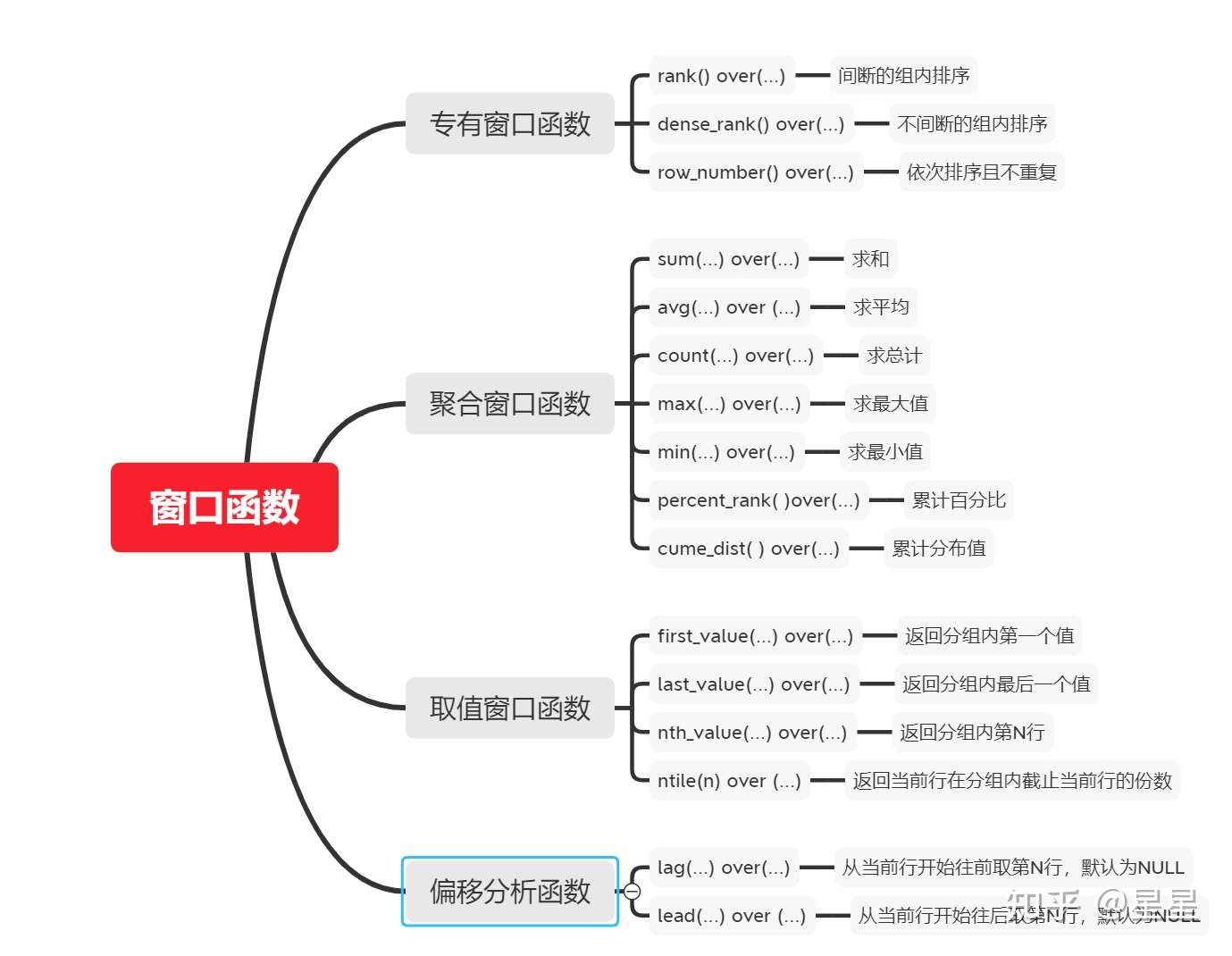
一、窗口函数基本点
(一)定义
窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集 合上执行的特殊函数。对于每条记录都要在此窗口内执行函数,窗口大小都是固定的,这种属于静态窗口;不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
(二)基本用法
函数名([expr]) over(partition by <要分列的组> order by <要排序的列> rows between <数据范围>)
sum(...A...) over(partition by ...B... order by ...C... rows between ...D1... and ...D2...)
avg(...A...) over(partition by ...B... order by ...C... rows between ...D1... and ...D2...)
