1 索引介绍
索引是一种帮助查询语句能够快速定位到数据的一种技术。索引的存储方式有行存储索引、列存储索引和内存优化三种存储方式:
- 行存储索引,使用B+树结构,行存储指的是数据存储格式为堆、聚集索引和内存优化表的表,用于OLTP场景。行存储索引按顺序排列的值列表,每个值都有指向其所在的数据页面的指针。
- 聚集索引
- 非聚集索引
- 唯一索引
- 筛选索引
- 列存储索引,使用列结构存储,列存储指的是在逻辑上整理为包含行和列的表,实际上以列式数据格式存储的数据,用于OLAP场景。使用基于列的数据存储和查询处理。
- 聚集列存储
- 非聚集列存储
- 内存优化索引,使用Bw树存储,Bw树使用一种“旋转”技术,更适合处理处理范围查询和随机插入/删除操作,适用于各种场景下的数据存储和查询。
本文中我们讨论的索引就是行存储索引中的聚集索引和非聚集索引,不涉及其它索引。
Bw树使用一组新的旋转技术,支持更加高效的范围查询操作。而B+树则使用叶节点链表来处理范围查询。在B+树中,如果您需要范围查询,您需要遍历整个链表,这会增加查询的时间成本。相比之下,Bw树通过一些特殊的旋转操作,能够使得范围查询操作更加高效,从而显著提高查询性能。
假设需要查询数字在100到200之间的数据,那么B+树需要遍历相应的叶节点链表,而Bw树则可以使用一些特殊的旋转操作,跳过某些节点,快速定位到相应的数据范围,从而减少了查询的时间成本。
总体来说,Bw树在范围查询和随机操作等特殊情况下比B+树更加高效。但是对于其他类型的查询操作,它们的性能并没有很大的区别,具体的效果需要根据应用场景来进行具体分析。
2 行存储索引的数据组织结构
聚集索引和非聚集索引都是使用B+树结构组织的,最顶层称为根节点,中间层称为中间节点,最底层称为叶节点。在聚集索引中,叶节点包含了基础表的数据页,根节点和中间节点包含了索引行的索引页,每个索引行包含一个键值和一个指针,通过指针来找到某个叶节点的数据行。而在非聚集索引中,叶节点只包含了索引行的索引页,没有数据页,它的索引行中只有指针,通过指针来找到对应的堆表的RID或者聚集索引的数据页。
