更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群
文 / DataWind 团队封声
在使用 BI 工具的时候,经常遇到的问题是:“不会 SQL 怎么生产加工数据、不会算法可不可以做挖掘分析?”而专业算法团队在做数据挖掘时,数据分析及可视化也会呈现相对割裂的现象。流程化完成算法建模和数据分析工作,也是一个提效的好办法。
同时,对于专业数仓团队来说,相同主题的数据内容面临“重复建设,使用和管理时相对分散”的问题——究竟有没有办法在一个任务里同时生产,同主题不同内容的数据集?生产的数据集可不可以作为输入重新参与数据建设?
DataWind 可视化建模能力来了
由火山引擎推出的 BI 平台 DataWind 智能数据洞察,推出了全新进阶功能——可视化建模。
用户可通过可视化拖、拉、连线操作,将复杂的数据加工建模过程简化成清晰易懂的画布流程,各类用户按照所想即所得的思路完成数据生产加工,从而降低数据生产获取的门槛。
画布中支持同时构建多组画布流程,一图实现多数据建模任务的构建,提高数据建设的效率,降低任务管理成本;另外,画布中集成封装了超过 40 种数据清洗、特征工程算子,覆盖初阶到高阶的数据生产能力,无需 Coding 完成复杂的数据能力。
零门槛的 SQL 工具
数据的生产加工是获取及分析数据的第一步。
对于非技术使用者来说,SQL 语法存在一定使用门槛,同时本地文件无法定时更新,导致看板每次都需要手动重做。获取数据所需的技术人力往往需要排期,数据的获取时效及满足度大大打折,因此使用零代码的数据建设工具变得尤为重要。
下方列举两个典型场景,零门槛完成数据处理在工作中是如何应用的。
【场景 1】所想即所得,可视化完成数据处理过程
在产品运营迭代急需不同数据的及时输入反馈时,可以抽象数据的处理过程,通过可视化建模拖拉算子构建数据处理过程。
如要获取按照日期、城市粒度的订单数及订单金额,并获取每日 Top10 消耗金额数据的城市数据,操作如下:
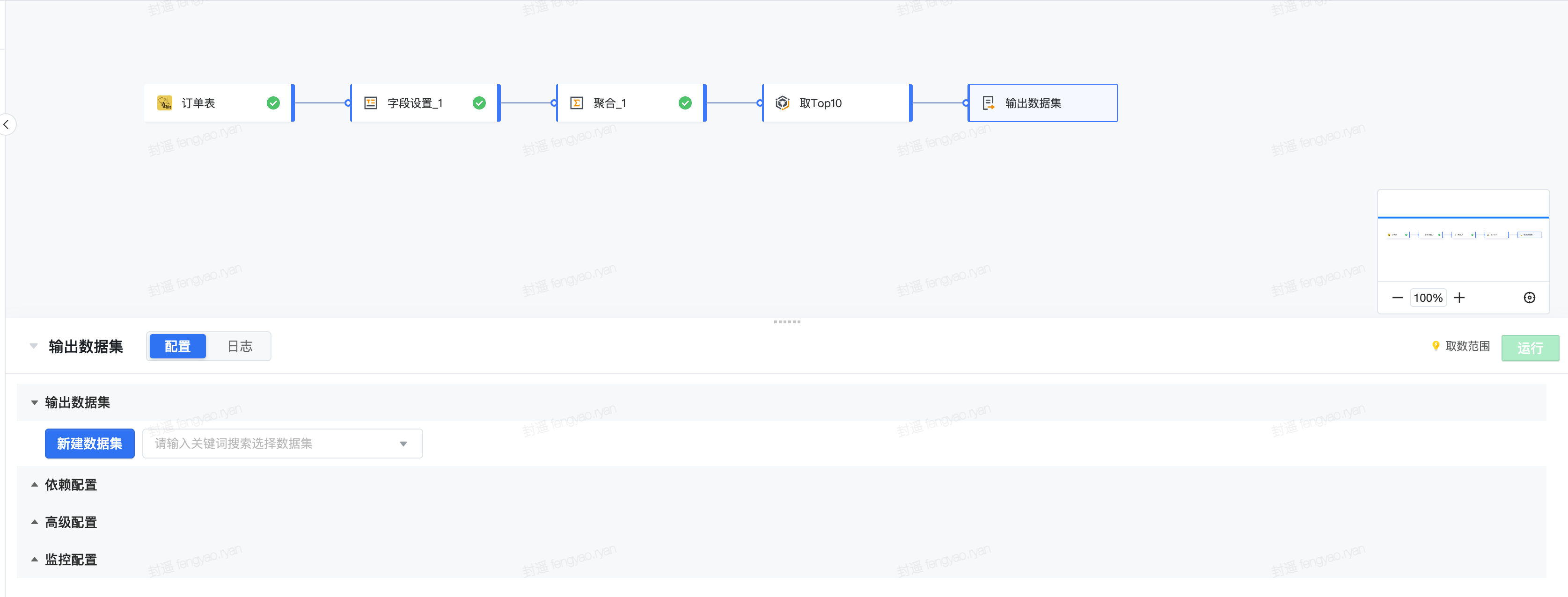
【场景 2】多表快速结合,轻松解决多数据关联计算
在数据处理过程中,有多个数据源需要进行组合使用,常规通过 Excel 需要掌握高阶 Vlookup 等算法有些难度,且耗时长。同时数据量较大时,电脑性能可能没办法完成数据的组合计算。
如有两份数据量比较大的订单数据和一份客户属性信息表,需要根据账单金额和成本金额计算利润金额,然后按照利润贡献高低取 Top100 的用户订单信息。

