表空间结构:区、段与碎片区
为什么要有区?
B+树中的每一层的页都会形成一个双向链表,双向链表之间的物理位置可能会离得非常远,当遇到范围查询的适用场景的时候,就会定位到最左边和最右边的记录,然后沿着双向链表一直扫描,而如果这其中的两个页面物理上离得特别远,就会成为随机I/O,由于磁盘和内存的速度相差了几个数量级(磁盘寻道、半圈旋转、数据传输),因此随机I/O的速度是非常慢的,所以应该尽量让链表中逻辑上相邻的页物理上也相邻,这样进行范围查询的时候就可以使用顺序I/O。
为了尽量让链表中逻辑上相邻的页物理上也相邻,因此引入区的概念,一个区就是物理上连续的64个页,即64*16=1MB。并且在数据量较大的时候,会以区为单位为索引分配空间而不是以页为基本单位,甚至数据特多多的时候,会一次性分配多个连续的区,虽然可能造成空间浪费,但是消除了很多的随机I/O,大大地提高了性能。
为什么要有段?
范围查询实际上是对叶子节点进行的顺序扫描,因此如果把叶子节点和非叶子节点都放到申请到的区的话,进行范围扫描的效果就大打折扣了,因此InnoDB对叶子结点和非叶子节点进行了区分,各自有各自的区,存放叶子节点或者非叶子节点的区就被称作是一个段(即按照功能划分),因此一个索引会产生两个段,一个是叶子节点段,一个是非叶子节点段。
常见的段有数据段、索引段和回滚段,数据段即是B+树中的叶子节点段,索引段则是非叶子节点段。
在InnoDB存储引擎中,对段的管理都是引擎自身完成的,简化了DBA对于段的管理。
段并不是物理上连续的区,而是一个逻辑的概念,由若干个零散的页面和一些完整的区组成的。
为什么要有碎片区?
默认情况下,一个使用InnoDB存储引擎的表只有一个聚簇索引,一个索引会生成两个段,而段则是以区为单位申请存储空间的,一个区占用1M,所以默认情况下一个只存储了几个记录的小表也会占用2M的存储空间,以后每添加一个索引就会再申请2M,这显然是不合理的。
因此便引入了碎片区:在一个碎片区中,并不是所有的页都是为了存储同一个段的数据而存在,而是碎片页中的页可以用于不同的目的,即一些可以用于段A、另一些可以用于段B,甚至有些页那个段都不属于。碎片区直属于表空间,并不属于任何一个段。
所以从此之后为每个段分配存储空间的策略是这样的:
- 在刚开始插入数据的时候,段是从某个碎片区以单个页面为单位来分配存储空间的
- 当某个段占用了
32个碎片区页面(即半个区)的时候,就会申请以完整的区为单位来分配存储空间
所以上面介绍区的时候才说:“段并不是物理上连续的区,而是一个逻辑的概念,由若干个零散的页面和一些完整的区组成的”
区的分类:
区大致可以分为4类:
- 空闲区:没有用过区中的任何页面
- 有剩余空间的碎片区:
- 没有有剩余空间的碎片区:
- 附属于某个段的区:即索引的叶子节点区和非叶子节点区

表空间
表空间可以看做是InnoDB存储引擎逻辑结构的最高级,所有的数据都存放在表空间里面。
表空间是一个逻辑容器,表空间的存储对象是段,在一个表空间中可以有一个或多个段,但是每一个段只能属于一个表空间,表空间数据库由一个或者多个段组成,表空间从管理上可以分为:系统表空间、独立表空间、撤销表空间和临时表空间。
独立表空间
-
即每一张表都有一个独立的表空间,也就是数据和索引都存放在自己的表空间中。独立的表空间(即单表)可以在不同的数据库之间迁移。
-
独立表空间的空间可以回收(DROP TABLE可以,其他情况则不能自动回收)。对于统计分析或者是日志表,删除大量数据之后可以通过:
ALTER TABLE TableName engine=innodb;回收不用的空间。 -
独立表空间的空间结构由段、区、页组成。
-
真实表空间对应的文件大小:在数据目录中,一个新建表的ibd文件在5.0中占用了96K(6个页),在8.0中则占用了112K(7页,一页存储的是表结构)。
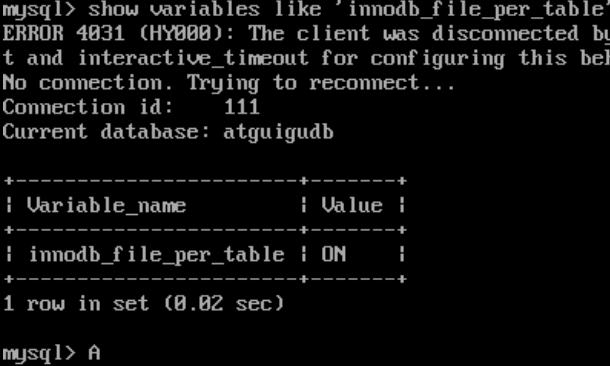
查看InnoDB的表空间类型:
show variables like 'innodb_file_per_table'
开启意味着每一张表都会单独保存为一个ibd文件。
系统表空间
系统表空间和独立表空间类似,只不过整个MySQL进程只有一个系统表空间,在系统表空间中会额外存储一些有关整个系统信息的页面,这部分是独立表空间中没有的。
InnoDB数据字典
这个内部系统表,就是数据字典,系统内部表不允许用户直接访问,但是提供了information_schema数据库中以innodb_sys开头的表以供参考,存储引起启动的时候,会首先读取这些以sys开头的系统表,然后填充到这些以InnoDB_sys开头的表中