A: 需要被加工的字段名称 B: 分组的字段名称 C: 排序的字段名称 D: 计算的行数范围
窗口从句的说明
rows between 2 preceding and current row # 取当前行和前面两行
rows between unbounded preceding and current row # 包括本行和之前所有的行
rows between current row and unbounded following # 包括本行和之后所有的行
rows between 3 preceding and current row # 包括本行和前面三行
rows between 3 preceding and 1 following # 从前面三行和下面一行,总共五行
# 当缺少窗口从句条件,窗口规范默认是rows between unbounded preceding and current row.
# 当order by和窗口从句都缺失, 窗口规范默认是 rows between unbounded preceding and unbounded following(三)分类
二、窗口函数需求实现
数据说明
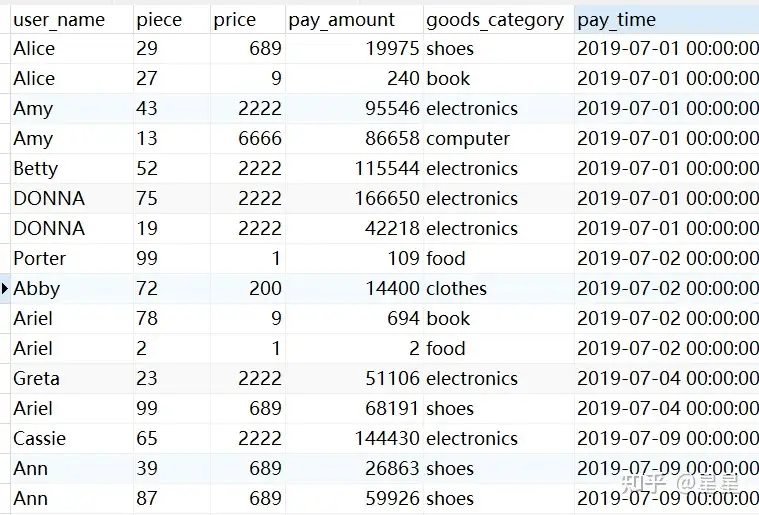 数据表格部分明细
数据表格部分明细
(一)累计计算函数:sum(...) avg(...) max(...) min(...)
1、累计求和:sum(...) over(...)
(1)累计求和-1年数据求和:需求- 查询出2019年每月的支付总额和当年累积支付总额
SELECT
a.MONTH,
sum_pay,
sum( a.sum_pay ) over ( ORDER BY a.MONTH) #ORDER BY MONTH
FROM
( SELECT MONTH ( pay_time ) MONTH, sum( pay_amount ) sum_pay FROM trade_data
WHERE YEAR ( pay_time ) = 2019 GROUP BY MONTH) a
#子查询的聚合函数重命名
#group by分组:统计每个月支付总额
# 当缺少窗口从句条件,窗口规范默认是rows between unbounded preceding and current row.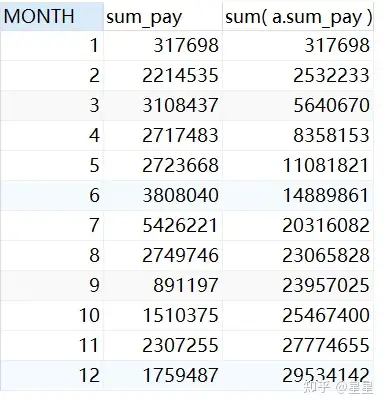
(2)累计求和-多年数据求和:需求-查询出2018-2019年每月的支付总额和当年累积支付总额
SELECT
a.YEAR,
a.MONTH,
pay_amount,