AI 数据挖掘,不再高不可及
当基础的数据清洗已经没办法满足数据建设和数据分析,需要 AI 算法加持去挖掘数据更多隐藏的价值时。算法团队同学可能苦于无法很好与可视化图表联动使用,没办法生产好的数据快速被应用;而普通用户可能直接被 AI 代码的高门槛直接压灭了这个算法的苗头——提需求又怕需求太浅、价值无法很好评估输出,此时算法挖掘成为了一种奢望。
DataWind 的可视化建模封装了超过 30 类常见的 AI 算子能力,用户仅需了解算法的作用可以通过配置化的方式配置算法算子的输入和训练目标即可完成模型训练,根据配置的其他数据内容快速得到预测结果。
特征工程算子(13)
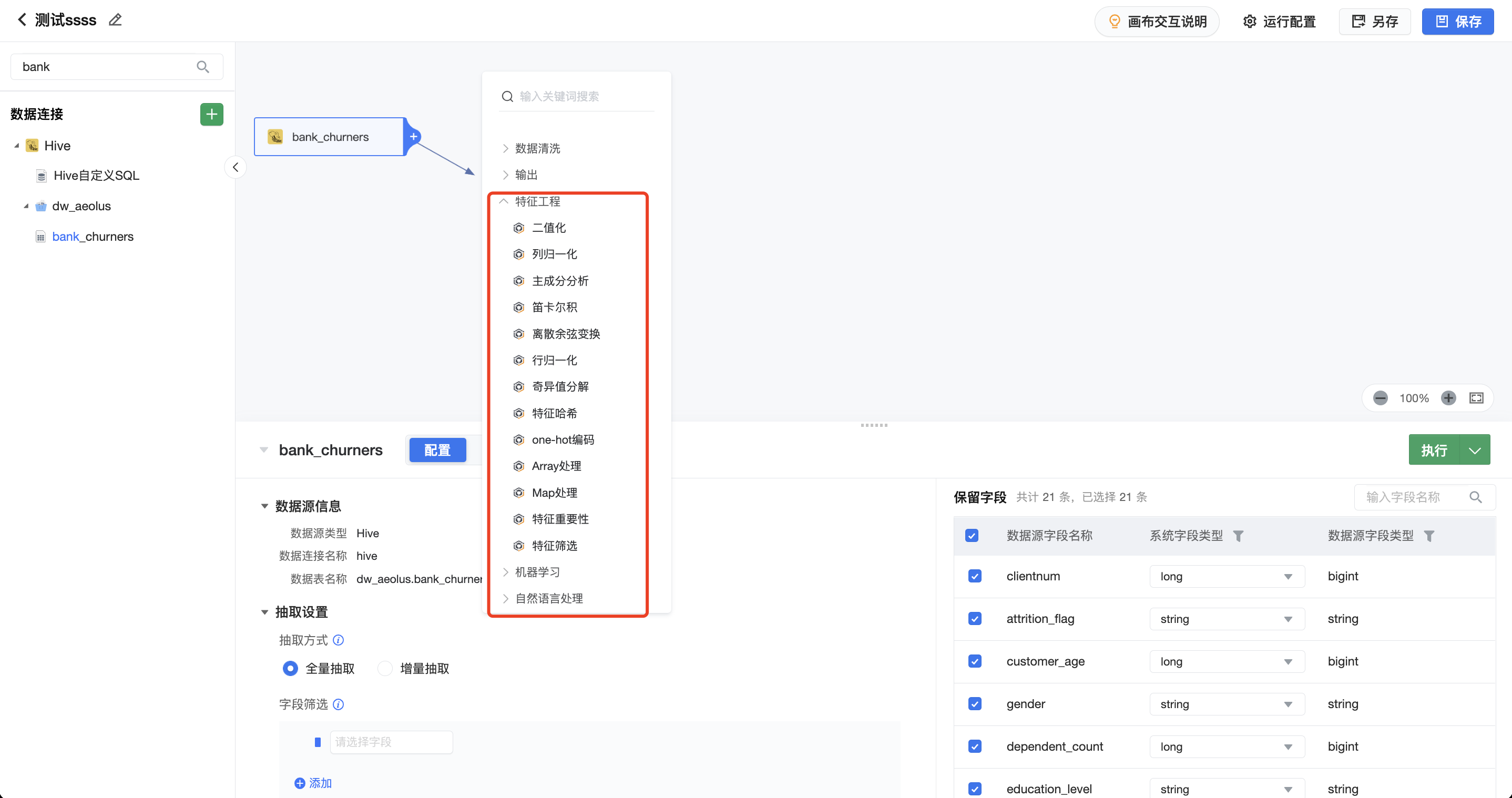
机器学习算子(22)

