1 前言
SQL中分组查询分为 GROUP BY 分组和 COMPUTE BY 分组两种。
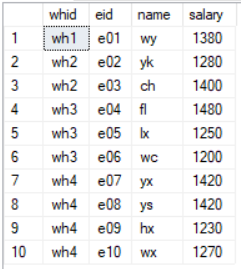
笔者以案例的形式分别讲解两种查询方式。在SQL Server数据库上建立staff表,以eid为主键,表数据如下:
2 GROUP BY 分组
select whid,count(*) as count,avg(salary) as avg
from staff
where salary>1250
group by whid
having count(*)>=2
order by whid desc
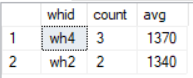
说明:
- GROUP BY 中的分组依据和SELECT 中的分组标识是相对应的;
- HAVING 子句限定分组条件,总是跟在GROUP BY 子句之后,不可以单独使用。
3 COMPUTE BY分组
select *
from staff
where salary>1250
order by whid desc
compute count(whid),avg(salary) by whid
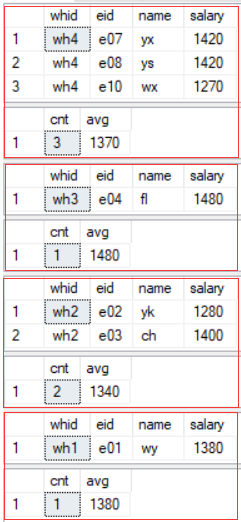
说明:
- COMPUTE ... BY...必须结合 ORDER BY 排序语句;
- 一般 BY 子句指定的列必须和 ORDER BY 子句指定的列顺序相同,但BY子句的列数可以少于 ORDER BY 子句的列数。
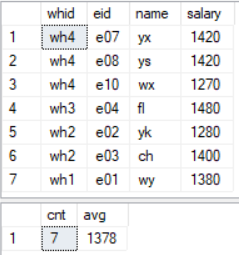
若去掉 BY 子句则是对全局的汇总,如下:
select *
from staff
where salary>1250
order by whid desc
compute count(whid),avg(salary)
注意:MySQL中没有 COMPUTE 语句。
声明:本文转自SQL分组查询
标签:salary,count,whid,SQL,查询,分组,子句 From: https://www.cnblogs.com/zhyan8/p/17232608.html