sum( a.pay_amount ) over ( PARTITION BY a.YEAR ORDER BY a.MONTH )
FROM
(
SELECT YEAR
( pay_time ) YEAR,
MONTH ( pay_time ) MONTH,
sum( pay_amount ) pay_amount
FROM
trade_data
WHERE
YEAR ( pay_time ) = 2018
OR YEAR ( pay_time ) = 2019
GROUP BY
YEAR,
MONTH
) a
#where里不能用别名,group by里可用别名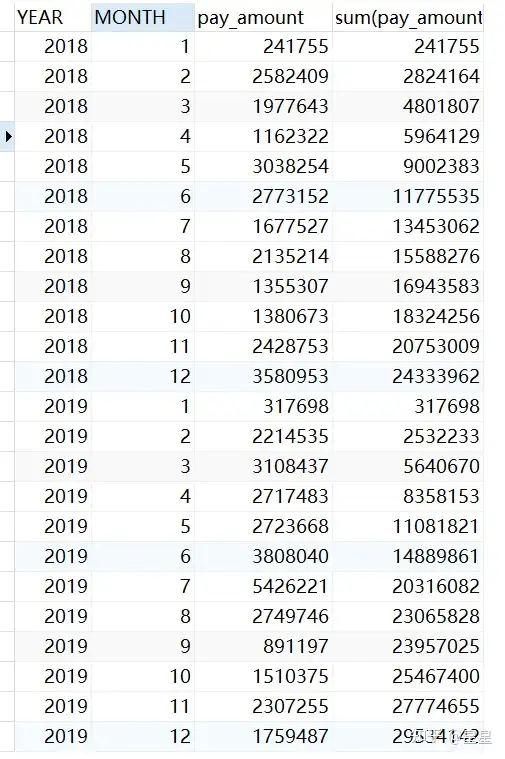
2、移动平均:avg(...) over(...)
需求:查询出2019年每个月的近三月移动平均支付金额
SELECT
a.MONTH,
a.pay_amount,
avg( pay_amount ) over ( ORDER BY a.MONTH rows BETWEEN 2 preceding AND current ROW )
FROM
(
SELECT YEAR
( pay_time ) YEAR,
MONTH ( pay_time ) MONTH,
sum( pay_amount ) pay_amount
FROM
trade_data
WHERE
YEAR ( pay_time ) = 2019
GROUP BY
MONTH
) a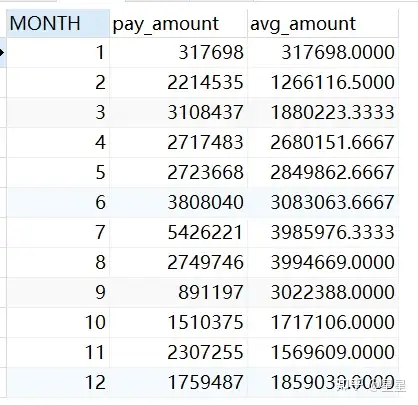
3、最大最小值:min(...) over / max(...)over()
需求:查询出每四个月的最大月总支付金额
SELECT
a.MONTH,
a.pay_amount,
max( a.pay_amount ) over ( ORDER BY a.MONTH rows BETWEEN 3 preceding AND current ROW ) max_amount
FROM
( SELECT substr( pay_time, 1, 7 ) MONTH, sum( pay_amount ) pay_amount FROM trade_data GROUP BY MONTH ) a
#substr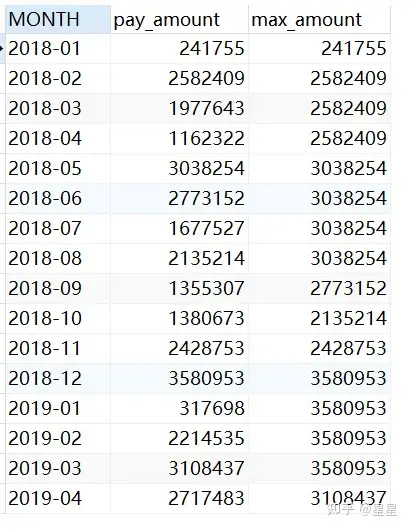
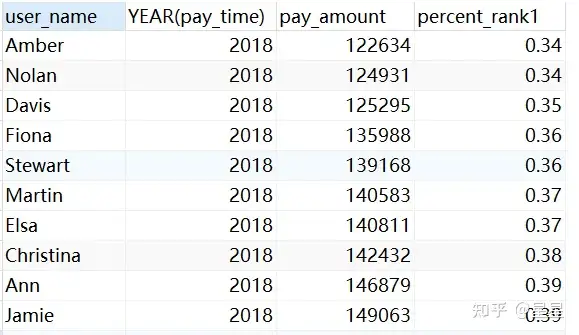
4、percent_rank( )over(...)累计百分比
计算分区或结果集中行的百分位数排名
需求:查询年份交易额的累计百分比,按照交易额升序排序
SELECT
user_name,