自然语言处理算子 (3)

AI 算子参数配置

AI 模型训练效果

下方将以两个典型场景为例,看不写 Python 如何完成数据挖掘。
【初阶】不会 Python 也可做数据挖掘
用户日常工作基本不涉及写 Python,但存在做数据挖掘的需求场景。他需要基于存量高意向客户样本做客户意向度挖掘。此时可通过可视化建模构建数据挖掘流程:
-
拖入样本数据和全部数据作为数据输入
-
拖入分类算法,如 XGB 算法用于模型训练
-
拖入预测算子,搭建模型与全部数据的关系进行预测
-
实际数据和预测结果结合输出数据集,从而分析全部用户数据的意向分布

【高阶】不写 Python 也可构建复杂算法模型
用户需要根据现有数据,构建一个用户回购模型。在模型搭建中需要经过数据清洗、格式转换之后采用梯度提升树构建预测模型,此时可以根据可视化建模构建回购模型流程: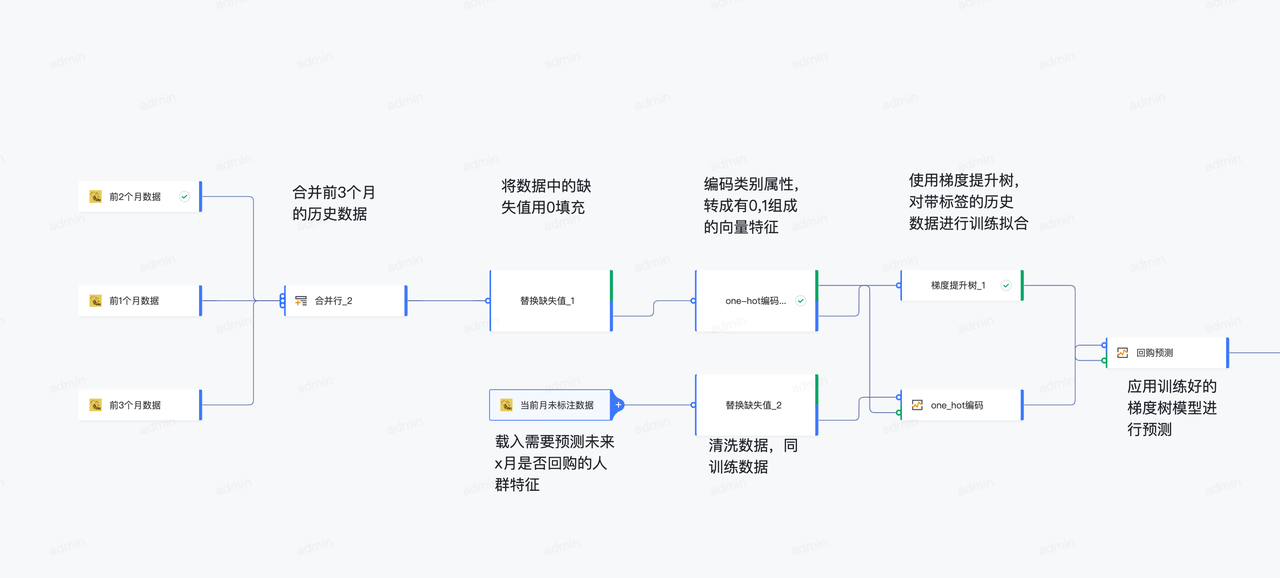
-
合并行:将 n 个算子(图中的长方形)输出数据表根据一致的表头合并成一张总的数据表,用户销售数据没有增删新属性时此处不用改动。
-
缺失值替换:属性列存在空值(null)时,会影响后续模型计算,使用替换缺失值算子可以将空值替换为指定默认值,用户销售数据没有增删新属性时此处不用改动。
-
one-hot 编码: 文本类型的属性无法直接被模型训练使用,需要 one_hot 编码成数字向量例如:


