目录
1 集群
1.1 简介
MongoDB 有三种集群部署模式,分别为主从复制(Master-Slaver)、副本集(Replica Set)和分⽚(Sharding)模式。
- 副本集:
Replica Set
⾼可⽤(主要⽬标):当⼀个结点故障时⾃动切换到其他结点
数据冗余(主要⽬标):数据复制到n个结点上,增加数据安全性,同时为⾼可⽤提供基础
功能隔离(次要⽬标):使⽤不同的结点隔离某些有特殊需求的功能,⽐如使⽤⼀个结点进⾏OLAP运算(⼤规模资源占⽤),使⽤⼀个结
点在远程做灾备(性能要求不如本地⾼),读写分离等等; - 分片:
Sharded Cluster
⽔平扩展:当⼀台服务器满⾜不了需求的时候,我们可以选择垂直扩展(增加服务器硬件),它虽然简单,但很容易达到极限,并且⾯临成本⾼等明显缺点。成本更低的⽅式是使⽤n台服务器组成集群来满⾜系统需求。这就是分⽚集的主要设计⽬标
缩短响应时间:因为可以把数据分散到多台服务器上,⾃然每台服务器的处理压⼒减⼩,处理时间就会缩短
这⾥会出现⼀个问题:假设每台服务器出故障的机率是p,那么n台服务器有⼀台出现故障的机率就是p * n,如果不做⾼可⽤设计,集群出现故障的概率就与机器数量成正⽐,这在⼯程上是不能接受的。
幸运的是我们已经有了解决⾼可⽤的⽅案,也就是复制集。所以MongoDB的分⽚集群要求每⼀个⽚都是复制集(当然测试环境也可以使⽤单结点,⽣产环境不推荐 - 主从:
Master-Slaver
⽬前已经不推荐使⽤
主从复制模式的集群中只能有⼀个主节点,主节点提供所有的增、删、查、改服务,从节点不提供任何服务,但是可以通过设置使从节点提供查询服务,这样可以减少主节点的压⼒。
另外,每个从节点要知道主节点的地址,主节点记录在其上的所有操作,从节点定期轮询主节点获取这些操作,然后对⾃⼰的数据副本执⾏这些操作,从⽽保证从节点的数据与主节点⼀致。
在主从复制的集群中,当主节点出现故障时,只能⼈⼯介⼊,指定新的主节点,从节点不会⾃动升级为主节点。同时,在这段时间内,该集群架构只能处于只读状态。
1.2 复制集
1.2.1 简介
副本集是一组保持着相同数据集合的mongod实例,其中1个mongod为primary,接收全部写操作其余secodary只负责读操作
primary instance打开oplog,secendary读取oplog,并产生相同的数据集
replicattion set多台服务器维护相同的数据副本,提高服务器的可用性
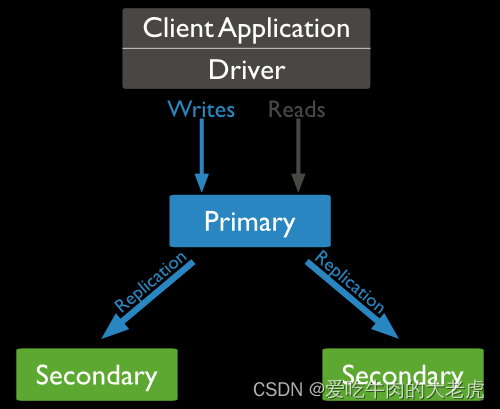
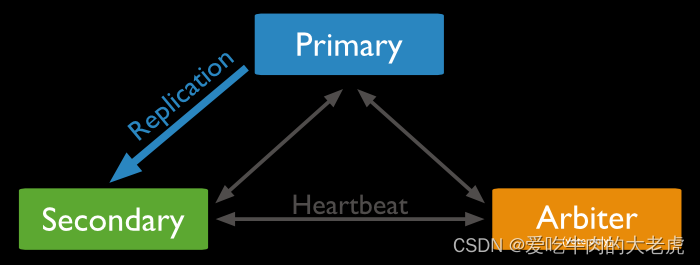
副本集中仲裁关系
1.2.2 复制集设置
1.2.2.1 创建目录并启动
mkdir -p /data/r0 /data/r1 /data/r2
注意:在启动3个实例时,必须要声明 实例属于某复制集
./bin/mongod --port 27017 --dbpath /data/r0 --replSet rsa --fork --logpath /var/log/mongo17.log
./bin/mongod --port 27018 --dbpath /data/r1 --replSet rsa --fork --logpath /var/log/mongo18.log
./bin/mongod --port 27019 --dbpath /data/r2 --replSet rsa --fork --logpath /var/log/mongo19.log
注意:
- 当在启动服务时报错,报错:
To see additional information in this output, start without the "--fork" option
先看下三个服务的dbpath是不是指向同一个了,三个服务的dbpath应该三个不同的目录,当把dbpath指向正确的地方时还不能启动,那就把dbpath目录下的文件都删除掉
因为kill -9 杀掉进程会产生mongod.lock文件,先把mongod.lock文件删了试试看,如果不行就把dbpath下全删除了
1.2.2.2 配置及初始化
先随便连上一台服务器,然后切换到admin数据库
var rsconf = {
_id:'rsa', //复制集名字
members: //成员集合
[
{_id:0,
host:'192.168.1.201:27017'