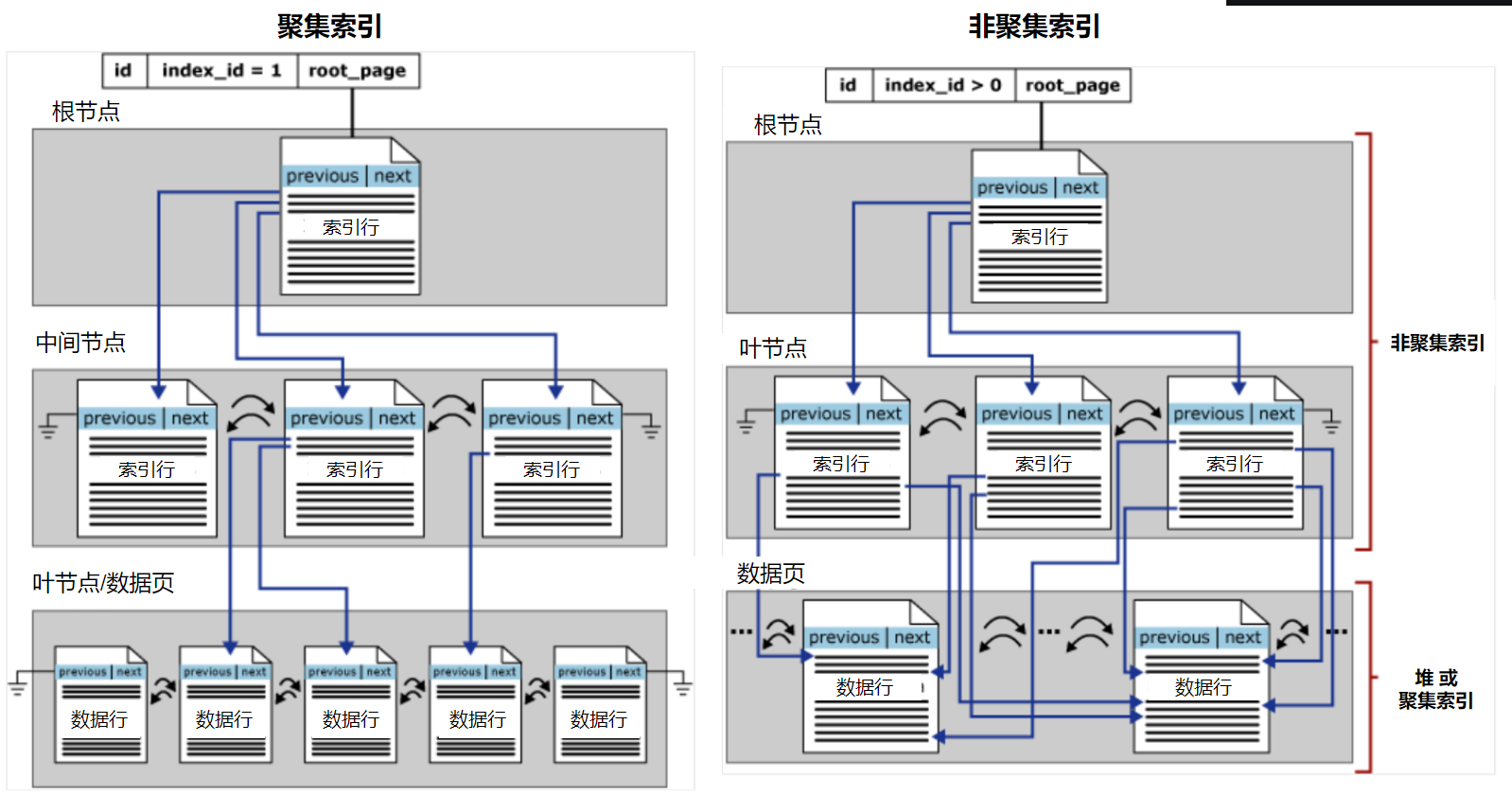
聚集索引决定了表中数据行的存储顺序(升序/降序),所以每张表只能有1个聚集索引,可以使用CREATE CLUSTERED INDEX来手动创建聚集索引,也可以是在建表时指定主键的方式来自动创建。
每张表可以有多个非聚集索引,可以针对不同的查询语句和业务场景来创建非聚集索引,只能是使用CREATE NONCLUSTERED INDEX来手动创建非聚集索引。
3 两种索引的空间占用对比
由于聚集索引的叶节点存储了是数据页,由中间节点存放了指针,而非聚集索引的叶节点存放了指针(行定位器),那通过B+树的构造,可以大概判断是非聚集索引要消耗的空间更多,因为非聚集索引要存放更多的指针信息(叶节点的数量肯定会比中间节点的数量多)。
3.1 使用sp_spaceused查看索引大小
- 查看基础表order_line,目前行数1232537行,数据大小约80MB,未创建索引。
使用exec sp_spaceused order_line命令查看。

- 在order_line表的
ol_w_id、ol_d_id、ol_o_id和ol_number列上创建聚簇索引order_line_i1_clustered
CREATE UNIQUE CLUSTERED INDEX [order_line_i1_clustered] ON [dbo].[order_line]
(
[ol_w_id] ASC,
[ol_d_id] ASC,
[ol_o_id] ASC,
[ol_number] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = OFF, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
- 查看表的索引大小,约232KB,说明聚簇索引
order_line_i1_clustered的大小为232KB-24KB=208KB。
使用exec sp_spaceused order_line命令查看。