-
梯度提升树:负责拟合训练数据,输出一个可以用于预测的模型(图中没有标注的参数不需要维护人员修改):

-
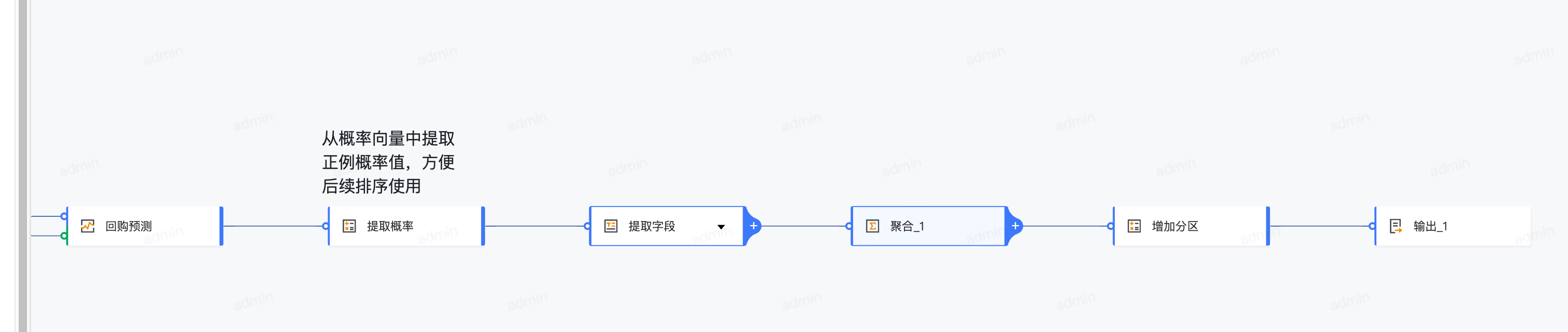
聚合_1:去除预测数据中的重复项,取最大概率。
-
提取字段:提取必要的 label 和概率值输出。
多场景、多任务建设,管理不再分散
作为数据分析师,日常也会有很多构建数据集、搭建数据看板的工作。但通常从数仓获取的底表会是一张宽表,在此基础之上,根据不同的场景需求搭建不同的数据集任务。
在后续的使用时,常常会遇到类似的的数据集越来越多,但具体逻辑又无法很好的对比确认。此时,如果所有数据集逻辑在一个数据集里面配置生成,每个数据集通过任务流程就可以判断和定义应用就好了。
针对这一场景,DataWind 的可视化建模能力也可以很好的完成。可视化建模功能支持单一数据集同时被多种逻辑处理加工生成多个数据集。以处理订单数据和用户数据为例:
-
有用户想看订单的统计数据,那么可以搭建订单统计数据集的数据处理流程;
-
有用户就想看明细数据,但是需要对明细字段进行加工清洗,这时可以构建订单明细表数据集的处理流程;
-
有些用户又想结合用户属性去统计用户的订单分布,那么构建多表关联结合指标聚合生成完成用户订单统计数据集;
-
同样逻辑可以生成多表关联下的用户订单明细数据集。
由此,通过一个任务、两个数据输入完成了 4 个数据集的生成,4 个数据集可以构建一个数据主题域,后续相关数据使用均可从此任务输出的数据集进行使用。

关于我们
火山引擎智能数据洞察 DataWind
火山引擎智能数据洞察 DataWind 是一款支持大数据明细级别自助分析的增强型 ABI 平台。从数据接入、数据整合,到查询、分析,最终以数据门户、数字大屏、管理驾驶舱的可视化形态呈现给业务用户,让数据发挥价值。
标签:AI,算子,用户,建模,算法,可视化,SQL,数据挖掘,数据 From: https://www.cnblogs.com/bytedata/p/17007823.html