RabbitMQ
一、什么是消息队列
消息指的是两个应用间传递的数据。数据的类型有很多种形式,可能只包含文本字符串,也可能包含嵌入对象。
“消息队列(Message Queue)”是在消息的传输过程中保存消息的容器。在消息队列中,通常有生产者和消费者两个角色。生产者只负责发送数据到消息队列,谁从消息队列中取出数据处理,他不管。消费者只负责从消息队列中取出数据处理,他不管这是谁发送的数据。

二、为什么使用消息队列
主要有三个作用:
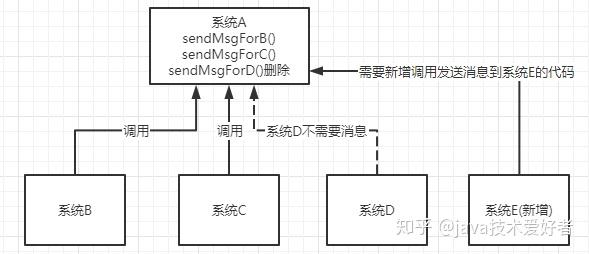
- 解耦。如图所示。假设有系统B、C、D都需要系统A的数据,于是系统A调用三个方法发送数据到B、C、D。这时,系统D不需要了,那就需要在系统A把相关的代码删掉。假设这时有个新的系统E需要数据,这时系统A又要增加调用系统E的代码。为了降低这种强耦合,就可以使用MQ,系统A只需要把数据发送到MQ,其他系统如果需要数据,则从MQ中获取即可。
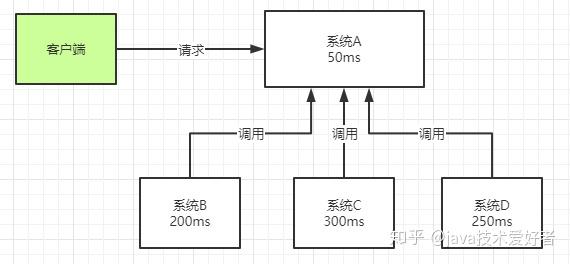
- 异步。如图所示。一个客户端请求发送进来,系统A会调用系统B、C、D三个系统,同步请求的话,响应时间就是系统A、B、C、D的总和,也就是800ms。如果使用MQ,系统A发送数据到MQ,然后就可以返回响应给客户端,不需要再等待系统B、C、D的响应,可以大大地提高性能。对于一些非必要的业务,比如发送短信,发送邮件等等,就可以采用MQ。
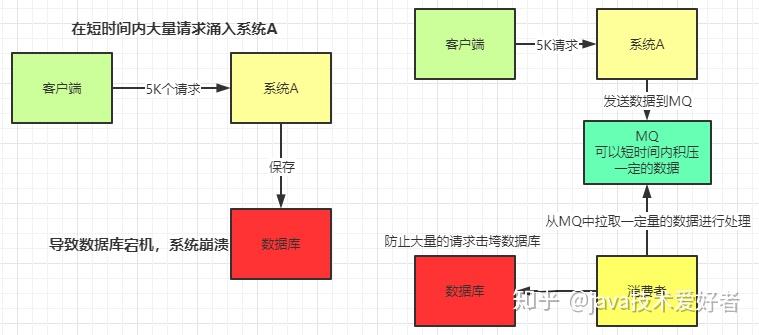
- 削峰。如图所示。这其实是MQ一个很重要的应用。假设系统A在某一段时间请求数暴增,有5000个请求发送过来,系统A这时就会发送5000条SQL进入MySQL进行执行,MySQL对于如此庞大的请求当然处理不过来,MySQL就会崩溃,导致系统瘫痪。如果使用MQ,系统A不再是直接发送SQL到数据库,而是把数据发送到MQ,MQ短时间积压数据是可以接受的,然后由消费者每次拉取2000条进行处理,防止在请求峰值时期大量的请求直接发送到MySQL导致系统崩溃。
三、RabbitMQ的特点
RabbitMQ是一款使用Erlang语言开发的,实现AMQP(高级消息队列协议)的开源消息中间件。首先要知道一些RabbitMQ的特点,官网可查:
- 可靠性。支持持久化,传输确认,发布确认等保证了MQ的可靠性。
- 灵活的分发消息策略。这应该是RabbitMQ的一大特点。在消息进入MQ前由Exchange(交换机)进行路由消息。分发消息策略有:简单模式、工作队列模式、发布订阅模式、路由模式、通配符模式。
- 支持集群。多台RabbitMQ服务器可以组成一个集群,形成一个逻辑Broker。
- 多种协议。RabbitMQ支持多种消息队列协议,比如 STOMP、MQTT 等等。
- 支持多种语言客户端。RabbitMQ几乎支持所有常用编程语言,包括 Java、.NET、Ruby 等等。
- 可视化管理界面。RabbitMQ提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker。
- 插件机制。RabbitMQ提供了许多插件,可以通过插件进行扩展,也可以编写自己的插件。
压力测试
ApiFox
采用ApiFox接口管理工具进行压力测试
pprof介绍
Go语言内置了获取程序运行数据的工具,包括以下两个标准库:runtime/pprof: 采集工具型应用运行数据进行分析 net/http/pprof: 采集服务型应用运行时数据进行分析
pprof开启后,每隔一段时间(10ms)就会收集当前的堆栈信息,获取各个函数占用的CPU以及内存资源,然后通过对这些采样数据进行分析,形成一个性能分析报告。
性能优化主要有一下几个方面:
CPU Profile:报告程序的CPU使用情况,按照一定频率去采集应用程序在CPU和寄存器上面的数据。
Memory Profile(Heap Profile):报告程序的内存使用情况。
Block Profiling: 报告goroutines不在运行状态的情况,可以用来分析和查找死锁等性能瓶颈。