- 在order_line表的ol_w_id、ol_d_id、ol_o_id和ol_number列上创建非聚簇索引
order_line_i1_nonclustered
CREATE UNIQUE CLUSTERED INDEX [order_line_i1_clustered] ON [dbo].[order_line]
(
[ol_w_id] ASC,
[ol_d_id] ASC,
[ol_o_id] ASC,
[ol_number] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = OFF, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
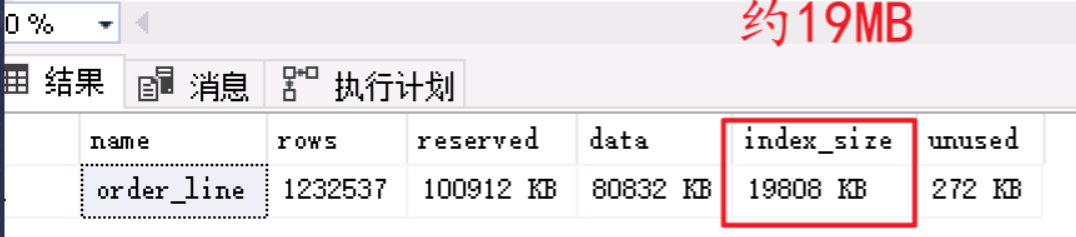
- 查看表的索引大小,约19MB,说明非聚簇索引
order_line_i1_clustered的大小为18MB~19MB。
使用exec sp_spaceused order_line命令查看。
3.2 使用DBCC查看索引大小
我们也可以通过另外一种方式来证明,通过查询索引ID,再使用dbcc ind将索引的所有页返回,然后再计算索引页的结果
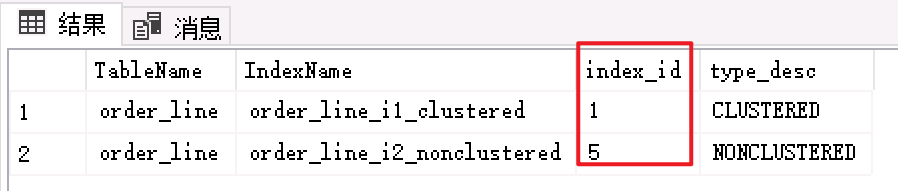
- 首先查看两个表的查询索引ID
SELECT t.name AS TableName,i.name AS IndexName,i.index_id,i.type_desc
FROM sys.dm_db_partition_stats AS s
INNER JOIN sys.indexes AS i
ON s.object_id = i.object_id
AND s.index_id = i.index_id
INNER JOIN sys.tables AS t
ON t.object_id = i.object_id
WHERE t.name='order_line'
2. 将两个索引的DBCC IND结果输出到dbcc_ind_result表中,然后计算索引的大小