YEAR ( pay_time ),
sum( pay_amount ) pay_amount,
round( percent_rank ( ) over ( PARTITION BY YEAR ( pay_time ) ORDER BY sum( pay_amount ) ), 2 ) percent_rank1
FROM
trade_data
GROUP BY
user_name
需求:30%的累计和
SELECT
a.time1,
a.percent_rank1,
a.pay_amount,
sum( a.pay_amount ) over ( rows BETWEEN unbounded preceding AND current ROW ) AS sum_sum
FROM
(
SELECT
SUBSTR( pay_time, 1, 7 ) time1,
sum( pay_amount ) pay_amount,
round( percent_rank ( ) over ( ORDER BY sum( pay_amount ) ), 2 ) percent_rank1
FROM
trade_data
GROUP BY
time1
) a
WHERE
percent_rank1 = 0.3
#注意:percent_rank1 的数值需要在数据结果表中有,不是特别灵活
5、cume_dist( ) over(...)累计分布值
CUME_DIST()是一个窗口函数,它返回一组值中值的累积分布。它表示值小于或等于行的值除以总行数的行数。
需求:查询2018年的累计分布值,按照交易额降序排序
SELECT
substr( pay_time, 1, 7 ) MONTH,
sum( pay_amount ) sum_amount,
row_number ( ) over ( ORDER BY sum( pay_amount ) ) rk,
round( cume_dist ( ) over ( ORDER BY sum( pay_amount ) ), 2 ) cume_dis
FROM
trade_data
WHERE
YEAR ( pay_time ) = '2018'
GROUP BY
MONTH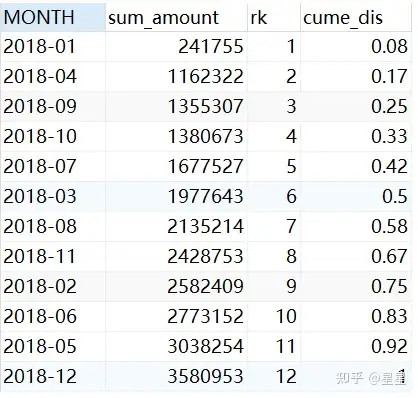
(二)排序:row_number() over (...) rank() over(...) dense_rank() over(...) ntile(n)over(...)
row_number() over (...) rank() over(...) dense_rank() over(...)
