当你在MySQL高并发情况下的进行性能调优时,需要知道调整后的影响。例如查询是否变快了?锁是否会减慢运行速度?内存使用情况如何?磁盘IO等待时间变了吗?
.
Performance Schema就有一个 存储回答上述问题所需数据的数据库 。本篇文章将帮你了解Performance
Schema的工作原理、局限性,以及如何更好地使用它和sys Schema来搞清楚MySQL内部的运行细节。
目录
- 1. Performance Schema介绍
-
* 1.1 插桩元件- 1.2 消费者表的分类
- 1.3 资源消耗
- 1.4 局限性
- 1.5 sys Schema
- 1.6 理解线程
- 2 Performance Schema - 配置
-
* 2.1 启用与禁用-Performance Schema- 2.2 启用与禁用-插桩
- 2.3 启用与禁用-消费者表
- 2.4 优化特定对象的监控
- 2.5 优化线程的监控
- 2.6 调整Performance Schema的内存大小
- 2.7 默认值
- 3 Performance Schema - 使用
-
* 3.1 检查SQL语句-
* 常规SQL语句- 预处理语句
- 存储过程
- 语句剖析
- 3.2 检查读写性能
- 3.3 检查元数据锁
- 3.4 检查内存使用情况
-
* 直接使用performance schema- 使用sys schema
- 3.5 检查变量
- 3.6 检查最常见的错误
- 3.7 检查Performance Schema自身
- 小结
-
1. Performance Schema介绍
介绍Performance Schema的工作机制前,先解释两个概念:
- 程序插桩(instrument): 指在MySQL代码中插入探测代码,以获取我们想了解的信息(也就是生产数据的代码,即所需数据的提供者、生产者)。就像一般的的链路监控框架,如 Google的Dapper 就是通过在代码中插入探测代码的方式获取信息。 (一般Java链路监控框架是通过代理的方式修改字节码文件, 在代码中间插入获取信息的代码。)
- 消费者表(consumer): 指的是存储关于程序插桩代码信息的表。如果我们为查询模块添加插桩,相应的消费者表将记录如 执行总数、未使用索引次数、耗时 等信息。如图MySQL存在名为performance_schema的 内置数据库 ,里面有各种数据表存储了有关 MySQL内部运行的操作上的底层指标 。
 在这里插入图片描述
在这里插入图片描述
Performance Schema的一般功能如下图所示
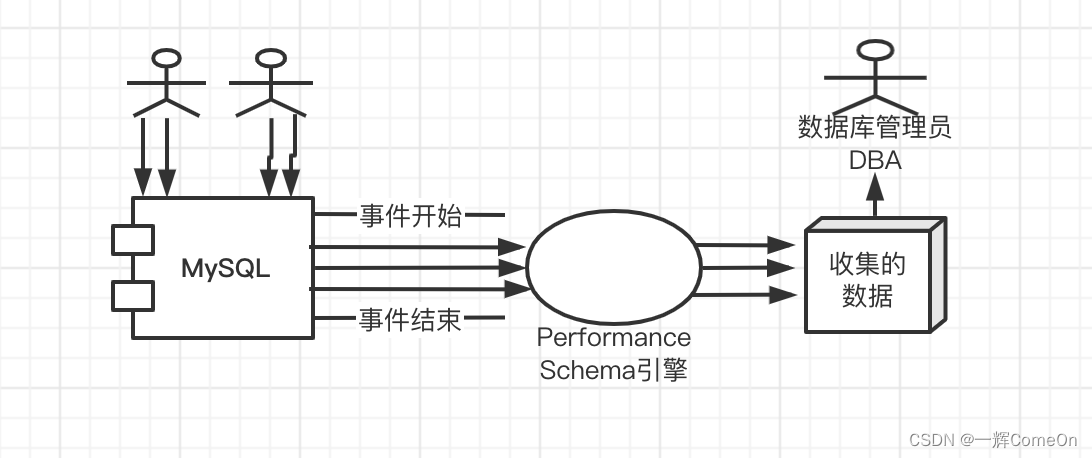
当应用程序用户连接到MySQL并执行被测量的插桩指令时,performance_schema将每个检查的调用封装到两个宏中,然后将结果记录在相应的消费者表中。这里的要点是,
启用插桩会调用额外的代码,这意味着插桩会消耗CPU资源
1.1 插桩元件
在这里插桩元件可以理解为收集信息的组件(也就是 数据生产者
),是插入的“桩”与“桩的底座”的组合元件,每一个组件都代表着一些代码(收集信息