CREATE TABLE dbcc_ind_result (
PageFID int,
PagePID int,
IAMFID int,
IAMPID int,
ObjectID int,
IndexID int,
PartitionNumber int,
PartitionID bigint,
iam_chain_type varchar(30),
PageType int,
IndexLevel int,
NextPageFID int,
NextPagePID int,
PrevPageFID int,
PrevPagePID int
);
GO
INSERT INTO dbcc_ind_result exec('DBCC IND(0,order_line,1)');
GO
INSERT INTO dbcc_ind_result exec('DBCC IND(0,order_line,5)');
GO
SELECT d.IndexID,i.name,COUNT(*) AS PageCount,COUNT(*)*8 AS SizeKB
FROM dbcc_ind_result d
INNER JOIN sys.indexes AS i
ON d.ObjectID = i.object_id
AND d.IndexID = i.index_id
WHERE d.PageType=2
GROUP BY d.IndexID,i.name
GO

实验证明,在相同的列上,非聚集索引比聚集索引需要更多的空间来存放指针信息(行定位器),消耗更多的空间。
4 两种索引读取数据的方式
前文提到聚集索引的叶节点存放的是数据页,而非聚集索引叶节点存放的是指针来指向数据的位置,数据的位置可以是堆(head)的RID,也可以时聚集索引的叶节点。下面创建一张测试表来验证。
4.1 未创建索引时
- 创建测试表,生产10000行测试数据
DROP TABLE IF EXISTS dbo.Test1;
CREATE TABLE dbo.Test1 (
C1 INT,
C2 INT);