row_number() over(partition by ...A... order by ...B... )
rank() over(partition by ...A... order by ...B... )
dense_rank() over(partition by ...A... order by ...B... )
A:分组的字段名称 B:排序的字段名称
注意:row_number()、rank() 和dense_rank()紧邻的括号内是不加任何字段名称的
row_number:它会为查询出来的每一行记录生成一个序号,依次排序且不会重复
dense_rank函数在生成序号时是连续的
rank函数生成的序号有可能不连续
需求:2020年1月,购买商品品类数的用户排名
select
user_name,
count( DISTINCT goods_category ) count_sum,
row_number ( ) over ( ORDER BY count( DISTINCT goods_category ) ) rn1,
dense_rank ( ) over ( ORDER BY count( DISTINCT goods_category ) ) rn2,
rank ( ) over ( ORDER BY count( DISTINCT goods_category ) ) rn3
FROM
trade_data
WHERE
SUBSTR( pay_time, 1, 7 ) = "2020-01"
GROUP BY
user_name
#count(Distinct XX)
#Substr日期加上引号;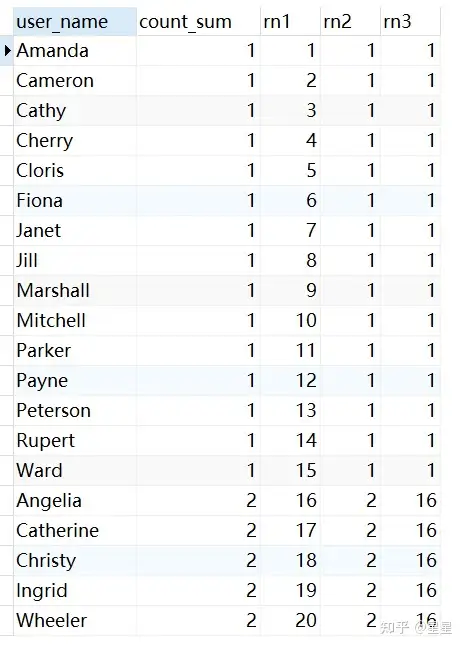
(三)取值函数
ntile(n) over (...) ;first_value(...) ;last_value(...) over(...);nth_value(XX,n)
1、ntile(n) over (...)
ntile(n) over(partition by ..A..order by..B..) n:切分的片数 A:分组的字段名称 B:排序的字段名称
ntile(n),用于将分组数据按照顺序切分成n片,返回当前切片值
NTILE不支持ROWS BETWEEN
需求:查询出将2020年2月的支付用户,按照支付金额分成5组后的结果
SELECT
a.user_name,
a.sum,
ntile ( 5 ) over ( ORDER BY a.sum DESC ) Level
FROM
(
SELECT
user_name,
sum( pay_amount ) sum
FROM
trade_data
WHERE
SUBSTR( pay_time, 1, 7 ) = "2020-02"
GROUP BY
user_name
ORDER BY
sum
) a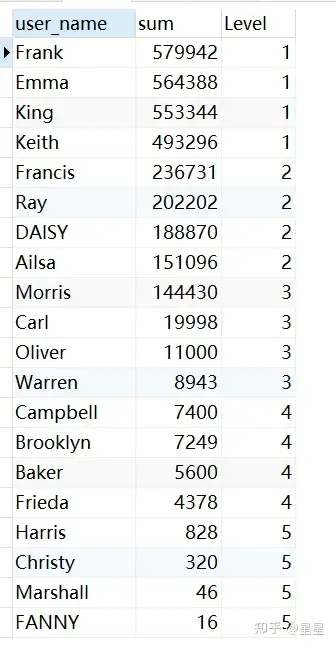
需求:查询出2020年支付金额排名前30%的所有用户
SELECT
b.user_name,