Goroutine Profiling: 报告goroutines的使用情况,有哪些roroutines,它们的调用关系是怎样的。
go tool pprof http://127.0.0.1:8081/debug/pprof/profile
远程服务器的三个用途
VSFTP 远程文件上传服务
vsftpd是“very secure TTP daemon”的缩写,是一个完全免费的、开放源代码的ftp服务器软件. vsftpd是一款在Linux发行版中最受推崇的ftp服务器程序,小巧轻快,安全易用,支持虚拟用户,支持带宽限制等功能
ffmpeg 提供截图服务
Nginx 静态资源服务
https://blog.csdn.net/kingroc/article/details/50839994
利用nginx搭建视频点播, 直播服务器
Nginx服务的配置
# 已经配置好图片服务器,视频服务器
#user www www;
worker_processes auto;
#error_log /www/wwwlogs/nginx_error.log crit;
pid /www/server/nginx/logs/nginx.pid;
worker_rlimit_nofile 51200;
server
{
listen 80;
# server_name video;
index index.html;
root /home/ftpuser/video;
error_page 404 /404.html;
#include enable-php.conf;
location / {
root html;
index index.html index.htm;
}
#http://43.138.25.60/1.mp4 ##定位到了mp4视频的位置
location ~ .*\.mp4$ {
mp4;
}
#http://43.138.25.60/images/a.jpg
location /images{
root /home/ftpuser; ## 定位到了images图片文件夹的位置
}
access_log /www/wwwlogs/access.log;
}
Redis和Mysql相互关联的问题(如何解决数据一致性的问题)
-
为了提高响应速度,使用协程进行数据库的更新操作,对于由此引发的数据库请求响应数量过大可能导致数据库异常的问题,使用消息队列
rabbitMQ将数据库需要响应的大量请求做缓冲处理。 -
由于用户在客户端刷视频过程中,服务端需要提前加载当前视频的评论数量,而评论数量的获取速度会直接影响视频的刷新或播放速度,直观影响用户刷视频的体验。因此计划将评论id值存入缓存,当需要获取评论数量时,直接从缓存中获取评论数量返回客户端。考虑到一个视频有多个评论,Redis使用key-set数据结构存储视频id-评论id。在使用的过程中,只有在首次加载Redis内容的时候会从数据库读取评论数量,其他情况下,都是直接在缓存中读取评论数量,大大地提高了评论数量获取的性能。
-
此函数用于给一个评论赋值:评论信息+用户信息 填充 注意加锁的使用
-
得到集合后,
协程调用获取视频点赞数量方法,将每个视频点赞数据存进预先开辟的切片空间,等协程运行完后,进行遍历累加,提高了响应速度。 -
采用协程并发将对应videoId的点赞数添加到集合中去
-
遍历videoIdList,添加进key的集合中,若失败,删除key,并返回错误信息,这么做的原因是防止脏读,保证redis与mysql数据一致性
-
如果加载过缓存中的信息key:strUserId,则加入value:videoId;
如果redis LikeUserId 添加失败,数据库操作成功,会有脏数据,所以 只有redis操作成功才执行数据库likes表操作 -
如果数据库操作失败了,redis是正确数据,客户端显示的是点赞成功,不会影响后续结果 -
只有当该用户取消所有点赞视频的时候redis才会重新加载数据库信息,这时候因为取消赞了必然和数据库信息一致 同样这条信息消费成功与否也不重要,因为redis是正确信息,理由如上