WITH Nums
AS (SELECT TOP (10000)
ROW_NUMBER() OVER (ORDER BY (SELECT 1)) AS n
FROM master.sys.all_columns AS ac1
CROSS JOIN master.sys.all_columns AS ac2)
INSERT INTO dbo.Test1 (
C1,
C2)
SELECT n,
2
FROM Nums;
- 打开统计信息和执行计划功能, 从10000行中查询1行数据,例如查询C1列为1000的数据。

SET STATISTICS TIME;
SET STATISTICS IO;
SELECT t.C1,t.C2
FROM dbo.Test1 AS t
WHERE C1 = 1000;
执行后可以看到统计信息项,发生了22个逻辑读:
表 'Test1'。扫描计数 1,逻辑读取 22 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
并且执行计划中使用了全表扫描,需要读取10000行数据。

4.2 创建非聚集索引后
在C1列创建1个非聚集索引后,再观察统计信息和执行计划是否发生变化
- 创建非聚集索引
CREATE NONCLUSTERED INDEX incl ON dbo.Test1(C1);
创建非聚集索引的过程中,消耗了和前一个查询相同的资源,统计信息一样:
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Test1'。扫描计数 1,逻辑读取 22 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
2. 执行相同的查询语句,观察统计信息和执行计划
这一次统计信息发生了变化,比没有索引的情况下消耗的逻辑读更少,只发生了3个逻辑读:
表 'Test1'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