b.sum,
b.LEVEL
FROM
(
SELECT
a.user_name,
a.sum,
ntile ( 10 ) over ( ORDER BY a.sum DESC ) LEVEL
FROM
( SELECT user_name, sum( pay_amount ) sum FROM trade_data
WHERE YEAR ( pay_time ) = "2020" GROUP BY user_name ORDER BY sum ) a
) b
WHERE
b.LEVEL IN ( 1, 2, 3 )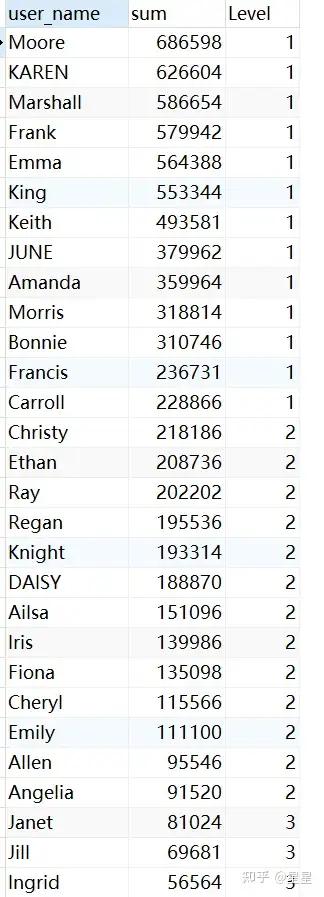
2、first_value(...) over(...)返回分组内第1个数值
需求:查询每年支付金额最少的客户
SELECT
user_name,
YEAR ( pay_time ),
sum( pay_amount ) sum_amount,
first_value ( user_name ) over ( PARTITION BY YEAR ( pay_time ) ORDER BY sum( pay_amount ) ) Fvalue
FROM
trade_data
GROUP BY
user_name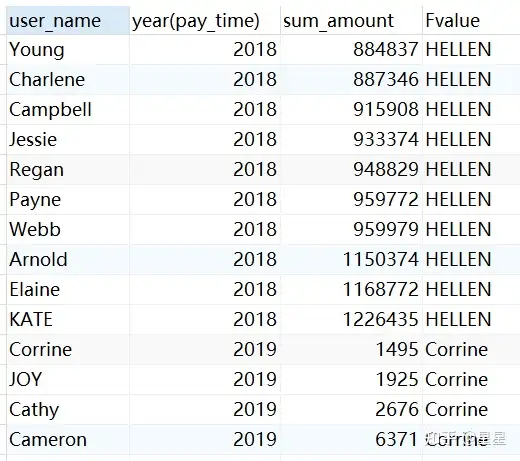
3、last_value(...) over(...)返回分组内最后1个数值
需求:查询每年支付金额最多的客户
SELECT
user_name,
YEAR ( pay_time ),
sum( pay_amount ) sum_amount,
last_value ( user_name ) over ( PARTITION BY YEAR ( pay_time ) ORDER BY sum( pay_amount ) RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) lvalue
FROM
trade_data
GROUP BY
user_name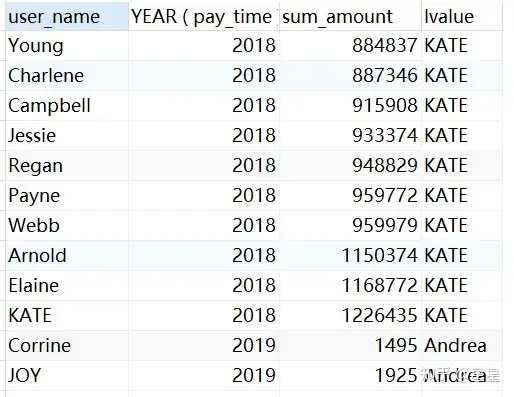
4、nth_value(XX,n) over(...)返回分组内第N行
需求:查询每年支付金额第2多的客户
SELECT
user_name,
YEAR ( pay_time ),
sum( pay_amount ) sum_amount,
nth_value ( user_name, 2 ) over ( PARTITION BY YEAR ( pay_time ) ORDER BY sum( pay_amount ) RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING ) lvalue
FROM
trade_data
GROUP BY
user_name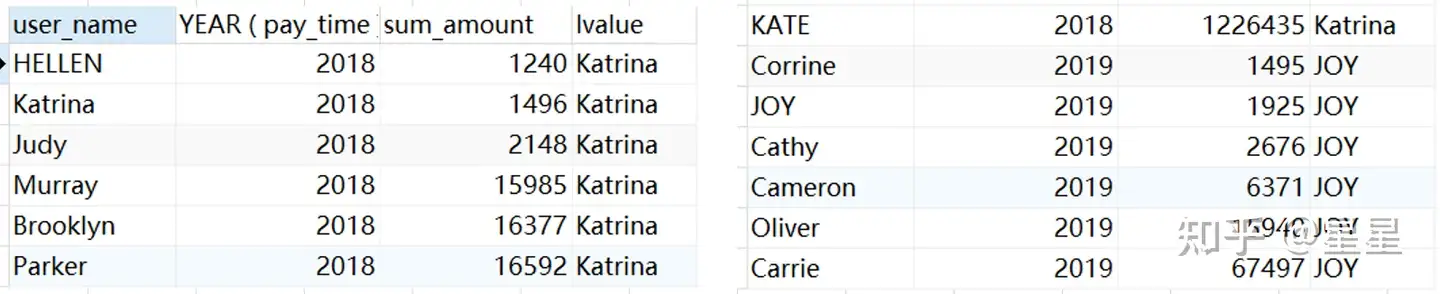
(四)偏移分析函数:lag(...) over(...) lead(...)over(...)
