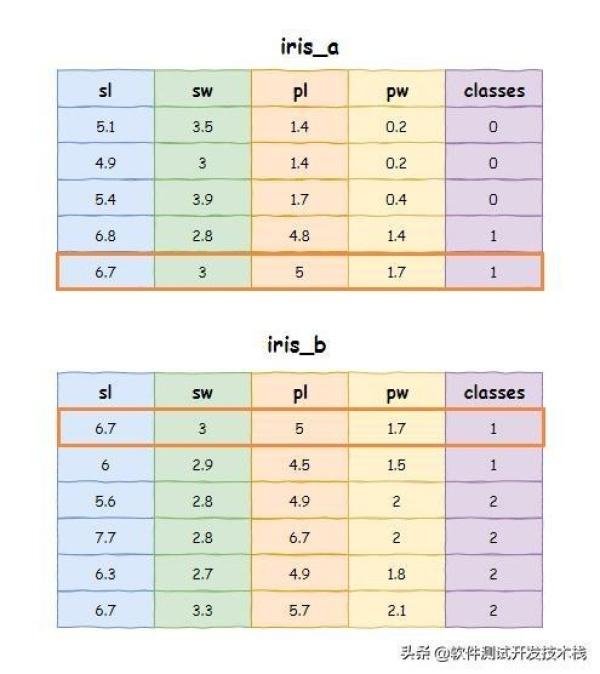
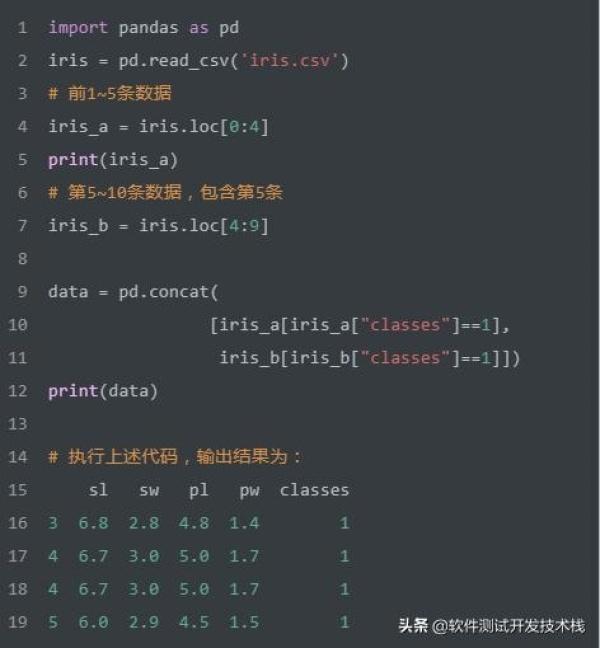
合并结果 UNION ALL 允许重复
>如上SQL实现将两个select查询结果进行合并,允许存在重复记录。我们使用Pandas实现该SQL,代码如下:
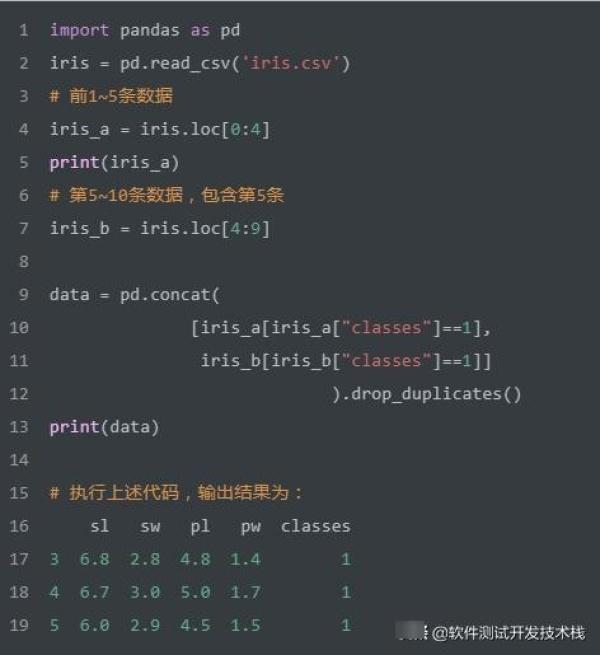
合并结果 UNION 不允许重复
>如上SQL实现将两个select查询结果进行合并,不允许存在重复记录。我们使用Pandas实现该SQL,代码如下:
仅用于笔记记录
标签:实现,如上,查询,通俗易懂,SQL,如下,Pandas From: https://www.cnblogs.com/hls91/p/17407559.html