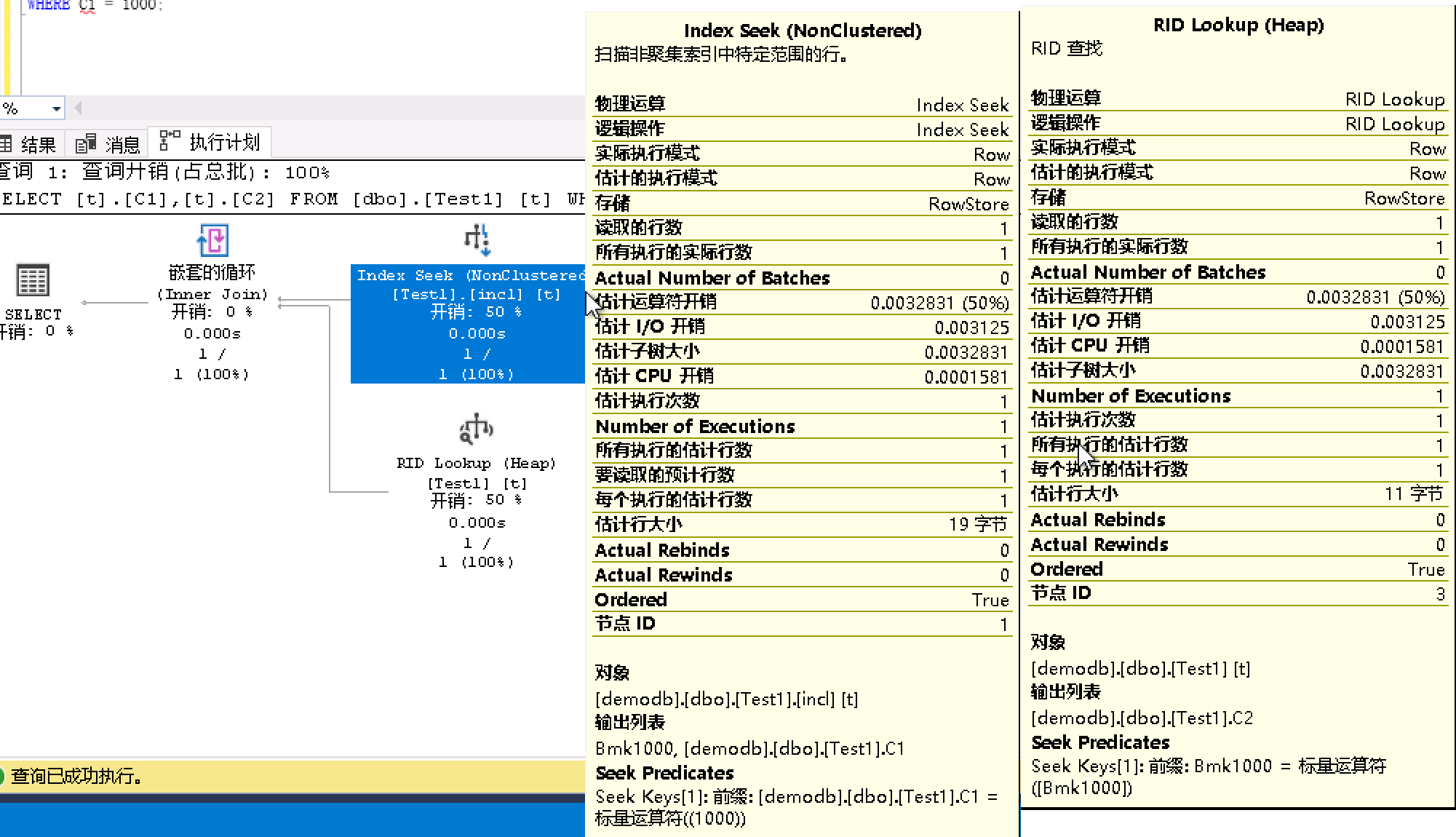
而执行计划则由Table SCAN变为了Index Seek和RID,先是扫描非聚集索引中特定范围的行,该行的指针信息为Bmk1000,再将该指针信息到堆中的RID,再返回数据,这个过程在表中只需要读取1行数据。
4.3 创建聚集索引后
在非聚集索引的基础上,我们再创建一个聚集索引,通过语句的执行计划来了解读取数据的方式。
- 创建聚集索引
CREATE CLUSTERED INDEX icl ON dbo.Test1(C1);
创建聚集索引的过程中,产生的统计信息要比非聚集要多,消耗资源也要更多:
表 'Test1'。扫描计数 1,逻辑读取 22 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Test1'。扫描计数 1,逻辑读取 24 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
再来看看执行计划,由于再4.2中创建了非聚集索引,执行计划里将创建聚集索引的操作拆成了两条语句,并且还是INSERT语句:
- 查询1:首先还是对表进行了一次全表扫描,并且按照升序的方式进行了排序后,再将数据插入到聚集索引里面。这里对应的就是逻辑读取
22次这条统计信息,完成了整个聚集索引的创建。 - 查询2:然后对整个聚集索引扫描,并将非聚集索引的指针信息更新为聚集索引的叶节点。这里对应的就是逻辑读取
24次这条统计信息,完成了整个非聚集索引的指针信息更新。

- 再次执行相同的查询语句,消耗的逻辑读比非聚集索引要少,只需要2次逻辑读
表 'Test1'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
执行计划也不再需要使用非聚集索引和堆的RID返回数据
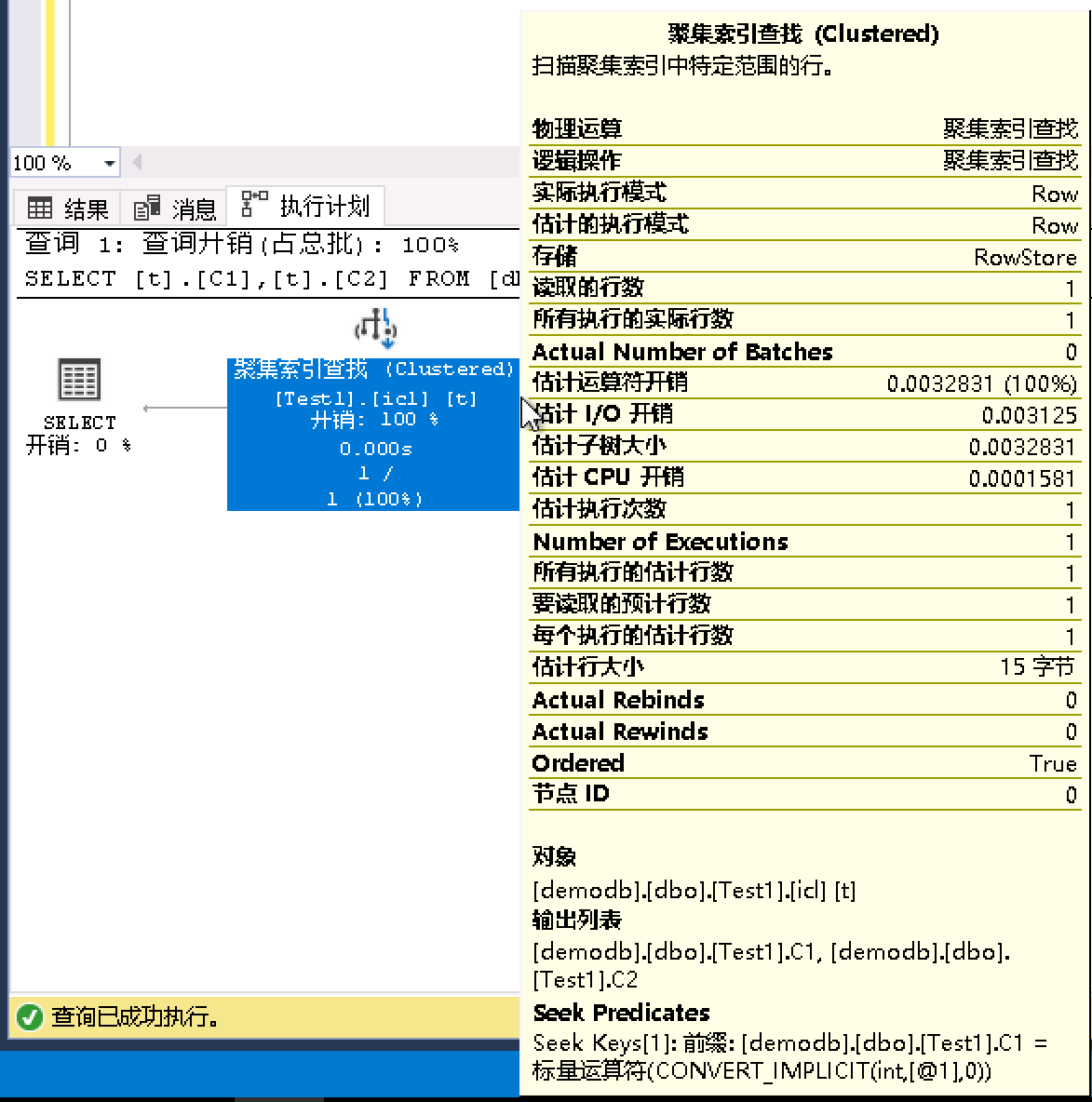
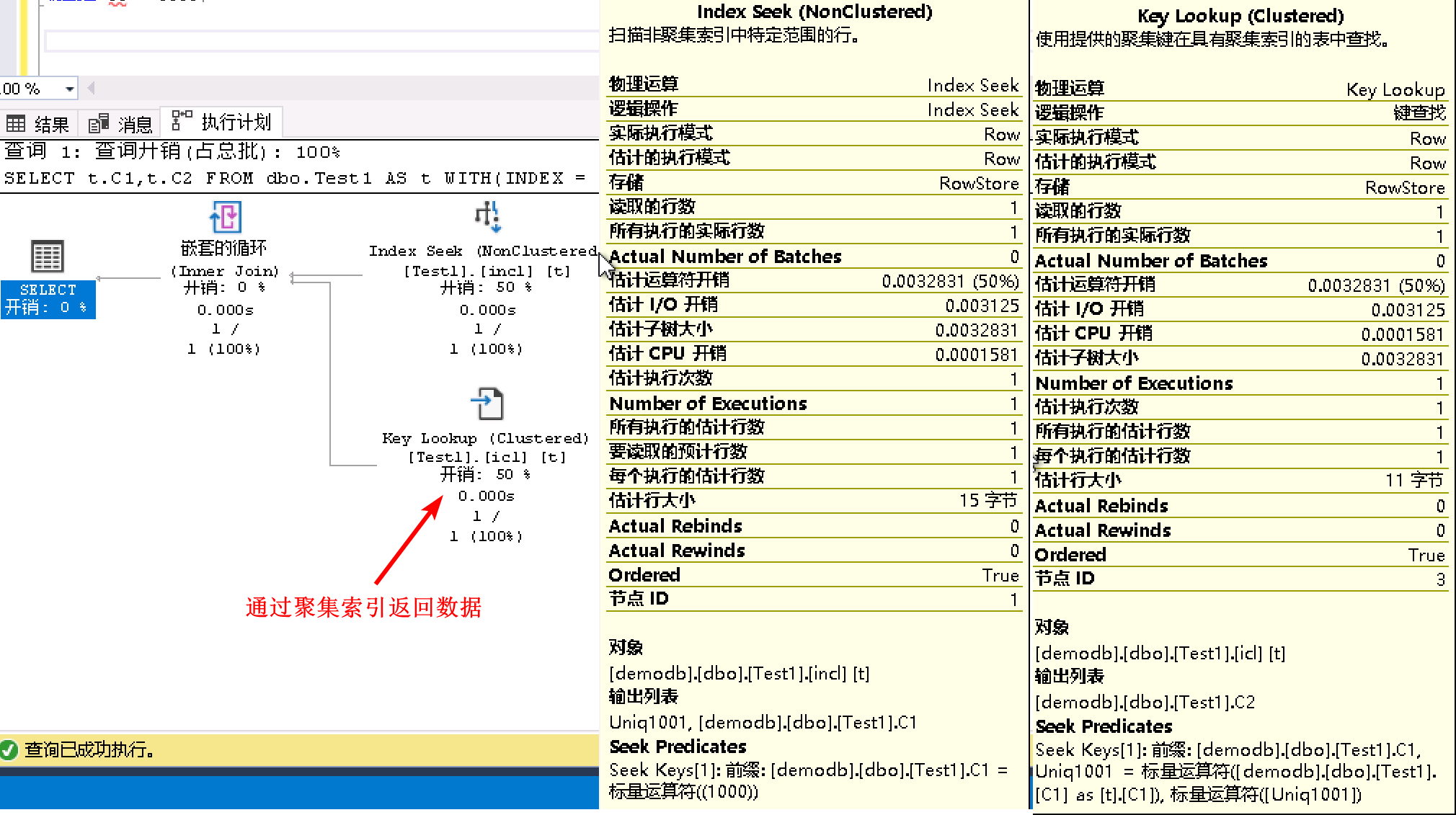
- 继续验证非聚集索引是否会通过聚集索引来返回数据,需要使用提示语法来固定语句使用非聚集索引。