},
{_id:1,
host:'192.168.1.201:27018'
},
{_id:2,
host:'192.168.1.201:27019'
}
]
}
根据配置做初始化
rs.initiate(rsconf);
查看复制集信息:
查看配置
rs.conf();
查看状态
rs.status();
查看帮助信息
rs.help();
1.2.2.3 操作节点
添加节点
rs.add('192.168.1.201:27018');
rs.add('192.168.1.201:27019');
删除节点
rs.remove('192.168.1.201:27019');
主节点插入数据
>use test
>db.user.insert({uid:1,name:'lily'});
连接secondary查询同步情况
./bin/mongo --port 27019
>use test
>show tables
rsa:SECONDARY> show tables;
Sat Aug 17 16:03:55.786 JavaScript execution failed: error: { "$err" : "not master and slaveOk=false", "code" : 13435 }
出现上述错误,是因为slave默认不许读写
>rs.slaveOk();
>show tables
1.2.2.4 不正常关闭服务
mongodb不正常关闭形成的mongodb被锁定,这算是一个Mongod启动的一个常见错误,非法关闭的时候,lock 文件没有remove,第二次启动的时候检查到有lock 文件的时候,就报这个错误了
- 首先删除数据库目录下的
mongod.lock文件 repair方式启动mongodb
./mongod -f /etc/mongod.conf --repair
1.3 分片
1.3.1 简介
分片是指把数据分布存储在多台机器上,从而达到存储超大数据,及提高数据吞吐量的目的,分片就要使用命令mongos命令来请求路由
注意:在replication中,每台机器存储的内容是一致的,而sharding中,每台机器存储数据的一部分
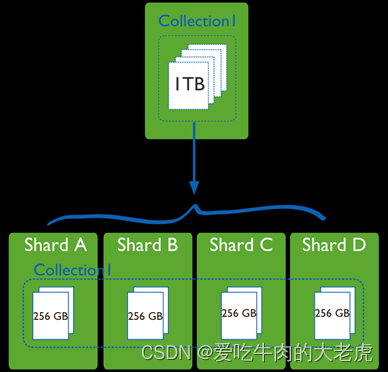
1.3.2 结构
分片要有如下要素:
- 要有
N(N>=2)个mongod服务做片节点 - 要有
config server维护meta信息 - 要启动
mongos做路由 - 要设定号数据的分片规则(
config server才能维护)
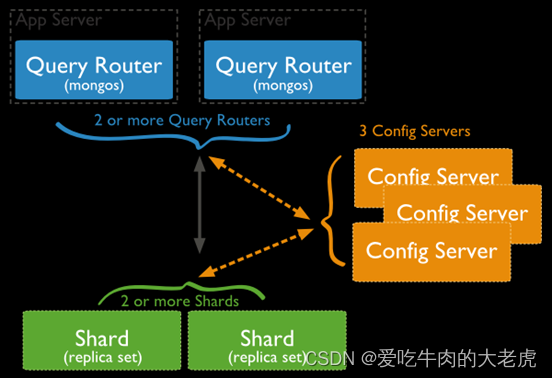
mongos查询某条数据时,要先找config server,询问得到该数据在哪个shard分片上
mongs,请求路由config server,存储元数据--即某台数据存储于某个sharding
它不存储真的数据,存储meta信息,即某条数据在哪个片上的信息shard--mongod实例或repla set
1.3.3 配置分片
1.3.3.1 创建分片服务
./bin/mongod --port 27017 --dbpath share/data01 --logpath logs/mongod01.log --fork --replSet share --shardsvr
./bin/mongod --port 27018 --dbpath share/data02 --logpath logs/mongod02.log --fork --replSet share --shardsvr
./bin/mongod --port 27019 --dbpath share/data03 --logpath logs/mongod03.log --fork --replSet share --shardsvr
1.3.3.2 创建配置服务
创建配置服务,这里我们完全可以像启动普通mongodb服务一样启动
./bin/mongod --port 28017 --dbpath replSet/data01 --logpath logs/mongod01.log --fork --replSet config --configsvr
./bin/mongod --port 28018 --dbpath replSet/data02 --logpath logs/mongod02.log --fork --replSet config --configsvr