Lag和Lead函数可以在同一次查询中取出同一字段的前N行的数据(Lag)和后N行的数据(Lead) 作为独立的列
在实际应用当中,若要用到取今天和昨天的某字段差值时,Lag和Lead函数的应用就显得尤为重要: lag(exp_str,offset,defval) over(partion by ......order by ......)
lead(exp_str,offset,defval) over(partion by ......order by ......)
需求: 查询出King和West的时间偏移(前N行)
SELECT
user_name,
date( pay_time ),
lag ( date( pay_time ), 1, date( pay_time ) ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) lag1,
lag ( date( pay_time ) ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) lag1,
lag ( date( pay_time ), 2, date( pay_time ) ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) lag2,
lag ( date( pay_time ), 2 ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) lag2
FROM
trade_data
WHERE
user_name IN ( "King", "West" );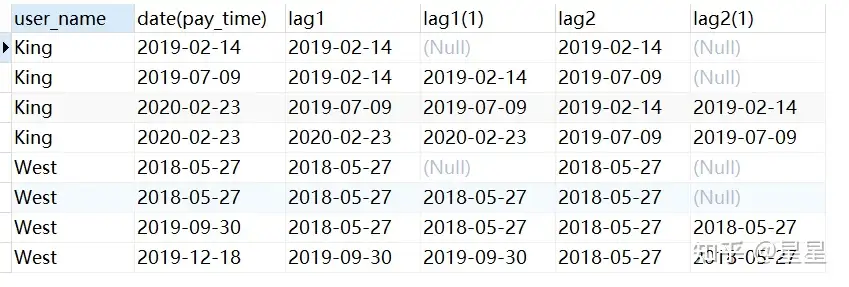
需求: King和West的时间偏移(后N行)
SELECT
user_name,
date( pay_time ),
lead ( date( pay_time ), 1, date( pay_time ) ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) lead1,
lead ( date( pay_time ) ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) lead1,
lead ( date( pay_time ), 2, date( pay_time ) ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) lead2,
lead ( date( pay_time ), 2 ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) lead2
FROM
trade_data
WHERE
user_name IN ( "King", "West" );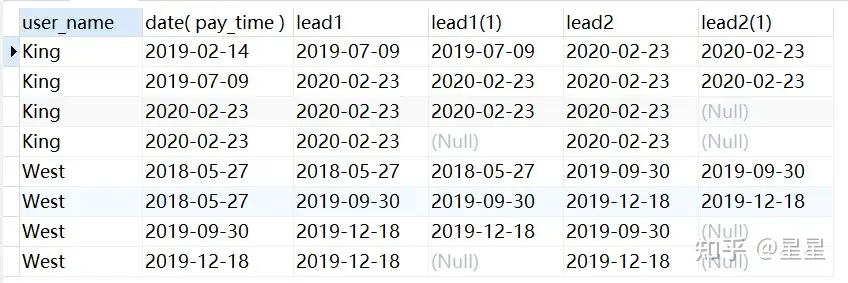
需求:查询出支付时间间隔超过100天的用户数
SELECT
count( DISTINCT a.user_name )
FROM
(
SELECT
user_name,
date( pay_time ) time1,
lag ( date( pay_time ), 1, date( pay_time ) ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) time2