SELECT t.C1,t.C2
FROM dbo.Test1 AS t WITH(INDEX = incl)
WHERE C1 = 1000;
发现这种读取数据的方式要消耗更多的逻辑读,比RID多了1次逻辑读,比聚集索引多了2次逻辑读:
表 'Test1'。扫描计数 1,逻辑读取 4 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
执行计划中先到非聚集索引查找C1=1000所在的行,然后再将输出的指针信息Uniq1001到聚集索引中执行键值查找,返回数据。
5 行存储索引的基础总结
行存储索引的聚集索引和非聚集索引在生产环境上普遍都会使用到,在本文的基础上,我们进行简单总结。
- 在数据组织结构上
聚集索引的叶节点存储的是数据页,决定了表数据的排序方式;非聚集索引的叶节点存储的是指针(行定位器),有可能是堆的RID,也有可能是聚集索引的指针。 - 在空间占用上
聚集索引只需要很小的空间来存储数据页的信息和顺序;非聚集索引需要存储数据的指针,占用空间大。 - 在读取数据的方式上
聚集索引直接通过叶节点读取数据页;非聚集索引需要通过指针找到RID或者聚集索引的指针,再通过聚集索引查找键值。 - 在逻辑读的次数上
直接读聚集索引,逻辑读最小,测试逻辑读次数为2
通过非聚集索引+RID,逻辑读居中,测试逻辑读次数为3
通过聚集索引+非聚集索引,逻辑读最大,测试逻辑读次数为4 - 在创建方式上
聚集索引:创建主键时自动使用主键列为聚集索引,没有主键时可以通过CRAETE CLUSTERED INDEX 创建,可以指定多个列;每张表只能有1个聚集索引。
非聚集索引:手动创建,通过CRAETE NONCLUSTERED INDEX 创建;每张表可以有多个非聚集索引。
本次仅对索引的基本知识进行介绍,后续再根据不同的使用场景来验证和说明。
标签:lob,存储,读取,聚集,Server,索引,SQL,id From: https://www.cnblogs.com/kernelry/p/17392438.html