./bin/mongod --port 28019 --dbpath replSet/data03 --logpath logs/mongod03.log --fork --replSet config --configsvr
1.3.3.3 配置连接路由
配置mongos,通过 configdb 来说明是为哪个服务服务的
./bin/mongos --port 30000 --logpath /var/log/mongo30.log\
--configdb 127.0.0.1:27020 --fork
报错:
BadValue: configdb supports only replica set connection string
如上, 出现这个问题, 是因为使用的MongoDB 5.0.6版,这个版本在之前的版本上有做调整,要求configs服务器是副本集模式。3.2和3.2以下都不做强制要求的。
解决办法:
configs服务器配置成副本集模式
比如:./bin/mongos --port 30000 --configdb rsa/127.0.0.1:28017 --logpath logs/router.log --fork- 把MongoDB换成3.4以下版本
连接路由器,通过mongos的端口连接
./bin/mongo --port 30000
1.3.3.4 添加分片
sh.addShard('share/127.0.0.1:27017,127.0.0.1:27018,127.0.0.1:27019');
分片相关的状态
sh.status();
查看帮助信息
sh.help();
1.3.3.5 对库表进行分片
添加待分片的库
sh.enableSharding(databaseName);
添加待分片的文档
>sh.shardCollection('dbName.collection',{field:1});
field是collection的一个字段,系统将会利用filed的值,来计算应该分到哪一个片上.这个filed叫片键(shard key)
1.3.3.6 分片相关问题
mongodb不是从单篇文档的级别,绝对平均的散落在各个片上,而是N篇文档,形成一个块chunk,优先放在某个片上,当这片上的chunk,比另一个片的chunk,区别比较大时, (>=3) ,会把本片上的chunk,移到另一个片上,以chunk为单位,维护片之间的数据均衡
问: 为什么插入了10万条数据,才2个chunk?
答: 说明chunk比较大(默认是64M),在config数据库中,修改chunksize的值
查看chunk大小:db.settings.find()
修改命令:db.settings.save({_id:'chunksize,value:1});
问: 既然优先往某个片上插入,当chunk失衡时(一个片34chunk,另一个36chunk),会自动移动chunk,自然随着数据的增多,shard的实例之间有chunk来回移动的现象,这将带来什么问题?
答: 服务器之间IO的增加,
问: 能否自定义一个规则,某N条数据形成1个块,预告分配M个chunk,M个chunk预告分配在不同片上,以后的数据直接入各自预分配好的chunk,不再来回移动?
答: 能,手动预先分片
1.3.4 手动预先分片
以shop.user表为例
- 配置分片的表
user表用userid做shard key
sh.shardCollection('shop.user',{userid:1}); - 使用
sh.splitAt分片
预先在1K 2K...40K这样的界限切好chunk(虽然chunk是空的), 这些chunk将会均匀移动到各片上.
for(var i=1;i<=40;i++) { sh.splitAt('shop.user',{userid:i*1000}) } - 通过
mongos添加user数据
数据会添加到预先分配好的chunk上,chunk就不会来回移动了.
1.3.5 复制集和分片相结合
配置复制集参考上面步骤
配置分片参考上面步骤,向分片中添加复制集分片时不同
sh.addShard('复制集名字'/ip:port);
sh.addShard('rsa/127.0.0.1:27017');
sh.addShard('rsa/127.0.0.1:27018');