FROM
trade_data
) a
WHERE
a.time2 IS NOT NULL
AND DATEDIFF( a.time1, a.time2 ) > 100;运行结果:180
需求:日期按照用户倒序排序
SELECT
user_name,
date( pay_time ) time1,
lag ( date( pay_time ), 1, date( pay_time ) ) over ( PARTITION BY user_name ORDER BY date( pay_time ) desc) time2
FROM
trade_data
#Time1与time2同时倒序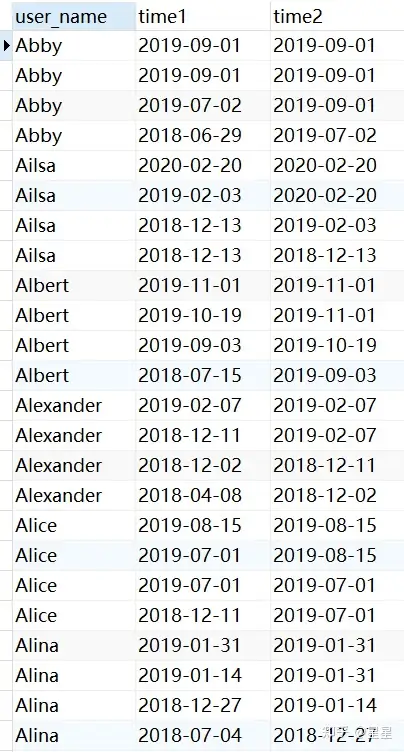
需求:查询出每年支付时间间隔最长的用户
第1步:把时间偏移
SELECT
user_name,
date( pay_time ) t1,
lead ( date( pay_time ), 1 ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) t2
FROM
trade_data
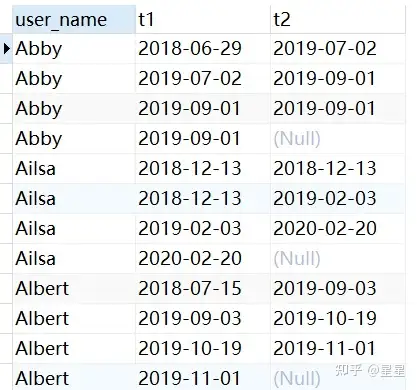
第2步:时间差
SELECT
count( DISTINCT user_name )
FROM
(
SELECT
user_name,
date( pay_time ) t1,
lead ( date( pay_time ), 1 ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) t2
FROM
trade_data
) a
WHERE
DATEDIFF( t2, t1 ) > 100
and t2 is not null需求:查询出每年支付时间间隔最长的用户
select year(b.pay_time),b.user_name,b.GAP
from
(
SELECT
a.pay_time,year(a.pay_time),a.user_name,
DATEDIFF( t2, t1 ) GAP,
rank() over (PARTITION by year(a.pay_time) order by DATEDIFF( t2, t1 ) desc) as rn
FROM
(
SELECT
user_name,pay_time,
date( pay_time ) t1,
lead ( date( pay_time ), 1 ) over ( PARTITION BY user_name ORDER BY date( pay_time ) ) t2
FROM
trade_data
) a
where a.t2 is not null
)b
where rn=1
#XX is not null
#where 不用同一个层级语句的别名
#order根据partition by的字段内部分组与排序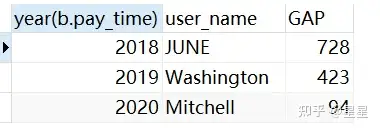
三、窗口函数多样化
(一)与case when 结合使用
(二)与随机函数rand结合使用
转载自:https://zhuanlan.zhihu.com/p/509380543
标签:...,窗口,name,pay,over,MySQL,详情,time,user From: https://www.cnblogs.com/zhuozige/p/16953037.html